检查点
Scale Up Hello App
/ 30
Create node pool
/ 30
Managing a Regional Cluster
/ 20
Simulate Traffic
/ 20
探索 GKE 虚拟机的费用优化
GSP767

概览
Google Kubernetes Engine 集群的底层基础设施由节点(单个计算虚拟机实例)构成。本实验展示了集群基础设施优化如何助力节省费用,并为应用打造更高效的架构。
您将学习相关策略,为示例工作负载选择适当形式的机器类型,从而尽可能提高您宝贵的基础设施资源的利用率(并避免其利用率低下)。除了您使用的基础设施类型之外,基础设施的实际地理位置也会影响到费用。通过本练习,您将探索如何创建高成本效益的策略,从而管理可用性更高的区域级集群。
目标
在本实验中,您将学习如何完成以下操作:
- 检查部署的资源使用情况
- 为部署扩容
- 将工作负载迁移到使用经优化的机器类型的节点池
- 探索适合您的集群的位置选项
- 监控不同可用区中 Pod 之间的流日志
- 移动高流量 Pod 以尽可能降低跨可用区流量费用
设置和要求
点击“开始实验”按钮前的注意事项
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。我们会为您提供新的临时凭据,让您可以在实验规定的时间内用来登录和访问 Google Cloud。
为完成此实验,您需要:
- 能够使用标准的互联网浏览器(建议使用 Chrome 浏览器)。
- 完成实验的时间 - 请注意,实验开始后无法暂停。
如何开始实验并登录 Google Cloud 控制台
-
点击开始实验按钮。如果该实验需要付费,系统会打开一个弹出式窗口供您选择付款方式。左侧是实验详细信息面板,其中包含以下各项:
- 打开 Google Cloud 控制台按钮
- 剩余时间
- 进行该实验时必须使用的临时凭据
- 帮助您逐步完成本实验所需的其他信息(如果需要)
-
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示登录页面。
提示:请将这些标签页安排在不同的窗口中,并将它们并排显示。
注意:如果您看见选择账号对话框,请点击使用其他账号。 -
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
{{{user_0.username | "<用户名>"}}} 您也可以在实验详细信息面板中找到用户名。
-
点击下一步。
-
复制下面的密码,然后将其粘贴到欢迎对话框中。
{{{user_0.password | "<密码>"}}} 您也可以在实验详细信息面板中找到密码。
