Prüfpunkte
Calculate trips taken by Yellow taxi in each month of 2015
/ 10
Calculate average speed of Yellow taxi trips in 2015
/ 10
Test whether fields are good inputs to your fare forecasting model
/ 20
Create a BigQuery dataset to store models
/ 10
Create a taxifare model
/ 20
Evaluate classification model performance
/ 10
Predict taxi fare amount
/ 20
Taxikosten mit einem ML-Prognosemodell in BigQuery vorhersagen
- GSP246
- Überblick
- Einrichtung und Anforderungen
- Aufgabe 1: Taxidaten analysieren
- Aufgabe 2: Ziel festlegen
- Aufgabe 3: Features auswählen und Trainings-Dataset erstellen
- Aufgabe 4: BigQuery-Dataset zum Speichern von Modellen erstellen
- Aufgabe 5: BigQuery ML-Modelltyp auswählen und Optionen festlegen
- Aufgabe 6: Leistung eines Klassifizierungsmodells bewerten
- Aufgabe 7: Kosten einer Taxifahrt vorhersagen
- Aufgabe 8: Modell mit Feature Engineering verbessern
- Aufgabe 9: Wissen testen
- Aufgabe 10: Weitere Datasets
- Das wars! Sie haben das Lab erfolgreich abgeschlossen.
GSP246

Überblick
BigQuery ist eine vollständig verwaltete, automatisierte und kostengünstige Analysedatenbank von Google. Mit diesem Tool können Sie mehrere Terabyte an Daten abfragen und müssen dabei weder eine Infrastruktur verwalten noch benötigen Sie einen Datenbankadministrator.
Mit BigQuery ML können Data Analysts bei minimalem Programmieraufwand ML‑Modelle (Machine Learning) erstellen, trainieren und bewerten sowie damit Vorhersagen treffen.
In diesem Lab analysieren Sie mehrere Millionen Fahrten mit den typischen gelben New York City Taxi Cabs, die in einem öffentlichen BigQuery-Dataset verfügbar sind. Danach erstellen Sie anhand dieser Daten mithilfe von BigQuery ein ML‑Modell, das die voraussichtlichen Taxikosten auf Grundlage der Modelleingaben vorhersagt. Außerdem bewerten Sie die Leistung des Modells und nutzen es für Vorhersagen.
Lerninhalte
Aufgaben in diesem Lab:
- Mit BigQuery nach öffentlichen Datasets suchen
- Das öffentliche Dataset zu New York City Taxi Cabs abfragen und analysieren
- Ein Trainings- und Bewertungs-Dataset zur Batch-Vorhersage erstellen
- Prognosemodell (lineare Regression) in BigQuery ML erstellen
- Die Leistung Ihres ML-Modells bewerten
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange die Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung selbst durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Pop-up-Fenster geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können. Auf der linken Seite befindet sich der Bereich Details zum Lab mit diesen Informationen:
- Schaltfläche Google Cloud Console öffnen
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite Anmelden geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden. -
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}} Sie finden den Nutzernamen auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}} Sie finden das Passwort auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos. Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen. -
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.

Die BigQuery Console öffnen
- Klicken Sie in der Google Cloud Console im Navigationsmenü auf BigQuery.
Zuerst wird das Fenster Willkommen bei BigQuery in der Cloud Console geöffnet, das neben allgemeinen Informationen auch einen Link zur Kurzanleitung und zu den Versionshinweisen enthält.
- Klicken Sie auf Fertig.
Die BigQuery Console wird geöffnet.
Aufgabe 1: Taxidaten analysieren
Frage: Wie viele Fahrten mit NYC Taxi Cabs fanden im Jahr 2015 monatlich statt?
- Kopieren Sie die folgende SQL-Abfrage und fügen Sie sie in den Abfrage-EDITOR ein:
- Klicken Sie dann auf Ausführen.
