检查点
Scale Up Hello App
/ 30
Create node pool
/ 30
Managing a Regional Cluster
/ 20
Simulate Traffic
/ 20
探索如何讓 GKE 虛擬機器發揮最佳成本效益
GSP767

總覽
Google Kubernetes Engine 叢集的底層基礎架構是由一個個 Compute VM 執行個體的節點組成。本實驗室將說明如何藉由最佳化叢集基礎架構來節省成本,讓應用程式採用更有效率的架構。
您將瞭解如何選擇適當配置的機型來處理樣本工作負載,最大化利用寶貴的基礎架構資源,避免資源利用率過低的問題。除了您使用的基礎架構類型外,基礎架構的實際地理位置也會影響成本。透過這項練習,您將探索如何制定經濟實惠的高可用性區域叢集管理策略。
目標
本實驗室的學習內容包括:
- 檢視 Deployment 的資源使用情形
- 向上擴充 Deployment
- 將工作負載遷移至使用最佳機型的節點集區
- 瞭解各種叢集位置選擇
- 監控位於不同可用區的 Pod 之間的流量記錄
- 移動高流量的 Pod,有效降低跨可用區傳輸流量的成本
設定和需求
點選「Start Lab」按鈕前的須知事項
請詳閱以下操作說明。研究室活動會計時,而且中途無法暫停。點選「Start Lab」 後就會開始計時,讓您瞭解有多少時間可以使用 Google Cloud 資源。
您將在真正的雲端環境中完成實作研究室活動,而不是在模擬或示範環境。為達此目的,我們會提供新的暫時憑證,讓您用來在研究室活動期間登入及存取 Google Cloud。
如要完成這個研究室活動,請先確認:
- 您可以使用標準的網際網路瀏覽器 (Chrome 瀏覽器為佳)。
- 是時候完成研究室活動了!別忘了,活動一開始將無法暫停。
如何開始研究室及登入 Google Cloud 控制台
-
按一下「Start Lab」(開始研究室) 按鈕。如果研究室會產生費用,畫面中會出現選擇付款方式的彈出式視窗。左側的「Lab Details」窗格會顯示下列項目:
- 「Open Google Cloud console」按鈕
- 剩餘時間
- 必須在這個研究室中使用的暫時憑證
- 完成這個實驗室所需的其他資訊 (如有)
-
點選「Open Google Cloud console」;如果使用 Chrome 瀏覽器,也能按一下滑鼠右鍵,然後選取「在無痕式視窗中開啟連結」。
接著,實驗室會啟動相關資源並開啟另一個分頁,當中顯示「登入」頁面。
提示:您可以在不同的視窗中並排開啟分頁。
注意:如果頁面中顯示「選擇帳戶」對話方塊,請點選「使用其他帳戶」。 -
如有必要,請將下方的 Username 貼到「登入」對話方塊。
