체크포인트
Scale Up Hello App
/ 30
Create node pool
/ 30
Managing a Regional Cluster
/ 20
Simulate Traffic
/ 20
GKE 가상 머신의 비용 최적화 살펴보기
GSP767

개요
Google Kubernetes Engine 클러스터의 기본 인프라는 개별 Compute VM 인스턴스인 노드로 구성됩니다. 이 실습에서는 클러스터 인프라 최적화가 비용을 절감하고 애플리케이션을 위한 보다 효율적인 아키텍처를 구축하는 데 어떤 도움이 되는지 보여줍니다.
예시 워크로드용으로 적절하게 구성된 머신 유형을 선택하여 귀중한 인프라 리소스를 최대한 활용하고 활용도 저하를 막는 전략을 배우게 됩니다. 사용 중인 인프라 유형 외에도 해당 인프라의 물리적 지리적 위치도 비용에 영향을 미칩니다. 이 실습을 통해 고가용성 리전 클러스터를 관리하기 위한 비용 효과적인 전략을 수립하는 방법을 살펴볼 수 있습니다.
목표
이 실습에서는 다음 작업을 수행하는 방법을 배웁니다.
- 배포 리소스 사용량 조사
- 배포 확장
- 최적화된 머신 유형을 사용하여 워크로드를 노드 풀로 마이그레이션
- 클러스터의 위치 옵션 살펴보기
- 서로 다른 영역의 포드 간 흐름 로그 모니터링
- 고 트래픽 포드를 이동하여 영역 간 트래픽 비용 최소화
설정 및 요건
실습 시작 버튼을 클릭하기 전에
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머에는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지 표시됩니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 직접 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
- 표준 인터넷 브라우저 액세스 권한(Chrome 브라우저 권장)
- 실습을 완료하기에 충분한 시간---실습을 시작하고 나면 일시중지할 수 없습니다.
실습을 시작하고 Google Cloud 콘솔에 로그인하는 방법
-
실습 시작 버튼을 클릭합니다. 실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 팝업이 열립니다. 왼쪽에는 다음과 같은 항목이 포함된 실습 세부정보 패널이 있습니다.
- Google Cloud 콘솔 열기 버튼
- 남은 시간
- 이 실습에 사용해야 하는 임시 사용자 인증 정보
- 필요한 경우 실습 진행을 위한 기타 정보
-
Google Cloud 콘솔 열기를 클릭합니다(Chrome 브라우저를 실행 중인 경우 마우스 오른쪽 버튼으로 클릭하고 시크릿 창에서 링크 열기를 선택합니다).
실습에서 리소스가 가동되면 다른 탭이 열리고 로그인 페이지가 표시됩니다.
팁: 두 개의 탭을 각각 별도의 창으로 나란히 정렬하세요.
참고: 계정 선택 대화상자가 표시되면 다른 계정 사용을 클릭합니다. -
필요한 경우 아래의 사용자 이름을 복사하여 로그인 대화상자에 붙여넣습니다.
{{{user_0.username | "Username"}}} 실습 세부정보 패널에서도 사용자 이름을 확인할 수 있습니다.
-
다음을 클릭합니다.
-
아래의 비밀번호를 복사하여 시작하기 대화상자에 붙여넣습니다.
{{{user_0.password | "Password"}}} 실습 세부정보 패널에서도 비밀번호를 확인할 수 있습니다.
-
다음을 클릭합니다.
중요: 실습에서 제공하는 사용자 인증 정보를 사용해야 합니다. Google Cloud 계정 사용자 인증 정보를 사용하지 마세요. 참고: 이 실습에 자신의 Google Cloud 계정을 사용하면 추가 요금이 발생할 수 있습니다. -
이후에 표시되는 페이지를 클릭하여 넘깁니다.
- 이용약관에 동의합니다.
- 임시 계정이므로 복구 옵션이나 2단계 인증을 추가하지 않습니다.
- 무료 체험판을 신청하지 않습니다.
잠시 후 Google Cloud 콘솔이 이 탭에서 열립니다.

이 실습에서는 사용할 작은 클러스터를 생성합니다. 클러스터 프로비저닝에는 약 2~5분이 소요됩니다.
실습 시작 버튼을 눌렀을 때 로딩 서클과 함께 파란색 리소스 프로비저닝 중 메시지가 표시되면 아직 클러스터가 생성 중인 것입니다.
기다리는 동안 다음 안내와 설명을 읽을 수 있지만 리소스 프로비저닝이 완료될 때까지 모든 셸 명령어는 작동하지 않습니다.
작업 1. 노드 머신 유형 이해
일반 개요
머신 유형은 시스템 메모리 크기, 가상 CPU(vCPU) 개수, 영구 디스크 한도를 포함하여 VM(가상 머신) 인스턴스에 제공할 수 있는 가상화된 하드웨어 리소스 집합입니다. 머신 유형은 다양한 워크로드에 따라 제품군별로 그룹화되고 선별됩니다.
노드 풀의 머신 유형을 선택할 때 일반적으로 범용 머신 유형 제품군은 다양한 워크로드에 최고의 가성비를 제공합니다. 범용 머신 유형은 N 시리즈와 E2 시리즈로 구성됩니다.
