检查点
Provision Lab Environment
/ 20
Container-native Load Balancing Through Ingress
/ 20
Load Testing an Application
/ 20
Readiness and Liveness Probes
/ 20
Create Pod Disruption Budgets
/ 20
GKE 工作负载优化
GSP769

概览
使用 Google Cloud 的好处很多,按实际资源用量付费的结算模式就是其中之一。因此,您不仅需要为应用和基础设施分配合理数量的资源,还要切实高效地利用它们。GKE 为您提供了许多工具和策略,可帮助您减少对不同资源和服务的使用,并提高应用的可用性。
本实验将介绍几个有助您提高资源效率和工作负载可用性的概念。在了解并微调集群的工作负载后,您就能更好地确保只使用需要的资源,同时优化集群费用。
目标
在本实验中,您将学习如何完成以下任务:
- 通过 Ingress 创建容器原生负载均衡器
- 对应用执行负载测试
- 配置活跃性探测和就绪性探测
- 创建 Pod 中断预算
设置和要求
点击“开始实验”按钮前的注意事项
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。我们会为您提供新的临时凭据,让您可以在实验规定的时间内用来登录和访问 Google Cloud。
为完成此实验,您需要:
- 能够使用标准的互联网浏览器(建议使用 Chrome 浏览器)。
- 完成实验的时间 - 请注意,实验开始后无法暂停。
如何开始实验并登录 Google Cloud 控制台
-
点击开始实验按钮。如果该实验需要付费,系统会打开一个弹出式窗口供您选择付款方式。左侧是实验详细信息面板,其中包含以下各项:
- 打开 Google Cloud 控制台按钮
- 剩余时间
- 进行该实验时必须使用的临时凭据
- 帮助您逐步完成本实验所需的其他信息(如果需要)
-
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示登录页面。
提示:请将这些标签页安排在不同的窗口中,并将它们并排显示。
注意:如果您看见选择账号对话框,请点击使用其他账号。 -
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
{{{user_0.username | "<用户名>"}}} 您也可以在实验详细信息面板中找到用户名。
-
点击下一步。
-
复制下面的密码,然后将其粘贴到欢迎对话框中。
{{{user_0.password | "<密码>"}}} 您也可以在实验详细信息面板中找到密码。
-
点击下一步。
重要提示:您必须使用实验提供的凭据。请勿使用您的 Google Cloud 账号凭据。 注意:在本次实验中使用您自己的 Google Cloud 账号可能会产生额外费用。 -
继续在后续页面中点击以完成相应操作:
- 接受条款及条件。
- 由于该账号为临时账号,请勿添加账号恢复选项或双重验证。
- 请勿注册免费试用。
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

激活 Cloud Shell
Cloud Shell 是一种装有开发者工具的虚拟机。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行。Cloud Shell 提供可用于访问您的 Google Cloud 资源的命令行工具。
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell
。
如果您连接成功,即表示您已通过身份验证,且当前项目会被设为您的 PROJECT_ID 环境变量所指的项目。输出内容中有一行说明了此会话的 PROJECT_ID:
gcloud 是 Google Cloud 的命令行工具。它已预先安装在 Cloud Shell 上,且支持 Tab 自动补全功能。
- (可选)您可以通过此命令列出活跃账号名称:
-
点击授权。
-
现在,输出的内容应如下所示:
输出:
- (可选)您可以通过此命令列出项目 ID:
输出:
输出示例:
gcloud, in Google Cloud, refer to the gcloud CLI overview guide.