{{{user_0.username | "Username"}}} 您也可以在「Lab Details」窗格找到 Username。
-
點選「下一步」。
-
複製下方的 Password,並貼到「歡迎使用」對話方塊。
{{{user_0.password | "Password"}}} 您也可以在「Lab Details」窗格找到 Password。
-
點選「下一步」。
重要事項:請務必使用實驗室提供的憑證,而非自己的 Google Cloud 帳戶憑證。 注意:如果使用自己的 Google Cloud 帳戶來進行這個實驗室,可能會產生額外費用。 -
按過後續的所有頁面:
- 接受條款及細則。
- 由於這是臨時帳戶,請勿新增救援選項或雙重驗證機制。
- 請勿申請免費試用。
Google Cloud 控制台稍後會在這個分頁開啟。

本實驗室會為您生成一個小型叢集,佈建時間大約 2 至 5 分鐘。
如果按下「Start Lab」按鈕後看見藍色的 resources being provisioned 訊息和載入圈圈,代表您的叢集仍在建立中。
在等待期間,您可以閱讀後續的指示和說明,但是在資源佈建完成之前,您將無法執行任何指令。
工作 1:瞭解節點機型
一般總覽
機型是虛擬機器 (VM) 執行個體可以使用的一組虛擬化硬體資源,包括系統記憶體大小、虛擬 CPU (vCPU) 數量與永久磁碟容量限制。機型可依工作負載分為不同系列。
選擇節點集區的機型時,一般用途機型系列通常可提供滿足各種工作負載的最佳性價比。一般用途機型包含 N 系列和 E2 系列:
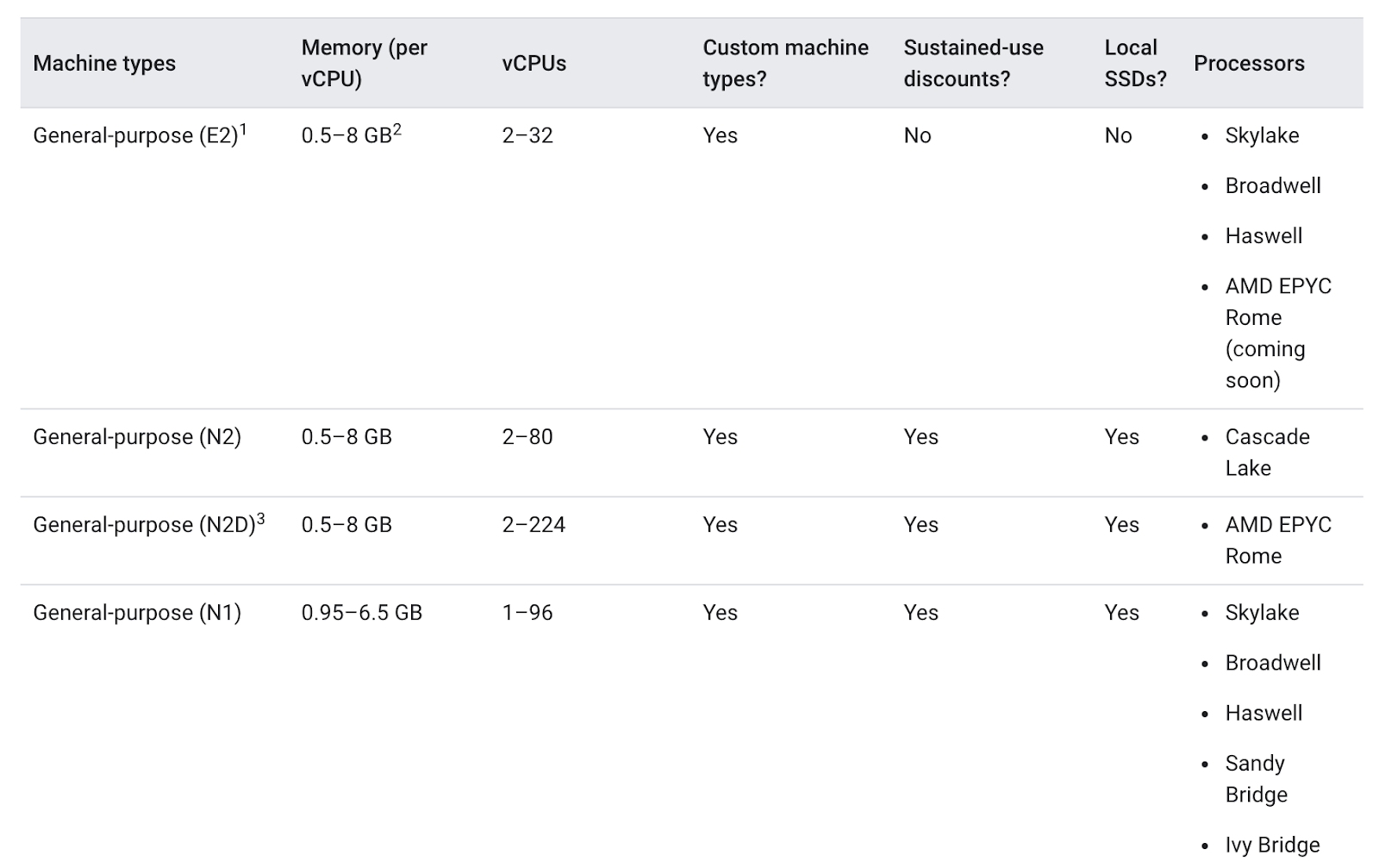
機型之間的差異不一定對應用程式有助益。一般而言,E2 和 N1 系列的效能類似,但前者經過成本最佳化。通常單獨使用 E2 機型比較能節省成本。
不過使用叢集時,最重要的是根據應用程式的需求充分利用資源。大型應用程式或 Deployment 因為需要大規模調度資源,所以將工作負載堆疊在少數最佳化機器上,會比分散在很多一般用途的機器上更經濟實惠。
您在做出這項決定時,一定要對應用程式有充分瞭解,因為這樣才能確保選出符合應用程式需求的機型。
在下一節中,您將看到示範應用程式,並將其遷移至配置合適機型的節點集區。
工作 2:選擇適合 Hello 應用程式的機型
檢視 Hello 示範叢集的需求
啟動時,實驗室已產生 Hello 示範叢集,其中包含兩個 E2 中型節點 (2 個 vCPU,4 GB 記憶體)。這個叢集正在針對名為 Hello App 的簡易網頁應用程式部署一項備用資源。此應用程式是用 Go 編寫的網路伺服器,會對所有要求回應「Hello, World!」訊息。
- 實驗室佈建完畢後,請在 Cloud 控制台中依序點選「導覽選單」和「Kubernetes Engine」。
-