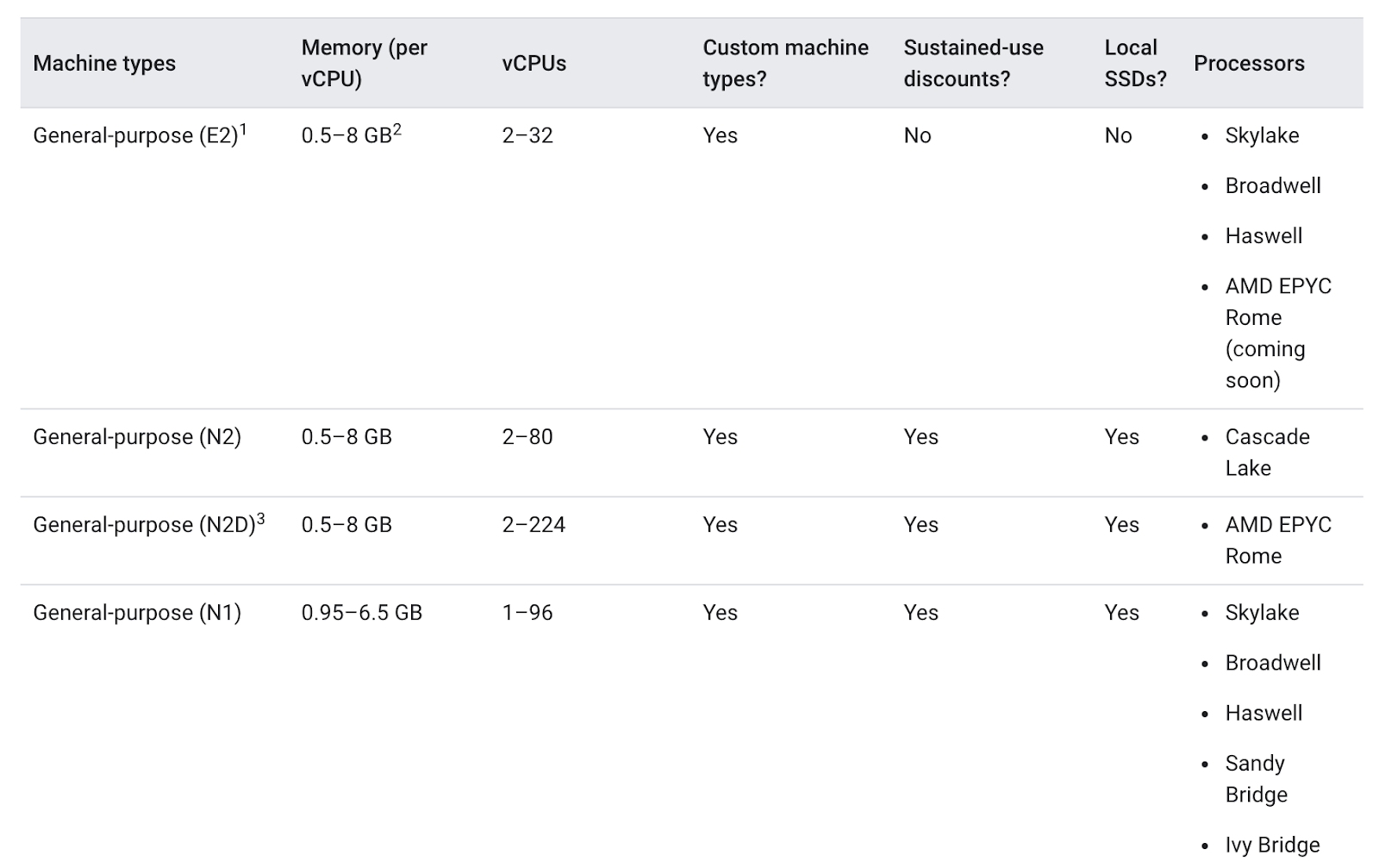
머신 유형 간의 차이는 앱에 도움이 될 수도 있고 도움이 되지 않을 수도 있습니다. 일반적으로 E2는 N1과 성능이 비슷하지만 비용 측면에서 최적화되어 있습니다. 일반적으로 E2 머신 유형만 활용하면 비용을 절감할 수 있습니다.
그러나 클러스터의 경우 활용되는 리소스를 애플리케이션의 필요에 맞게 최적화하는 것이 가장 중요합니다. 더 큰 애플리케이션이나 대규모 확장이 필요한 배포에서 워크로드를 여러 대의 범용 머신에 분산시키는 것보다 최적화된 머신 몇 대에 스택하는 것이 더 저렴할 수 있습니다.
이러한 의사결정에 도달하려면 앱의 세부정보를 이해해야 합니다. 앱에 특정 요구사항이 있는 경우 머신 유형을 앱에 맞게 구성해야 합니다.
다음 섹션에서는 데모 앱을 살펴보고 이를 머신 유형이 올바르게 구성된 노드 풀로 마이그레이션합니다.
작업 2. Hello 앱에 적합한 머신 유형 선택
Hello 데모 클러스터의 요구사항 조사
시작 시 실습용으로 2개의 E2 medium(vCPU 2개, 4GB 메모리) 노드가 포함된 Hello 데모 클러스터가 생성됩니다. 이 클러스터는 Hello 앱이라는 간단한 웹 애플리케이션의 복제본 하나를 배포합니다. 앱은 모든 요청에 'Hello, World!' 메시지로 응답하는 Go로 작성된 웹 서버입니다.
- 실습용 프로비저닝이 완료되면 Cloud 콘솔에서 탐색 메뉴를 클릭한 다음 Kubernetes Engine을 클릭합니다.
-
Kubernetes 클러스터 창에서 hello-demo-cluster를 선택합니다.
-
다음 창에서 노드 탭을 선택합니다.
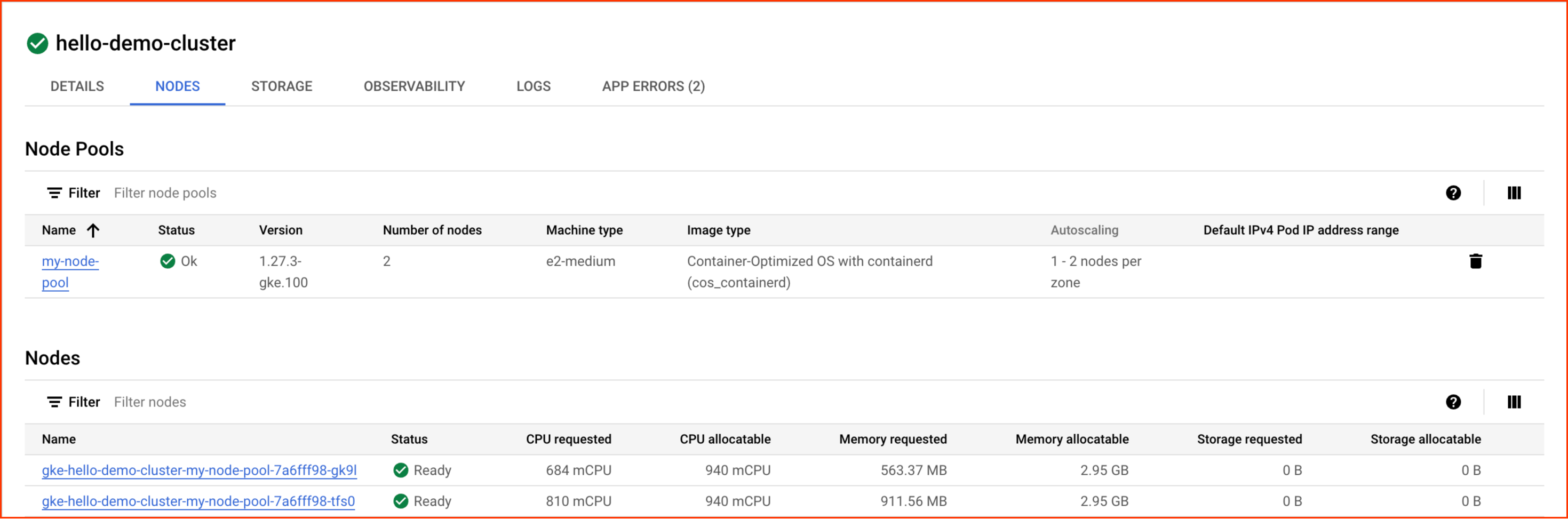
이제 클러스터 노드 목록이 표시됩니다.

GKE가 클러스터 리소스를 어떻게 활용했는지 관찰합니다. 각 노드에서 요청하는 CPU와 메모리의 양은 물론 노드에서 잠재적으로 할당할 수 있는 양을 확인할 수 있습니다.
- 클러스터의 첫 번째 노드를 클릭합니다.
