체크포인트
Provision Lab Environment
/ 20
Container-native Load Balancing Through Ingress
/ 20
Load Testing an Application
/ 20
Readiness and Liveness Probes
/ 20
Create Pod Disruption Budgets
/ 20
GKE 워크로드 최적화
GSP769

개요
Google Cloud를 사용하면 얻을 수 있는 많은 이점 중 하나는 사용한 리소스에 대해서만 요금을 청구하는 결제 모델입니다. 따라서 앱과 인프라에 합리적인 양의 리소스를 할당하는 것뿐만 아니라 이를 가장 효율적으로 사용하는 것이 중요합니다. GKE에는 다양한 리소스와 서비스의 사용을 줄이면서 애플리케이션의 가용성을 높일 수 있는 여러 가지 도구와 전략이 있습니다.
이 실습에서는 워크로드의 리소스 효율성과 가용성을 높이는 데 도움이 되는 몇 가지 개념을 살펴봅니다. 클러스터의 워크로드를 이해하고 미세 조정하면 필요한 리소스만 사용하고 클러스터의 비용을 최적화할 수 있습니다.
목표
이 실습에서는 다음 작업을 수행하는 방법을 배웁니다.
- 인그레스를 통해 컨테이너 기반 부하 분산기 만들기
- 애플리케이션 부하 테스트
- 활성 및 준비 프로브 구성
- 포드 중단 예산 만들기
설정 및 요건
실습 시작 버튼을 클릭하기 전에
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머에는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지 표시됩니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 직접 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
- 표준 인터넷 브라우저 액세스 권한(Chrome 브라우저 권장)
- 실습을 완료하기에 충분한 시간---실습을 시작하고 나면 일시중지할 수 없습니다.
실습을 시작하고 Google Cloud 콘솔에 로그인하는 방법
-
실습 시작 버튼을 클릭합니다. 실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 팝업이 열립니다. 왼쪽에는 다음과 같은 항목이 포함된 실습 세부정보 패널이 있습니다.
- Google Cloud 콘솔 열기 버튼
- 남은 시간
- 이 실습에 사용해야 하는 임시 사용자 인증 정보
- 필요한 경우 실습 진행을 위한 기타 정보
-
Google Cloud 콘솔 열기를 클릭합니다(Chrome 브라우저를 실행 중인 경우 마우스 오른쪽 버튼으로 클릭하고 시크릿 창에서 링크 열기를 선택합니다).
실습에서 리소스가 가동되면 다른 탭이 열리고 로그인 페이지가 표시됩니다.
팁: 두 개의 탭을 각각 별도의 창으로 나란히 정렬하세요.
참고: 계정 선택 대화상자가 표시되면 다른 계정 사용을 클릭합니다. -
필요한 경우 아래의 사용자 이름을 복사하여 로그인 대화상자에 붙여넣습니다.
{{{user_0.username | "Username"}}} 실습 세부정보 패널에서도 사용자 이름을 확인할 수 있습니다.
-
다음을 클릭합니다.
-
아래의 비밀번호를 복사하여 시작하기 대화상자에 붙여넣습니다.
{{{user_0.password | "Password"}}} 실습 세부정보 패널에서도 비밀번호를 확인할 수 있습니다.
-
다음을 클릭합니다.
중요: 실습에서 제공하는 사용자 인증 정보를 사용해야 합니다. Google Cloud 계정 사용자 인증 정보를 사용하지 마세요. 참고: 이 실습에 자신의 Google Cloud 계정을 사용하면 추가 요금이 발생할 수 있습니다. -
이후에 표시되는 페이지를 클릭하여 넘깁니다.
- 이용약관에 동의합니다.
- 임시 계정이므로 복구 옵션이나 2단계 인증을 추가하지 않습니다.
- 무료 체험판을 신청하지 않습니다.
잠시 후 Google Cloud 콘솔이 이 탭에서 열립니다.

Cloud Shell 활성화
Cloud Shell은 다양한 개발 도구가 탑재된 가상 머신으로, 5GB의 영구 홈 디렉터리를 제공하며 Google Cloud에서 실행됩니다. Cloud Shell을 사용하면 명령줄을 통해 Google Cloud 리소스에 액세스할 수 있습니다.
