Prüfpunkte
Scale Up Hello App
/ 30
Create node pool
/ 30
Managing a Regional Cluster
/ 20
Simulate Traffic
/ 20
Kostenoptimierung für virtuelle GKE-Maschinen
GSP767

Übersicht
Die zugrunde liegende Infrastruktur eines Google Kubernetes Engine-Clusters besteht aus Knoten. Dies sind einzelne Compute-VM-Instanzen. In diesem Lab erfahren Sie, wie Sie durch die Optimierung der Clusterinfrastruktur Kosten sparen und die Architektur für Ihre Anwendungen effizienter gestalten können.
Sie lernen Strategien zur Maximierung der Auslastung und zum Vermeiden einer Unterauslastung Ihrer wertvollen Infrastrukturressourcen durch Auswahl geeigneter Maschinentypen für eine Beispielarbeitslast kennen. Neben der Art der Infrastruktur wirkt sich auch ihr geografischer Standort auf die Kosten aus. Im Rahmen dieser Übung lernen Sie, wie Sie eine kostengünstige Strategie für das Verwalten regionaler Cluster mit höherer Verfügbarkeit verfolgen können.
Lernziele
Aufgaben in diesem Lab:
- Ressourcennutzung eines Deployments ermitteln
- Deployment hochskalieren
- Arbeitslast zu einem Knotenpool mit optimiertem Maschinentyp migrieren
- Standortoptionen für den Cluster vergleichen
- Flusslogs zwischen Pods in verschiedenen Zonen überwachen
- Pod, der viel Traffic verursacht, verschieben, um die Kosten für zonenübergreifenden Traffic zu minimieren
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange die Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung selbst durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Pop-up-Fenster geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können. Auf der linken Seite befindet sich der Bereich Details zum Lab mit diesen Informationen:
- Schaltfläche Google Cloud Console öffnen
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite Anmelden geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden. -
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}} Sie finden den Nutzernamen auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}} Sie finden das Passwort auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos. Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen. -
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.

In diesem Lab wird ein kleiner Cluster für Sie erstellt. Das Bereitstellen des Clusters dauert etwa zwei bis fünf Minuten.
Wenn Sie auf Lab starten geklickt haben und die Meldung resources being provisioned in Blau mit einem Ladekreis angezeigt wird, wird der Cluster gerade erstellt.
Während Sie warten, können Sie bereits die weitere Anleitung und die nächsten Erklärungen lesen. Shell-Befehle funktionieren jedoch erst, wenn die Bereitstellung der Ressourcen abgeschlossen ist.
Aufgabe 1: Knotenmaschinentypen kennenlernen
Allgemeiner Überblick
Ein Maschinentyp bezeichnet eine Reihe virtualisierter Hardwareressourcen, die der Instanz einer virtuellen Maschine (VM) zur Verfügung stehen. Dazu gehören die Kapazität des Systemspeichers, die Anzahl der virtuellen CPUs (vCPUs) und der maximal verfügbare nichtflüchtige Speicher. Maschinentypen werden für verschiedene Arbeitslasten gruppiert und nach Familien sortiert.
Maschinentypen für allgemeine Zwecke bieten für eine Vielzahl von Arbeitslasten das beste Preis-Leistungs-Verhältnis. Zu diesen Maschinentypen gehören die N-Serie und die E2-Serie:
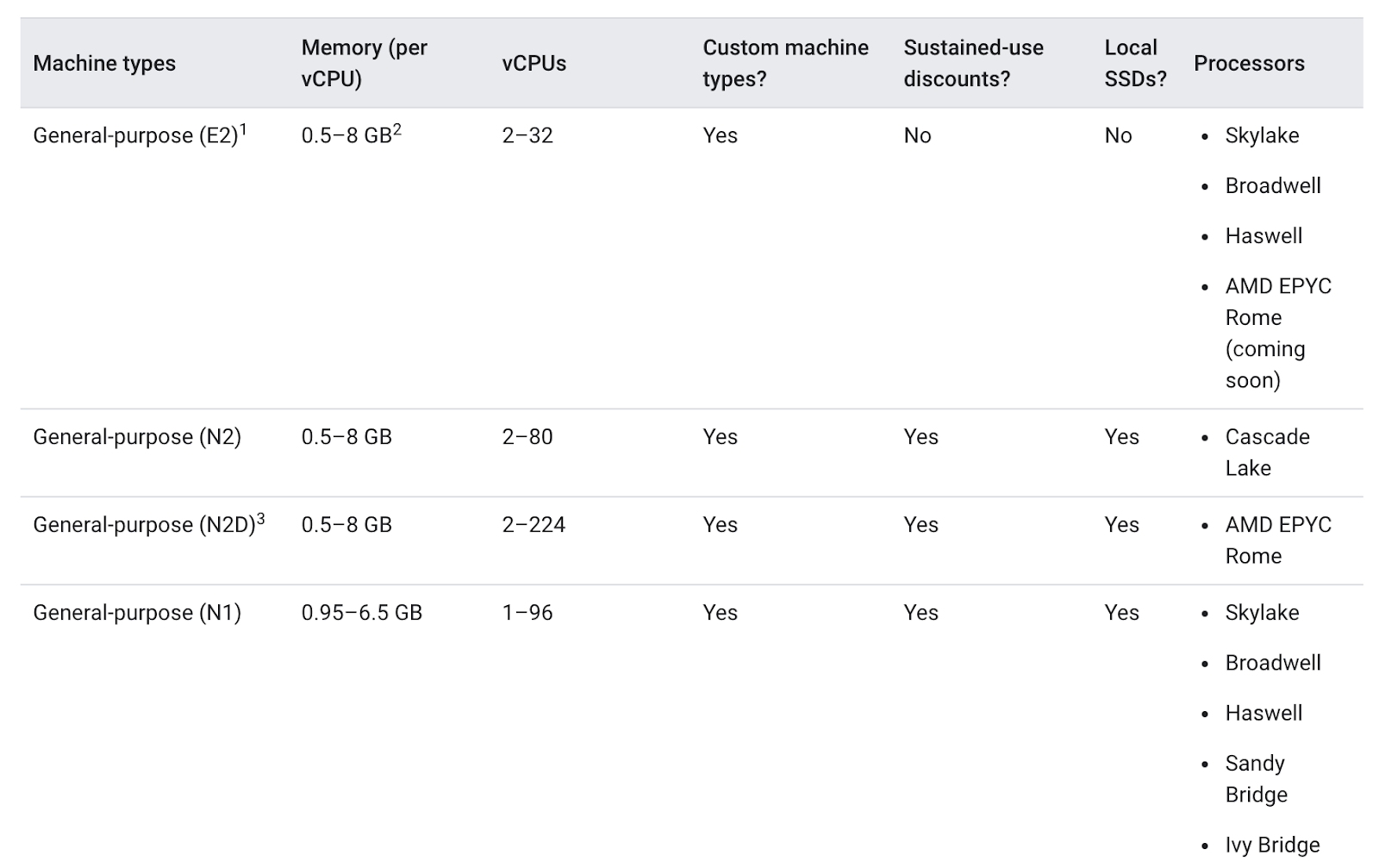
Die Unterschiede zwischen den Maschinentypen können für Ihre Anwendung hilfreich sein oder auch nicht. Generell bietet der Typ E2 eine ähnliche Leistung wie der Typ N1, aber er ist kostenoptimiert. In der Regel können Sie mit dem Maschinentyp E2 Kosten sparen.
