Checkpoint
Create an API Key
/ 40
Make an Entity Analysis Request
/ 30
Check the Entity Analysis response
/ 30
Analisi di sentiment ed entità con l'API Natural Language
- GSP038
- Panoramica
- Obiettivi
- Configurazione e requisiti
- Attività 1: crea una chiave API
- Attività 2: invia una richiesta di analisi delle entità
- Attività 3: chiama l'API Natural Language
- Attività 4: analisi del sentiment con l'API Natural Language
- Attività 5: analisi del sentiment relativo all'entità
- Attività 6: analisi della sintassi e delle parti del discorso
- Attività 7: elaborazione del linguaggio naturale multilingue
- Complimenti!
GSP038

Panoramica
L'API Cloud Natural Language consente di estrarre entità da un testo, analizzarne sentiment e sintassi e classificarlo in categorie.
In questo lab imparerai a utilizzare l'API Natural Language per analizzare entità, sentiment e sintassi.
Obiettivi
In questo lab, imparerai a:
- Creare una richiesta API Natural Language e chiamare l'API con curl
- Estrarre entità ed eseguire analisi del sentiment sul testo con l'API Natural Language
- Eseguire analisi linguistiche sul testo con l'API Natural Language
- Creare una richiesta API Natural Language in una lingua diversa
Configurazione e requisiti
Prima di fare clic sul pulsante Avvia lab
Leggi le seguenti istruzioni. I lab sono a tempo e non possono essere messi in pausa. Il timer si avvia quando fai clic su Avvia lab e ti mostra per quanto tempo avrai a disposizione le risorse Google Cloud.
Con questo lab pratico avrai la possibilità di completare le attività in prima persona, in un ambiente cloud reale e non di simulazione o demo. Riceverai delle nuove credenziali temporanee che potrai utilizzare per accedere a Google Cloud per la durata del lab.
Per completare il lab, avrai bisogno di:
- Accesso a un browser internet standard (Chrome è il browser consigliato).
- È ora di completare il lab: ricorda che, una volta iniziato, non puoi metterlo in pausa.
Come avviare il lab e accedere alla console Google Cloud
-
Fai clic sul pulsante Avvia lab. Se devi effettuare il pagamento per il lab, si apre una finestra popup per permetterti di selezionare il metodo di pagamento. A sinistra, trovi il riquadro Dettagli lab con le seguenti informazioni:
- Il pulsante Apri console Google Cloud
- Tempo rimanente
- Credenziali temporanee da utilizzare per il lab
- Altre informazioni per seguire questo lab, se necessario
-
Fai clic su Apri console Google Cloud (o fai clic con il tasto destro del mouse e seleziona Apri link in finestra di navigazione in incognito se utilizzi il browser Chrome).
Il lab avvia le risorse e apre un'altra scheda con la pagina di accesso.
Suggerimento: disponi le schede in finestre separate posizionate fianco a fianco.
Nota: se visualizzi la finestra di dialogo Scegli un account, fai clic su Usa un altro account. -
Se necessario, copia il Nome utente di seguito e incollalo nella finestra di dialogo di accesso.
{{{user_0.username | "Username"}}} Puoi trovare il Nome utente anche nel riquadro Dettagli lab.
-
Fai clic su Avanti.
-
Copia la Password di seguito e incollala nella finestra di dialogo di benvenuto.
{{{user_0.password | "Password"}}} Puoi trovare la Password anche nel riquadro Dettagli lab.
-
Fai clic su Avanti.
Importante: devi utilizzare le credenziali fornite dal lab. Non utilizzare le credenziali del tuo account Google Cloud. Nota: utilizzare il tuo account Google Cloud per questo lab potrebbe comportare addebiti aggiuntivi. -
Fai clic nelle pagine successive:
- Accetta i termini e le condizioni.
- Non inserire opzioni di recupero o l'autenticazione a due fattori, perché si tratta di un account temporaneo.
- Non registrarti per le prove gratuite.
Dopo qualche istante, la console Google Cloud si apre in questa scheda.

Attività 1: crea una chiave API
Poiché utilizzerai curl per inviare una richiesta all'API Natural Language, devi generare una chiave API da passare nell'URL della richiesta.
-
Per creare una chiave API, nella console Cloud, seleziona Menu di navigazione > API e servizi > Credenziali.
-
Fai clic su Crea credenziali e seleziona Chiave API.
-
Copia la chiave API generata e fai clic su Chiudi.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Per eseguire le operazioni successive, collegati all'istanza di cui è stato eseguito il provisioning per te tramite SSH.
-
Fai clic su Menu di navigazione > Compute Engine. Dovrebbe comparire l'istanza di Linux di cui è stato eseguito il provisioning,
linux-instance, nell'elenco Istanze VM. -
Fai clic sul pulsante SSH. Verrai indirizzato a una shell interattiva.
-
Nella riga di comando, inserisci il comando seguente sostituendo
<YOUR_API_KEY>con la chiave che hai appena copiato:
Attività 2: invia una richiesta di analisi delle entità
Il primo metodo dell'API Natural Language che utilizzi è analyzeEntities. Con questo metodo, l'API può estrarre entità (come persone, luoghi ed eventi) dal testo. Per provare l'analisi delle entità dell'API, utilizza la frase seguente:
Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series.
