








Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Provision testing environment
/ 20
Scale pods with Horizontal Pod Autoscaling
/ 20
Scale size of pods with Vertical Pod Autoscaling
/ 20
Cluster autoscaler
/ 20
Node Auto Provisioning
/ 10
Optimize larger loads
/ 10
Google Kubernetes Engine memiliki solusi horizontal dan vertikal untuk menskalakan pod dan juga infrastruktur Anda secara otomatis. Dalam kaitannya dengan pengoptimalan biaya, alat-alat tersebut menjadi sangat berguna untuk memastikan bahwa workload Anda dijalankan seefisien mungkin dan Anda cukup membayar sesuai dengan penggunaan.
Dalam lab ini, Anda akan menyiapkan dan mengamati Penskalaan Otomatis Pod Horizontal dan Penskalaan Otomatis Pod Vertikal untuk penskalaan tingkat pod, serta Autoscaler Cluster (solusi infrastruktur horizontal) dan Penyediaan Otomatis Node (solusi infrastruktur vertikal) untuk penskalaan tingkat node. Pertama-tama, Anda akan menggunakan alat penskalaan otomatis tersebut untuk menghemat sebanyak mungkin resource dan mengurangi ukuran cluster selama periode permintaan rendah. Selanjutnya, Anda akan meningkatkan permintaan cluster dan mengamati cara penskalaan otomatis mempertahankan ketersediaan.
Dalam lab ini, Anda akan mempelajari cara:
Baca petunjuk ini. Lab memiliki timer dan Anda tidak dapat menjedanya. Timer, yang dimulai saat Anda mengklik Start Lab, akan menampilkan durasi ketersediaan resource Google Cloud untuk Anda.
Lab praktik ini dapat Anda gunakan untuk melakukan sendiri aktivitas lab di lingkungan cloud sungguhan, bukan di lingkungan demo atau simulasi. Untuk mengakses lab ini, Anda akan diberi kredensial baru yang bersifat sementara dan dapat digunakan untuk login serta mengakses Google Cloud selama durasi lab.
Untuk menyelesaikan lab ini, Anda memerlukan:
Klik tombol Start Lab. Jika Anda perlu membayar lab, jendela pop-up akan terbuka untuk memilih metode pembayaran. Di sebelah kiri adalah panel Lab Details dengan info berikut:
Klik Open Google Cloud console (atau klik kanan dan pilih Open Link in Incognito Window jika Anda menjalankan browser Chrome).
Lab akan menjalankan resource, lalu membuka tab lain yang menampilkan halaman Sign in.
Tips: Atur tab di jendela terpisah secara berdampingan.
Jika perlu, salin Username di bawah dan tempel ke dialog Sign in.
Anda juga dapat menemukan Username di panel Lab Details.
Klik Next.
Salin Password di bawah dan tempel ke dialog Welcome.
Anda juga dapat menemukan Password di panel Lab Details.
Klik Next.
Klik halaman berikutnya:
Setelah beberapa saat, Konsol Google Cloud akan terbuka di tab ini.

Cloud Shell adalah mesin virtual yang dilengkapi dengan berbagai alat pengembangan. Mesin virtual ini menawarkan direktori beranda persisten berkapasitas 5 GB dan berjalan di Google Cloud. Cloud Shell menyediakan akses command-line untuk resource Google Cloud Anda.
 di bagian atas konsol Google Cloud.
di bagian atas konsol Google Cloud.Setelah terhubung, Anda sudah diautentikasi, dan project ditetapkan ke PROJECT_ID Anda. Output berisi baris yang mendeklarasikan PROJECT_ID untuk sesi ini:
gcloud adalah alat command line untuk Google Cloud. Alat ini sudah terinstal di Cloud Shell dan mendukung pelengkapan command line.
Klik Authorize.
Output Anda sekarang akan terlihat seperti ini:
Output:
Output:
Contoh output:
gcloud yang lengkap di Google Cloud, baca panduan ringkasan gcloud CLI.
Untuk membantu mendemonstrasikan penskalaan otomatis pod horizontal, lab ini menggunakan image Docker kustom yang didasarkan pada image php-apache. Image tersebut menetapkan halaman index.php yang menjalankan beberapa komputasi dengan penggunaan CPU yang intensif. Anda akan memantau deployment image ini.
php-apache:Klik Check my progress untuk memastikan Anda telah menjalankan tugas di atas.
