








Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Provision testing environment
/ 20
Scale pods with Horizontal Pod Autoscaling
/ 20
Scale size of pods with Vertical Pod Autoscaling
/ 20
Cluster autoscaler
/ 20
Node Auto Provisioning
/ 10
Optimize larger loads
/ 10
Die Google Kubernetes Engine bietet horizontale und vertikale Lösungen für die automatische Skalierung Ihrer Pods und Ihrer Infrastruktur. Wenn es um Kostenoptimierung geht, sind diese Tools äußerst nützlich, um sicherzustellen, dass Ihre Arbeitslasten so effizient wie möglich ausgeführt werden und dass Sie nur für das bezahlen, was Sie tatsächlich nutzen.
In diesem Lab werden horizontales Pod-Autoscaling und vertikales Pod-Autoscaling für die Skalierung auf Pod-Ebene sowie Cluster Autoscaler (horizontale Infrastrukturlösung) und automatische Knotenbereitstellung (vertikale Infrastrukturlösung) für Skalierung auf Knotenebene eingerichtet und beobachtet. Zuerst verwenden Sie diese Tools zur automatischen Skalierung, um so viele Ressourcen wie möglich einzusparen und die Größe Ihres Clusters in Zeiträumen mit weniger Nachfrage zu verringern. Dann werden Sie die Nachfrage Ihres Clusters erhöhen und beobachten, wie die automatische Skalierung die Verfügbarkeit aufrechterhält.
Aufgaben in diesem Lab:
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange die Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung selbst durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Pop-up-Fenster geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können. Auf der linken Seite befindet sich der Bereich Details zum Lab mit diesen Informationen:
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite Anmelden geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
Sie finden den Nutzernamen auch im Bereich Details zum Lab.
Klicken Sie auf Weiter.
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
Sie finden das Passwort auch im Bereich Details zum Lab.
Klicken Sie auf Weiter.
Klicken Sie sich durch die nachfolgenden Seiten:
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.

Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Mit Cloud Shell erhalten Sie Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen.
 .
.Wenn Sie verbunden sind, sind Sie bereits authentifiziert und das Projekt ist auf Ihre Project_ID,
gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
Ausgabe:
Ausgabe:
gcloud finden Sie in Google Cloud in der Übersicht zur gcloud CLI.
Um die horizontale Pod-Autoskalierung zu demonstrieren, verwendet dieses Lab ein benutzerdefiniertes Docker-Image, das auf dem php-apache Image basiert. Es definiert eine index.php Seite, die einige CPU-intensive Berechnungen durchführt. Sie überwachen das Deployment dieses Images.
php-apache Deployment:Klicken Sie auf Fortschritt prüfen.
Horizontales Pod-Autoscaling ändert die Form Ihrer Kubernetes-Arbeitslast, indem die Anzahl der Pods in Abhängigkeit von der CPU- oder Speicherauslastung der Arbeitslast automatisch erhöht oder verringert wird. Dies kann auch als Reaktion auf benutzerdefinierte Messwerte erfolgen, die innerhalb von Kubernetes gemeldet werden, oder als Reaktion auf externe Messwerte aus Quellen außerhalb Ihres Clusters.
Sie sollten jetzt das php-apache Deployment mit 3/3 ausgeführten Pods sehen:
php-apache Deployment an:Klicken Sie auf Fortschritt prüfen.
Mit diesem autoscale-Befehl wird ein horizontales Pod-Autoscaling konfiguriert, das zwischen 1 und 10 Replikate der Pods verwaltet, die von der php-apache Bereitstellung gesteuert werden. Der cpu-percent-Flag gibt 50 % als angestrebte durchschnittliche CPU-Auslastung der angeforderten CPU über alle Pods hinweg an. HPA passt die Anzahl der Replikate (über die Bereitstellung) an, um eine durchschnittliche CPU-Auslastung von 50 % über alle Pods hinweg aufrechtzuerhalten.
In der Spalte Ziele sollten Sie 1 %/50 % sehen.
Dies bedeutet, dass die Pods in Ihrem Deployment derzeit 1 % ihrer durchschnittlichen Ziel-CPU-Auslastung erreicht haben. Dies ist zu erwarten, da die Anwendung php-apache im Moment keinen Traffic erhält.
kubectl get hpa erneut aus. Ihr HPA hat bisher keine Bewertung erstellt. Beachten Sie auch die Spalte Replikate. Zu Beginn wird der Wert 3 verwendet. Diese Zahl wird beim Autoscaling geändert, wenn sich die Anzahl der benötigten Pods ändert.
