








Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Provision testing environment
/ 20
Scale pods with Horizontal Pod Autoscaling
/ 20
Scale size of pods with Vertical Pod Autoscaling
/ 20
Cluster autoscaler
/ 20
Node Auto Provisioning
/ 10
Optimize larger loads
/ 10
Google Kubernetes Engine tiene soluciones horizontales y verticales para ajustar automáticamente la escala de tus Pods y tu infraestructura. Cuando se trata de optimizar costos, estas herramientas se vuelven muy útiles para garantizar que tus cargas de trabajo se ejecuten de la manera más eficiente posible y que solo pagues por lo que usas.
En este lab, configurarás y observarás el Ajuste automático de escala horizontal de Pods y el Ajuste de escala automático vertical de Pods para el escalamiento a nivel del Pod, y el Escalador automático de clúster (solución de infraestructura horizontal) y el Aprovisionamiento automático de nodos (solución de infraestructura vertical) para el escalamiento a nivel de nodo. Primero, usarás estas herramientas de ajuste de escala automático para ahorrar tantos recursos como sea posible y reducir el tamaño de tu clúster durante un período de baja demanda. Luego, aumentarás las demandas de tu clúster y observarás cómo el ajuste de escala automático mantiene la disponibilidad.
En este lab, aprenderás a hacer lo siguiente:
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
Haga clic en el botón Comenzar lab. Si debe pagar por el lab, se abrirá una ventana emergente para que seleccione su forma de pago. A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordene las pestañas en ventanas separadas, una junto a la otra.
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
También puedes encontrar el nombre de usuario en el panel Detalles del lab.
Haz clic en Siguiente.
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
También puedes encontrar la contraseña en el panel Detalles del lab.
Haz clic en Siguiente.
Haga clic para avanzar por las páginas siguientes:
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.

Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
 en la parte superior de la consola de Google Cloud.
en la parte superior de la consola de Google Cloud.Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu PROJECT_ID. El resultado contiene una línea que declara el PROJECT_ID para esta sesión:
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
Haz clic en Autorizar.
Ahora, el resultado debería verse de la siguiente manera:
Resultado:
Resultado:
Resultado de ejemplo:
gcloud, consulta la guía con la descripción general de gcloud CLI en Google Cloud.
Con el objetivo de demostrar el ajuste automático de escala horizontal de Pods, este lab usa una imagen de Docker personalizada basada en la imagen php-apache. Esta define una página index.php que realiza algunos cálculos de uso intensivo de CPU. Supervisarás un Deployment de esta imagen.
php-apache:Haz clic en Revisar mi progreso para verificar la realización de la tarea indicada arriba.
El ajuste automático de escala horizontal de Pods cambia la forma de tu carga de trabajo de Kubernetes aumentando o disminuyendo automáticamente la cantidad de Pods en función del consumo de memoria o CPU de la carga de trabajo, o en función de las métricas personalizadas que se establecen desde Kubernetes o las métricas externas de fuentes fuera del clúster.
Deberías ver el Deployment php-apache con 3/3 Pods en ejecución:
php-apache:Haz clic en Revisar mi progreso para verificar la realización de la tarea indicada arriba.
El comando autoscale configurará un Horizontal Pod Autoscaler que mantendrá entre 1 y 10 réplicas de los Pods controlados por el Deployment php-apache. La marca cpu-percent especifica un uso promedio objetivo de CPU del 50% de la CPU solicitada en todos los Pods. El HPA ajustará la cantidad de réplicas (a través del Deployment) para mantener un uso de CPU promedio del 50% en todos los Pods.
En la columna Targets, deberías ver 1%/50%.
Esto significa que, por el momento, las CPUs de los Pods de tu implementación se encuentran al 1% de su capacidad promedio objetivo. Esto era de esperarse, ya que la aplicación php-apache no recibe tráfico en este momento.
kubectl get hpa. Tu HPA aún no creó una evaluación. Además, toma nota de la columna Replicas. Para comenzar, el valor será 3. El escalador automático cambiará este número a medida que cambie la cantidad de Pods necesarios.
En este caso, el escalador automático reducirá verticalmente la escala del Deployment a la cantidad mínima de Pods que se indica cuando ejecutas el comando autoscale. El ajuste automático de escala horizontal de Pods tarda entre 5 y 10 minutos, y necesitará cerrar o iniciar Pods nuevos en función del modo en que realice el escalamiento.
