Prüfpunkte
Create an API Key
/ 40
Make an Entity Analysis Request
/ 30
Check the Entity Analysis response
/ 30
Entitäten- und Sentimentanalyse mit der Natural Language API
- GSP038
- Überblick
- Ziele
- Einrichtung und Anforderungen
- Aufgabe 1: API-Schlüssel erstellen
- Aufgabe 2: Anfrage zur Entitätsanalyse senden
- Aufgabe 3: Die Natural Language API aufrufen
- Aufgabe 4: Sentimentanalyse mit der Natural Language API
- Aufgabe 5: Sentimentanalyse pro Entität
- Aufgabe 6: Syntax und Wortarten analysieren
- Aufgabe 7: Mehrsprachige Verarbeitung natürlicher Sprache
- Das war's! Sie haben das Lab erfolgreich abgeschlossen.
GSP038

Überblick
Mit der Cloud Natural Language API können Sie Entitäten aus Text extrahieren, Text klassifizieren, d. h. Kategorien zuordnen, sowie Stimmungs- und Syntaxanalysen machen.
In diesem Lab erfahren Sie, wie Sie mit der Natural Language API verschiedene Arten von Entitäten, Stimmung und Syntax analysieren können.
Ziele
Aufgaben in diesem Lab:
- Eine Natural Language API-Anfrage erstellen und die API mit „curl“ aufrufen
- Mit der Natural Language API Entitäten extrahieren und eine Sentimentanalyse eines Textes machen
- Einen Text mit der Natural Language API sprachlich analysieren
- Eine Natural Language API-Anfrage in einer anderen Sprache erstellen
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange die Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung selbst durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Pop-up-Fenster geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können. Auf der linken Seite befindet sich der Bereich Details zum Lab mit diesen Informationen:
- Schaltfläche Google Cloud Console öffnen
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite Anmelden geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden. -
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}} Sie finden den Nutzernamen auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}} Sie finden das Passwort auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos. Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen. -
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.

Aufgabe 1: API-Schlüssel erstellen
Da Sie mit curl eine Anfrage an die Natural Language API senden, müssen Sie einen API-Schlüssel generieren, um die Anfrage-URL zu übergeben.
-
Öffnen Sie zum Erstellen eines API-Schlüssels in der Cloud Console das Navigationsmenü und wählen Sie APIs und Dienste > Anmeldedaten aus.
-
Klicken Sie auf Anmeldedaten erstellen und wählen Sie den API-Schlüssel aus.
-
Kopieren Sie den generierten API-Schlüssel und klicken Sie auf Schließen.
Klicken Sie auf Fortschritt prüfen.
Für die nächsten Schritte müssen Sie über SSH eine Verbindung mit der für Sie bereitgestellten Instanz herstellen.
-
Klicken Sie im Navigationsmenü auf „Compute Engine“. Die bereitgestellte Linux-Instanz
linux-instancesollte in der Liste VM-Instanzen aufgeführt sein. -
Klicken Sie auf die Schaltfläche SSH. Sie werden zu einer interaktiven Shell weitergeleitet.
-
Geben Sie in der Befehlszeile Folgendes ein. Achten Sie darauf, für
<YOUR_API_KEY>den gerade kopierten Schlüssel einzusetzen:
Aufgabe 2: Anfrage zur Entitätsanalyse senden
Die erste Natural Language API-Methode, die Sie verwenden, ist analyzeEntities. Damit kann die API Entitäten (wie Personen, Orte und Ereignisse) aus Text extrahieren. Für die Entitätenanalyse der API verwenden wir folgenden Satz:
Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series.
Sie legen die Anfrage für die Natural Language API in der Datei request.json fest.
- Verwenden Sie den Codeeditor nano, um die Datei
request.jsonzu erstellen:
- Geben Sie in
request.jsonden folgenden Code ein oder fügen Sie ihn ein:
- Drücken Sie STRG + X, um nano zu beenden, dann auf Y, um die Datei zu speichern, und abschließend zur Bestätigung die Eingabetaste.
In der Anfrage teilen Sie der Natural Language API Informationen zu dem von Ihnen gesendeten Text mit. Unterstützt werden die Typwerte PLAIN_TEXT und HTML. Unter "content" übergeben Sie den Text, der zur Analyse an die Natural Language API gesendet werden soll.
Die Natural Language API unterstützt auch das Senden von Dateien aus Cloud Storage zur Textverarbeitung. Wenn Sie eine Datei aus Cloud Storage senden möchten, ersetzen Sie content durch gcsContentUri und verwenden Sie den Wert des URI der Textdatei in Cloud Storage.
encodingType: Teilt der API mit, welche Art von Textcodierung bei der Verarbeitung des Textes verwendet werden soll. Die API berechnet damit die Position bestimmter Entitäten im Text.
Klicken Sie auf Fortschritt prüfen.
