Puntos de control
Provision Lab Environment
/ 20
Container-native Load Balancing Through Ingress
/ 20
Load Testing an Application
/ 20
Readiness and Liveness Probes
/ 20
Create Pod Disruption Budgets
/ 20
Optimiza cargas de trabajo de GKE
- GSP769
- Descripción general
- Objetivos
- Configuración y requisitos
- Tarea 1: Configura el balanceo de cargas nativo del contenedor a través de un objeto Ingress
- Tarea 2: Realiza una prueba de carga en una aplicación
- Tarea 3: Configura sondeos de preparación y funcionamiento
- Tarea 4: Presupuestos de interrupción de Pods
- ¡Felicitaciones!
GSP769

Descripción general
Uno de los tantos beneficios de usar Google Cloud es su modelo de facturación, que factura solo por los recursos que usas. Con esto en mente, es esencial que no solo asignes una cantidad razonable de recursos a tu infraestructura y aplicaciones, sino también que los aproveches de la forma más eficiente. Con GKE, tienes varias herramientas y estrategias disponibles para reducir el uso de diferentes recursos y servicios y mejorar la disponibilidad de la aplicación.
En este lab, se explican algunos conceptos que ayudarán a aumentar la eficiencia y la disponibilidad de los recursos asignados a tus cargas de trabajo. Comprender y ajustar la carga de trabajo de los clústeres permite asegurarse de usar solo los recursos necesarios y optimizar los costos asociados.
Objetivos
En este lab, aprenderás a hacer lo siguiente:
- Crear un balanceador de cargas nativo del contenedor a través de un objeto Ingress
- Someter una aplicación a una prueba de carga
- Configurar sondeos de preparación y funcionamiento
- Crear un presupuesto de interrupción de Pods
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab: Recuerda que, una vez que comienzas un lab, no puedes pausarlo.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haga clic en el botón Comenzar lab. Si debe pagar por el lab, se abrirá una ventana emergente para que seleccione su forma de pago. A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón Abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debe usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordene las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta. -
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}} También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}} También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud. Nota: Usar tu propia Cuenta de Google podría generar cargos adicionales. -
Haga clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.

Activa Cloud Shell
Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
- Haz clic en Activar Cloud Shell
en la parte superior de la consola de Google Cloud.
Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu PROJECT_ID. El resultado contiene una línea que declara el PROJECT_ID para esta sesión:
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
- Puedes solicitar el nombre de la cuenta activa con este comando (opcional):
-
Haz clic en Autorizar.
-
Ahora, el resultado debería verse de la siguiente manera:
Resultado:
- Puedes solicitar el ID del proyecto con este comando (opcional):
Resultado:
Resultado de ejemplo:
gcloud, consulta la guía con la descripción general de gcloud CLI en Google Cloud.
Aprovisiona el entorno del lab
- Establece la zona predeterminada como "
":
-
Haz clic en Autorizar.
-
Crea un clúster de tres nodos:
Se incluye la marca --enable-ip-alias para habilitar el uso de las IP de alias para Pods, que serán necesarias para configurar un balanceo de cargas nativo del contenedor a través de un objeto Ingress.
Para este lab, usarás una aplicación web HTTP sencilla que primero implementarás como un solo Pod.
- Crea un manifiesto para el Pod
gb-frontend:
- Aplica el manifiesto recién creado a tu clúster:
de 1 a 2 minutos para obtener la puntuación de esta tarea.Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 1: Configura el balanceo de cargas nativo del contenedor a través de un objeto Ingress
El balanceo de cargas nativo del contenedor permite que los balanceadores de cargas apunten directamente a los Pods de Kubernetes y distribuyan el tráfico de manera uniforme a estos.
