Puntos de control
Calculate trips taken by Yellow taxi in each month of 2015
/ 10
Calculate average speed of Yellow taxi trips in 2015
/ 10
Test whether fields are good inputs to your fare forecasting model
/ 20
Create a BigQuery dataset to store models
/ 10
Create a taxifare model
/ 20
Evaluate classification model performance
/ 10
Predict taxi fare amount
/ 20
Predice las tarifas de taxis con un modelo de previsión de AA de BigQuery
- GSP246
- Descripción general
- Configuración y requisitos
- Tarea 1: Explora los datos de taxis de NYC
- Tarea 2: Identifica un objetivo
- Tarea 3: Selecciona atributos y crea tu conjunto de datos de entrenamiento
- Tarea 4: Crea un conjunto de datos de BigQuery para almacenar modelos
- Tarea 5: Selecciona un tipo de modelo de BigQuery ML y especifica las opciones
- Tarea 6: Evalúa el rendimiento del modelo de clasificación
- Tarea 7: Predice el importe de las tarifas de taxis
- Tarea 8: Mejora el modelo con la ingeniería de atributos
- Tarea 9: Pon a prueba tus conocimientos
- Tarea 10: Otros conjuntos de datos para explorar
- ¡Felicitaciones!
GSP246

Descripción general
BigQuery es la base de datos analítica de bajo costo, no-ops y completamente administrada de Google. Con BigQuery, puedes consultar muchos terabytes de datos sin tener que administrar ninguna infraestructura y sin la necesidad de un administrador de base de datos.
BigQuery ML les proporciona a los analistas de datos la capacidad de crear, entrenar, evaluar y predecir a través de modelos de aprendizaje automático con programación mínima.
En este lab, trabajarás con millones de viajes de taxis amarillos de la ciudad de Nueva York disponibles en un conjunto de datos públicos de BigQuery. Usarás esos datos para crear un modelo de aprendizaje automático en BigQuery para predecir la tarifa del viaje en función de las entradas del modelo, y evaluarás su rendimiento y harás predicciones con él.
Aprendizajes esperados
En este lab, aprenderás a realizar las siguientes tareas:
- Usar BigQuery para buscar conjuntos de datos públicos
- Consultar y explorar el conjunto de datos públicos de taxis
- Crear un conjunto de datos de entrenamiento y evaluación para usar en la predicción por lotes
- Crear un modelo de previsión (regresión lineal) en BigQuery ML
- Evaluar el rendimiento de tu modelo de aprendizaje automático
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab: Recuerda que, una vez que comienzas un lab, no puedes pausarlo.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haga clic en el botón Comenzar lab. Si debe pagar por el lab, se abrirá una ventana emergente para que seleccione su forma de pago. A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón Abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debe usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordene las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta. -
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}} También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}} También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud. Nota: Usar tu propia Cuenta de Google podría generar cargos adicionales. -
Haga clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.

Cómo abrir la consola de BigQuery
- En la consola de Google Cloud, seleccione elmenú de navegación > BigQuery.
Se abrirá el cuadro de mensaje Te damos la bienvenida a BigQuery en la consola de Cloud. Este cuadro de mensaje contiene un vínculo a la guía de inicio rápido y las notas de la versión.
- Haga clic en Listo.
Se abrirá la consola de BigQuery.
Tarea 1: Explora los datos de taxis de NYC
Pregunta: ¿Cuántos viajes por mes hicieron los taxis amarillos en 2015?
- Copia el siguiente código SQL y pégalo en el EDITOR de consultas:
- Luego, haz clic en Ejecutar.
Deberías recibir el siguiente resultado:
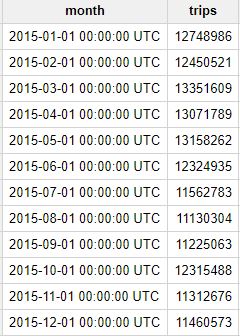
Como podemos ver, todos los meses del año 2015 hubo más de 10 millones de viajes en taxi en la ciudad de Nueva York. No es una cantidad pequeña.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará una puntuación de evaluación.
