Puntos de control
Create an API Key
/ 40
Make an Entity Analysis Request
/ 30
Check the Entity Analysis response
/ 30
Análisis de opiniones y entidades con la API de Natural Language
- GSP038
- Descripción general
- Objetivos
- Configuración y requisitos
- Tarea 1. Crea una clave de API
- Tarea 2. Realiza una solicitud de análisis de entidades
- Tarea 3. Llama a la API de Natural Language
- Tarea 4. Análisis de opiniones con la API de Natural Language
- Tarea 5. Cómo analizar opiniones sobre entidades
- Tarea 6. Cómo analizar la sintaxis y la categoría gramatical
- Tarea 7. Procesamiento de lenguaje natural multilingüe
- ¡Felicitaciones!
GSP038

Descripción general
La API de Cloud Natural Language te permite extraer entidades de textos, realizar análisis de opiniones y sintácticos, y clasificar texto en categorías.
En este lab, aprenderás a usar la API de Natural Language para analizar entidades, opiniones y sintaxis.
Objetivos
En este lab, aprenderás a hacer lo siguiente:
- Crear una solicitud a la API de Natural Language y llamar a la API con curl
- Extraer entidades y ejecutar un análisis de opiniones en texto con la API de Natural Language
- Realizar un análisis lingüístico de un texto con la API de Natural Language
- Crear una solicitud a la API de Natural Language en otro idioma
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab: Recuerda que, una vez que comienzas un lab, no puedes pausarlo.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haga clic en el botón Comenzar lab. Si debe pagar por el lab, se abrirá una ventana emergente para que seleccione su forma de pago. A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón Abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debe usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordene las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta. -
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}} También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}} También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud. Nota: Usar tu propia Cuenta de Google podría generar cargos adicionales. -
Haga clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.

Tarea 1. Crea una clave de API
Como usarás curl para enviar una solicitud a la API de Natural Language, deberás generar una clave de API para pasar tu URL de solicitud.
-
Para crear una clave de API, en la consola de Cloud, selecciona el menú de navegación > APIs y servicios > Credenciales.
-
Haz clic en Crear credenciales y selecciona Clave de API.
-
Copia la clave de API que se generó y haz clic en Cerrar.
Haz clic en Revisar mi progreso para verificar el objetivo.
Para realizar los próximos pasos, conéctate a través de SSH a la instancia que se te aprovisionó.
-
Haz clic en menú de navegación > Compute Engine. Deberías ver la instancia de Linux que se aprovisionó,
linux-instance, en la lista Instancias de VM. -
Haz clic en el botón SSH. Se te redireccionará a una shell interactiva.
-
En la línea de comandos, reemplaza
<YOUR_API_KEY>por la clave que acabas de copiar:
Tarea 2. Realiza una solicitud de análisis de entidades
El primer método de la API de Natural Language que usarás es analyzeEntities. Con este método, la API puede extraer entidades (como personas, lugares y eventos) del texto. Para probar el análisis de entidades de la API, utiliza la siguiente oración:
Joanne Rowling, quien escribe bajo el seudónimo J. K. Rowling y Robert Galbraith, es una novelista y guionista británica que escribió la saga de fantasía Harry Potter.
Compila tu solicitud a la API de Natural Language en el archivo request.json.
- Crea el archivo
request.jsoncon nano (un editor de código):
- Escribe o pega el siguiente código en
request.json:
- Presiona CTRL + X para salir de nano, Y para guardar el archivo y, luego, INTRO para confirmar.
En la solicitud, se le informa a la API de Natural Language acerca del texto que se está enviando. Los valores de "type" admitidos son PLAIN_TEXT o HTML. En "content", se pasa el texto que enviaremos a la API de Natural Language para el análisis.
Esta API también admite el envío de archivos almacenados en Cloud Storage para el procesamiento de texto. Si quisieras enviar un archivo de Cloud Storage, tendrías que reemplazar content por gcsContentUri y asignarle el valor del URI del archivo de texto en Cloud Storage.
encodingType informa a la API qué tipo de codificación se debe utilizar cuando procesa el texto. La API utilizará esa información para calcular en qué parte de nuestro texto aparecerán entidades específicas.
Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 3. Llama a la API de Natural Language
- Ahora puedes pasar el cuerpo de tu solicitud, junto con la variable de entorno de la clave de API que guardaste anteriormente, a la API de Natural Language con el siguiente comando
curl(todo en una sola línea de comandos):
- Para verificar la respuesta, ejecuta el siguiente comando:
Tu respuesta debería comenzar de la siguiente manera:
Para cada entidad de la respuesta, obtienes la entidad type, la dirección URL de Wikipedia asociada (si existe), el valor de salience y los índices que indican dónde aparece esta entidad en el texto. El valor de salience es un número del rango [0,1] que indica la centralidad de la entidad en el texto completo.
La API de Natural Language también puede reconocer la misma entidad mencionada de diferentes maneras. Observa la lista mentions en la respuesta: la API puede indicar que "Joanne Rowling", "Rowling", "novelista" y "Robert Galbriath" corresponden a lo mismo.
Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 4. Análisis de opiniones con la API de Natural Language
Además de extraer entidades, la API de Natural Language te permite realizar el análisis de opiniones de un bloque de texto. Esta solicitud JSON incluirá los mismos parámetros que la solicitud anterior, pero esta vez se cambiará el texto para incluir opiniones más sólidas.
- Utiliza nano para reemplazar el código de
request.jsonpor lo siguiente y, si lo deseas, cambia la información decontentque aparece a continuación por tu propio texto:
-
Presiona CTRL + X para salir de nano, Y para guardar el archivo y, luego, INTRO para confirmar.
-
Luego, envía la solicitud al extremo
analyzeSentimentde la API:
La respuesta debería verse de la siguiente manera:
Ten en cuenta que obtienes dos tipos de valores de opiniones: opiniones para el documento completo y opiniones por cada oración. El método de opiniones devuelve dos valores:
-
score: es un número entre -1.0 y 1.0 que indica qué tan positivo o negativo es el enunciado. -
magnitude: es un número de 0 a infinito que representa el peso de las opiniones expresadas en el enunciado, independientemente de que sea positivo o negativo.
Los bloques de textos más largos con enunciados de mucho peso tienen valores de mayor magnitud. La puntuación de la primera oración es positiva (0.7), mientras que la puntuación de la segunda es neutral (0.1).
Tarea 5. Cómo analizar opiniones sobre entidades
Además de proporcionar detalles de opiniones sobre el documento de texto completo, la API de Natural Language puede desglosar opiniones por entidades en el texto. Utiliza esta oración como ejemplo:
Me gustó el sushi, pero el servicio fue terrible.
En este caso, obtener una puntuación de opiniones para toda la oración, como lo hizo anteriormente, podría no ser tan útil. Si se tratara de una opinión de un restaurante y hubiera cientos de opiniones para el mismo restaurante, querrías saber exactamente qué aspectos les gustaron o no a las personas en sus opiniones. Afortunadamente, la API de Natural Language tiene un método que te permite obtener las opiniones de cada entidad en el texto, que se denomina analyzeEntitySentiment. Veamos cómo funciona.
- Utiliza nano para actualizar
request.jsoncon la oración de abajo:
-
Presiona CTRL + X para salir de nano, Y para guardar el archivo y, luego, INTRO para confirmar.
-
Luego, llama al extremo
analyzeEntitySentimentcon el siguiente comando curl:
En la respuesta, obtendrás dos objetos de entidad: uno para “sushi” y otro para “servicio”. Esta es la respuesta completa de JSON:
Puedes ver que la puntuación devuelta para “sushi” fue una neutral de 0, mientras que la de “servicio” fue de -0.7. Genial. También puedes observar que se muestran dos objetos de opiniones para cada entidad. Si cualquiera de estos términos se mencionara más de una vez, la API mostraría una puntuación y una magnitud de opiniones diferentes para cada mención, junto con una opinión agregada para la entidad.