Sin el balanceo de cargas nativo del contenedor, el tráfico del balanceador de cargas viajaría a grupos de instancias de nodo y, luego, se enrutaría mediante reglas iptables a los Pods que pueden estar o no en el mismo nodo:
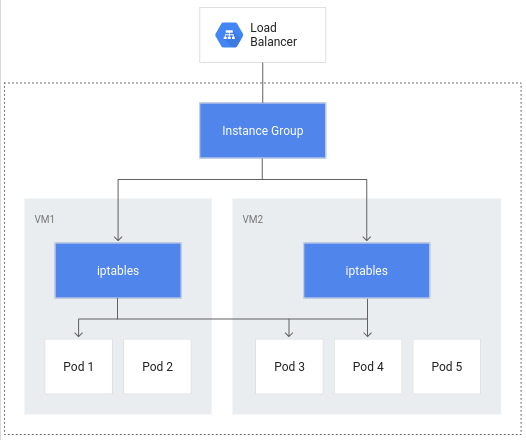
El balanceo de cargas nativo del contenedor permite que los Pods se conviertan en los objetos principales del balanceo de cargas, lo que podría reducir la cantidad de saltos de red:
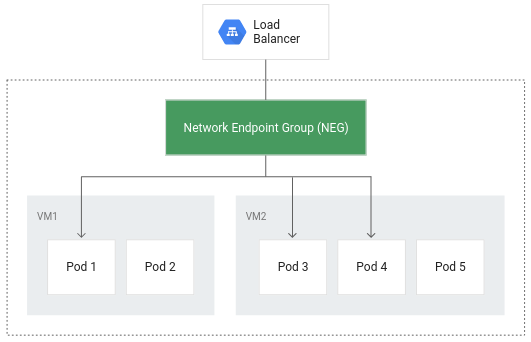
Además de lograr un enrutamiento más eficiente, el balanceo de cargas nativo del contenedor reduce considerablemente el uso de redes, mejora el rendimiento y distribuye el tráfico entre los Pods, y verifica el estado a nivel de la aplicación.
Para aprovechar el balanceo de cargas nativo del contenedor, la configuración nativa de la VPC debe estar habilitada en el clúster. Esto se indicó cuando creaste el clúster e incluiste la marca --enable-ip-alias.
- El siguiente manifiesto configurará un Service llamado
ClusterIPque se usará para enrutar el tráfico al Pod de tu aplicación y permitir que GKE cree un grupo de extremos de red:
El manifiesto incluye un campo denominado annotations, en el que la anotación de cloud.google.com/neg habilitará el balanceo de cargas nativo del contenedor para tu aplicación cuando se cree un objeto Ingress.
- Aplica el cambio al clúster:
- A continuación, crea un objeto Ingress para tu aplicación:
- Aplica el cambio al clúster:
Cuando se crea el objeto Ingress, se crea un balanceador de cargas HTTP(S) junto con un NEG (grupo de extremos de red) en cada zona en la que se ejecuta el clúster. Después de unos minutos, se asignará una IP externa al objeto Ingress.
El balanceador de cargas que se creó tiene un servicio de backend que se ejecuta en tu proyecto; este define cómo Cloud Load Balancing distribuye el tráfico. Este servicio de backend tiene un estado asociado.
- Para verificar el estado del servicio de backend, primero recupera el nombre:
- Obtén el estado del servicio:
La verificación de estado tardará unos minutos en volver a un buen estado.
El resultado se verá similar al siguiente:
Una vez que el estado de cada instancia se informe como HEALTHY, podrás acceder a la aplicación mediante su IP externa.
- Recupérala con el siguiente comando:
- Si ingresas la IP externa en una ventana del navegador, se cargará la aplicación.
Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 2: Realiza una prueba de carga en una aplicación
Comprender la capacidad de las aplicaciones es un paso importante a la hora de elegir solicitudes y límites de recursos para los Pods de tu app, así como para decidir la mejor estrategia de ajuste de escala automático.
Al comienzo del lab, se implementó tu aplicación como un solo Pod. Cuando pruebes la carga de tu aplicación para que se ejecute en un solo Pod sin un ajuste de escala automático configurado, conocerás cuántas solicitudes simultáneas puede manejar tu aplicación, cuánta CPU y memoria requiere y cómo puede responder a una carga pesada.