在「Kubernetes 叢集」視窗中選取 hello-demo-cluster。
-
在後續視窗中選取「節點」分頁標籤:
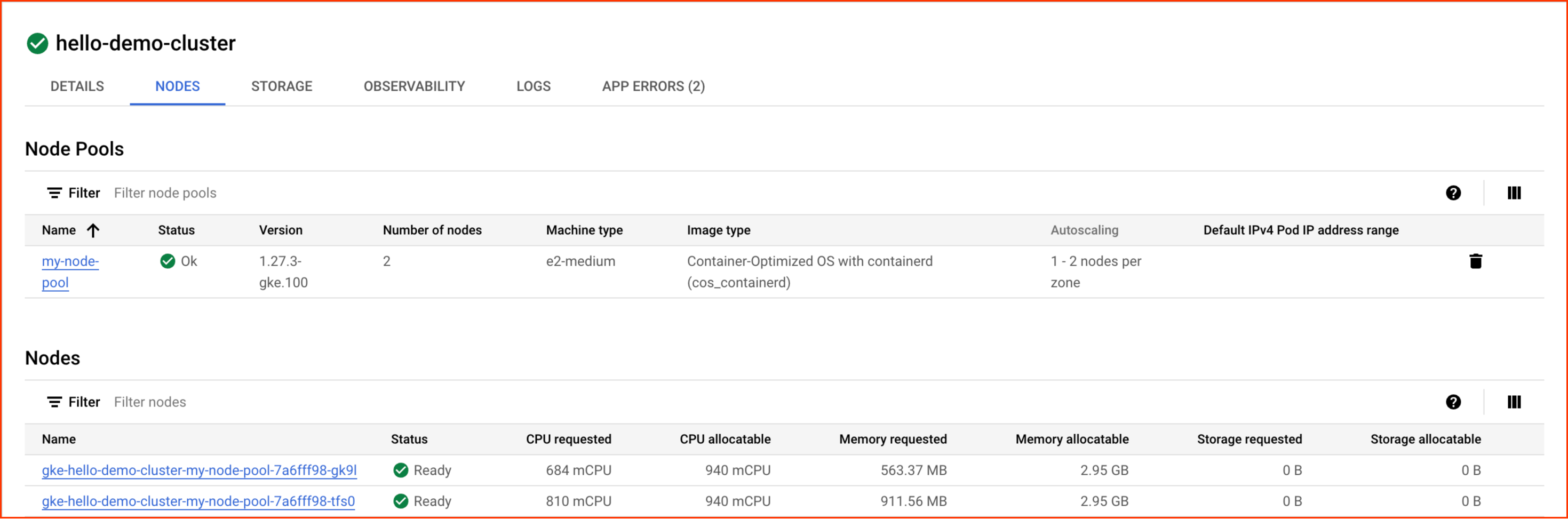
您應會看到自己的叢集節點清單。

請觀察 GKE 如何利用您的叢集資源。您可以查看每個節點要求了多少 CPU 和記憶體,以及節點能分配的資源量。
- 按一下叢集的第一個節點。
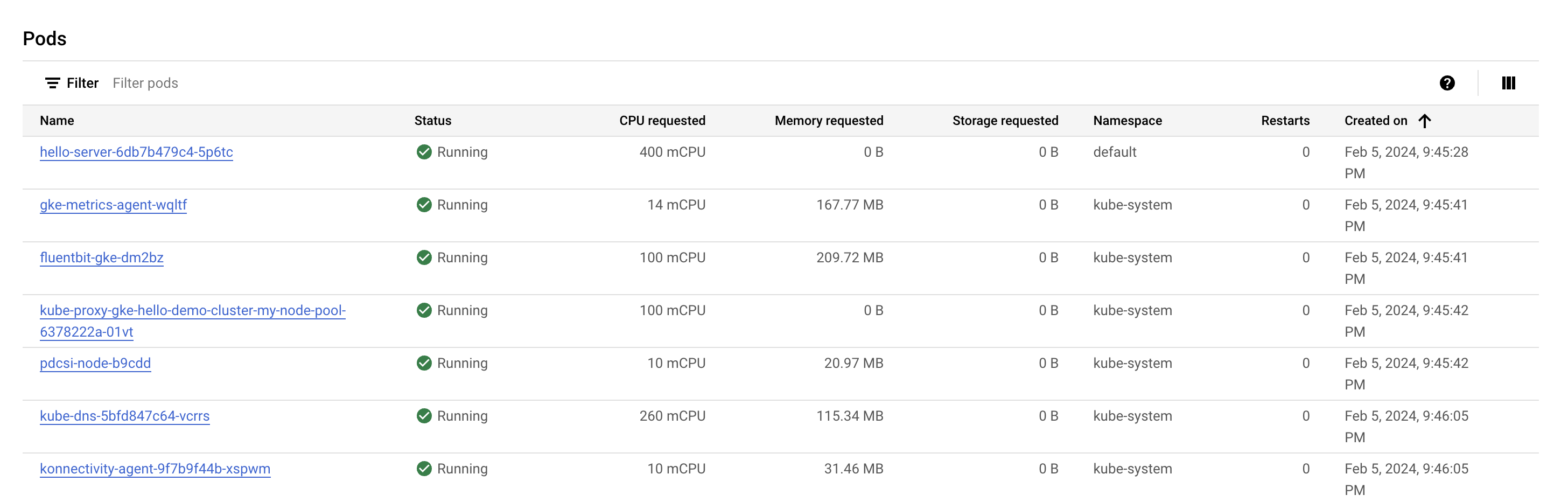
請查看「Pod」部分。您應該會在 default 命名空間中看到 hello-server Pod。如果找不到 hello-server Pod,請返回選取叢集的第二個節點。
您會發現 hello-server Pod 要求了 400 mCPU,另外還有一些 kube-system Pod 正在運作。這些 Pod 載入的目的是協助執行 GKE 的叢集服務,例如監控。
- 按下「返回」按鈕,回到原先的「節點」頁面。
如您所見,執行一項 Hello-App 備用資源和基本的 kube-system 服務時,需要兩個 E2-medium 節點。此外,儘管您已使用叢集中大部分的 CPU 資源,卻僅使用大約三分之一的記憶體配額。
如果這個應用程式的工作負載固定不變,您就能精確知道需要多少 CPU 和記憶體,建立完全符合這些需求的機型。如此一來,即可節省整個叢集基礎架構的成本。
不過,GKE 叢集通常會執行多個工作負載,這些工作負載一般需要配合需求擴充或縮減。
如果將 Hello 應用程式向上擴充,會怎麼樣?
啟動 Cloud Shell
Cloud Shell 是搭載多項開發工具的虛擬機器,提供永久的 5 GB 主目錄,而且在 Google Cloud 中運作。Cloud Shell 提供指令列存取權,方便您使用 Google Cloud 資源。
- 點按 Google Cloud 控制台上方的「啟用 Cloud Shell」圖示
。
連線完成即代表已通過驗證,且專案已設為您的 PROJECT_ID。輸出內容中有一行宣告本工作階段 PROJECT_ID 的文字:
gcloud 是 Google Cloud 的指令列工具,已預先安裝於 Cloud Shell,並支援 Tab 鍵自動完成功能。
- (選用) 您可以執行下列指令來列出使用中的帳戶:
-
點按「授權」。
-
輸出畫面應如下所示:
輸出內容:
- (選用) 您可以使用下列指令來列出專案 ID:
輸出內容:
輸出內容範例:
gcloud 的完整說明,請前往 Google Cloud 並參閱「gcloud CLI overview guide」(gcloud CLI 總覽指南)。
向上擴充 Hello 應用程式
- 存取您的叢集憑證:
- 向上擴充