In diesem Fall skaliert der Autoscaler das Deployment auf die minimale Anzahl von Pods herunter, die beim Ausführen des Befehls autoscale angegeben wird. Das horizontale Pod-Autoscaling dauert 5–10 Minuten und erfordert je nach Skalierungsrichtung das Herunterfahren oder Starten neuer Pods.
Fahren Sie mit dem nächsten Schritt des Labs fort. Sie werden die Ergebnisse des Autoscalings später überprüfen.
cpu-percent als Zielmesswert für Ihren Autoscaler verwenden, ermöglicht HPA die Definition benutzerdefinierter Messwerte, sodass Sie Ihre Pods auf der Grundlage anderer nützlicher Messwerte skalieren können, die in den Protokollen erfasst werden.Dank vertikalem Pod-Autoscaling müssen Sie sich keine Gedanken mehr über die Werte machen, die Sie für die CPU‑ und Speicheranforderungen eines Containers angeben. Das Autoscaling kann Werte für CPU‑ und Speicheranforderungen und Limits empfehlen oder die Werte automatisch aktualisieren.
Vertikales Pod-Autoscaling wurde bereits auf dem scaling-demo Cluster aktiviert.
Die Ausgabe sollte enabled: true sein.
gcloud container clusters update scaling-demo --enable-vertical-pod-autoscaling aktiviert werdenUm VPA zu demonstrieren, stellen Sie die Anwendung hello-server bereit.
hello-server auf Ihren Cluster an:hello-server-Pods zu überprüfen:Im obigen Beispiel wird ein vertikaler Pod-Autoscaler erstellt, der auf das Deployment hello-server mit einer Update-Richtlinie von Off abzielt. Ein VPA kann eine von drei verschiedenen Update-Richtlinien haben, die je nach Anwendung nützlich sein können:
hello-vpa an:VerticalPodAutoscaler auf:Suchen Sie am Ende der Ausgabe nach den „Container-Empfehlungen“. Wenn Sie diese nicht sehen, warten Sie noch etwas und führen Sie den vorherigen Befehl erneut aus. Sobald sie angezeigt werden, sehen Sie mehrere unterschiedliche Empfehlungstypen, jeweils mit Werten für CPU und Speicher:
Sie werden feststellen, dass der VPA empfiehlt, die CPU-Anforderung für diesen Container auf 25m anstelle der vorherigen 100m festzulegen und Ihnen außerdem einen Wert für die anzufordernde Speichermenge vorschlägt. An diesem Punkt können diese Empfehlungen manuell auf das hello-server-Deployment angewendet werden.
Um den VPA und seine Auswirkungen in diesem Lab zu beobachten, ändern Sie die hello-vpa-Update-Richtlinie auf Auto und beobachten die Skalierung.
Aktualisieren Sie das Manifest, um die Richtlinie auf Auto zu setzen und wenden Sie die Konfiguration an:
Um die Größe eines Pods zu ändern, muss der vertikale Pod-Autoscaler diesen Pod löschen und in der gewünschten Größe neu erstellen. Um Ausfallzeiten zu vermeiden, löscht der VPA standardmäßig nicht den letzten aktiven Pod und passt auch dessen Größe nicht an. Aus diesem Grund benötigen Sie mindestens zwei Replikate, um zu sehen, dass der VPA Änderungen vornimmt.
hello-server-Deployment auf zwei Replikate:hello-server-xxx-Pods im Status Wird beendet oder im Status Ausstehend sehen (oder gehen Sie zu Kubernetes Engine > Arbeitslasten):Dies ist ein Zeichen dafür, dass Ihr VPA Ihre Pods löscht und deren Größe ändert. Sobald Sie dies sehen, drücken Sie Strg + c, um den Befehl zu beenden.
Klicken Sie auf Fortschritt prüfen.
