Prüfpunkte
Create Namespaces
/ 10
Access Control in Namespaces
/ 25
Resource Quotas
/ 25
Monitoring GKE and GKE Usage Metering
/ 40
Mandantenfähigen GKE-Cluster mit Namespaces verwalten
- GSP766
- Übersicht
- Lernziele
- Einrichtung und Anforderungen
- Aufgabe 1: Benötigte Dateien herunterladen
- Aufgabe 2: Namespaces ansehen und erstellen
- Aufgabe 3: Zugriffssteuerung in Namespaces verwalten
- Aufgabe 4: Ressourcenkontingente festlegen
- Aufgabe 5: GKE-Monitoring und -Nutzungsmessung kennenlernen
- Das wars! Sie haben das Lab erfolgreich abgeschlossen.
GSP766

Übersicht
Bei der Überlegung, wie sich die Kosten einer Google Cloud-Infrastruktur optimieren lassen, deren Kern Google Kubernetes Engine-Cluster (GKE) bilden, sollte vor allem darauf geachtet werden, dass die abgerechneten Ressourcen effizient eingesetzt werden. Ein häufiger Fehler ist, Nutzer oder Teams Clustern im Verhältnis 1:1 zuzuweisen, was zu einer starken, kaum nachvollziehbaren Zunahme der Cluster führt.
Ein mandantenfähiger Cluster kann von mehreren Nutzern oder Teams gemeinsam für ihre Arbeitslasten verwendet werden, wobei die Isolierung und faire Aufteilung der Ressourcen sichergestellt bleiben. Dies wird durch das Erstellen von Namespaces ermöglicht. Dank Namespaces können mehrere virtuelle Cluster auf demselben physischen Cluster existieren.
In diesem Lab lernen Sie, wie Sie mit verschiedenen Namespaces einen mandantenfähigen Cluster einrichten, um die Ressourcennutzung und damit auch die Kosten zu optimieren.
Lernziele
Aufgaben in diesem Lab:
- Mehrere Namespaces in einem GKE-Cluster erstellen
- Rollenbasierte Zugriffssteuerung für den Namespace-Zugriff konfigurieren
- Kubernetes-Ressourcenkontingente für das faire Aufteilen von Ressourcen auf mehrere Namespaces konfigurieren
- Monitoring-Dashboards ansehen und konfigurieren, um die Ressourcennutzung nach Namespace zu prüfen
- Bericht zur GKE-Nutzungsmessung in Looker Studio erstellen, der detaillierte Messwerte der Ressourcennutzung nach Namespace enthält
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange die Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung selbst durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Pop-up-Fenster geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können. Auf der linken Seite befindet sich der Bereich Details zum Lab mit diesen Informationen:
- Schaltfläche Google Cloud Console öffnen
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite Anmelden geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden. -
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}} Sie finden den Nutzernamen auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}} Sie finden das Passwort auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos. Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen. -
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.

Vorbereitung
Nachdem Sie auf Lab starten geklickt haben, wird die Meldung Provisioning Lab Resources in Blau mit einem Hinweis zur geschätzten Restdauer angezeigt. In dieser Zeit wird die Umgebung erstellt und konfiguriert, die Sie verwenden werden, um das Verwalten eines mandantenfähigen Clusters zu testen. Innerhalb von etwa fünf Minuten wird ein Cluster erstellt, BigQuery-Datasets werden kopiert und Dienstkonten, die die Teams darstellen, werden angelegt.
Sobald dies erledigt ist, wird die Meldung nicht mehr angezeigt.
Warten Sie, bis die Vorbereitungen abgeschlossen sind und die Meldung ausgeblendet wird, bevor Sie mit dem Lab beginnen.
Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Mit Cloud Shell erhalten Sie Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren
.
Wenn Sie verbunden sind, sind Sie bereits authentifiziert und das Projekt ist auf Ihre Project_ID,
gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
- (Optional) Sie können den aktiven Kontonamen mit diesem Befehl auflisten:
- Klicken Sie auf Autorisieren.
Ausgabe:
- (Optional) Sie können die Projekt-ID mit diesem Befehl auflisten:
Ausgabe:
gcloud finden Sie in Google Cloud in der Übersicht zur gcloud CLI.
Aufgabe 1: Benötigte Dateien herunterladen
- In diesem Lab benötigen Sie für einige Schritte
yaml-Dateien zum Konfigurieren des Kubernetes-Clusters. Laden Sie diese Dateien in Cloud Shell aus dem entsprechenden Cloud Storage-Bucket herunter:
- Ändern Sie das aktuelle Arbeitsverzeichnis in
gke-qwiklab:
Aufgabe 2: Namespaces ansehen und erstellen
- Führen Sie den folgenden Befehl aus, um eine Standard-Computing-Zone einzurichten und den bereitgestellten Cluster
multi-tenant-clusterzu authentifizieren:
Standard-Namespaces
Kubernetes-Cluster haben standardmäßig vier System-Namespaces.