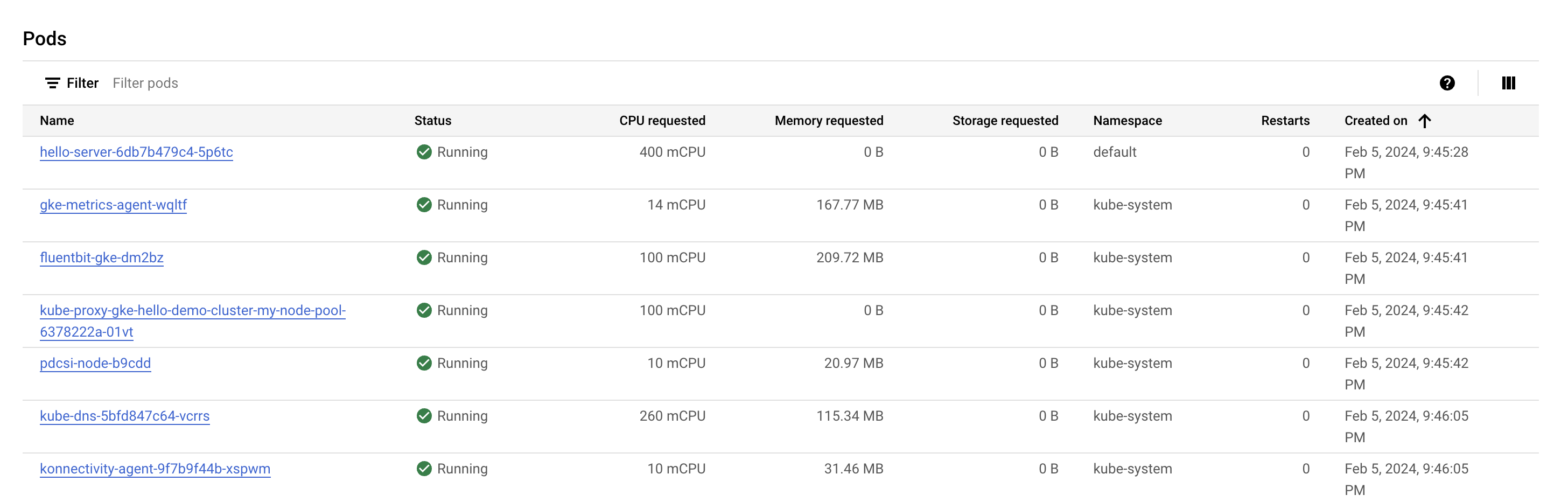
포드 섹션을 살펴봅니다. 기본 네임스페이스에 hello-server 포드가 있어야 합니다. hello-server 포드가 없으면 다시 돌아가 클러스터의 두 번째 노드를 대신 선택합니다.
hello-server 포드가 400mcpu를 요청하는 것을 확인할 수 있습니다. 또한 실행 중인 다른 kube-system 포드도 몇 개 표시되어야 합니다. 이러한 포드는 모니터링과 같은 GKE의 클러스터 서비스를 사용 설정하기 위해 로드됩니다.
- 뒤로 버튼을 눌러 이전 노드 페이지로 되돌아갑니다.
이미 필수 kube-system 서비스와 함께 Hello-App의 복제본 하나를 실행하려면 두 개의 E2-medium 노드가 필요하다는 것을 확인했습니다. 또한 클러스터 CPU 리소스의 대부분을 사용하는 동안 할당 가능한 메모리의 약 1/3만 사용합니다.
이 앱의 워크로드가 완전히 정적인 경우 필요한 CPU와 메모리의 정확한 양을 갖춘 커스텀 형태의 머신 유형을 만들 수 있습니다. 이렇게 하면 결과적으로 전체 클러스터 인프라 비용이 절감됩니다.
그러나 GKE 클러스터가 여러 워크로드를 실행하는 경우가 많으므로 일반적으로 해당 워크로드는 수직 확장 및 축소해야 합니다.
Hello 앱이 수직 확장되면 어떻게 될까요?
Cloud Shell 활성화
Cloud Shell은 다양한 개발 도구가 탑재된 가상 머신으로, 5GB의 영구 홈 디렉터리를 제공하며 Google Cloud에서 실행됩니다. Cloud Shell을 사용하면 명령줄을 통해 Google Cloud 리소스에 액세스할 수 있습니다.
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화
를 클릭합니다.
연결되면 사용자 인증이 이미 처리된 것이며 프로젝트가 PROJECT_ID로 설정됩니다. 출력에 이 세션의 PROJECT_ID를 선언하는 줄이 포함됩니다.
gcloud는 Google Cloud의 명령줄 도구입니다. Cloud Shell에 사전 설치되어 있으며 명령줄 자동 완성을 지원합니다.
- (선택사항) 다음 명령어를 사용하여 활성 계정 이름 목록을 표시할 수 있습니다.
-
승인을 클릭합니다.
-
다음과 비슷한 결과가 출력됩니다.
출력:
- (선택사항) 다음 명령어를 사용하여 프로젝트 ID 목록을 표시할 수 있습니다.
출력:
출력 예시:
gcloud 전체 문서는 Google Cloud에서 gcloud CLI 개요 가이드를 참조하세요.
Hello 앱 수직 확장
- 클러스터의 사용자 인증 정보에 액세스합니다.
-
Hello-Server수직 확장:
내 진행 상황 확인하기를 클릭하여 위 작업을 올바르게 수행했는지 확인합니다.
- 콘솔로 돌아와 왼쪽의 Kubernetes Engine 메뉴에서 워크로드를 선택합니다.
hello-server가 최소 가용성을 보유하지 않음 오류 상태임을 볼 수 있습니다.
- 오류 메시지를 클릭하면 상태 세부정보를 볼 수 있습니다. 이유는
CPU 부족임을 알 수 있습니다.
예견할 수 있는 상황이죠. 기억하겠지만 클러스터에는 CPU 리소스가 거의 남지 않았고 hello-server의 다른 복제본으로 추가 400m를 요청했습니다.
- 새 요청을 처리하도록 노드 풀을 늘립니다.
-
메시지가 표시되면
Y를 입력하고Enter키를 누릅니다. -
콘솔에서
hello-server워크로드 상태가 정상으로 바뀔 때까지 워크로드 페이지를 새로고침합니다.

클러스터 조사
워크로드가 성공적으로 수직 확장되면 클러스터의 노드 탭으로 다시 이동합니다.
- hello-demo-cluster를 클릭합니다.

- 그런 다음 노드 탭을 클릭합니다.
노드 풀이 클수록 더 많은 워크로드를 처리할 수 있지만 인프라의 리소스가 어떻게 활용되고 있는지 살펴봐야 합니다.
GKE는 클러스터의 리소스를 최대한 활용하지만 여기에서 어느 정도 최적화가 가능한 부분이 있습니다. 노드 중 하나가 대부분의 메모리를 사용하고 있지만 노드 중 두 개에 상당량의 사용하지 않은 메모리가 있음을 알 수 있습니다.