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화
를 클릭합니다.
연결되면 사용자 인증이 이미 처리된 것이며 프로젝트가 PROJECT_ID로 설정됩니다. 출력에 이 세션의 PROJECT_ID를 선언하는 줄이 포함됩니다.
gcloud는 Google Cloud의 명령줄 도구입니다. Cloud Shell에 사전 설치되어 있으며 명령줄 자동 완성을 지원합니다.
- (선택사항) 다음 명령어를 사용하여 활성 계정 이름 목록을 표시할 수 있습니다.
-
승인을 클릭합니다.
-
다음과 비슷한 결과가 출력됩니다.
출력:
- (선택사항) 다음 명령어를 사용하여 프로젝트 ID 목록을 표시할 수 있습니다.
출력:
출력 예시:
gcloud 전체 문서는 Google Cloud에서 gcloud CLI 개요 가이드를 참조하세요.
실습 환경 프로비저닝
- 기본 영역을 '
'(으)로 설정합니다.
-
승인을 클릭합니다.
-
3개의 노드 클러스터를 만듭니다.
인그레스를 통한 컨테이너 기반 부하 분산에 필요한 포드에 별칭 IP 사용을 설정하기 위해 --enable-ip-alias 플래그가 포함됩니다.
이 실습에서는 먼저 단일 포드로 배포할 간단한 HTTP 웹 앱을 사용합니다.
-
gb-frontend포드에 대한 매니페스트를 만듭니다.
- 새로 만든 매니페스트를 클러스터에 적용합니다.
1~2분 정도 기다려야 할 수 있습니다.내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 1. 인그레스를 통한 컨테이너 기반 부하 분산
부하 분산기는 컨테이너 기반 부하 분산을 통해 Kubernetes 포드를 직접 대상으로 지정하고 트래픽을 포드에 균일하게 분산시킬 수 있습니다.
컨테이너 기반 부하 분산이 없으면 부하 분산기 트래픽은 노드 인스턴스 그룹으로 이동하여 iptables 규칙을 통해 같은 노드에 있거나 없을 수 있는 포드로 라우팅됩니다.
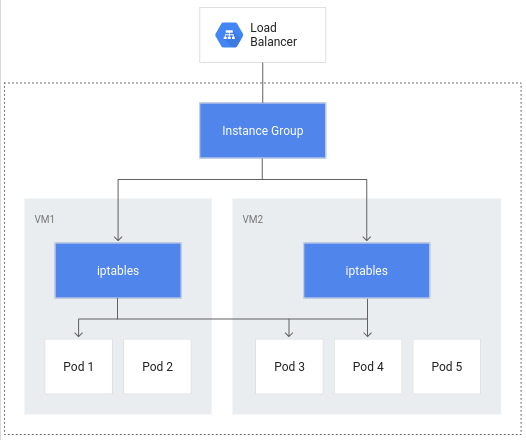
컨테이너 기반 부하 분산을 사용하면 포드가 부하 분산의 핵심 객체가 되어 잠재적으로 네트워크 홉 수를 줄일 수 있습니다.
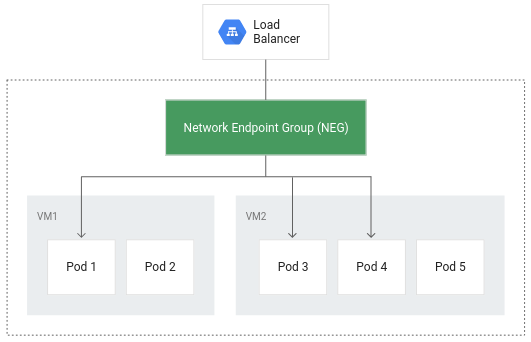
컨테이너 기반 부하 분산은 보다 효율적인 라우팅 외에도 네트워크 사용률을 크게 줄이고, 성능을 개선하며, 포드 간에 트래픽을 균등하게 분산하고, 애플리케이션 수준의 상태 점검을 가능하게 합니다.