- Mit dem folgenden Befehl können Sie eine vollständige Liste der Namespaces des aktuellen Clusters abrufen:
Die Ausgabe sollte in etwa so aussehen:
- default: Der Standard-Namespace, der verwendet wird, wenn kein anderer Namespace angegeben ist.
- kube-node-lease: Dient der Verwaltung der Freigabeobjekte, die mit den Heartbeats der Knoten des Clusters verknüpft sind.
- kube-public: Wird für Ressourcen verwendet, die für alle Nutzer im gesamten Cluster sicht‑ oder lesbar sein müssen.
- kube-system: Wird für vom Kubernetes-System erstellte Komponenten verwendet.
Nicht alles gehört einem Namespace an. Knoten, nichtflüchtige Volumes und Namespaces selbst gehören beispielsweise zu keinem Namespace.
- Führen Sie den folgenden Befehl aus, um eine Liste aller Namespace-Ressourcen abzurufen:
Namespace-Ressourcen müssen bei der Erstellung mit einem Namespace verknüpft werden. Dazu verwenden Sie das Flag --namespace oder geben den Namespace im Metadatenfeld der yaml-Datei an.
- Sie können den Namespace aber auch über einen
kubectl get-Unterbefehl zum Anzeigen der Ressourcen eines Namespace angeben. Beispiel:
Dadurch erhalten Sie eine Liste aller Dienste im Namespace kube-system.
Neue Namespaces erstellen
- Erstellen Sie zwei Namespaces für
team-aundteam-b:
Die Ausgabe von kubectl get namespace sollte jetzt die beiden neuen Namespaces enthalten:
Durch Angabe des Tags --namespace können Sie im vorhandenen Namespace Clusterressourcen erstellen. Namen von Ressourcen wie Deployments oder Pods müssen nur im jeweiligen Namespace einmalig sein.
- Führen Sie beispielsweise den folgenden Befehl aus, um einen Pod in den Namespaces „team-a“ und „team-b“ mit demselben Namen bereitzustellen:
- Der Befehl
kubectl get pods -Azeigt Ihnen, dass es zwei Pods mit dem Namenapp-servergibt (einen in jedem Team-Namespace):
Ausgabe:
Klicken Sie auf Fortschritt prüfen.
- Führen Sie
kubectl describeaus, um zu jedem der neu erstellten Pods weitere Details zu sehen. Geben Sie den Namespace mit dem Tag „--namespace“ an:
- Wenn Sie nur mit den Ressourcen in einem Namespace arbeiten möchten, können Sie diesen einmal im
kubectl-Kontext festlegen, anstatt bei jedem Befehl das Flag--namespacezu verwenden:
- Danach werden alle weiteren Befehle auch ohne das Flag
--namespacefür den angegebenen Namespace ausgeführt:
Im nächsten Abschnitt konfigurieren Sie die rollenbasierte Zugriffssteuerung für die Namespaces, um den Cluster besser zu organisieren.
Aufgabe 3: Zugriffssteuerung in Namespaces verwalten
Der Zugriff auf Namespace-Ressourcen in einem Cluster wird durch das Gewähren von IAM-Rollen, kombiniert mit der in Kubernetes integrierten rollenbasierten Zugriffssteuerung (Role-Based Access Control, RBAC) geregelt. Eine IAM-Rolle gewährt einem Konto Zugriff auf das Projekt, während die RBAC-Berechtigungen detaillierten Zugriff auf die Namespace-Ressourcen (Pods, Deployments, Dienste usw.) eines Clusters gewähren.
IAM-Rollen
Identity and Access Management (IAM) dient dazu, für Kubernetes die Zugriffssteuerung sowie Berechtigungen auf einer höheren Organisations‑ und Projektebene zu verwalten.
In IAM können Nutzern und Dienstkonten verschiedene Rollen zugewiesen werden, die ihre GKE-Zugriffsrechte steuern. Die detaillierten RBAC-Berechtigungen bauen auf dem über IAM gewährten Zugriff auf und können diesen nicht einschränken. Daher sollte die mandantenfähigen Namespace-Clustern zugewiesene IAM-Rolle nur minimalen Zugriff gewähren.