In einem Cluster ist jedoch am wichtigsten, dass die genutzten Ressourcen optimal auf die Anforderungen der Anwendung zugeschnitten sind. Bei größeren Anwendungen oder Deployments, die stark skaliert werden müssen, kann es günstiger sein, die Arbeitslasten auf einige wenige optimierte Maschinen zu verteilen, anstatt auf viele für allgemeine Zwecke.
Die Details der Anwendung genau zu kennen, ist für diesen Prozess zur Entscheidungsfindung äußerst wichtig. Wenn Ihre Anwendung bestimmte Anforderungen hat, können Sie darauf achten, dass der Maschinentyp darauf abgestimmt ist.
Im folgenden Abschnitt sehen Sie sich eine Demo-App an und migrieren diese zu einem Knotenpool mit einem gut geeigneten Maschinentyp.
Aufgabe 2: Passenden Maschinentyp für die Hello-App auswählen
Anforderungen des Hello-Demo-Clusters kennenlernen
Beim Start des Labs wurde ein Hello-Demo-Cluster mit zwei Knoten vom Typ „e2-medium“ (2 vCPUs, 4 GB Arbeitsspeicher) erstellt. Über diesen Cluster wird ein Replikat einer einfachen Web-Anwendung namens Hello-App bereitgestellt. Dies ist ein in Go geschriebener Webserver, der auf alle Anfragen mit der Nachricht „Hello, World!“ reagiert.
- Nachdem die Lab-Bereitstellung abgeschlossen ist, klicken Sie in der Cloud Console auf das Navigationsmenü und dann auf Kubernetes Engine.
-
Wählen Sie im Fenster Kubernetes-Cluster Ihren Cluster hello-demo-cluster aus.
-
Wechseln Sie im nächsten Fenster zum Tab Knoten:
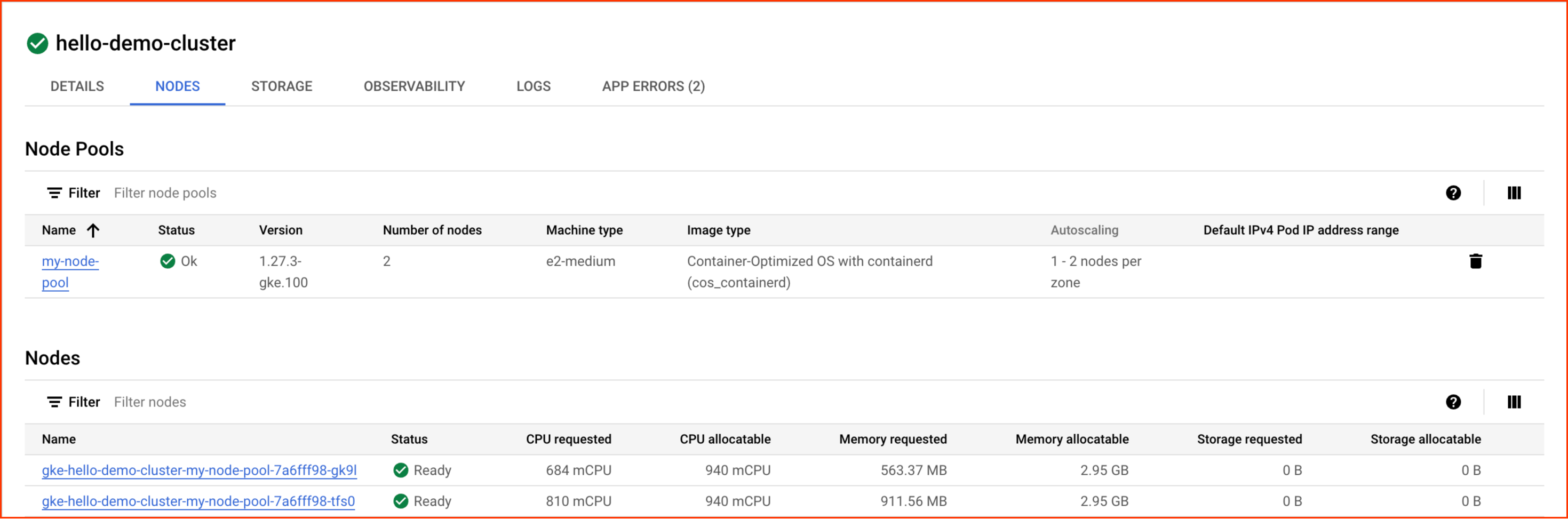
Ihnen sollte eine Liste der Knoten des Clusters angezeigt werden:

Sehen Sie sich an, wie die GKE die Ressourcen des Clusters bisher genutzt hat. Sie sehen, wie viel CPU-Kapazität und Arbeitsspeicher von jedem Knoten angefragt wird und wie viel die Knoten potenziell zuweisen könnten.
- Klicken Sie auf den ersten Knoten des Clusters.
