



Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Create a cloud data fusion instance
/ 25
Add Cloud Data Fusion API Service Agent role to service account
/ 25
Deploy a sample pipeline
/ 25
View the result
/ 25
This lab teaches you how to create a Data Fusion instance and deploy a sample pipeline that's provided. The pipeline reads a JSON file containing NYT bestseller data from Cloud Storage. The pipeline then runs transformations on the file to parse and clean the data. And finally loads a subset of the records into BigQuery.
In this lab you will learn to:
For each lab, you get a new Google Cloud project and set of resources for a fixed time at no cost.
Sign in to Qwiklabs using an incognito window.
Note the lab's access time (for example, 1:15:00), and make sure you can finish within that time.
There is no pause feature. You can restart if needed, but you have to start at the beginning.
When ready, click Start lab.
Note your lab credentials (Username and Password). You will use them to sign in to the Google Cloud Console.
Click Open Google Console.
Click Use another account and copy/paste credentials for this lab into the prompts.
If you use other credentials, you'll receive errors or incur charges.
Accept the terms and skip the recovery resource page.
Since this is a temporary account, which will last only as long as this lab:
 ) at the top-left.
) at the top-left.Cloud Shell is a virtual machine that contains development tools. It offers a persistent 5-GB home directory and runs on Google Cloud. Cloud Shell provides command-line access to your Google Cloud resources. gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab completion.
Click the Activate Cloud Shell button (
Click Continue.
It takes a few moments to provision and connect to the environment. When you are connected, you are also authenticated, and the project is set to your PROJECT_ID.
(Output)
(Example output)
(Output)
(Example output)
Before you begin working on Google Cloud, you must ensure that your project has the correct permissions within Identity and Access Management (IAM).
In the Google Cloud console, on the Navigation menu (
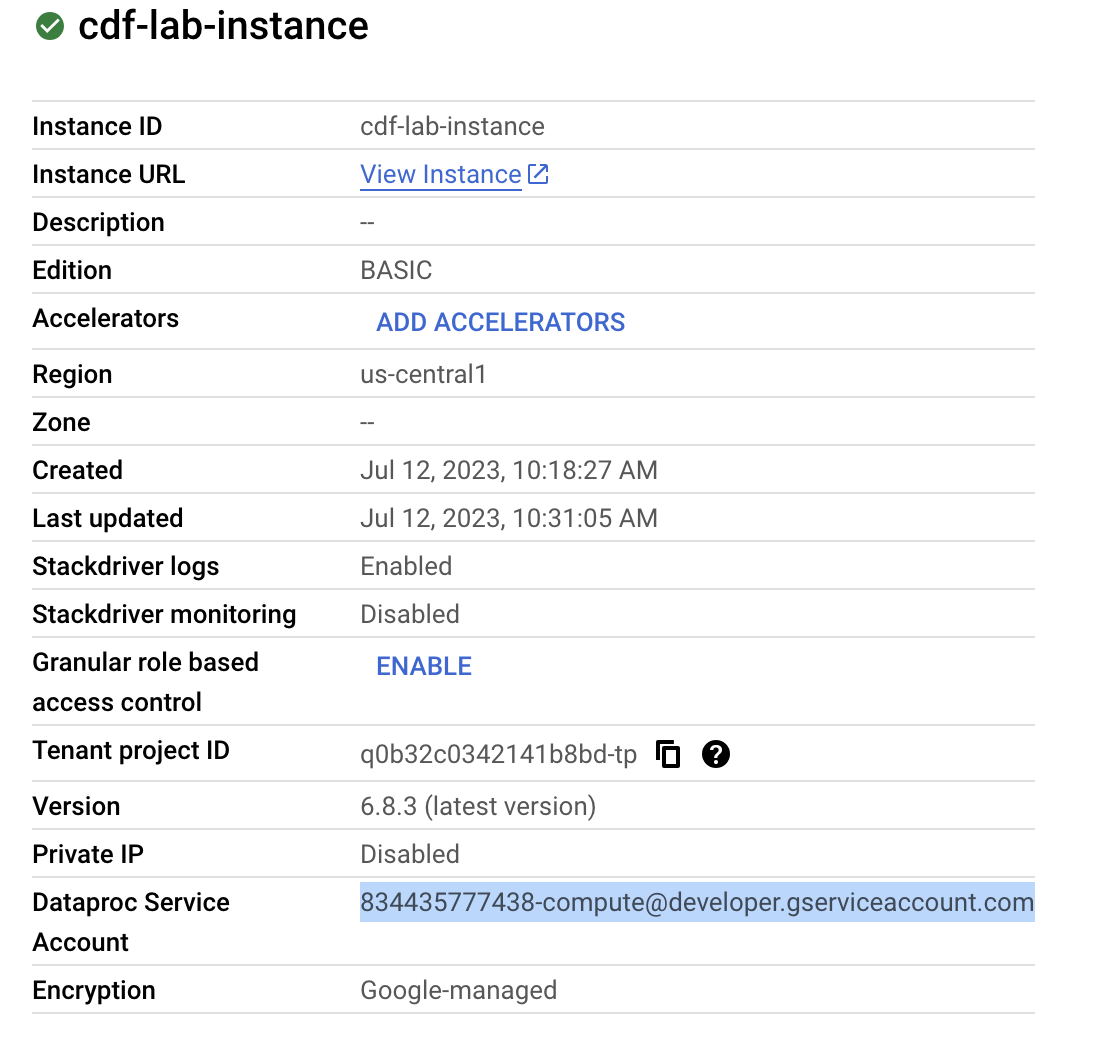
Confirm that the default compute Service Account {project-number}-compute@developer.gserviceaccount.com is present and has the editor role assigned. The account prefix is the project number, which you can find on Navigation menu > Cloud overview.
