Your Learning progress might get lost. Sign in or Join to save your progress.
close
Achieving Advanced Insights with BigQuery
Course
·
5 hours 30 minutes
check
Complete
< 1%
complete
Quick tip: Review the prerequisites before you run the lab
Use an Incognito or private browser window to run this lab. This prevents any conflicts between your personal account and the student account, which may cause extra charges incurred to your personal account.
Test and share your knowledge with our community!
done
Get access to over 700 hands-on labs, skill badges, and courses
Get access to over 700 hands-on labs, skill badges, and courses
Overview
BigQuery is Google's fully managed, NoOps, low cost analytics database. With BigQuery you can query terabytes and terabytes of data without having any infrastructure to manage or needing a database administrator. BigQuery uses SQL and can take advantage of the pay-as-you-go model. BigQuery allows you to focus on analyzing data to find meaningful insights.
This lab focuses on how to architect a data warehouse for query performance. In this lab, you will compare a traditional relational schema with joins against a denormalized schema. You will also use BigQuery's Query Execution Plan to quantifiably assess performance trade-offs.
What you'll do
In this lab, you will learn how to perform these tasks:
Load a comma-separated value (CSV) file into a BigQuery table using the web UI.
Load a JavaScript® Object Notation (JSON) file into a BigQuery table using the command-line interface (CLI).
Transform data and join tables using the web UI.
Store query results in a destination table.
Query a destination table using the web UI to confirm your data was transformed and loaded correctly.
Setup and requirements
For each lab, you get a new Google Cloud project and set of resources for a fixed time at no cost.
Sign in to Qwiklabs using an incognito window.
Note the lab's access time (for example, 1:15:00), and make sure you can finish within that time.
There is no pause feature. You can restart if needed, but you have to start at the beginning.
When ready, click Start lab.
Note your lab credentials (Username and Password). You will use them to sign in to the Google Cloud Console.
Click Open Google Console.
Click Use another account and copy/paste credentials for this lab into the prompts.
If you use other credentials, you'll receive errors or incur charges.
Accept the terms and skip the recovery resource page.
Activate Google Cloud Shell
Google Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud.
Google Cloud Shell provides command-line access to your Google Cloud resources.
In Cloud console, on the top right toolbar, click the Open Cloud Shell button.
Click Continue.
It takes a few moments to provision and connect to the environment. When you are connected, you are already authenticated, and the project is set to your PROJECT_ID. For example:
gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab-completion.
You can list the active account name with this command:
[core]
project = qwiklabs-gcp-44776a13dea667a6
Note:
Full documentation of gcloud is available in the
gcloud CLI overview guide
.
Open BigQuery Console
In the Google Cloud Console, select Navigation menu > BigQuery.
The Welcome to BigQuery in the Cloud Console message box opens. This message box provides a link to the quickstart guide and lists UI updates.
Click Done.
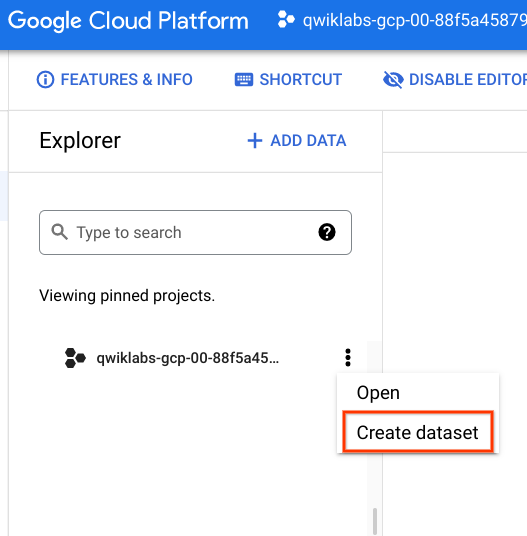
Task 1. Create a new dataset to store your tables
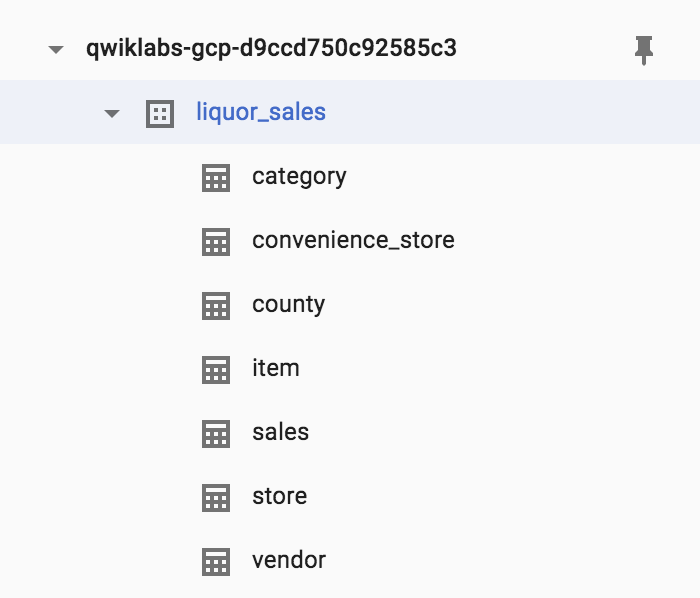
In your BigQuery project, create a new dataset titled liquor_sales.