Sie sollten das folgende Ergebnis erhalten:
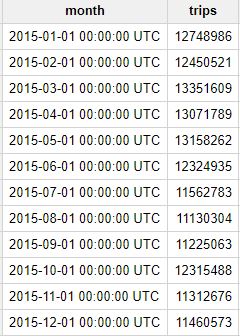
Wie zu sehen ist, gab es 2015 jeden Monat mehr als 10 Millionen Fahrten von NYC Taxi Cabs – nicht gerade wenig!
Abgeschlossene Aufgabe testen
Klicken Sie auf Fortschritt prüfen. Haben Sie die Aufgabe erfolgreich abgeschlossen, erhalten Sie ein Testergebnis.
Frage: Wie hoch war die Durchschnittsgeschwindigkeit im Jahr 2015 bei Fahrten mit NYC Taxi Cabs?
- Ersetzen Sie die vorherige Abfrage durch die folgende und klicken Sie dann auf Ausführen:
Sie sollten das folgende Ergebnis erhalten:

Tagsüber liegt die Durchschnittsgeschwindigkeit bei etwa 11–12 mph (18–19 km/h). Um 05:00 Uhr morgens ist sie mit ungefähr 21 mph (34 km/h) beinahe doppelt so hoch. Dies ergibt durchaus Sinn, da es um diese Uhrzeit wahrscheinlich weniger Verkehr auf den Straßen gibt.
Abgeschlossene Aufgabe testen
Klicken Sie auf Fortschritt prüfen. Haben Sie die Aufgabe erfolgreich abgeschlossen, erhalten Sie ein Testergebnis.
Aufgabe 2: Ziel festlegen
Sie erstellen in BigQuery nun ein ML-Modell, das auf Grundlage des historischen Taxifahrten-Datasets und der Angaben für eine konkrete Fahrt die Kosten einer Taxifahrt in New York City vorhersagt. Dies kann die Planung einer Fahrt für Fahrgast und Taxiunternehmen erleichtern.
Aufgabe 3: Features auswählen und Trainings-Dataset erstellen
Das Dataset zu Taxifahrten in NYC ist ein öffentliches Dataset der Stadt, das in BigQuery geladen wurde, damit Sie es analysieren können.
Unter diesem Link finden Sie eine vollständige Übersicht der Felder. Anschließend können Sie eine Vorschau des Datasets aufrufen und nützliche Features ermitteln, die den Zusammenhang zwischen bisherigen Daten zu Taxifahrten und einem konkreten Fahrpreis verdeutlichen.
Ihr Team möchte nun testen, ob sich die folgenden Felder gut als Eingaben für das Fahrtkosten-Prognosemodell eignen:
- Mautgebühren
- Fahrtkosten
- Tageszeit
- Startadresse
- Zieladresse
- Anzahl der Passagiere
- Ersetzen Sie die vorherige Abfrage durch folgende:
Beachten Sie bei der Abfrage Folgendes:
- Der Hauptteil der Abfrage befindet sich unten (
SELECT * from taxitrips). - Der Großteil der Extraktion aus dem NYC-Dataset wird in der Unterabfrage
taxitripsvorgenommen, in derenSELECT-Anweisung die Trainingsfeatures und Labels spezifiziert sind. - Mit der
WHERE-Klausel werden alle Daten entfernt, die Sie nicht für das Training verwenden möchten. - Die
WHERE-Klausel enthält außerdem eine Sampling-Klausel, sodass nur ein Tausendstel der Daten eingelesen wird. - Definieren Sie eine Variable namens
TRAIN, sodass Sie schnell einen unabhängigenEVAL-Satz erstellen können.
- Nachdem Sie nun den Zweck dieser Abfrage besser verstanden haben, klicken Sie auf Ausführen.