Penskalaan Otomatis Pod Horizontal mengubah bentuk workload Kubernetes Anda dengan otomatis meningkatkan atau mengurangi jumlah pod sebagai respons terhadap konsumsi memori atau CPU workload, atau sebagai respons terhadap metrik kustom yang dilaporkan dari dalam Kubernetes atau metrik eksternal dari sumber di luar cluster Anda.
Anda akan melihat deployment php-apache dengan 3/3 pod sedang berjalan:
php-apache:Klik Check my progress untuk memastikan Anda telah menjalankan tugas di atas.
Perintah autoscale ini akan mengonfigurasi Horizontal Pod Autoscaler yang akan mempertahankan 1-10 replika pod yang dikontrol oleh deployment php-apache. Flag cpu-percent menetapkan 50% sebagai target pemanfaatan CPU rata-rata untuk CPU yang diminta di semua pod. HPA akan menyesuaikan jumlah replika (melalui deployment) untuk mempertahankan pemanfaatan CPU rata-rata sebesar 50% di semua pod.
Di bawah kolom Targets, Anda akan melihat 1%/50%.
Angka ini berarti pod dalam deployment Anda saat ini menggunakan 1% dari target pemanfaatan CPU rata-rata. Hal ini tidak mengejutkan karena aplikasi php-apache tidak menerima traffic apa pun saat ini.
kubectl get hpa. HPA Anda belum membuat penilaian. Perhatikan juga kolom Replicas. Sebagai permulaan, nilainya adalah 3. Angka ini akan diubah oleh autoscaler sesuai perubahan jumlah pod yang diminta.
Dalam hal ini, autoscaler akan menurunkan skala deployment hingga mencapai jumlah minimum pod yang ditunjukkan saat Anda menjalankan perintah autoscale. Penskalaan Otomatis Pod Horizontal memerlukan waktu 5-10 menit dan akan mengharuskan dimatikannya atau dimulainya pod baru, tergantung apakah skalanya diturunkan atau ditingkatkan.
Lanjutkan ke langkah berikutnya dalam lab ini. Anda akan memeriksa hasil autoscaler nanti.
cpu-percent sebagai metrik target untuk autoscaler. Namun, HPA memungkinkan Anda menetapkan metrik kustom agar ukuran pod dapat diskalakan berdasarkan metrik berguna lainnya yang terekam dalam log.Dengan Penskalaan Otomatis Pod Vertikal, Anda tidak perlu lagi memikirkan nilai yang harus ditetapkan untuk permintaan CPU dan memori sebuah container. Autoscaler dapat merekomendasikan nilai untuk permintaan serta batas CPU dan memori, atau memperbarui nilai tersebut secara otomatis.
Penskalaan Otomatis Pod Vertikal sudah diaktifkan pada cluster scaling-demo.
Output-nya akan menampilkan enabled: true
gcloud container clusters update scaling-demo --enable-vertical-pod-autoscalingUntuk mendemonstrasikan VPA, deploy aplikasi hello-server.
hello-server ke cluster Anda:hello-server:Perintah di atas menghasilkan manifes untuk Vertical Pod Autoscaler yang menarget deployment hello-server dengan Update Policy (kebijakan update) Off. Sebuah VPA dapat memiliki salah satu dari tiga kebijakan update berbeda, yang dapat berguna bergantung pada aplikasi Anda:
hello-vpa:VerticalPodAutoscaler:Temukan "Container Recommendations" di bagian akhir output. Jika tidak ada, tunggu sedikit lebih lama, lalu jalankan kembali perintah sebelumnya. Setelah Container Recommendations muncul, Anda akan melihat beberapa jenis rekomendasi, masing-masing disertai nilai untuk CPU dan memori:
Anda akan melihat bahwa VPA merekomendasikan agar permintaan CPU untuk container ini ditetapkan ke 25m, bukan 100m seperti sebelumnya, serta menyarankan banyaknya memori yang sebaiknya diminta. Pada tahap ini, rekomendasi tersebut dapat diterapkan ke deployment hello-server secara manual.
Untuk mengamati VPA dan efeknya dalam lab ini, ubah kebijakan update hello-vpa ke Auto, lalu perhatikan penskalaannya.