In the Explorer section, click on the View actions icon next to your project ID and select Create dataset.
The Create dataset dialog opens.
Set the dataset ID to liquor_sales. Leave the other options at their default values, and click Create dataset.
In the left pane, you see a liquor_sales table listed under your project.
Task 2. Load and query relational data
In this section, you measure query performance for relational data in BigQuery.
BigQuery supports large JOINs, and JOIN performance is good. However, BigQuery is a columnar datastore, and maximum performance is achieved on denormalized datasets. Because BigQuery storage is inexpensive and scalable, it's a good practice to denormalize and pre-JOIN datasets into homogeneous tables. In other words, you exchange compute resources for storage resources (the latter being more performant and cost-effective).
In this section, you will be doing the following:
Upload a set of tables from a relational schema (in 3rd normal form).
Run queries against the relational tables.
Note the performance of the queries to compare to the performance of the same queries against a table from a denormalized schema containing the same information.
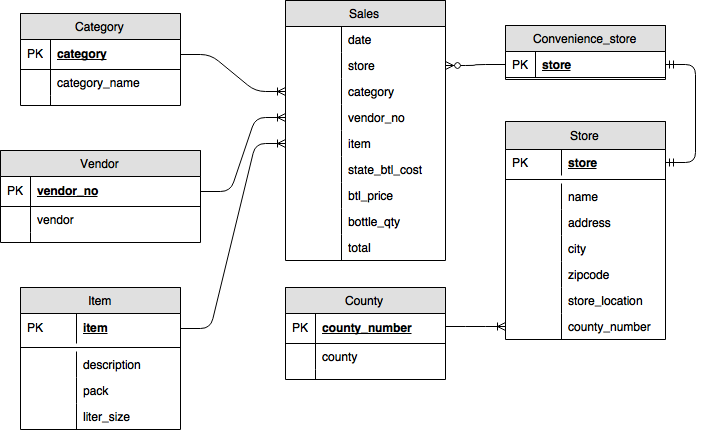
You upload tables that have a relational schema. The relational schema consists of the following tables:
Table name
Description
sales
Contains the date and sales metrics.
item
The description of the item sold.
vendor
The producer of the item.
category
The grouping to which the item belongs.
store
The store that sold th item.
county
The county where the item was sold.
convenience_store
The list of stores that are considered convenience stores.
Here's a diagram of the relational schema.
Create the sales table
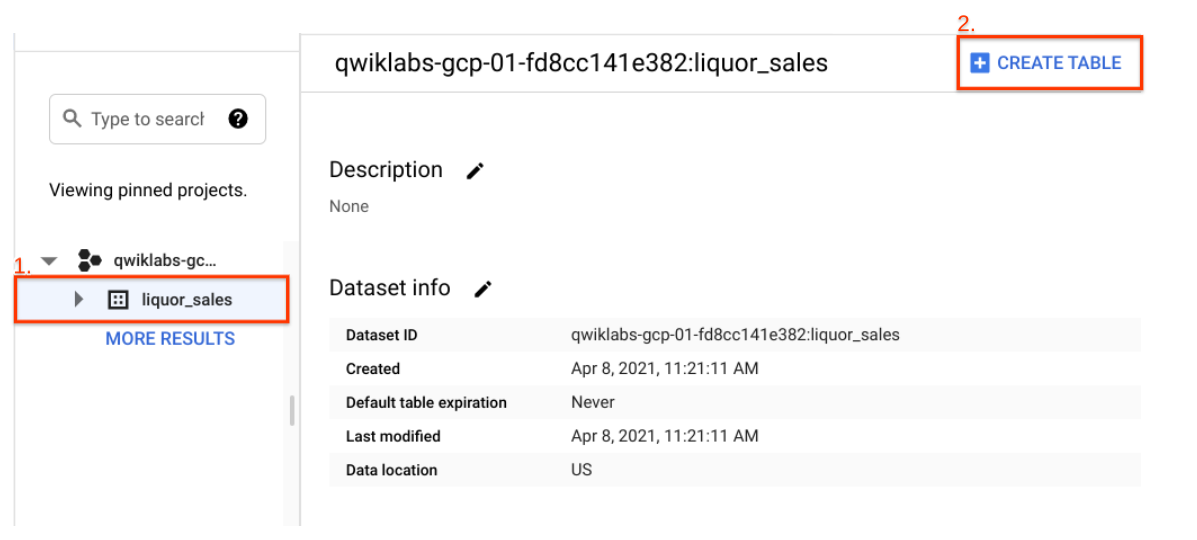
In the Explorer section, click on the View actions icon next to the liquor_sales dataset, select Open, and then click Create Table.
