Points de contrôle
Provision Lab Environment
/ 20
Container-native Load Balancing Through Ingress
/ 20
Load Testing an Application
/ 20
Readiness and Liveness Probes
/ 20
Create Pod Disruption Budgets
/ 20
Optimisation des charges de travail GKE
GSP769

Présentation
L'un des nombreux avantages de Google Cloud est son modèle de facturation, qui vous facture uniquement les ressources que vous utilisez. Par conséquent, il est impératif de n'allouer qu'une quantité raisonnable de ressources pour vos applications et votre infrastructure, et de les utiliser au mieux. GKE offre un certain nombre d'outils et de stratégies qui vous permettent de réduire l'utilisation de différents services et ressources, tout en améliorant la disponibilité de votre application.
Cet atelier présente quelques concepts qui vous aideront à augmenter l'efficacité et la disponibilité des ressources pour vos charges de travail. En analysant et en ajustant la charge de travail de votre cluster, vous pouvez vous assurer que vous n'utilisez que les ressources dont vous avez besoin, et ainsi optimiser les coûts associés au cluster.
Objectifs
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Créer un équilibreur de charge natif en conteneurs via une entrée
- Tester la charge d'une application
- Configurer des vérifications d'activité et d'aptitude
- Créer un budget d'interruptions de pods
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- vous disposez d'un temps limité ; une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google Cloud
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte. -
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}} Vous trouverez également le nom d'utilisateur dans le panneau Détails concernant l'atelier.
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}} Vous trouverez également le mot de passe dans le panneau Détails concernant l'atelier.
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud. Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés. -
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais gratuits.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
- Cliquez sur Activer Cloud Shell
en haut de la console Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Le résultat contient une ligne qui déclare YOUR_PROJECT_ID (VOTRE_ID_PROJET) pour cette session :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- (Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
-
Cliquez sur Autoriser.
-
Vous devez à présent obtenir le résultat suivant :
Résultat :
- (Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
Résultat :
Exemple de résultat :
gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
Provisionner l'environnement de l'atelier
- Définissez la zone par défaut sur "
" :
-
Cliquez sur Autoriser.
-
Créez un cluster à trois nœuds :
L'option --enable-ip-alias est incluse afin de permettre aux pods d'utiliser des adresses IP d'alias, qui seront nécessaires pour l'équilibrage de charge natif en conteneurs via une entrée.
Dans cet atelier, vous allez utiliser une application Web HTTP simple que vous commencerez par déployer en tant que pod unique.
- Créez un fichier manifeste pour le pod
gb-frontend:
- Appliquez le fichier manifeste ainsi créé à votre cluster :
une à deux minutes avant d'obtenir la note de cette tâche.Cliquez sur Vérifier ma progression pour valider l'objectif.
Tâche 1 : Équilibrage de charge natif en conteneurs via une entrée
L'équilibrage de charge natif en conteneurs permet aux équilibreurs de charge de cibler directement les pods Kubernetes et de répartir le trafic de manière homogène entre ceux-ci.