Hello-Server:
點選「Check my progress」確認上述工作已完成。
- 返回控制台,從左側的「Kubernetes Engine」選單中選取「工作負載」。
您應會看到 hello-server 顯示「Does not have minimum availability」錯誤狀態
- 按一下錯誤訊息即可查看狀態詳細資料。您會看見錯誤原因是
Insufficient cpu。
這在預期之內。如前所述,叢集中幾乎沒有多餘的 CPU 資源,所以您已要求增加另一項 hello-server 備用資源,並額外增加 400m。
- 增加節點集區來應對新的要求:
-
系統提示您繼續操作時,請輸入
y並按下Enter鍵。 -
在控制台中重新整理「工作負載」頁面,直到
hello-server工作負載的狀態變成「正常」:

檢查您的叢集
成功向上擴充工作負載後,請返回叢集的「節點」分頁。
- 按一下 hello-demo-cluster:

- 接著點選「節點」分頁標籤。
節點集區越大,能處理的工作負載越重,但請注意基礎架構資源的使用情形。
雖然 GKE 會盡量充分利用叢集資源,但仍有改進空間。如您所見,其中一個節點使用了大部分的記憶體,但另外兩個節點還有大量未使用的記憶體。
這時若繼續向上擴充應用程式,就會開始看到類似情況。Kubernetes 會嘗試尋找節點來處理每項新的 hello-server Deployment 備用資源,如果找不到可用節點,則會建立 CPU 大約 600m 的新節點。
裝箱問題
所謂裝箱問題,是指將一些體積或形狀不同的物品,裝入一定數量、有規則形狀的「箱子」或容器中。解題目標是以最有效率的方式,將這些物品「裝箱」至最少數量的箱子中。
最佳化執行應用程式的 Kubernetes 叢集,實際上就是在解決類似的問題。假設您有多個應用程式,各有不同的資源需求 (例如記憶體和 CPU),那麼您要盡可能讓這些應用程式有效利用 Kubernetes 管理的基礎架構資源 (可能占叢集成本的大部分)。
您的 Hello 示範叢集未採用效率極高的裝箱方式。若能在 Kubernetes 中配置更適合這個工作負載的機型,會更經濟實惠。
遷移至最佳化節點集區
- 使用更大的機型建立新的節點集區:
點選「Check my progress」確認上述工作已完成。
現在,您可以依照下列步驟將 Pod 遷移至新的節點集區:
-
隔離現有節點集區:將現有節點集區 (
node) 中的節點標示為「不可排程」。這樣一來,Kubernetes 就會停止將新 Pod 安排至這些節點。 -
清空現有節點集區:正常清空在現有節點集區 (
node) 的節點上執行的工作負載。
- 首先,隔離原始節點集區:
- 接著清空集區:
這時,應該會看到 Pod 在名為 larger-pool 的新節點集區中運作:
- 遷移 Pod 後,即可放心刪除舊的節點集區:
- 系統提示您繼續操作時,請輸入
y和enter。
刪除作業大約需要 2 分鐘。等待時,您可以先閱讀下一節。
費用分析
您已將原本需要三部 e2-medium 機器處理的工作負載,改成用一部 e2-standard-2 機器處理。
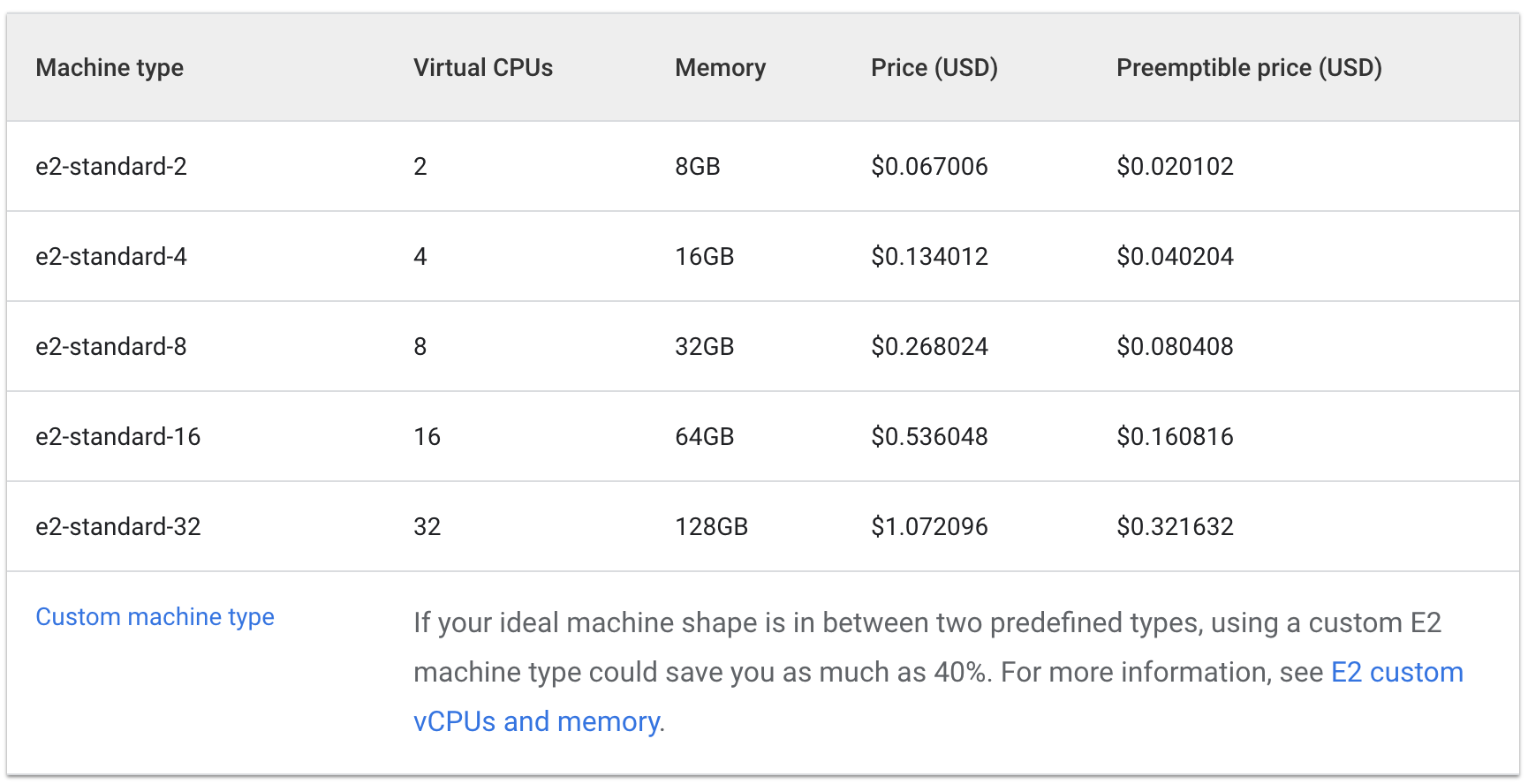
我們來看看使用 e2 標準和共用核心機型的每小時費用:
Standard:
Shared Core:
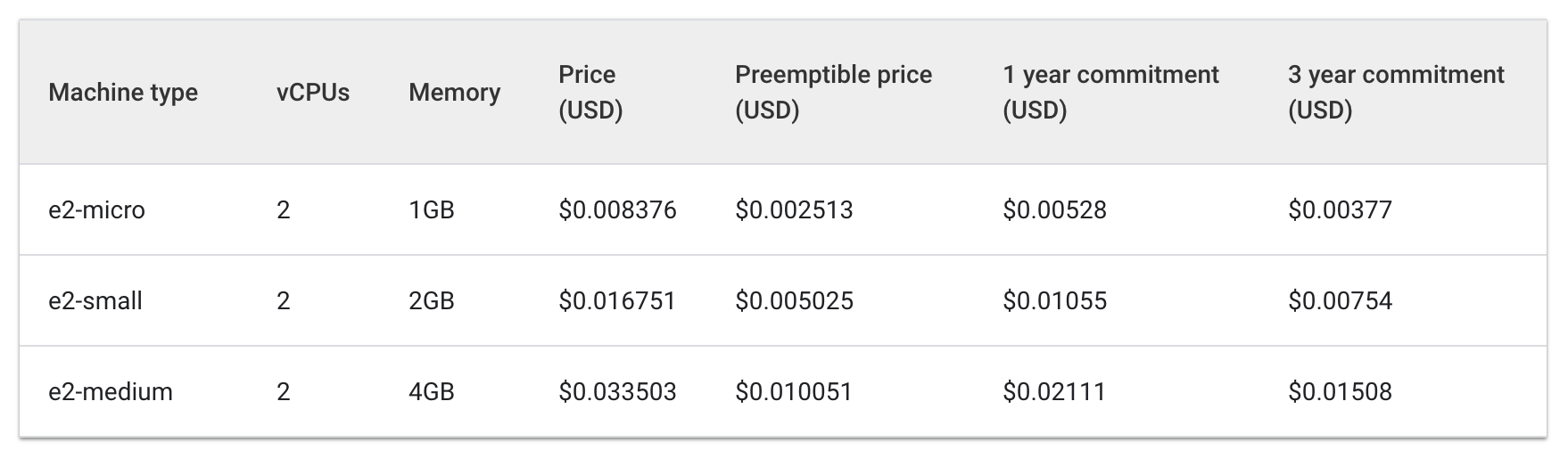
三部 e2-medium 機器每小時的費用約 $0.1 美元,一部 e2-standard-2 機器每小時的費用約 $0.067 美元。
每小時省下 $.04 美元看似微不足道,但在應用程式的整個生命週期中,這筆成本可能持續增加,逐漸累積成可觀費用。由於 e2-standard-2 機器可以更有效率地封裝工作負載,而且空間利用率更高,因此擴充成本增長速度較慢。
有趣的是,E2-medium 這種共用核心機型是出於經濟效益的考量,專門針對不需要大量資源的小型應用程式設計。然而,對於 Hello-App 目前的工作負載來說,使用機型較大的節點集區卻是更符合成本效益的策略。
在 Cloud 控制台中,您應該仍在 hello-demo 叢集的「節點」分頁上。請重新整理此分頁,檢視 larger-pool 節點的「已要求的 CPU」和「可分配的 CPU」欄位。
您會發現還有改進空間。新節點可以容納工作負載的另一項備用資源,省去佈建其他節點的需求。另外,您或許能根據應用程式需要的 CPU 和記憶體,選擇適合的自訂大小機型,進一步節省資源。
值得注意的是,這些價格將視您的叢集位置而異。在下一部分中,您將瞭解如何選擇最佳區域與管理區域叢集。
選擇合適的叢集位置
區域和可用區總覽
您的叢集節點使用的 Compute Engine 資源託管於全球多個據點,這些據點是由眾多區域和可用區構成。區域是您可以託管資源的特定地理位置,具有三個以上的可用區。
可用區中的資源,比如虛擬機器執行個體或可用區永久磁碟,都稱為可用區資源。靜態外部 IP 位址等其他資源,則為區域性資源。區域性資源可供所屬區域內的任何資源使用,不受可用區限制;可用區資源則只能由所屬可用區內的其他資源使用。
選擇區域或可用區時,請務必考慮下列事項:
- 應對故障情形 - 如果應用程式資源僅分配至單一可用區,當該可用區變得無法使用,應用程式也將無法使用。若應用程式規模較大並具高需求,通常最佳做法是將資源分配至多個可用區或區域,以便應對故障情形。
- 降低網路延遲時間 - 為降低網路延遲時間,建議選擇離您的服務點較近的區域或可用區。比如,若是您的顧客大部分位於美國東岸,那麼在挑選主要區域和可用區時,最好是選擇距離那裡較近的地方。