Perbarui manifes untuk menetapkan kebijakan ke Auto, lalu terapkan konfigurasi berikut:
Untuk mengubah ukuran sebuah pod, Vertical Pod Autoscaler harus menghapus pod tersebut dan membuatnya ulang dengan ukuran baru. Secara default, untuk menghindari periode nonaktif, VPA tidak akan menghapus dan mengubah ukuran pod yang terakhir aktif. Karenanya, Anda memerlukan setidaknya 2 replika untuk melihat perubahan yang dibuat oleh VPA.
hello-server ke 2 replika:hello-server-xxx berstatus terminating atau pending (atau klik Kubernetes Engine > Workloads):Ini adalah tanda bahwa VPA sedang menghapus dan mengubah ukuran pod. Setelah melihat output ini, tekan Ctrl + c untuk menghentikan perintah.
Klik Check my progress untuk memastikan Anda telah menjalankan tugas di atas.
Sampai tahap ini, Horizontal Pod Autoscaler Anda kemungkinan besar sudah menurunkan skala deployment php-apache.
php-apache telah diturunkan menjadi 1 pod.php-apache, tunggu beberapa menit lagi sampai autoscaler melakukan tindakan.php-apache menerima lebih banyak permintaan, skalanya akan ditingkatkan kembali untuk mengakomodasi beban itu.Hal ini sangat berguna dalam upaya mengoptimalkan biaya. Dengan autoscaler yang disesuaikan dengan baik, Anda dapat menjaga agar aplikasi tetap memiliki ketersediaan tinggi, sekaligus hanya membayar untuk resource yang diperlukan untuk menjaga ketersediaan itu, apa pun tingkat permintaannya.
Sekarang, VPA tentu sudah mengubah ukuran pod di deployment hello-server.
kubectl set resources deployment hello-server --requests=cpu=25m. Terkadang, VPA dalam mode otomatis dapat memerlukan waktu lama atau menetapkan nilai batas atas atau batas bawah yang tidak akurat tanpa memiliki waktu untuk mengumpulkan data yang akurat. Agar tidak kehilangan waktu dalam lab ini, penggunaan rekomendasi seolah-olah VPA dalam mode "Off" merupakan solusi praktis. Dalam kasus ini, VPA menjadi alat yang sangat baik untuk mengoptimalkan pemanfaatan resource dan, sebagai akibatnya, menghemat biaya. Permintaan CPU awal sebesar 400m lebih tinggi daripada yang diperlukan container ini. Dengan menyesuaikan permintaan tersebut menjadi 25m seperti yang direkomendasikan, Anda dapat menggunakan lebih sedikit CPU dari node pool, bahkan berpotensi meminta lebih sedikit node untuk disediakan di cluster.
Dengan kebijakan update Auto, VPA Anda akan terus menghapus dan mengubah ukuran pod di deployment hello-server selama masa aktifnya. VPA dapat menaikkan skala pod seiring meningkatnya permintaan untuk menangani traffic yang padat, lalu menurunkannya kembali selama periode nonaktif. Hal ini bagus untuk mengakomodasi kenaikan permintaan yang stabil pada aplikasi Anda, tetapi dengan risiko kehilangan ketersediaan saat traffic melonjak tajam.
Bergantung pada aplikasi Anda, penggunaan VPA dengan kebijakan update Off dan penerapan rekomendasi sesuai kebutuhan secara umum merupakan pendekatan yang paling aman untuk mengoptimalkan pemanfaatan resource dan memaksimalkan ketersediaan cluster.
Di bagian selanjutnya, Anda akan mempelajari cara mengoptimalkan pemanfaatan resource lebih jauh dengan Autoscaler Cluster dan Penyediaan Otomatis Node.
Autoscaler Cluster didesain untuk menambah atau menghapus node berdasarkan permintaan. Saat permintaan tinggi, autoscaler cluster akan menambahkan node ke node pool untuk mengakomodasi permintaan itu. Saat permintaan rendah, autoscaler cluster akan menurunkan kembali skala cluster dengan menghapus node. Dengan begitu, Anda dapat mempertahankan cluster tetap dalam ketersediaan tinggi sekaligus meminimalkan biaya berlebih yang terkait dengan mesin tambahan.
Proses ini akan memerlukan waktu beberapa menit.
Saat menskalakan cluster, keputusan terkait kapan waktunya menghapus node merupakan kompromi antara pengoptimalan pemanfaatan resource dan ketersediaannya. Menghapus node yang kurang dimanfaatkan akan meningkatkan pemanfaatan cluster, tetapi workload baru mungkin harus menunggu sampai resource disediakan lagi agar dapat berjalan.