If the account is not present in IAM or does not have the editor role, follow the steps below to assign the required role.
In the Google Cloud console, on the Navigation menu, click Cloud overview.
From the Project info card, copy the Project number.
On the Navigation menu, click IAM & Admin > IAM.
At the top of the IAM page, click Add.
For New principals, type:
Replace {project-number} with your project number.
For Select a role, select Basic (or Project) > Editor.
Click Save.
In the Cloud console, from the Navigation menu, select APIs & Services > Library.
In the search box, type fusion to find the Cloud Data Fusion API and click on the hyperlink.
The API is already enabled, click Manage then click Disable API. Confirm Disable.
After the API is disabled, click Enable to re-enable the API.
In the Cloud console, from the Navigation menu click View All Products under Analytics select Data Fusion.
Click the Create an Instance link at the top of the section to create a Cloud Data Fusion instance.
In the Create Data Fusion instance page that loads:
a. Enter a name for your instance (like cdf-lab-instance). For region select us-central1.
b. Under Edition, select Basic
c. Click Grant Permission if required.
d. Click on the dropdown icon next to Advanced Options, under Logging and monitoring, check the checkbox for Enable Stackdriver logging service
e. Leave all other fields as-is, then click Create.
Click Check my progress to verify the objective.
Next, you will grant permissions to the service account associated with the instance, using the following steps.
In the Cloud console navigate to the IAM & Admin > IAM.
On the IAM Permissions page, click +Grant Access.
In the New principals field paste the service account.
Click into the Select a role field and start typing Cloud Data Fusion API Service Agent, then select it.
Click Save.
Click Check my progress to verify the objective.
When using Cloud Data Fusion, you use both the Cloud console and the separate Cloud Data Fusion UI.
In the Cloud console, you can create and delete Cloud Data Fusion instances, and view Cloud Data Fusion instance details.
In the Cloud Data Fusion web UI, you can use the various pages, such as Pipeline Studio or Wrangler, to use Cloud Data Fusion functionality.
