








Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Provision testing environment
/ 20
Scale pods with Horizontal Pod Autoscaling
/ 20
Scale size of pods with Vertical Pod Autoscaling
/ 20
Cluster autoscaler
/ 20
Node Auto Provisioning
/ 10
Optimize larger loads
/ 10
Google Kubernetes Engine에는 인프라는 물론 포드 자동 확장을 위한 수평 및 수직 솔루션이 포함되어 있습니다. 비용 최적화 측면에서 이러한 도구는 가능한 한 워크로드를 효율적으로 실행하고 사용한 만큼만 비용을 지불하도록 보장하는 데 매우 유용합니다.
이 실습에서는 포드 수준의 확장을 위한 수평형 포드 자동 확장 및 수직형 포드 자동 확장, 노드 수준 확장을 위한 클러스터 자동 확장 처리(수평 인프라 솔루션) 및 노드 자동 프로비저닝(수직 인프라 솔루션)을 설정하고 관찰합니다. 먼저 자동 확장 도구를 사용해서 가능한 한 많은 리소스를 저장하고 수요가 낮은 기간 동안은 클러스터 크기를 축소합니다. 그런 다음 클러스터 수요를 늘리고 자동 확장의 가용성이 어떻게 유지되는지 관찰합니다.
이 실습에서는 다음 작업을 수행하는 방법을 배웁니다.
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머에는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지 표시됩니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 직접 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
실습 시작 버튼을 클릭합니다. 실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 팝업이 열립니다. 왼쪽에는 다음과 같은 항목이 포함된 실습 세부정보 패널이 있습니다.
Google Cloud 콘솔 열기를 클릭합니다(Chrome 브라우저를 실행 중인 경우 마우스 오른쪽 버튼으로 클릭하고 시크릿 창에서 링크 열기를 선택합니다).
실습에서 리소스가 가동되면 다른 탭이 열리고 로그인 페이지가 표시됩니다.
팁: 두 개의 탭을 각각 별도의 창으로 나란히 정렬하세요.
필요한 경우 아래의 사용자 이름을 복사하여 로그인 대화상자에 붙여넣습니다.
실습 세부정보 패널에서도 사용자 이름을 확인할 수 있습니다.
다음을 클릭합니다.
아래의 비밀번호를 복사하여 시작하기 대화상자에 붙여넣습니다.
실습 세부정보 패널에서도 비밀번호를 확인할 수 있습니다.
다음을 클릭합니다.
이후에 표시되는 페이지를 클릭하여 넘깁니다.
잠시 후 Google Cloud 콘솔이 이 탭에서 열립니다.

Cloud Shell은 다양한 개발 도구가 탑재된 가상 머신으로, 5GB의 영구 홈 디렉터리를 제공하며 Google Cloud에서 실행됩니다. Cloud Shell을 사용하면 명령줄을 통해 Google Cloud 리소스에 액세스할 수 있습니다.
 를 클릭합니다.
를 클릭합니다.연결되면 사용자 인증이 이미 처리된 것이며 프로젝트가 PROJECT_ID로 설정됩니다. 출력에 이 세션의 PROJECT_ID를 선언하는 줄이 포함됩니다.
gcloud는 Google Cloud의 명령줄 도구입니다. Cloud Shell에 사전 설치되어 있으며 명령줄 자동 완성을 지원합니다.
승인을 클릭합니다.
다음과 비슷한 결과가 출력됩니다.
출력:
출력:
출력 예시:
gcloud 전체 문서는 Google Cloud에서 gcloud CLI 개요 가이드를 참조하세요.
수평형 포드 자동 확장을 시연하는 데 도움이 되도록 이 실습에서는 php-apache 이미지 기반의 커스텀 Docker 이미지를 사용합니다. 이 이미지는 CPU 집약적인 계산을 수행하는 index.php 페이지를 정의합니다. 이 이미지의 배포를 모니터링합니다.
php-apache 배포의 매니페스트를 만듭니다.내 진행 상황 확인하기를 클릭하여 위 작업을 올바르게 수행했는지 확인합니다.
수평형 포드 자동 확장은 워크로드의 CPU 또는 메모리 소비에 대응하거나 Kubernetes 내에서 보고되는 커스텀 측정항목 또는 클러스터 외부 소스의 외부 측정항목에 대응하여 포드 수를 자동으로 늘리거나 줄임으로써 Kubernetes 워크로드의 형태를 변경합니다.
