チェックポイント
Calculate trips taken by Yellow taxi in each month of 2015
/ 10
Calculate average speed of Yellow taxi trips in 2015
/ 10
Test whether fields are good inputs to your fare forecasting model
/ 20
Create a BigQuery dataset to store models
/ 10
Create a taxifare model
/ 20
Evaluate classification model performance
/ 10
Predict taxi fare amount
/ 20
BigQuery ML 予測モデルによるタクシー運賃の予測
GSP246

概要
BigQuery は、Google が低価格で提供する NoOps のフルマネージド分析データベースです。テラバイト単位の大規模なデータをクエリすることが可能で、インフラストラクチャを所有して管理したりデータベース管理者を配置したりする必要はありません。
BigQuery ML は、最小限のコーディングで ML モデルを作成、トレーニング、評価、予測する機能をデータ アナリストに提供します。
このラボでは、BigQuery の一般公開データセットの中から、数百万件に及ぶニューヨーク市内のタクシー賃走データを探索します。このデータを使用して ML モデルを BigQuery 内に作成し、モデル入力に基づいてタクシー運賃を予測します。次に、モデルの性能を評価し、そのモデルで予測を行います。
学習内容
このラボでは、次のタスクの実行方法について学びます。
- BigQuery を使用して一般公開データセットを見つける
- タクシーの一般公開データセットでクエリを実行して探索する
- バッチ予測に使用するトレーニングと評価のデータセットを作成する
- BigQuery ML で予測(線形回帰)モデルを作成する
- ML モデルの性能を評価する
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google Cloud コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウでリンクを開く] を選択します)。
ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
{{{user_0.username | "Username"}}} [ラボの詳細] パネルでも [ユーザー名] を確認できます。
-
[次へ] をクリックします。
-
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
{{{user_0.password | "Password"}}} [ラボの詳細] パネルでも [パスワード] を確認できます。
-
[次へ] をクリックします。
重要: ラボで提供された認証情報を使用する必要があります。Google Cloud アカウントの認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後、このタブで Google Cloud コンソールが開きます。

BigQuery コンソールを開く
- Google Cloud コンソールで、ナビゲーション メニュー > [BigQuery] を選択します。
[Cloud コンソールの BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスには、クイックスタート ガイドとリリースノートへのリンクが表示されます。
- [完了] をクリックします。
BigQuery コンソールが開きます。
タスク 1. ニューヨーク市のタクシーデータを探索する
質問: 2015 年のイエロー タクシーの毎月の賃走回数はどれくらいですか。
- 次の SQL コードをコピーしてクエリエディタに貼り付けます。
- [実行] をクリックします。
次の結果が表示されます。
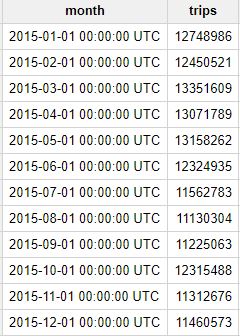
2015 年におけるニューヨーク市内のタクシー賃走回数は、毎月 1,000 万回を超えていることがわかります。これはかなりの量です。
完了したタスクをテストする
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが付与されます。
質問: 2015 年のイエロー タクシーの平均速度は?