To navigate the Cloud Data Fusion UI, follow these steps:
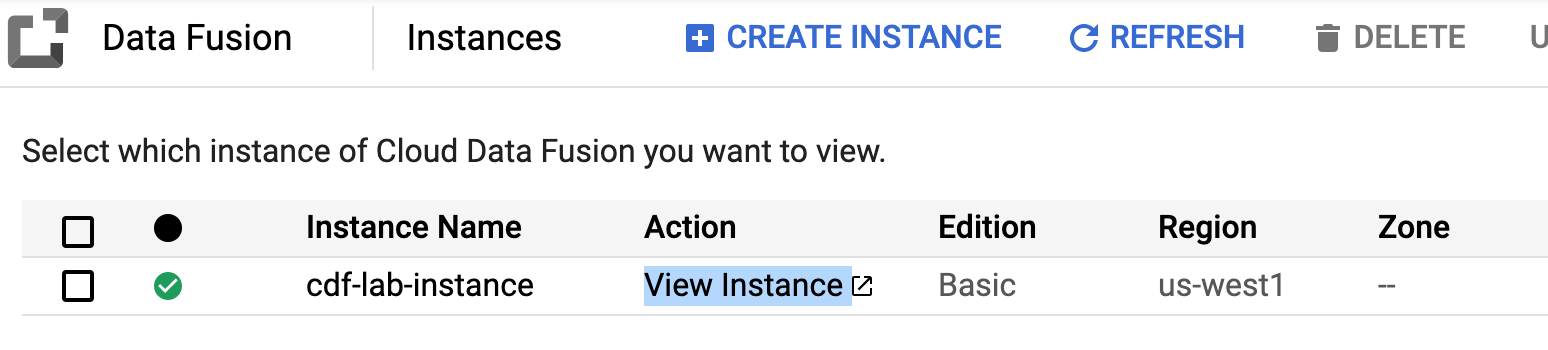
In the Cloud console return to Navigation menu > Data Fusion.
Click the View Instance link next to your Data Fusion instance. Select your lab credentials to sign in, if required.
If prompted to take a tour of the service click on No, Thanks. You should now be in the Cloud Data Fusion UI.
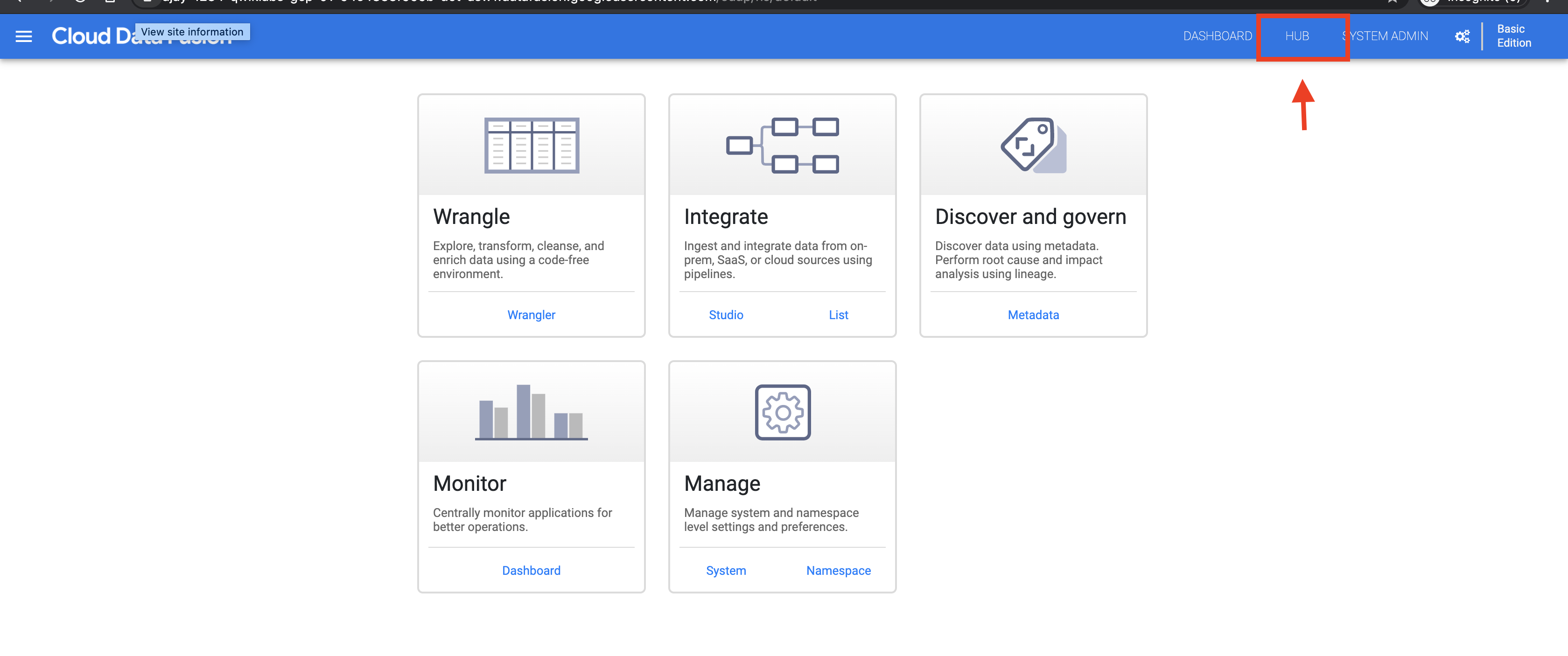
Notice that the Cloud Data Fusion web UI comes with its own navigation panel (on the left) to navigate to the page you need.