컨테이너 기반 부하 분산을 활용하려면 클러스터에서 VPC 기반 설정을 사용하도록 설정해야 합니다. 이는 클러스터를 만들고 --enable-ip-alias 플래그를 포함할 때 표시되었습니다.
- 다음 매니페스트는 GKE가 네트워크 엔드포인트 그룹을 만들 수 있도록 애플리케이션 포드로 트래픽을 라우팅하는 데 사용되는
ClusterIP서비스를 구성합니다.
매니페스트에는 annotations 필드가 포함되어 있어서 cloud.google.com/neg에 대한 주석이 인그레스가 생성될 때 애플리케이션에 대해 컨테이너 기반 부하 분산을 사용하도록 설정합니다.
- 변경사항을 클러스터에 적용합니다.
- 다음으로 애플리케이션에 대한 인그레스를 만듭니다.
- 변경사항을 클러스터에 적용합니다.
인그레스를 만들면 클러스터가 실행되는 각 영역에 NEG(네트워크 엔드포인트 그룹)와 함께 HTTP(S) 부하 분산기가 생성됩니다. 몇 분 후 인그레스에 외부 IP가 할당됩니다.
생성된 부하 분산기에는 프로젝트에서 실행되는 백엔드 서비스가 있습니다. 이 백엔드 서비스는 Cloud Load Balancing이 트래픽을 분산하는 방법을 정의합니다. 이 백엔드 서비스에는 연결된 상태가 있습니다.
- 백엔드 서비스의 상태를 확인하려면 먼저 이름을 검색합니다.
- 서비스의 상태를 가져옵니다.
상태 점검에서 정상 상태가 반환되기까지 몇 분 정도 걸립니다.
출력은 다음과 유사할 수 있습니다.
각 인스턴스의 상태가 정상으로 보고되면 외부 IP를 통해 애플리케이션에 액세스할 수 있습니다.
- 다음을 사용하여 검색합니다.
- 브라우저 창에 외부 IP를 입력하면 애플리케이션이 로드됩니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 2. 애플리케이션 부하 테스트
애플리케이션 용량을 이해하는 것은 애플리케이션의 포드에 대한 리소스 요청 및 제한을 선택하고 최상의 자동 확장 전략을 결정할 때 취해야 할 중요한 단계입니다.
실습을 시작할 때 앱을 단일 포드로 배포했습니다. 자동 확장을 구성하지 않은 상태에서 단일 포드에서 실행 중인 애플리케이션을 부하 테스트하면 애플리케이션이 처리할 수 있는 동시 요청 수, 필요한 CPU 및 메모리 양, 과부하에 대한 대응 방법을 알아볼 수 있습니다.
포드를 부하 테스트하려면 오픈소스 부하 테스트 프레임워크인 Locust를 사용합니다.
- Cloud Shell에서 Locust용 Docker 이미지 파일을 다운로드합니다.
제공된 locust-image 디렉터리의 파일에는 Locust 구성 파일이 포함됩니다.
- Locust용 Docker 이미지를 빌드하고 프로젝트의 Container Registry에 저장합니다.
- 프로젝트의 Container Registry에 Docker 이미지가 있는지 확인합니다.
예상 출력:

Locust는 메인 머신과 부하를 생성하는 여러 작업자 머신으로 구성됩니다.
- 매니페스트를 복사하여 적용하면 메인 머신에 대한 단일 포드 배포와 작업자 머신에 대한 5개 복제본 배포가 생성됩니다.
- Locust UI에 액세스하려면 해당 LoadBalancer 서비스의 외부 IP 주소를 검색합니다.
외부 IP 값이 <pending>인 경우 잠시 기다렸다가 유효한 값이 표시될 때까지 이전 명령어를 다시 실행합니다.
- 새 브라우저 창에서
[EXTERNAL_IP_ADDRESS]:8089로 이동하여 Locust 웹페이지를 엽니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
Locust를 사용하면 많은 동시 사용자가 애플리케이션을 생성할 수 있습니다. 특정 비율로 생성되는 사용자 수를 입력하여 트래픽을 시뮬레이션할 수 있습니다.