Para realizar una prueba de carga de tu Pod, se usará Locust, un framework de prueba de carga de código abierto.
- Descarga los archivos de imagen de Docker para Locust en tu entorno de Cloud Shell:
Los archivos del directorio que se proporcionó, locust-image, incluyen archivos de configuración de Locust.
- Compila la imagen de Docker para Locust y guárdala en el Container Registry del proyecto:
- Verifica que la imagen de Docker esté en el Container Registry del proyecto:
Resultado esperado:

Locust consta de una instancia principal y una cantidad de máquinas de trabajador para generar la carga.
- Con la copia y aplicación del manifiesto, se creará un Deployment de un solo Pod para la instancia principal y un Deployment de 5 réplicas para los trabajadores:
- Para acceder a la IU de Locust, recupera la dirección IP externa de su Service de tipo LoadBalancer correspondiente:
Si el valor de la IP externa es <pending>, espera un minuto y vuelve a ejecutar el comando anterior hasta que se muestre un valor válido.
- En una nueva ventana del navegador, navega a
[EXTERNAL_IP_ADDRESS]:8089para abrir la página web de Locust:
Haz clic en Revisar mi progreso para verificar el objetivo.
Locust te permite colmar tu aplicación con varios usuarios simultáneos. Puedes ingresar una cantidad de usuarios que se generan a una velocidad determinada para simular el tráfico.
-
En este ejemplo, con la idea de representar una carga típica, ingresa 200 para la cantidad de usuarios que se simularán y 20 para la velocidad a la que se generarán.
-
Haz clic en Start swarming.
Después de unos segundos, el estado debería ser Running, con 200 usuarios y alrededor de 150 solicitudes por segundo (RPS).
-
Ve a la consola de Cloud y haz clic en el menú de navegación (
) > Kubernetes Engine.
-
En el panel izquierdo, selecciona Cargas de trabajo.
-
Luego, haz clic en tu Pod implementado gb-frontend.
Se abrirá la página de detalles del Pod, en la que podrás ver un gráfico de su uso de memoria y CPU. Observa los valores usados y solicitados.
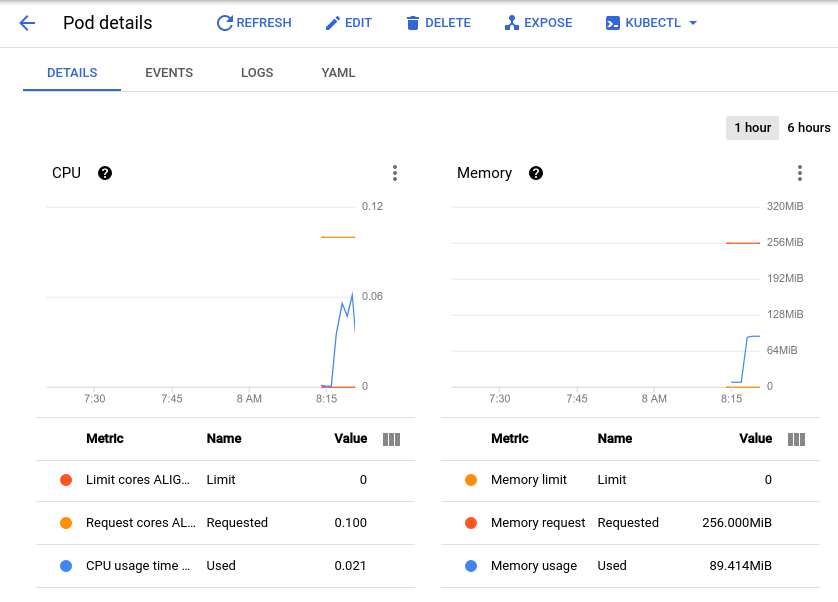
Con la prueba de carga actual de alrededor de 150 solicitudes por segundo, es posible que veas un uso de CPU tan bajo como 0.04 y tan alto como 0.06. Esto representa entre el 40% y el 60% de la solicitud de CPU de tu Pod. Por otro lado, el uso de memoria se mantiene alrededor de los 80 Mi, muy por debajo de los 256 Mi solicitados. Esta es tu capacidad por Pod. Esta información será útil a la hora de configurar el escalador automático del clúster, los límites y las solicitudes de recursos, y de elegir cómo implementar un escalador automático horizontal o vertical de Pods, o si debes implementarlo en absoluto.
