

Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Create an API Key
/ 40
Make an Entity Analysis Request
/ 30
Check the Entity Analysis response
/ 30
L'API Cloud Natural Language vous permet d'extraire des entités à partir de texte, d'effectuer des analyses des sentiments et de la syntaxe, ainsi que de classer du texte selon des catégories.
Dans cet atelier, vous allez découvrir comment utiliser l'API Natural Language pour analyser les entités, les sentiments et la syntaxe d'un texte.
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
Vous trouverez également le nom d'utilisateur dans le panneau Détails concernant l'atelier.
Cliquez sur Suivant.
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
Vous trouverez également le mot de passe dans le panneau Détails concernant l'atelier.
Cliquez sur Suivant.
Accédez aux pages suivantes :
Après quelques instants, la console Cloud s'ouvre dans cet onglet.

Étant donné que vous utilisez curl pour envoyer une requête à l'API Natural Language, vous devez générer une clé API afin de transmettre l'URL de la requête.
Pour créer une clé API, dans la console Cloud, accédez au menu de navigation > API et services > Identifiants.
Cliquez sur Créer des identifiants et sélectionnez Clé API.
Copiez la clé API et cliquez sur Fermer.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Pour poursuivre, connectez-vous à l'instance configurée pour vous via SSH.
Accédez au menu de navigation > Compute Engine. L'instance Linux provisionnée, linux-instance, doit s'afficher dans la liste Instances de VM.
Cliquez sur le bouton SSH. Vous êtes redirigé vers un shell interactif.
Dans la ligne de commande, saisissez la commande suivante, en remplaçant <YOUR_API_KEY> par la clé que vous venez de copier :
analyzeEntities sera la première méthode de l'API Natural Language que vous utiliserez. Grâce à cette méthode, l'API peut extraire des entités (telles que des personnes, des lieux et des événements) d'un texte. Pour tester l'analyse des entités de l'API, utilisez la phrase suivante :
Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series.
Construisez votre requête pour l'API Natural Language dans un fichier request.json.
request.json :request.json :Dans la requête, vous donnez à l'API Natural Language des informations sur le texte que vous envoyez. Les valeurs de type acceptées sont PLAIN_TEXT ou HTML. Vous indiquez dans "content" la chaîne de texte à envoyer à l'API Natural Language pour analyse.
L'API Natural Language permet également l'envoi de fichiers stockés dans Cloud Storage pour le traitement de texte. Pour envoyer un fichier à partir de Cloud Storage, remplacez content par gcsContentUri et transmettez la valeur de l'URI du fichier texte dans Cloud Storage.
encodingType indique à l'API le type d'encodage de texte à utiliser lors du traitement du texte. L'API l'utilisera pour calculer l'emplacement d'entités spécifiques dans le texte.
Cliquez sur Vérifier ma progression pour valider l'objectif.
curl suivante (dans une seule ligne de commande) :Le début de la réponse doit se présenter comme suit :
Pour chaque entité de la réponse, vous obtenez le type, l'URL Wikipédia associée (le cas échéant), l'élément salience (saillance) et l'index des endroits où elle apparaît dans le texte. La saillance correspond à un chiffre compris dans la plage [0,1] qui se rapporte à la centralité de l'entité par rapport au texte dans son ensemble.
L'API Natural Language est également en mesure de reconnaître une même entité évoquée sous différentes formes. Observez la liste mentions de la réponse : l'API est capable de dire que "Joanne Rowling", "Rowling", "novelist" et "Robert Galbriath" font tous référence à une même entité.
Cliquez sur Vérifier ma progression pour valider l'objectif.
Outre l'extraction d'entités, l'API Natural Language permet d'effectuer une analyse des sentiments dans une chaîne de texte. La requête JSON suivante comportera les mêmes paramètres que la requête ci-dessus, mais cette fois, vous modifierez le texte pour y inclure des éléments liés à des sentiments "plus forts".
request.json par ce qui suit. Vous pouvez aussi remplacer le contenu de content ci-dessous par votre propre texte :Appuyez sur Ctrl+X pour quitter nano, sur Y pour enregistrer le fichier, puis sur Entrée pour confirmer.
Vous allez ensuite envoyer la requête au point de terminaison analyzeSentiment de l'API :
La réponse doit se présenter comme suit :
Comme vous pouvez le remarquer, vous obtenez deux types de valeurs de sentiment : les sentiments pour le document dans son ensemble, et les sentiments exprimés dans chaque phrase. La méthode d'analyse des sentiments renvoie deux valeurs :
score : il s'agit d'un nombre compris entre -1,0 et 1,0 qui indique le degré de positivité ou de négativité de la phrase.magnitude : il s'agit d'un nombre compris entre 0 et l'infini représentant l'intensité des sentiments exprimés dans la déclaration, sans tenir compte de son aspect positif ou négatif.Les longues chaînes de texte exprimant des sentiments intenses ont des valeurs de magnitude plus élevées. Le score de la première phrase est positif (0,7), tandis que celui de la deuxième est neutre (0,1).