-
이 예시에서는 일반적인 부하를 나타내기 위해 시뮬레이션할 사용자 수에 200을 입력하고 해치 비율에 20을 입력합니다.
-
생성 시작을 클릭합니다.
몇 초 후 상태에 사용자가 200명이고 초당 요청 수(RPS)가 약 150개로 실행 중이라는 메시지가 표시됩니다.
-
Cloud 콘솔로 전환하고 탐색 메뉴(
) > Kubernetes Engine을 클릭합니다.
-
왼쪽 창에서 워크로드를 선택합니다.
-
그런 다음 배포된 gb-frontend 포드를 클릭합니다.
그러면 포드의 CPU 및 메모리 사용률 그래프를 볼 수 있는 포드 세부정보 페이지로 이동합니다. 사용된 값과 요청된 값을 관찰합니다.
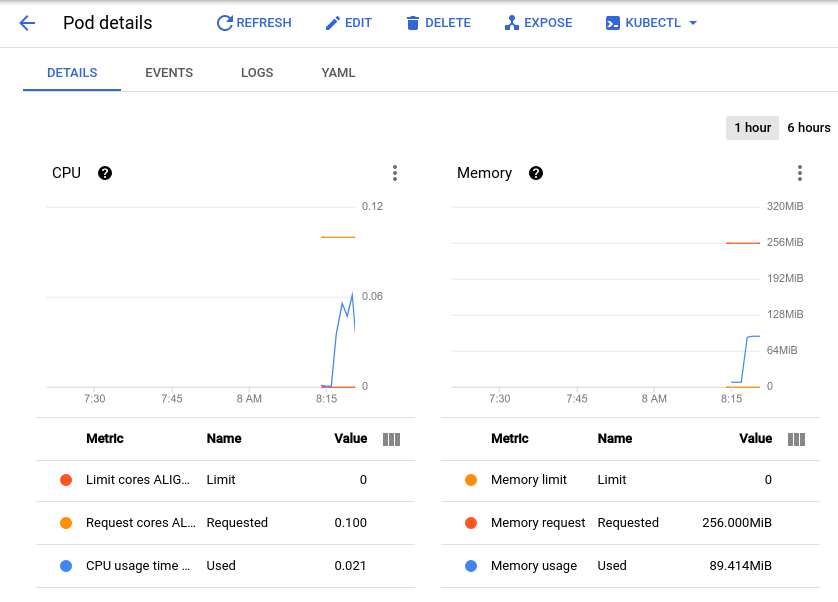
약 150개의 초당 요청 수로 현재 부하 테스트를 수행하면 CPU 사용률이 최저 0.04에서 최고 0.06까지 다양하게 나타나는 것을 볼 수 있습니다. 이는 한 포드의 CPU 요청이 40~60%임을 나타냅니다. 반면 메모리 사용률은 요청된 256Mi보다 훨씬 낮은 80Mi 정도로 유지됩니다. 이는 포드당 용량입니다. 이 정보는 클러스터 자동 확장 처리, 리소스 요청 및 제한을 구성하는 경우와 수평형 또는 수직형 포드 자동 확장 처리를 구현하는 방법 또는 여부를 선택하는 경우에 유용합니다.
기준과 함께 갑작스러운 버스트 또는 급증 후 애플리케이션의 성능도 고려해야 합니다.
-
Locust 브라우저 창으로 돌아가서 페이지 상단의 상태 아래에서 편집을 클릭합니다.
-
이번에는 시뮬레이션할 사용자 수에 900을 입력하고 해치 비율에 300을 입력합니다.
-
생성 시작을 클릭합니다.
포드는 2~3초 내에 갑자기 700개의 추가 요청을 수신합니다. RPS 값이 약 150에 도달하고 상태가 사용자 900명으로 표시되면 다시 포드 세부정보 페이지로 전환하여 그래프의 변화를 관찰합니다.