-
点击下一步。
重要提示:您必须使用实验提供的凭据。请勿使用您的 Google Cloud 账号凭据。 注意:在本次实验中使用您自己的 Google Cloud 账号可能会产生额外费用。 -
继续在后续页面中点击以完成相应操作:
- 接受条款及条件。
- 由于该账号为临时账号,请勿添加账号恢复选项或双重验证。
- 请勿注册免费试用。
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

本实验会生成一个小型集群供您使用。该集群需要大约 2-5 分钟完成配置。
在点击开始实验按钮后,如果您看到一条蓝色的正在配置资源消息,并带有一个加载圆圈,则表示您的集群仍未创建完毕。
在等待期间,您可以先行阅读后续说明和解释,但在配置完成之前,任何 shell 命令都无法执行。
任务 1. 了解节点的机器类型
总览
机器类型是虚拟机 (VM) 实例可用的虚拟化硬件资源的集合,包括系统内存大小、虚拟 CPU (vCPU) 的数量和永久性磁盘限制。系统会根据不同的工作负载按系列对机器类型进行分组和搭配。
为节点池选择机器类型时,通用机器类型通常可以为多种工作负载提供最佳性价比。通用机器类型包括 N 系列和 E2 系列:
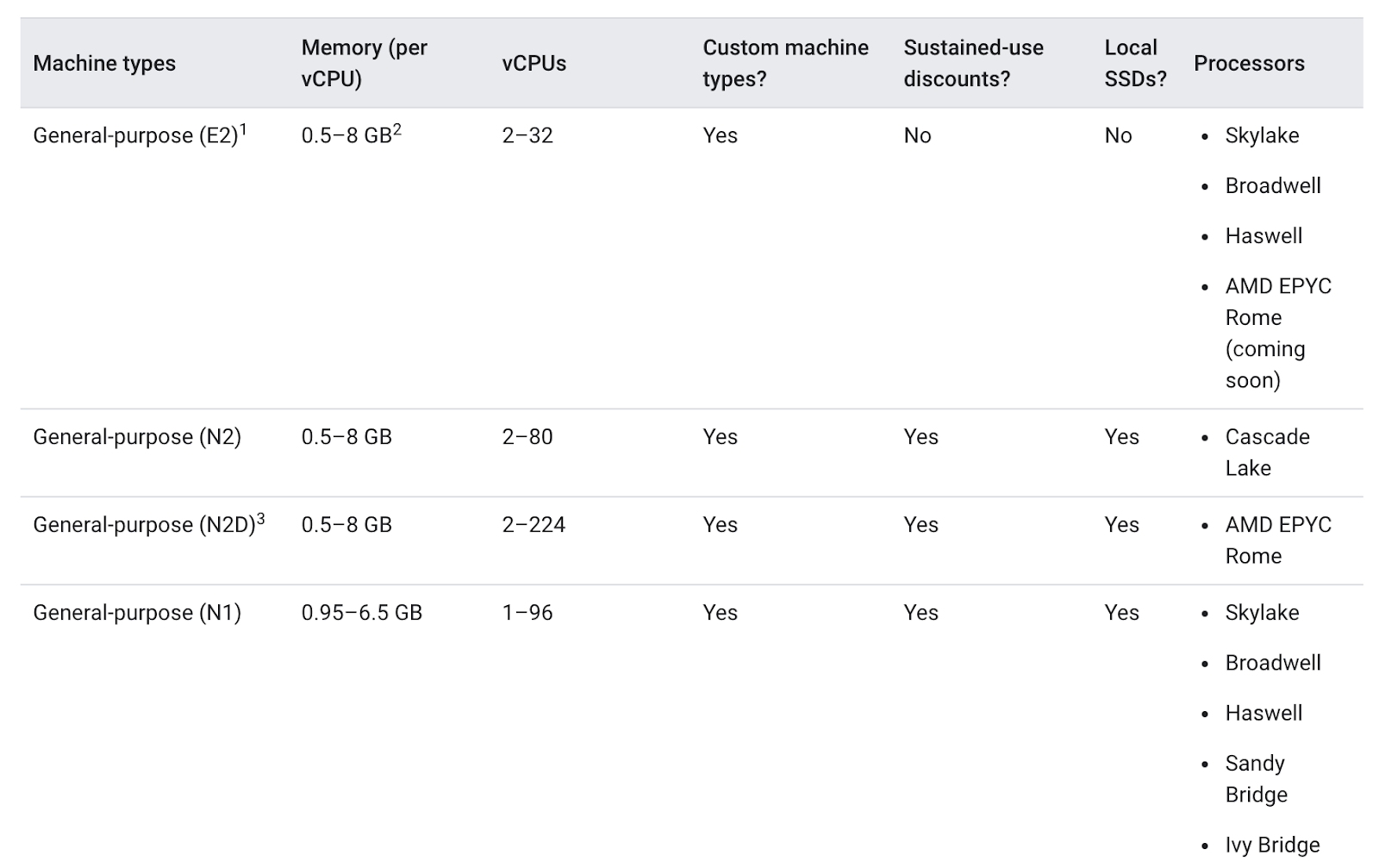
不同机器类型之间的差异或许对您的应用有益,也或许对您的应用无益。整体而言,E2 的性能与 N1 相似,但 E2 针对费用进行了优化。通常情况下,使用 E2 机器类型本身就有助于节省费用。
但对于集群而言,最重要的是根据应用的需求优化所使用的资源。对于需要大幅度扩容且规模较大的应用或部署,相较于将工作负载分散到大量通用机器中,将工作负载集中到少量经过优化的机器上可能更为经济。
为推进这一决策过程,了解应用的细节非常重要。如果您的应用有特定要求,您可以确保机器类型的形式适合应用。
在下面的部分中,您将查看一个演示版应用,并将其迁移到具有适当机器类型的节点池。
任务 2. 为 Hello 应用选择适当的机器类型
检查 Hello 演示集群的要求
在启动时,本实验会生成一个 Hello 演示集群,具有两个 E2-medium(2 个 vCPU,4GB 内存)节点。此集群部署一个名为 Hello App 的简单 Web 应用的副本、一个使用 Go 语言编写的 Web 服务器(以“Hello, World!”消息响应所有请求)。
- 实验配置完成后,在 Cloud 控制台中点击导航菜单,再点击 Kubernetes Engine。
-
在 Kubernetes 集群窗口中,选择您的 hello-demo-cluster。