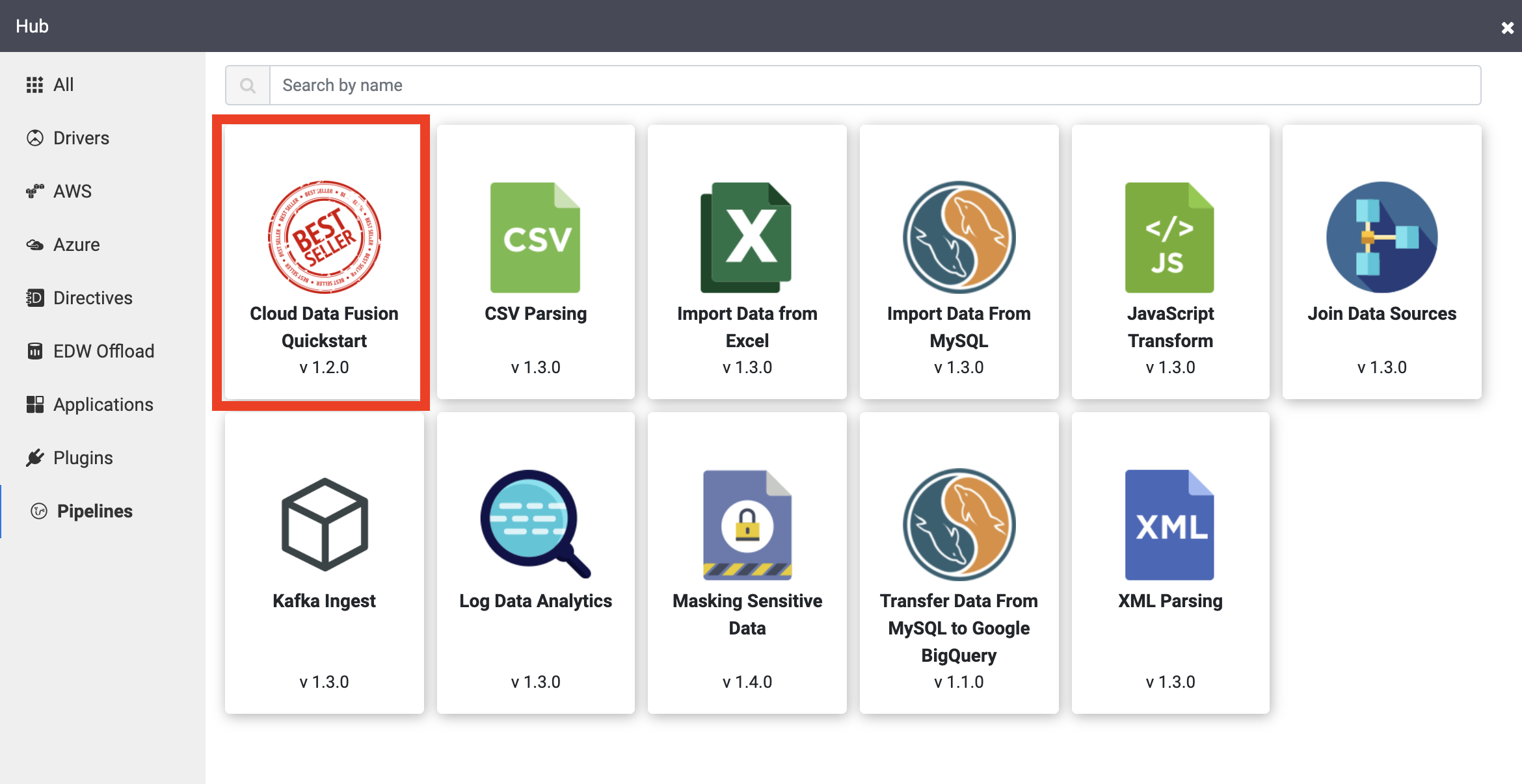
Sample pipelines are available through the Cloud Data Fusion Hub, which allows you to share reusable Cloud Data Fusion pipelines, plugins, and solutions.