Die folgende Tabelle enthält gängige GKE-IAM-Rollen, die Sie zuweisen können:
| Rolle | Beschreibung |
|---|---|
Kubernetes Engine Admin |
Berechtigung zum vollständigen Verwalten von Clustern und deren Kubernetes API-Objekten. Ein Nutzer mit dieser Rolle kann alle Ressourcen in allen Clustern und zugehörigen Namespaces erstellen, bearbeiten und löschen. |
Kubernetes Engine Developer |
Bietet Zugriff auf Kubernetes API-Objekte in Clustern. Ein Nutzer mit dieser Rolle kann Ressourcen in allen Clustern und zugehörigen Namespaces erstellen, bearbeiten und löschen. |
Kubernetes Engine Cluster Admin |
Berechtigung zum Verwalten von Clustern. Ein Nutzer mit dieser Rolle kann keine Ressourcen in Clustern oder zugehörigen Namespaces direkt erstellen oder bearbeiten, aber er kann beliebige Cluster erstellen, bearbeiten und löschen. |
Kubernetes Engine Viewer |
Bietet Lesezugriff auf GKE-Ressourcen. Ein Nutzer mit dieser Rolle hat Lesezugriff auf Namespaces und ihre Ressourcen. |
Kubernetes Engine Cluster Viewer |
Informationen zum Zugriff auf GKE-Cluster abrufen und auflisten. Diese Rolle ist mindestens erforderlich, um auf Ressourcen in den Namespaces eines Clusters zuzugreifen. |
Die meisten dieser Rollen gewähren einen zu umfangreichen Zugriff, der sich mit RBAC nicht einschränken lässt. Die IAM-Rolle Kubernetes Engine Cluster Viewer bietet jedoch gerade ausreichende Berechtigungen, um auf den Cluster und die Namespace-Ressourcen zuzugreifen.
Ihr Lab-Projekt umfasst ein Dienstkonto, das für einen Entwickler steht, der den Namespace team-a verwendet.
- Gewähren Sie dem Konto die Rolle „Kubernetes Engine Cluster Viewer“, indem Sie den folgenden Befehl ausführen:
Kubernetes RBAC
In einem Cluster wird der Zugriff auf jeden Ressourcentyp (Pods, Dienste, Deployments usw.) entweder durch eine Rolle oder eine Clusterrolle festgelegt. Nur Rollen dürfen auf einen Namespace beschränkt werden. Eine Rolle legt die Ressourcen und die für jede Ressource zulässigen Aktionen fest, während eine Rollenbindung angibt, welchen Nutzerkonten oder Gruppen der Zugriff zugewiesen werden soll.
Legen Sie den Ressourcentyp sowie die Verben fest, die angeben, welche Art von Aktion zulässig ist, um eine Rolle im aktuellen Namespace zu erstellen.
- Rollen mit nur einer Regel können mit
kubectl createerstellt werden:
Zum Erstellen von Rollen mit mehreren Regeln benötigen Sie eine yaml-Datei. Ein Beispiel finden Sie in den zu Beginn des Labs heruntergeladenen Dateien.
- Sehen Sie sich die
yaml-Datei an:
Beispielausgabe:
- Weisen Sie die obige Rolle zu:
- Erstellen Sie eine Rollenbindung zwischen dem Dienstkonto „team-a-developers“ und der Rolle „developer“:
Rollenbindung testen
- Laden Sie die Dienstkontoschlüssel herunter, die nötig sind, um die Identität des Dienstkontos zu übernehmen:
Klicken Sie auf Fortschritt prüfen.
-
Klicken Sie in Cloud Shell auf das Symbol
+, um einen neuen Tab im Terminal zu öffnen. -
Führen Sie den folgenden Befehl aus, um das Dienstkonto zu aktivieren. So können Sie die Befehle als dieses Konto ausführen:
- Rufen Sie die Anmeldedaten für den Cluster als dieses Dienstkonto ab:
- Wie Sie sehen, können Sie als „team-a-dev“ Pods im Namespace „team-a“ auflisten:
Ausgabe:
- Pods im Namespace „team-b“ können Sie dagegen nicht auflisten:
Ausgabe:
-
Kehren Sie zum ersten Cloud Shell-Tab zurück oder öffnen Sie einen neuen.
-
Aktualisieren Sie die Clusteranmeldedaten und setzen Sie den Kontext auf den Namespace „team-a“ zurück:
Aufgabe 4: Ressourcenkontingente festlegen
Wenn ein Cluster in einer mandantenfähigen Umgebung freigegeben wird, ist es wichtig sicherzustellen, dass Nutzer nicht mehr als den ihnen zustehenden Anteil der Clusterressourcen verwenden können. Über ein Ressourcenkontingentobjekt (ResourceQuota) können Sie Einschränkungen definieren, um den Ressourcenverbrauch in einem Namespace zu beschränken. Mit einem Ressourcenkontingent können Sie ein Limit für die Objektanzahl (Pods, Dienste, zustandsorientierte Sets usw.), die Gesamtsumme der Speicherressourcen (Anforderungen nichtflüchtiger Volumes, sitzungsspezifischer Speicher, Speicherklassen) oder die Gesamtsumme der Computing-Ressourcen (CPU und Arbeitsspeicher) festlegen.
- Mit dem folgenden Befehl beschränken Sie beispielsweise die Anzahl der in Namespace
team-azulässigen Pods auf zwei und die Anzahl der Load Balancer auf einen:
- Erstellen Sie einen zweiten Pod im Namespace „team-a“:
- Versuchen Sie nun, einen dritten Pod zu erstellen:
Ihnen sollte der folgende Fehler angezeigt werden:
- Mit
kubectl describekönnen Sie die Details des Ressourcenkontingents abrufen:
Ausgabe:
Hier sehen Sie eine Liste der durch das Ressourcenkontingent eingeschränkten Ressourcen sowie das konfigurierte feste Limit und die aktuell genutzte Menge.