-
在以下窗口中选择节点标签页:
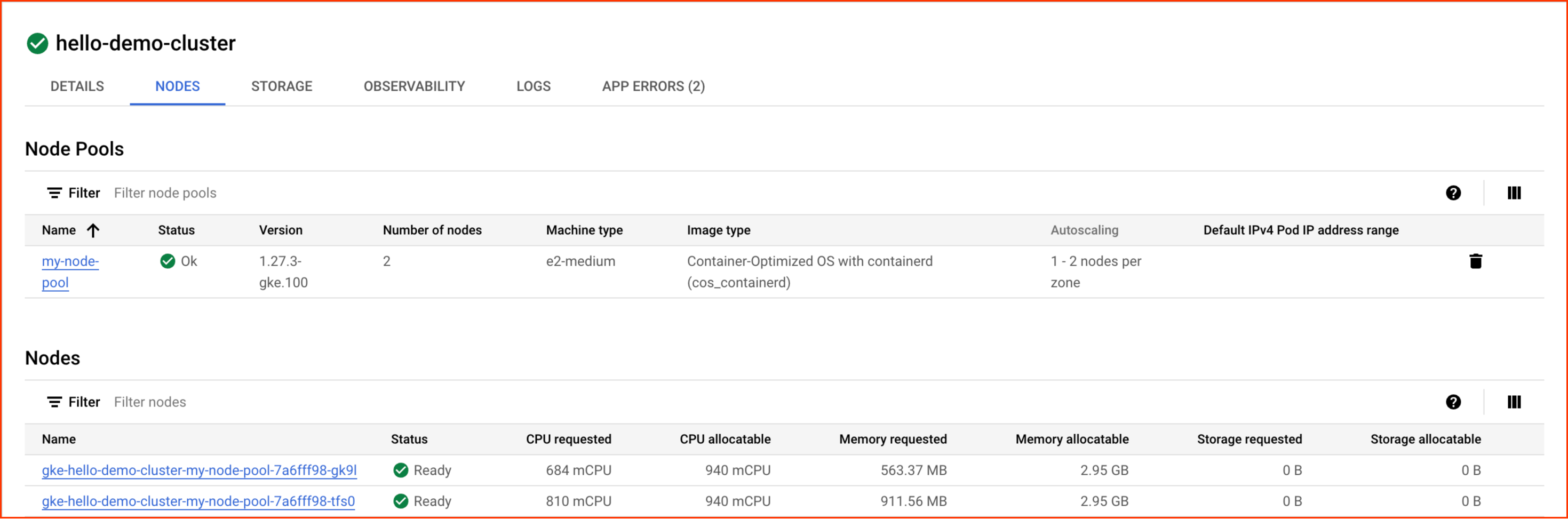
您现在应该会看到集群的节点列表:

观察 GKE 如何利用集群的资源。您可以看到各节点请求的 CPU 和内存量,以及您的节点可分配的资源量。
- 点击集群的第一个节点。
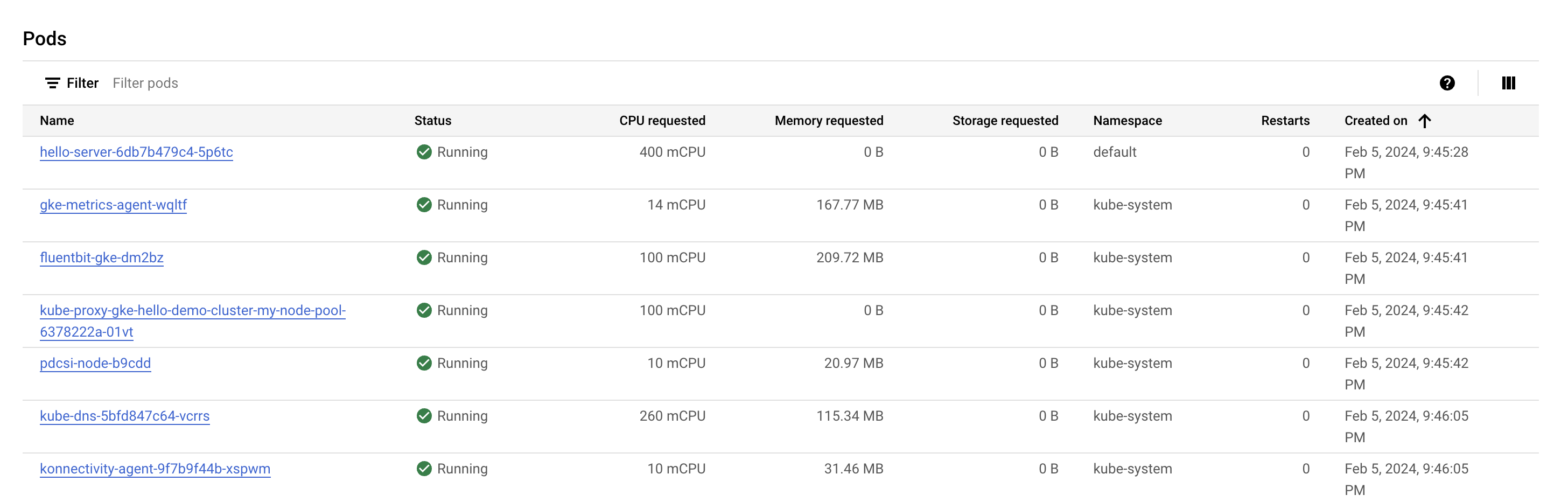
查看 Pod 部分。您应该会在 default 命名空间内看到 hello-server Pod。如果未看到 hello-server Pod,请返回并改为选择集群中的第二个节点。
您会注意到 hello-server Pod 请求 400 mcpu,此外还应该看到有其他一些 kube-system Pod 正在运行。加载这些 Pod 的目的是帮助启用 GKE 的集群服务,例如监控。
- 点击返回按钮,返回到前面的节点页面。
您会注意到,运行一个 Hello-App 副本及基本 kube-system 服务需要两个 E2-medium 节点。此外,您使用了集群的大部分 CPU 资源,但仅使用了大约三分之一的可分配内存。
如果此应用的工作负载完全是静态的,您可以创建一个具有自定义、适当形式的机器类型,提供能确切满足需求的 CPU 和内存量。这样后续即可节省整体集群基础设施的费用。
但 GKE 集群往往会运行多个工作负载,这些工作负载通常需要进行扩缩。
如果 Hello App 需要扩容,情况会怎样?
激活 Cloud Shell
Cloud Shell 是一种装有开发者工具的虚拟机。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行。Cloud Shell 提供可用于访问您的 Google Cloud 资源的命令行工具。
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell
。
如果您连接成功,即表示您已通过身份验证,且当前项目会被设为您的 PROJECT_ID 环境变量所指的项目。输出内容中有一行说明了此会话的 PROJECT_ID:
gcloud 是 Google Cloud 的命令行工具。它已预先安装在 Cloud Shell 上,且支持 Tab 自动补全功能。
- (可选)您可以通过此命令列出活跃账号名称:
-
点击授权。
-
现在,输出的内容应如下所示:
输出:
- (可选)您可以通过此命令列出项目 ID:
输出:
输出示例:
gcloud, in Google Cloud, refer to the gcloud CLI overview guide.