Sans l'équilibrage de charge natif en conteneurs, le trafic de l'équilibreur de charge est transféré vers les groupes d'instances de nœuds, puis acheminé via des règles iptables vers des pods se trouvant ou non dans le même nœud :
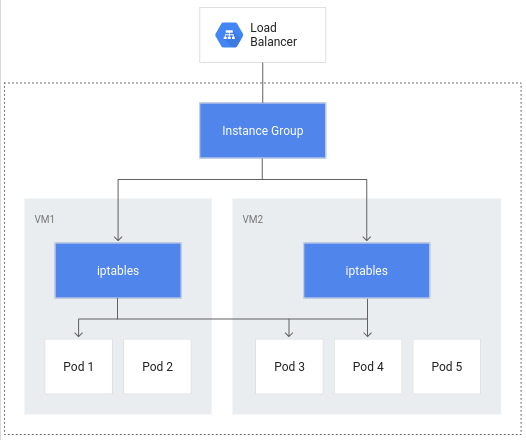
L'équilibrage de charge natif en conteneurs permet d'appliquer directement l'équilibrage de charge aux pods, et donc de réduire potentiellement le nombre de sauts de réseau :
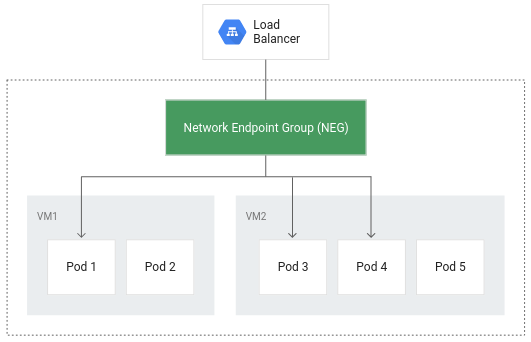
Outre le fait d'offrir un routage plus efficace, l'équilibrage de charge natif en conteneurs permet de réduire considérablement l'utilisation du réseau, d'améliorer les performances, de répartir le trafic entre les pods de façon homogène et de vérifier l'état au niveau des applications.
Pour tirer parti de l'équilibrage de charge natif en conteneurs, le paramètre de VPC natif doit être activé sur le cluster. Cela vous a été indiqué lorsque le cluster a été créé avec l'option --enable-ip-alias.
- Le fichier manifeste suivant configure un service
ClusterIPqui sera utilisé pour router le trafic vers le pod de votre application, afin de permettre à GKE de créer un groupe de points de terminaison du réseau :
Le fichier manifeste comprend un champ annotations où l'annotation de cloud.google.com/neg permet d'activer l'équilibrage de charge natif en conteneurs pour votre application lorsqu'une entrée est créée.
- Appliquez la modification à votre cluster :
- Créez ensuite une entrée pour votre application :
- Appliquez la modification à votre cluster :
Lors de la création de l'entrée, un équilibreur de charge HTTP(S) est créé avec un groupe de points de terminaison du réseau dans chaque zone d'exécution du cluster. Après quelques minutes, l'entrée reçoit une adresse IP externe.
L'équilibreur de charge créé dispose d'un service de backend qui s'exécute dans votre projet et définit la manière dont Cloud Load Balancing répartit le trafic. Un état de fonctionnement est associé à ce service de backend.
- Pour vérifier l'état du service de backend, commencez par récupérer son nom :
- Obtenez l'état de fonctionnement du service :
Vous devrez patienter quelques minutes avant d'obtenir l'état de fonctionnement HEALTHY (Opérationnel).
Le résultat ressemble à ce qui suit :
Une fois que l'état de chaque instance a été vérifié comme étant HEALTHY (Opérationnel), vous pouvez accéder à l'application via son adresse IP externe.
- Récupérez-la avec la commande suivante :
- Si vous saisissez cette adresse IP externe dans une fenêtre de navigateur, l'application se charge.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Tâche 2 : Test de charge d'une application
Il est important de comprendre la capacité de votre application afin de configurer correctement les demandes et les limites de ressources pour les pods de votre application, et de décider de la meilleure stratégie d'autoscaling.
Au début de l'atelier, vous avez déployé votre application en tant que pod unique. En testant la charge de votre application sur un pod unique sans autoscaling configuré, vous découvrirez le nombre de requêtes simultanées que votre application peut traiter, la quantité de ressources processeur et de mémoire dont elle a besoin, et son comportement face à des charges importantes.
Pour tester la charge de votre pod, vous utiliserez Locust, un framework de test de charge Open Source.
- Téléchargez les fichiers image Docker pour Locust dans Cloud Shell :
Le répertoire locust-image contient entre autres des fichiers de configuration Locust.
- Créez l'image Docker pour Locust et stockez-la dans le registre Container Registry de votre projet :
- Vérifiez que l'image Docker se trouve dans le registre Container Registry de votre projet :
Résultat attendu :

Locust se compose d'un nœud principal et d'un certain nombre de machines de type "nœud de calcul" permettant de générer une charge.