Das Ergebnis sollte ungefähr so aussehen:
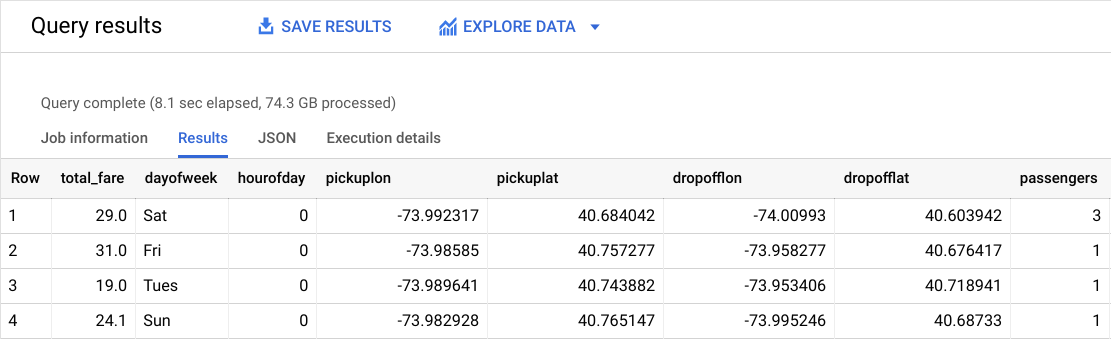
Wie heißt das Label (richtige Antwort)?
total_fare ist das Label (was Sie voraussagen werden). Dieses Feld setzt sich aus tolls_amount und fare_amount zusammen. Trinkgelder der Fahrgäste werden also nicht berücksichtigt, da diese nach eigenem Ermessen gegeben werden.
Abgeschlossene Aufgabe testen
Klicken Sie auf Fortschritt prüfen. Haben Sie die Aufgabe erfolgreich abgeschlossen, erhalten Sie ein Testergebnis.
Aufgabe 4: BigQuery-Dataset zum Speichern von Modellen erstellen
In diesem Abschnitt erstellen Sie ein neues BigQuery-Dataset, in dem Ihre ML-Modelle gespeichert werden.
-
Klicken Sie links unter Explorer auf das Symbol Aktionen ansehen neben der Projekt‑ID und klicken Sie dann auf Dataset erstellen.
-
Machen Sie im Dialogfeld „Dataset erstellen“ folgende Angaben:
- Geben Sie unter Dataset-ID den Begriff taxi ein.
- Wählen Sie für Standorttyp die Option us (mehrere Regionen in den USA) aus.
- Übernehmen Sie für alle anderen Werte die Standardeinstellung.
- Klicken Sie dann auf Dataset erstellen.
Abgeschlossene Aufgabe testen
Klicken Sie auf Fortschritt prüfen. Haben Sie die Aufgabe erfolgreich abgeschlossen, erhalten Sie ein Testergebnis.
Aufgabe 5: BigQuery ML-Modelltyp auswählen und Optionen festlegen
Nachdem Sie die Ausgangsfeatures ausgewählt haben, können Sie nun Ihr erstes ML-Modell in BigQuery erstellen.
Sie haben die Wahl zwischen folgenden Modelltypen:
- Prognose numerischer Werte wie der Verkäufe im kommenden Monat mit linearer Regression (linear_reg).
- Binäre oder mehrklassige Klassifikation wie Spam bzw. Nicht-Spam-E-Mails mit logistischer Regression (logistic_reg).
- k-Means-Clustering für unüberwachtes Lernen zur explorativen Datenanalyse (kmeans).
- Geben Sie die folgende Abfrage ein, um ein Modell zu erstellen und Modelloptionen festzulegen.
-
Klicken Sie dann auf Ausführen, um das Modell zu trainieren.
-
Warten Sie fünf bis zehn Minuten.
Sie werden mit folgender Benachrichtigung darüber informiert, dass der Vorgang abgeschlossen ist und das Modell erfolgreich trainiert wurde: „Durch diese Anweisung wird ein neues Modell namens qwiklabs-gcp-03-xxxxxxxx:taxi.taxifare_model erstellt.“
- Prüfen Sie nun, ob taxifare_model tatsächlich im Taxi-Dataset angezeigt wird.