预配实验环境
- 将默认可用区设置为“
”:
-
点击授权。
-
创建包含三个节点的集群:
其中添加 --enable-ip-alias 标志是为了可以让 Pod 使用别名 IP,在通过 Ingress 配置容器原生负载均衡时将需要使用这些 IP。
在本实验中,您将使用一个简单的 HTTP Web 应用,并首先将其部署为单个 Pod。
- 为
gb-frontendPod 创建清单:
- 将新创建的清单应用到集群:
1 到 2 分钟才能看到此任务的得分。点击检查我的进度,验证已完成以下目标:
任务 1. 通过 Ingress 配置容器原生负载均衡
利用容器原生负载均衡,负载均衡器能够直接定位 Kubernetes Pod,还能将流量均匀分发给 Pod。
如果没有容器原生负载均衡,则负载均衡器流量将传输到节点实例组,然后通过 iptables 规则路由到不一定在同一节点中的 Pod。
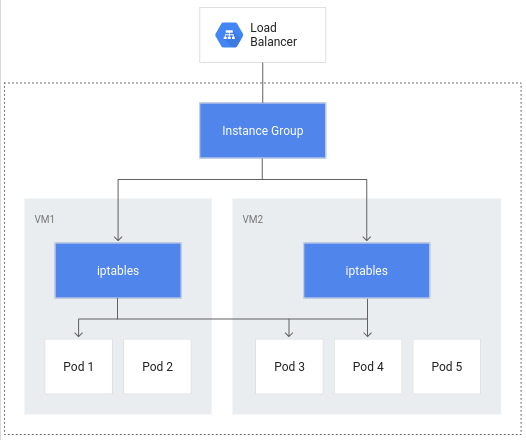
通过容器原生负载均衡,Pod 可以让核心对象实现负载均衡,从而有助于减少网络跃点的数量:
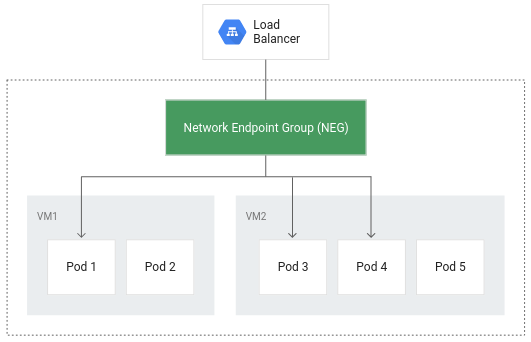
除了提高路由效率外,容器原生负载均衡还可以显著降低网络利用率、提高性能、在 Pod 之间均匀分发流量,以及执行应用级的健康检查。
为充分利用容器原生负载均衡,务必在集群上启用 VPC 原生设置。当您在创建集群并添加 --enable-ip-alias 标志时,系统会指明这一点。
- 下面的清单将配置一项
ClusterIP服务,此服务可用于将流量路由至应用 Pod,以便 GKE 创建网络端点组:
此清单中包含一个 annotations 字段,其中针对 cloud.google.com/neg 的注释可以在创建 Ingress 时,让您的应用实现容器原生负载均衡。
- 将所做的更改应用到集群:
- 然后,为应用创建 Ingress:
- 将所做的更改应用到集群:
创建 Ingress 后,系统将会在集群运行的每个可用区中创建一个 HTTP(S) 负载均衡器及相应的 NEG(网络端点组)。几分钟后,系统将会为该 Ingress 分配一个外部 IP。
所创建的负载均衡器会在您的项目中运行一项后端服务,以用于定义 Cloud Load Balancing 分发流量的方式。此后端服务具有相关联的健康状况。
- 如需检查该后端服务的健康状况,请首先检索其名称:
- 获取该服务的健康状况:
健康检查可能需要几分钟才能返回该服务的健康状况。
输出将如下所示:
当每个实例的健康状况都报告为“HEALTHY”时,您就可以通过该外部 IP 访问应用了。
- 使用以下命令检索该 Ingress:
- 在浏览器窗口中输入其外部 IP,系统将加载相应的应用。
点击检查我的进度,验证已完成以下目标:
任务 2. 对应用执行负载测试
在为应用 Pod 选择资源请求和限制,以及确定最佳的自动扩缩策略时,了解应用的容量至关重要。
在本实验开始时,您已经将应用部署为单个 Pod。对于未配置自动扩缩的单个 Pod,您可以对在该 Pod 上运行的应用执行负载测试,从而了解您的应用可处理的并发请求数、所需要的 CPU 和内存大小,以及它可能会如何应对高负载的情况。
在对 Pod 进行负载测试时,您将使用开源负载测试框架 Locust。
- 在 Cloud Shell 中输入以下命令,以下载 Locust 的 Docker 映像文件:
所提供的 locust-image 目录中包含 Locust 配置文件。