Continúa con el siguiente paso del lab. Inspeccionarás los resultados del escalador automático más adelante.
cpu-percent como la métrica objetivo para tu escalador automático en este lab, HPA permite que se definan métricas personalizadas de manera que puedas escalar los Pods según otras métricas útiles capturadas en los registros.El Ajuste de escala automático vertical de Pods te libera de tener que pensar qué valores especificar para las solicitudes de CPU y de memoria de un contenedor. El escalador automático te puede recomendar valores de solicitudes y límites de CPU y memoria o puede actualizar automáticamente los valores.
El Ajuste de escala automático vertical de Pods ya se habilitó en el clúster scaling-demo.
El resultado debería ser enabled: true.
gcloud container clusters update scaling-demo --enable-vertical-pod-autoscalingPara demostrar el VPA, implementarás la aplicación hello-server.
hello-server a tu clúster:hello-server:Lo anterior genera un manifiesto para un Vertical Pod Autoscaler orientado al Deployment hello-server con una política de actualización Off. Un VPA puede tener una de las tres políticas de actualización que pueden resultar útiles según tu aplicación:
hello-vpa:VerticalPodAutoscaler:Busca “Container Recommendations” al final del resultado. Si no aparece, espera un poco más y vuelve a ejecutar el comando anterior. Cuando aparezca, verás varios tipos de recomendaciones diferentes, cada uno con valores para CPU y memoria:
Notarás que el VPA recomienda que la solicitud de CPU de este contenedor esté configurada en 25m en lugar de 100m como antes y también te proporciona una sugerencia de cuánta memoria debería solicitarse. En este punto, estas recomendaciones se pueden aplicar de forma manual al Deployment hello-server.
Para observar el VPA y sus efectos en este lab, cambiarás la política de actualización de hello-vpa a Auto y observarás el escalamiento.
Actualiza el manifiesto para establecer la política en Auto y aplica la configuración:
Para cambiar el tamaño de un Pod, el Vertical Pod Autoscaler deberá borrar ese Pod y volver a crearlo con el tamaño nuevo. De forma predeterminada, para evitar el tiempo de inactividad, el VPA no borrará el último Pod activo ni cambiará su tamaño. Debido a esto, necesitarás al menos 2 réplicas para ver los cambios en el VPA.
hello-server a 2 réplicas:hello-server-xxx en el estado terminating o en pending (o dirígete a Kubernetes Engine > Cargas de trabajo):Esto indica que tu VPA está borrando tus Pods y cambiando su tamaño. Cuando observes esto, presiona Ctrl + C para salir del comando.
Haz clic en Revisar mi progreso para verificar la realización de la tarea indicada arriba.
En este punto, es probable que el Horizontal Pod Autoscaler haya reducido verticalmente la escala de tu Deployment php-apache.
php-apache redujo la escala verticalmente a 1 Pod.php-apache, debes esperar algunos minutos más hasta que el escalador automático realice la acción.php-apache, volvería a escalar verticalmente para responder ante la carga.Esto es muy útil cuando se considera la optimización de costos. Un escalador automático bien ajustado implica mantener la alta disponibilidad de la aplicación mientras que pagas únicamente por los recursos necesarios para mantener esa disponibilidad, independientemente de la demanda.
Ahora el VPA debería haber cambiado el tamaño de tus Pods en el Deployment hello-server.
kubectl set resources deployment hello-server --requests=cpu=25m Hay ocasiones en las que el VPA en modo automático demora mucho tiempo o establece valores de límite inferiores o superiores por no tener el tiempo necesario para recopilar datos precisos. Para no perder tiempo en el lab, una solución fácil es usar la recomendación como si estuviera en modo “Off”. En este caso, el VPA se convierte en una excelente herramienta para optimizar el uso de recursos y, en efecto, ahorrar costos. La solicitud original de 400m de CPU era mayor que la que necesitaba este contenedor. Si ajustas la solicitud al valor recomendado de 25m, podrás usar menos CPU del grupo de nodos, lo que podría implicar que se necesiten menos nodos en el clúster.