An diesem Punkt wird der horizontale Pod-Autoscaler wahrscheinlich Ihr php-apache-Deployment herunterskaliert haben.
php-apache-Deployment auf 1 Pod herunterskaliert wurde.php-apache-Deployment sehen, warten Sie noch ein paar Minuten, bis der Autoscaler aktiv wird.php-apache bei einer höheren Nachfrage wieder skalieren, um die Last zu bewältigen.Dies ist besonders mit Blick auf Kostenoptimierung äußerst nützlich. Ein gut abgestimmter Autoscaler bedeutet, dass Ihre Anwendung hochgradig verfügbar bleibt, und Sie dabei nur für die Ressourcen zahlen, die zur Aufrechterhaltung dieser Verfügbarkeit erforderlich sind, unabhängig von der Nachfrage.
Jetzt sollte der VPA die Größe Ihrer Pods im Deployment hello-server angepasst haben.
kubectl set resources deployment hello-server --requests=cpu=25m . Manchmal braucht der VPA im Automodus sehr lange oder legt ungenaue obere oder untere Grenzwerte fest, wenn keine Zeit für die Erfassung genauer Daten bleibt. Um keine Zeit im Lab zu verlieren, können Sie einfach die Empfehlung so verwenden, als ob sie im „Off“-Modus wäre. In diesem Fall ist der VPA ein hervorragendes Instrument zur Optimierung der Ressourcennutzung und damit zur Kosteneinsparung. Die ursprüngliche Anforderung von 400m CPU war höher als der Bedarf dieses Containers. Indem Sie die Anforderung auf die empfohlenen 25m anpassen, können Sie weniger CPU aus dem Knotenpool verwenden, sodass möglicherweise weniger Knoten im Cluster bereitgestellt werden müssen.
Mit der Auto-Update-Richtlinie würde Ihr VPA die Pods des hello-server-Deployment während der gesamten Lebensdauer löschen und ihre Größe ändern. Bei größeren Anfragen könnten Pods hochskaliert werden, um starken Traffic zu bewältigen, und während einer Ausfallzeit wieder herunterskaliert werden. Dies kann bei einer stetig steigenden Nachfrage nach Ihrer Anwendung von Nutzen sein. Es besteht jedoch das Risiko eines Verfügbarkeitsverlusts bei starken Spitzenwerten.
Je nach Anwendung ist es im Allgemeinen am sichersten, den VPA mit der Update-Richtlinie Off zu aktualisieren und die Empfehlungen nach Bedarf zu befolgen, um sowohl die Ressourcennutzung zu optimieren als auch die Verfügbarkeit Ihres Clusters zu maximieren.
In den nächsten Abschnitten erfahren Sie, wie Sie Ihre Ressourcennutzung mit dem Cluster Autoscaler und der automatischen Knotenbereitstellung weiter optimieren können.
Der Cluster Autoscaler ist so konzipiert, dass Knoten je nach Bedarf hinzugefügt oder entfernt werden können. Wenn die Nachfrage hoch ist, fügt der Cluster Autoscaler dem Knotenpool Knoten hinzu, um die Nachfrage zu decken. Wenn die Nachfrage gering ist, skaliert der Cluster Autoscaler Ihren Cluster zurück, indem er Knoten entfernt. Auf diese Weise können Sie die hohe Verfügbarkeit Ihres Clusters aufrechterhalten und gleichzeitig überflüssige Kosten im Zusammenhang mit zusätzlichen Maschinen minimieren.
Das dauert einige Minuten.
Bei der Skalierung eines Clusters ist die Entscheidung, wann ein Knoten entfernt werden soll, ein Kompromiss zwischen der Optimierung der Auslastung und der Verfügbarkeit von Ressourcen. Mit dem Entfernen zu wenig genutzter Knoten wird die Clusterauslastung verbessert, neue Arbeitslasten müssen jedoch vor ihrer Ausführung möglicherweise warten, bis Ressourcen wieder bereitgestellt werden.
Sie können angeben, welches Autoscaling-Profil bei solchen Entscheidungen verwendet werden soll. Derzeit sind folgende Profile verfügbar:
Auslastung optimieren, sodass Sie die Auswirkungen der Skalierung in vollem Umfang beobachten können:Beobachten Sie Ihren Cluster bei aktivierter automatischer Skalierung in der Cloud Console. Klicken Sie auf die drei Balken oben links, um das Navigationsmenü zu öffnen.
Klicken Sie im Navigationsmenü auf Kubernetes Engine > Cluster.
Wählen Sie auf der Seite Cluster den Cluster scaling-demo.