- 为 Locust 构建 Docker 映像,并将其存储在项目的 Container Registry 中:
- 验证该 Docker 映像已包含在项目的 Container Registry 中:
预期输出:

Locust 包含一台主工作器以及数台生成负载的工作器。
- 通过复制并应用清单,可为主工作器创建单个 Pod Deployment,并为其他工作器创建有 5 个副本的 Deployment:
- 如需访问 Locust 界面,请检索其对应的 LoadBalancer 服务的外部 IP 地址:
如果其外部 IP 值为 <pending>,则稍等片刻后重新运行上述命令,直至系统显示有效值。
- 在新的浏览器窗口中,转到
[EXTERNAL_IP_ADDRESS]:8089以打开 Locust 网页:
点击检查我的进度,验证已完成以下目标:
Locust 让您可以 swarm(召集)大量用户同时使用您的应用。您可以输入按特定速率生成的用户数来模拟流量。
-
在本例中,为了代表一个典型负载,为要模拟的用户数输入 200,并将 hatch rate(用户生成速率)设为 20。
-
点击 Start swarming(开始召集)。
几秒钟后,状态应显示为有 200 名用户在运行中,并且每秒请求数 (RPS) 约为 150 个。
-
切换到 Cloud 控制台,依次点击导航菜单 (
) > Kubernetes Engine。
-
从左侧窗格中选择工作负载。
-
然后,点击所部署的 gb-frontend Pod。
系统会将您转到“Pod 详细信息”页面,您可以在此页面中查看 Pod 的 CPU 利用率和内存利用率图表。观察其中的已使用值和已请求值。
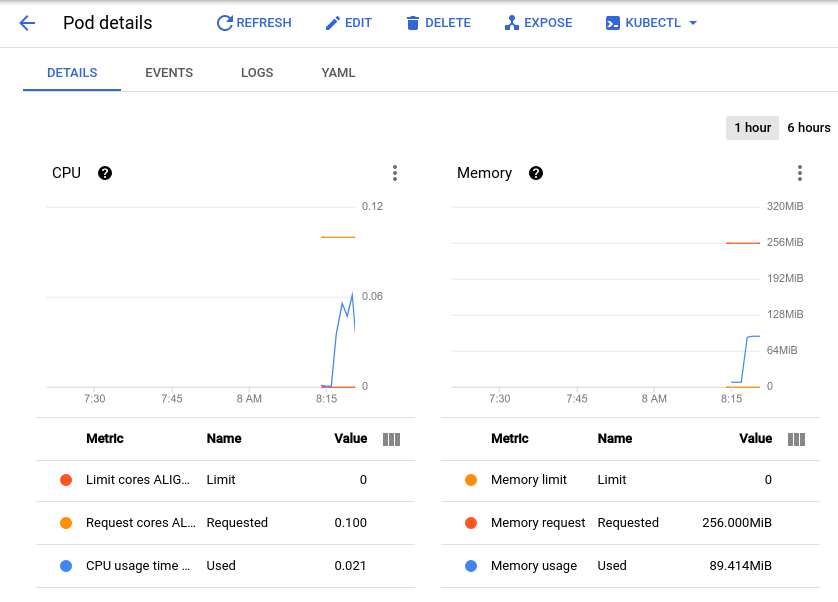
由于当前负载测试每秒钟大约会生成 150 个请求,因此您可能会发现 CPU 利用率在低至 0.04 高至 0.06 的区间内变化。这代表您的一个 Pod 的 CPU 请求利用率是 40-60%。另一方面,内存利用率始终保持在 80Mi 左右,明显低于请求的利用率 256Mi。这就是每个 Pod 的容量。此信息很有用,可便于您配置集群自动扩缩器、资源请求和限制,以及选择采用 Pod 横向自动扩缩器还是纵向自动扩缩器及其具体实现方式。
除了基准情况外,您还应考虑应用在流量激增或高峰后可能的表现。
-
返回 Locust 浏览器窗口,点击页面顶部 STATUS(状态)下的 Edit(修改)。
-
这次,为要模拟的用户数输入 900,并将用户生成速率设为 300。
-
点击 Start swarming(开始召集)。
您的 Pod 将会在 2-3 秒钟的时间内突然收到 700 个额外的请求。在 RPS 值达到 150 左右,并且状态显示有 900 名用户后,切换回到 Pod 详细信息页并观察图表的变化。
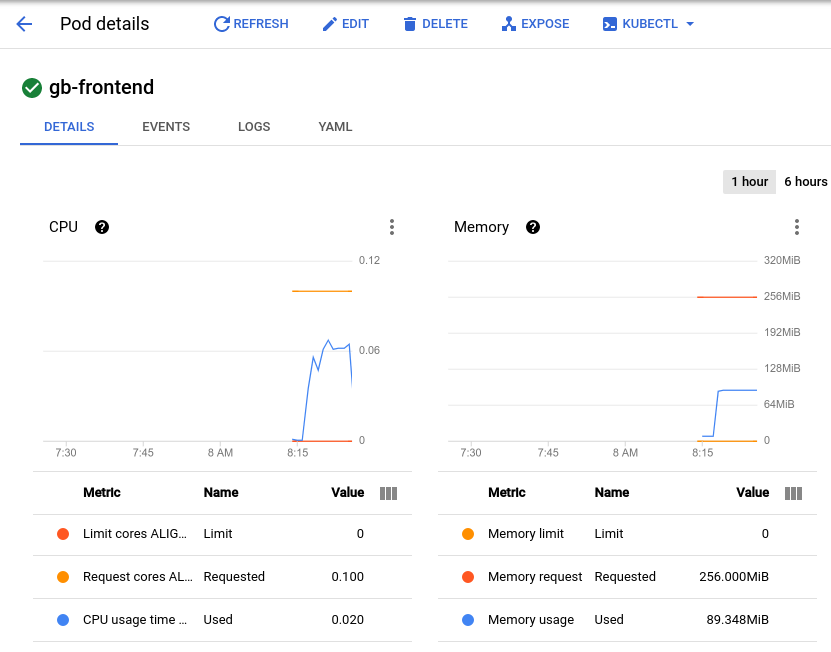
此时内存利用率仍然保持不变,但 CPU 利用率几乎达到了峰值 0.07,也就是说,您的 Pod 的 CPU 请求利用率达到了 70%。如果此应用是 Deployment,您也许可以将总内存请求量安全地降低到较低的值,并将横向自动扩缩器配置为在达到指定的 CPU 使用率时触发。
任务 3. 就绪性探测和活跃性探测
设置活跃性探测
如果您已经在 Kubernetes Pod 或 Deployment 规范中配置活跃性探测,它就会持续运行以检测容器是否需要重启并在需要时触发重启。此类探测可自动重启可能仍处于运行中状态的死锁应用,十分有用。例如,Kubernetes 托管的负载均衡器(如某个服务)只有在一个 Pod 的所有容器都通过就绪性探测后,才会向其后端发送流量。