- Copiez et appliquez le fichier manifeste pour créer un déploiement à pod unique pour le nœud principal et un déploiement à cinq instances répliquées pour les nœuds de calcul :
- Pour accéder à l'interface utilisateur de Locust, récupérez l'adresse IP externe du service LoadBalancer correspondant :
Si la valeur External IP (Adresse IP externe) est <pending>, attendez une minute et réexécutez la commande précédente jusqu'à ce qu'une valeur valide s'affiche.
- Dans une nouvelle fenêtre de navigateur, accédez à
[EXTERNAL_IP_ADDRESS]:8089pour ouvrir la page Web Locust :
Cliquez sur Vérifier ma progression pour valider l'objectif.
Locust vous permet de créer un essaim sur votre application en simulant un grand nombre d'utilisateurs en même temps. Vous pouvez ainsi simuler du trafic en spécifiant le nombre d'utilisateurs et le taux d'apparition.
-
Dans cet exemple, pour représenter une charge type, saisissez 200 pour le nombre d'utilisateurs à simuler et 20 pour le taux d'apparition.
-
Cliquez sur Start swarming (Démarrer le travail en essaim).
Au bout de quelques secondes, l'état doit être passé à Running (En cours d'exécution) avec 200 utilisateurs et environ 150 requêtes par seconde (RPS).
-
Accédez à la console Cloud, puis cliquez sur Menu de navigation (
) > Kubernetes Engine.
-
Sélectionnez Charges de travail dans le volet de gauche.
-
Cliquez ensuite sur votre pod gb-frontend déployé.
Vous accédez ainsi à la page des détails du pod, qui affiche un graphique représentant l'utilisation du processeur et de la mémoire de votre pod. Observez les valeurs utilisées et les valeurs demandées.
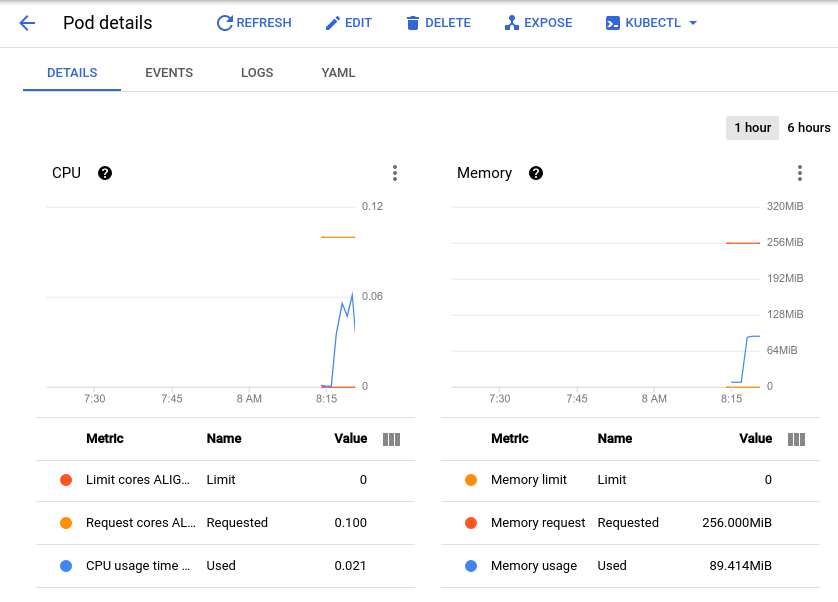
Avec le test de charge actuel, qui génère environ 150 requêtes par seconde, l'utilisation du processeur peut varier de 0,04 à 0,06. Cela représente 40 à 60 % de la demande de ressources de processeur pour votre pod unique. En revanche, l'utilisation de la mémoire stagne à environ 80 Mi, bien en dessous des 256 Mi demandés. Il s'agit de la capacité par pod. Ces informations seront utiles pour configurer l'autoscaler de cluster, les demandes et les limites de ressources, et pour choisir entre un autoscaler horizontal ou vertical des pods et le implémenter.
En plus des valeurs de référence, nous vous recommandons de tenir compte des performances de votre application après une utilisation intensive ou des pics de trafic soudains.