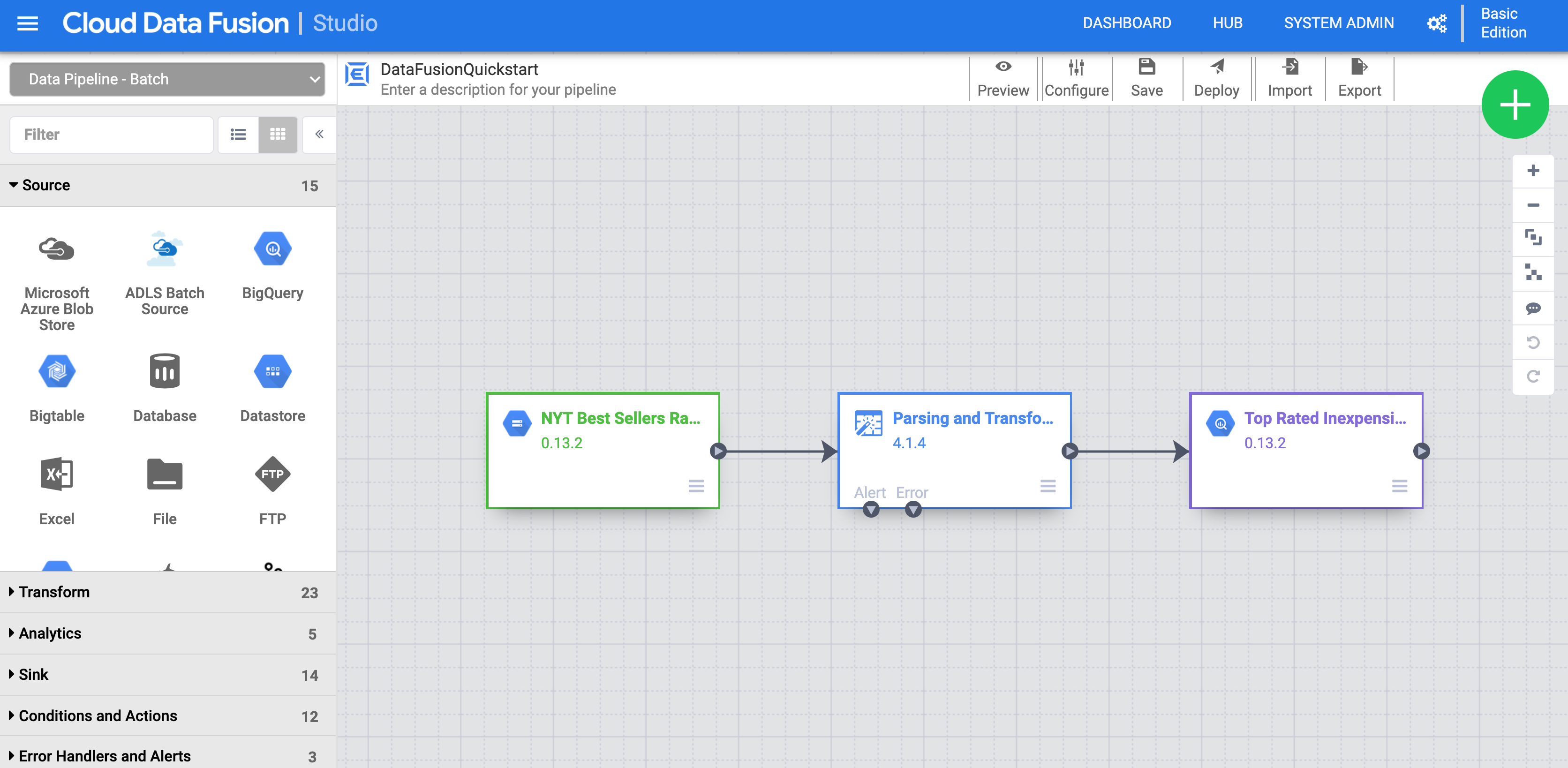
In the left panel, click Pipelines.