이 시점에서 앱을 계속 수직 확장하면 비슷한 패턴이 나타나기 시작합니다. Kubernetes는 hello-server 배포의 새 복제본마다 노드를 찾으려다 실패하고 약 600m의 CPU를 사용하여 새 노드를 만듭니다.
빈 패킹 문제
빈 패킹 문제는 다양한 볼륨/모양의 항목을 개수가 한정된 규칙적인 모양의 '빈'(즉 컨테이너)에 넣어야 하는 문제입니다. 본질적으로 항목을 최소한의 빈에 넣어 가능한 한 효율적으로 '패킹'하기가 까다롭습니다.
이는 실행되는 애플리케이션의 Kubernetes 클러스터를 최적화하려고 할 때 직면하는 문제와 유사합니다. 보유한 여러 애플리케이션은 리소스 요구사항(즉, 메모리 및 CPU)이 다양합니다. Kubernetes로 자동 관리되는 인프라 리소스(클러스터 비용의 대부분을 사용할 가능성이 높음)에 이러한 애플리케이션을 최대한 효율적으로 맞춰야 합니다.
Hello 데모 클러스터는 효율적인 빈 패킹을 사용하지 않습니다. 이 워크로드에 더 적합한 머신 유형을 사용하도록 Kubernetes를 구성하는 것이 보다 경제적입니다.
최적화된 노드 풀로 마이그레이션
- 더 큰 머신 유형으로 새 노드 풀을 만듭니다.
내 진행 상황 확인하기를 클릭하여 위 작업을 올바르게 수행했는지 확인합니다.
이제 다음 단계에 따라 포드를 새 노드 풀로 마이그레이션할 수 있습니다.
-
기존 노드 풀 차단: 이 작업은 기존 노드 풀(
노드)에 있는 노드를 예약할 수 없는 상태로 표시합니다. 예약할 수 없는 상태로 표시한 다음에는 Kubernetes가 이러한 노드에 대한 새 포드 예약을 중지합니다. -
기존 노드 풀 드레이닝: 이 작업은 기존 노드 풀(
노드)의 노드에서 실행 중인 워크로드를 적절하게 제거합니다.
- 먼저 원본 노드 풀을 차단합니다.
- 다음으로 풀을 드레이닝합니다.
이 시점에서 포드가 새 larger-pool 노드 풀에서 실행되고 있음을 확인해야 합니다.
- 포드가 마이그레이션되면 이전 노드 풀을 삭제하는 것이 안전합니다.
- 계속할 것인지를 물으면
y를 입력하고Enter키를 누릅니다.
삭제에는 약 2분 정도 걸릴 수 있습니다. 기다리는 동안 다음 섹션을 읽어보세요.
비용 분석
동일한 워크로드를 실행하는데 이제 하나의 e2-standard-2 머신에서 세 대의 e2-medium 머신이 필요합니다.
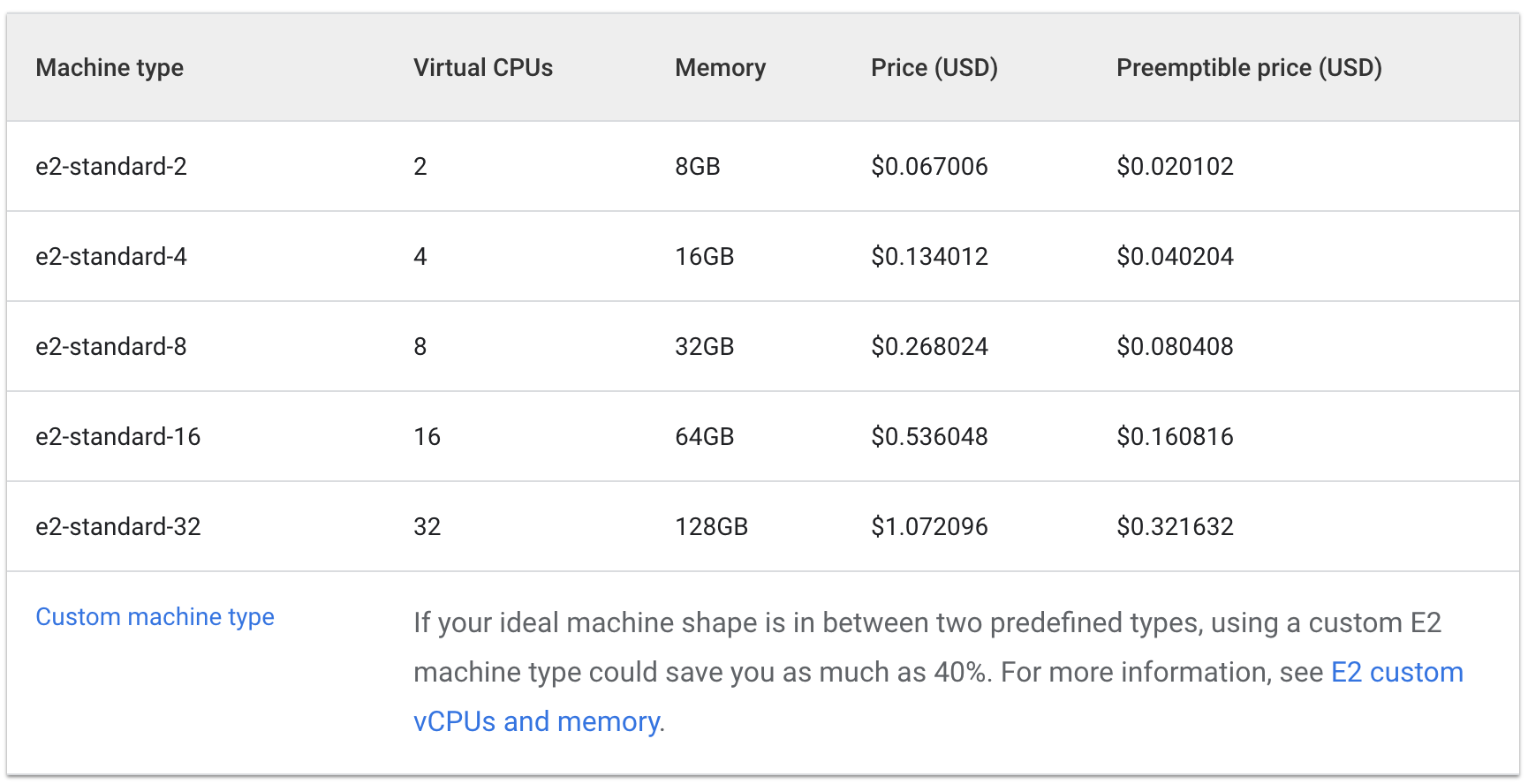
e2 표준 및 공유 코어 머신 유형을 갖추는 데 드는 시간당 비용을 살펴봅니다.