Con la política de actualización en Auto, tu VPA seguirá borrando los Pods del Deployment hello-server y cambiando su tamaño durante toda su vida útil. Puedes escalar verticalmente los Pods con solicitudes más grandes para manejar mucho tráfico y, luego, reducir la escala de forma vertical durante un tiempo de inactividad. Esto puede ser muy útil para los aumentos constantes en la demanda de tu aplicación, pero corres el riesgo de perder la disponibilidad durante grandes aumentos repentinos.
Según tu aplicación, suele ser más seguro usar el VPA con la política de actualización en Off y aplicar las recomendaciones según sea necesario para optimizar el uso de los recursos y maximizar la disponibilidad de tu clúster.
En las próximas secciones, analizarás cómo optimizar aún más el uso de los recursos con el escalador automático de clúster y el aprovisionamiento automático de nodos.
El escalador automático de clúster está diseñado para agregar o quitar nodos en función de la demanda. Cuando la demanda es alta, el escalador automático de clúster agregará nodos al grupo de nodos para satisfacer esa demanda. Cuando la demanda es baja, el escalador automático de clúster reduce verticalmente la escala de tu clúster mediante la eliminación de nodos. Esto te permite mantener una alta disponibilidad de tu clúster, al mismo tiempo que minimiza los costos excesivos asociados a máquinas adicionales.
Este proceso tardará unos minutos en completarse.
Cuando escalas un clúster, la decisión de cuándo quitar un nodo representa el equilibrio entre la optimización para el uso o la disponibilidad de los recursos. Quitar los nodos poco usados mejora el uso del clúster, pero es posible que las cargas de trabajo nuevas tengan que esperar que los recursos se aprovisionen nuevamente antes de poder ejecutarse.
Puedes especificar qué perfil de ajuste de escala automático usar cuando tomes esas decisiones. Los perfiles disponibles en este momento son los siguientes:
optimize-utilization para que se puedan observar los efectos completos del escalamiento:Cuando se habilite el ajuste de escala automático, observa tu clúster en la consola de Cloud. Haz clic en las tres barras ubicadas en la parte superior izquierda para abrir el Menú de navegación.
En Menú de navegación, selecciona Kubernetes Engine > Clústeres.
En la página Clústeres, selecciona el clúster scaling-demo.
En la página del clúster scaling-demo, selecciona la pestaña Nodos (Nodes).
Si combinas los valores de CPU solicitada y CPU asignable para los 3 nodos, los totales serían 1555m y 2820m, respectivamente. Esto significa que hay un total de 1265m de CPU disponibles en todo el clúster. Esto es más grande de lo que puede proporcionar un nodo.
Para optimizar el uso, la carga de trabajo actual a la demanda actual se podría consolidar en dos nodos en lugar de tres. Sin embargo, tu clúster aún no redujo su escala verticalmente de forma automática. Esto se debe a los Pods del sistema, distribuidos a través de todo el clúster.
Tu clúster ejecuta varios Deployments en el espacio de nombres de kube-system que permiten que funcionen los diferentes servicios de GKE, como el registro, la supervisión, el ajuste de escala automático, etc.
De forma predeterminada, la mayoría de los Pods del sistema de estos Deployments evitan que el escalador automático del clúster los deje completamente sin conexión para reprogramarlos. En general, esto se debe a que muchos de estos Pods recopilan datos usados en otros Deployments y Services. Por ejemplo, si metrics-agent dejara de funcionar temporalmente, provocaría una interrupción en los datos recopilados para el VPA y el HPA, o si pasara lo mismo con el Pod fluentd, se podría crear una interrupción en sus registros en la nube.
A los fines de este lab, aplicarás Presupuestos de interrupción de Pods a tus Pods de kube-system, lo que permitirá que el escalador automático del clúster los reprograme de forma segura en otro nodo. Esto te dará suficiente espacio para reducir verticalmente la escala de tu clúster.
Los Presupuestos de interrupción de Pods (PDB) definen la forma en que Kubernetes debe manejar las interrupciones, como las actualizaciones, las eliminaciones de Pods, la falta de recursos, etc. En los PDB, puedes especificar la cantidad max-unavailable o min-available de Pods que debería tener un Deployment.
kube-system:Haz clic en Revisar mi progreso para verificar la realización de la tarea indicada arriba.