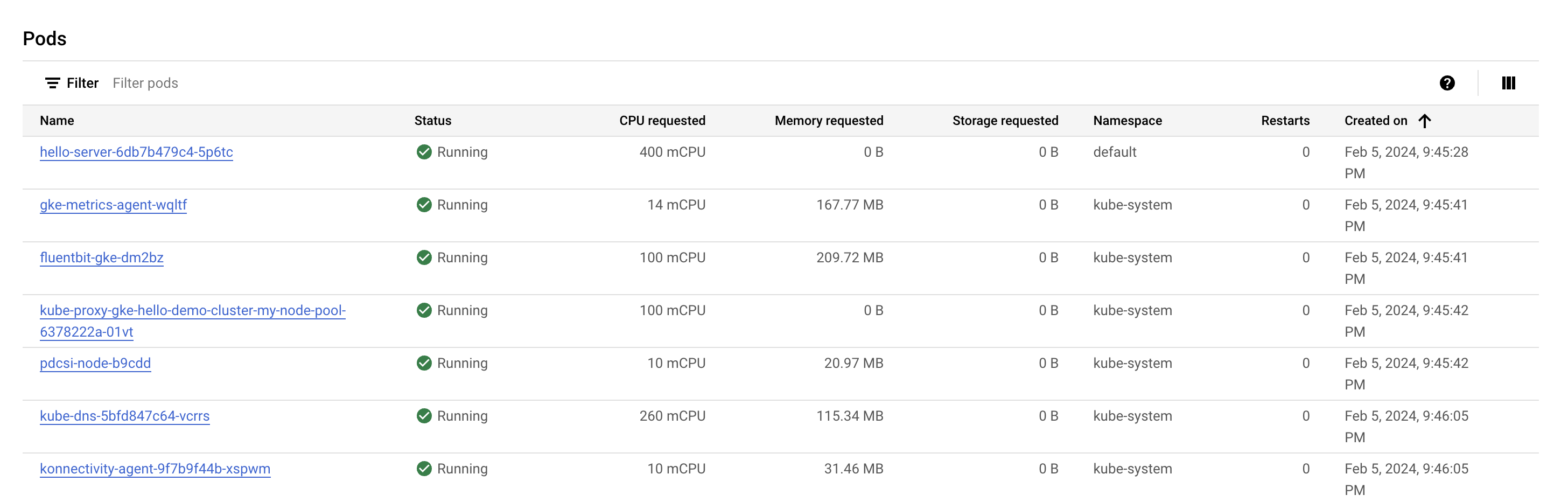
Sehen Sie sich den Abschnitt Pods an. Dort sollte der Pod hello-server im Namespace default aufgeführt sein. Falls Sie den Pod hello-server nicht sehen, wählen Sie stattdessen den zweiten Knoten des Clusters aus.
Sie sehen, dass der Pod hello-server 400 mCPU anfragt. Außerdem sollten einige weitere kube-system-Pods ausgeführt werden. Diese werden für die Clusterdienste der GKE wie das Monitoring genutzt.
- Klicken Sie auf Zurück, um zur vorherigen Seite Knoten zurückzukehren.
Wie Sie sehen, sind zwei Knoten vom Typ „e2-medium“ nötig, um ein Replikat der Hello-App sowie die grundlegenden kube-system-Dienste auszuführen. Während dafür ein Großteil der CPU-Ressourcen des Clusters benötigt wird, nutzen Sie bisher nur etwa ein Drittel des zuweisbaren Arbeitsspeichers.
Wäre die Arbeitslast dieser App komplett statisch, könnten Sie einen benutzerdefinierten Maschinentyp mit genau der benötigten CPU‑ und Arbeitsspeicherkapazität erstellen. Dadurch würden Sie bei den Kosten für die gesamte Clusterinfrastruktur sparen.
Auf GKE-Clustern werden jedoch oft mehrere Arbeitslasten ausgeführt und diese müssen meist hoch‑ und herunterskaliert werden.
Was würde passieren, wenn die Hello-App hochskaliert würde?
Cloud Shell aktivieren
Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Mit Cloud Shell erhalten Sie Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren
.
Wenn Sie verbunden sind, sind Sie bereits authentifiziert und das Projekt ist auf Ihre Project_ID,
gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
- (Optional) Sie können den aktiven Kontonamen mit diesem Befehl auflisten:
- Klicken Sie auf Autorisieren.
Ausgabe:
- (Optional) Sie können die Projekt-ID mit diesem Befehl auflisten:
Ausgabe:
gcloud finden Sie in Google Cloud in der Übersicht zur gcloud CLI.
Hello-App hochskalieren
- Rufen Sie die Anmeldedaten des Clusters auf:
- Skalieren Sie
hello-serverhoch:
Klicken Sie auf Fortschritt prüfen.
- Klicken Sie in der Console im Menü Kubernetes Engine auf der linken Seite auf Arbeitslasten.
Vielleicht wird Ihnen der Pod hello-server mit dem Fehlerstatus Keine Mindestverfügbarkeit vorhanden angezeigt.
- Klicken Sie auf die Fehlermeldung, um die Statusdetails einzublenden. Als Grund wird Ihnen
Insufficient cpuangezeigt.
Das ist nicht überraschend, denn der Cluster hatte praktisch keine verfügbaren CPU-Ressourcen mehr und Sie haben mit einem zweiten Replikat von hello-server weitere 400 mCPU angefragt.
- Erweitern Sie den Knotenpool, um die neue Anfrage zu verarbeiten:
-
Wenn Sie gefragt werden, ob Sie fortfahren möchten, geben Sie
yein und drücken Sie dieEingabetaste. -
Aktualisieren Sie in der Console die Seite Arbeitslasten, bis für den Status der Arbeitslast von
hello-serverder Wert Ok angezeigt wird:

Cluster untersuchen
Nachdem Sie die Arbeitslast hochskaliert haben, kehren Sie zum Tab „Knoten“ des Clusters zurück.
- Klicken Sie auf hello-demo-cluster:

- Klicken Sie auf den Tab Knoten.
Der größere Knotenpool kann die höhere Arbeitslast bewältigen, aber sehen Sie sich einmal an, wie die Ressourcen der Infrastruktur genutzt werden.
Obwohl die GKE die Ressourcen eines Clusters bestmöglich nutzt, gibt es hier noch Optimierungsbedarf. Wie Sie sehen, wird der Arbeitsspeicher des einen Knotens fast vollständig genutzt, während der Arbeitsspeicher von zwei weiteren Knoten kaum ausgelastet ist.
Wenn Sie die App weiter hochskalieren würden, könnten Sie ein ähnliches Muster beobachten. Kubernetes würde versuchen, für jedes neue Replikat des Deployments hello-server einen Knoten zu finden. Dies würde fehlschlagen und das System würde einen neuen Knoten mit ca. 600 mCPU erstellen.
Bin-Packing-Problem
Ein Bin-Packing-Problem tritt auf, wenn Sie Elemente mit unterschiedlichem Volumen oder unterschiedlicher Form in einer begrenzten Anzahl gleichmäßig geformter „Bins“ oder Container unterbringen müssen. Die Herausforderung besteht darin, die Elemente so effizient wie möglich in die geringstmögliche Anzahl an Behältern zu „packen“.
Das Optimieren von Kubernetes-Clustern für die Anwendungen, die auf ihnen ausgeführt werden, funktioniert ähnlich. Dabei müssen Sie für mehrere Anwendungen, die vermutlich unterschiedliche Ressourcenanforderungen hinsichtlich Arbeitsspeicher und CPU haben, so effizient wie möglich passende Infrastrukturressourcen finden, die Kubernetes für Sie verwaltet. Hier fallen voraussichtlich die höchsten Kosten für Ihren Cluster an.
Der Hello-Demo-Cluster geht das Bin-Packing-Problem nicht sehr effizient an. Es wäre kostengünstiger, Kubernetes für die Verwendung eines Maschinentyps zu konfigurieren, der besser zu dieser Arbeitslast passt.
Zu optimiertem Knotenpool migrieren
- Erstellen Sie einen neuen Knotenpool mit einem größeren Maschinentyp:
Klicken Sie auf Fortschritt prüfen.