Click the Cloud Data Fusion Quickstart pipeline, and then click Create on the popup that appears.
In the Cloud Data Fusion Quickstart configuration panel, click Finish.
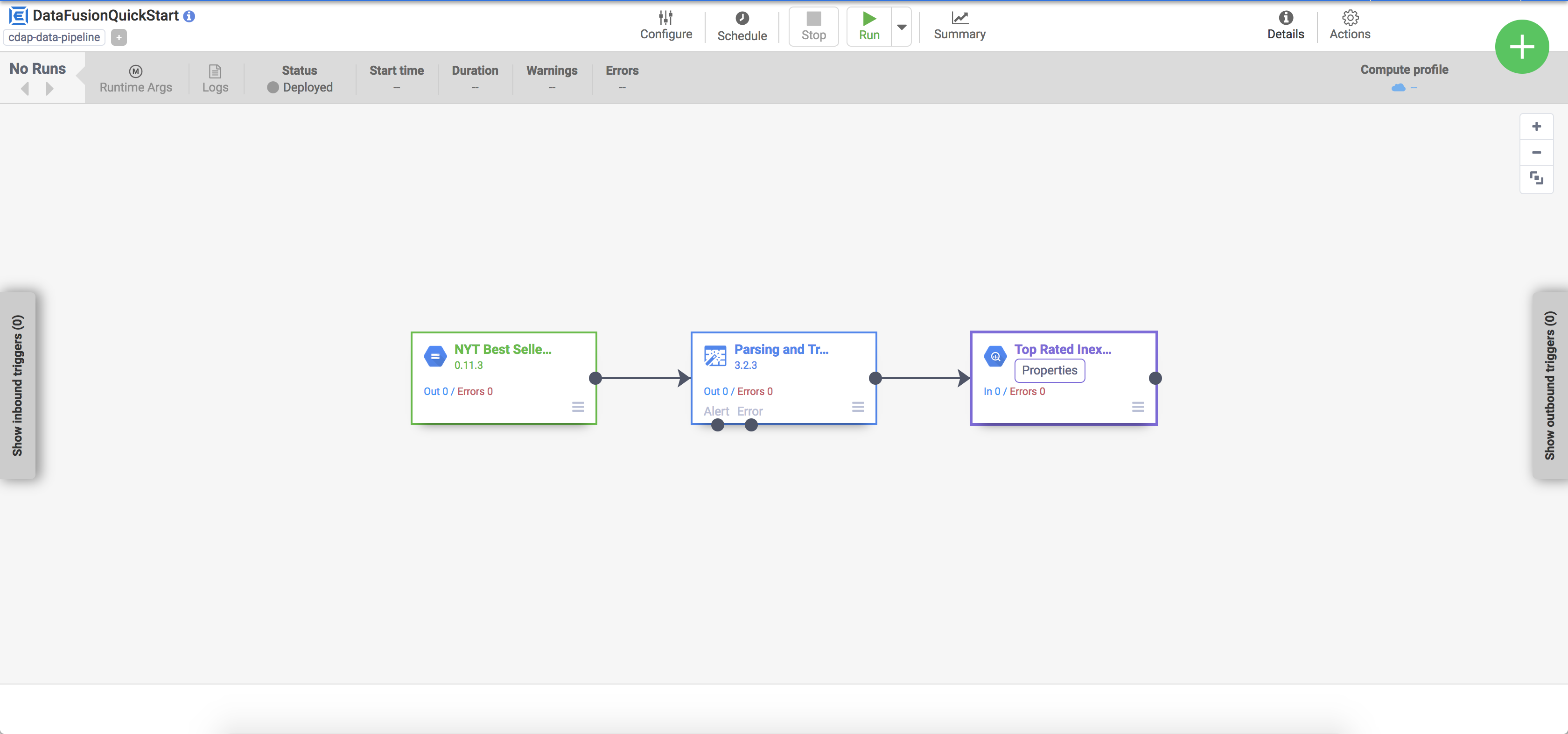
Click Customize Pipeline. A visual representation of your pipeline appears in the Pipeline Studio, which is a graphical interface for developing data integration pipelines. Available pipeline plugins are listed on the left, and your pipeline is displayed on the main canvas area. You can explore your pipeline by holding the pointer over each pipeline node and clicking the Properties button that appears. The Properties menu for each node allows you to view the objects and operations associated with the node.