Pregunta: ¿Cuál fue la velocidad promedio de los viajes de taxis amarillos en 2015?
- Reemplaza la consulta anterior por lo siguiente y, luego, haz clic en Ejecutar:
Deberías recibir el siguiente resultado:

Durante el día, la velocidad promedio es de aproximadamente 18 a 19 km/h; pero, a las 5:00 a.m., la velocidad promedio casi se duplica a 34 km/h. Por intuición, esto tiene sentido, ya que probablemente haya menos tráfico en las calles a las 5:00 a.m.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará una puntuación de evaluación.
Tarea 2: Identifica un objetivo
Ahora crearás un modelo de aprendizaje automático en BigQuery para predecir el precio de un viaje en taxi en la ciudad de Nueva York basándote en el conjunto de datos históricos y los datos de viajes. Predecir la tarifa antes de acceder al servicio puede resultar muy útil cuando se trata de la planificación de viajes, tanto en el caso del pasajero como de la agencia de taxis.
Tarea 3: Selecciona atributos y crea tu conjunto de datos de entrenamiento
El conjunto de datos de taxis amarillos de la ciudad de Nueva York es un conjunto de datos públicos que proporciona la ciudad y que se cargó en BigQuery para que lo puedas analizar.
Explora la lista completa de campos y, luego, obtén una vista previa del conjunto de datos en busca de atributos útiles que ayudarán a que un modelo de aprendizaje automático comprenda la relación entre los datos sobre viajes históricos en taxi y el precio de la tarifa.
Tu equipo decide probar si estos campos representan buenas entradas para tu modelo de previsión de tarifas:
- Importe de peaje
- Importe de tarifa
- Hora del día
- Dirección de partida
- Dirección de destino
- Cantidad de pasajeros
- Reemplaza la consulta por los siguientes valores:
Observa algunos puntos sobre la consulta:
- La parte principal de la consulta se encuentra al final (
SELECT * from taxitrips). -
taxitripshace la mayor parte de la extracción del conjunto de datos de la ciudad de Nueva York. La variableSELECTcontiene tu etiqueta y los atributos de entrenamiento. - La variable
WHEREquita los datos sobre los que no deseas entrenar. -
WHEREtambién incluye una cláusula de muestra para seleccionar solo 1/1,000 de los datos. - Define una variable llamada
TRAINpara poder compilar con rapidez un conjuntoEVALindependiente.
- Ahora que comprendes mejor el propósito de esta consulta, haz clic en Ejecutar.
Deberías obtener un resultado similar al siguiente:
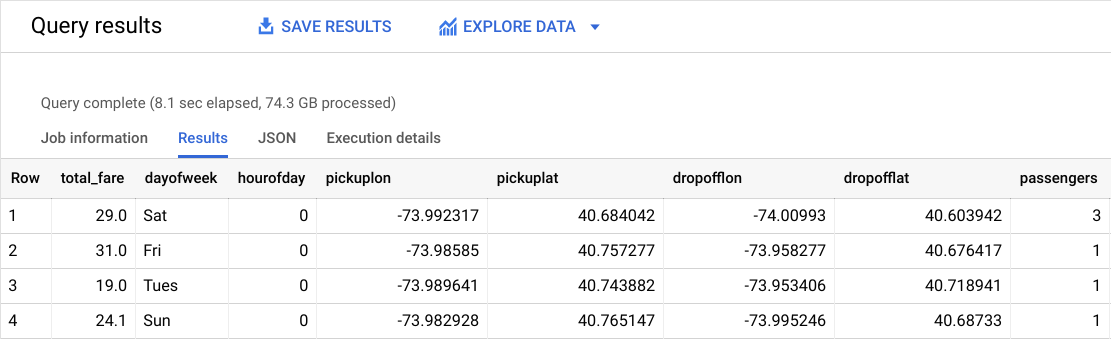
¿Cuál es la etiqueta (respuesta correcta)?
total_fare es la etiqueta (lo que vas a predecir). Creaste este campo a partir de tolls_amount y fare_amount para poder ignorar las propinas de los clientes como parte del modelo, ya que estas son a discreción.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará una puntuación de evaluación.
