








Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Provision testing environment
/ 20
Scale pods with Horizontal Pod Autoscaling
/ 20
Scale size of pods with Vertical Pod Autoscaling
/ 20
Cluster autoscaler
/ 20
Node Auto Provisioning
/ 10
Optimize larger loads
/ 10
O Google Kubernetes Engine tem soluções horizontais e verticais para escalonar automaticamente os pods e a infraestrutura. Quando o assunto é otimização de custos, essas ferramentas são muito úteis para que as cargas de trabalho sejam executadas com máxima eficiência e você pague apenas pelo que usar.
Neste laboratório, você vai configurar e observar os escalonamentos automáticos horizontal e vertical no nível do pod e também o escalonador automático de clusters (solução de infraestrutura horizontal) e o provisionamento automático de nós (solução de infraestrutura vertical) no nível do nó. Primeiro, você vai usar essas ferramentas de escalonamento automático para poupar o máximo de recursos possível e reduzir o tamanho do cluster durante um período de baixa demanda. Depois, você vai aumentar as demandas do cluster e observar como o escalonamento automático mantém a disponibilidade.
Neste laboratório, você vai aprender a:
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você vai encontrar o seguinte:
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
Você também encontra o Nome de usuário no painel Detalhes do laboratório.
Clique em Seguinte.
Copie a Senha abaixo e cole na caixa de diálogo de boas-vindas.
Você também encontra a Senha no painel Detalhes do laboratório.
Clique em Seguinte.
Acesse as próximas páginas:
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.

O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
 na parte de cima do console do Google Cloud.
na parte de cima do console do Google Cloud.Depois de se conectar, vai notar que sua conta já está autenticada, e que o projeto está configurado com seu PROJECT_ID. A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
Clique em Autorizar.
A saída será parecida com esta:
Saída:
Saída:
Exemplo de saída:
gcloud, acesse o guia com informações gerais sobre a gcloud CLI no Google Cloud.
Para demonstrar o escalonamento automático horizontal de pods, este laboratório usa uma imagem Docker personalizada com base na imagem do php-apache. Ela define uma página index.php que executa alguns cálculos com uso intensivo da CPU. Você vai monitorar uma implantação dessa imagem.
php-apache:Clique em Verificar meu progresso para conferir se você executou a tarefa.
O escalonamento automático horizontal de pods muda a forma da carga de trabalho do Kubernetes, aumentando ou diminuindo automaticamente o número de pods em resposta ao consumo de memória ou CPU da carga de trabalho ou às métricas personalizadas informadas no Kubernetes ou às métricas externas fora do cluster.
A implantação do php-apache vai aparecer com 3/3 pods em execução:
php-apache:Clique em Verificar meu progresso para conferir se você executou a tarefa.
O comando autoscale configura um escalonador automático horizontal de pods (HPA) que mantém de uma a 10 réplicas dos pods controladas pela implantação do php-apache. A flag cpu-percent especifica 50% como a meta média de utilização da CPU solicitada em todos os pods. O HPA ajusta o número de réplicas (via implantação) para manter uma utilização média da CPU de 50% em todos os pods.
Na coluna Destinos, você vai encontrar 1%/50%.
Isso significa que os pods da sua implantação estão em 1% do uso médio desejado da CPU. Isso é esperado porque o app php-apache não está recebendo tráfego no momento.
kubectl get hpa de novo. O HPA ainda não criou uma avaliação. Além disso, observe a coluna Replicas. No início, o valor será 3. Esse número será alterado pelo escalonador automático à medida que o número de pods necessários mudar.
Nesse caso, o escalonador automático reduz o escalonamento vertical da implantação até o número mínimo de pods indicado quando você executa o comando autoscale. O escalonamento automático horizontal de pods leva de 5 a 10 minutos e requer o desligamento ou a inicialização de novos pods, dependendo de como está escalonando.