- 前のクエリを以下に置き換え、[実行] をクリックします。
次の結果が表示されます。

日中の平均速度はおよそ時速 11~12 マイルですが、午前 5 時の平均速度はほぼ倍の時速 21 マイルになっています。午前 5 時は交通量が少ないはずなので、これは直感的に理解できます。
完了したタスクをテストする
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが付与されます。
タスク 2. 対象を特定する
次に、機械学習モデルを BigQuery に作成し、過去の賃走データセットに基づいてニューヨーク市のタクシー運賃を予測します。乗車前に運賃を予測できれば、乗客とタクシー会社の双方が、より効率的に乗車と配車の計画を立てられるようになります。
タスク 3. 特徴量を選択し、トレーニング データセットを作成する
ニューヨーク市のイエロー タクシーのデータセットは、市が提供する一般公開データセットです。これは BigQuery に読み込まれ、自由に探索できるようになっています。
フィールドの全一覧を確認してから、データセットをプレビューし、ML モデルが過去のタクシー賃走と運賃の関係を理解するのに役立つ特徴を見つけます。
以下のフィールドが運賃予測モデルに適した入力であるかどうかをテストします。
- 通行料
- 運賃
- 時間帯
- 乗車場所
- 降車場所
- 乗客の人数
- クエリを以下に置き換えます。
このクエリについて、以下の点に注意します。
- クエリのメインの部分は一番下の「
SELECT * FROM taxitrips」です。 -
taxitripsがニューヨーク市のデータセットの抽出の大部分を担い、SELECTにトレーニングの特徴とラベルが含まれます。 -
WHEREでトレーニングを行わないデータを取り除きます。 -
WHEREには、データの 1/1,000 のみを取得するためのサンプリング句も含まれます。 - 独立した
EVALセットを簡単に構築できるよう、TRAINという変数を定義しています。
- このクエリの目的について理解を深めたところで、[実行] をクリックします。
次のような結果が表示されます。
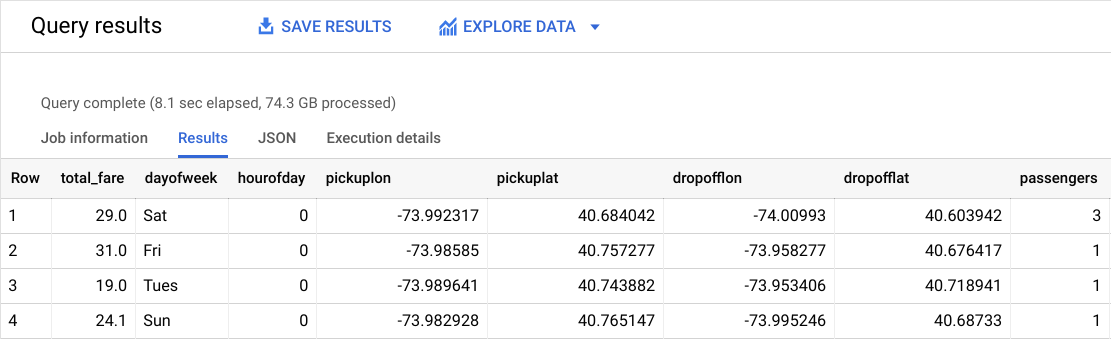
どれがラベル(正解)ですか。
total_fare がラベル(今回の予測対象)です。このフィールドは tolls_amount と fare_amount から作成しています。チップは任意であるため、モデルでは無視できます。
完了したタスクをテストする
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが付与されます。
タスク 4. モデルを格納する BigQuery データセットを作成する
このセクションでは、新しい BigQuery データセットを作成します。このデータセットに ML モデルを格納します。
-
左側の [エクスプローラ] パネルで、プロジェクト ID の横にある [アクションを表示] アイコンをクリックした後、[データセットを作成] をクリックします。
-
[データセットを作成] ダイアログに、次のように入力します。
- [データセット ID] に「taxi」と入力します。
- ロケーション タイプとして、[us(米国の複数のリージョン)] を選択します。
- その他の値はデフォルトのままにします。
- [データセットを作成] をクリックします。
完了したタスクをテストする
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが付与されます。
タスク 5. BigQuery ML モデルタイプを選択し、オプションを指定する
最初に使用する特徴を選択したので、ML モデルを BigQuery で作成する準備ができました。
次のモデルタイプから選択できます。
- 予測: 線形回帰による、翌月の売上などの数値の予測(linear_reg)。