Crea la tua richiesta all'API Natural Language nel file request.json.
- Utilizza Nano (un editor di codice) per creare il file
request.json:
- Digita o incolla il seguente codice in
request.json:
- Premi CTRL+X per uscire da Nano, quindi Y per salvare il file e INVIO per confermare.
Nella richiesta, stai indicando all'API Natural Language il testo inviato. I valori di tipo supportati sono PLAIN_TEXT o HTML. In content, passi il testo da inviare all'API Natural Language per l'analisi.
L'API Natural Language supporta anche l'invio di file archiviati in Cloud Storage per l'elaborazione del testo. Se vuoi inviare un file da Cloud Storage, devi sostituire content con gcsContentUri e assegnargli un valore pari all'URI del file di testo in Cloud Storage.
encodingType indica all'API il tipo di codifica del testo da utilizzare durante l'elaborazione del nostro testo. L'API lo utilizzerà per calcolare dove determinate entità compaiono nel nostro testo.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Attività 3: chiama l'API Natural Language
- Ora puoi passare all'API Natural Language il corpo della richiesta, insieme alla variabile di ambiente della chiave API salvata in precedenza, con il seguente comando
curl(tutto in un'unica riga di comando):
- Per verificare la risposta esegui:
L'inizio della risposta dovrebbe essere simile al seguente:
Per ogni entità nella risposta, ottieni i seguenti elementi: type dell'entità, URL di Wikipedia associato, se presente, salience e indici della posizione in cui l'entità compare nel testo. Il valore di salience è un numero compreso tra 0 e 1 e si riferisce alla centralità dell'entità rispetto al testo nel suo insieme.
L'API Natural Language può anche riconoscere stessa entità menzionata in modi diversi. Dai un'occhiata all'elenco mentions nella risposta: l'API è in grado di dire che "Joanne Rowling", "Rowling", "novelist" e "Robert Galbriath" puntano tutti alla stessa cosa.
Fai clic su Controlla i miei progressi per verificare l'obiettivo.
Attività 4: analisi del sentiment con l'API Natural Language
Oltre a estrarre entità, l'API Natural Language consente anche di eseguire l'analisi del sentiment su un blocco di testo. Questa richiesta JSON includerà gli stessi parametri della richiesta precedente, ma questa volta cambierà il testo per includere un elemento con un sentiment più forte.
- Utilizza Nano per sostituire il codice in
request.jsoncon quanto segue e, se vuoi, sostituiscicontentcon il tuo testo:
-
Premi CTRL+X per uscire da Nano, quindi Y per salvare il file e INVIO per confermare.
-
Dopodiché, invia la richiesta all'endpoint
analyzeSentimentdell'API:
La tua risposta dovrebbe essere simile alla seguente:
Tieni presente che ottieni due tipi di valori di sentiment: un sentiment per il documento nel suo insieme e un sentiment scomposto per frase. Il metodo sentiment restituisce due valori:
-
score- (punteggio) è un numero compreso tra -1,0 e 1,0 che indica quanto sia positiva o negativa l'affermazione. -
magnitude- è un numero compreso tra 0 e infinito che rappresenta il peso del sentiment espresso nell'affermazione, indipendentemente dal fatto che sia positiva o negativa.
Blocchi di testo più lunghi con affermazioni molto pesanti hanno valori di magnitude più elevati. Lo score per la prima frase è positivo (0,7), mentre quello per la seconda è neutro (0,1).
Attività 5: analisi del sentiment relativo all'entità
Oltre a fornire dettagli sul sentiment dell'intero documento di testo, l'API Natural Language può anche scomporre il sentiment in base alle entità nel testo. Usa questa frase come esempio:
I liked the sushi but the service was terrible.
In questo caso, ottenere un punteggio relativo al sentiment per l'intera frase come hai fatto in precedenza potrebbe non essere così utile. Se si trattasse della recensione di un ristorante per cui esistono centinaia di recensioni, vorresti sapere esattamente quali cose sono piaciute e quali non sono piaciute alle persone che lo hanno recensito. Fortunatamente, l'API Natural Language dispone di un metodo che consente di ottenere il sentiment per ciascuna entità nel testo, chiamato analyzeEntitySentiment. Vediamo come funziona.
- Utilizza Nano per aggiornare
request.jsoncon la frase seguente:
-
Premi CTRL+X per uscire da Nano, quindi Y per salvare il file e INVIO per confermare.
-
Quindi chiama l'endpoint
analyzeEntitySentimentcon il seguente comando curl:
Nella risposta ottieni due oggetti entità: uno per "sushi" e uno per "service" (servizio). Ecco la risposta JSON completa:
Puoi notare che il punteggio restituito per "sushi" è un punteggio neutro pari a 0, mentre "service" ha ottenuto un punteggio di -0,7. Interessante! Potresti anche notare che vengono restituiti due oggetti sentiment per ciascuna entità. Se uno di questi termini venisse menzionato più di una volta, l'API restituirebbe valori score e magnitude per il sentiment diversi per ogni menzione, insieme a un sentiment aggregato per l'entità.