- Führen Sie den folgenden Befehl aus, um
test-quotaauf ein Limit von sechs Pods zu ändern:
Sie können die yaml-Datei bearbeiten, die kubectl zum Ändern des Kontingents verwendet. Das feste Kontingent ist der Wert von count/pods unter spec.
- Ändern Sie den Wert von
count/podsunter „spec“ in 6:
- Drücken Sie zum Speichern und Beenden Strg + X, Y und die Eingabetaste.
Die Ausgabe sollte nun das geänderte Kontingent enthalten:
Ausgabe:
CPU‑ und Arbeitsspeicherkontingente
Bei CPU und Arbeitsspeicher können Sie ein Kontingent für die Summe der Anfragen (Wert, den ein Container garantiert erhält) oder die Summe der Limits (Wert, den der Container auf keinen Fall überschreiten darf) festlegen.
In diesem Lab hat der Cluster vier Maschinen vom Typ „e2-standard-2“ mit jeweils zwei Kernen und 8 GB Arbeitsspeicher. Ihnen wurde eine beispielhafte YAML-Datei für das Ressourcenkontingent des Clusters bereitgestellt:
cpu-mem-quota.yaml
- Wenden Sie die Dateikonfiguration an:
Durch dieses Kontingent wird die Summe der CPU‑ und Arbeitsspeicheranfragen aller Pods auf 2 CPUs und 8 GiB beschränkt und das Limit liegt bei 4 CPUs bzw. 12 GiB.
- Erstellen Sie mit
cpu-mem-demo-pod.yamleinen neuen Pod, um das CPU‑ und Arbeitsspeicherkontingent zu veranschaulichen:
cpu-mem-demo-pod.yaml:
- Wenden Sie die Dateikonfiguration an:
- Nachdem dieser Pod erstellt wurde, führen Sie den folgenden Befehl aus, um zu sehen, wie sich die CPU‑ und Arbeitsspeicheranfragen und ‑limits im Kontingent widerspiegeln:
Ausgabe:
Klicken Sie auf Fortschritt prüfen.
Aufgabe 5: GKE-Monitoring und -Nutzungsmessung kennenlernen
Bei den meisten mandantenfähigen Clustern ist die Wahrscheinlichkeit hoch, dass sich die Arbeitslasten und Ressourcenanforderungen der einzelnen Mandanten mit der Zeit ändern und die Ressourcenkontingente angepasst werden müssen. Durch das Monitoring können Sie sich einen allgemeinen Überblick über die Ressourcen verschaffen, die die Namespaces verwenden.
Die GKE-Nutzungsmessung liefert Ihnen detailliertere Informationen über diese Ressourcennutzung sowie die Kosten jedes Mandanten.
Monitoring-Dashboard
- Maximieren Sie in der Cloud Console oben links auf der Seite das Navigationsmenü und klicken Sie darin auf Vorgänge > Monitoring.
Das Erstellen des Arbeitsbereichs für Ihr Projekt dauert eine Minute.
- Wählen Sie dann auf der Seite „Übersicht“ aus dem linken Menü die Option Dashboards aus:
- Klicken Sie auf der Seite Dashboard-Übersicht auf GKE.
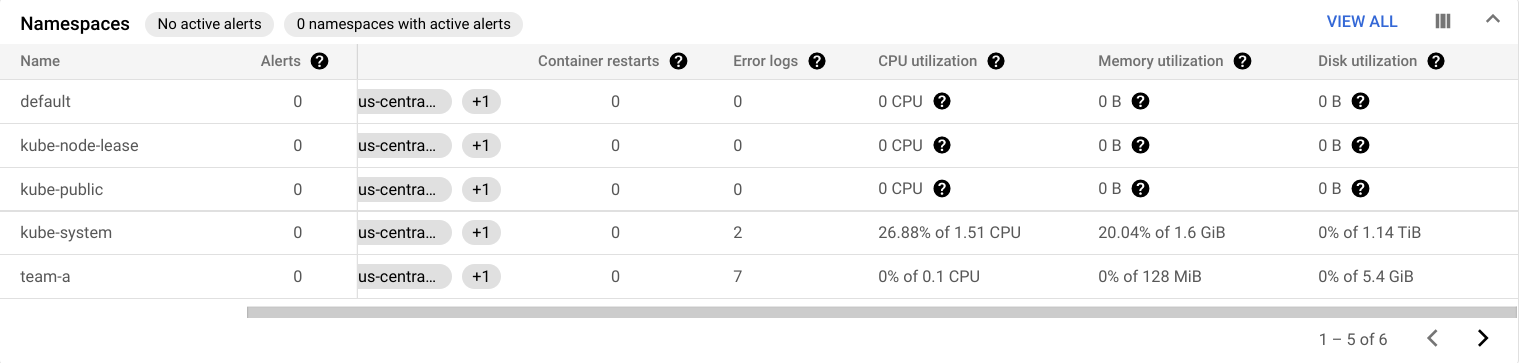
Das GKE-Dashboard enthält eine Reihe von Tabellen zu CPU, Arbeitsspeicher und Laufwerksauslastung, zusammengefasst nach mehreren Ressourcen.