-
Revenez à la fenêtre du navigateur Locust et cliquez sur l'option Edit (Modifier) située en haut de la page, sous l'état.
-
Cette fois, saisissez 900 pour le nombre d'utilisateurs à simuler et 300 pour le taux d'apparition.
-
Cliquez sur Start swarming (Démarrer le travail en essaim).
Votre pod recevra soudainement 700 demandes supplémentaires, dans les deux à trois secondes. Une fois que la valeur RPS a atteint environ 150 et que l'état indique 900 utilisateurs, revenez à la page Détails du pod et observez l'évolution des graphiques.
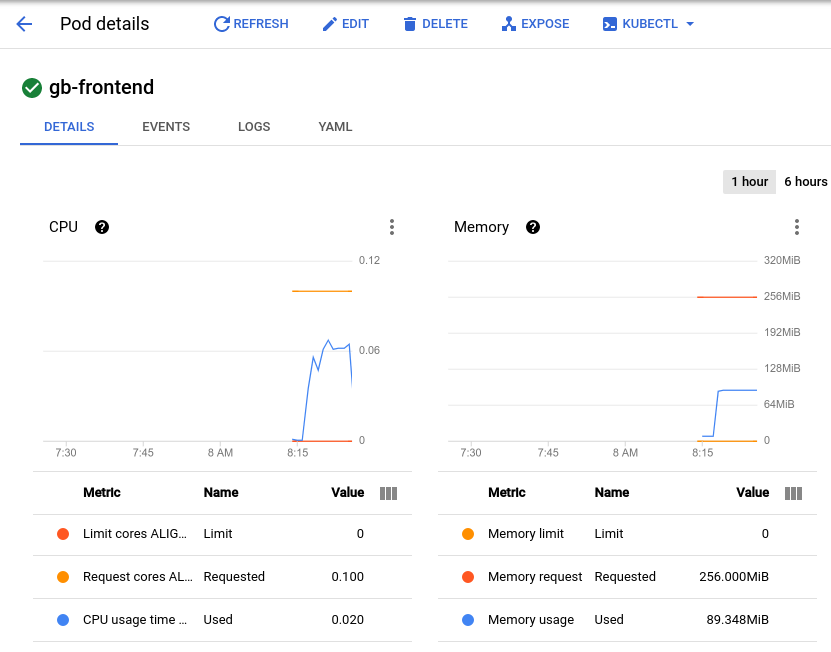
Si la mémoire n'a pas bougé, vous pouvez en revanche constater que le processeur a atteint presque 0,07, soit 70 % de la demande de ressources de processeur pour votre pod. Si cette application était destinée à un déploiement, vous pourriez certainement réduire la demande de mémoire totale en toute sécurité et configurer votre autoscaler horizontal pour qu'il se déclenche en fonction de l'utilisation du processeur.
Tâche 3 : Vérifications d'aptitude et d'activité
Configurer une vérification d'activité
Une vérification d'activité, si elle est configurée dans le pod Kubernetes ou la spécification de déploiement, s'exécute en continu pour détecter si un conteneur a besoin d'être redémarré, et déclencher ce redémarrage le cas échéant. Cette option permet de redémarrer automatiquement les applications bloquées dont l'exécution n'est peut-être pas achevée. Par exemple, un équilibreur de charge géré par Kubernetes (tel qu'un service) n'enverra le trafic à un backend de pod que si tous ses conteneurs réussissent une vérification d'aptitude.
- Pour nous permettre d'illustrer une vérification d'activité, le code suivant génère un fichier manifeste pour un pod dont la vérification d'activité est basée sur l'exécution de la commande cat sur un fichier généré lors de sa création :
- Appliquez le fichier manifeste à votre cluster pour créer le pod :
La valeur initialDelaySeconds indique le temps qui doit s'écouler entre le démarrage du conteneur et la première vérification. La valeur periodSeconds indique la fréquence de vérification.
startupProbe, qui indique si l'application dans le conteneur est démarrée. Si un élément startupProbe est présent, aucune autre vérification ne sera exécutée tant que l'état Success (Réussite) n'aura pas été obtenu. Cette configuration est recommandée pour les applications dont les temps de démarrage peuvent varier, afin d'éviter les interruptions liées à une vérification d'activité.Dans cet exemple, la vérification d'activité consiste principalement à déterminer si le fichier /tmp/alive est présent dans le système de fichiers du conteneur.