Als Nächstes bewerten Sie die Leistung des Modells anhand neuer, ungesehener Bewertungsdaten.
Abgeschlossene Aufgabe testen
Klicken Sie auf Fortschritt prüfen. Haben Sie die Aufgabe erfolgreich abgeschlossen, erhalten Sie ein Testergebnis.
Aufgabe 6: Leistung eines Klassifizierungsmodells bewerten
Kriterien auswählen
Für lineare Regressionsmodelle sollten Sie einen Verlustmesswert wie die Wurzel der mittleren Fehlerquadratsumme (Root Mean Square Error, RMSE) verwenden. Es empfiehlt sich, ein Modell solange zu trainieren und zu verbessern, bis es den niedrigsten RMSE-Wert erreicht hat.
Das Feld mean_squared_error kann in BigQuery ML bei der Bewertung des trainierten ML-Modells abgefragt werden. Fügen Sie eine SQRT()-Funktion hinzu, um den RMSE-Wert zu erhalten.
Da die Trainingsphase nun abgeschlossen ist, können Sie die Leistung Ihres Modells mit dieser Abfrage und ML.EVALUATE testen.
- Kopieren Sie die folgende Abfrage und fügen Sie sie in den Abfrage-EDITOR ein. Klicken Sie dann auf Ausführen:
Damit wird das Modell mit dem Filter params.EVAL gegen ein anderes Dataset mit Taxifahrten ausgeführt.
- Prüfen Sie nach der Ausführung des Modells die Ergebnisse. Ihr RMSE-Wert kann geringfügig abweichen.
|
Zeile |
RMSE |
|
1 |
9,477056435999074 |
Nachdem Sie das Modell evaluiert haben, erhalten Sie einen RMSE-Wert von 9,47. Der Fehlerwert von 9,47 kann mit denselben Einheiten ausgewertet werden wie „total_fare“, also lautet das Ergebnis +-9,47 $.
Ob das Modell mit diesem Verlustmesswert bereit für die Produktion ist, hängt von den Benchmark-Kriterien ab, die Sie vor der Trainingsphase definiert haben. Beim Benchmarking wird die niedrigste akzeptable Leistung und Accuracy des Modells festlegt.
Abgeschlossene Aufgabe testen
Klicken Sie auf Fortschritt prüfen. Haben Sie die Aufgabe erfolgreich abgeschlossen, erhalten Sie ein Testergebnis.
Aufgabe 7: Kosten einer Taxifahrt vorhersagen
Als Nächstes schreiben Sie eine Abfrage, um mithilfe des neuen Modells Vorhersagen zu treffen.
- Kopieren Sie die folgende Abfrage und fügen Sie sie in den Abfrage-EDITOR ein. Klicken Sie dann auf Ausführen:
Nun werden die vom Modell vorhergesagten Taxikosten sowie die tatsächlichen Preise und weitere Features dieser Fahrten angezeigt. Ihre Ergebnisse sollten ähnlich wie die unten stehenden aussehen:

Abgeschlossene Aufgabe testen
Klicken Sie auf Fortschritt prüfen. Haben Sie die Aufgabe erfolgreich abgeschlossen, erhalten Sie ein Testergebnis.
Aufgabe 8: Modell mit Feature Engineering verbessern
Das Erstellen von Machine-Learning-Modellen ist ein iterativer Prozess. Nachdem die Leistung des ursprünglichen Modells bewertet wurde, ist es gang und gäbe, die Features und Zeilen zu überprüfen und zu optimieren. So sehen Sie, ob Sie ein noch besseres Modell erhalten können.
Trainings-Dataset filtern
Sehen Sie sich die allgemeinen Statistiken für Taxifahrtkosten an.