The deployed pipeline appears in the pipeline details view, where you can do the following:
View the pipeline's structure and configuration.
Run the pipeline manually or set up a schedule or a trigger.
View a summary of the pipeline's historical runs, including execution times, logs, and metrics.
Click Check my progress to verify the objective.
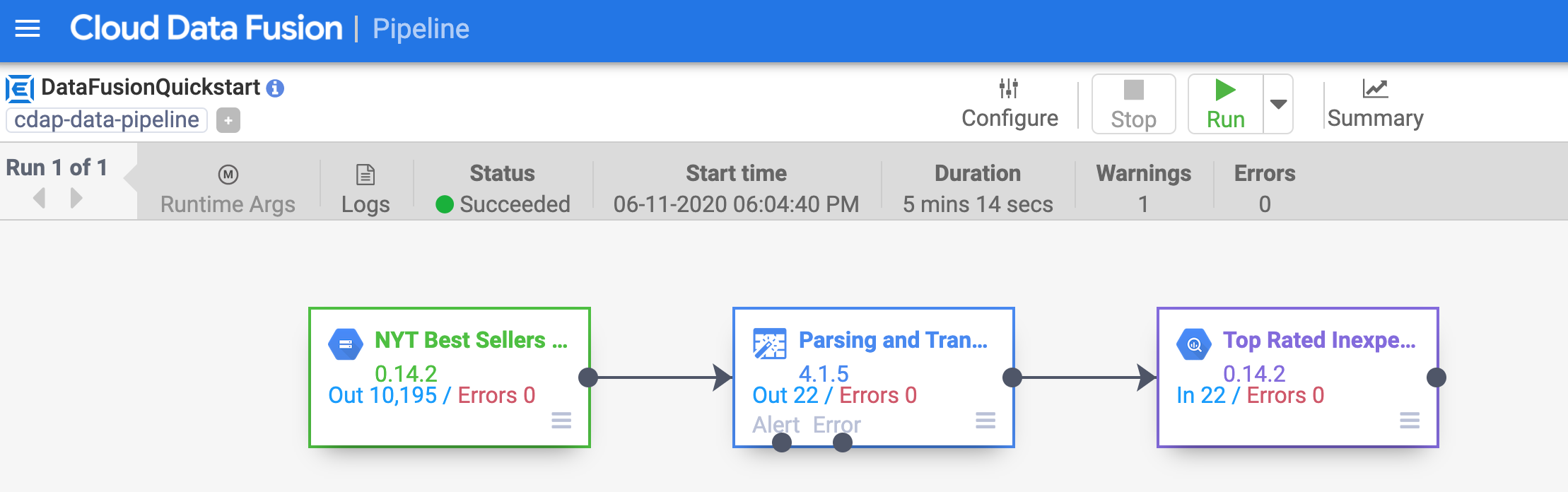
The pipeline writes output into a BigQuery table. You can verify that using the following steps.
Click to open this link to the BigQuery UI in Cloud console or right-click on the console tab and select Duplicate, then use the Navigation menu to select BigQuery.
In the left pane, click your Project ID (it will start with qwiklabs).