In der Tabelle „Namespaces“ finden Sie beispielsweise die Auslastung für alle Namespaces Ihres Clusters:
Die Tabelle „Arbeitslasten“ enthält die Nutzungsdaten für die auf dem Cluster ausgeführten Arbeitslasten.
-
Klicken Sie auf Alle ansehen.
-
Wählen Sie im Feld
Filter hinzufügendie Option Namespaces > team-a aus. -
Klicken Sie dann auf Anwenden.
Dadurch werden die Arbeitslasten gefiltert und nur die angezeigt, die im Namespace „team-a“ ausgeführt werden:
Metrics Explorer
-
Klicken Sie im linken Bereich auf Metrics Explorer.
-
Klicken Sie im Feld „Messwert auswählen“ auf das Drop-down-Menü Messwert.
-
Geben Sie unter „Nach Ressourcen‑ oder Messwertnamen filtern“ Kubernetes-Container ein.
-
Klicken Sie auf Kubernetes-Container > Container.
-
Wählen Sie
CPU-Nutzungszeitaus. -
Klicken Sie auf Anwenden.
-
Klicken Sie im Filterbereich auf Filter hinzufügen, um den Namespace „kube-system“ auszuschließen.
-
Wählen Sie
namespace_nameals Label aus. -
Wählen Sie
!= (does not equal)als Vergleich undkube-systemals Wert aus. -
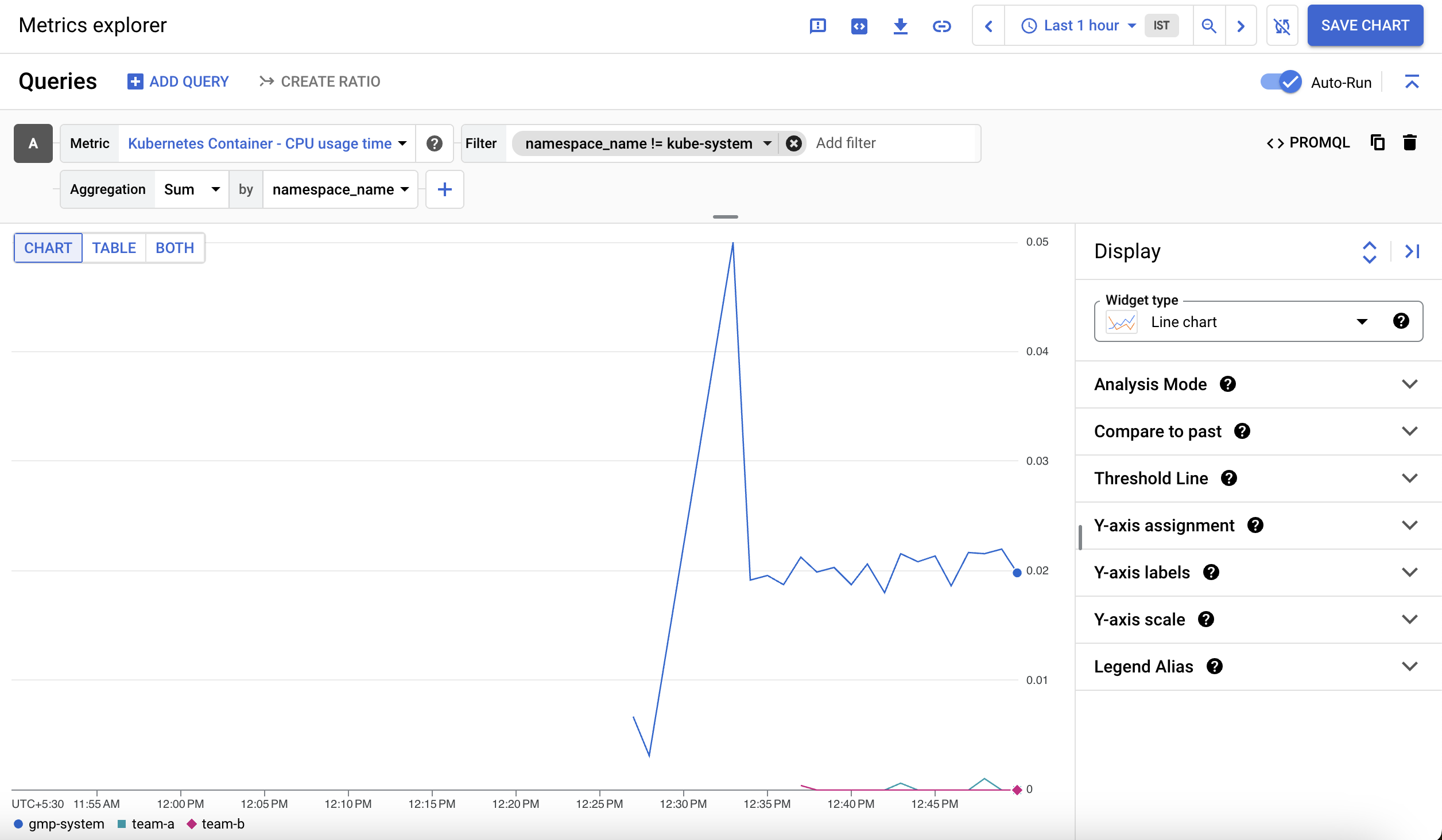
Wählen Sie im Drop-down-Menü Aggregation die Option Summe und im Drop-down-Menü „von“ die Option namespace_name aus. Klicken Sie dann auf Ok.