Tarea 4: Crea un conjunto de datos de BigQuery para almacenar modelos
En esta sección, crearás un conjunto de datos nuevo de BigQuery que almacenará tus modelos de AA.
-
En el panel Explorador, que se encuentra a la izquierda, haz clic en el ícono Ver acciones junto al ID del proyecto y, luego, haz clic en Crear conjunto de datos.
-
En el diálogo Crear conjunto de datos, ingresa lo siguiente:
- En ID de conjunto de datos, escribe taxi.
- Selecciona us (varias regiones en Estados Unidos) como el Tipo de ubicación.
- Deja los demás valores en la configuración predeterminada.
- Luego, haz clic en Crear conjunto de datos.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará una puntuación de evaluación.
Tarea 5: Selecciona un tipo de modelo de BigQuery ML y especifica las opciones
Ahora que ya seleccionaste tus atributos iniciales, tienes todo listo para crear tu primer modelo de AA en BigQuery.
Hay varios tipos de modelos entre los cuales puede elegir:
- La previsión de valores numéricos, como las ventas del mes próximo, con regresión lineal (linear_reg).
- La clasificación binaria o multiclase, como los correos electrónicos deseados y no deseados, con regresión logística (logistic_reg).
- El agrupamiento en clústeres de k-means si deseas un aprendizaje sin supervisión de exploración (kmeans).
- Ingresa la siguiente consulta para crear un modelo y especifica sus opciones.
-
Luego, haz clic en Ejecutar para entrenar tu modelo.
-
Espera a que el modelo se entrene (de 5 a 10 minutos).
Luego del entrenamiento del modelo, verás el mensaje "This statement will create a new model named qwiklabs-gcp-03-xxxxxxxx:taxi.taxifare_model", que indica que el modelo se entrenó correctamente.
- Revisa tu conjunto de datos de taxis y confirma que ahora aparezca taxifare_model.
A continuación, evaluarás el rendimiento del modelo en comparación con nuevos datos de evaluación no vistos.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará una puntuación de evaluación.
Tarea 6: Evalúa el rendimiento del modelo de clasificación
Selecciona tus criterios de rendimiento
Para los modelos de regresión lineal, debes usar una métrica de pérdidas como raíz cuadrada del error cuadrático medio (RMSE). Debes continuar entrenando y mejorando el modelo hasta que tenga la RMSE más baja.
En BQML, mean_squared_error es un campo para consultas cuando evalúas tu modelo entrenado de AA. Agrega un SQRT() para obtener el RMSE.
Ahora que el entrenamiento se completó, puedes evaluar qué tan bien se desempeña el modelo con esta consulta usando ML.EVALUATE.
- Copia el siguiente código, pégalo en el EDITOR de consultas y haz clic en Ejecutar:
Ahora estás evaluando el modelo con un conjunto distinto de viajes de taxi con el filtro params.EVAL.
- Después de que el modelo se ejecute, revisa los resultados (el valor de la RMSE de tu modelo variará ligeramente).
|
Fila |
RMSE |
|
1 |
9.477056435999074 |
Luego de evaluar tu modelo, obtienes un RMSE de 9.47. Como calculamos la raíz del error cuadrático medio (RMSE), el error de 9.47 se puede evaluar en las mismas unidades que total_fare, de manera que es +-$9.47.
Conocer si esta métrica de pérdidas es aceptable o no para llevar tu modelo a producción depende totalmente de tus criterios de comparativas, que se configuran antes de comenzar a entrenar los modelos. Las comparativas implican establecer un nivel mínimo de exactitud y rendimiento aceptable.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará una puntuación de evaluación.
Tarea 7: Predice el importe de las tarifas de taxis
A continuación, escribe una consulta para usar tu nuevo modelo y hacer predicciones con él.