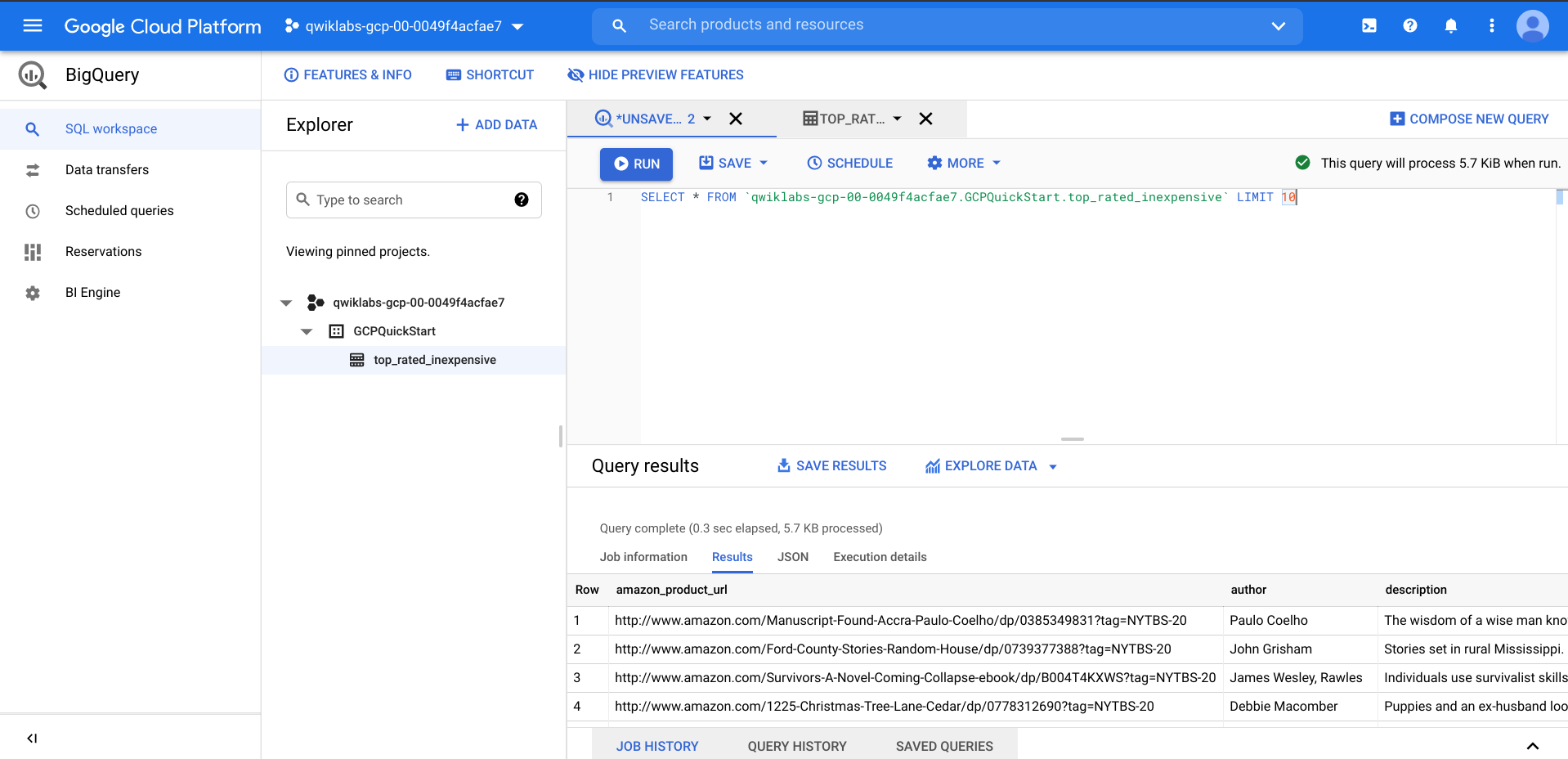
Under the GCPQuickstart dataset in your project, click the top_rated_inexpensive table, then run a simple query, such as:
Click Check my progress to verify the objective.
In this lab, you learned how to create a Data Fusion instance and deploy a sample pipeline that reads an input file from Cloud Storage, transforms and filters the data to output a subset of the data into BigQuery.
When you have completed your lab, click End Lab. Qwiklabs removes the resources you’ve used and cleans the account for you.
You will be given an opportunity to rate the lab experience. Select the applicable number of stars, type a comment, and then click Submit.
The number of stars indicates the following:
You can close the dialog box if you don't want to provide feedback.
For feedback, suggestions, or corrections, please use the Support tab.
Manual Last Updated January 28, 2025
Lab Last Tested January 28, 2025
Copyright 2022 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.



현재 이 콘텐츠를 이용할 수 없습니다
이용할 수 있게 되면 이메일로 알려드리겠습니다.

감사합니다
이용할 수 있게 되면 이메일로 알려드리겠습니다.

One lab at a time
Confirm to end all existing labs and start this one