为 Hello App 扩容
- 访问集群的凭据:
- 为
Hello-Server扩容:
点击检查我的进度,验证您已完成上述任务。
- 返回到控制台,从左侧的 Kubernetes Engine 菜单中选择工作负载。
您可能会看到 hello-server 具有 Does not have minimum availability(不具备最低限度的可用性)错误状态。
- 点击错误消息以获取状态详情。您会看到,原因是
Insufficient cpu(CPU 不足)。
这符合预期。您或许还记得,该集群几乎没有多余的 CPU 资源,您通过 hello-server 的另外一个副本请求了另外 400m 的资源。
- 扩大节点池以处理新请求:
-
在系统提示您继续时,输入
y并按Enter键。 -
在控制台中,刷新工作负载页面,直至看到
hello-server工作负载的状态变为 OK(正常):

检查集群
在工作负载成功扩容之后,返回到集群的“节点”标签页。
- 点击 hello-demo-cluster:

- 随后点击节点标签页。
较大的节点池可以处理更繁重的工作负载,但应该观察基础设施资源的利用方式。
GKE 会尽可能使用集群的资源,但在这里仍有一定的优化空间。您可以看到,其中一个节点充分利用了内存,但有两个节点还有大量未得到利用的内存。
此时,如果您继续为应用程序扩容,那么就会开始看到类似的模式。Kubernetes 会尝试为 hello-server 部署的每个新副本查找一个节点,并在失败后使用大约 600m 的 CPU 资源创建一个新节点。
装箱问题
在装箱问题中,您必须将不同体积/形状的物品装入数量有限、形状规则的“箱子”(即容器)中。本质上来说,难点在于将物品装入最少数量的箱子中,尽可能高效地“打包”这些物品。
在尝试为 Kubernetes 集群运行的应用优化这些集群时,面临的挑战与此相似。您有许多应用,它们很可能有着不同的资源需求(即内存和 CPU 资源需求)。您必须尽可能高效地利用 Kubernetes 为您管理的基础设施资源(集群的大部分费用很可能来源于此),以容纳这些应用。
您的 Hello 演示集群使用的装箱方式不够高效。将 Kubernetes 配置为使用更适合此工作负载的机器类型要更具成本效益。
迁移到经过优化的节点池
- 创建使用更大的机器类型的新节点池:
点击检查我的进度,验证您已完成上述任务。
您现在可以按照以下步骤操作,将 Pod 迁移到新节点池:
-
封锁现有节点池:此操作会将现有节点池 (
node) 中的节点标记为不可调度。在您将其标记为无法调度之后,Kubernetes 会停止将新 Pod 调度到这些节点。 -
排空现有节点池:此操作会正常逐出正在现有节点池 (
node) 的节点上运行的工作负载。
- 首先,封锁原始节点池:
- 接下来,排空节点池:
此时应该会看到,您的 Pod 在新的 larger-pool 节点池上运行:
- 在 Pod 迁移完毕后,即可安全地删除旧节点池:
- 在系统提示您继续时,输入
y并按Enter键。
删除操作大约需要 2 分钟时间完成。在等待期间,您可以阅读下一部分内容。
费用分析
现在,您在一台 e2-standard-2 机器上运行之前需要三台 e2-medium 机器的同一个工作负载。
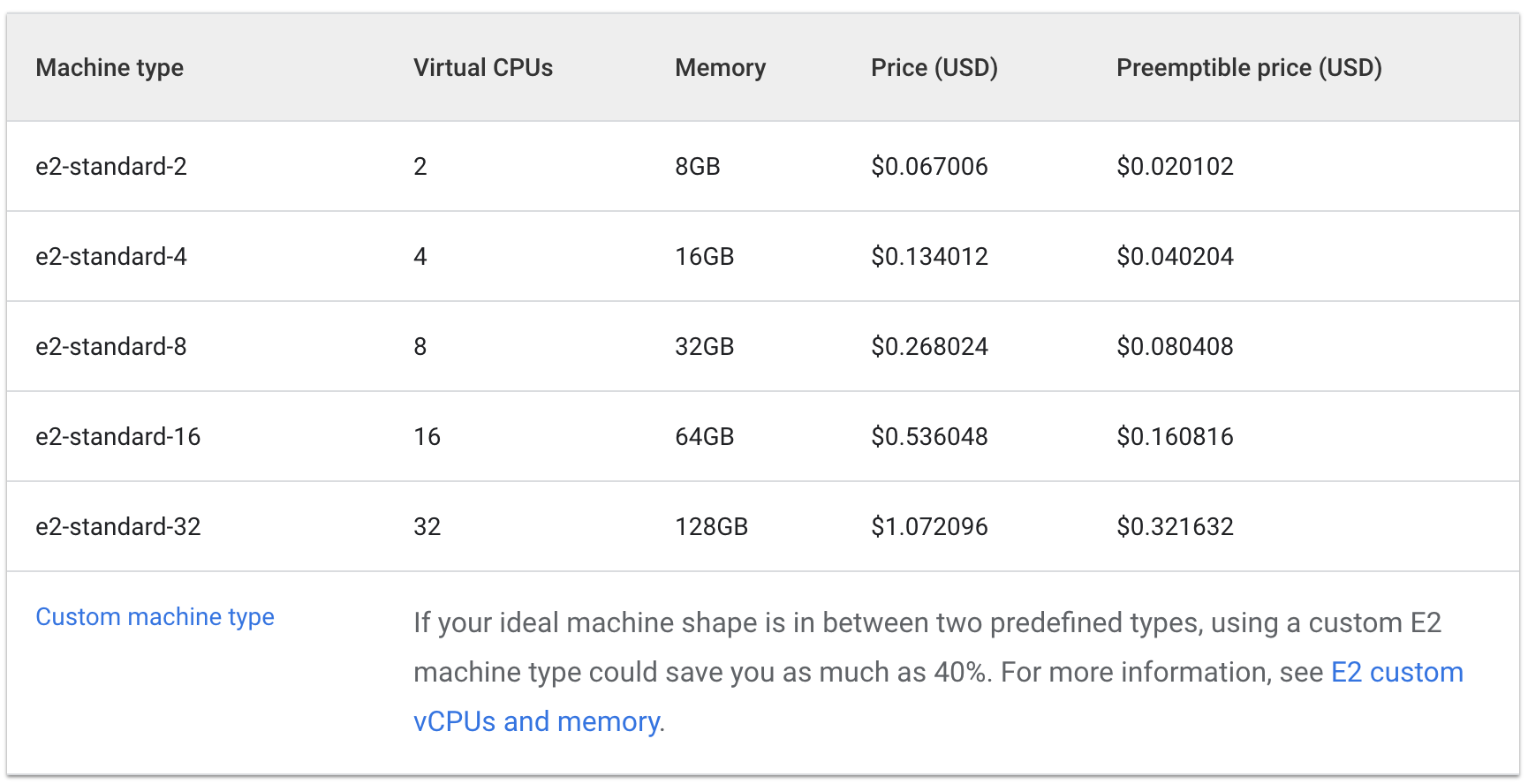
查看运行 e2 标准和共享核心机器类型的每小时费用:
标准:
共享核心:
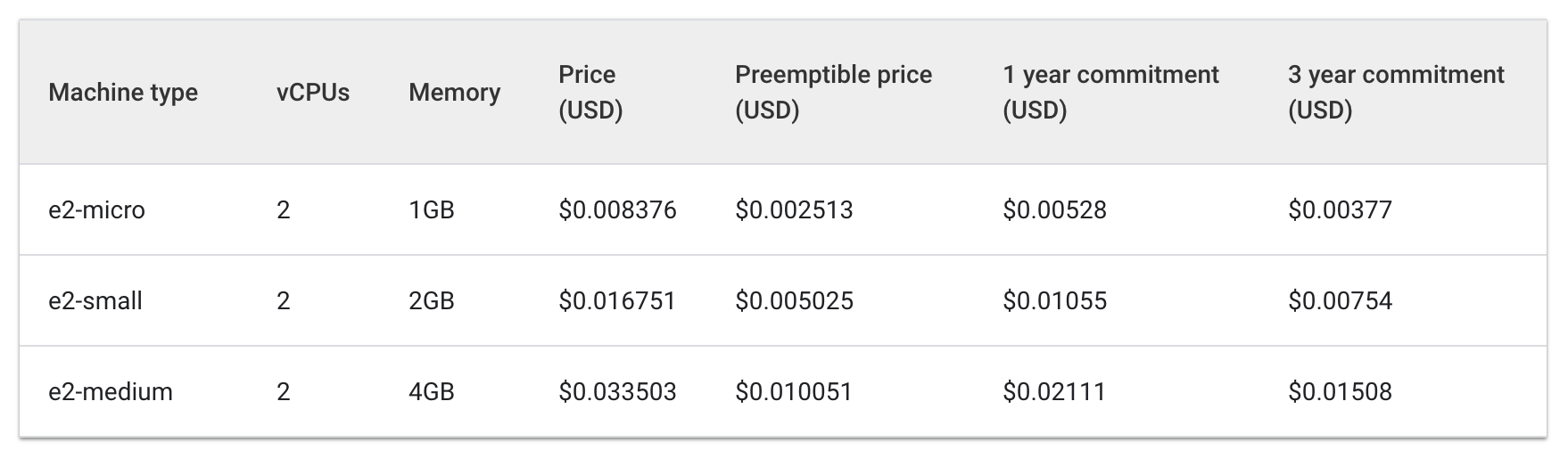
三台 e2-medium 机器的每小时费用大约是 0.1 美元,根据列表提供的信息,一台 e2-standard-2 机器的每小时费用大约是 0.067 美元。
每小时节省 0.04 美元的费用看似微不足道,但在运行应用的整个生命周期中,这样的费用可以积少成多。在规模较大时,节省下的费用也会更加可观。由于 e2-standard-2 机器可以更高效地容纳您的工作负载,未被利用的空间更少,扩容费用的增长速度更慢。
这值得关注,因为 E2-medium 是一种共享核心机器类型,旨在以出色的成本效益满足非资源密集型小型应用的需求。但对于 Hello-App 当前的工作负载,您可以看到,最终更具成本效益的策略是使用具有更大机器类型的节点池。
在 Cloud 控制台中,您应该仍然处于 hello-demo 集群的节点标签页中。刷新此标签页,检查您的 larger-pool 节点的请求的 CPU 和可分配的 CPU 字段。
请注意,此处仍然存在进一步优化的余地。新节点可容纳工作负载的另一个副本,而不需要配置另外一个节点。您也可以选择自定义大小的机器类型,恰到好处地满足应用的 CPU 和内存需求,从而节省更多资源。
应该注意,根据集群位置的不同,这些价格会有所不同。本实验的下一部分将介绍如何选择最合适的区域,以及如何管理区域级集群。
为集群选择适当的位置
区域和可用区概览
用于集群节点的 Compute Engine 资源托管在全球多个位置。这些位置由区域和可用区构成。区域是指某个地理位置,您可以在其中托管自己的资源。区域有三个或以上的可用区。
位于一个可用区内的资源(例如虚拟机实例或可用区级永久性磁盘)称为可用区级资源。静态外部 IP 地址等其他资源则是区域级资源。区域级资源可供该区域内的任何资源(无论位于哪个可用区)使用,而可用区级资源则只能由同一可用区内的其他资源使用。
选择区域或可用区时,务必考虑以下事项:
- 应对故障 - 如果您的应用所用的资源仅分布在一个可用区内,一旦该可用区不可用,您的应用也就无法使用。对于规模较大、要求严格的应用,最佳实践通常是将资源分布到多个可用区或区域之中,以应对故障。