3/3 포드가 실행되는 php-apache 배포가 표시됩니다.
php-apache 배포에 수평 자동 확장을 적용합니다.내 진행 상황 확인하기를 클릭하여 위 작업을 올바르게 수행했는지 확인합니다.
이 autoscale 명령어는 수평형 포드 자동 확장 처리를 구성하여 php-apache 배포에서 제어되는 포드의 복제본을 1~10개 사이로 유지합니다. cpu-percent 플래그는 모든 포드에서 요청된 CPU의 목표 평균 CPU 사용률을 50%로 지정합니다. HPA(수평형 포드 자동 확장 처리)는 모든 포드에서 평균 CPU 사용률을 50%로 유지하도록 배포를 통해 복제본 수를 조정합니다.
목표 열에 1%/50%가 표시됩니다.
즉, 배포 내의 포드가 현재 목표 평균 CPU 사용률의 1%입니다. 이는 php-apache 앱이 현재 트래픽을 수신하고 있지 않기 때문에 예상되는 동작입니다.
kubectl get hpa 명령어를 다시 실행합니다. HPA에서 아직 평가를 생성하지 않았습니다. 또한 복제본 열에 주목합니다. 처음 시작할 때 값은 3입니다. 이 숫자는 필요한 포드 수가 변경될 때 자동 확장 처리에 따라 변경됩니다.
여기에서 자동 확장 처리는 autoscale 명령어를 실행할 때 표시된 최소 포드 수로 배포를 축소합니다. 수평형 포드 자동 확장에는 5~10분이 걸리고 확장 방법에 따라 새 포드를 종료하거나 시작해야 합니다.
이 실습의 다음 단계를 계속 진행합니다. 자동 확장 처리 결과를 나중에 검사할 수 있습니다.
cpu-percent를 사용하는 경우 HPA는 커스텀 측정항목의 정의를 허용하여 사용자가 로그에 캡처된 다른 유용한 측정항목을 기준으로 포드를 확장할 수 있게 합니다.수직형 포드 자동 확장을 사용하면 컨테이너의 CPU 및 메모리 요청에 어떤 값을 지정해야 할지를 고민하지 않아도 됩니다. 자동 확장 처리는 CPU 및 메모리의 요청 및 한도 값을 추천하거나 값을 자동으로 업데이트할 수 있습니다.
수직형 포드 자동 확장은 scaling-demo 클러스터에 이미 사용 설정되어 있습니다.
출력에 enabled: true가 표시됩니다.
gcloud container clusters update scaling-demo --enable-vertical-pod-autoscaling 명령어로 사용 설정할 수 있습니다.VPA를 시연하기 위해 hello-server 앱을 배포하겠습니다.
hello-server 배포를 적용합니다.hello-server 포드의 컨테이너 사양을 조사합니다.위 코드는 업데이트 정책이 사용 중지된 hello-server 배포를 대상으로 하는 수직형 포드 자동 확장 처리의 매니페스트를 생성합니다. VPA는 애플리케이션에 따라 유용할 수 있는 3개의 서로 다른 업데이트 정책 중 하나를 포함할 수 있습니다.
hello-vpa의 매니페스트를 적용합니다.VerticalPodAutoscaler를 확인합니다.출력 끝에서 'Container Recommendations'를 찾습니다. 표시되지 않으면 잠시 더 기다린 후 이전 명령어를 다시 시도합니다. 표시되면 CPU 및 메모리 값과 함께 여러 다른 추천 유형을 볼 수 있습니다.
요청할 메모리 양에 대한 추천 값 외에도 VPA에서 이 컨테이너의 CPU 요청을 이전의 100m 대신 25m로 설정하도록 추천하는 것을 볼 수 있습니다. 이 시점에서 이러한 추천은 hello-server 배포에 수동으로 적용할 수 있습니다.
이 실습 내에서는 VPA와 해당 효과를 관찰하기 위해서 hello-vpa 업데이트 정책을 자동으로 변경하고 확장을 관찰합니다.
정책을 자동으로 설정하도록 매니페스트를 업데이트하고 구성을 적용합니다.