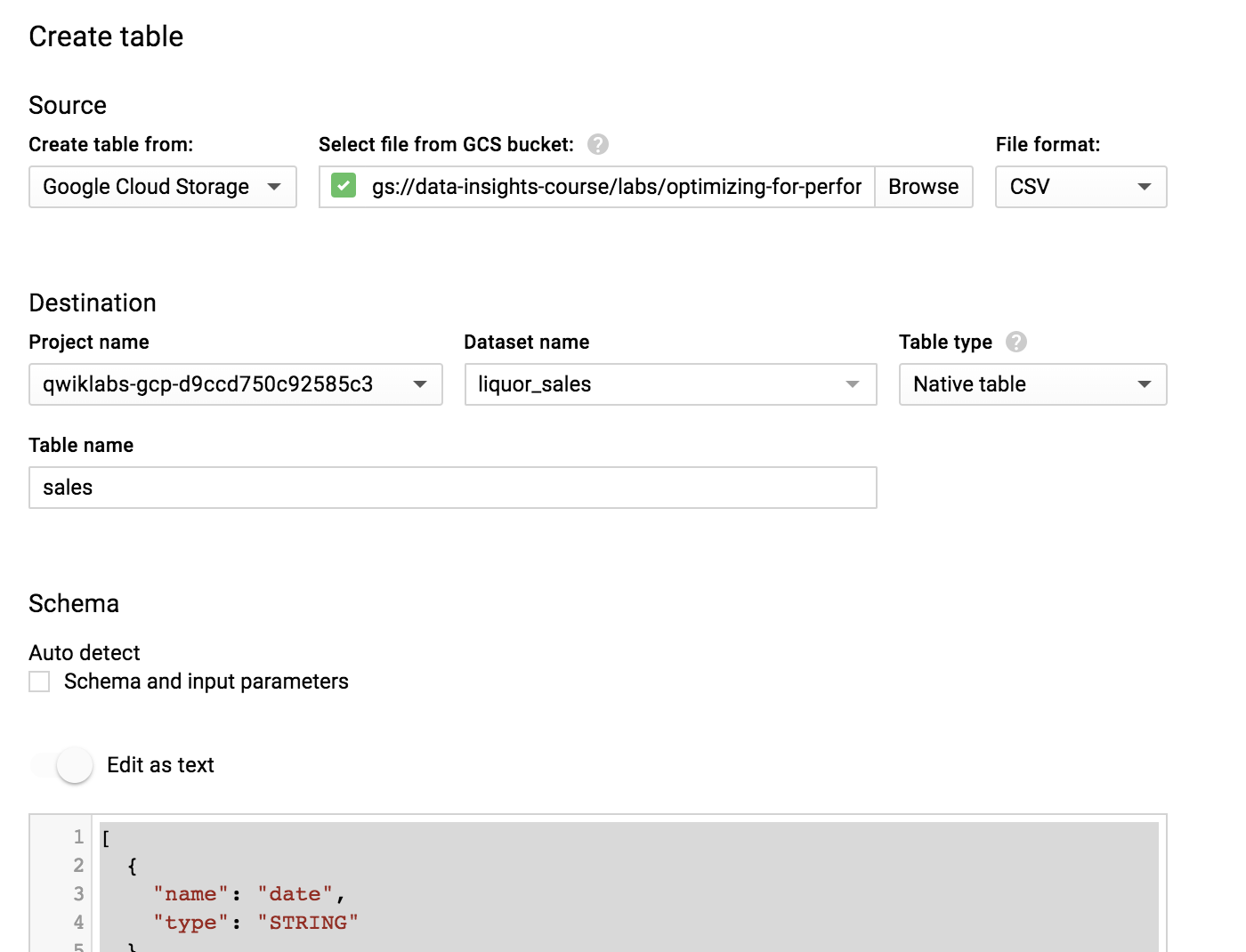
On the Create Table page, in the Source section, do the following:
For Create table from, choose Google Cloud Storage.