- 减少网络延迟时间 - 为了减少网络延迟时间,您可能需要选择靠近您的服务点的区域或可用区。例如,如果您的客户大多位于美国东海岸,则可能需要选择靠近美国东海岸的主要区域和可用区。
集群最佳实践
区域之间的费用各异,具体取决于多种因素。例如,us-west2 区域中的资源往往比 us-central1 中的资源费用更高。
为集群选择区域或可用区时,应检查您的应用的功能。对于延迟时间敏感型生产环境,应将应用布置在网络延迟时间更短、效率更高的区域/可用区内,这有可能实现最佳性价比。
但在对延迟时间不敏感的开发环境中,则可以选择价格更低的区域,以节省费用。
处理集群可用性
GKE 中可用集群的类型包括:可用区级(单可用区或多可用区)集群和区域级集群。从表面来看,单可用区集群是价格最低的方案。但为保证应用的高可用性,最好将集群的基础设施资源分布到多个可用区之间。
在许多情况下,都应该通过多可用区级集群或区域级集群优先保证集群可用性,这能造就性价比最优的架构。
任务 3. 管理区域级集群
设置
跨多个可用区管理集群的资源要略微复杂一些。如果不够仔细,就有可能因 Pod 之间不必要的可用区间通信产生额外的费用。
在此部分中,我们将观察集群的网络流量,并将两个高流量 Pod(相互生成大量流量)移动到同一个可用区内。
- 在 Cloud Shell 标签页内,创建一个新的区域级集群(此命令需要几分钟时间才能完成):
为演示 Pod 之间与节点之间的流量,您要在区域级集群的不同节点上创建两个 Pod。我们将使用 ping 来生成从一个 Pod 传送到另一个 Pod 的流量,这是为了生成后续可以监控的流量。
- 运行以下命令,为您的第一个 Pod 创建清单:
- 在 Kubernetes 中使用以下命令创建第一个 Pod:
- 接下来,运行以下命令来为第二个 Pod 创建清单:
- 在 Kubernetes 中创建第二个 Pod:
点击检查我的进度,验证您已完成上述任务。
您创建的 Pod 使用 node-hello 容器,并在收到请求时输出一条 Hello Kubernetes 消息。
回顾您创建的 pod-2.yaml 文件,可以看到 Pod 反亲和性是一条既定规则。这可确保不会在与 pod-1 相同的节点上调度该 Pod。这是通过匹配基于 pod-1 security: demo 标签的表达式实现的。Pod 亲和性用于确保 Pod 在同一个节点上调度,而 Pod 反亲和性用于确保 Pod 不在同一个节点上调度。
在本例中,Pod 反亲和性用于帮助说明节点之间的流量,但巧妙使用 Pod 反亲和性和 Pod 亲和性可以帮您更好地利用区域级集群的资源。
- 查看您创建的 Pod:
返回内容中将包含两个 Pod,其状态均为正在运行,并显示了内部 IP。
示例输出如下:
记下 pod-2 的 IP 地址。您在后续命令中要用到它。
模拟流量
- 获取连接至
pod-1容器的 shell:
- 在您的 shell 中,向
pod-2发送请求,注意将 [POD-2-IP] 替换为之前显示的pod-2内部 IP:
记下从 pod-1 ping pod-2 的平均延迟时间。
检查流日志
在从 pod-1 ping pod-2 时,您可以在创建集群的 VPC 子集上启用流日志,以观测流量。
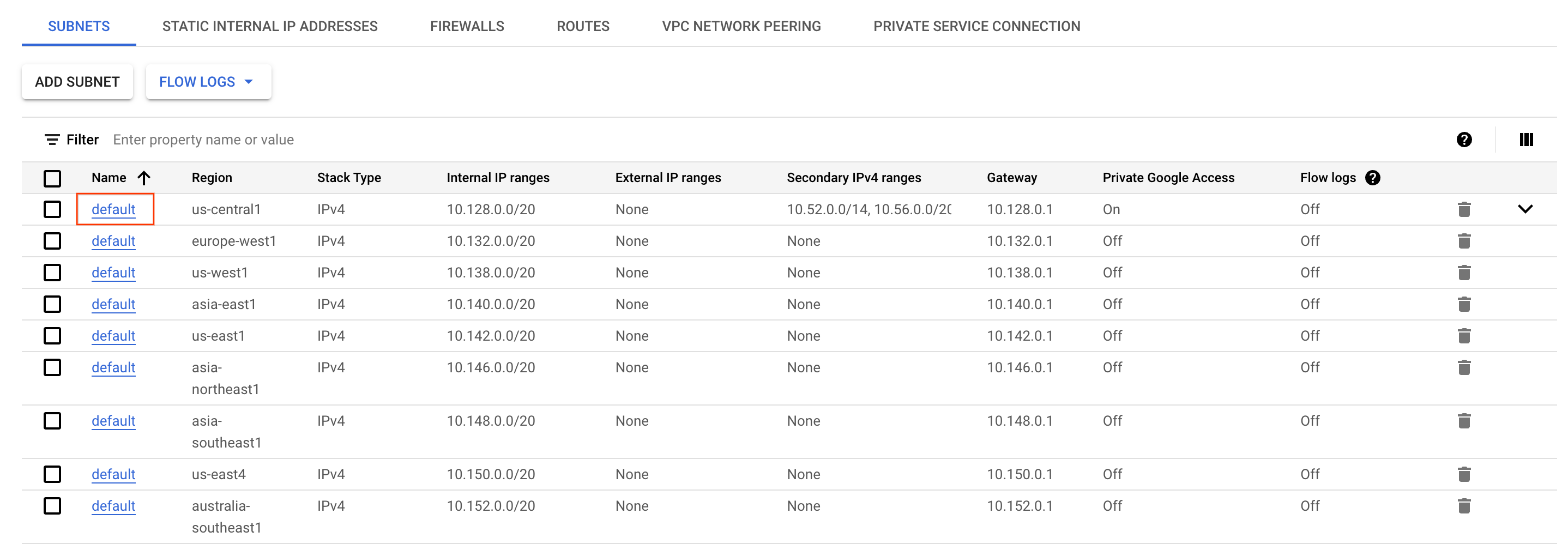
- 在 Cloud 控制台中打开导航菜单,在网络部分中选择 VPC 网络。
- 找到并点击
区域中的 default子网。
-
点击屏幕顶部的修改。
-
将流日志选择为启用。
-
然后点击保存。
-
接下来点击在 Logs Explorer 中查看流日志。

您现在会看到一个日志列表,每当通过您的某个实例发送或接收某些数据时,此处都会显示大量信息。
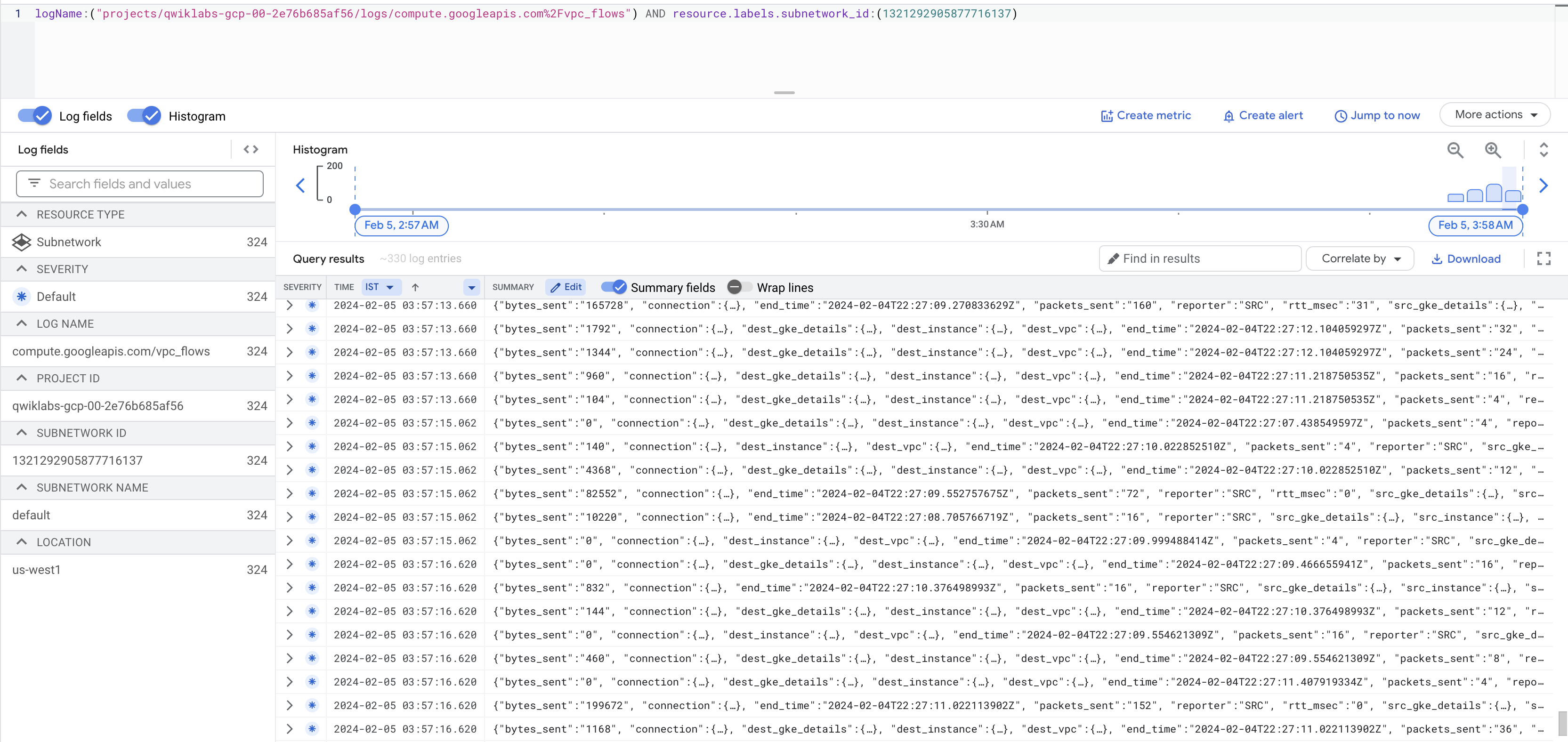
如果未生成日志,请将 vpc_flows 前面的 / 替换为 %2F,如上方屏幕截图所示。
这可能有些难以阅读。接下来将其导出到 BigQuery 表,这样即可查询相关信息。
- 点击更多操作 > 创建接收器。
-
将接收器命名为
FlowLogsSample。 -
点击下一步。
接收器目标位置
- 为您的接收器服务选择 BigQuery 数据集。
- 为您的 BigQuery 数据集选择新建 BigQuery 数据集。
- 将数据集命名为“us_flow_logs”,然后点击创建数据集。
其他所有选项均可保留原样。
-
点击创建接收器。
-
现在检查新创建的数据集。在 Cloud 控制台中,点击导航菜单的分析部分中的 BigQuery。
-
点击完成。
-
选择您的项目名称,再选择 us_flow_logs,即可查看新创建的表。如果未看到任何表,您可能需要刷新,直至其创建完毕。
-
点击您的
us_flow_logs数据集下的compute_googleapis_com_vpc_flows_xxx表。
-
点击查询 > 在新标签页中。
-
在 BigQuery 编辑器中,将此命令粘贴到
SELECT与FROM之间:
- 点击运行。
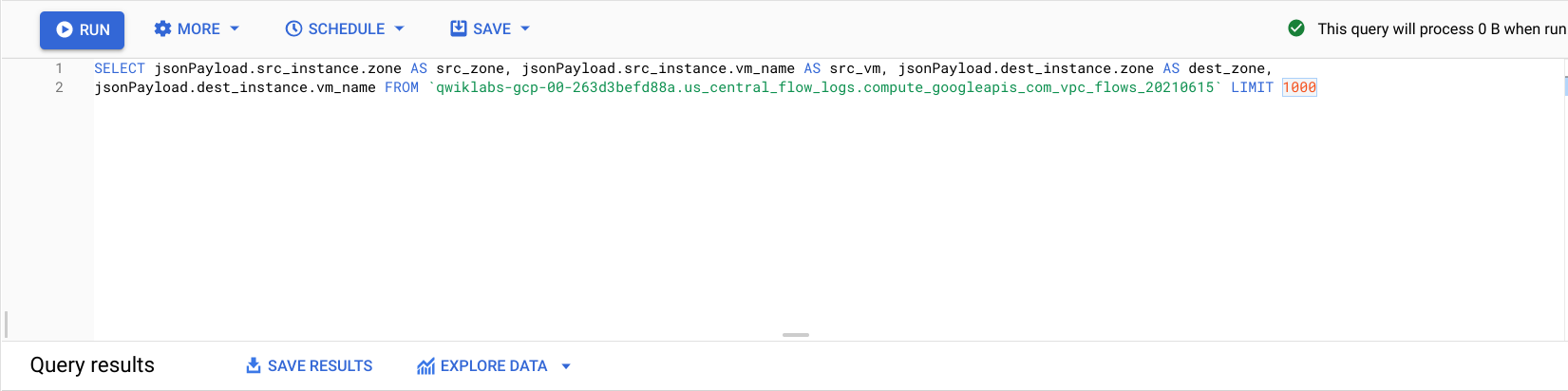
您会看到之前的流日志,但按照来源可用区、来源虚拟机、目标可用区和目标虚拟机进行了过滤。
找到表明在您的 regional-demo 集群的两个不同可用区之间进行了调用的几行日志。

观察流量日志,您会看到不同可用区之间存在频繁的流量。
接下来需要将 Pod 移动到同一个可用区内,并观察获益。