- Vous pouvez vérifier l'état du conteneur du pod en consultant les événements du pod :
À la fin du résultat, vous trouverez une section "Events" (Événements) contenant les cinq derniers événements. À ce stade, cette section des événements du pod ne doit inclure que ceux liés à sa création et à son démarrage :
Ce journal des événements inclut tous les échecs de la vérification d'activité, ainsi que les redémarrages déclenchés en conséquence.
- Supprimez manuellement le fichier utilisé par la vérification d'activité :
-
Une fois le fichier supprimé, la commande
catutilisée par la vérification d'activité doit renvoyer un code de sortie différent de zéro. -
Vérifiez à nouveau les événements du pod :
La vérification d'activité échoue, et le journal affiche la séquence d'événements générée par cet échec. La liste commence par la vérification d'activité ayant échoué (Liveness probe failed: cat: /tmp/alive: No such file or directory) et se termine par le redémarrage du conteneur (Started container) :
livenessProbe qui dépend du code de sortie d'une commande spécifiée. En plus d'être utilisé en tant que vérification de commande, un livenessProbe peut être configuré en tant que vérification HTTP dépendant d'une réponse HTTP, ou en tant que vérification TCP dépendant de la possibilité d'établir une connexion TCP sur un port spécifique. Configurer une vérification d'aptitude
Bien qu'un pod puisse démarrer et être considéré comme opérationnel selon la vérification d'activité, il est possible qu'il ne soit pas encore prêt à recevoir du trafic immédiatement. Cela est courant pour les déploiements servant de backend à un service tel qu'un équilibreur de charge. Une vérification d'aptitude permet de déterminer à quel moment un pod et ses conteneurs sont prêts à recevoir du trafic.
- Pour illustrer cela, créez un fichier manifeste afin de générer un pod unique qui servira de serveur Web de test ainsi qu'un équilibreur de charge :
- Appliquez le fichier manifeste à votre cluster et créez un équilibreur de charge à l'aide de celui-ci :
- Récupérez l'adresse IP externe attribuée à votre équilibreur de charge (une minute peut être nécessaire après la commande précédente pour qu'une adresse lui soit attribuée) :
-
Saisissez l'adresse IP dans une fenêtre de navigateur. Un message d'erreur vous indique que le site n'est pas accessible.
-
Vérifiez les événements du pod :
Le résultat indique que la vérification d'aptitude a échoué :
Un échec de la vérification d'aptitude ne déclenche pas le redémarrage du pod, comme c'est le cas lors d'une vérification d'activité.
- Utilisez la commande suivante pour générer le fichier que la vérification d'aptitude doit contrôler :
La section Conditions de la description du pod doit maintenant afficher la valeur True (Vrai) pour Ready (Prêt).
Résultat :
- À présent, actualisez l'onglet de navigateur pointant vers l'adresse IP externe associée au service readiness-demo-svc. Le message "Welcome to nginx!" (Bienvenue dans nginx !) doit s'afficher correctement.
Définir des vérifications d'aptitude pertinentes pour vos conteneurs d'applications permet de s'assurer que les pods ne reçoivent du trafic que lorsqu'ils sont prêts. Vous pouvez par exemple vérifier si le cache de votre application est chargé au démarrage.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Tâche 4 : Budgets d'interruptions de pods
Pour assurer la fiabilité et le temps d'activité de votre application GKE, vous devez exploiter les budgets d'interruptions de pods (PDB, Pod Disruption Budgets). PodDisruptionBudget est une ressource Kubernetes qui limite le nombre de pods d'une application dupliquée pouvant être interrompus simultanément en raison de perturbations volontaires.