Das angezeigte Diagramm enthält die Container-CPU-Nutzungszeit nach Namespace:
GKE-Nutzungsmessung
Im Rahmen der GKE-Nutzungsmessung können Sie die Nutzungs‑ und Verbrauchsdaten Ihrer GKE-Clusterressourcen in ein BigQuery-Dataset exportieren und mit Looker Studio visualisieren. So können Sie sich die Ressourcennutzung detaillierter ansehen. Die Nutzungsmessung erlaubt es Ihnen, fundiertere Entscheidungen über Ressourcenkontingente und die effiziente Clusterkonfiguration zu treffen.
Die folgenden beiden Datasets wurden Ihrem Projekt hinzugefügt:
cluster_dataset: Dieses Dataset wird vor dem Aktivieren der GKE-Nutzungsmessung im Cluster manuell erstellt. Es enthält zwei von der GKE generierte Tabellen („gke_cluster_resource_consumption“ und „gke_cluster_resource_usage“) und wird kontinuierlich mit neuen Messwerten zur Clusternutzung aktualisiert.
billing_dataset: Dieses Dataset wird vor dem Aktivieren des BigQuery-Exports für die Abrechnung manuell erstellt. Es enthält die Tabelle „gcp_billing_export_v1_xxxx“ und wird jeden Tag mit den täglichen Kosten des Projekts aktualisiert.
- Führen Sie den folgenden Befehl aus, um die GKE-Nutzungsmessung im Cluster zu aktivieren und das Dataset
cluster_datasetanzugeben:
Tabelle mit GKE-Kostenaufschlüsselung erstellen
Die Tabelle „cost_breakdown“ kann aus den Abrechnungs‑ und Ressourcennutzungstabellen in Ihrem Projekt erstellt werden. Sie erstellen diese Tabelle im Cluster-Dataset mithilfe der Datei usage_metering_query_template.sql. Die Vorlage finden Sie unter Grundlagen der Nutzung von Clusterressourcen.
Zuerst definieren Sie in Cloud Shell einige Umgebungsvariablen.
- Legen Sie den Pfad der bereitgestellten Abrechnungstabelle, des bereitgestellten Datasets für die Nutzungsmessung sowie einen Namen für die Kostenaufschlüsselungstabelle fest:
- Legen Sie als Nächstes den Pfad der Abfragevorlage für die Nutzungsmessung, die Sie zu Beginn des Labs heruntergeladen haben, eine Ausgabedatei für die Nutzungsmessungsabfrage, die erzeugt wird, sowie ein Startdatum für die Daten fest. Die Daten reichen bis zum 26.10.2020 zurück:
- Erstellen Sie nun mit diesen Umgebungsvariablen und der Abfragevorlage die Nutzungsmessungsabfrage:
- Führen Sie den folgenden Befehl aus, um anhand der Abfrage, die Sie im vorherigen Schritt erstellt haben, die Kostenaufschlüsselungstabelle einzurichten:
- Die Datenübertragung sollte einen Autorisierungslink bereitstellen. Klicken Sie darauf, melden Sie sich mit Ihrem Teilnehmerkonto an, folgen Sie der Anleitung und fügen Sie
version_infoin Cloud Shell ein.
Danach sollte Ihnen die Meldung angezeigt werden, dass die Übertragungskonfiguration erfolgreich erstellt wurde.
Datenquelle in Looker Studio erstellen
-
Öffnen Sie die Looker Studio-Seite „Datenquellen“.
-
Klicken Sie oben links auf Erstellen > Datenquelle, um eine neue Datenquelle hinzuzufügen.
Ihnen wird das Fenster Kontoeinrichtung abschließen angezeigt.
-
Klicken Sie auf das Kästchen zum Akzeptieren der Nutzungsbedingungen und anschließend auf Weiter.
-
Wählen Sie in Schritt 2 Bitte angeben, welche Benachrichtigungen Sie erhalten möchten jeweils die Option Nein aus, da dies ein temporäres Lab/Konto ist.
-
Klicken Sie auf Weiter.
Ihnen wird eine Liste der Google-Connectors angezeigt, die von Looker Studio unterstützt werden.
- Wählen Sie BigQuery aus.
-
Klicken Sie auf Autorisieren, um Looker Studio Zugriff auf Ihr BigQuery-Projekt zu gewähren.