- Copia el siguiente código, pégalo en el EDITOR de consultas y haz clic en Ejecutar:
Ahora verás las predicciones del modelo para tarifas de taxi junto con las tarifas reales y otros atributos de esos viajes. Tus resultados deberían ser similares a los que se muestran a continuación:

Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará una puntuación de evaluación.
Tarea 8: Mejora el modelo con la ingeniería de atributos
La creación de modelos de aprendizaje automático es un proceso iterativo. Una vez evaluado el rendimiento de nuestro modelo inicial, a menudo volvemos atrás y reducimos nuestros atributos y filas para ver si podemos conseguir un modelo todavía mejor.
Filtra el conjunto de datos de entrenamiento
Ahora, visualiza las estadísticas comunes para las tarifas de taxis.
- Copia el siguiente código, pégalo en el EDITOR de consultas y haz clic en Ejecutar:
Deberías obtener un resultado similar al siguiente:
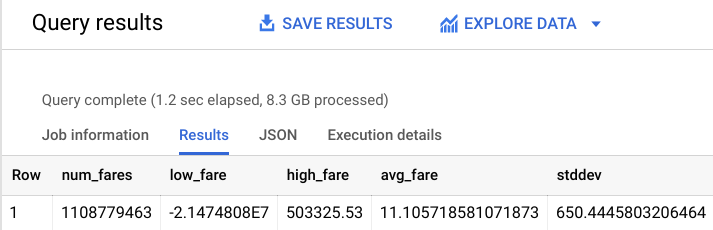
Como puedes ver, hay algunos valores atípicos extraños en nuestro conjunto de datos (tarifas negativas o superiores a $50,000). Aplica algo de nuestra experiencia en el tema para evitar que el modelo aprenda de valores atípicos extraños.
Limita los datos solo a tarifas que se encuentren entre $$6 y $$200.
- Copia el siguiente código, pégalo en el EDITOR de consultas y haz clic en Ejecutar:
Deberías obtener un resultado similar al siguiente:
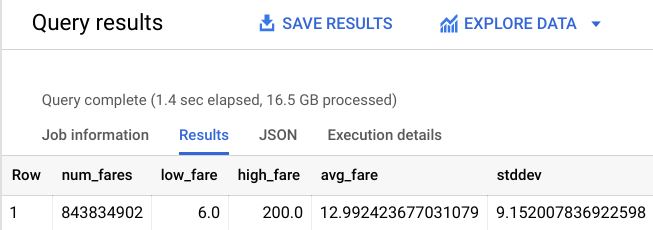
Eso está un poco mejor. Mientras haces esto, limita la distancia recorrida de modo que te enfoques totalmente en la ciudad de Nueva York.
- Copia el siguiente código, pégalo en el EDITOR de consultas y haz clic en Ejecutar:
Deberías obtener un resultado similar al siguiente:
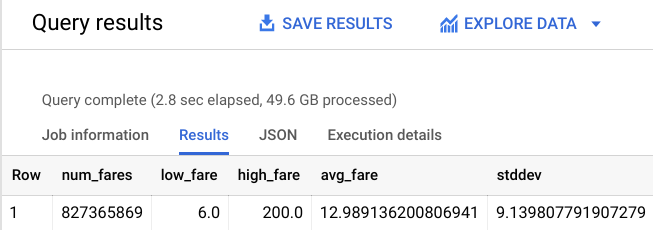
Todavía tienes un conjunto de datos de entrenamiento grande de más de 800 millones de viajes a partir del que aprenderá nuestro modelo nuevo. Vuelve a entrenar el modelo con estas nuevas limitaciones y observa su rendimiento.
Vuelve a entrenar el modelo
Asigna el nombre taxi.taxifare_model_2 al nuevo modelo y vuelve a entrenar el modelo de regresión lineal para predecir la tarifa total. Notarás que también agregaste algunos atributos calculados para la distancia euclidiana (línea recta) entre las ubicaciones para recoger y dejar pasajeros.