Jetzt können Sie Pods zum neuen Knotenpool migrieren:
-
Vorhandenen Knotenpool sperren: Durch diesen Vorgang werden die Knoten im vorhandenen Knotenpool
nodeals nicht mehr planbar gekennzeichnet. Sobald Sie die Knoten als nicht mehr planbar gekennzeichnet haben, stellt Kubernetes die Zuweisung von neuen Pods für die Knoten ein. -
Vorhandenen Knotenpool leeren: Durch diesen Vorgang werden die Arbeitslasten entfernt, die auf den Knoten des vorhandenen Knotenpools
nodeausgeführt werden.
- Sperren Sie zuerst den ursprünglichen Knotenpool:
- Leeren Sie als Nächstes den Pool:
Jetzt sollten die Pods auf dem neuen Knotenpool larger-pool ausgeführt werden:
- Nachdem die Pods migriert wurden, können Sie den alten Knotenpool löschen:
- Wenn Sie gefragt werden, ob Sie fortfahren möchten, geben Sie
yein und drücken Sie dieEingabetaste.
Das Löschen kann etwa zwei Minuten dauern. Während Sie warten, können Sie sich schon einmal den nächsten Abschnitt durchlesen.
Kostenanalyse
Sie führen jetzt dieselbe Arbeitslast, für die bisher drei Maschinen des Typs e2-medium erforderlich waren, auf einer e2-standard-2-Maschine aus.
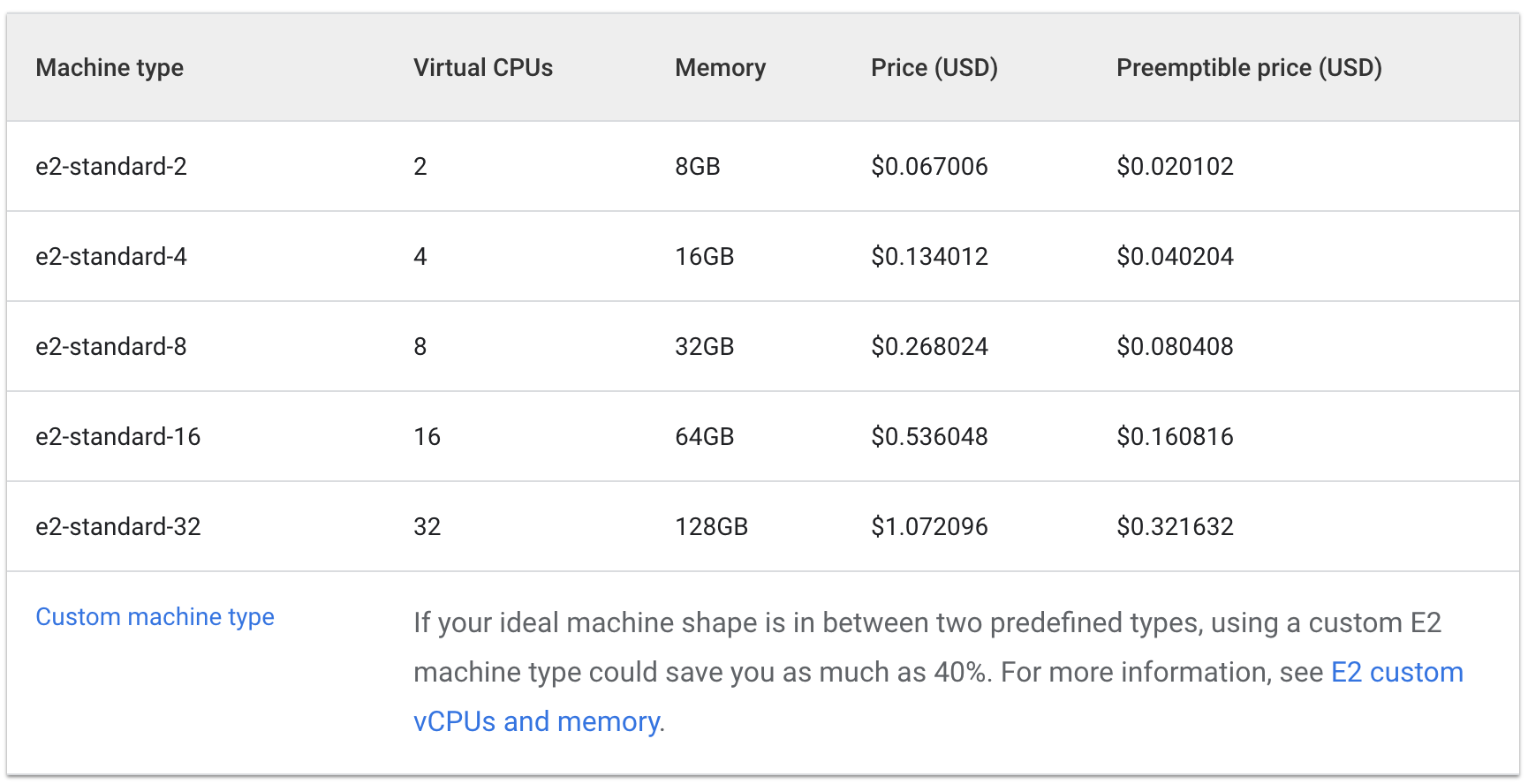
Sehen wir uns einmal die stündlichen Kosten für „e2-standard“-Maschinentypen und solche mit gemeinsam genutztem Kern an:
Standard:
Gemeinsam genutzter Kern:
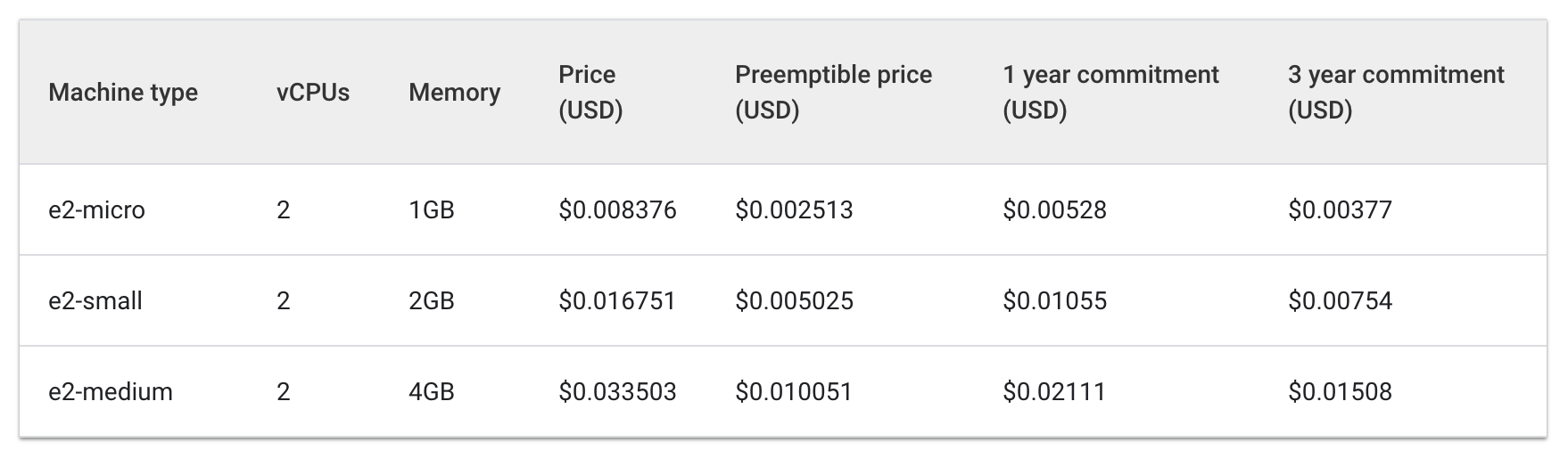
Die Kosten von drei e2-medium-Maschinen belaufen sich auf etwa 0,1 $ pro Stunde, während eine e2-standard-2-Maschine ca. 0,067 $ pro Stunde kostet.