- Kopieren Sie die folgende Abfrage und fügen Sie sie in den Abfrage-EDITOR ein. Klicken Sie dann auf Ausführen:
Die Ausgabe sollte ungefähr so aussehen:
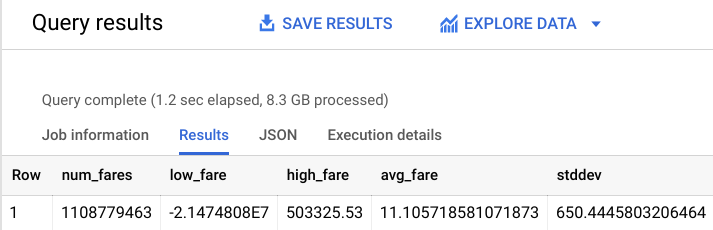
Wie zu sehen ist, gibt es im Dataset einige seltsame Ausreißer (negative Fahrtkosten oder Fahrtkosten über 50.000 $). Bringen Sie nun Ihre fachliche Erfahrung ein, damit das Modell nicht anhand dieser Sonderfälle lernt.
Beschränken Sie die Daten auf Fahrtkosten zwischen 6 und 200 $.
- Kopieren Sie die folgende Abfrage und fügen Sie sie in den Abfrage-EDITOR ein. Klicken Sie dann auf Ausführen:
Die Ausgabe sollte ungefähr so aussehen:
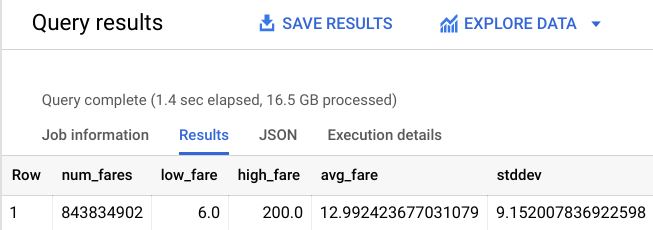
Das ist ein bisschen besser. Schränken Sie nun die zurückgelegte Strecke ein, damit Sie sich wirklich auf New York City konzentrieren.
- Kopieren Sie die folgende Abfrage und fügen Sie sie in den Abfrage-EDITOR ein. Klicken Sie dann auf Ausführen:
Die Ausgabe sollte ungefähr so aussehen:
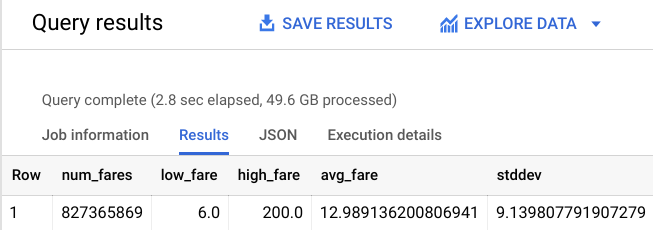
Sie haben immer noch ein großes Trainings-Dataset mit über 800 Millionen Fahrten, von dem das neue Modell lernen kann. Trainieren Sie das Modell mit diesen neuen Einschränkungen neu, um zu sehen, wie gut es funktioniert.
Modell erneut trainieren
Nennen Sie das neue Modell taxi.taxifare_model_2 und trainieren Sie das lineare Regressionsmodell neu, um den Gesamtpreis vorherzusagen. Sie werden feststellen, dass auch einige berechnete Features für die euklidische Entfernung (gerade Linie) zwischen Abholort und Ziel hinzugefügt wurden.