Tarea 6. Cómo analizar la sintaxis y la categoría gramatical
Utiliza el análisis sintáctico, otro método de la API de Natural Language, para investigar más a fondo los detalles lingüísticos del texto. analyzeSyntax extrae información lingüística y divide un texto específico en una serie de oraciones y tokens (en general, límites de palabras) para proporcionar un análisis más detallado de esos tokens. Para cada palabra en el texto, la API te indicará la categoría gramatical (sustantivo, verbo, adjetivo, etc.) y cómo se relaciona con otras palabras en la oración (¿Es el verbo raíz?, ¿es un modificador?).
Inténtalo con una oración simple. Esta solicitud JSON será similar a las anteriores, pero se agrega una clave de atributos. Esto indicará a la API que realice una anotación sintáctica.
- Utiliza nano para reemplazar el código de
request.jsonpor la siguiente información:
-
Presiona CTRL + X para salir de nano, Y para guardar el archivo y, luego, INTRO para confirmar.
-
Luego, llama al método
analyzeSyntaxde la API:
La respuesta debería mostrar un objeto como el siguiente para cada token de la oración:
Desglosemos la respuesta:
-
partOfSpeechindica que "Joanne" es un sustantivo. -
dependencyEdgeincluye datos que puedes usar para crear un árbol de análisis de dependencia del texto. Fundamentalmente, este es un diagrama que muestra cómo se relacionan las palabras en una oración. Un árbol de análisis de dependencia de la oración anterior debería ser de la siguiente manera:
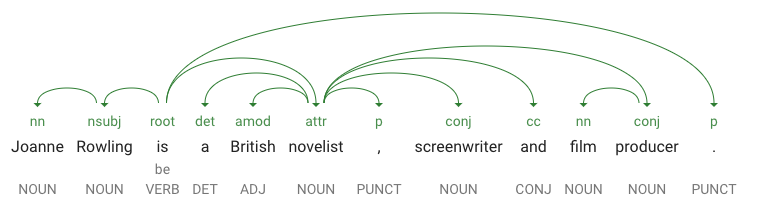
-
headTokenIndexes el índice del token que contiene un arco que señala a “Joanne”. Piensa en cada token de la oración como una palabra en un array. -
headTokenIndexde 1 para "Joanne" se refiere a la palabra "Rowling", a la que está conectada en el árbol. La etiquetaNN(abreviatura de modificador compuesto del sustantivo) describe la función de la palabra en la oración. “Joanne” modifica a “Rowling”, el sujeto de la oración. -
lemmaes la forma canónica de la palabra. Por ejemplo, las palabras ejecutamos, ejecuta, ejecutó y ejecutando pertenecen al lemma ejecutar. El valor de lemma es útil para hacer el seguimiento de los casos en que una palabra está presente en un fragmento de texto grande a lo largo del tiempo.
Tarea 7. Procesamiento de lenguaje natural multilingüe
La API de Natural Language admite otros idiomas distintos del inglés (la lista completa puedes encontrarla en la Guía de idiomas compatibles).
- Modifica el código en
request.jsoncon una oración en japonés:
- Presiona CTRL + X para salir de nano, Y para guardar el archivo y, luego, INTRO para confirmar.
Ten en cuenta que no le indicaste a la API en qué idioma está el texto, pero no te preocupes: ya está programada para detectarlo automáticamente.
- Luego, envíalo al extremo
analyzeEntities:
Obtendrás la siguiente respuesta:
Las URLs de Wikipedia también dirigen a las páginas de Wikipedia en japonés. ¡Es genial!
¡Felicitaciones!
Aprendiste cómo realizar un análisis de texto con la API de Cloud Natural Language mediante la extracción de entidades, el análisis de opiniones y la creación de anotaciones sintácticas. En este lab, creaste una solicitud a la API de Natural Language y la llamaste con curl, además de trabajar con ella para extraer entidades y realizar un análisis de opiniones en texto y un análisis lingüístico en texto. También creaste una solicitud a la API en otro idioma.
Próximos pasos
- Consulta los instructivos de la API de Natural Language en la documentación.
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 14 de febrero de 2024
Prueba más reciente del lab: 13 de octubre de 2023
Copyright 2024 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.