Anda dapat menentukan profil penskalaan otomatis mana yang akan digunakan saat membuat keputusan tersebut. Profil yang saat ini tersedia adalah:
optimize-utilization agar efek penuh penskalaan dapat diamati:Setelah penskalaan otomatis aktif, amati cluster Anda di Konsol Cloud. Klik ikon tiga garis di kiri atas untuk membuka Navigation menu.
Dari Navigation menu, pilih Kubernetes Engine > Clusters.
Di halaman Clusters, pilih cluster scaling-demo.
Di halaman cluster scaling-demo, pilih tab Nodes.
Jika nilai CPU requested dan CPU allocatable untuk ke-3 nodes digabung, totalnya akan berjumlah 1555m dan 2820m. Artinya, total terdapat 1265m CPU yang tersedia di seluruh cluster. Jumlah ini lebih banyak daripada yang dapat disediakan oleh satu node.
Untuk mengoptimalkan pemanfaatan, workload terkini pada tingkat permintaannya saat ini dapat dikonsolidasikan menjadi dua node, bukan tiga. Namun, skala cluster Anda belum otomatis diturunkan. Hal ini karena pod sistem tersebar ke seluruh cluster.
Cluster Anda menjalankan sejumlah deployment pada namespace kube-system yang memungkinkan berfungsinya berbagai layanan GKE seperti logging, pemantauan, penskalaan otomatis, dll.
Secara default, sebagian besar pod sistem dari deployment ini akan mencegah autoscaler cluster menjadikan pod tersebut offline sepenuhnya untuk menjadwalkannya ulang. Secara umum, hal ini baik karena banyak dari pod ini mengumpulkan data yang digunakan di deployment dan layanan lain. Misalnya, penonaktifan sementara pod metrics-agent akan menimbulkan kesenjangan dalam data yang dikumpulkan untuk VPA dan HPA, atau penonaktifan pod fluentd akan menimbulkan kesenjangan dalam log cloud Anda.
Untuk keperluan lab ini, Anda akan menerapkan Pod Disruption Budget ke pod kube-system agar autoscaler cluster dapat menjadwalkan ulang pod tersebut di node lain dengan aman. Cara ini akan menghasilkan cukup ruang untuk mengurangi skala cluster Anda.
Pod Disruption Budget (PDB) menentukan cara Kubernetes menangani disrupsi seperti upgrade, penghapusan pod, kehabisan resource, dll. Di PDB, Anda dapat menetapkan jumlah pod max-unavailable dan/atau min-available yang harus dimiliki sebuah deployment.
kube-system:Klik Check my progress untuk memastikan Anda telah menjalankan tugas di atas.
Dalam setiap perintah ini, Anda memilih pod deployment kube-system berbeda berdasarkan label yang ditetapkan saat pembuatannya dan menetapkan bahwa boleh ada 1 pod yang tidak tersedia untuk setiap deployment tersebut. Hal ini akan membuat autoscaler dapat menjadwalkan ulang pod sistem.
Setelah PDB diterapkan, skala cluster Anda akan diperkecil dari tiga node menjadi dua node dalam waktu satu atau dua menit.
Di Konsol Cloud, refresh tab Nodes untuk scaling-demo untuk memeriksa bagaimana resource Anda dikemas:
Anda telah mengonfigurasi otomatisasi yang memperkecil skala cluster dari tiga node menjadi dua node!
Bicara masalah biaya, sebagai akibat dari penurunan skala nodepool, Anda akan ditagih untuk jumlah mesin yang lebih sedikit selama periode permintaan rendah di cluster Anda. Penskalaan ini dapat lebih dramatis lagi jika terjadi fluktuasi dari periode permintaan tinggi ke permintaan rendah selama hari itu.
Perlu diperhatikan bahwa, sementara Autoscaler Cluster menghapus node yang tidak perlu, Penskalaan Otomatis Pod Vertikal dan Penskalaan Otomatis Pod Horizontal membantu mengurangi permintaan CPU dalam jumlah yang cukup sehingga node tidak lagi diperlukan. Menggabungkan alat-alat tersebut merupakan cara bagus untuk mengoptimalkan biaya keseluruhan dan pemanfaatan resource.