叢集最佳做法
區域成本差異取決於多種因素。比如,us-west2 區域的資源通常比 us-central1 的資源昂貴。
選擇叢集要使用的區域或可用區時,請考慮您的應用程式執行的操作。對於易受到延遲影響的正式環境,通常性價比最高的做法是將應用程式置於網路延遲時間較短、效率較高的區域/可用區。
另一方面,對於不太受延遲影響的開發環境,則可選擇成本較低的區域。
處理叢集可用性
GKE 中的可用叢集分為可用區叢集 (單一可用區或多可用區) 和區域叢集。從表面上看,單一可用區叢集是最便宜的選擇,但為了確保應用程式具備高可用性,最好將叢集的基礎架構資源分配至多個可用區。
很多情況下,採用多可用區叢集或區域叢集來優先確保可用性,可產生最佳性價比結構。
工作 3:管理區域叢集
設定
跨可用區管理叢集資源會稍微複雜一些。一不小心,就可能因為 Pod 之間出現不必要的跨可用區通訊,累積額外成本。
在這一節中,您將觀察叢集的網路流量,並將兩個互相帶來大量流量的高流量 Pod 移至同一可用區。
- 在「Cloud Shell」分頁中建立新的區域叢集 (這項指令需要幾分鐘完成):
為了展現 Pod 和節點之間的流量,您將在區域叢集中的不同節點上建立兩個 Pod。我們將使用 ping 產生從其中一個 Pod 到另一個 Pod 的流量,以便監控。
- 執行以下指令,建立第一個 Pod 的資訊清單:
- 使用以下指令,在 Kubernetes 中建立第一個 Pod:
- 接著執行以下指令,建立第二個 Pod 的資訊清單:
- 在 Kubernetes 中建立第二個 Pod:
點選「Check my progress」,確認上述工作已完成。
您建立的 Pod 會使用 node-hello 容器,並在收到要求時輸出 Hello Kubernetes 訊息。
如果回顧您建立的 pod-2.yaml 檔案,就會看到「Pod 反相依性」是一條定義規則。這可以確保此 Pod「不會」安排至與 pod-1 相同的節點上,因為規則會比對以 pod-1 的 security: demo 標籤為基礎的運算式。「Pod 相依性」規則可確保 Pod 「安排至同一節點」,「Pod 反相依性」規則可確保 Pod「不會安排至同一節點」。
這裡使用「Pod 反相依性」規則是為了呈現節點之間的流量,而您可以藉由靈活運用「Pod 反相依性」和「Pod 相依性」,更有效利用區域叢集資源。
- 查看您建立的 Pod:
您會看到這些傳回的 Pod 都顯示 Running 狀態和各自的內部 IP。
輸出範例:
請記下 pod-2 的 IP 位址,以備在後續指令中使用。
模擬流量
- 取得
pod-1容器的殼層:
- 在殼層中傳送要求至