- 为了展示活跃性探测是如何运作的,下面的代码将为 Pod 生成一个清单,该 Pod 将根据对所创建的文件执行 cat 命令的情况来执行活跃性探测:
- 将清单应用到您的集群以创建该 Pod:
其中,initialDelaySeconds 值表示在容器启动后到应执行第一次探测前的持续时间。periodSeconds 值表示执行探测的频率。
startupProbe,以指示容器内的应用是否启动。如果在 Pod 中添加了 startupProbe,则只有在它返回 Success 状态后,系统才会执行其他探测。对于启动时间变化不定的应用,建议执行此配置,以免应用因活跃性探测而中断。在本例中,活跃性探测本质上只检查容器的文件系统中是否存在文件 /tmp/alive。
- 通过查看 Pod 的事件来确认其容器的健康状况:
输出底部应该包含一个 Events 部分,其中包含该 Pod 的最后 5 个事件。此时,该 Pod 的事件中应仅包含与其创建和启动相关的事件:
此事件日志中将包含所有活跃性探测失败的容器以及因此而触发的重启。
- 手动删除活跃性探测正在使用的文件:
-
移除该文件后,活跃性探测所使用的
cat命令应该会返回一个非零退出代码。 -
再次查看该 Pod 的事件:
由于活跃性探测运行失败,您会发现系统在日志中添加了相应的事件,并显示已执行的一系列步骤。首先显示了活跃性探测失败 (Liveness probe failed: cat: /tmp/alive: No such file or directory),结尾指明正在再次启动容器 (Started container):
livenessProbe(活跃性探测),其结果取决于指定命令的退出代码。除了命令探测外,您还可以将 livenessProbe 配置为 HTTP 探测,其结果由 HTTP 响应决定。或配置为 TCP 探测,其结果取决于是否可以在特定端口建立 TCP 连接。设置就绪性探测
虽然通过活跃性探测可以确认 Pod 已成功启动且健康运行,但它也可能尚未做好准备,无法立即接收流量。这在作为服务后端(例如负载均衡器)的 Deployment 中很常见。而就绪性探测可用于确定 Pod 及其容器是否准备好开始接收流量。
- 为展示它是如何运作的,请创建一个清单,然后创建一个 Pod 作为测试 Web 服务器以及负载均衡器:
- 将清单应用到您的集群,并通过它来创建一个负载均衡器:
- 检索为您的负载均衡器分配的外部 IP 地址(在上一个命令完成后,可能需要 1 分钟的时间才能确定要分配的地址):
-
在浏览器窗口中输入该 IP 地址,您会发现系统返回一则错误消息,指明无法访问该站点。
-
查看该 Pod 的事件:
输出显示此次就绪性探测运行失败:
与活跃性探测不同,就绪性探测失败不会触发 Pod 重启。
- 使用以下命令生成就绪性探测要检查的文件:
现在,Pod 说明 Conditions 部分中的 Ready 值应显示为 True。
输出如下:
- 现在,刷新包含 readiness-demo-svc 外部 IP 的浏览器标签页。您应该会看到正确显示的“Welcome to nginx!”(欢迎访问 nginx!)消息。
通过为应用容器设置有意义的就绪性探测,可确保 Pod 只有在做好准备后才会接收流量。例如,检查应用所依赖的缓存在启动时是否加载,这就是有意义的就绪性探测。
点击检查我的进度,验证已完成以下目标:
任务 4. Pod 中断预算