포드 크기를 조절하기 위해서는 수직형 포드 자동 확장 처리가 포드를 삭제하고 새 크기로 포드를 다시 만들어야 합니다. 기본적으로 다운타임을 방지하기 위해 VPA는 마지막 활성 포드를 삭제하고 크기를 조절하지 않습니다. 따라서 VPA로 인한 변경사항을 확인하기 위해서는 복제본이 2개 이상 필요합니다.
hello-server 배포를 2개의 복제본으로 확장합니다.hello-server-xxx 포드 상태가 종료 중 또는 대기 중으로 표시될 때까지 기다립니다(또는 Kubernetes Engine > 워크로드로 이동).이는 VPA가 포드를 삭제하고 크기를 조절 중임을 나타내는 신호입니다. 이 신호가 표시되면 Ctrl + c를 눌러서 명령어를 종료합니다.
내 진행 상황 확인하기를 클릭하여 위 작업을 올바르게 수행했는지 확인합니다.
이제 수평형 포드 자동 확장 처리로 php-apache 배포가 축소되었을 것입니다.
php-apache 배포가 1개 포드로 축소된 것을 볼 수 있습니다.php-apache 배포 복제본이 여전히 3개 표시되면 자동 확장 처리가 작업을 수행할 때까지 몇 분 더 기다려야 합니다.php-apache 앱의 수요가 증가하면 해당 부하를 고려해서 백업을 확장합니다.이는 특히 비용 최적화를 고려할 때 유용합니다. 잘 조정된 자동 확장 처리의 경우 애플리케이션을 고가용성 상태로 유지하면서도 수요와 관계없이 해당 가용성을 유지하는 데 필요한 리소스에 대해서만 비용을 지불할 수 있습니다.
이제 VPA로 hello-server 배포의 포드 크기를 조절했습니다.
kubectl set resources deployment hello-server --requests=cpu=25m 명령어를 사용해서 CPU 리소스를 목표로 수동 설정합니다. 경우에 따라 자동 모드의 VPA 시간이 오래 걸리거나 정확한 데이터를 수집하는 시간이 없어 부정확한 상한값 또는 하한값이 설정될 수 있습니다. 실습 시간을 아끼기 위해 '사용 중지' 모드일 때의 추천을 따르면 간단히 해결됩니다. 여기에서는 VPA가 리소스 사용률을 최적화하여 결과적으로 비용을 절약할 수 있는 훌륭한 도구입니다. 원래 요청인 CPU 400m는 이 컨테이너에 필요한 것보다 높은 값이었습니다. 요청을 추천 값인 25m로 조정하면 노드 풀에서 사용하는 CPU를 줄이고 잠재적으로 클러스터에 프로비저닝해야 하는 노드를 줄일 수 있습니다.
자동 업데이트 정책에서 VPA는 전체 기간 동안 걸쳐서 hello-server 배포의 포드를 계속 삭제하고 크기를 조절합니다. 많은 트래픽을 처리하기 위해 요청 수를 늘려 포드를 확장한 후 다운타임 중에 요청 수를 줄일 수 있습니다. 이렇게 하면 애플리케이션 수요가 지속적으로 증가할 때 유용할 수 있지만 사용량이 급증할 때 가용성을 잃을 위험이 있습니다.
애플리케이션에 따라 사용 중지 업데이트 정책과 함께 VPA를 사용하고, 리소스 사용 최적화와 클러스터 가용성 극대화를 위해 필요에 따라 추천을 따르는 것이 일반적으로 안전합니다.
다음 섹션에서는 클러스터 자동 확장 처리 및 노드 자동 프로비저닝으로 리소스 사용률을 최적화하는 방법을 살펴봅니다.
클러스터 자동 확장 처리는 수요에 따라 노드를 추가하거나 삭제하도록 설계되어 있습니다. 수요가 높으면 클러스터 자동 확장 처리가 이러한 수요를 수용하기 위해 노드 풀에 노드를 추가합니다. 수요가 낮으면 클러스터 자동 확장 처리가 노드를 삭제하여 클러스터를 다시 축소합니다. 이렇게 하면 추가 머신과 관련된 불필요한 비용을 최소화하면서 클러스터를 고가용성 상태로 유지할 수 있습니다.
완료되기까지 몇 분 정도 걸립니다.
클러스터를 확장할 때 노드 삭제 시기를 결정하기 위해서는 사용률 최적화와 리소스 가용성 간의 절충이 필요합니다. 사용률이 낮은 노드를 삭제하면 클러스터 사용률이 향상되지만, 새 워크로드를 실행하려면 리소스가 다시 프로비저닝될 때까지 기다려야 할 수 있습니다.