Eine Ersparnis von 0,04 $ pro Stunde erscheint gering, aber im Laufe der Lebenszeit einer Anwendung macht dies doch einen deutlichen Unterschied. In einem größeren Maßstab wäre es noch deutlicher erkennbar. Da die e2-standard-2-Maschine die Arbeitslast effizienter bewältigen kann, bleibt weniger Speicherplatz ungenutzt und die Skalierungskosten würden langsamer steigen.
Dies ist interessant, da der Maschinentyp e2-medium einer mit gemeinsam genutztem Kern ist. Dieser Typ ist für kleine, nicht ressourcenintensive Anwendungen besonders kostengünstig. Für die aktuelle Arbeitslast der Hello-App ist die Wahl eines Knotenpools mit einem größeren Maschinentyp jedoch im Hinblick auf die Kosten die bessere Strategie.
Sie sollten sich in der Cloud Console immer noch im Tab Knoten des Clusters hello-demo befinden. Aktualisieren Sie den Tab und sehen Sie sich die Felder Angeforderte CPU und Zuweisbare CPU für den Knoten larger-pool an.
Hier gibt es noch Optimierungsmöglichkeiten. Der neue Knoten hätte noch Platz für ein weiteres Replikat der Arbeitslast, ohne dass ein zusätzlicher Knoten bereitgestellt werden müsste. Alternativ könnten Sie einen benutzerdefinierten Maschinentyp auswählen, der genau die CPU‑ und Arbeitsspeicheranforderungen der Anwendung erfüllt. Dadurch könnten Sie sogar noch mehr Ressourcen sparen.
Die Preise hängen allerdings auch vom Standort des Clusters ab. Daher geht es im nächsten Abschnitt dieses Labs um die Auswahl der am besten geeigneten Region und die Verwaltung eines regionalen Clusters.
Geeigneten Standort für einen Cluster auswählen
Überblick über Regionen und Zonen
Die Compute Engine-Ressourcen, die für die Knoten Ihres Clusters verwendet werden, befinden sich an unterschiedlichen Standorten auf der ganzen Welt. Diese Standorte setzen sich aus Regionen und Zonen zusammen. Eine Region ist ein bestimmter geografischer Standort, an dem Sie Ihre Ressourcen hosten können. Regionen haben mindestens drei Zonen.
Ressourcen, die sich in einer Zone befinden, wie Instanzen virtueller Maschinen oder zonale nichtflüchtige Speicher, werden als zonale Ressourcen bezeichnet. Andere Ressourcen wie statische externe IP-Adressen zählen zur Region. Regionale Ressourcen können von jeder Ressource in dieser Region unabhängig von der Zone genutzt werden, während zonale Ressourcen nur von anderen Ressourcen in derselben Zone genutzt werden können.
Bedenken Sie bei der Auswahl einer Region oder Zone Folgendes:
- Umgang mit Ausfällen: Wenn sich die Ressourcen für Ihre Anwendung in nur einer Zone befinden und diese nicht mehr verfügbar ist, ist auch Ihre Anwendung nicht mehr verfügbar. Für umfangreichere, sehr gefragte Anwendungen wird daher empfohlen, die Ressourcen auf mehrere Zonen oder Regionen zu verteilen.
- Geringere Netzwerklatenz: Zur Verringerung der Netzwerklatenz sollten Sie eine Region oder Zone wählen, die sich in der Nähe Ihres Point of Service befindet. Wenn Sie beispielsweise vor allem Kunden an der Ostküste der USA haben, sollten Sie möglichst eine Primärregion und ‑zone wählen, die sich in der Nähe dieses Bereichs befinden.
Best Practices für Cluster
Die Kosten verschiedener Regionen hängen von einer Vielzahl von Faktoren ab. Ressourcen in der Region us-west2 sind beispielsweise in der Regel teurer als solche in der Region us-central1.
Überlegen Sie bei der Auswahl einer Region oder Zone für den Cluster, was genau Ihre Anwendung tut. Bei einer latenzempfindlichen Produktionsumgebung erzielen Sie mit einer Region/Zone mit geringerer Netzwerklatenz und höherer Effizienz vermutlich das beste Preis-Leistungs-Verhältnis für Ihre Anwendung.
Eine weniger latenzempfindliche Entwicklungsumgebung könnten Sie dagegen in einer kostengünstigeren Region ansiedeln.
Clusterverfügbarkeit
Zu den verfügbaren GKE-Clustertypen gehören zonale (einzel‑ oder multizonale) und regionale Cluster. Ein einzelzonaler Cluster scheint erst einmal die kostengünstigste Option zu sein. Damit Ihre Anwendungen hochverfügbar sind, ist es jedoch besser, die Clusterressourcen auf mehrere Zonen zu verteilen.
In vielen Fällen erzielen Sie mit einem multizonalen oder regionalen Cluster, bei dem die Verfügbarkeit im Vordergrund steht, das beste Preis-Leistungs-Verhältnis.
Aufgabe 3: Regionalen Cluster verwalten
Einrichtung
Das Verwalten der Ressourcen Ihres Clusters in verschiedenen Zonen ist etwas komplexer. Wenn Sie nicht aufpassen, fallen möglicherweise zusätzliche Kosten durch unnötige interzonale Kommunikation zwischen den Pods an.
In diesem Abschnitt beobachten Sie den Netzwerk-Traffic Ihres Clusters und verschieben zwei Pods, die viel Traffic zwischen sich verursachen, in dieselbe Zone.