Les interruptions volontaires incluent les actions administratives telles que la suppression d'un déploiement, la mise à jour du modèle de pod d'un déploiement et l'exécution d'une mise à jour progressive, le drainage des nœuds sur lesquels résident les pods d'une application ou le déplacement des pods vers des nœuds différents.
Tout d'abord, vous devez déployer votre application en tant que déploiement.
- Supprimez votre application à pod unique :
- Générez ensuite un fichier manifeste qui créera l'application et déclenchera le déploiement de cinq instances répliquées :
- Appliquez ce déploiement à votre cluster :
Cliquez sur Vérifier ma progression pour valider l'objectif.
Avant de créer un PDB, vous devez drainer les nœuds de votre cluster et observer le comportement de votre application sans PDB.
- Pour drainer les nœuds, passez en revue le résultat des nœuds de
default-poolet exécutez la commandekubectl drainsur chaque nœud :
La commande ci-dessus évince les pods du nœud spécifié et les marque comme non programmables (via la commande cordon), de sorte qu'aucun nouveau pod ne puisse être créé sur le nœud. Si les ressources disponibles le permettent, les pods sont redéployés sur un autre nœud.
- Une fois votre nœud drainé, vérifiez le nombre d'instances répliquées de votre déploiement
gb-frontend:
Le résultat devrait ressembler à ceci :
Après le drainage d'un nœud, votre déploiement peut ne comporter aucune instance répliquée disponible, comme indiqué dans le résultat ci-dessus. Si aucun pod n'est disponible, votre application est arrêtée. Réessayez de drainer les nœuds, mais cette fois-ci, définissez un budget d'interruptions de pods pour votre application.
- Pour cela, vous devez tout d'abord réintégrer les nœuds drainés en les marquant comme ordonnançables. La commande ci-dessous permet de programmer à nouveau les pods sur le nœud :
- Vérifiez une nouvelle fois l'état de votre déploiement :
Le résultat doit se présenter comme suit, avec cinq instances répliquées disponibles :
- Créez un budget d'interruptions de pods qui déclarera que le nombre minimal de pods disponibles doit être de quatre :
- Une fois encore, drainez l'un des nœuds de votre cluster et observez le résultat :
Une fois que vous avez évincé l'un des pods de votre application, celle-ci produira en boucle le résultat suivant :
-
Appuyez sur CTRL+C pour quitter la commande.
-
Vérifiez à nouveau l'état de vos déploiements :
Le résultat doit se présenter comme suit :
Jusqu'à ce que Kubernetes puisse déployer un 5e pod sur un nœud différent pour évincer le suivant, les pods restants demeurent disponibles afin de respecter le budget d'interruptions de pods (PDB). Dans cet exemple, le budget d'interruptions de pods a été configuré pour indiquer min-available, mais un PDB peut également être configuré pour définir la valeur max-unavailable (nombre maximal de pods non disponibles). Les deux valeurs peuvent être exprimées sous la forme d'un nombre entier représentant le nombre de pods, ou d'un pourcentage du nombre total de pods.
Félicitations !
Vous avez appris à créer un équilibreur de charge natif en conteneurs via une entrée, afin de bénéficier d'un équilibrage de charge et d'un routage plus efficaces. Vous avez exécuté un test de charge simple sur une application GKE et observé l'utilisation de référence du processeur et de la mémoire, ainsi que la réaction de l'application aux pics de trafic. Vous avez également configuré des vérifications d'aptitude et d'activité, ainsi qu'un budget d'interruption des pods, afin de garantir la disponibilité de votre application. Ces outils et techniques, combinés les uns aux autres, contribuent à l'efficacité globale de l'exécution de votre application sur GKE, en limitant le trafic réseau inutile, en définissant des indicateurs pertinents pour le comportement de l'application, et en améliorant sa disponibilité.
Étapes suivantes et informations supplémentaires
Consultez ces ressources pour approfondir les sujets abordés dans cet atelier :
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 12 mars 2024
Dernier test de l'atelier : 12 mars 2024
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.