En cada uno de estos comandos, selecciona un Pod de implementación de kube-system distinto según una etiqueta definida en su creación, la cual especifica que puede haber 1 Pod no disponible para cada una de estas implementaciones. Esto permitirá que el escalador automático reprograme los Pods del sistema.
Con los PDB establecidos, tu clúster debería reducir su escala verticalmente de tres nodos a dos en un minuto o dos.
En la consola de Cloud, actualiza la pestaña Nodos de tu scaling-demo para inspeccionar cómo se empaquetaron los recursos:
Configuraste la automatización que redujo verticalmente la escala de tu clúster de tres a dos nodos.
Si tienes en cuenta los costos, debido a que redujiste verticalmente la escala de tu grupo de nodos, se te facturará por menos máquinas durante períodos de baja demanda en tu clúster. Este escalamiento podría ser aún más marcado si fluctuara entre períodos de alta demanda y baja demanda durante el día.
Es importante tener en cuenta que, si bien el escalador automático del clúster quitó un nodo innecesario, el Ajuste de escala automático vertical de Pods y el Ajuste automático de escala horizontal de Pods ayudaron a reducir la demanda de CPU lo suficiente como para que el nodo ya no fuera necesario. Combinar estas herramientas es una excelente manera de optimizar los costos generales y el uso de recursos.
Por lo tanto, el escalador automático del clúster ayuda a agregar y quitar nodos en respuesta a los Pods que necesitan programarse. Sin embargo, GKE tiene otra función específicamente para escalar de forma vertical; se denomina aprovisionamiento automático de nodos.
El aprovisionamiento automático de nodos (NAP) agrega nuevos grupos de nodos que tienen el tamaño para satisfacer la demanda. Sin el aprovisionamiento automático de nodos, el escalador automático del clúster solo creará nodos nuevos en los grupos de nodos que hayas especificado, lo que significa que los nodos nuevos serán el mismo tipo de máquina que los otros nodos en ese grupo. Esto es ideal para optimizar el uso de recursos en cargas de trabajo por lotes y otras aplicaciones que no necesitan escalamiento extremo, ya que crear un grupo de nodos que esté optimizado de forma específica para tu caso de uso podría llevar más tiempo que solo agregar más nodos a un grupo de nodos existente.
En el comando, especificas un número mínimo y máximo para los recursos de CPU y memoria. Esto se aplica a todo el clúster.
El NAP puede demorar un poco y es muy probable que no cree un grupo de nodos nuevo para el clúster scaling-demo en su estado actual.
En las siguientes secciones, aumentarás la demanda en tu clúster y observarás las acciones de sus escaladores automáticos y el NAP.
Haz clic en Revisar mi progreso para verificar la realización de la tarea indicada arriba.
Hasta ahora, analizaste cómo el HPA, el VPA y el escalador automático del clúster pueden ayudarte a ahorrar recursos y costos mientras tu aplicación tiene una demanda baja. Ahora verás cómo estas herramientas administran la disponibilidad ante una mayor demanda.
php-apache:Regresa a la pestaña original de Cloud Shell.
En un plazo aproximado de un minuto, deberías ver una mayor carga de CPU en tu HPA mediante la ejecución del siguiente comando:
Espera y vuelve a ejecutar el comando hasta que veas tu objetivo por encima del 100%.
También puedes supervisar tu clúster si actualizas la pestaña Nodos en la pestaña de la consola de Cloud.
Después de unos minutos, verás que ocurren algunos eventos.
php-apache para controlar el aumento de la carga.Espera hasta que tu Deployment php-apache escale verticalmente hasta 7 réplicas y la pestaña de nodos se vea similar a la siguiente:
Tu clúster escaló verticalmente de forma eficiente para satisfacer una demanda mayor. Sin embargo, ten en cuenta la cantidad de tiempo que le tomó para manejar este aumento repentino de demanda. Para muchas aplicaciones, perder la disponibilidad mientras se aprovisionan recursos nuevos puede ser un problema.
Cuando se escala verticalmente debido a cargas más grandes, el ajuste automático de escala horizontal de Pods agrega nuevos Pods mientras que el ajuste automático de escala vertical de Pods cambiará su tamaño en función de la configuración hayas establecido. Si hay espacio en un nodo existente, podría omitir la extracción de la imagen y comenzar a ejecutar inmediatamente la aplicación en un Pod nuevo. Si trabajas con un nodo que no implementó tu aplicación anteriormente, es posible que demore un poco más si necesita descargar las imágenes del contenedor antes de ejecutarla.