- Erstellen Sie im Tab Cloud Shell einen neuen regionalen Cluster. Das Ausführen dieses Befehls dauert einige Minuten:
Zum Simulieren von Traffic zwischen den Pods und Knoten erstellen Sie zwei Pods in separaten Knoten in Ihrem regionalen Cluster. Mit ping erzeugen Sie Traffic von einem Pod zum anderen, den Sie dann überwachen können.
- Führen Sie den folgenden Befehl aus, um ein Manifest für den ersten Pod zu erstellen:
- Mit diesem Befehl erstellen Sie den ersten Pod in Kubernetes:
- Führen Sie als Nächstes den folgenden Befehl aus, um ein Manifest für den zweiten Pod zu erstellen:
- Erstellen Sie den zweiten Pod in Kubernetes:
Klicken Sie auf Fortschritt prüfen.
Die von Ihnen erstellten Pods verwenden den Container node-hello und geben die Nachricht Hello Kubernetes aus, wenn sie angefragt werden.
In der Datei pod-2.yaml, die Sie erstellt haben, gibt es eine definierte Regel für die Pod-Anti-Affinität. Damit können Sie sicherstellen, dass der Pod nicht auf demselben Knoten wie pod-1 geplant ist. Dies erfolgt durch den Abgleich eines Ausdrucks mit dem Label security: demo von pod-1. Die Pod-Affinität stellt sicher, dass Pods auf demselben Knoten geplant werden, während die Pod-Anti-Affinität dafür sorgt, dass Pods nicht auf demselben Knoten geplant werden.
In diesem Fall wird die Pod-Anti-Affinität verwendet, um den Traffic zwischen Knoten klarer darzustellen. Aber durch einen intelligenten Einsatz von Pod-Anti-Affinität und Pod-Affinität können Sie die Ressourcen Ihres regionalen Clusters noch besser nutzen.
- Sehen Sie sich die erstellten Pods an:
Beide Pods werden mit dem Status Running und internen IP-Adressen ausgegeben.
Beispielausgabe:
Notieren Sie sich die IP-Adresse von pod-2. Sie benötigen sie im nächsten Befehl.
Traffic simulieren
- Rufen Sie für den Container
pod-1eine Shell ab:
- Senden Sie in der Shell eine Anfrage an
pod-2und ersetzen Sie [POD-2-IP] durch die fürpod-2angezeigte interne IP-Adresse:
Notieren Sie sich die durchschnittliche Latenz eines Ping von pod-1 an pod-2.
Flusslogs untersuchen
Wenn pod-1 Pings an pod-2 sendet, können Sie in dem Subnetz der VPC, in dem der Cluster erstellt wurde, Flusslogs aktivieren, um den Traffic zu beobachten.
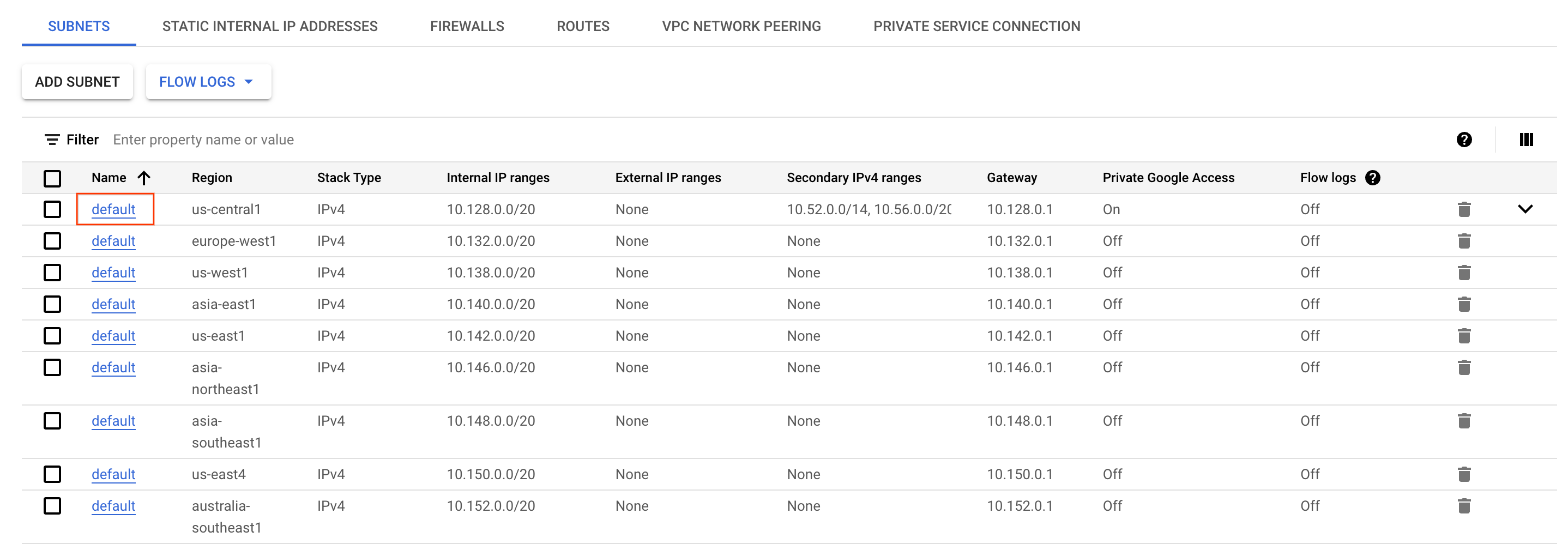
- Rufen Sie in der Cloud Console das Navigationsmenü auf und wählen Sie im Abschnitt Netzwerk die Option VPC-Netzwerk aus.
- Suchen Sie in der Region
das Subnetz defaultund klicken Sie darauf.
-
Klicken Sie oben auf der Seite auf Bearbeiten.
-
Wählen Sie für Flusslogs die Einstellung An aus.
-
Klicken Sie auf Speichern.
-
Klicken Sie dann auf Flusslogs im Log-Explorer ansehen.

Sie sehen jetzt eine Liste mit Logs, die viele Informationen enthalten. Jedes Mal, wenn die Instanzen etwas gesendet oder empfangen haben, wird dort ein Eintrag erstellt.