En plus de fournir des informations sur les sentiments exprimés dans l'ensemble du document texte, l'API Natural Language est également capable d'isoler les sentiments par entité dans la chaîne de texte. Utilisez cette phrase comme exemple :
I liked the sushi but the service was terrible.
Ici, il ne sera peut-être pas utile de calculer le score de l'analyse des sentiments de l'ensemble de la phrase, comme nous l'avons fait plus haut. Imaginez qu'il s'agisse d'une critique de restaurant parmi des centaines d'autres : vous allez plutôt chercher à extraire des informations précises concernant les points positifs et négatifs soulevés par les clients. Il se trouve que l'API Natural Language dispose d'une méthode appelée analyzeEntitySentiment, qui permet d'obtenir un sentiment pour chaque entité de la chaîne de texte. Voyons comment elle fonctionne.
request.json :Appuyez sur Ctrl+X pour quitter nano, sur Y pour enregistrer le fichier, puis sur Entrée pour confirmer.
Envoyez ensuite une requête au point de terminaison analyzeEntitySentiment avec la commande curl suivante :
Vous recevez une réponse comportant deux objets d'entités, un pour "sushi" et l'autre pour "service". Voici la réponse JSON complète :
Vous pouvez voir que le score attribué à "sushi" est un score neutre de 0, tandis que celui attribué à "service" est de -0,7. C'est parfait ! Vous remarquerez également que deux objets de sentiment ont été attribués à chaque entité. Si l'un de ces deux termes avait été mentionné à plus d'une reprise, l'API aurait renvoyé un score de sentiment et de magnitude distinct pour chaque occurrence, ainsi qu'un sentiment global pour l'entité.
Utilisez l'analyse syntaxique, une autre méthode de l'API Natural Language, pour obtenir des informations linguistiques plus détaillées sur le texte. La méthode analyzeSyntax extrait les informations linguistiques en divisant le texte donné en une série de phrases et de jetons (qui correspondent généralement aux mots), afin de fournir une analyse approfondie de ces jetons. L'API nous indique la classe de chaque mot du texte (nom, verbe, adjectif, etc.) et sa fonction dans la phrase (s'agit du verbe principal, d'un modificateur ?).
Essayez avec une phrase simple. Cette requête JSON sera similaire aux requêtes déjà envoyées, avec une caractéristique clé supplémentaire. Elle indiquera à l'API que vous souhaitez effectuer une annotation syntaxique.
request.json par ce qui suit :Appuyez sur Ctrl+X pour quitter nano, sur Y pour enregistrer le fichier, puis sur Entrée pour confirmer.
Appelez ensuite la méthode analyzeSyntax de l'API :
La réponse devrait renvoyer un objet semblable à l'exemple ci-dessous pour chaque jeton dans la phrase :
Analysons cette réponse plus en détail :
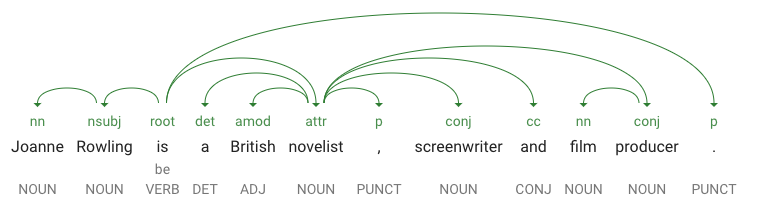
partOfSpeech indique que "Joanne" est un nom.dependencyEdge comporte des données que vous pourrez utiliser pour créer l'arbre syntaxique de dépendance du texte. Il s'agit pour l'essentiel d'un diagramme montrant les relations entre les termes dans le texte. L'arbre syntaxique de dépendance de la phrase ci-dessus ressemblerait à ceci :headTokenIndex correspond à l'index de l'élément dont l'arc pointe vers "Joanne". Considérez chaque élément de la phrase comme un mot dans un tableau.headTokenIndex de valeur 1 pour "Joanne" se rapporte au terme "Rowling", auquel il est relié au sein de l'arbre syntaxique. L'étiquette NN (abréviation de "noun compound modifier", ou modificateur de mot composé) décrit le rôle du terme dans la phrase. "Joanne" modifie "Rowling," le sujet de la phrase.lemma correspond à la forme canonique d'un mot. Par exemple, les mots vouloir, voulu, voulait et veux ont tous un lemme identique : vouloir. La valeur du lemme est utile pour comptabiliser au fur et à mesure les occurrences d'un mot dans une longue chaîne de texte.L'API Natural Language accepte également d'autres langues que l'anglais (la liste complète est disponible dans le guide d'assistance de Natural Language).
request.json :Vous remarquerez que vous n'avez pas à préciser à l'API la langue que vous utilisez, car elle la détecte automatiquement.
analyzeEntities :Et vous obtenez la réponse suivante :
Les URL vous redirigent vers les pages Wikipédia en japonais. Tout simplement.
Vous avez appris à effectuer une analyse de texte avec l'API Cloud Natural Language en extrayant des entités, en analysant des sentiments et en réalisant des annotations syntaxiques. Dans cet atelier, vous avez créé une requête pour l'API Natural Language et appelé l'API avec curl, extrait des entités et exécuté une analyse des sentiments sur du texte avec l'API Natural Language, effectué l'analyse linguistique d'un texte et créé une requête pour l'API Natural Language dans une autre langue.
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 14 février 2024
Dernier test de l'atelier : 13 octobre 2023
Copyright 2025 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.



Ce contenu n'est pas disponible pour le moment
Nous vous préviendrons par e-mail lorsqu'il sera disponible

Parfait !
Nous vous contacterons par e-mail s'il devient disponible

One lab at a time
Confirm to end all existing labs and start this one