若要确保 GKE 应用可靠、正常运行,一部分要依赖于充分利用 Pod 中断预算 (PDB)。PodDisruptionBudget 是一项 Kubernetes 资源,用于限制副本应用中因主动中断而同时停止运行的 Pod 数量。
主动中断包括多种管理操作,例如删除 Deployment,更新 Deployment 的 Pod 模板并执行滚动更新,排空应用 Pod 所在的节点,或者将 Pod 移到其他节点等。
首先,您必须将应用部署为 Deployment。
- 删除您的单个 Pod 应用:
- 生成一个清单,并将其创建为包含 5 个副本的 Deployment:
- 将此 Deployment 应用到您的集群:
点击检查我的进度,验证已完成以下目标:
创建 PDB 之前,您需要先排空集群中的节点,并观察应用在没有实施 PDB 时的行为。
- 循环遍历
default-pool节点的输出,并对每个节点运行kubectl drain命令,以排空这些节点:
上述命令将会从指定节点上逐出所有 Pod 并封锁该节点,以确保不会在该节点上创建新 Pod。在可用资源允许的情况下,Pod 会重新部署到其他节点上。
- 在排空节点后,查看您的
gb-frontend上的 Deployment 副本数量:
输出可能会如下所示:
如上面的输出所示,排空节点后,您的 Deployment 只有 0 个可用副本。由于没有任何可用的 Pod,您的应用实际上停止了运行。我们再来排空一次节点,但这次为您的应用设置 Pod 中断预算。
- 首先取消封锁节点,让已排空的节点恢复正常。下面的命令可将 Pod 重新部署到该节点上:
- 再次查看您的 Deployment 的状态:
现在输出应该如下所示,所有 5 个副本全都可用:
- 创建 Pod 中断预算,声明可用 Pod 的数量下限为 4:
- 再次排空您集群中的一个节点,并观察输出:
成功逐出应用的其中一个 Pod 后,它将会循环执行以下命令:
-
按 CTRL+C 退出该命令。
-
再次查看您的 Deployment 状态:
输出现在应该如下所示:
直到 Kubernetes 能够将第 5 个 Pod 部署到其他节点上,以逐出下一个 Pod 之前,其余的 Pod 都将依照 PDB 要求保持可用状态。本例中配置了 Pod 中断预算并指明了 min-available 值,但您也可以配置 PDB 并定义一个 max-unavailable 值。这两个值可表示为代表 Pod 数量的整数,也可表示为占 Pod 总数的百分比。
恭喜!
您已经学习了如何通过 Ingress 创建容器原生负载均衡器,以便更高效地利用负载均衡和路由。您还对 GKE 应用运行了简单的负载测试,并观察了它的基准 CPU 利用率和内存利用率,以及它是如何应对流量高峰的。此外,您还配置了活跃性探测和就绪性探测以及 Pod 中断预算,以确保您的应用正常运行。这些工具和方法相辅相成,可显著减少无关的网络流量,为运行良好的应用定义有意义的指标,并提高应用的可用性,从而全面提升应用在 GKE 上的运行效率。
后续步骤/了解详情
请查看以下资源,详细了解本实验中介绍的主题:
Google Cloud 培训和认证
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
上次更新手册的时间:2024 年 3 月 12 日
上次测试实验的时间:2024 年 3 月 12 日
版权所有 2024 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。