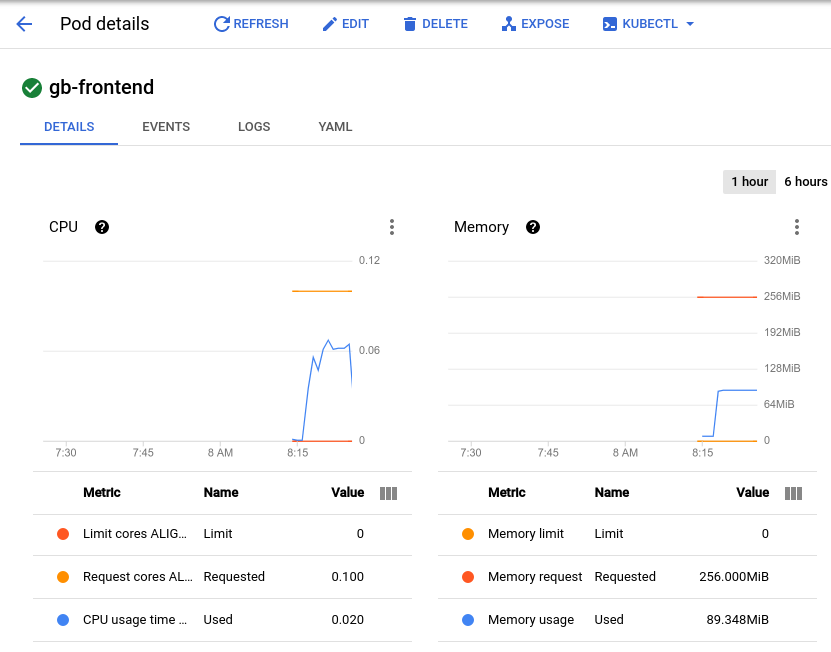
메모리가 동일하게 유지되는 동안 CPU 최고치는 거의 0.07로, 이는 포드에 대한 CPU 요청의 70%에 해당합니다. 이 앱이 배포된 경우, 총 메모리 요청을 더 낮은 양으로 안전하게 줄이고 CPU 사용량에 따라 트리거되도록 수평 자동 확장 처리를 구성할 수 있습니다.
작업 3. 준비 및 활성 프로브
활성 프로브 설정
Kubernetes 포드 또는 배포 사양으로 구성된 경우, 활성 프로브가 지속적으로 실행되어 컨테이너 재시작이 필요한지 여부를 감지하고 재시작을 트리거합니다. 이는 아직 실행 중 상태일 수 있는 교착 상태의 애플리케이션을 자동으로 재시작하는 데 유용합니다. 예를 들어 Kubernetes 관리형 부하 분산기(예: 서비스)는 모든 컨테이너가 준비 프로브를 통과하는 경우에만 트래픽을 포드 백엔드로 전송합니다.
- 활성 프로브를 시연하기 위해 다음은 생성 시 생성된 파일에 대한 cat 명령어의 실행을 기반으로 활성 프로브가 있는 포드에 대한 매니페스트를 생성합니다.
- 매니페스트를 클러스터에 적용하여 포드를 만듭니다.
initialDelaySeconds 값은 컨테이너가 시작된 후 첫 번째 프로브가 수행되기까지의 시간을 나타냅니다. periodSeconds 값은 프로브가 수행되는 빈도를 나타냅니다.
startupProbe를 포함하도록 포드를 구성할 수도 있습니다. startupProbe가 있는 경우 Success 상태가 반환될 때까지 다른 프로브는 수행되지 않습니다. 이는 활성 프로브의 중단을 방지하기 위해 시작 시간이 가변적일 수 있는 애플리케이션에 권장됩니다.이 예시에서 활성 프로브는 기본적으로 /tmp/alive 파일이 컨테이너의 파일 시스템에 존재하는지 확인합니다.
- 포드의 이벤트를 확인하여 포드의 컨테이너의 상태를 확인할 수 있습니다.
출력된 내용 하단에 포드의 마지막 5개 이벤트가 포함된 이벤트 섹션이 있어야 합니다. 이 시점에서 포드의 이벤트에는 생성 및 시작과 관련된 이벤트만 포함되어야 합니다.
이 이벤트 로그에는 활성 프로브의 모든 실패와 그 결과로 트리거된 재시작이 포함됩니다.