이러한 결정을 내릴 때 사용할 자동 확장 프로필을 지정할 수 있습니다. 현재 사용 가능한 프로필은 다음과 같습니다.
optimize-utilization 자동 확장 프로필로 전환합니다.자동 확장이 사용 설정된 상태로 Cloud 콘솔에서 클러스터를 관찰합니다. 왼쪽 상단의 막대 3개를 클릭하여 탐색 메뉴를 엽니다.
탐색 메뉴에서 Kubernetes Engine > 클러스터를 선택합니다.
클러스터 페이지에서 scaling-demo 클러스터를 선택합니다.
scaling-demo 클러스터 페이지에서 노드 탭을 선택합니다.
노드 3개에 대해 요청한 CPU 및 CPU 할당 가능 값을 조합할 경우 합계는 각각 1,555m 및 2,820m입니다. 즉, 전체 클러스터에서 CPU 총 1,265m를 사용할 수 있습니다. 이는 하나의 노드에서 제공할 수 있는 값보다 큽니다.
사용률을 최적화하기 위해 현재 수요의 현재 워크로드는 3개가 아닌 2개의 노드에 통합할 수 있습니다. 하지만 클러스터는 아직 자동으로 축소되지 않았습니다. 이는 클러스터 전체에 배포된 시스템 포드 때문입니다.
클러스터는 kube-system 네임스페이스 아래에서 여러 배포를 실행하여 로깅, 모니터링, 자동 확장 등의 여러 GKE 서비스가 작동하도록 합니다.
기본적으로 이러한 배포에서 대부분의 시스템 포드는 클러스터 자동 확장 처리가 이를 완전히 오프라인으로 전환해서 다시 예약할 수 없도록 방지합니다. 일반적으로 이러한 포드가 다른 배포 및 서비스에 사용된 데이터를 수집하기 때문에 이렇게 하는 것이 좋습니다. 예를 들어 metrics-agent가 일시적으로 작동 중지되면 VPA 및 HPA에 대해 수집된 데이터에 격차가 발생합니다. 또는 fluentd 포드가 작동 중지되면 클라우드 로그에 격차가 발생할 수 있습니다.
이 실습에서는 클러스터 자동 확장 처리가 다른 노드에서 안전하게 포드를 다시 예약할 수 있도록 포드 중단 예산을 kube-system 포드에 적용해 봅니다. 이렇게 하면 클러스터를 축소할 충분한 공간을 확보할 수 있습니다.
포드 중단 예산(PDB)은 Kubernetes가 업그레이드, 포드 삭제, 리소스 부족 등의 중단 문제를 처리하는 방법을 정의합니다. PDB에서는 배포에 포함할 포드의 max-unavailable 또는 min-available 값을 지정할 수 있습니다.
kube-system 포드에 대해 포드 중단 예산을 만듭니다.내 진행 상황 확인하기를 클릭하여 위 작업을 올바르게 수행했는지 확인합니다.
이러한 각 명령어에서는 생성 시 정의된 라벨에 따라 다른 kube-system 배포 포드를 선택하고 이러한 각 배포에 대해 1개의 사용 불가능한 포드가 있을 수 있도록 지정합니다. 이렇게 하면 자동 확장 처리가 시스템 포드를 다시 예약할 수 있습니다.
PDB를 적용하면 클러스터의 노드가 1~2분 정도 내에 3개에서 2개로 축소됩니다.
Cloud 콘솔에서 scaling-demo의 노드 탭을 새로고침하여 리소스가 패키징된 방식을 조사합니다.
지금까지 노드 3개에서 2개로 클러스터를 축소하는 자동화를 설정했습니다.
노드 풀 축소에 따른 비용을 고려하면 클러스터에서 수요가 낮은 기간 동안 더 적은 머신에 대한 비용이 청구됩니다. 이러한 확장은 하루 중 수요가 높은 기간에서 낮은 기간으로 자주 변동될 때 더 극적일 수 있습니다.
클러스터 자동 확장 처리로 불필요한 노드를 삭제하면서 수직형 포드 자동 확장 및 수평형 포드 자동 확장을 통해 노드가 더 이상 필요하지 않도록 CPU 수요를 충분히 줄였다는 점을 주목해야 합니다. 이러한 도구를 조합하면 전반적인 비용과 리소스 사용량을 효과적으로 최적화할 수 있습니다.