Enter the path to the Google Cloud Storage bucket name:
Go back to the BigQuery web UI. Confirm you see the new tables loaded into your liquor_sales dataset. Refresh the browser if needed.
Query relational data
Next, you use the Query editor to query your data.
Under the Query editor code box, click More > Query Settings.
In the Resource management, Cache preference section, uncheck the Use Cached Results checkbox and click Save. If you have to run the query more than once, you don't want to use cached results.
In the Query editor window, enter the following query against the relational tables and click Run:
#standardSQL
SELECT
gstore.county AS county,
ROUND(cstore_total/gstore_total * 100,1) AS cstore_percentage
FROM (
SELECT
cy.county AS county,
SUM(total) AS gstore_total
FROM
`liquor_sales.sales` AS s
JOIN
`liquor_sales.store` AS st
ON
s.store = st.store
JOIN
`liquor_sales.county` AS cy
ON
st.county_number = cy.county_number
LEFT OUTER JOIN
`liquor_sales.convenience_store` AS c
ON
s.store = c.store
WHERE
c.store IS NULL
GROUP BY
county) AS gstore
JOIN (
SELECT
cy.county AS county,
SUM(total) AS cstore_total
FROM
`liquor_sales.sales` AS s
JOIN
`liquor_sales.store` AS st
ON
s.store = st.store
JOIN
`liquor_sales.county` AS cy
ON
st.county_number = cy.county_number
LEFT OUTER JOIN
`liquor_sales.convenience_store` AS c
ON
s.store = c.store
WHERE
c.store IS NOT NULL
GROUP BY
county) AS hstore
ON
gstore.county = hstore.county
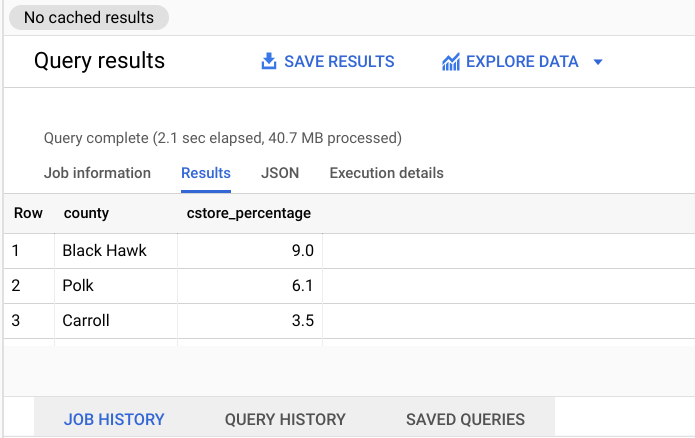
At the bottom, in the Query results section, click on the Results tab. Note the Query complete time. An example is shown below (your execution time may vary).
This will be compared to the time to query a flattened dataset in later sections.
Task 3. Load and query flattened data
In this section, you denormalize the schemas and analyze liquor sales for the state of Iowa using the flattened data. Running this query on the flattened data should be faster than running on the relational data. You will note the time to compare and confirm.
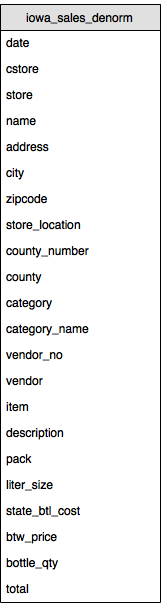
A denormalized schema flattens all relational data into a single row. For example, in the denormalized schema, county_number, county, store, name, address, city, zipcode, store_location, county_number, and cstore are fields containing all fields from the County, Store, and Convenience_store tables.
Note: The cstore field (in the denormalized schema) represents the convenience_store.store field in the relational schema above. It has a value of Y if a store is a convenience store, and null otherwise.
The following diagram shows the denormalized schema.
Create the iowa_sales_denorm table
In the left pane, select liquor_sales dataset and click Create Table on the right.
The Create table dialog opens.
In the Source section, configure the following:
For Create table from, choose Google Cloud Storage.
Enter the path to the Google Cloud Storage bucket name:
In the Advanced options section, configure as follows:
For Field delimiter, verify that Comma is selected.
Because iowa_sales_denorm.csv contains a single header row, for Header rows to skip, enter 1.
Check Quoted newlines.
Accept the remaining default values and click Create Table.