Wählen Sie auf der Clusterseite der Skalierungsdemo den Tab Knoten.
Kombiniert man die Werte von angeforderte CPU und zuweisbare CPU für die 3 Knoten, wären die Gesamtmengen 1555m bzw. 2820m. Dies bedeutet, dass im gesamten Cluster insgesamt 1265m CPU-Kapazitäten zur Verfügung stehen. Dies ist mehr, als von einem Knoten bereitgestellt werden könnte.
Um die Auslastung zu optimieren, könnte die derzeitige Arbeitslast bei ihrem aktuellen Bedarf auf 2 statt 3 Knoten konsolidiert werden. Ihr Cluster hat sich jedoch noch nicht automatisch herunterskaliert. Der Grund dafür sind die über den Cluster verteilten System-Pods.
Ihr Cluster führt eine Reihe von Deployments unter dem Namenspace kube-system aus, die das Funktionieren der verschiedenen GKE-Dienste wie Protokollierung, Überwachung, automatische Skalierung usw. ermöglichen.
Standardmäßig verhindern die meisten System-Pods aus diesen Deployments, dass der Cluster Autoscaler sie komplett offline nimmt, um sie neu zu planen. Im Allgemeinen ist dies erwünscht, da viele dieser Pods Daten erfassen, die in anderen Deployments und Diensten verwendet werden. Ein vorübergehender Ausfall von metrics-agent würde beispielsweise zu einer Lücke in den für VPA und HPA erfassten Daten führen. Der Ausfall des fluentd-Pods könnte eine Lücke in Ihren Cloud-Protokollen verursachen.
In diesem Lab wenden Sie Budget für Pod-Störungen auf Ihre kube-system-Pods an, was es dem Cluster Autoscaler ermöglicht, sie sicher auf einem anderen Knoten neu zu planen. So haben Sie genügend Platz, um Ihren Cluster zu verkleinern.
Budgets für Pod-Störungen (PDB) legen fest, wie Kubernetes mit Störungen wie Upgrades, Pod-Entfernungen, fehlenden Ressourcen usw. umgehen soll. In PDBs können Sie die max-unavailable- und/oder die min-available-Anzahl an Pods festlegen, die ein Deployment haben sollte.
kube-system-Pods zu erstellen:Klicken Sie auf Fortschritt prüfen.
In jedem dieser Befehle wählen Sie einen anderen kube-system-Deployment-Pod auf der Grundlage eines bei der Erstellung definierten Labels und mit der Angabe, dass für jedes dieser Deployments ein nicht verfügbarer Pod vorhanden sein kann. Dadurch kann der Autoscaler die System-Pods neu einplanen.
Mit den PDBs sollte Ihr Cluster in 1 oder 2 Minuten von 3 auf 2 Knoten skaliert werden.
Aktualisieren Sie in der Cloud Console den Tab Knoten Ihrer scaling-demo, um zu überprüfen, wie Ihre Ressourcen gepackt wurden:
Sie haben eine Automatisierung eingerichtet, die Ihren Cluster von 3 auf 2 Knoten verkleinert.
Was die Kosten angeht, so werden Ihnen durch die Verkleinerung Ihres Knotenpools in Zeiten geringerer Nachfrage in Ihrem Cluster weniger Maschinen in Rechnung gestellt. Diese Skalierung könnte sogar noch dramatischer ausfallen, wenn Ihr Bedarf während des Tages zwischen Zeiten mit hohem und niedrigem Bedarf schwanken würde.
Beachten Sie, dass der Cluster Autoscaler zwar einen unnötigen Knoten entfernt hat, aber das vertikale Pod-Autoscaling und das horizontale Pod-Autoscaling dazu beigetragen haben, die CPU-Nachfrage so weit zu reduzieren, dass der Knoten nicht mehr benötigt wurde. Die Kombination dieser Tools ist eine hervorragende Möglichkeit, Ihre Gesamtkosten und Ihren Ressourcenverbrauch zu optimieren.
Der Cluster Autoscaler hilft also beim Hinzufügen und Entfernen von Knoten als Reaktion auf Pods, die geplant werden müssen. GKE verfügt jedoch über eine weitere Funktion zur vertikalen Skalierung, die automatische Knotenbereitstellung.