따라서 클러스터 자동 확장 처리는 예약이 필요한 포드에 대한 응답으로 노드를 추가 및 삭제하는 데 도움이 됩니다. 하지만 GKE에는 노드 자동 프로비저닝이라고 부르는 또 다른 수직 확장 기능이 있습니다.
노드 자동 프로비저닝(NAP)은 실제로 수요를 충족하도록 크기가 조절된 새 노드 풀을 추가합니다. 노드 자동 프로비저닝이 없으면 클러스터 자동 확장 처리가 지정된 노드 풀에서만 새 노드를 만듭니다. 즉, 새 노드는 해당 풀에 있는 다른 노드와 동일한 머신 유형입니다. 이는 기존 풀에 노드를 추가할 때보다 특정 사용 사례에 맞게 특별히 최적화된 노드 풀을 만들 때 긴 시간이 걸리기 때문에 극한의 확장이 필요하지 않은 일괄 워크로드 및 기타 앱에서 리소스 사용을 최적화하는 데 이상적입니다.
이 명령어에서는 CPU 및 메모리 리소스에 대한 최솟값과 최댓값을 지정합니다. 이는 전체 클러스터에 사용됩니다.
NAP는 약간 더 긴 시간을 소모하며 현재 상태에서 scaling-demo 클러스터에 대해 새 노드 풀을 만들지 않을 가능성이 높습니다.
다음 섹션에서는 클러스터 수요를 늘리고 NAP 및 자동 확장 처리의 동작을 관찰합니다.
내 진행 상황 확인하기를 클릭하여 위 작업을 올바르게 수행했는지 확인합니다.
지금까지 애플리케이션 수요가 낮을 때 HPA, VPA, 클러스터 자동 확장 처리를 통해 리소스 및 비용을 줄이는 방법을 살펴봤습니다. 이제는 수요가 증가했을 때 이러한 도구로 가용성을 처리하는 방법을 살펴보겠습니다.
php-apache 서비스로 전송합니다.원래 Cloud Shell 탭으로 돌아갑니다.
1분 정도 내에 다음을 실행하여 HPA에서 높은 CPU 부하를 확인합니다.
잠시 기다렸다가 목표가 100%를 넘으면 명령어를 다시 실행합니다.
또한 Cloud 콘솔에서 노드 탭을 새로고침하여 클러스터를 모니터링할 수 있습니다.
몇 분 후 몇 가지 결과가 발생합니다.
php-apache 배포를 자동으로 수직 확장합니다.php-apache 배포가 복제본 최대 7개로 수직 확장되고 노드 탭이 다음과 비슷하게 표시될 때까지 기다립니다.
클러스터가 높은 수요를 충족하도록 효과적으로 수직 확장되었습니다! 하지만 이러한 수요 급증을 처리하는 데 걸린 시간이 얼마나 되는지 확인하세요. 많은 애플리케이션에서는 새 리소스를 프로비저닝하는 동안 가용성 손실 문제가 발생할 수 있습니다.
더 큰 부하를 위해 수직 확장할 때 수평형 포드 자동 확장은 새 포드를 추가하고 수직형 포드 자동 확장은 설정에 따라 포드 크기를 조절합니다. 기존 노드에 공간이 없으면 이미지 가져오기를 건너뛰고 새 포드에서 애플리케이션 실행을 즉시 시작할 수 있습니다. 애플리케이션을 배포한 적이 없는 노드로 작업하는 경우 필요에 따라 실행 전 컨테이너 이미지를 다운로드해야 하므로 시간이 약간 추가될 수 있습니다.
따라서 기존 노드에 공간이 충분하지 않고 클러스터 자동 확장 처리를 사용할 때는 시간이 더 오래 걸릴 수 있습니다. 이제 새 노드를 프로비저닝하고, 설정하고, 이미지를 다운로드하고, 포드를 시작해야 합니다. 노드 자동 프로비저닝 도구가 클러스터에서처럼 새 노드 풀을 만들려는 경우 새 노드 풀을 먼저 프로비저닝하고 이후 새 노드에 대해 동일한 단계를 진행해야 하므로 시간이 더 오래 걸립니다.