표준:
공유 코어:
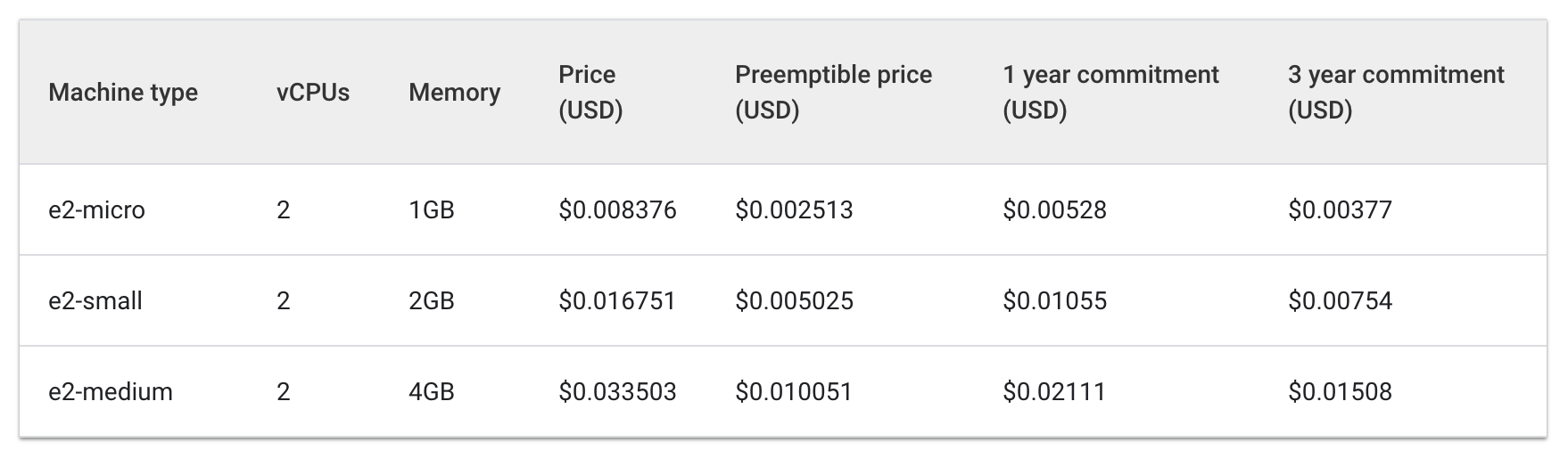
세 대의 e2-medium 머신 비용은 시간당 약 $0.1이며, 나열된 하나의 e2-standard-2는 시간당 $0.067입니다.
시간당 $.04의 절약은 작게 느껴질 수 있지만 이 비용은 실행 중인 애플리케이션의 전체 기간 동안 합산됩니다. 또한 규모가 클수록 더욱 눈에 띄는 금액이 됩니다. e2-standard-2 머신은 워크로드를 보다 효율적으로 패킹할 수 있고 사용되지 않는 공간이 적기 때문에 수직 확장 비용이 더디게 늘어납니다.
이는 흥미롭게도 E2-medium이 리소스 집약적이지 않은 소규모 애플리케이션에 비용 효과적으로 설계된 공유 코어 머신 유형이기 때문에 그렇습니다. 하지만 Hello-App의 현재 워크로드에서는 더 큰 머신 유형이 포함된 노드 풀을 사용하는 것이 더 비용 효과적인 전략일 수 있습니다.
Cloud 콘솔에서 hello-demo 클러스터의 노드 탭에 계속 있어야 합니다. 이 탭을 새로고침하고 larger-pool 노드의 요청한 CPU와 할당 가능한 CPU 필드를 조사합니다.
추가로 최적화할 여지가 있습니다. 새 노드는 다른 노드를 프로비저닝할 필요 없이 워크로드의 다른 복제본에 적합할 수 있습니다. 또는 더 많은 리소스를 절약하면서 애플리케이션의 CPU 및 메모리 필요에 맞는 커스텀 크기의 머신 유형을 선택할 수도 있습니다.
비용은 클러스터 위치에 따라 달라질 수 있습니다. 이 실습의 다음 부분에서는 가장 좋은 리전을 선택하고 리전 클러스터를 관리하는 방법을 다룹니다.
클러스터에 적합한 위치 선택
리전 및 영역 개요
클러스터 노드에 사용되는 Compute Engine 리소스는 전 세계 여러 곳에서 호스팅됩니다. 이러한 위치는 리전과 영역으로 구성됩니다. 리전은 리소스를 호스팅할 수 있는 특정한 지리적 위치로, 영역이 3개 이상입니다.
가상 머신 인스턴스 또는 영역 영구 디스크와 같이 영역에 있는 리소스를 영역별 리소스라고 합니다. 고정 외부 IP 주소와 같은 기타 리소스는 리전별 리소스입니다. 리전별 리소스는 영역과 관계없이 해당 리전의 모든 리소스에서 사용할 수 있지만, 영역별 리소스는 같은 영역에 있는 다른 리소스에서만 사용할 수 있습니다.
리전이나 영역을 선택할 때 다음 사항을 고려해야 합니다.
- 실패 처리 - 앱의 리소스가 한 영역에만 배포되었는데 해당 영역을 사용할 수 없게 되면 앱도 사용할 수 없습니다. 규모가 크고 수요가 많은 앱의 경우 오류를 처리할 때 여러 영역이나 리전에 리소스를 배포하는 것이 주로 권장됩니다.
- 네트워크 지연 시간 감소 - 네트워크 지연 시간을 줄이기 위해 서비스 지점과 가까운 리전이나 영역을 선택하는 것이 좋습니다. 예를 들어 미국 동부 해안에 대부분의 고객이 있는 경우 이 지역과 가까운 기본 리전 및 영역을 선택할 수 있습니다.
클러스터를 위한 권장사항
비용은 다양한 요인에 따라 리전마다 다릅니다. 예를 들어 us-west2 리전의 리소스는 us-central1의 리소스보다 더 비싼 경향이 있습니다.
클러스터의 리전이나 영역을 선택할 때는 앱이 무엇을 하는지 조사하세요. 지연 시간에 민감한 프로덕션 환경의 경우 네트워크 지연 시간이 줄어들고 효율성이 향상된 리전/영역에 앱을 배치하면 최고의 가성비를 얻을 수 있습니다.
그러나 지연 시간에 민감하지 않은 개발 환경을 비용이 덜 드는 리전에 배치하면 비용을 줄일 수 있습니다.
클러스터 가용성 처리
GKE에서 사용 가능한 클러스터 유형에는 영역별(단일 영역 또는 멀티 영역) 및 리전별 유형이 포함됩니다. 보이는 그대로 단일 영역 클러스터가 가장 저렴한 옵션입니다. 그러나 애플리케이션의 고가용성을 위해서는 클러스터의 인프라 리소스를 여러 영역에 분산하는 것이 가장 좋습니다.
대부분의 경우 멀티 영역 또는 리전 클러스터를 통해 클러스터의 가용성에 우선순위를 두면 최적의 가성비를 갖춘 아키텍처가 됩니다.