Jadi, autoscaler cluster membantu menambahkan dan menghapus node sebagai respons terhadap pod yang perlu dijadwalkan. Namun, GKE secara spesifik memiliki fitur lain untuk penskalaan vertikal yang disebut penyediaan otomatis node.
Penyediaan Otomatis Node (NAP) menambahkan node pool baru yang disesuaikan ukurannya untuk memenuhi permintaan. Tanpa NAP, autoscaler cluster hanya akan membuat node baru di node pool yang ditentukan, yang berarti node baru tersebut akan berupa jenis mesin yang sama dengan node lain di pool itu. Hal ini bagus untuk membantu mengoptimalkan penggunaan resource pada workload batch dan aplikasi lain yang tidak memerlukan penskalaan ekstrem, karena pembuatan node pool yang dioptimalkan secara spesifik untuk kasus penggunaan Anda dapat memerlukan waktu lebih lama daripada sekadar menambahkan lebih banyak node ke pool yang ada.
Dalam perintah ini, Anda menentukan jumlah minimum dan maksimum untuk resource CPU dan memori. Jumlah ini mencakup seluruh cluster.
NAP dapat memerlukan waktu sedikit lebih lama dan juga sangat mungkin tidak akan membuat node pool baru untuk cluster scaling-demo pada statusnya saat ini.
Di bagian selanjutnya, Anda akan meningkatkan permintaan ke cluster dan mengamati tindakan autoscaler dan juga NAP.
Klik Check my progress untuk memastikan Anda telah menjalankan tugas di atas.
Sejauh ini, Anda telah menganalisis cara HPA, VPA, dan autoscaler cluster membantu menghemat resource dan biaya saat tingkat permintaan aplikasi Anda rendah. Sekarang, Anda akan mempelajari bagaimana ketiga alat tersebut menangani ketersediaan saat permintaan tinggi.
php-apache:Kembali ke tab Cloud Shell asal.
Dalam waktu kurang lebih satu menit, Anda akan melihat beban CPU yang lebih tinggi di HPA dengan menjalankan:
Tunggu dan jalankan lagi perintah ini sampai target Anda terlihat di atas 100%.
Anda juga dapat memantau cluster dengan memuat ulang tab nodes di Konsol Cloud.
Setelah beberapa menit, hal-hal berikut akan terjadi.
php-apache akan otomatis ditingkatkan oleh HPA untuk menangani beban yang lebih tinggi.Tunggu hingga skala deployment php-apache ditingkatkan menjadi 7 replika dan tab node Anda terlihat seperti ini:
Skala cluster Anda ditingkatkan secara efisien untuk mengimbangi permintaan yang lebih tinggi. Namun, perhatikan lamanya waktu yang diperlukan untuk menangani lonjakan permintaan ini. Pada banyak aplikasi, kehilangan ketersediaan selagi menyediakan resource baru dapat menjadi masalah.
Saat meningkatkan skala untuk beban yang lebih besar, penskalaan otomatis pod horizontal akan menambahkan pod baru, sedangkan penskalaan otomatis pod vertikal akan mengubah ukuran pod sesuai dengan setelan Anda. Jika node yang ada masih memiliki ruang, node tersebut tidak perlu mengambil image dan dapat langsung mulai menjalankan aplikasi di pod baru. Jika node yang Anda tangani belum pernah men-deploy aplikasi Anda, tambahan waktu harus diperhitungkan jika node tersebut perlu mendownload image container sebelum menjalankannya.
Jadi, jika Anda tidak memiliki cukup ruang di node yang ada dan Anda menggunakan autoscaler cluster, waktu yang diperlukan dapat lebih lama lagi. Sekarang, autoscaler perlu menyediakan node baru, menyiapkannya, lalu mendownload image dan menjalankan pod. Jika penyedia otomatis node akan membuat node pool baru seperti yang dilakukannya di cluster Anda, akan perlu waktu yang lebih lama lagi karena Anda harus menyediakan node pool baru terlebih dahulu, baru kemudian menyelesaikan semua langkah yang sama untuk node baru tersebut.
Guna menangani latensi yang berbeda-beda untuk penskalaan otomatis ini, sebaiknya Anda menyediakan resource sedikit berlebih (overprovision) untuk mengurangi tekanan pada aplikasi Anda saat dilakukan peningkatan skala otomatis. Hal ini sangat penting untuk pengoptimalan biaya agar Anda tidak perlu membayar untuk resource ekstra yang tidak dibutuhkan serta tidak mengorbankan performa aplikasi.