자동 확장에 대해 다양한 지연 시간을 처리하기 위해서는 자동 수직 확장 시 앱에 대한 부담이 줄어들도록 약간 과도하게 프로비저닝하는 것이 좋을 수 있습니다. 이는 특히 비용 최적화 측면에서 중요합니다. 필요보다 많은 리소스에 대해 비용을 지불하는 것은 좋지 않지만 앱 성능이 저하되어서도 안 되기 때문입니다.
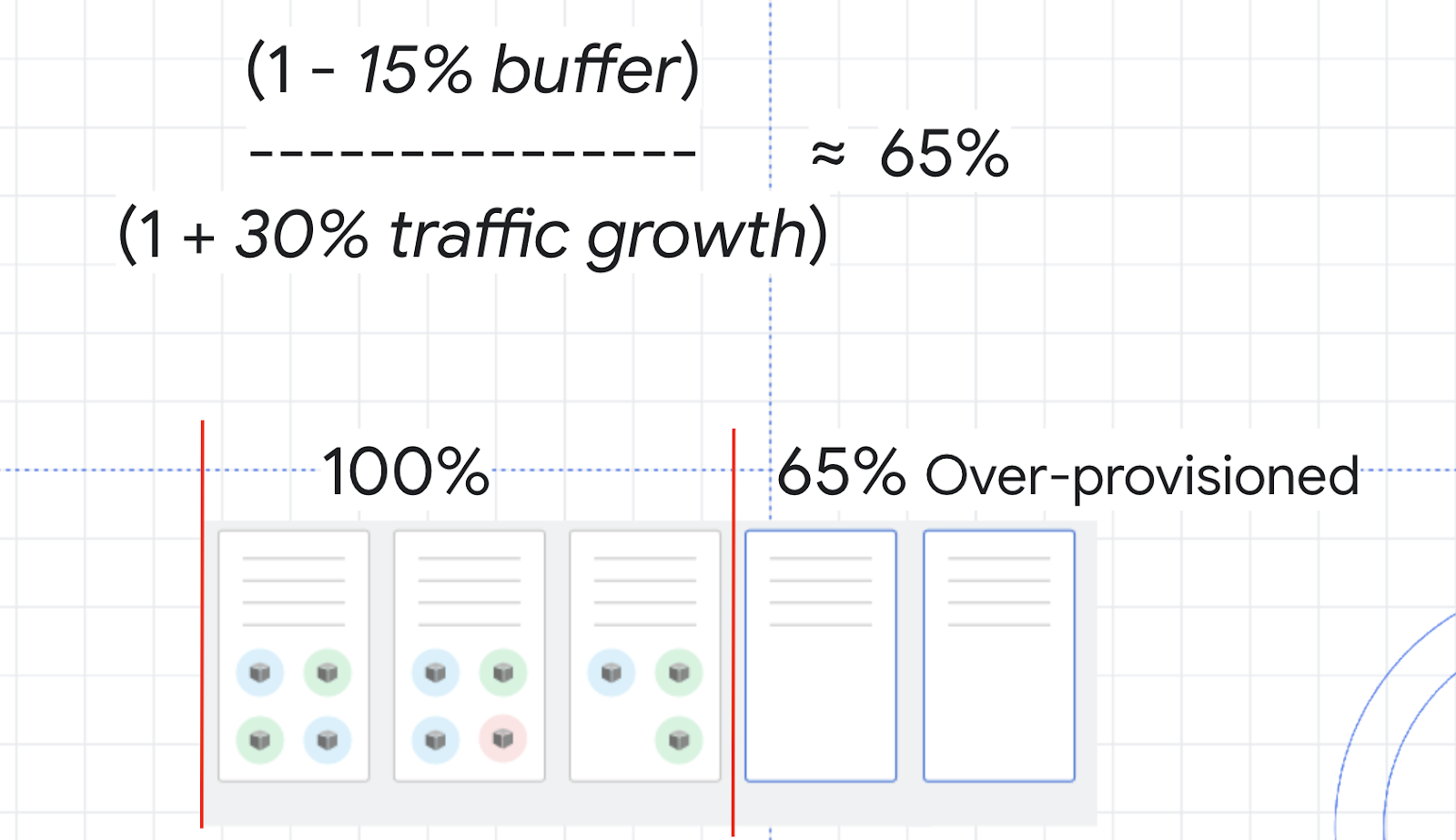
얼마나 과도하게 프로비저닝해야 하는지 파악하기 위해서는 다음 수식을 사용할 수 있습니다.