- 分類: ロジスティック回帰による、迷惑メールの分類などのバイナリ分類またはマルチクラス分類(logistic_reg)。
- クラスタリング: 原因分析のために教師なし学習を使用する場合に利用できる、K 平均法クラスタリング(kmeans)。
- 次のクエリを入力して、モデルを作成し、モデル オプションを指定します。
-
次に、[実行] をクリックしてモデルのトレーニングを行います。
-
モデルのトレーニングが終わるのを待ちます(5~10 分)。
モデルのトレーニングが終わると、モデルが正しくトレーニングされたことを示す「このステートメントにより、qwiklabs-gcp-03-xxxxxxxx:taxi.taxifare_model という名前の新しいモデルが作成されます。」というメッセージが表示されます。
- taxi データセット内に taxifare_model があることを確認します。
次に、未知の評価データに対するモデルの性能を評価します。
完了したタスクをテストする
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが付与されます。
タスク 6. 分類モデルの性能を評価する
性能の評価基準を選択する
線形回帰モデルには、二乗平均平方根誤差(RMSE)などの損失指標を使用します。RMSE が下がるまでトレーニングを続け、モデルを改善していきます。
BQML では、トレーニング済みの ML モデルを評価するときにクエリ可能なフィールドとして mean_squared_error があります。RMSE を取得するには SQRT() を追加します。
トレーニングが完了したので、ML.EVALUATE を使用したクエリでモデルの性能を評価できます。
- 以下をコピーしてクエリエディタに貼り付け、[実行] をクリックします。
params.EVAL フィルタで、異なるタクシー賃走データセットに対してモデルを評価します。
- モデルの実行後、モデルの結果を確認します(モデルの実際の RMSE 値はわずかに異なる場合があります)。
|
行 |
rmse |
|
1 |
9.477056435999074 |
モデルを評価したら、RMSE が 9.47 になりました。ここで取得したのは二乗平均平方根誤差(RMSE)であるため、誤差 9.47 は total_fare と同じ単位で評価できます。したがって、+-$9.47 になります。
この損失指標で、このモデルを本番環境に使用してもいいかどうかは、モデルのトレーニング開始前に設定するベンチマーク基準によって異なります。ベンチマークとは、許容できる最低レベルのモデルの性能と精度を確立するための基準です。
完了したタスクをテストする
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが付与されます。
タスク 7. タクシー運賃を予測する
次に、新しいモデルを使用して予測を行うためのクエリを作成します。
- 以下をコピーしてクエリエディタに貼り付け、[実行] をクリックします。
タクシー運賃に対するモデルの予測が、その賃走の実際の運賃とその他の特徴とともに表示されます。結果は以下のようになります。

完了したタスクをテストする
[進行状況を確認] をクリックして、実行したタスクを確認します。タスクが正常に完了すると、評価スコアが付与されます。
タスク 8. 特徴量エンジニアリングによるモデルの強化
機械学習モデルの構築は反復的なプロセスです。初期モデルの性能を評価した後、前に戻って機能や行をプルーニングし、改善の余地がないか確認します。
トレーニング データセットのフィルタリング
次に、タクシー運賃の一般的な統計情報を表示します。
- 以下をコピーしてクエリエディタに貼り付け、[実行] をクリックします。
次のような出力が返されます。
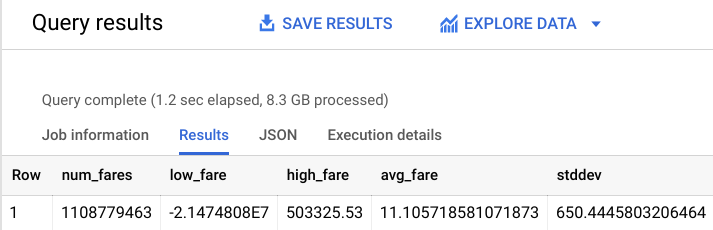