- Copia el siguiente código, pégalo en el EDITOR de consultas y haz clic en Ejecutar:
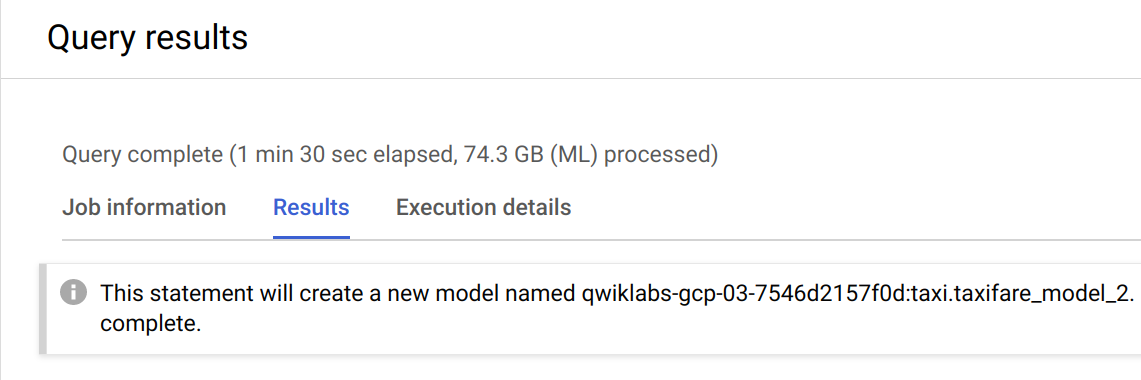
Volver a entrenar el modelo puede llevar algunos minutos. Puedes ir al siguiente paso cuando recibas este mensaje en la consola:
Evalúa el modelo nuevo
Ahora que el modelo de regresión lineal se ha optimizado, evalúa el conjunto de datos con él y observa su rendimiento.
- Copia el siguiente código, pégalo en el EDITOR de consultas y haz clic en Ejecutar:
Deberías obtener un resultado similar al siguiente:
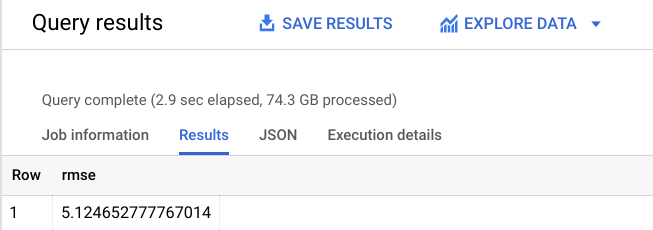
Como puedes ver, bajamos la RMSE a +-$$5.12. Esto es mucho mejor que el valor +-$$9.47 de tu primer modelo.
Dado que la RMSE define la desviación estándar de los errores de predicción, vemos que la regresión lineal que se volvió a entrenar hizo que nuestro modelo fuera mucho más preciso.
Tarea 9: Pon a prueba tus conocimientos
A continuación, se presentan algunas preguntas de opción múltiple para reforzar tus conocimientos de los conceptos de este lab. Trata de responderlas lo mejor posible.
Tarea 10: Otros conjuntos de datos para explorar
Puedes utilizar el proyecto bigquery-public-data si deseas explorar la creación de modelos en otros conjuntos de datos, como la previsión de tarifas para viajes en taxi en Chicago.
-
Para abrir el conjunto de datos bigquery-public-data, haz clic en +Agregar > Destaca un proyecto por nombre > Ingresa el nombre del proyecto y, luego, escribe el nombre
bigquery-public-data. -
Haz clic en Destacar.
El proyecto bigquery-public-data aparecerá en la sección Explorador.
¡Felicitaciones!
Creaste con éxito un modelo de aprendizaje automático en BigQuery para prever la tarifa de los taxis de la ciudad de Nueva York.
Próximos pasos y más información
- Para obtener más información sobre BigQuery ML, consulta la documentación.
- Para obtener más información sobre cómo administrar modelos de BigQuery ML en Vertex AI, consulta la documentación para registrar modelos de BigQuery ML con Model Registry.
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 7 de febrero de 2024
Prueba más reciente del lab: 24 de agosto de 2023
Copyright 2024 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.