예를 들어 클러스터의 CPU 사용률을 조정한다고 가정해 보세요. 사용률이 100%에 도달하지 않도록 안전한 거리를 유지하기 위해 버퍼를 15%로 선택할 수 있을 것입니다. 수식에서 트래픽 변수는 다음 2~3분 동안 예상되는 트래픽 증가율입니다. 앞서 실행한 부하 테스트에서 0%~150%는 다소 극단적인 성장 사례였으므로 대신 평균적인 트래픽 증가율인 30%라고 가정해 보세요.
이러한 값을 사용하면 약 65% 정도의 안전 버퍼를 계산할 수 있습니다. 즉, 문제를 최소화하면서 수직 확장을 해결하기 위해 약 65% 정도로 리소스를 과도하게 프로비저닝할 수 있습니다.
클러스터 자동 확장을 사용해서 클러스터를 과도하게 프로비저닝하는 효율적인 전략은 일시중지 포드를 사용하는 것입니다.
일시중지 포드는 높은 우선순위 배포에 따라 삭제 및 대체될 수 있는 낮은 우선순위 배포입니다. 즉, 버퍼 공간 예약을 제외하고 어떤 작업도 실제로 수행하지 않는 낮은 우선순위 포드를 만들 수 있습니다. 높은 우선순위 포드에 공간이 필요하면 일시중지 포드를 삭제하고 다른 노드 또는 새 노드에 다시 예약하여 우선순위가 높은 포드가 즉시 예약될 수 있게 합니다.
새 노드가 어떻게 생성되었는지 관찰합니다. 새 노드 풀에서 새로 생성된 일시중지 포드에 맞게 생성되었을 것입니다. 이제 부하 테스트를 다시 실행할 때 php-apache 배포에 추가 노드가 필요한 경우 일시중지 포드가 있는 노드에서 노드를 예약할 수 있습니다. 그러면 일시중지 포드는 새 노드에 배치됩니다. 이 방법은 더미 일시중지 포드를 통해 클러스터가 미리 새 노드를 프로비저닝하여 실제 애플리케이션을 훨씬 빠르게 수직 확장할 수 있기 때문에 유용합니다. 트래픽이 더 높을 것으로 예상되는 경우 일시중지 포드를 더 추가할 수 있지만 노드당 2개 이상의 일시중지 포드를 추가하는 것은 권장되지 않습니다.
내 진행 상황 확인하기를 클릭하여 위 작업을 올바르게 수행했는지 확인합니다.
수고하셨습니다. 이 실습에서는 수요에 따라 효과적으로 자동 수직 확장/축소하도록 클러스터를 구성했습니다. 수평형 포드 자동 확장과 수직형 포드 자동 확장은 클러스터 배포를 자동으로 확장하기 위한 솔루션을 제공하며, 클러스터 자동 확장 처리와 노드 자동 프로비저닝은 클러스터 인프라를 자동으로 확장하기 위한 솔루션을 제공합니다.
언제나처럼 이러한 도구 중 무엇을 사용할지는 워크로드에 따라 달라집니다. 이러한 자동 확장 처리를 신중하게 사용하여 필요할 때 가용성을 극대화하고 수요가 낮은 기간에는 필요한 리소스에 대해서만 비용을 지불할 수 있습니다. 비용 측면에서 볼 때 리소스 사용량을 최적화하고 비용을 절약할 수 있습니다.
이 실습에서 다뤄진 주제에 대해 자세히 알아보려면 다음 리소스를 확인하세요.
Google Cloud 기술을 최대한 활용하는 데 도움이 됩니다. Google 강의에는 빠른 습득과 지속적인 학습을 지원하는 기술적인 지식과 권장사항이 포함되어 있습니다. 기초에서 고급까지 수준별 학습을 제공하며 바쁜 일정에 알맞은 주문형, 실시간, 가상 옵션이 포함되어 있습니다. 인증은 Google Cloud 기술에 대한 역량과 전문성을 검증하고 입증하는 데 도움이 됩니다.
설명서 최종 업데이트: 2024년 2월 1일
실습 최종 테스트: 2023년 9월 20일
Copyright 2025 Google LLC All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.



현재 이 콘텐츠를 이용할 수 없습니다
이용할 수 있게 되면 이메일로 알려드리겠습니다.

감사합니다
이용할 수 있게 되면 이메일로 알려드리겠습니다.

One lab at a time
Confirm to end all existing labs and start this one