Aufgabe 3: Die Natural Language API aufrufen
- Mit dem folgenden
curl-Befehl können Sie nun den Anfragetext zusammen mit der zuvor gespeicherten Umgebungsvariablen mit dem API-Schlüssel an die Natural Language API übergeben. Platzieren Sie dabei alle Elemente in der gleichen Befehlszeile:
- Um die Antwort zu überprüfen, führen Sie folgenden Code aus:
Der Anfang der Antwort sollte folgendermaßen aussehen:
Zu jeder Entität in der Antwort erhalten Sie den Entitätstyp (type), die zugehörige Wikipedia-URL (falls vorhanden), die Salienz (salience) und die Indizes darüber, wo diese Entität im Text zu finden ist. Die Salienz ist eine Zahl im Bereich [0,1], die sich auf die Zentralität der Entität im gesamten Dokumenttext bezieht.
Die Natural Language API kann außerdem dieselbe Entität auf unterschiedliche Weisen erkennen. Sehen Sie sich die Liste mentions in der Antwort an: Die API erkennt, dass sich "Joanne Rowling", "Rowling", "novelist" und "Robert Galbriath" auf dieselbe Person beziehen.
Klicken Sie auf Fortschritt prüfen.
Aufgabe 4: Sentimentanalyse mit der Natural Language API
Mit der Natural Language API können Sie nicht nur Entitäten extrahieren, sondern auch eine Sentimentanalyse für einen Textblock machen. Die JSON-Anfrage enthält in diesem Fall dieselben Parameter wie die obige Anfrage, jedoch ändern Sie jetzt den Text, indem Sie Elemente aufnehmen, die auf eine intensivere Stimmung hindeuten.
- Ersetzen Sie den Code in
request.jsonmithilfe von nano durch den folgenden. Untercontentkönnen Sie einen eigenen Text eingeben:
-
Drücken Sie STRG + X, um nano zu beenden, dann auf Y, um die Datei zu speichern, und abschließend zur Bestätigung die Eingabetaste.
-
Als Nächstes senden Sie die Anfrage an den Endpunkt
analyzeSentimentder API:
Die Antwort sollte folgendermaßen aussehen:
Sie sehen, dass die Antwort zwei Arten von "sentiment"-Werten enthält: einen für das gesamte Dokument und einen für jeden einzelnen Satz. Die Sentimentanalyse gibt zwei Werte zurück:
-
score– eine Zahl zwischen -1,0 und 1,0, die angibt, wie positiv oder negativ die Aussage ist. -
magnitude– eine Zahl im Bereich 0 bis unendlich, die das Gewicht der zum Ausdruck gebrachten Stimmung angibt, unabhängig davon, ob die Aussage positiv oder negativ ist.
Längere Textblöcke mit stark gewichteten Aussagen haben höhere "magnitude"-Werte. Der Wert für den ersten Satz ist positiv (0,7), während der Wert für den zweiten Satz neutral ist (0,1).
Aufgabe 5: Sentimentanalyse pro Entität
Die Natural Language API liefert nicht nur Informationen über die Stimmung im gesamten Textdokument, sondern kann die Stimmung auch nach Entitäten im Text aufschlüsseln. Sehen Sie sich diesen Beispielsatz an:
I liked the sushi but the service was terrible.
In diesem Fall liefert eine Sentimentanalyse für den gesamten Satz, so wie sie oben durchgeführt wurde, keine aussagekräftigen Ergebnisse. Wenn dies eine Restaurantbewertung wäre und es Hunderte von Bewertungen für dasselbe Restaurant gäbe, würden Sie wissen wollen, was genau den Kunden gefallen hat und was nicht. Glücklicherweise verfügt die Natural Language API über die Methode analyzeEntitySentiment, mit der Sie die Stimmung für jede Entität im Text ermitteln können. Jetzt können Sie sich ansehen, wie das funktioniert.
- Fügen Sie den folgenden Satz mithilfe von nano in
request.jsonein:
-
Drücken Sie STRG + X, um nano zu beenden, dann auf Y, um die Datei zu speichern, und abschließend zur Bestätigung die Eingabetaste.
-
Rufen Sie dann den Endpunkt
analyzeEntitySentimentmit dem folgenden „curl“-Befehl auf:
Die Antwort enthält zwei Entitätenobjekte: eines für „sushi“ und eines für „service“. Die vollständige JSON-Antwort sieht so aus:
Sie sehen, dass der zurückgegebene Wert für „sushi“ die neutrale Punktzahl 0 beträgt, der für „service“ hingegen -0,7. Nicht schlecht, oder? Sie stellen auch fest, dass für jede Entität zwei "sentiment"-Objekte ausgegeben werden. Wenn einer dieser Begriffe mehr als einmal vorkommen würde, würde die API bei jeder Erwähnung einen anderen Wert für „sentiment“ und „magnitude“ sowie einen aggregierten „sentiment“-Wert für die Entität ausgeben.