작업 3. 리전 클러스터 관리
설정
여러 영역에 걸쳐 클러스터 리소스를 관리하기란 좀 더 복잡합니다. 주의하지 않으면 포드 사이에서 불필요한 영역 간 통신으로 인해 추가 비용이 쌓일 수 있습니다.
이 섹션에서는 클러스터의 네트워크 트래픽을 관찰하고 서로 많은 트래픽을 생성하는 두 개의 고 트래픽 포드를 동일한 영역에 있도록 이동합니다.
- Cloud Shell 탭에서 새 리전 클러스터를 만듭니다(이 명령어를 완료하는 데 몇 분 정도 걸림).
포드와 노드 간의 트래픽을 시연하기 위해 리전 클러스터의 개별 노드에 두 개의 포드를 생성합니다. ping을 사용해 한 포드에서 다른 포드로 트래픽을 생성하여 모니터링할 수 있는 트래픽을 생성합니다.
- 이 명령어를 실행하여 첫 번째 포드에 대한 매니페스트를 만듭니다.
- 이 명령어를 사용하여 Kubernetes에서 첫 번째 포드를 만듭니다.
- 그런 후 이 명령어를 실행하여 두 번째 포드의 매니페스트를 만듭니다.
- Kubernetes에서 두 번째 포드를 만듭니다.
내 진행 상황 확인하기를 클릭하여 위 작업을 올바르게 수행했는지 확인합니다.
만든 포드는 node-hello 컨테이너를 사용하고 요청하면 Hello Kubernetes 메시지를 출력합니다.
만든 pod-2.yaml 파일을 다시 확인하면 포드 안티어피니티가 정의된 규칙임을 알 수 있습니다. 이렇게 하면 포드가 동일한 노드에 pod-1로 예약되지 않습니다. 이는 pod-1의 security: demo 라벨을 기반으로 표현식을 일치시키는 방식으로 이루어집니다. 포드 어피니티는 포드가 동일한 노드에 예약되었음을 확인하는 데 사용되는 반면 포드 안티어피니티는 포드가 동일한 노드에 예약되지 않았음을 확인하는 데 사용됩니다.
이러한 경우 노드 간 트래픽을 효과적으로 묘사하기 위해 포드 안티어피니티가 사용되지만 포드 안티어피니티 및 포드 어피니티를 스마트하게 사용하면 리전 클러스터의 리소스를 더 잘 활용할 수 있습니다.
- 만든 포드를 봅니다.
실행 중 상태와 내부 IP로 반환된 두 포드가 모두 표시됩니다.
샘플 출력:
pod-2의 IP 주소를 메모합니다. 이 IP 주소는 다음 명령어에서 사용됩니다.
트래픽 시뮬레이션
- 셸을
pod-1컨테이너로 가져옵니다.
- 셸에서 [POD-2-IP]를
pod-2에 표시된 내부 IP로 바꾼 후 요청을pod-2로 보냅니다.
pod-1에서 pod-2를 핑하는 데 걸린 평균 지연 시간을 메모합니다.
흐름 로그 조사
pod-2를 핑하는 pod-1로 클러스터가 생성된 VPC의 서브넷에서 흐름 로그를 사용하여 트래픽을 관찰할 수 있습니다.
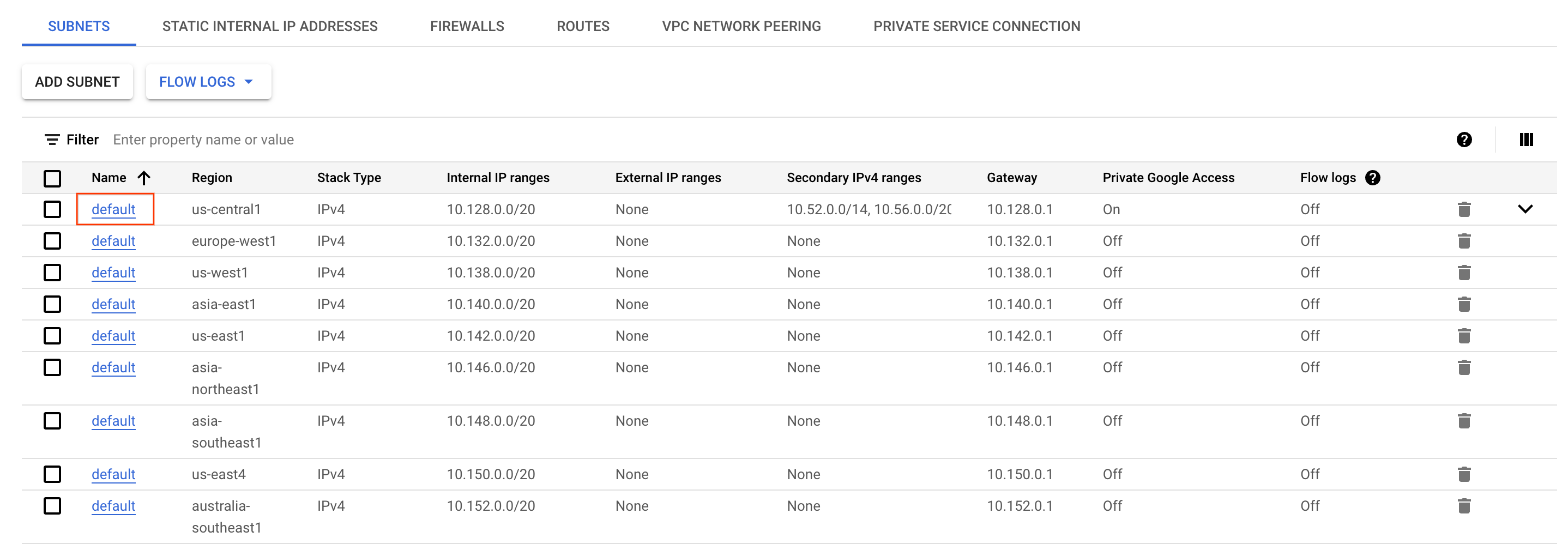
- Cloud 콘솔에서 탐색 메뉴를 열고 네트워킹 섹션에서 VPC 네트워크를 선택합니다.
-
리전에서 기본서브넷을 찾아 클릭합니다.
-
화면 상단에 있는 편집을 클릭합니다.
-
사용 설정할 흐름 로그를 선택합니다.
-
저장을 클릭합니다.
-
다음으로 로그 탐색기에서 흐름 로그 보기를 클릭합니다.

이제 인스턴스 중 하나에서 무언가를 보내거나 받을 때마다 많은 양의 정보를 표시하는 로그 목록이 나타납니다.