データセットに異常値(負の値の運賃や $50,000 を超える運賃など)があるのがわかります。モデルが不自然な外れ値を学習しないように、タクシー運賃に関する知識を適用します。
$6 から $200 までの間の運賃のみにデータを制限します。
- 以下をコピーしてクエリエディタに貼り付け、[実行] をクリックします。
次のような出力が返されます。
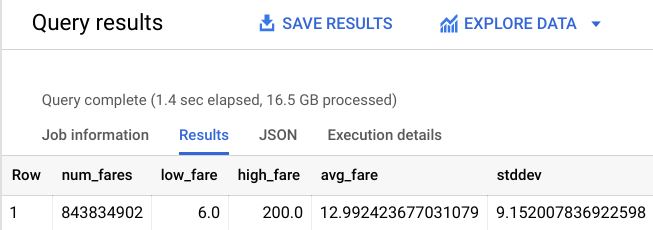
結果は多少絞られました。今回はニューヨーク市にターゲットを絞っているため、ここで移動距離を制限します。
- 以下をコピーしてクエリエディタに貼り付け、[実行] をクリックします。
次のような出力が返されます。
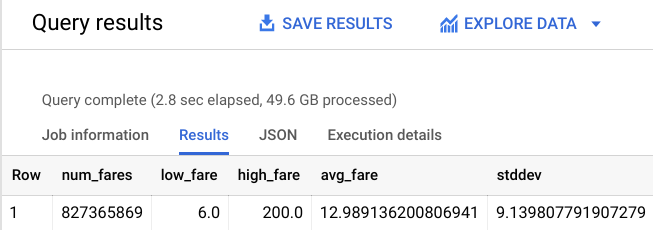
この学習モデルには、まだ 8 億を超える乗車件数を含む大きなサイズのトレーニング データセットがあります。以下の新しい制約を使用してモデルを再トレーニングし、それがどの程度良好に機能するかを見てみます。
モデルの再トレーニング
新しいモデル taxi.taxifare_model_2 を呼び出し、線形回帰モデルの再トレーニングにより合計運賃を予測します。乗車と降車の間のユークリッド距離(直線)のための計算機能もいくつか追加しました。
- 以下をコピーしてクエリエディタに貼り付け、[実行] をクリックします。
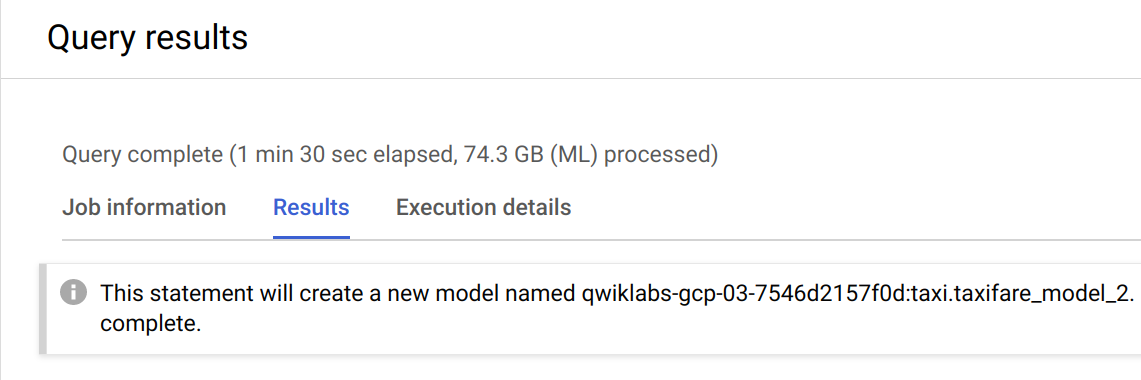
モデルの再トレーニングには数分かかります。コンソールに以下のメッセージが表示されたら、次のステップに進むことができます。
新しいモデルの評価
線形回帰モデルが最適化されたので、それを使ってデータセットを評価し、どの程度機能するかを見てみます。
- 以下をコピーしてクエリエディタに貼り付け、[実行] をクリックします。
次のような出力が返されます。
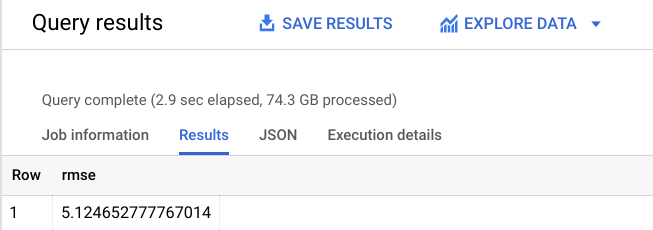
RMSE は、+-$5.12 に減少しました。これは最初のモデルの +-$9.47 よりも大幅に改善しています。
RMSE により予測エラーの標準偏差が定義されるために、再トレーニングされた線形回帰によってモデルの精度が大幅に向上したことがわかります。
タスク 9. 理解度チェック
今回のラボで学習した内容の理解を深めていただくため、以下の多肢選択問題を用意しました。正解を目指して頑張ってください。
タスク 10. 探索できるその他のデータセット
シカゴのタクシー運賃を予測するなど、他のデータセットでモデルの構築を試してみる場合は、bigquery-public-data プロジェクトを利用できます。
-
bigquery-public-data データセットを開くために [+ 追加] > [名前を指定してプロジェクトにスターを付ける] > [プロジェクト名を入力] をクリックし、名前として「
bigquery-public-data」を入力します。 -
[スターを付ける] をクリックします。
bigquery-public-data プロジェクトが [エクスプローラ] セクションに表示されます。
お疲れさまでした
BigQuery で ML モデルを構築し、ニューヨーク市のタクシー運賃を予測できました。
次のステップと詳細情報
- BiqQuery ML について詳しくは、BigQuery ML のドキュメントをご覧ください。
- Vertex AI で BigQuery ML モデルを管理する方法の詳細については、 Model Registry を使用した BigQuery ML モデルの登録に関するドキュメントをご覧ください。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2024 年 2 月 7 日
ラボの最終テスト日: 2023 年 8 月 24 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。