Vá para a próxima etapa do laboratório. Você vai inspecionar os resultados do escalonador automático mais adiante.
cpu-percent como a métrica desejada do escalonador automático neste laboratório, o HPA permite a definição de métricas personalizadas para escalonar seus pods com base em outras métricas úteis capturadas nos registros.Com o escalonamento automático vertical de pods, você não precisa se preocupar com os valores a serem especificados para as solicitações de memória e CPU de um contêiner. O escalonador automático (VPA, na sigla em inglês) pode recomendar valores para as solicitações e os limites de CPU e memória ou atualizar os valores automaticamente.
O escalonamento automático vertical de pods já foi ativado no cluster scaling-demo.
A resposta será enabled: true.
gcloud container clusters update scaling-demo --enable-vertical-pod-autoscalingPara demonstrar o VPA, implante o app hello-server.
hello-server ao seu cluster:hello-server do contêiner:O exemplo acima gera um manifesto para um VPA destinado à implantação do hello-server com uma política de atualização Off. Um VPA pode ter uma destas três políticas de atualização, que são úteis dependendo do seu aplicativo:
hello-vpa:VerticalPodAutoscaler:Localize "Container Recommendations" no final da resposta. Se não aparecer, aguarde um pouco mais e tente executar o comando anterior novamente. Quando aparecer, você verá vários tipos de recomendação, cada um com valores de CPU e memória:
Você perceberá que o VPA recomenda que a solicitação de CPU para esse contêiner seja definida como 25m, em vez do valor 100m anterior, além de sugerir um volume de memória a ser solicitado. No momento, essas recomendações podem ser aplicadas manualmente à implantação do hello-server.
Para acompanhar o VPA e os efeitos dele neste laboratório, mude a política de atualização hello-vpa para Auto e observe o escalonamento.
Atualize o manifesto para definir a política como Auto e aplique a configuração:
Para redimensionar um pod, o escalonador automático vertical de pods precisa excluir e recriar o pod com o novo tamanho. Por padrão, para evitar inatividade, o VPA não excluirá nem redimensionará o último pod ativo. Por isso, você precisará de pelo menos duas réplicas para ver o VPA fazer mudanças.
hello-server para duas réplicas:hello-server-xxx no status terminating ou pending (ou acesse Kubernetes Engine > Cargas de trabalho):Esse é um sinal de que o VPA está excluindo e redimensionando seus pods. Depois de ver isso, pressione Ctrl + c para sair do comando.
Clique em Verificar meu progresso para conferir se você executou a tarefa.
Neste momento, o escalonador automático horizontal de pods provavelmente terá reduzido o escalonamento vertical da implantação do php-apache.
php-apache foi reduzido a um pod.php-apache, aguarde mais alguns minutos até o escalonador automático agir.php-apache tivesse mais demanda, ele seria escalonado novamente de acordo com a carga.Isso é extremamente útil para a otimização de custos. Um escalonador automático bem ajustado mantém a alta disponibilidade do seu aplicativo, e você só paga pelos recursos necessários para manter essa disponibilidade em qualquer demanda.
O VPA deve ter redimensionado seus pods na implantação do hello-server.
kubectl set resources deployment hello-server --requests=cpu=25m Às vezes, o VPA no modo automático pode demorar muito ou definir valores imprecisos de limites superiores ou inferiores, sem tempo para coletar dados precisos. Para não perder tempo no laboratório, use a recomendação como se ela estivesse no modo "Off". Nesse caso, o VPA se torna uma ferramenta excelente para otimizar a utilização de recursos e, na verdade, reduzir custos. A solicitação original de 400m de CPU era maior do que a necessidade do contêiner. Ao ajustar a solicitação para o valor 25m recomendado, você usa menos CPU do pool de nós, possivelmente a ponto de exigir o provisionamento de menos nós no cluster.