移动高流量 Pod 以尽可能降低跨可用区流量费用
-
返回 Cloud Shell,按 Ctrl + C 取消
ping命令。 -
输入
exit命令以退出pod-1的 shell:
- 运行以下命令以修改
pod-2清单:
这会将 Pod 反亲和性规则更改为 Pod 亲和性规则,并且依然使用相同的逻辑。现在,pod-2 将在与 pod-1 相同的节点上调度。
- 删除当前正在运行的
pod-2:
- 删除
pod-2之后,使用新修改的清单重新创建这个 Pod:
点击检查我的进度,验证您已完成上述任务。
- 查看您创建的 Pod,并确保其状态均为
正在运行:
从输出结果中,您可以看到 Pod-1 和 Pod-2 现在都在同一个节点上运行。
记下 pod-2 的 IP 地址。您在后续命令中要用到它。
- 获取连接至
pod-1容器的 shell:
- 在您的 shell 中,向
pod-2发送请求,注意将 [POD-2-IP] 替换先前记下的pod-2的内部 IP:
您可以注意到,这些 Pod 之间的平均 ping 时间比先前缩短了很多。
此时,您可以返回到流日志 BigQuery 数据集,并检查最新日志,验证没有更多不需要的可用区间通信。
费用分析
查看 Google Cloud 内虚拟机间的出站流量价格:
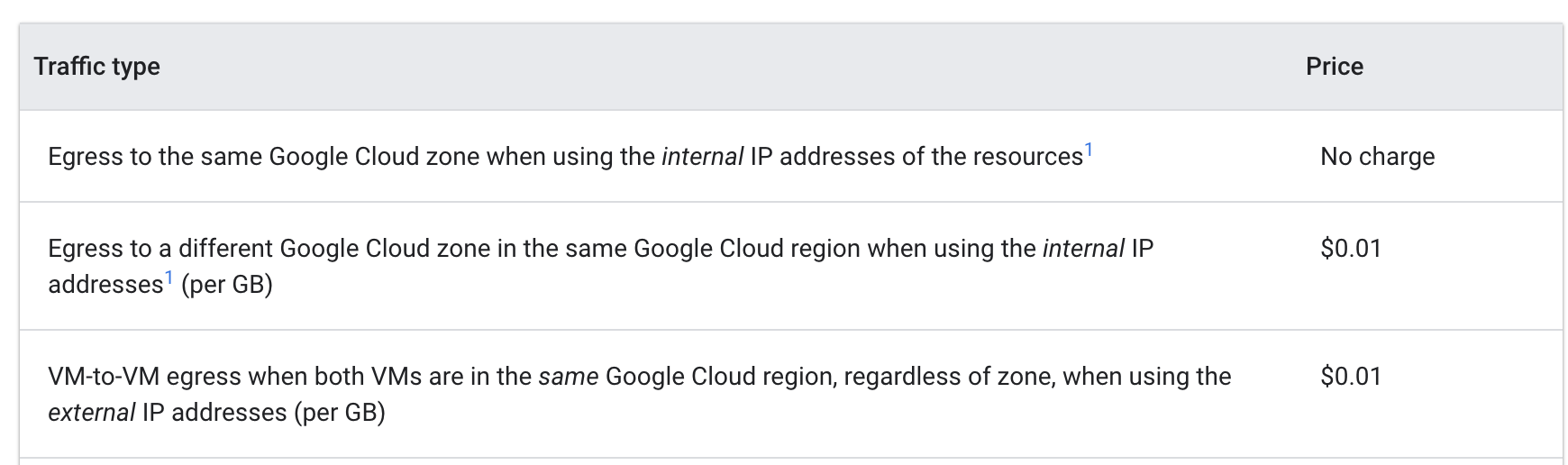
Pod 从不同可用区对彼此执行 ping 操作时,费用是每 GB 0.01 美元。虽然看似微不足道,但在有多个服务频繁在可用区之间进行调用的大规模集群中,这笔费用会迅速积少成多。
将 Pod 移动到同一个可用区之后,ping 就不会产生费用了。
恭喜!
您已经探索了 GKE 集群中的虚拟机的费用优化。首先,将工作负载迁移到具有更合适的机器类型的节点池。随后是认识不同区域的优缺点。最后是移动一个区域级集群中的高流量 Pod,使其始终与作为通信对象的 Pod 位于同一个可用区内。
本实验为您展示了适用于 GKE 虚拟机且成本效益出众的工具和策略,但要优化虚拟机,您首先需要了解自己的应用及其需求。在确定 GKE 集群基础虚拟机的最有效位置和机器类型时,应该了解您将运行哪些种类的工作负载,并预估应用的要求,这几乎总是会影响到您的决策。
有效利用集群的基础设施对费用优化有着极大的助益。
后续步骤/了解详情
Google Cloud 培训和认证
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
上次更新手册的时间:2024 年 4 月 30 日
上次测试实验的时间:2024 年 4 月 30 日
版权所有 2024 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。