BigQuery creates a load job to create the table and upload data into the table (this may take a few seconds).
Click Personal History to track job progress.
Enter and run the following query against the table with a denormalized schema (this query produces the same results as the query in the previous section):
#standardSQL
SELECT
gstore.county AS county,
ROUND(cstore_total/gstore_total * 100,1) AS cstore_percentage
FROM (
SELECT
county,
sum(total) AS gstore_total
FROM
`liquor_sales.iowa_sales_denorm`
WHERE cstore is null
GROUP BY
county) AS gstore
JOIN (
SELECT
county,
sum(total) AS cstore_total
FROM
`liquor_sales.iowa_sales_denorm`
WHERE cstore is not null
GROUP BY
county) AS cstore
ON gstore.county = cstore.county
ORDER BY county
At the bottom, in the Query results section, click on the Results tab, note the Query complete time. This will be compared to the time to query a flattened dataset in later sections.
Note the time the query takes to run by subtracting the Start Time from the End Time.
Notice that the query corresponding to the table with denormalized schema runs slightly faster, and has simpler syntax. Wherever possible, pre-JOIN datasets into homogeneous tables to optimize performance in BigQuery.
Compare query performance with execution details
Select PROJECT HISTORY.
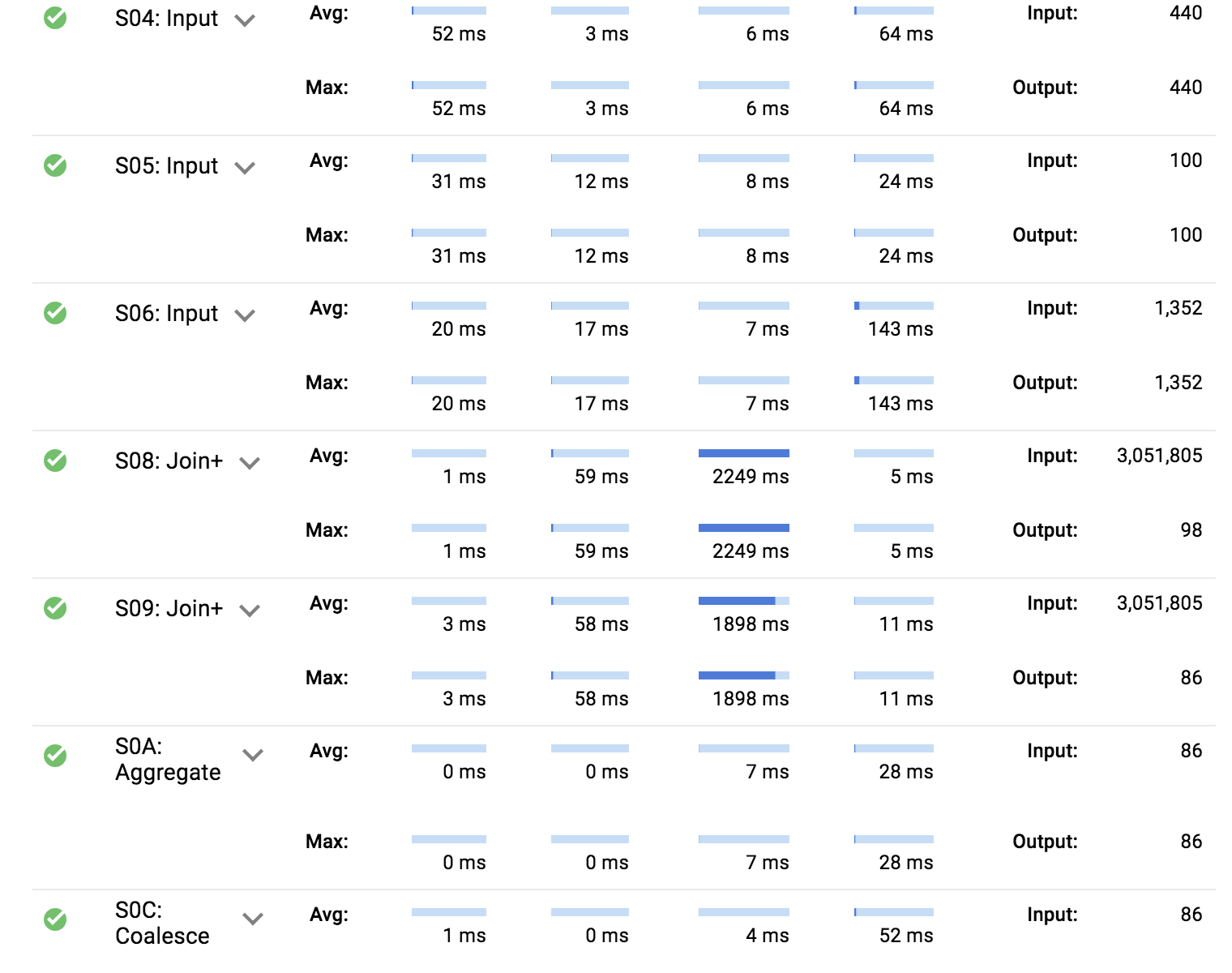
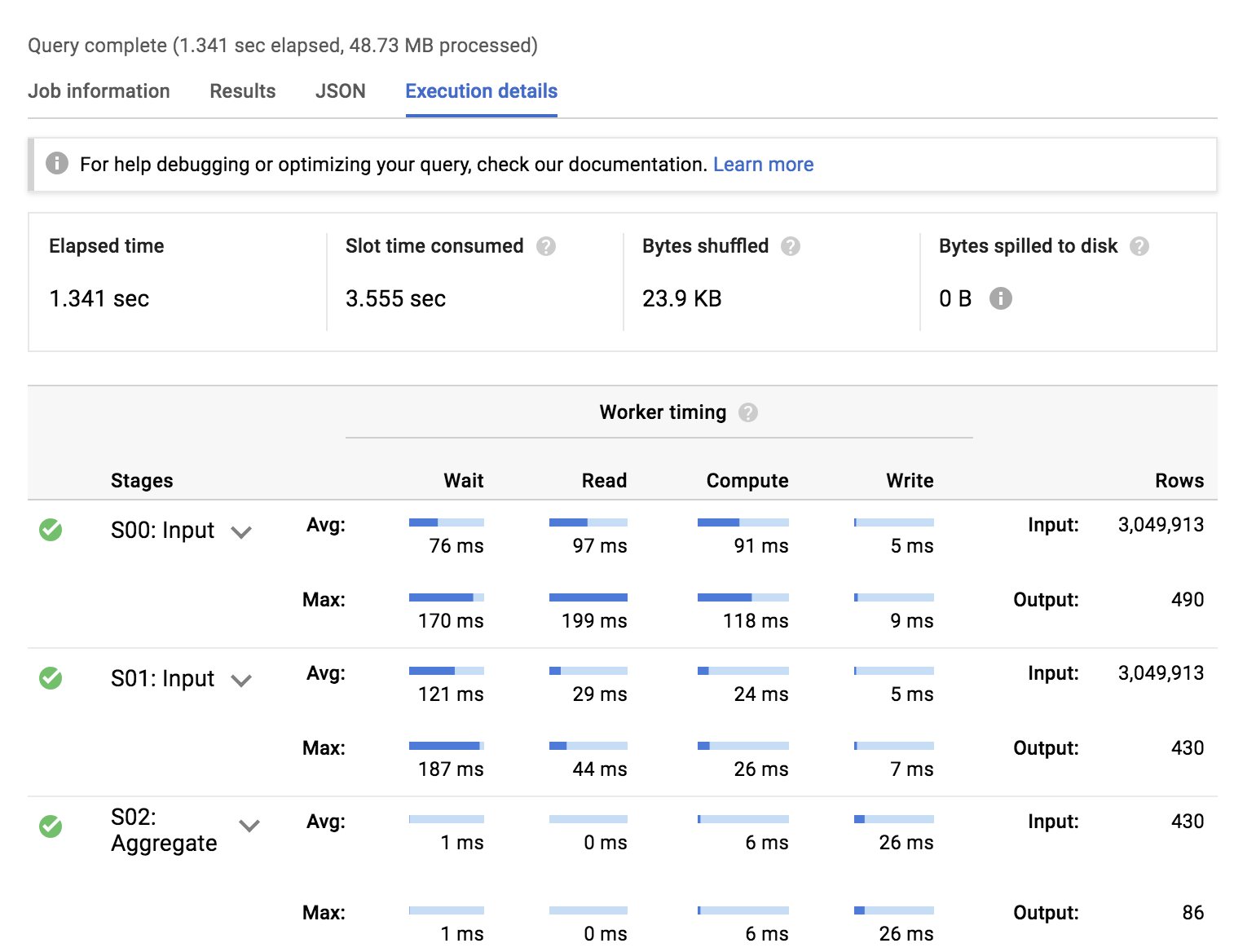
Click the first query job you ran against the normalized relational schema, then click OPEN AS NEW QUERY.
Select Execution details.