Com a política de atualização "Auto", o VPA continuaria excluindo e redimensionando os pods da implantação do hello-server durante todo o ciclo de vida. Ele poderia escalonar os pods verticalmente com solicitações maiores para gerenciar o tráfego pesado, depois reduzi-los durante uma inatividade. Isso pode ser ótimo para lidar com os aumentos constantes de demanda do seu aplicativo, mas corre o risco de perder disponibilidade durante picos intensos.
Dependendo do aplicativo, geralmente é mais seguro usar o VPA com a política de atualização Off e seguir as recomendações conforme necessário para otimizar o uso de recursos e maximizar a disponibilidade do cluster.
Nas próximas seções, você vai aprender a otimizar ainda mais a utilização de recursos com o escalonador automático de clusters e o provisionamento automático de nós.
O escalonador automático de clusters foi projetado para adicionar ou remover nós com base na demanda. O escalonador automático de clusters adiciona nós ao pool para atender a uma alta demanda. Quando a demanda é baixa, ele reduz o escalonamento do cluster removendo nós. Dessa forma, é possível manter a alta disponibilidade do cluster e, ao mesmo tempo, minimizar os custos supérfluos associados a máquinas adicionais.
Esse processo leva alguns minutos.
Ao escalonar um cluster, a decisão de quando remover um nó está relacionada à otimização do uso ou à disponibilidade de recursos. Remover nós subutilizados melhora o uso do cluster, mas talvez novas cargas de trabalho precisem esperar que os recursos sejam provisionados novamente antes de serem executadas.
Ao tomar essas decisões, especifique qual perfil de escalonamento automático deve ser usado. Os perfis disponíveis no momento são:
optimize-utilization para observar todos os efeitos do escalonamento:Com o escalonamento automático ativado, observe seu cluster no console do Cloud. Clique nas três barras na parte superior esquerda para abrir o Menu de navegação.
No Menu de navegação, selecione Kubernetes Engine > Clusters.
Na página Clusters, selecione o cluster scaling-demo.
Na página desse cluster, selecione a guia Nós.
Se você combinar os valores de CPU requested e CPU allocatable para os três nós, os totais serão 1555m e 2820m, respectivamente. Isso significa que há um total de 1265m CPUs disponíveis em todo o cluster. Isso é maior do que o que pode ser fornecido por um nó.
Para otimizar a utilização, a carga de trabalho da demanda atual pode ser consolidada em dois nós, em vez de três. No entanto, o escalonamento vertical do cluster ainda não foi reduzido automaticamente. Isso se deve aos pods do sistema distribuídos no cluster.
O cluster executa várias implantações no namespace do kube-system para que os vários serviços do GKE funcionem, como geração de registros, monitoramento, escalonamento automático etc.
Por padrão, a maioria dos pods do sistema dessas implantações impede que o escalonador automático de clusters as deixe completamente off-line para reprogramá-las. Geralmente isso é desejado porque muitos desses pods coletam dados usados em outras implantações e serviços. Por exemplo, ficar temporariamente indisponível em metrics-agent pode causar uma lacuna nos dados coletados para o VPA e o HPA, ou o pod fluentd pode causar uma lacuna nos registros da nuvem.
Neste laboratório, você aplicará orçamentos de interrupção aos pods do kube-system para permitir que o escalonador automático de clusters os reprograme com segurança em outro nó. Com isso, você terá espaço suficiente para reduzir o cluster.
Os orçamentos de interrupção de pod (PDB) definem como o Kubernetes deve lidar com interrupções, como upgrades, remoções de pods, falta de recursos etc. Em PDBs, é possível especificar o número max-unavailable e/ou o min-available dos pods que uma implantação precisa ter.
kube-system:Clique em Verificar meu progresso para conferir se você executou a tarefa.
Em cada um desses comandos, você seleciona um pod de implantação do kube-system diferente com base em um rótulo definido na criação dele, especificando que pode haver um pod indisponível em cada uma dessas implantações. Assim, o escalonador automático poderá reprogramar os pods do sistema.