- 활성 프로브에서 사용 중인 파일을 수동으로 삭제합니다.
-
파일이 삭제되면 활성 프로브에서 사용 중인
cat명령어는 0이 아닌 종료 코드를 반환해야 합니다. -
다시 한번 포드의 이벤트를 확인합니다.
활성 프로브가 실패하면 시작되는 일련의 단계를 보여주는 로그에 이벤트가 추가되는 것을 볼 수 있습니다. 이 이벤트는 활성 프로브 실패(Liveness probe failed: cat: /tmp/alive: No such file or directory)로 시작하고 다시 한번 컨테이너 시작(Started container)으로 끝납니다.
livenessProbe에 대한 명령어 프로브를 사용합니다. 명령어 프로브 외에도 HTTP 응답에 따라 달라지는 HTTP 프로브 또는 특정 포트에서 TCP 연결이 가능한지 여부에 따라 달라지는 TCP 프로브에 따라 livenessProbe를 구성할 수 있습니다. 준비 프로브 설정
포드가 성공적으로 시작하고 활성 프로브가 이를 정상으로 간주하더라도 트래픽을 수신할 준비가 바로 되지 않을 가능성이 높습니다. 이는 부하 분산기와 같이 서비스에 백엔드로 작동하는 배포에 나타나는 일반적인 현상입니다. 준비 프로브는 포드와 포드의 컨테이너가 트래픽 수신을 시작할 준비가 되었는지 판단하는 데 사용됩니다.
- 이를 시연하려면 부하 분산기와 함께 테스트 웹 서버 역할을 하는 단일 포드를 만드는 매니페스트를 만듭니다.
- 매니페스트를 클러스터에 적용하고 부하 분산기를 만듭니다.
- 부하 분산기에 할당된 외부 IP 주소를 검색합니다(이전 명령어를 실행한 후 주소가 할당되는 데 1분 정도 소요될 수 있음).
-
브라우저 창에 IP 주소를 입력하면 사이트에 도달할 수 없음을 나타내는 오류 메시지가 표시됩니다.
-
포드의 이벤트를 확인합니다.
다음 출력은 준비 프로브가 실패했음을 나타냅니다.
활성 프로브와 달리 비정상 준비 프로브는 포드 재시작을 트리거하지 않습니다.
- 다음 명령어를 사용하여 준비 프로브가 확인할 파일을 생성합니다.
이제 포드 설명의 Conditions 섹션에 Ready의 값이 True로 표시됩니다.
출력:
- 이제 readiness-demo-svc 외부 IP가 있는 브라우저 탭을 새로고침합니다. 'Welcome to nginx!' 메시지가 제대로 표시되어야 합니다.
애플리케이션 컨테이너에 유의미한 준비 프로브를 설정하면 포드가 트래픽을 수신할 준비가 된 경우에만 트래픽을 수신하도록 할 수 있습니다. 예를 들어 애플리케이션이 활용하는 캐시가 시작 시 로드되는지 확인하도록 유의미한 준비 프로브를 설정할 수 있습니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 4. 포드 중단 예산
GKE 애플리케이션의 안정성과 업타임을 보장하기 위해서는 포드 중단 예산(pdp)을 활용해야 합니다. PodDisruptionBudget은 자발적 중단으로 인해 동시에 다운될 수 있는 복제된 애플리케이션의 포드 수를 제한하는 Kubernetes 리소스입니다.
자발적 중단에는 배포 삭제, 배포의 포드 템플릿 업데이트, 순차적 업데이트 수행, 애플리케이션의 포드가 상주하는 노드 드레이닝, 다른 노드로의 포드 이동과 같은 관리 작업이 포함됩니다.
먼저 애플리케이션을 배포로 배포해야 합니다.
- 단일 포드 앱을 삭제합니다.
- 5개의 복제본으로 구성된 배포로 앱을 생성할 매니페스트를 생성합니다.
- 이 배포를 클러스터에 적용합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
PDB를 만들기 전에 클러스터의 노드를 드레이닝하고 PDB가 없는 상태에서 애플리케이션의 동작을 관찰합니다.