pod-2,並將 [POD-2-IP] 替換成pod-2的內部 IP 位址:
請注意從 pod-1 到 pod-2 執行連線偵測 (ping) 的平均延遲時間。
檢查流量記錄
從 pod-1 對 pod-2 執行連線偵測 (ping) 時,您可以在建立叢集的虛擬私有雲子網路上啟用流量記錄,用於觀察流量。
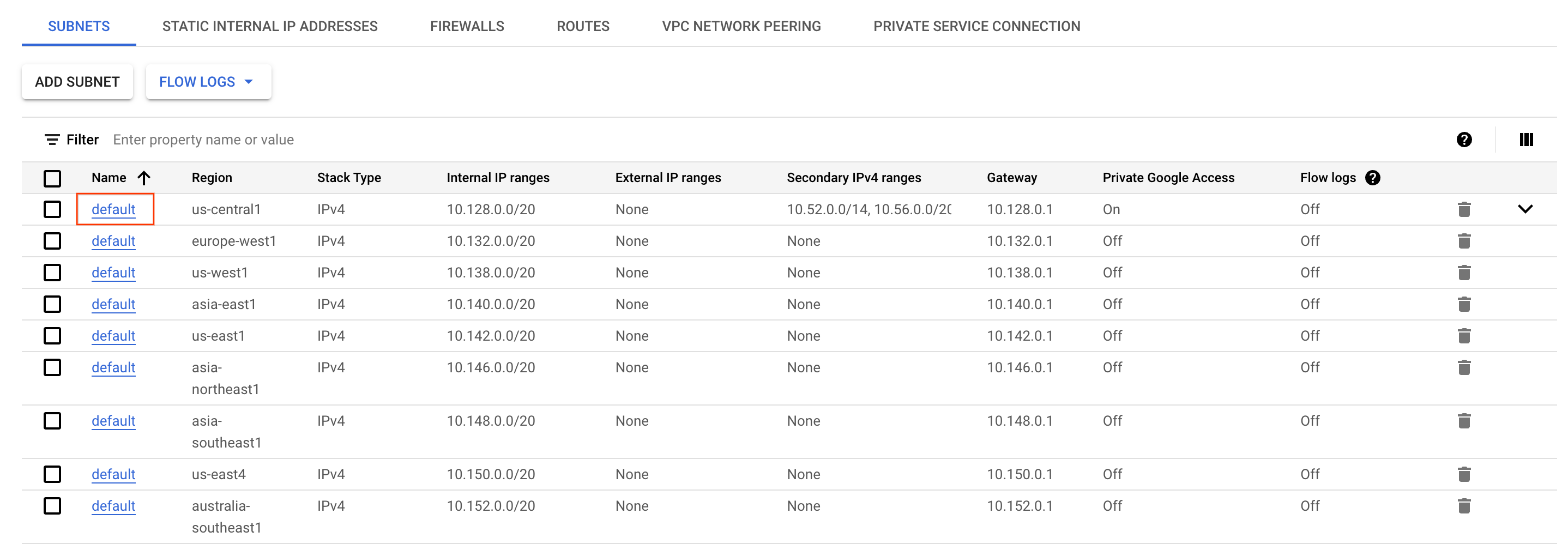
- 在 Cloud 控制台中開啟「導覽選單」,選取「網路」部分中的「虛擬私有雲網路」。
- 在
區域中找到並點選 default子網路。
-
按一下畫面頂端的「編輯」。
-
將「流量記錄」設為「開啟」。
-
點選「儲存」。
-
接著點選「在記錄檔探索工具查看流量記錄」。

您將看到一份記錄清單,列出您的任何執行個體每次收發內容時產生的大量資訊。
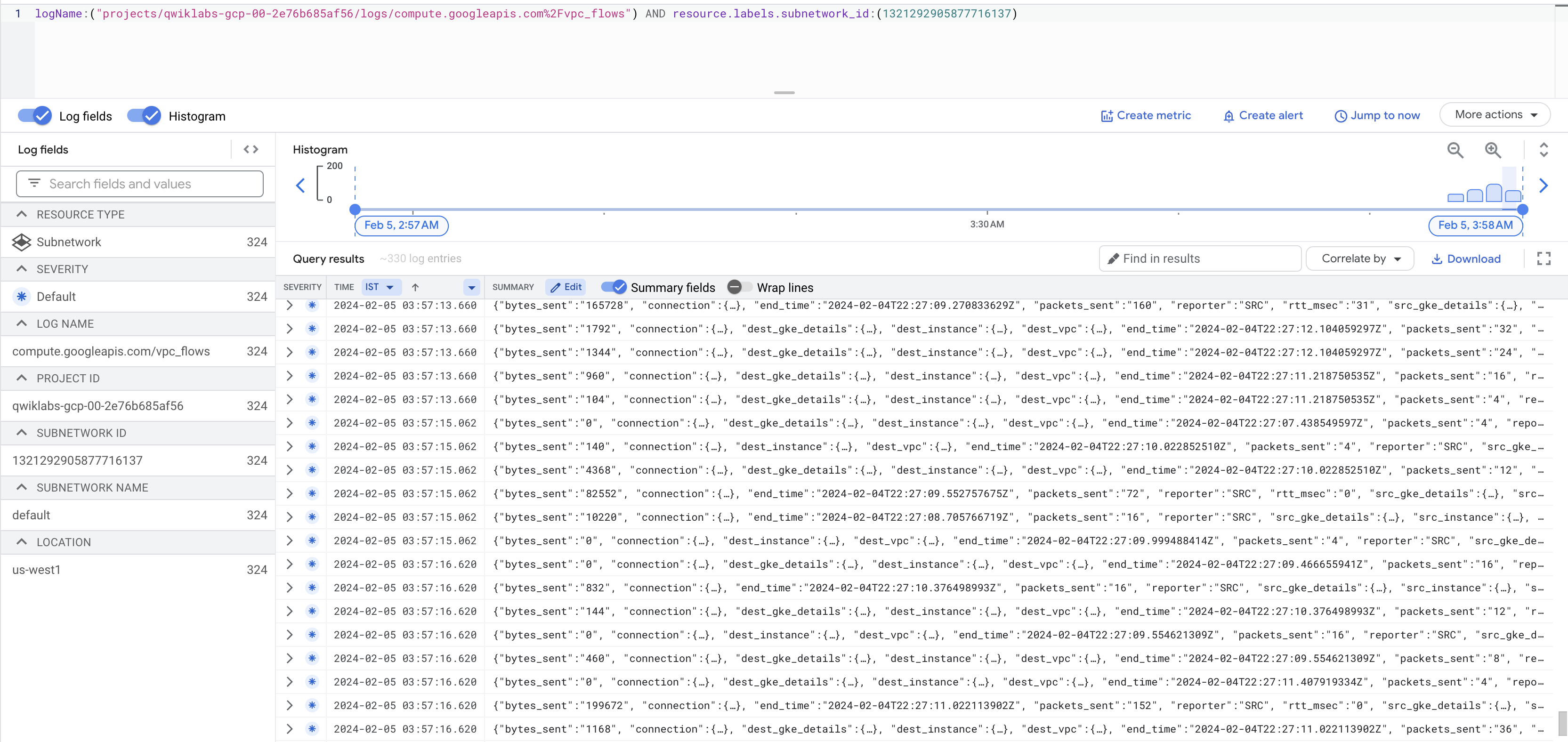
如未產生記錄,請將 vpc_flows 前面的 / 替換成 %2F,如上方螢幕截圖所示。
這可能不太容易辨識。接著,請匯出成 BigQuery 資料表,以便查詢相關資訊。
- 依序點選「更多動作」>「建立接收器」。
-
將接收器命名為
FlowLogsSample。 -
點選「下一步」。
接收器目的地位置
- 選擇將「接收器服務」設為「BigQuery 資料集」。
- 針對「BigQuery 資料集」,選取「建立新的 BigQuery 資料集」。
- 將資料集命名為「us_flow_logs」,按一下「建立資料集」。
其他設定可以保持不變。
-
按一下「建立接收器」。
-
接著檢查新建立的資料集。在 Cloud 控制台中點選「導覽選單」,然後在「數據分析」部分點選「BigQuery」。
-
點選「完成」。
-
選取您的專案名稱,接著選取「us_flow_logs」即可查看新建立的資料表。如果看不到任何資料表,可能需要重新整理幾次。
-
在
us_flow_logs資料集底下,點選compute_googleapis_com_vpc_flows_xxx資料表。
-
依序點選「查詢」>「在新分頁中開啟」。
-
在「BigQuery 編輯器」中,將以下內容貼到
SELECT和FROM之間:
- 按一下「執行」。
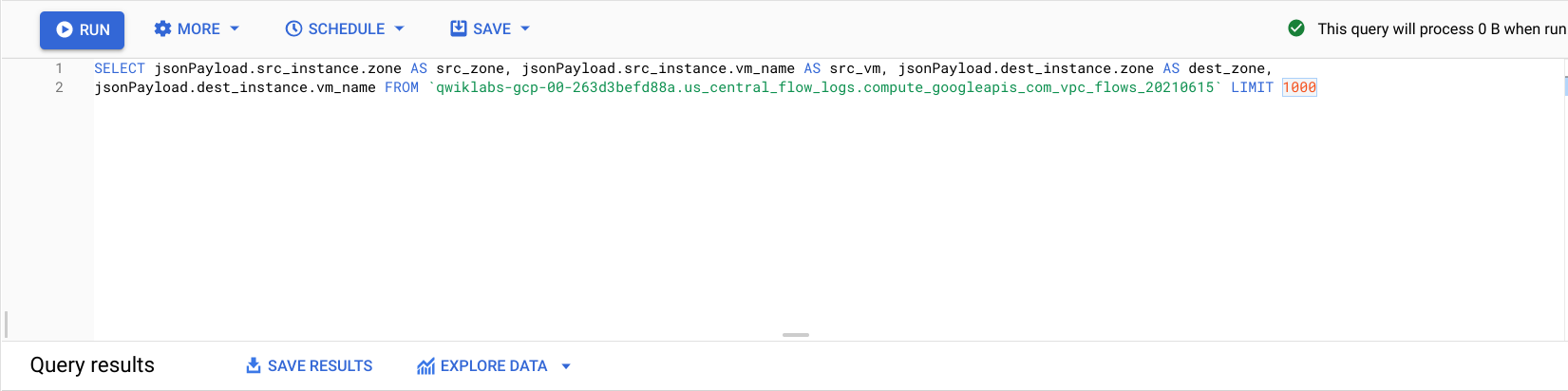
先前的流量記錄將根據 source zone、source vm、destination zone 和 destination vm 篩選列出。
找出顯示 regional-demo 叢集中的兩個可用區之間呼叫的資料列。

觀察流量記錄時,可以看到不同可用區之間經常有流量轉移。
接下來,您要將 Pod 移至同一可用區,觀察這有什麼好處。
移動高流量的 Pod,有效降低跨可用區傳輸流量的成本