Por lo tanto, si no tienes suficiente espacio en tus nodos existentes y usas el escalador automático del clúster, podría tardar aún más. Ahora deberá aprovisionar un nodo nuevo, configurarlo y, luego, descargar la imagen e iniciar los Pods. Si el aprovisionador automático de nodos crea un grupo de nodos nuevo como lo hizo en tu clúster, tendrás aún más tiempo para aprovisionar el nuevo grupo de nodos primero y, luego, seguir los mismos pasos para el nodo nuevo.
A la hora de manejar estas diferentes latencias para el ajuste de escala automático, es probable que quieras aprovisionar en exceso un poco, de modo que haya menos presión en sus aplicaciones cuando se realice el ajuste de escala automático vertical. Esto es muy importante para la optimización de costos, ya que no es conveniente pagar por más recursos de los que necesitas, pero tampoco es recomendable que el rendimiento de tus aplicaciones se vea comprometido.
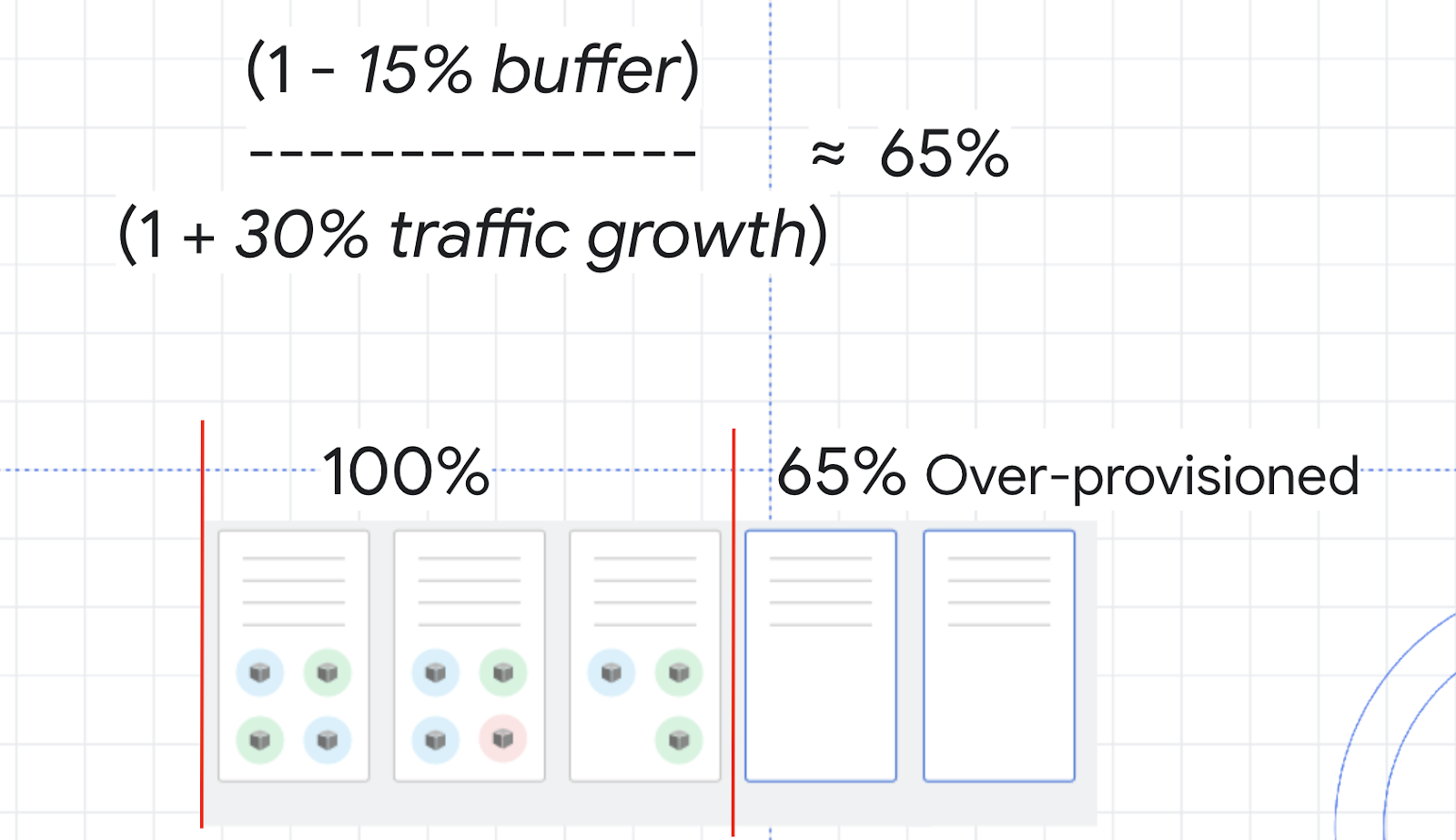
Para decidir cuánto debes aprovisionar en exceso, puedes usar esta fórmula:
Como ejemplo, piensa en el uso de CPU para tu clúster. No es conveniente que alcance el 100%, por lo que puedes elegir un búfer del 15% para mantener una distancia segura. En ese caso, la variable de tráfico de la fórmula sería el porcentaje de aumento de tráfico estimado en los próximos 2 a 3 minutos. En la prueba de carga que ejecutaste antes, del 0% al 150% era un ejemplo de aumento extremo; por lo tanto, en su lugar, imagina un aumento del tráfico promedio del 30%.
Con estos números, puedes calcular un búfer de seguridad de aproximadamente el 65%. Esto significa que es probable que debas aprovisionar en exceso tus recursos en aproximadamente un 65% para poder manejar los aumentos verticales de escala y, al mismo tiempo, minimizar los problemas.
Una estrategia eficiente para aprovisionar en exceso un clúster con el ajuste de escala automático del clúster es usar Pods de pausa.
Los Pods de pausa son implementaciones de prioridad baja que se pueden quitar y reemplazar por implementaciones de prioridad alta. Esto significa que puedes crear Pods de prioridad baja que en realidad no hagan nada, excepto reservar espacio de búfer. Cuando el Pod de prioridad más alta necesite espacio, los Pods de pausa se quitarán y se reprogramarán en otro nodo, o en un nodo nuevo, y el Pod de prioridad más alta tendrá el espacio que necesita para programarse rápidamente.