Automatische Knotenbereitstellung (NAP) fügt tatsächlich neue Knotenpools hinzu, die der Nachfrage entsprechend dimensioniert sind. Ohne die automatische Knotenbereitstellung erstellt der Cluster Autoscaler nur neue Knoten in den von Ihnen angegebenen Knotenpools, d. h., die neuen Knoten sind vom gleichen Maschinentyp wie die anderen Knoten in diesem Pool. Dies ist ideal, um die Ressourcennutzung für Batch-Workloads und andere Anwendungen zu optimieren, die keine extreme Skalierung benötigen, da die Erstellung eines Knotenpools, der speziell für Ihren Anwendungsfall optimiert ist, mehr Zeit in Anspruch nehmen kann als das Hinzufügen weiterer Knoten zu einem bestehenden Pool.
In diesem Befehl geben Sie eine Mindest- und Höchstzahl für Ihre CPU- und Speicherressourcen an. Dies gilt für den gesamten Cluster.
NAP kann etwas Zeit in Anspruch nehmen, und es ist auch sehr wahrscheinlich, dass kein neuer Knotenpool für den scaling-demo Cluster in seinem aktuellen Zustand erstellt wird.
In den nächsten Abschnitten werden Sie die Nachfrage nach Ihrem Cluster erhöhen und die Aktionen Ihrer Autoscaler sowie von NAP beobachten.
Klicken Sie auf Fortschritt prüfen.
Bisher haben Sie analysiert, wie HPA, VPA und Cluster Autoscaler dazu beitragen können, Ressourcen und Kosten zu sparen, wenn Ihre Anwendung nur eine geringe Nachfrage hat. Jetzt werden Sie sehen, wie diese Tools die Verfügbarkeit bei erhöhter Nachfrage handhaben.
php-apache zu senden:Gehen Sie auf Ihren ursprünglichen Cloud Shell -Tab zurück.
Innerhalb von etwa einer Minute sollten Sie die höhere CPU-Auslastung Ihres HPA erkennen, indem Sie Folgendes ausführen:
Warten Sie und führen Sie den Befehl erneut aus, bis Ihr Ziel über 100 % liegt.
Sie können Ihren Cluster auch überwachen, indem Sie den Tab Knoten in Ihrer Cloud Console aktualisieren.
Warten Sie ein paar Minuten, bis etwas passiert.
php-apache Deployment von HPA automatisch hochskaliert, um die erhöhte Last zu bewältigen.Warten Sie, bis Ihr Deployment php-apache auf sieben Replikate hochskaliert ist und Ihr Knoten-Tab in etwa so aussieht:
Ihr Cluster skaliert effizient, um eine höhere Nachfrage zu bedienen. Beachten Sie jedoch, wie lange es gedauert hat, diese Nachfragespitze zu bewältigen. Für viele Anwendungen kann der Verlust der Verfügbarkeit bei der Bereitstellung neuer Ressourcen ein Problem darstellen.
Bei der Skalierung für größere Lasten werden bei der horizontalen Pod-Autoskalierung neue Pods hinzugefügt, während bei der vertikalen Pod-Autoskalierung die Größe der Pods je nach Ihren Einstellungen angepasst wird. Wenn auf einem vorhandenen Knoten Platz ist, kann er das Abrufen des Images überspringen und sofort mit der Ausführung der Anwendung auf einem neuen Pod beginnen. Wenn Sie mit einem Knoten arbeiten, der Ihre Anwendung noch nicht bereitgestellt hat, kann es etwas länger dauern, bis er die Container-Images heruntergeladen hat, bevor er sie ausführt.
Wenn Sie also nicht genügend Platz auf Ihren vorhandenen Knoten haben und den Cluster Autoscaler verwenden, kann es sogar noch länger dauern. Jetzt muss er einen neuen Knoten bereitstellen, ihn einrichten, dann das Image herunterladen und die Pods starten. Wenn das Auto-Provisioning einen neuen Knotenpool erstellt, wie es in Ihrem Cluster der Fall war, benötigen Sie sogar noch mehr Zeit, da Sie zuerst den neuen Knotenpool bereitstellen und dann die gleichen Schritte für den neuen Knoten durchführen müssen.