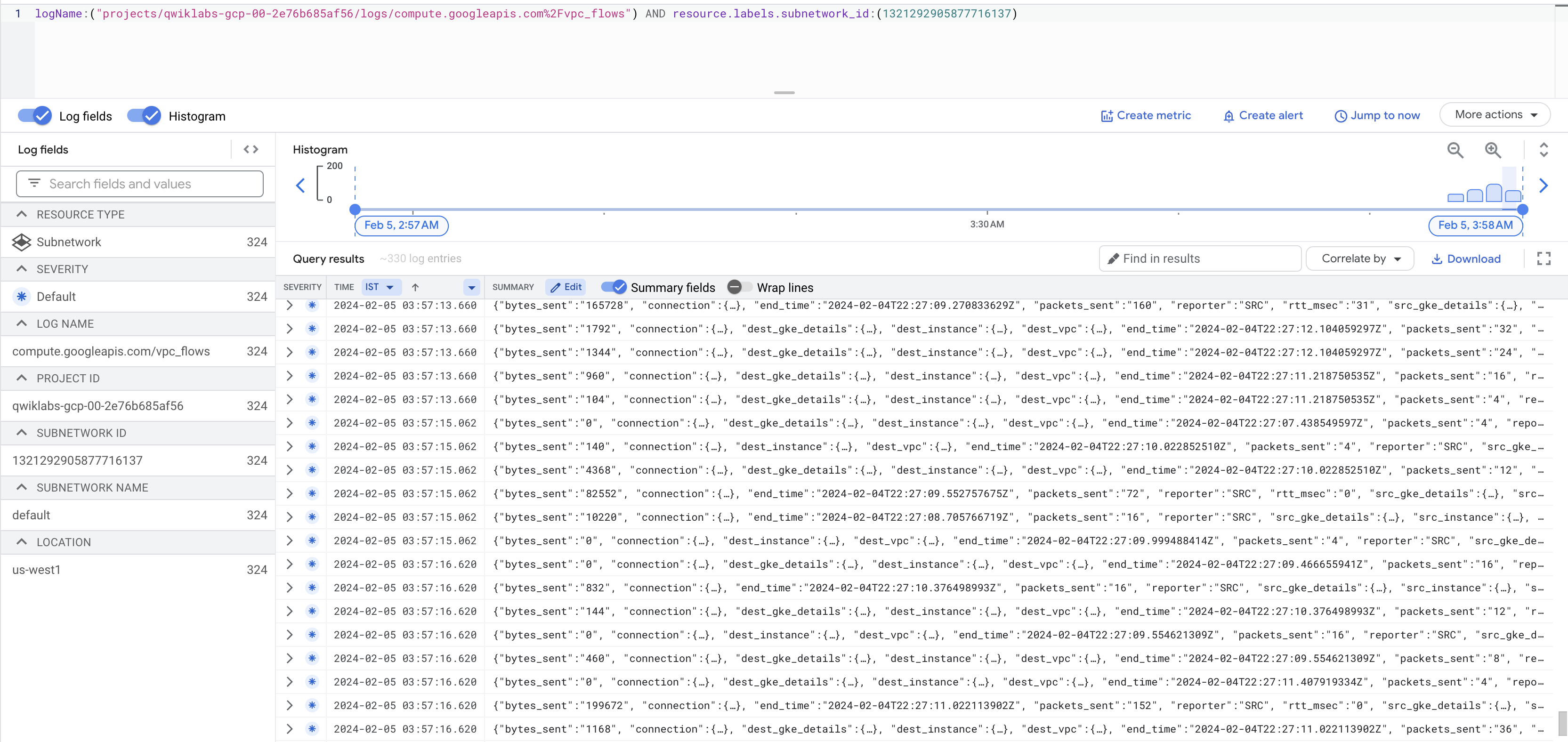
로그가 생성되지 않으면 위 스크린샷에 나와 있는 대로 vpc_flows 앞에 있는 /를 %2F로 바꿉니다.
읽기가 조금 어려울 수 있습니다. 그런 다음 관련 정보를 쿼리할 수 있도록 BigQuery 테이블로 내보냅니다.
- 작업 더보기 > 싱크 만들기를 클릭합니다.
-
싱크 이름을
FlowLogsSample로 지정합니다. -
다음을 클릭합니다.
싱크 대상
- 싱크 서비스에서 BigQuery 데이터 세트를 선택합니다.
- BigQuery 데이터 세트에서 새 BigQuery 데이터 세트 만들기를 선택합니다.
- 데이터 세트 이름을 'us_flow_logs'로 지정하고 데이터 세트 만들기를 클릭합니다.
나머지는 그대로 둡니다.
-
싱크 만들기를 클릭합니다.
-
이제 새로 생성된 데이터 세트를 조사합니다. Cloud 콘솔의 탐색 메뉴에서 애널리틱스 섹션의 BigQuery를 클릭합니다.
-
완료를 클릭합니다.
-
프로젝트 이름을 선택한 후 us_flow_logs를 선택해 새롭게 만든 테이블을 확인합니다. 테이블이 없으면 생성될 때까지 새로고침해야 할 수도 있습니다.
-
us_flow_logs데이터 세트 아래에서compute_googleapis_com_vpc_flows_xxx테이블을 클릭합니다.
-
쿼리 > 새 탭을 클릭합니다.
-
BigQuery 편집기에서 이를
SELECT와FROM사이에 붙여넣습니다.
- 실행을 클릭합니다.
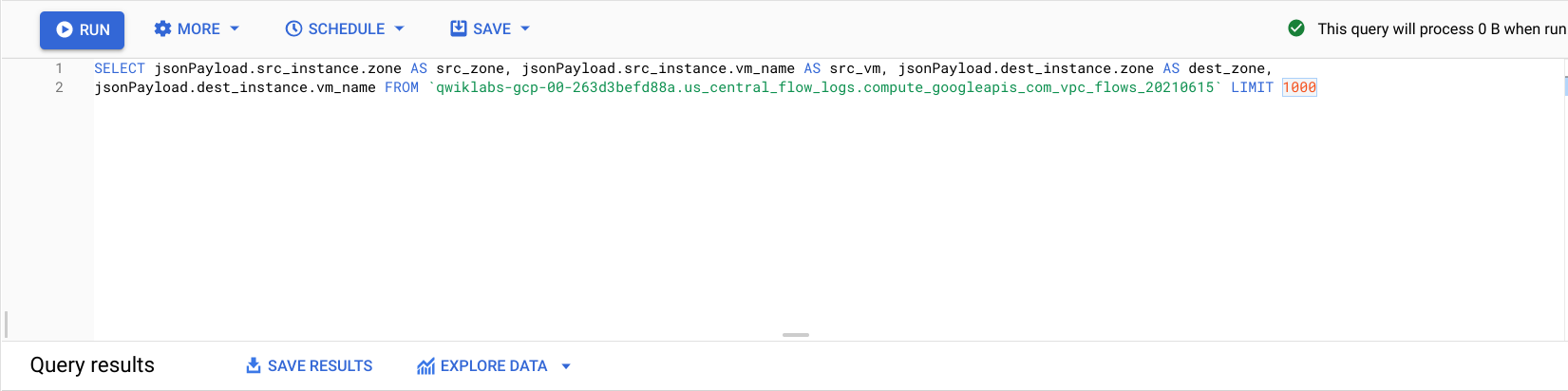
이전의 흐름 로그가 표시되지만 source zone, source vm, destination zone, destination vm으로 필터링됩니다.
regional-demo 클러스터의 서로 다른 두 영역 간에 호출이 이루어지는 행 몇 개를 찾습니다.