Com os PDBs em vigor, o cluster reduz o escalonamento vertical de três para dois nós em um ou dois minutos.
No console do Cloud, atualize a guia Nós do cluster scaling-demo para inspecionar como seus recursos foram empacotados:
Você configurou a automação que reduziu o escalonamento do cluster de três para dois nós.
Pensando nos custos, como resultado da redução do escalonamento vertical do pool de nós, você pagará por menos máquinas durante os períodos de baixa demanda no cluster. Esse escalonamento poderia ser ainda mais significativo se você estivesse flutuando dos períodos de alta demanda para os de baixa demanda durante o dia.
É importante observar que, enquanto o escalonador automático de clusters removeu um nó desnecessário, o escalonamento automático vertical de pods e o escalonamento automático horizontal de pods ajudaram a reduzir a demanda de CPU o suficiente para que o nó não fosse mais necessário. Combinar essas ferramentas é uma ótima maneira de otimizar os custos gerais e o uso de recursos.
Portanto, o escalonador automático de clusters adiciona e remove nós em resposta aos pods que precisam ser programados. No entanto, o GKE tem outro recurso para escalonar verticalmente, chamado de provisionamento automático de nós.
O provisionamento automático de nós (NAP, na sigla em inglês) adiciona pools de nós dimensionados para atender à demanda. Sem o provisionamento automático de nós, o escalonador automático de clusters só cria nós nos pools especificados, o que significa que os novos nós têm o mesmo tipo de máquina que os outros nós do pool. Isso é perfeito para otimizar o uso de recursos para cargas de trabalho em lote e outros aplicativos que não precisam de escalonamento extremo, já que a criação de um pool de nós otimizado especificamente para seu caso de uso pode levar mais tempo do que apenas adicionar nós a um pool.
No comando, especifique os números mínimo e máximo para os recursos de CPU e memória. Isso vale para todo o cluster.
O NAP pode levar um pouco de tempo, e é provável que não vai criar um pool de nós para o cluster scaling-demo no estado atual.
Nas próximas seções, você vai aumentar a demanda para o cluster e observar as ações dos seus escalonadores automáticos, além do NAP.
Clique em Verificar meu progresso para conferir se você executou a tarefa.
Até agora, você analisou como o HPA, o VPA e o escalonador automático de clusters podem economizar recursos e reduzir custos quando seu aplicativo está com baixa demanda. Agora você vai ver como essas ferramentas lidam com a disponibilidade para uma maior demanda.
php-apache:Volte para a guia original do Cloud Shell.
Em cerca de um minuto, você verá a carga de CPU mais alta no HPA executando:
Aguarde e execute o comando de novo até aparecer a meta acima de 100%.
Para monitorar o cluster, atualize a guia Nós no console do Cloud.
Depois de um tempo, algumas coisas vão acontecer.
php-apache será escalonada automaticamente pelo HPA para processar o aumento de carga.Aguarde até que a implantação do php-apache seja escalonada em até sete réplicas, e a guia de nós fique parecida com esta:
O cluster foi escalonado verticalmente de maneira eficiente para atender a uma demanda mais alta. No entanto, observe o tempo que levou para lidar com esse aumento na demanda. Para muitos aplicativos, a perda de disponibilidade durante o provisionamento de novos recursos pode ser um problema.
Ao escalonar verticalmente para cargas maiores, o escalonamento automático horizontal de pods vai adicionar novos pods. Já o escalonamento automático vertical de pods vai redimensioná-los de acordo com as configurações. Se houver espaço em um nó atual, talvez seja possível pular a imagem e começar a executar o aplicativo em um novo pod imediatamente. Se você estiver trabalhando com um nó que não tenha implantado o aplicativo antes, um pouco de tempo poderá ser adicionado caso seja necessário fazer o download das imagens do contêiner antes de executá-lo.