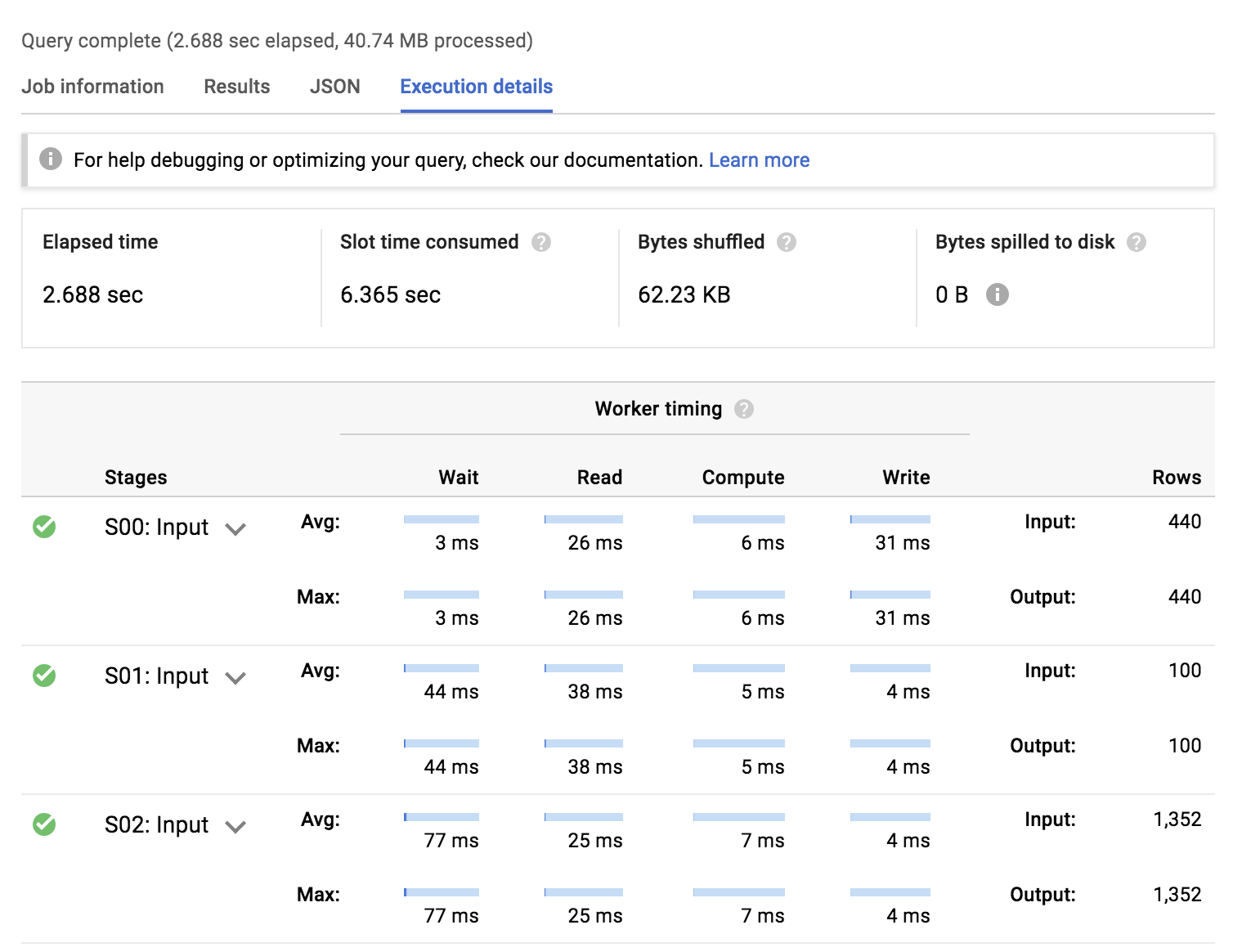
The execution plan has two major sections:
Average and max worker timing by type of work per stage
High level perforomance benchmarks
Elapsed time: Total time for the query to process.
Slot time consumed: If the query were not processed in parallel on multiple machines, how long would it take to process.
Bytes shuffled: Automatic in-memory data shuffling for massive parallel processing.
Bytes spilled to disk: If data cannot be processed in memory, how much was spilled to persistent disk (usually data skew is to blame).
First, compare the benchmark timings between each of the queries we ran.
Next, compare the type of work where the workers spent the most time.
Query 1. Relational schema execution details
Query 2. Denormalized schema execution details
Observations:
The denormalized query (#2) is faster and uses less slot time to achieve the same result.
The relational query (#1) has many more input stages and spends the most worker time in joining the datasets together.