Aufgabe 6: Syntax und Wortarten analysieren
Mit der Syntaxanalyse, einer weiteren Methode der Natural Language API, können Sie noch mehr sprachliche Details zu einem Text erhalten. analyzeSyntax extrahiert linguistische Informationen und unterteilt den vorliegenden Text in eine Reihe von Sätzen und Tokens (im Allgemeinen Wortgrenzen) für eine weitere Analyse dieser Tokens. Für jedes Wort im Text ermittelt die API die Wortart (z. B. Substantiv, Verb, Adjektiv) und in welcher Beziehung es zu anderen Wörtern im Satz steht (Ist es das Vollverb? Ein Attribut?).
Probieren Sie es mit einem einfachen Satz aus. Die JSON-Anfrage ähnelt den vorherigen Anfragen, enthält jedoch einen zusätzlichen Funktionsschlüssel. So wird der API vermittelt, dass Sie eine Syntaxannotation machen möchten.
- Ersetzen Sie den Code in
request.jsonmithilfe von nano durch Folgendes:
-
Drücken Sie STRG + X, um nano zu beenden, dann auf Y, um die Datei zu speichern, und abschließend zur Bestätigung die Eingabetaste.
-
Rufen Sie dann die Methode
analyzeSyntaxder API auf:
In der Antwort sollte ein Objekt wie das Folgende für jedes Token im Satz zurückgegeben werden:
Eine Aufschlüsselung der Antwort ergibt Folgendes:
-
partOfSpeechkönnen Sie entnehmen, dass "Joanne" ein Substantiv ist. -
dependencyEdgeenthält Daten, mit denen Sie einen Abhängigkeitsparsebaum des Textes erstellen können. Dabei handelt es sich um ein Diagramm, in dem dargestellt wird, in welcher Beziehung Wörter in einem Satz zueinander stehen. Ein Abhängigkeitsparsebaum für den obigen Satz würde folgendermaßen aussehen:
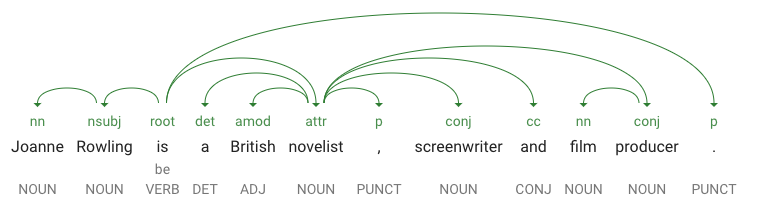
-
headTokenIndexist der Index des Tokens, das auf „Joanne“ verweist. Sie können sich jedes Token im Satz als Wort in einem Array vorstellen. -
headTokenIndexmit dem Wert „1“ für „Joanne“ bezieht sich auf „Rowling“, mit dem es im Baum verbunden ist. Das LabelNN(kurz für „noun compound modifier“) beschreibt die Rolle des Wortes im Satz. „Joanne“ bestimmt „Rowling“, das Subjekt des Satzes, näher. -
lemmaist die kanonische Form des Wortes. Zum Beispiel haben die Wörter laufen, läuft, lief und laufend alle das Lemma laufen. Der "lemma"-Wert ist hilfreich, um zu ermitteln, wie häufig ein Wort in einem langen Textabschnitt vorkommt.
Aufgabe 7: Mehrsprachige Verarbeitung natürlicher Sprache
Die Natural Language API unterstützt auch weitere Sprachen neben Englisch (eine vollständige Liste finden Sie in der Anleitung zur Sprachenunterstützung).
- Ersetzen Sie den Code in
request.jsondurch einen Satz auf Japanisch:
- Drücken Sie STRG + X, um nano zu beenden, dann auf Y, um die Datei zu speichern, und abschließend zur Bestätigung die Eingabetaste.
Sie haben nicht mitgeteilt, in welcher Sprache der Text vorliegt. Die API erkennt das automatisch.
- Als Nächstes senden Sie ihn an den Endpunkt
analyzeEntities:
Die Antwort sieht dann so aus:
Die Wikipedia-URLs verweisen sogar auf die japanischen Wikipedia-Seiten.
Das war's! Sie haben das Lab erfolgreich abgeschlossen.
Sie haben gelernt, wie Sie mit der Cloud Natural Language API eine Textanalyse machen, indem Sie Entitäten extrahieren, die Stimmung analysieren und Syntaxannotationen platzieren. In dieser Übung haben Sie eine Natural Language API-Anfrage erstellt und die API mit curl aufgerufen, Entitäten extrahiert und mit der Natural Language API eine Sentimentanalyse und eine linguistische Analyse von Text vorgenommen sowie eine Natural Language API-Anfrage in einer anderen Sprache gestellt.
Weitere Informationen
- Natural Language API-Anleitungen in der Dokumentation
Google Cloud-Schulungen und -Zertifizierungen
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 14. Februar 2024 aktualisiert
Lab zuletzt am 13. Oktober 2023 getestet
© 2024 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.