Portanto, se você não tiver espaço suficiente nos nós e estiver usando o escalonador automático de clusters, isso poderá demorar ainda mais. Agora ele precisa provisionar um novo nó, configurá-lo, fazer o download da imagem e iniciar os pods. Se o provisionamento automático de nós criar um novo pool de nós como no cluster, haverá ainda mais tempo conforme você provisionar o novo pool de nós para depois executar as mesmas etapas para o novo nó.
Para lidar com essas diferentes latências para o escalonamento automático, convém provisionar um pouco a mais para que haja menos pressão nos seus aplicativos durante o escalonamento automático. Isso é muito importante para a otimização de custos, porque você não quer pagar por mais recursos do que precisa, mas também não quer que o desempenho dos aplicativos seja prejudicado.
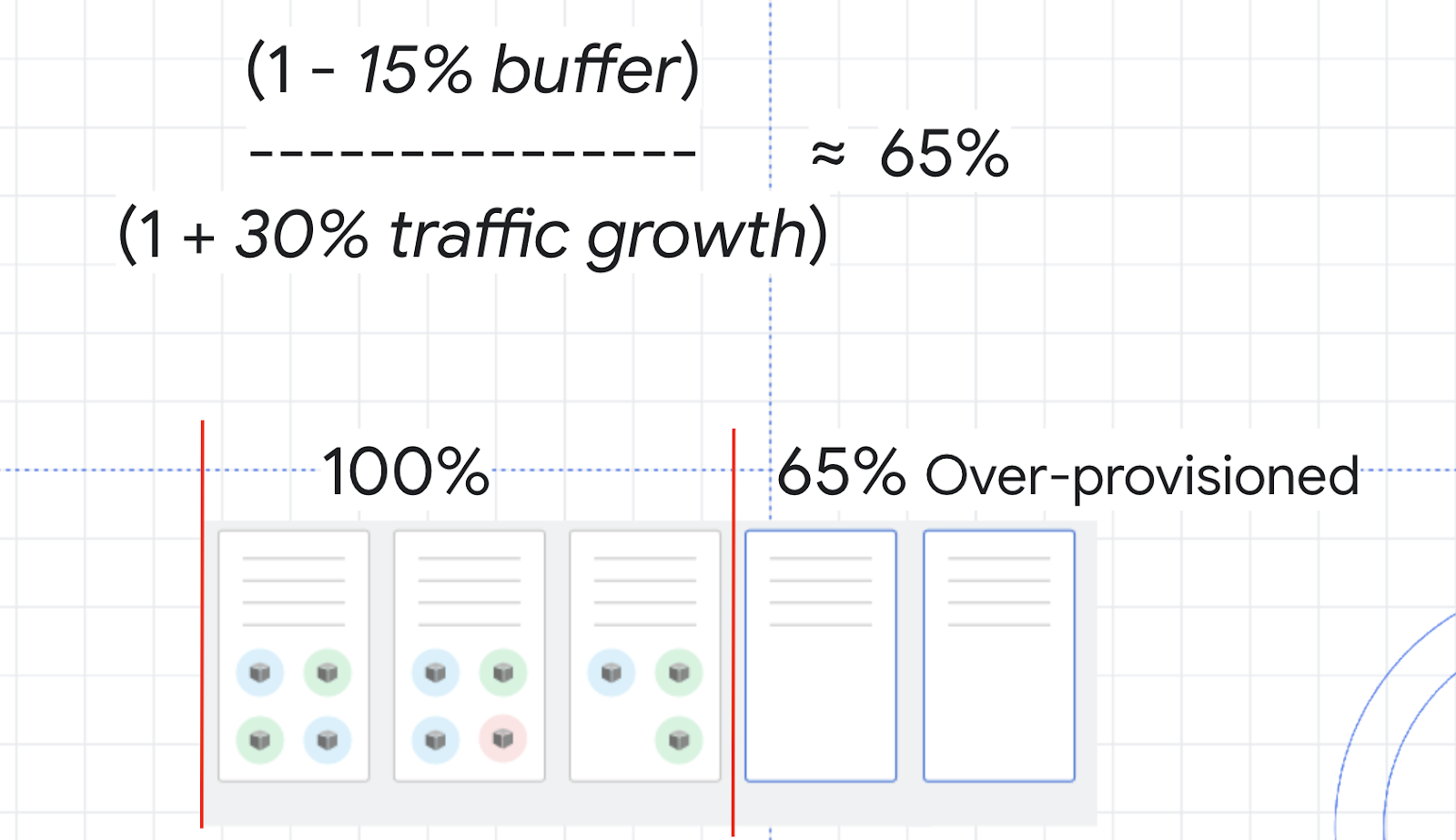
Para descobrir quanto provisionar a mais, use esta fórmula:
Como um exemplo, pense na utilização da CPU para o cluster. É melhor ela não atingir 100%, então você pode escolher um buffer de 15% para manter uma distância segura. A variável de tráfego na fórmula é a porcentagem do aumento de tráfego estimado nos próximos dois a três minutos. No teste de carga que você executou anteriormente, 0% a 150% foi um exemplo de crescimento extremo. Por isso, imagine um crescimento de tráfego médio de 30%.
Com esses números, você pode calcular um buffer de segurança de aproximadamente 65%. Isso significa que convém você provisionar a mais seus recursos em cerca de 65% para lidar com aumentos de escalonamento e minimizar problemas.
Uma estratégia eficiente para aumentar o provisionamento de um cluster com escalonamento automático de clusters é usar pods de pausa.
Pods de pausa são implantações de baixa prioridade que podem ser removidas e substituídas por implantações de alta prioridade. Isso significa que você pode criar pods de baixa prioridade que não fazem nada, exceto reserva de espaço de buffer. Quando o pod de maior prioridade precisa de espaço, os pods de pausa são removidos e reprogramados para outro nó, ou um novo nó, e o pod de maior prioridade tem o espaço de que precisa para ser programado rapidamente.