The denormalized query (#2) spends the most time reading data input and outputting the results. There is minimal time spent in aggregations and joins.
Neither query resulted in bytes spilled to disk which suggests out datasets are likely not skewed (or significantly large enough to spill out from memory from an individual worker).
Note: The queries used in this lab are for demonstration purposes only. The time difference between the 2 queries becomes more significant as the dataset sizes increase and the complexity of the JOIN clauses increases.
To learn more about execution details and query plan optimization, you can refer to the query plan explanation reference guide.
Avoiding performance anti-patterns
Now that you are familiar with effective database schema design, it is time to practice optimizing some poorly written queries.
The below query is running slowly, what can you do to correct it?
Copy and paste the below query into the Query editor and run the query to get a benchmark.
Goal: Count all the U.S. non-profit organizations that have filed taxes using paper (non-electronic) in 2015.
#standardSQL
# count all paper filings for 2015
SELECT * FROM `bigquery-public-data.irs_990.irs_990_2015`
WHERE UPPER(elf) LIKE '%P%' #Paper Filers in 2015
ORDER BY ein
# 86,831 as per pagination count, 23s
What can you do to improve the performance?
Compare against the below solution:
#standardSQL
SELECT COUNT(*) AS paper_filers FROM `bigquery-public-data.irs_990.irs_990_2015`
WHERE elf = 'P' #Paper Filers in 2015
# 86,831 at 2s
/*
Remove ORDER BY when there is no limit
Use Aggregation Functions
Examine data and confirmed P always uppercase
*/
Run your updated version and track the time.
Clear the Query editor.
This new below query is running slowly. (Run the query to get a benchmark; stop after 30 seconds if it does not complete).
Goal: Using the Employer Identification Number (ein) as a linking field, join together the tax return filings table with the organizational names table and return the names of all the organizations that filed in 2015.
Add this query in the Query editor, then click Run:
#standardSQL
# get all Organization names who filed in 2015
SELECT
tax.ein,
name
FROM
`bigquery-public-data.irs_990.irs_990_2015` tax
JOIN
`bigquery-public-data.irs_990.irs_990_ein` org
ON
tax.tax_pd = org.tax_period
Correct the above query. (Hint: Remember the correct JOIN field condition for our schema).
Compare against the below solution.
Add this query in the Query editor, then click Run:
#standardSQL
# get all Organization names who filed in 2015
SELECT
tax.ein,
name
FROM
`bigquery-public-data.irs_990.irs_990_2015` tax
JOIN
`bigquery-public-data.irs_990.irs_990_ein` org
ON
tax.ein = org.ein
# 86,831 as per pagination count, 23s
/*
Incorrect JOIN key resulted in CROSS JOIN
Correct result: 294,374 at 13s
*/
Run your updated version and track the time.
Do you see an improvement? How quickly does the query run?
Lessons learned
Congratulations!
This concludes this hands-on lab looking at Effective BigQuery Schema Design and Query Performance. You have loaded CVS and JSON files into BigQuery tables, transformed data and join tables, stored query results, and then confirmed that data was transformed and loaded correctly.
End your lab
When you have completed your lab, click End Lab. Google Cloud Skills Boost removes the resources you’ve used and cleans the account for you.
You will be given an opportunity to rate the lab experience. Select the applicable number of stars, type a comment, and then click Submit.
The number of stars indicates the following:
1 star = Very dissatisfied
2 stars = Dissatisfied
3 stars = Neutral
4 stars = Satisfied
5 stars = Very satisfied
You can close the dialog box if you don't want to provide feedback.
For feedback, suggestions, or corrections, please use the Support tab.
Copyright 2022 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.
Labs create a Google Cloud project and resources for a fixed time
Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
On the top left of your screen, click Start lab to begin
Use private browsing
Copy the provided Username and Password for the lab
Click Open console in private mode
Sign in to the Console
Sign in using your lab credentials. Using other credentials might cause errors or incur charges.
Accept the terms, and skip the recovery resource page
Don't click End lab unless you've finished the lab or want to restart it, as it will clear your work and remove the project
This content is not currently available
We will notify you via email when it becomes available
Great!
We will contact you via email if it becomes available
One lab at a time
Confirm to end all existing labs and start this one
Use private browsing to run the lab
Use an Incognito or private browser window to run this lab. This
prevents any conflicts between your personal account and the Student
account, which may cause extra charges incurred to your personal account.
This lab focuses on how to architect a data warehouse for query performance. You will compare a traditional relational schema with joins against a denormalized schema and use BigQuery’s Query Execution Plan to quantifiably assess performance trade-of