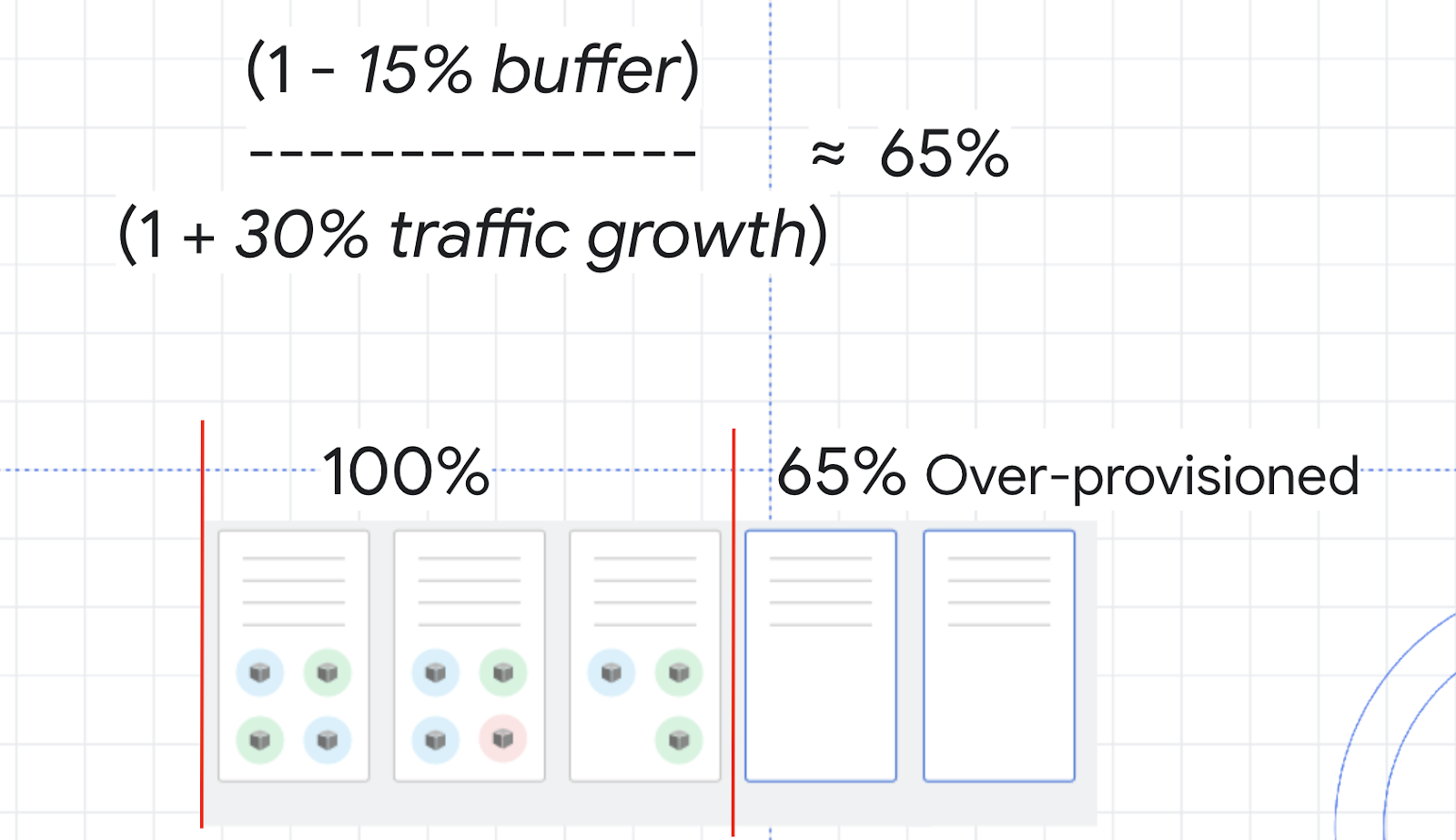
Untuk mencari tahu besarnya overprovision, Anda dapat menggunakan formula ini:
Misalnya, bayangkan pemanfaatan CPU untuk cluster Anda. Anda tidak ingin pemanfaatan CPU mencapai 100%, jadi Anda dapat memilih buffer 15% untuk menjaga jarak aman. Selanjutnya, variabel traffic dalam formula tersebut adalah persentase perkiraan pertumbuhan traffic dalam 2 hingga 3 menit ke depan. Dalam uji beban yang Anda jalankan sebelumnya, 0% hingga 150% merupakan contoh pertumbuhan yang agak ekstrem. Oleh karena itu, sebagai gantinya, bayangkan pertumbuhan traffic yang lebih lazim yakni 30%.