Observa cómo se crea un nodo nuevo (lo más probable es que sea en un grupo de nodos nuevo) para adaptarse a tu Pod de pausa recién creado. Ahora, si volvieras a ejecutar la prueba de carga, cuando necesites un nodo adicional para tu Deployment php-apache, podría programarse en el nodo con tu Pod de pausa mientras el Pod de pausa se coloca en un nodo nuevo. Esto es excelente, ya que tus Pods de pausa ficticios le permiten a tu clúster aprovisionar un nodo nuevo por adelantado para que tu aplicación real pueda escalar verticalmente mucho más rápido. Si esperaras una cantidad de tráfico más grande, puedes agregar más Pods de pausa, pero es una práctica recomendada no agregar más de un Pod de pausa por nodo.
Haz clic en Revisar mi progreso para verificar la realización de la tarea indicada arriba.
¡Felicitaciones! En este lab, configuraste un clúster para aumentar o reducir la escala verticalmente de forma automática y eficiente según su demanda. El ajuste automático de escala horizontal de Pods y el ajuste de escala automático vertical de Pods proporcionaron soluciones para escalar automáticamente los Deployments del clúster, mientras que el escalador automático del clúster y el aprovisionamiento automático de nodos proporcionaron soluciones para escalar automáticamente la infraestructura de tu clúster.
Como siempre, saber cuáles de estas herramientas usar dependerá de tu carga de trabajo. Usar estos escaladores automáticos con cuidado puede conllevar una mayor disponibilidad cuando lo requieras, mientras que solo pagas por lo que necesitas en momentos de baja demanda. Si piensas en términos de costos, esto significa que optimizas el uso de los recursos y ahorras dinero.
Consulta estos recursos para obtener más información sobre los temas abordados en este lab:
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 1 de febrero de 2024
Prueba más reciente del lab: 20 de septiembre de 2023
Copyright 2025 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.



Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible

¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible

One lab at a time
Confirm to end all existing labs and start this one