Um diese unterschiedlichen Latenzen beim Autoscaling zu bewältigen, sollten Sie etwas mehr überdimensionieren, damit Ihre Anwendungen beim automatischen Hochskalieren weniger unter Druck geraten. Dies ist für die Kostenoptimierung sehr wichtig. Schließlich wollen Sie vermeiden, mehr für Ressourcen zu bezahlen, als Sie benötigen. Allerdings wollen Sie auch nicht, dass die Leistung Ihrer Anwendungen beeinträchtigt wird.
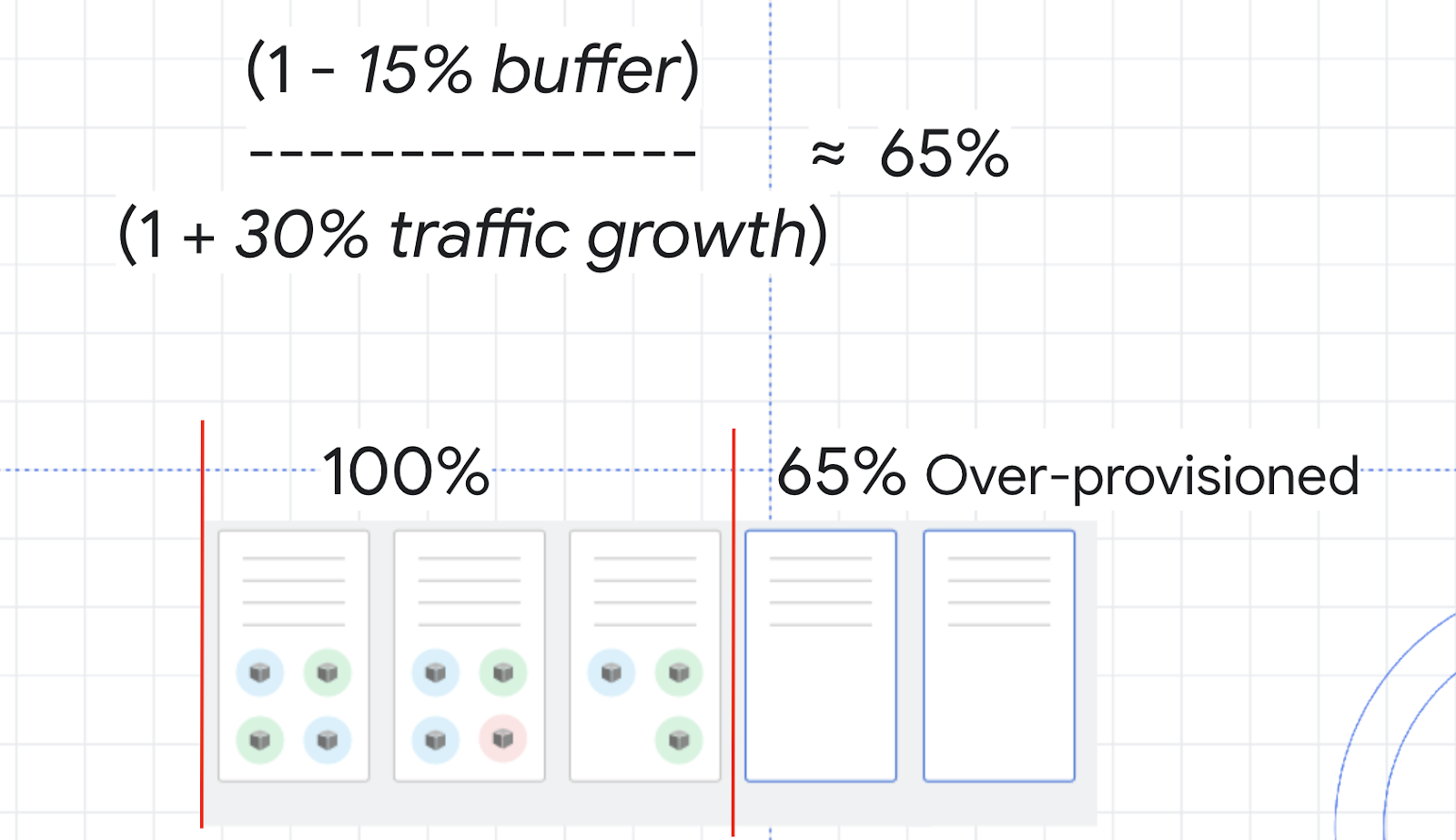
Um herauszufinden, wie hoch die Überdimensionierung sein sollte, können Sie diese Formel verwenden:
Denken Sie beispielsweise an die CPU-Auslastung für Ihren Cluster. Sie möchten nicht, dass 100 % erreicht werden, daher könnten Sie einen Puffer von 15 % wählen, um einen Sicherheitsabstand einzuhalten. Die Traffic-Variable in der Formel wäre dann der Prozentsatz des geschätzten Traffic-Wachstums in den nächsten zwei bis drei Minuten. In dem Belastungstest, den Sie vorhin durchgeführt haben, war 0 % auf 150 % ein ziemlich extremes Wachstumsbeispiel. Stellen Sie sich stattdessen ein mehr dem Durchschnitt entsprechendes Traffic-Wachstum von 30 % vor.