Observe a criação do novo nó, provavelmente em um novo pool, para se ajustar ao pod de pausa recém-criado. Se você executar o teste de carga novamente, quando precisar de um nó extra para a implantação do php-apache, ele poderá ser programado no nó com o pod de pausa enquanto o pod de pausa estiver em execução em um novo nó. Isso é excelente porque os pods de pausa fictícios permitem que o cluster provisione um novo nó com antecedência para que o aplicativo real possa ser escalonado com mais rapidez. Se você esperar maior tráfego, poderá adicionar mais pods de pausa. No entanto, a prática recomendada é não adicionar mais de um pod de pausa por nó.
Clique em Verificar meu progresso para conferir se você executou a tarefa.
Parabéns! Neste laboratório, você configurou um cluster para diminuir ou aumentar o escalonamento vertical de forma automática e eficiente de acordo com a demanda. Os escalonamentos automáticos de pods horizontal e vertical forneceram soluções para escalonar automaticamente as implantações do cluster. Já o escalonador automático de clusters e o provisionamento automático de nós forneceram soluções para o escalonamento automático da infraestrutura do cluster.
Como sempre, o uso de cada ferramenta vai depender da sua carga de trabalho. Com o uso cuidadoso de escalonadores automáticos, você maximiza a disponibilidade quando precisa e paga apenas o necessário em momentos de baixa demanda. Ao pensar nos custos, você vai otimizar o uso de recursos e economizar dinheiro.
Confira estes recursos para saber mais sobre os tópicos deste laboratório:
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 1º de fevereiro de 2024
Laboratório testado em 20 de setembro de 2023
Copyright 2025 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.



Este conteúdo não está disponível no momento
Você vai receber uma notificação por e-mail quando ele estiver disponível

Ótimo!
Vamos entrar em contato por e-mail se ele ficar disponível

One lab at a time
Confirm to end all existing labs and start this one