-
Benennen Sie die Datenquelle oben links auf der Seite von
Unbenannte DatenquelleinGKE-Nutzungum. -
Wählen Sie in der ersten Spalte Benutzerdefinierte Abfrage aus.
-
Wählen Sie in der Projektspalte Ihre Projekt-ID aus.
-
Geben Sie die folgende Abfrage in das Feld „Benutzerdefinierte Abfrage“ ein und ersetzen Sie
[PROJECT-ID]durch die Qwiklabs-Projekt-ID:
- Klicken Sie auf Verbinden.
Klicken Sie auf Fortschritt prüfen.
- Klicken Sie nun rechts oben.
Nachdem Sie die Datenquelle hinzugefügt haben, können Sie jetzt einen Bericht damit erstellen.
- Klicken Sie oben auf der Seite „Datenquelle“ auf Bericht erstellen.
Wenn Sie aus einer Datenquelle einen neuen Bericht erstellen, werden Sie aufgefordert, Daten zum Bericht hinzuzufügen.
- Klicken Sie auf ZUM BERICHT HINZUFÜGEN.
Looker Studio-Bericht erstellen
In diesem Bericht können Sie die Nutzungsmesswerte aus der Datenquelle basierend auf der BigQuery-Tabelle visualisieren.
Sie beginnen mit einer einfachen Tabelle:
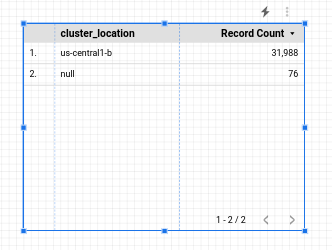
Sie konfigurieren die Tabelle so, dass sie eine Kostenaufschlüsselung nach Namespace zeigt. Wenn die Tabelle markiert ist, sehen Sie im Bereich rechts daneben die zugehörigen Daten.
- Ändern Sie in diesem Bereich Folgendes:
-
Zeitraumdimension:
usage_start_time -
Dimension:
namespace -
Messwert:
cost
Behalten Sie in allen anderen Feldern die Standardwerte bei.
Mithilfe eines Filters können Sie die Tabelle auf Namespace-Ressourcen beschränken.
- Klicken Sie im Datenbereich im Abschnitt „Filter“ auf Filter hinzufügen. Erstellen Sie einen Filter, durch den Ressourcen, die nicht einem Namespace zugewiesen sind, ausgeschlossen werden:

-
Klicken Sie auf Speichern.
-
Klicken Sie noch einmal auf Filter hinzufügen und Filter erstellen, um einen zweiten Filter zum Beschränken der Daten auf Anfragen zu definieren:

- Klicken Sie auf Speichern, um den Filter anzuwenden. Die Tabelle sollte dann in etwa so aussehen:

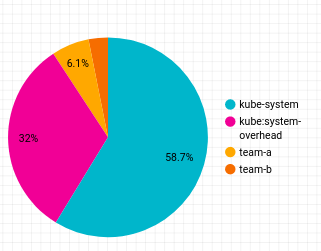
Als Nächstes fügen Sie dem Bericht ein Kreisdiagramm hinzu, das die Kostenaufschlüsselung nach Namespace zeigt.
-
Klicken Sie mit der rechten Maustaste auf die Tabelle, die Sie erstellt haben, und wählen Sie Duplizieren aus.
-
Ziehen Sie das duplizierte Tabellenobjekt an eine beliebige Stelle in Ihrem Bericht.
-
Klicken Sie nun auf die Überschrift des Konfigurationsbereichs:
- Klicken Sie auf das Symbol Kreisdiagramm:

Das Kreisdiagramm sieht so aus:
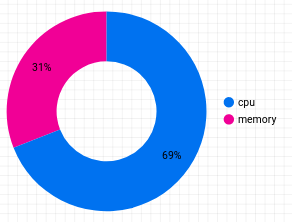
Als Nächstes fügen Sie ein Ringdiagramm hinzu, das die Kostenaufschlüsselung nach Ressourcentyp zeigt.
-
Klicken Sie oben in der Symbolleiste auf Diagramm hinzufügen und wählen Sie
aus, um ein Ringdiagramm zu erstellen.
-
Ziehen Sie das Diagramm an eine beliebige Stelle in Ihrem Bericht und konfigurieren Sie es so:
-
Zeitraumdimension:
usage_start_time -
Dimension:
resource_name -
Messwert:
cost
- Klicken Sie auf Filter hinzufügen und wählen Sie die beiden Filter aus, die Sie auf das vorherige Diagramm angewendet haben. Das Ringdiagramm sieht so aus:
-
Klicken Sie oben in der Symbolleiste auf Steuerelement hinzufügen und wählen Sie Drop-down-Liste aus, um eine Aufschlüsselung nach Namespace hinzuzufügen.
-
Ziehen Sie sie neben das Ringdiagramm und konfigurieren Sie sie so:
-
Zeitraumdimension:
usage_start_time -
Steuerfeld:
namespace -
Messwert:
None
-
Klicken Sie auf Filter hinzufügen.