Además de los usos de referencia, también debes tener en cuenta el rendimiento que podría tener tu aplicación después de experimentar aumentos de actividad repentinos.
-
Regresa a la ventana del navegador de Locust y, en la parte superior de la página, haz clic en Edit debajo del estado.
-
Esta vez, ingresa 900 para la cantidad de usuarios que se simularán y 300 para la velocidad a la que se generarán.
-
Haz clic en Start swarming.
De inmediato, el Pod recibirá 700 solicitudes adicionales en un período de 2 a 3 segundos. Una vez que el valor de RPS alcance alrededor de 150 y el estado indique 900 usuarios, regresa a la página de detalles del Pod y observa el cambio en los gráficos.
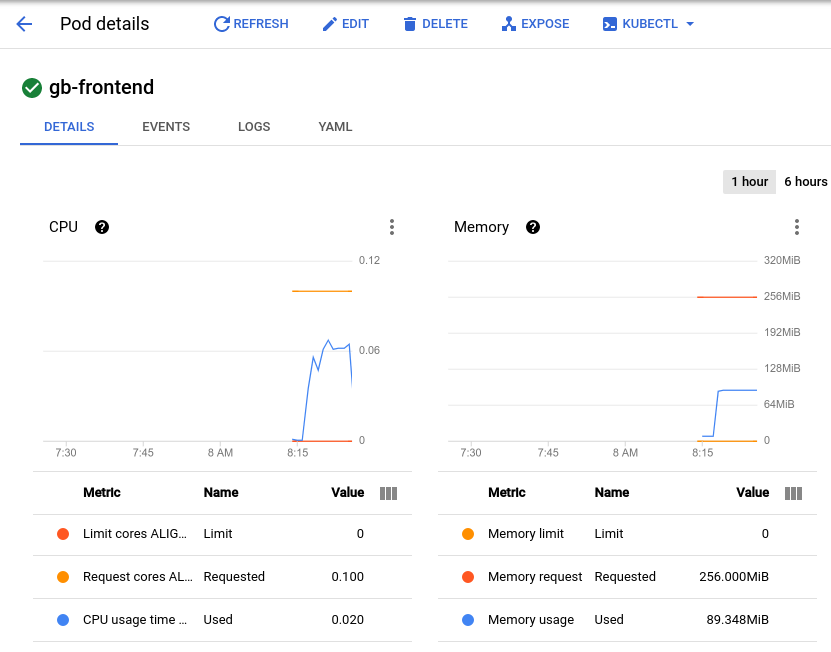
Si bien la memoria se mantuvo igual, verás que la CPU alcanzó su punto máximo a casi 0.07, lo cual representa el 70% de la solicitud de CPU de tu Pod. Si esta app fuera un Deployment, probablemente podrías reducir con seguridad la solicitud de memoria total a una cantidad menor y configurar el escalador automático horizontal para que active el uso de CPU.
Tarea 3: Configura sondeos de preparación y funcionamiento
Configura un sondeo de funcionamiento
Si se configura en el Pod de Kubernetes o en las especificaciones del Deployment, se ejecutará un sondeo de funcionamiento de forma continua para detectar si un contenedor requiere un reinicio y, en tal caso, activarlo. Estos sondeos son útiles para reiniciar automáticamente aplicaciones interbloqueadas que aún pueden estar en ejecución. Por ejemplo, un balanceador de cargas administrado por Kubernetes (como un Service) solo enviaría tráfico a un backend de Pod si todos sus contenedores pasan un sondeo de preparación.