- Kopieren Sie die folgende Abfrage und fügen Sie sie in den Abfrage-EDITOR ein. Klicken Sie dann auf Ausführen:
Es kann einige Minuten dauern, bis das Modell neu trainiert ist. Sie können mit dem nächsten Schritt fortfahren, wenn Sie in der Console die folgende Nachricht erhalten:
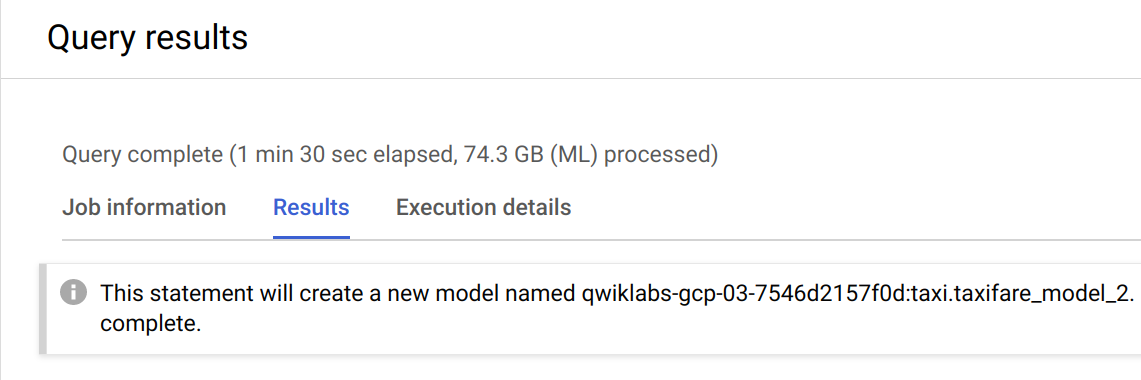
Neues Modell bewerten
Das lineare Regressionsmodell wurde optimiert. Sie können es nun zum Bewerten der Leistung des Datasets verwenden.
- Kopieren Sie die folgende Abfrage und fügen Sie sie in den Abfrage-EDITOR ein. Klicken Sie dann auf Ausführen:
Die Ausgabe sollte ungefähr so aussehen:
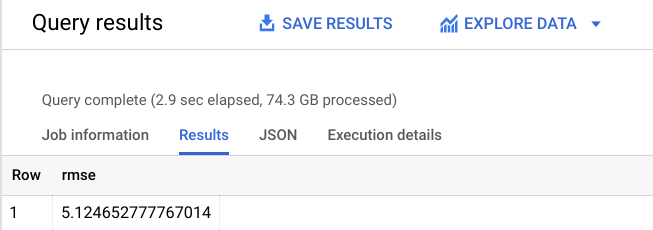
Wie zu sehen ist, haben Sie den RMSE-Wert auf +-5,12 $ gesenkt, was deutlich besser ist als +-9,47 $ für Ihr erstes Modell.
Da der RMSE-Wert die Standardabweichung von Vorhersagefehlern definiert, können Sie feststellen, dass die neu trainierte lineare Regression das Modell erheblich präziser gemacht hat.
Aufgabe 9: Wissen testen
Im Folgenden stellen wir Ihnen einige Multiple-Choice-Fragen, um Ihr bisher erworbenes Wissen zu testen und zu festigen. Beantworten Sie die Fragen so gut Sie können.
Aufgabe 10: Weitere Datasets
Sie können mit dem Projekt bigquery-public-data das Erstellen von Modellen an anderen Datasets üben, z. B. mit einem Prognosemodell für Taxikosten in Chicago.
-
Zum Öffnen des Datasets bigquery-public-data klicken Sie auf +Hinzufügen > Projekt nach Name markieren > Projektnamen eingeben. Geben Sie dann den Namen
bigquery-public-dataein. -
Klicken Sie auf Markieren.
Das Projekt bigquery-public-data wird im Bereich „Explorer“ aufgelistet.
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
Sie haben erfolgreich ein ML‑Modell in BigQuery erstellt, um die Kosten für Taxifahrten in New York City zu berechnen.
Weitere Informationen
- Weitere Informationen zu BigQuery ML finden Sie in der Dokumentation zu BigQuery ML.
- Weitere Informationen zum Verwalten von BigQuery ML‑Modellen in Vertex AI finden Sie in der Dokumentation zum Registrieren von BigQuery ML‑Modellen bei Model Registry.
Google Cloud-Schulungen und -Zertifizierungen
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 7. Februar 2024 aktualisiert
Lab zuletzt am 24. August 2023 getestet
© 2024 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.