-
返回「Cloud Shell」,按下 Ctrl + C 鍵以取消
ping指令。 -
輸入
exit指令以退出pod-1的殼層:
- 執行以下指令以編輯
pod-2資訊清單:
這會將 Pod Anti Affinity 規則改成 Pod Affinity 規則,但保留相同邏輯。也就是說,pod-2 將被安排在 pod-1 所用的節點上。
- 刪除目前執行的
pod-2:
-
pod-2刪除後,使用新編輯的資訊清單重新建立此 Pod:
點選「Check my progress」確認上述工作已完成。
- 查看已建立的 Pod,確認狀態皆為
Running:
在輸出內容中,可以看到 Pod-1 和 Pod-2 在同一節點上執行。
請記下 pod-2 的 IP 位址,以備在後續指令中使用。
- 取得
pod-1容器的殼層:
- 在殼層中傳送要求至
pod-2,並將 [POD-2-IP] 替換成先前指令中pod-2的內部 IP。
您會注意到,這些 Pod 之間的平均連線偵測 (ping) 時間比之前更短。
這時,您可以返回流量記錄的 BigQuery 資料集,檢查最近的記錄是否已經沒有不必要的跨可用區通訊。
費用分析
請參考 Google Cloud 內部 VM 之間的資料移轉定價:
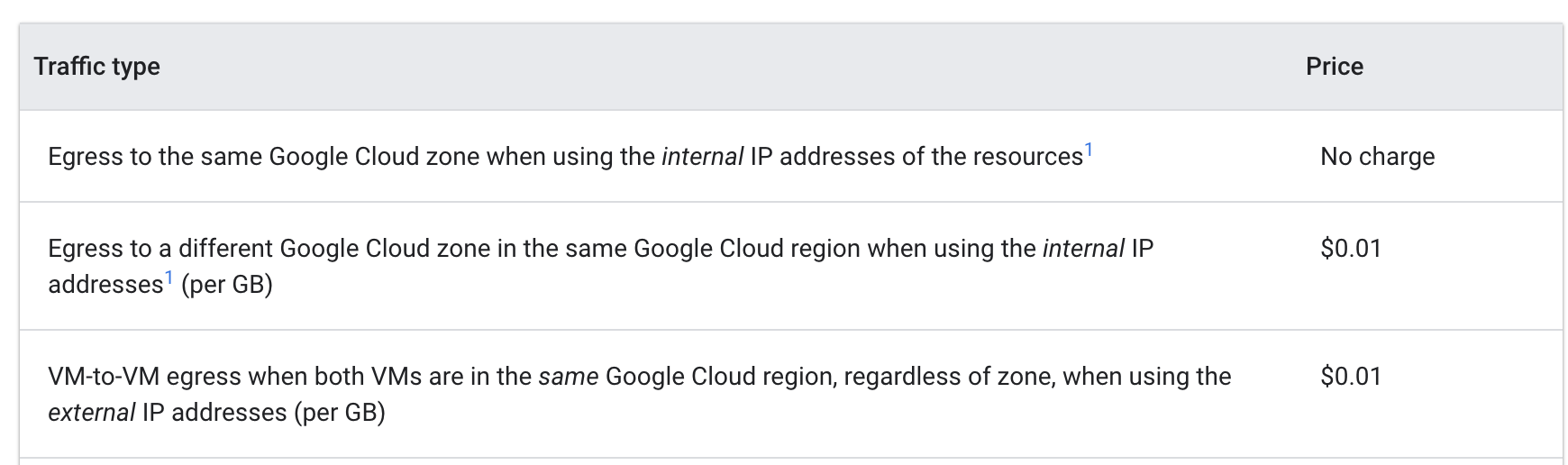
當不同可用區的 Pod 互相連線偵測 (ping) 時,每 GB 費用為 $0.01 美元。這筆費用看似微小,但是在多個服務經常跨可用區通訊的大規模叢集中,這些成本會迅速累積。
當您將 Pod 移至相同可用區後,執行連線偵測 (ping) 就不會再產生費用。
恭喜!
您已瞭解如何讓屬於 GKE 叢集的虛擬機器發揮最佳成本效益:首先是將工作負載遷移至配置合適機型的節點集區,接著是瞭解不同區域的優缺點,最後則是將區域叢集中的高流量 Pod 與相互通訊的 Pod 放在同一可用區。
在本實驗室中,我們已經介紹運用哪些工具和策略來配置 GKE 虛擬機器會更符合成本效益。不過,如果您想採用最佳的虛擬機器配置,仍然需要先瞭解自己的應用程式與相關需求。只要知道您將執行的工作負載類型,並估算應用程式的需求,即可在決定 GKE 叢集虛擬機器的位置與機型時,做出最經濟實惠的選擇。
有效利用叢集的基礎架構將大大有助於實現最佳成本效益。
後續行動/瞭解詳情
Google Cloud 教育訓練與認證
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2024 年 4 月 30 日
實驗室上次測試日期:2024 年 4 月 30 日
Copyright 2024 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。