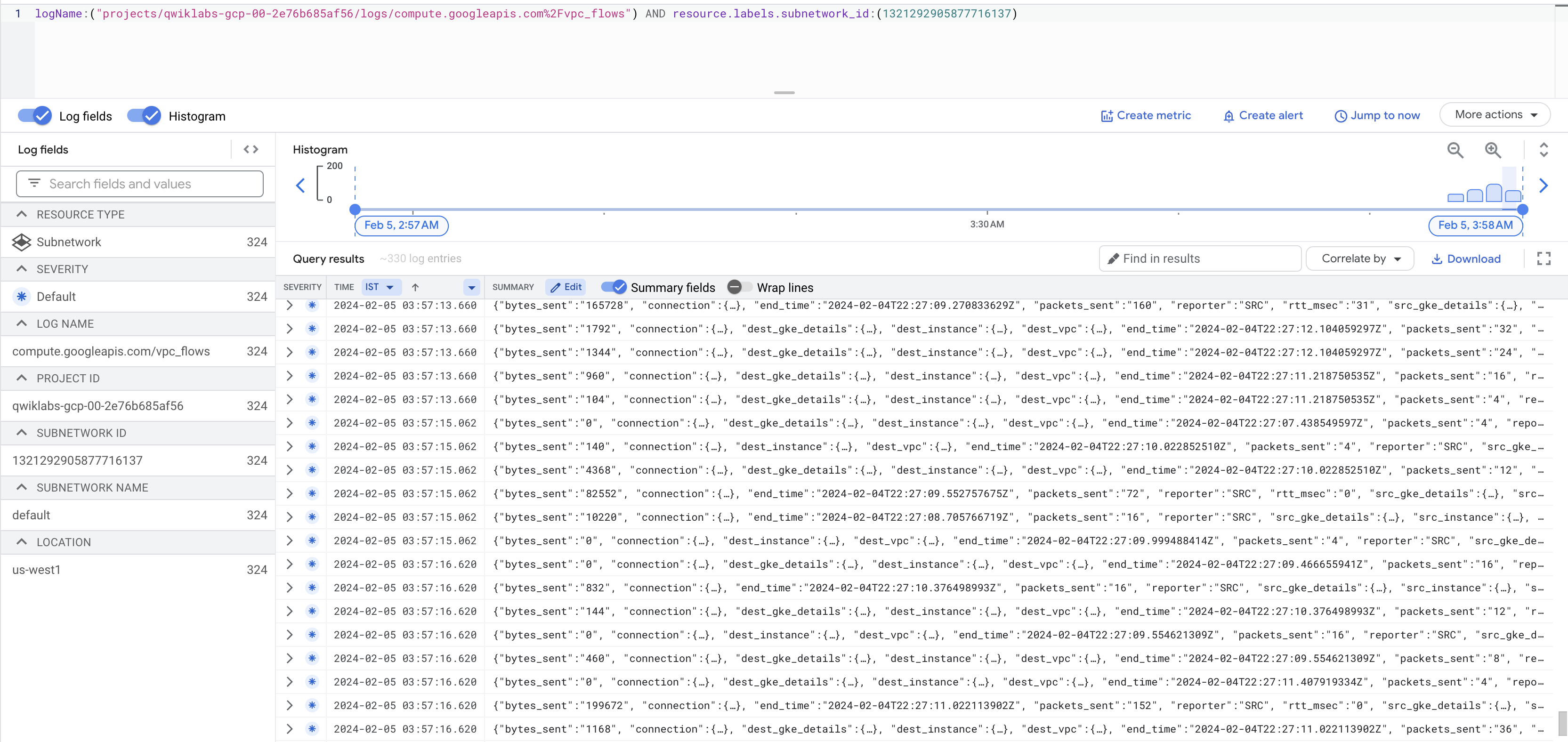
Falls keine Logs erzeugt werden, ersetzen Sie das Zeichen / vor „vpc_flows“ durch %2F, wie im obigen Screenshot gezeigt.
Das ist möglicherweise etwas schwer zu lesen. Exportieren Sie die Daten daher in eine BigQuery-Tabelle, um die relevanten Informationen abfragen zu können.
- Klicken Sie auf Weitere Aktionen > Senke erstellen.
-
Geben Sie der Senke den Namen
FlowLogsSample. -
Klicken Sie auf Weiter.
Senkenziel
- Wählen Sie als Senkendienst die Option BigQuery-Dataset aus.
- Wählen Sie unter BigQuery-Dataset die Option Neues BigQuery-Dataset erstellen aus.
- Geben Sie dem Dataset den Namen us_flow_logs und klicken Sie auf Dataset erstellen.
Alles andere können Sie unverändert lassen.
-
Klicken Sie auf Senke erstellen.
-
Sehen Sie sich nun das neu erstellte Dataset an. Klicken Sie dazu in der Cloud Console im Navigationsmenü im Abschnitt Analysen auf BigQuery.
-
Klicken Sie auf Fertig.
-
Klicken Sie auf den Projektnamen und dann auf us_flow_logs, um die neu erstellte Tabelle zu öffnen. Falls keine Tabelle angezeigt wird, aktualisieren Sie die Ansicht, bis sie erstellt wurde.
-
Klicken Sie unter dem Dataset
us_flow_logsauf die Tabellecompute_googleapis_com_vpc_flows_xxx.
-
Klicken Sie auf Abfrage > In neuem Tab.
-
Fügen Sie im BigQuery-Editor den folgenden Code zwischen
SELECTundFROMein:
- Klicken Sie auf Ausführen.
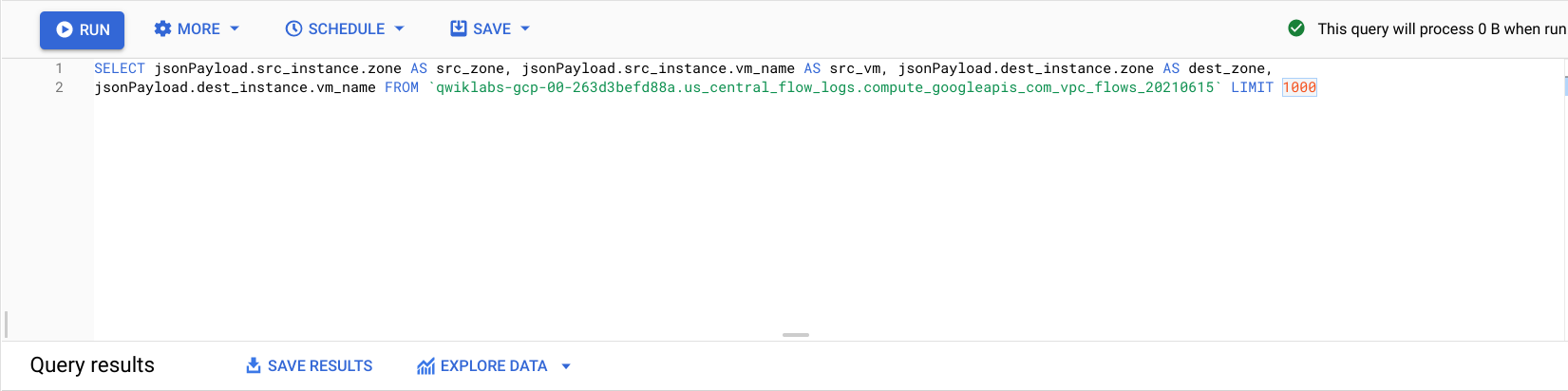
Jetzt werden Ihnen die Flusslogs gefiltert nach source zone, source vm, destination zone und destination vm angezeigt.