-
Wählen Sie Nicht zugewiesen (Namespace-Filter) aus der Liste aus.
-
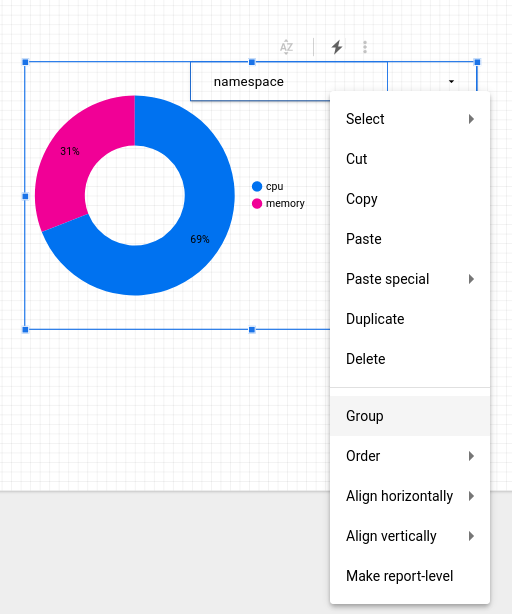
Konfigurieren Sie das Steuerelement so, dass es nur für das Ringdiagramm gilt. Markieren Sie dazu das Steuerungsobjekt und das Ringdiagramm mit dem Auswahlcursor, um ein Rechteck um die beiden Objekte zu ziehen.
-
Klicken Sie mit der rechten Maustaste und wählen Sie Gruppieren aus, um sie zu einer Gruppe zusammenzufassen:
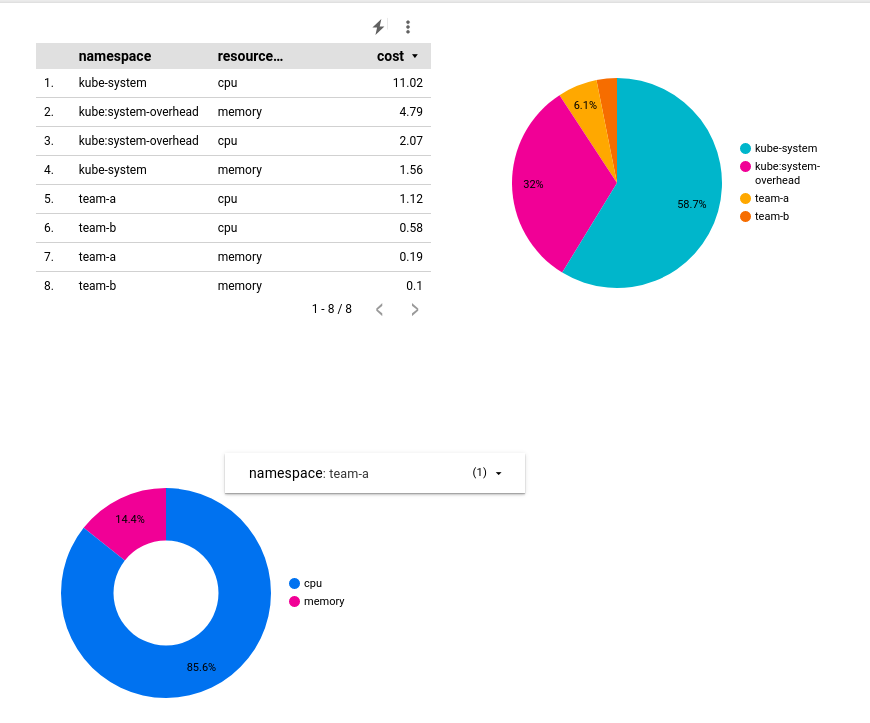
- Klicken Sie oben in der Symbolleiste auf Ansehen, um sich eine Vorschau des Berichts anzusehen.
Im Ansichtsmodus können Sie die Darstellung des Ringdiagramms auf einen bestimmten Namespace festlegen:
- Klicken Sie oben auf der Seite im Menü Teilen auf Bericht herunterladen, um eine Kopie des vollständigen Berichts als PDF-Datei herunterzuladen.
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
Mithilfe von Namespaces können Sie Cluster mandantenfähig konfigurieren. So minimieren Sie das Risiko einer Unterauslastung von Ressourcen sowie eine übermäßige Zunahme der Cluster und vermeiden gleichzeitig zusätzliche Kosten. Durch das Monitoring und die GKE-Nutzungsmessung können Sie außerdem die Ressourcenauslastung nach Namespace visualisieren, um fundiertere Entscheidungen über Ressourcenkontingente und die Clusterkonfiguration zu treffen.
Weitere Informationen
- Cluster-Mehrinstanzenfähigkeit
- Best Practices zum Ausführen kostenoptimierter Kubernetes-Anwendungen in GKE
Google Cloud-Schulungen und -Zertifizierungen
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 02. Februar 2024 aktualisiert
Lab zuletzt am 02. Februar 2024 getestet
© 2024 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.