-
default-pool의 노드의 출력을 반복하고 각 개별 노드에서kubectl drain명령어를 실행하여 노드를 드레이닝합니다.
위의 명령어는 지정된 노드에서 포드를 제거하고 새 포드를 만들 수 없도록 노드를 차단합니다. 사용 가능한 리소스가 허용하는 경우 포드는 다른 노드에 다시 배포됩니다.
- 노드가 드레이닝되면
gb-frontend배포의 복제본 수를 확인합니다.
출력은 다음과 유사할 수 있습니다.
노드를 드레이닝하면 위의 출력에 표시된 것처럼 배포에 사용 가능한 복제본이 0개까지 줄어들 수 있습니다. 사용 가능한 포드가 없으면 애플리케이션이 사실상 다운된 것입니다. 이번에는 애플리케이션에 대한 포드 중단 예산이 있는 경우를 제외하고 노드를 다시 드레이닝해 보겠습니다.
- 먼저 차단을 취소하여 드레이닝된 노드를 다시 가져옵니다. 아래 명령어를 사용하면 노드에 포드를 다시 예약할 수 있습니다.
- 다시 한번 배포 상태를 확인합니다.
출력은 다음과 유사해야 하며 5개의 복제본을 모두 사용할 수 있습니다.
- 사용 가능한 최소 포드 수를 4개로 선언하는 포드 중단 예산을 만듭니다.
- 다시 한번 클러스터의 노드 중 하나를 드레이닝하고 출력을 관찰합니다.
애플리케이션의 포드 중 하나를 성공적으로 제거한 후 다음을 반복합니다.
-
Ctrl+C를 눌러 명령어를 종료합니다.
-
다시 한번 배포 상태를 확인합니다.
이제 출력에 다음 내용이 표시되어야 합니다.
Kubernetes가 다음 포드를 제거하기 위해 다른 노드에 5번째 포드를 배포할 수 있을 때까지 나머지 포드는 PDB를 준수하기 위해 계속 사용할 수 있습니다. 이 예시에서는 min-available을 나타내도록 포드 중단 예산이 구성되었지만 max-unavailable을 정의하도록 PDB를 구성할 수도 있습니다. 두 값 모두 포드 수를 나타내는 정수 또는 전체 포드의 백분율로 표현할 수 있습니다.
수고하셨습니다
보다 효율적인 부하 분산 및 라우팅을 활용하기 위해 인그레스를 통해 컨테이너 기반 부하 분산기를 만드는 방법을 배웠습니다. GKE 애플리케이션에서 간단한 부하 테스트를 실행했고 기준 CPU 및 메모리 사용률과 트래픽 급증에 어떻게 대응하는지 관찰했습니다. 또한 애플리케이션의 가용성을 보장하기 위해 포드 중단 예산과 함께 활성 및 준비 프로브를 구성했습니다. 이러한 도구와 기법을 함께 사용하면 외부 네트워크 트래픽을 최소화하고 정상 작동하는 애플리케이션을 나타내는 유의미한 지표를 정의하며 애플리케이션 가용성을 개선하여 GKE에서 애플리케이션이 실행되는 방식에 대한 전반적인 효율성을 높일 수 있습니다.
다음 단계/더 학습하기
이 실습에서 다뤄진 주제에 대해 자세히 알아보려면 다음 리소스를 확인하세요.
Google Cloud 교육 및 자격증
Google Cloud 기술을 최대한 활용하는 데 도움이 됩니다. Google 강의에는 빠른 습득과 지속적인 학습을 지원하는 기술적인 지식과 권장사항이 포함되어 있습니다. 기초에서 고급까지 수준별 학습을 제공하며 바쁜 일정에 알맞은 주문형, 실시간, 가상 옵션이 포함되어 있습니다. 인증은 Google Cloud 기술에 대한 역량과 전문성을 검증하고 입증하는 데 도움이 됩니다.
설명서 최종 업데이트: 2024년 3월 12일
실습 최종 테스트: 2024년 3월 12일
Copyright 2024 Google LLC All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.