Suchen Sie einige Zeilen mit Aufrufen zwischen zwei verschiedenen Zonen im Cluster regional-demo.

An den Flusslogs können Sie ablesen, dass es viel Traffic zwischen den verschiedenen Zonen gibt.
Als Nächstes verschieben Sie die Pods in dieselbe Zone und sehen sich an, welche Vorteile dies hat.
Pod, der viel Traffic verursacht, verschieben, um die Kosten für zonenübergreifenden Traffic zu minimieren
-
Drücken Sie in Cloud Shell die Tastenkombination Strg + C, um den Befehl
pingzu beenden. -
Führen Sie den Befehl
exitaus, um die Shell vonpod-1zu verlassen:
- Führen Sie den folgenden Befehl aus, um das Manifest von
pod-2zu bearbeiten:
Dadurch wird die Regel Pod Anti Affinity in eine Pod Affinity-Regel geändert. Die Logik bleibt jedoch unverändert. Nun wird pod-2 auf demselben Knoten geplant wie pod-1.
- Löschen Sie den aktuell ausgeführten Pod
pod-2:
- Nachdem Sie
pod-2gelöscht haben, erstellen Sie ihn mit dem bearbeiteten Manifest neu:
Klicken Sie auf Fortschritt prüfen.
- Sehen Sie sich die erstellten Pods an und achten Sie darauf, dass beide den Status
Runninghaben:
Die Ausgabe zeigt, dass pod-1 und pod-2 nun auf demselben Knoten ausgeführt werden.
Notieren Sie sich die IP-Adresse von pod-2. Sie benötigen sie im nächsten Befehl.
- Rufen Sie für den Container
pod-1eine Shell ab:
- Senden Sie in der Shell eine Anfrage an
pod-2und ersetzen Sie [POD-2-IP] durch die interne IP-Adresse fürpod-2aus dem vorherigen Befehl:
Wie Sie sehen, ist die durchschnittliche Ping-Zeit zwischen diesen Pods nun viel kürzer.
Kehren Sie jetzt zu den Flusslogs im BigQuery-Dataset zurück und vergewissern Sie sich anhand der letzten Logs, dass keine unerwünschte interzonale Kommunikation mehr stattfindet.
Kostenanalyse
Sehen Sie sich die Preise für ausgehenden Traffic von VM zu VM in Google Cloud an:
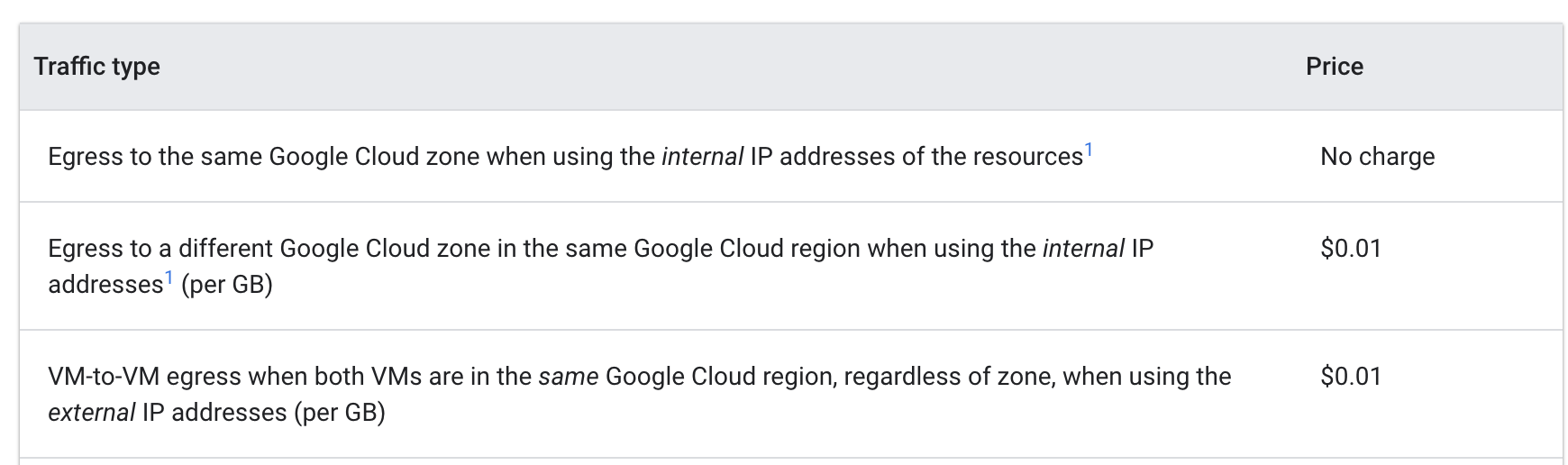
Pings zwischen den Pods in verschiedenen Zonen kosteten 0,01 $ pro GB. Dieser Betrag erscheint gering, kann aber in einem großen Cluster mit mehreren Diensten, die häufige Aufrufe zwischen verschiedenen Zonen ausführen, schnell steigen.
Nachdem Sie die Pods in dieselbe Zone verschoben hatten, kostete das Pingen nichts mehr.
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
Sie haben Möglichkeiten zur Kostenoptimierung virtueller Maschinen kennengelernt, die Teil eines GKE-Clusters sind. Zuerst haben Sie eine Arbeitslast in einen Knotenpool mit einem besser geeigneten Maschinentyp migriert. Dann haben Sie sich mit den Vor‑ und Nachteilen verschiedener Regionen befasst und zum Abschluss haben Sie einen Pod, der viel Traffic verursacht, in einem regionalen Cluster in dieselbe Zone verschoben, in der sich der Pod befindet, mit dem er kommuniziert.
Sie haben in diesem Lab kostengünstige Tools und Strategien für GKE-VMs kennengelernt, aber zum Optimieren virtueller Maschinen müssen Sie zuerst die Anwendungen und deren Anforderungen genau kennen. Informationen über die Arten von Arbeitslasten, die Sie ausführen möchten, sowie eine Einschätzung der Anforderungen Ihrer Anwendung beeinflussen in der Regel die Entscheidung darüber, welcher Standort und Maschinentyp für die virtuellen Maschinen des GKE-Clusters am besten geeignet ist.
Die effiziente Nutzung der Clusterinfrastruktur ist ein entscheidender Schritt zur Kostenoptimierung.
Weitere Informationen
- Leitfaden zu Ressourcen und Vergleichen für Maschinenfamilien
- Best Practices zum Ausführen kostenoptimierter Kubernetes-Anwendungen in GKE: Richtigen Maschinentyp auswählen
- Best Practices zum Ausführen kostenoptimierter Kubernetes-Anwendungen in GKE: Geeignete Region auswählen
Google Cloud-Schulungen und -Zertifizierungen
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 30. April 2024 aktualisiert
Lab zuletzt am 30. April 2024 getestet
© 2024 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.