Mit diesen Zahlen lässt sich ein Sicherheitspuffer von ca. 65 % errechnen. Dies bedeutet, dass Sie Ihre Ressourcen möglicherweise um etwa 65 % überdimensionieren sollten, um eine Skalierung zu bewältigen und gleichzeitig etwaige Probleme zu minimieren.
Eine effiziente Strategie zur Überdimensionierung eines Clusters mit Cluster-Autoscaling ist die Verwendung von Pausen-Pods.
Pausen-Pods sind Deployments mit niedriger Priorität, die entfernt und durch Deployments mit hoher Priorität ersetzt werden können. Das bedeutet, dass Sie Pods mit niedriger Priorität erstellen können, die eigentlich nichts tun, außer Pufferplatz zu reservieren. Wenn der Pod mit höherer Priorität Platz benötigt, werden die Pausen-Pods entfernt und auf einen anderen oder neuen Knoten verschoben, und der Pod mit höherer Priorität bekommt den Platz, den er für eine schnelle Planung benötigt.
Beobachten Sie, wie ein neuer Knoten erstellt wird, wahrscheinlich in einem neuen Knotenpool, der zu Ihrem neu erstellten Pausen-Pod passt. Wenn Sie den Belastungstest jetzt erneut ausführen und einen zusätzlichen Knoten für Ihr php-apache-Deployment benötigen, kann dieser auf dem Knoten mit Ihrem Pausen-Pod geplant werden, während Ihr Pausen-Pod stattdessen auf einem neuen Knoten platziert wird. Dies ist hervorragend, da Ihre Dummy-Pausen-Pods es Ihrem Cluster ermöglichen, im Voraus einen neuen Knoten bereitzustellen, sodass Ihre eigentliche Anwendung viel schneller skaliert werden kann. Wenn Sie mit einem höheren Datenverkehr rechnen, können Sie weitere Pausen-Pods hinzufügen. Es wird jedoch als bewährte Methode angesehen, nicht mehr als einen Pausen-Pod pro Knoten hinzuzufügen.
Klicken Sie auf Fortschritt prüfen.
Sie haben das Lab erfolgreich abgeschlossen. In diesem Lab haben Sie einen Cluster so konfiguriert, dass er je nach Bedarf automatisch und effizient nach oben oder unten skaliert wird. Horizontales Pod-Autoscaling und vertikales Pod-Autoscaling bieten Lösungen für die automatische Skalierung der Bereitstellungen Ihres Clusters, während der Cluster Autoscaler und die automatische Knotenbereitstellung Lösungen für die automatische Skalierung der Infrastruktur Ihres Clusters bieten.
Wie immer hängt es von Ihrer Arbeitslast ab, welches dieser Tools Sie verwenden sollten. Durch sorgfältigen Einsatz dieser Autoscaler können Sie die Verfügbarkeit bei Bedarf maximieren und in Zeiten geringer Nachfrage nur für das bezahlen, was Sie benötigen. Im Hinblick auf die Kosten bedeutet dies, dass Sie Ihre Ressourcennutzung optimieren und Geld sparen.
Mit diesen Ressourcen können Sie weitere Informationen zu den in diesem Lab behandelten Themen abrufen:
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 1. Februar 2024 aktualisiert
Lab zuletzt am 20. September 2023 getestet
© 2025 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.



Diese Inhalte sind derzeit nicht verfügbar
Bei Verfügbarkeit des Labs benachrichtigen wir Sie per E-Mail

Sehr gut!
Bei Verfügbarkeit kontaktieren wir Sie per E-Mail

One lab at a time
Confirm to end all existing labs and start this one