흐름 로그를 관찰하면 서로 다른 영역 간에 트래픽이 빈번하게 발생하는 것을 확인할 수 있습니다.
다음으로 포드를 동일한 영역으로 이동하고 이점을 살펴봅니다.
고 트래픽 포드를 이동하여 영역 간 트래픽 비용 최소화
-
Cloud Shell로 돌아온 후 Ctrl + C를 눌러
ping명령어를 취소합니다. -
exit명령어를 입력하여pod-1의 셸을 종료합니다.
- 이 명령어를 실행하여
pod-2매니페스트를 편집합니다.
이는 동일한 로직을 사용하는 동안에도 포드 안티어피니티 규칙을 포드 어피니티 규칙으로 변경합니다. 이제 동일한 노드에서 pod-2가 pod-1로 예약됩니다.
- 현재 실행 중인
pod-2를 삭제합니다.
-
pod-2가 삭제되면 새로 편집된 매니페스트를 사용하여 다시 생성합니다.
내 진행 상황 확인하기를 클릭하여 위 작업을 올바르게 수행했는지 확인합니다.
- 만든 포드를 보고 둘 다
실행 중인지 확인합니다.
출력에서 이제 Pod-1 및 Pod-2가 동일한 노드에서 실행 중임을 확인할 수 있습니다.
pod-2의 IP 주소를 메모합니다. 이 IP 주소는 다음 명령어에서 사용됩니다.
- 셸을
pod-1컨테이너로 가져옵니다.
- 셸에서 [POD-2-IP]를 이전 명령어의
pod-2의 내부 IP로 바꾼 후 요청을pod-2로 보냅니다.
이제 이러한 포드 사이의 평균 핑 시간이 훨씬 빨라진 것을 알 수 있습니다.
이 시점에서 흐름 로그 BigQuery 데이터 세트로 돌아가서 최근 로그를 확인하여 원하지 않는 영역 간 통신이 더 이상 없는지 확인할 수 있습니다.
비용 분석
Google Cloud 내 VM 간 이그레스 가격 책정을 살펴보세요.
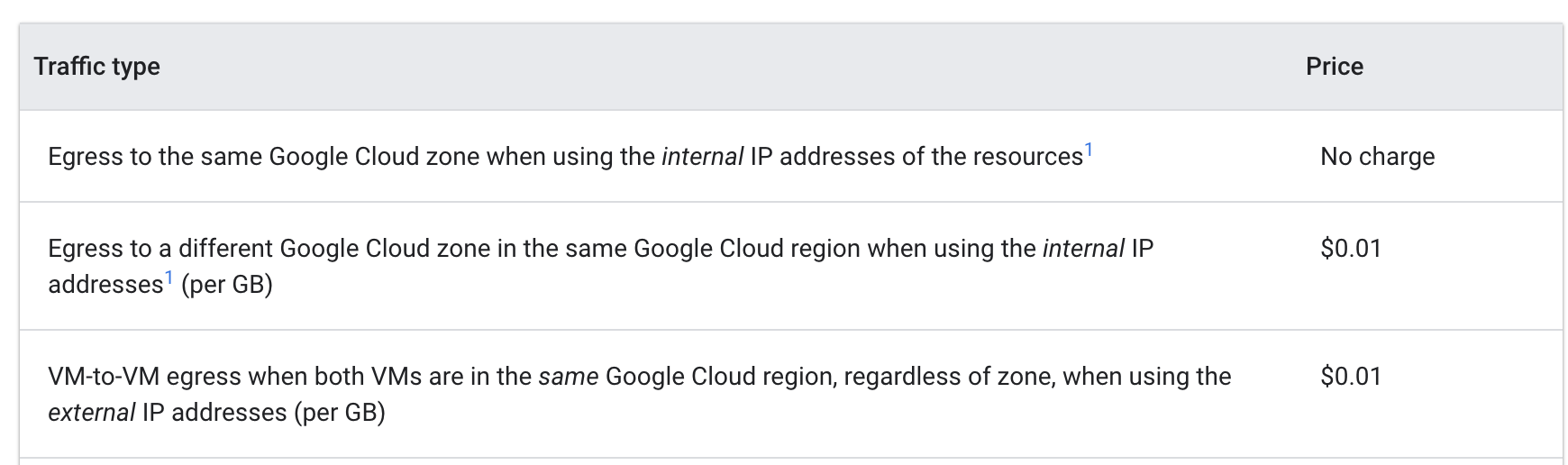
포드가 서로 다른 영역에서 서로 핑할 때 비용은 GB당 $0.01였습니다. 얼마 안 되는 비용처럼 보이지만 여러 서비스가 영역 간에 자주 호출하는 대규모 클러스터에서는 비용이 매우 빠르게 늘어날 수 있습니다.
포드를 동일한 영역으로 이동하면 핑이 무료입니다.
수고하셨습니다
GKE 클러스터의 일부인 가상 머신의 비용 최적화를 살펴보았습니다. 먼저, 더 잘 맞는 머신 유형을 사용하여 워크로드를 노드 풀로 마이그레이션합니다. 그런 다음 다양한 리전의 장단점을 이해하고 마지막으로 리전 클러스터 내의 고 트래픽 포드를 통신 중인 포드와 항상 동일한 영역에 있도록 이동합니다.
이 실습에서는 GKE VM을 위한 비용 효과적인 도구와 전략을 소개했지만 가상 머신을 최적화하려면 먼저 애플리케이션과 필요를 이해해야 합니다. 실행할 워크로드 종류를 파악하고 애플리케이션의 필요를 예측하는 작업은 GKE 클러스터 기반 가상 머신에 가장 효과적인 위치와 머신 유형을 결정하는 데 거의 항상 영향을 줍니다.
클러스터 인프라를 효율적으로 활용하면 비용 최적화에 많은 도움이 됩니다.
다음 단계/더 학습하기
- 머신 유형 문서
- GKE에서 비용에 최적화된 Kubernetes 애플리케이션을 위한 권장사항: 올바른 머신 유형 선택
- GKE에서 비용에 최적화된 Kubernetes 애플리케이션을 위한 권장사항: 적합한 리전 선택
Google Cloud 교육 및 자격증
Google Cloud 기술을 최대한 활용하는 데 도움이 됩니다. Google 강의에는 빠른 습득과 지속적인 학습을 지원하는 기술적인 지식과 권장사항이 포함되어 있습니다. 기초에서 고급까지 수준별 학습을 제공하며 바쁜 일정에 알맞은 주문형, 실시간, 가상 옵션이 포함되어 있습니다. 인증은 Google Cloud 기술에 대한 역량과 전문성을 검증하고 입증하는 데 도움이 됩니다.
설명서 최종 업데이트: 2024년 4월 30일
실습 최종 테스트: 2024년 4월 30일
Copyright 2024 Google LLC All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.