Dengan angka-angka ini, Anda dapat menghitung buffer pengaman yakni sekitar 65%. Artinya, Anda sebaiknya melakukan overprovision resource sekitar 65% untuk menangani peningkatan skala sekaligus meminimalkan masalah.
Salah satu strategi yang efisien untuk melakukan overprovision pada cluster dengan Autoscaling Cluster adalah dengan menggunakan Pause Pod.
Pause Pod adalah deployment berprioritas rendah yang dapat dihapus dan diganti dengan deployment berprioritas tinggi. Hal ini berarti Anda dapat membuat pod berprioritas rendah yang tidak melakukan apa-apa selain mereservasi ruang buffer. Saat pod berprioritas lebih tinggi memerlukan ruang, pause pod akan dihapus dan dijadwalkan ulang ke node lain, atau ke node baru, sedangkan pod dengan prioritas lebih tinggi memiliki ruang yang diperlukan agar dapat dijadwalkan dengan cepat.
Amati bagaimana node baru dibuat (kemungkinan besar di node pool baru) untuk disesuaikan dengan pause pod yang baru dibuat. Sekarang, jika Anda menjalankan uji beban lagi, saat Anda memerlukan node ekstra untuk deployment php-apache, deployment tersebut dapat dijadwalkan di node yang menampung pause pod, sementara pause pod Anda ditempatkan di node baru. Cara ini sangat baik karena pause pod dummy Anda memungkinkan cluster menyediakan node baru di awal sehingga aplikasi yang sebenarnya dapat ditingkatkan skalanya lebih cepat. Jika menginginkan volume traffic yang lebih tinggi, Anda dapat menambahkan lebih banyak pause pod, tetapi sebagai praktik terbaik, jangan tambahkan lebih dari satu pause pod per node.
Klik Check my progress untuk memastikan Anda telah menjalankan tugas di atas.
Selamat! Dalam lab ini, Anda telah mengonfigurasi cluster untuk menaikkan atau menurunkan skala secara otomatis dan efisien berdasarkan permintaan. Penskalaan Otomatis Pod Horizontal dan Penskalaan Otomatis Pod Vertikal menawarkan solusi untuk menskalakan deployment cluster secara otomatis, sedangkan Autoscaler Cluster dan Penyediaan Otomatis Node memberikan solusi untuk otomatis menskalakan infrastruktur cluster.
Seperti biasa, alat mana yang sebaiknya digunakan bergantung pada workload Anda. Dengan menggunakan autoscaler ini secara cermat, Anda akan dapat memaksimalkan ketersediaan pada saat diperlukan, sekaligus membayar hanya untuk resource yang Anda perlukan selama periode permintaan rendah. Dari perspektif biaya, hal ini berarti Anda dapat mengoptimalkan penggunaan resource dan menghemat uang.
Lihat referensi berikut untuk mempelajari lebih lanjut topik yang dibahas dalam lab ini:
...membantu Anda mengoptimalkan teknologi Google Cloud. Kelas kami mencakup keterampilan teknis dan praktik terbaik untuk membantu Anda memahami dengan cepat dan melanjutkan proses pembelajaran. Kami menawarkan pelatihan tingkat dasar hingga lanjutan dengan opsi on demand, live, dan virtual untuk menyesuaikan dengan jadwal Anda yang sibuk. Sertifikasi membantu Anda memvalidasi dan membuktikan keterampilan serta keahlian Anda dalam teknologi Google Cloud.
Manual Terakhir Diperbarui: 01 Februari 2024
Lab Terakhir Diuji: 20 September 2023
Hak cipta 2025 Google LLC Semua hak dilindungi undang-undang. Google dan logo Google adalah merek dagang dari Google LLC. Semua nama perusahaan dan produk lain mungkin adalah merek dagang masing-masing perusahaan yang bersangkutan.



Konten ini tidak tersedia untuk saat ini
Kami akan memberi tahu Anda melalui email saat konten tersedia

Bagus!
Kami akan menghubungi Anda melalui email saat konten tersedia

One lab at a time
Confirm to end all existing labs and start this one