- Para demostrar la operación de los sondeos de funcionamiento, el siguiente comando generará el manifiesto de un Pod que incluye este tipo de sondeo basado en la ejecución del comando cat en un archivo que se creó al momento de la creación del Pod:
- Aplica el manifiesto al clúster para crear el Pod:
El valor initialDelaySeconds representa el tiempo que debe transcurrir antes de que se deba realizar el primer sondeo una vez que se inicie el contenedor. El valor periodSeconds indica la frecuencia con la que se realizará el sondeo.
startupProbe que indica si se inició la aplicación alojada en el contenedor. Si hay un startupProbe presente, no se realizará ningún otro sondeo hasta que informe un estado Success. Esto se recomienda para aplicaciones que pueden tener tiempos de inicio variables de modo que se puedan evitar interrupciones ocasionadas por un sondeo de funcionamiento.En este ejemplo, el sondeo de funcionamiento básicamente está verificando si el archivo /tmp/alive existe en el sistema de archivos del contenedor.
- Para verificar el estado del contenedor del Pod, revisa sus eventos:
En la parte inferior del resultado, debería haber una sección denominada Events con los últimos 5 eventos del Pod. En este punto, los eventos del Pod solo deben incluir aquellos relacionados con su creación y su inicio:
Este registro de eventos incluirá como resultado los errores del sondeo de funcionamiento y los reinicios activados.
- Borra de forma manual el archivo que usa el sondeo de funcionamiento:
-
Después de que se quite el archivo, el comando
catque usa el sondeo de funcionamiento debe mostrar un código de salida que no sea cero. -
Vuelve a revisar los eventos del Pod:
Dado que el sondeo de funcionamiento falla, se mostrarán eventos agregados al registro que indicarán la serie de pasos que se iniciaron. El resultado comenzará con la falla del sondeo de funcionamiento (Liveness probe failed: cat: /tmp/alive: No such file or directory) y terminará con el contenedor que se inicia otra vez (Started container):
livenessProbe que depende del código de salida de un comando especificado. Además de un sondeo de comando, se podría configurar un livenessProbe como un sondeo HTTP que dependerá de la respuesta HTTP, o bien un sondeo TCP que dependerá de si se puede realizar una conexión TCP en un puerto específico. Configura un sondeo de preparación
Si bien un Pod podría iniciarse con éxito y considerarse en buen estado a través de un sondeo de funcionamiento, es probable que no esté listo para recibir tráfico de inmediato. Esto es común en los Deployments que funcionan como backend para un Service como un balanceador de cargas. Un sondeo de preparación se usa para determinar cuándo un Pod y sus contenedores están listos para comenzar a recibir tráfico.
- Para demostrarlo, crea un manifiesto que te permita crear un Pod único que sirva como servidor web de prueba junto con un balanceador de cargas:
- Aplica el manifiesto al clúster y crea un balanceador de cargas junto con este:
- Recupera la dirección IP externa asignada al balanceador de cargas (tras ejecutar el comando anterior, es posible que transcurra un minuto para que se asigne una dirección):
-
Ingresa la dirección IP en una ventana del navegador. Verás que aparecerá un mensaje de error que indica que no se puede acceder al sitio.
-
Verifica los eventos del Pod:
El resultado mostrará que el sondeo de preparación falló:
A diferencia del sondeo de funcionamiento, un sondeo de preparación en mal estado no activa el reinicio del Pod.
- Usa el siguiente comando para generar el archivo que busca el sondeo de preparación:
En la sección Conditions de la descripción del Pod, ahora debería aparecer True como el valor de Ready.
Resultado:
- Ahora actualiza la pestaña del navegador que tenía la IP externa de readiness-demo-svc. Deberías ver correctamente el mensaje "Welcome to nginx!".
Configurar sondeos de preparación significativos para los contenedores de tu aplicación garantiza que los Pods solo reciban tráfico cuando estén listos para hacerlo. Un ejemplo de un sondeo de preparación considerable es verificar si la caché en la que se basa tu aplicación se carga durante el inicio.
Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 4: Presupuestos de interrupción de Pods
Parte de garantizar la confiabilidad y el tiempo de actividad de las aplicaciones de GKE se basa en aprovechar los presupuestos de interrupción de Pods (PDB). PodDisruptionBudget es un recurso de Kubernetes que limita la cantidad de Pods de una aplicación replicada que se pueden quitar de forma simultánea debido a interrupciones voluntarias.
Las interrupciones voluntarias incluyen acciones administrativas, como borrar un Deployment, actualizar la plantilla de Pod del Deployment y realizar una actualización progresiva, vaciar los nodos en los que residen los Pods de una aplicación o mover Pods a diferentes nodos.
Primero, deberás implementar tu aplicación como un Deployment.
- Borra tu app de un solo Pod:
- Ahora, genera un manifiesto que creará la aplicación como un Deployment de 5 réplicas:
- Aplica este Deployment al clúster:
Haz clic en Revisar mi progreso para verificar el objetivo.
Antes de crear un PDB, vaciarás los nodos de tu clúster y observarás el comportamiento de tu aplicación sin un PDB establecido.
- Vacía los nodos realizando un bucle en el resultado de los nodos del
default-pooly ejecutando el comandokubectl drainen cada nodo:
El comando anterior expulsará los Pods del nodo especificado y acordonará el nodo para que no se puedan crear Pods nuevos en él. Si los recursos disponibles lo permiten, los Pods se vuelven a implementar en un nodo diferente.
- Cuando se haya vaciado el nodo, verifica el recuento de réplicas del Deployment
gb-frontend:
Es posible que el resultado sea similar al siguiente:
Después de vaciar un nodo, el Deployment podría tener tan solo 0 réplicas disponibles, como se indica en el resultado anterior. Si no hay Pods disponibles, tu aplicación se encuentra efectivamente inactiva. Intentemos vaciar los nodos de nuevo, pero esta vez lo haremos con un presupuesto de interrupción de Pods establecido para tu aplicación.
- En primer lugar, debes desacordonar los nodos vaciados para recuperarlos. El siguiente comando permite volver a programar los Pods en el nodo:
- Vuelve a verificar el estado del Deployment:
El resultado debería ser similar al siguiente, con las 5 réplicas disponibles:
- Crea un presupuesto de interrupción de Pods que declare que la cantidad mínima de Pods disponibles será 4:
- Una vez más, vacía uno de los nodos del clúster y observa el resultado:
Después de expulsar correctamente uno de los Pods de tu aplicación, se ejecutarán los siguientes comandos en bucle:
-
Presiona Ctrl + C para salir del comando.
-
Vuelve a verificar el estado de tu Deployment:
El resultado debería ser el siguiente:
Hasta que Kubernetes pueda implementar un 5º Pod en un nodo diferente para expulsar el siguiente, los Pods restantes permanecerán disponibles de modo que puedan cumplir con el PDB. En este ejemplo, el presupuesto de interrupción de Pods se configuró para indicar un min-available, pero un PDB también se puede configurar para definir un max-unavailable. Cualquier valor se puede expresar como un número entero que representa el recuento de Pods o un porcentaje del total de Pods.
¡Felicitaciones!
Aprendiste a crear un balanceador de cargas nativo del contenedor a través de un objeto Ingress para aprovechar un enrutamiento y un balanceo de cargas más eficientes. Ejecutaste una prueba de carga simple en una aplicación de GKE y observaste su uso básico de CPU y memoria, así como su respuesta a los aumentos repentinos de tráfico. Además, configuraste sondeos de funcionamiento y preparación, junto con un presupuesto de interrupción de Pods para garantizar la disponibilidad de tus aplicaciones. Estas herramientas y técnicas se complementan con el objetivo de mejorar la eficiencia general del funcionamiento de las aplicaciones en GKE, ya que minimizan el tráfico de red innecesario, definen indicadores significativos de las aplicaciones con buen comportamiento y mejoran la disponibilidad de las aplicaciones.
Próximos pasos y más información
Consulta estos recursos para obtener más información sobre los temas abordados en este lab:
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 12 de marzo de 2024
Prueba más reciente del lab: 12 de marzo de 2024
Copyright 2024 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.