Attività 6: analisi della sintassi e delle parti del discorso
Utilizza l'analisi sintattica, un altro dei metodi dell'API Natural Language, per approfondire i dettagli linguistici del testo. analyzeSyntax estrae informazioni linguistiche, scomponendo il testo specificato in una serie di frasi e token (in genere, limiti di parole), per fornire ulteriori analisi su quei token. L'API indica la parte del discorso (sostantivo, verbo, aggettivo ecc.) di ogni parola nel testo e come quest'ultima si collega alle altre parole nella frase (ad esempio, se è la radice del verbo o un modificatore).
Prova con una frase semplice. Questa richiesta JSON sarà simile a quelle precedenti, con l'aggiunta di una chiave di funzionalità, che indica all'API di eseguire l'annotazione della sintassi.
- Utilizza Nano per sostituire il codice in
request.jsoncon quanto segue:
-
Premi CTRL+X per uscire da Nano, quindi Y per salvare il file e INVIO per confermare.
-
Quindi chiama il metodo
analyzeSyntaxdell'API:
La risposta dovrebbe restituire un oggetto come quello seguente per ogni token nella frase:
Analizziamo la risposta:
-
partOfSpeechindica che "Joanne" è un sostantivo. -
dependencyEdgeinclude dati che puoi utilizzare per creare un albero di analisi delle dipendenze del testo. Essenzialmente, si tratta di un diagramma che mostra come le parole in una frase si relazionano tra loro. Un albero di analisi delle dipendenze per la frase precedente sarebbe simile a questo:
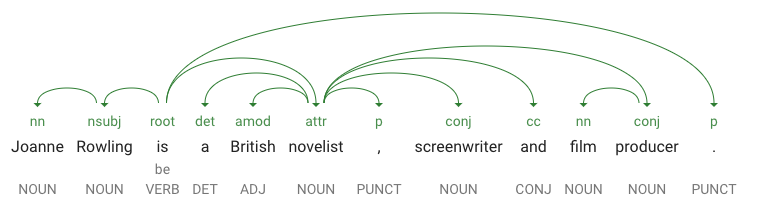
-
headTokenIndexè l'indice del token che ha un arco che punta a "Joanne". Pensa a ciascun token nella frase come a una parola in un array. -
headTokenIndexdi 1 per "Joanne" si riferisce alla parola "Rowling", a cui è collegato nell'albero. L'etichettaNN(abbreviazione di modificatore del sostantivo composto) descrive il ruolo della parola nella frase. "Joanne" modifica "Rowling", il soggetto della frase. -
lemmaè la forma canonica della parola. Ad esempio, le parole run, runs, ran e running hanno tutte il lemma run. Il valore lemma è utile per tenere traccia delle occorrenze di una parola in una porzione di testo di grandi dimensioni nel tempo.
Attività 7: elaborazione del linguaggio naturale multilingue
L'API Natural Language supporta anche altre lingue diverse dall'inglese (l'elenco completo è disponibile nella guida Supporto delle lingue).
- Modifica il codice in
request.jsoncon una frase in giapponese:
- Premi CTRL+X per uscire da Nano, quindi Y per salvare il file e INVIO per confermare.
Nota che, anche se non hai incluso questa informazione, l'API è in grado di rilevare automaticamente la lingua!
- Quindi, invialo all'endpoint
analyzeEntities:
Ottieni la seguente risposta:
Anche gli URL di Wikipedia puntano alle pagine in giapponese: fantastico!
Complimenti!
Hai imparato come eseguire l'analisi del testo con l'API Cloud Natural Language estraendo entità, analizzando il sentiment ed eseguendo l'annotazione della sintassi. In questo lab hai creato una richiesta API Natural Language e hai chiamato l'API con curl, hai estratto entità ed eseguito l'analisi del sentiment sul testo con l'API Natural Language, hai eseguito analisi linguistiche sul testo e hai creato una richiesta API Natural Language in una lingua diversa.
Passaggi successivi
- Guarda i tutorial relativi all'API Natural Language nella documentazione.
Formazione e certificazione Google Cloud
… per utilizzare al meglio le tecnologie Google Cloud. I nostri corsi ti consentono di sviluppare competenze tecniche e best practice per aiutarti a metterti subito al passo e avanzare nel tuo percorso di apprendimento. Offriamo vari livelli di formazione, dal livello base a quello avanzato, con opzioni di corsi on demand, dal vivo e virtuali, in modo da poter scegliere il più adatto in base ai tuoi impegni. Le certificazioni ti permettono di confermare e dimostrare le tue abilità e competenze relative alle tecnologie Google Cloud.
Ultimo aggiornamento del manuale: 14 febbraio 2024
Ultimo test del lab: 13 ottobre 2023
Copyright 2024 Google LLC Tutti i diritti riservati. Google e il logo Google sono marchi di Google LLC. Tutti gli altri nomi di società e prodotti sono marchi delle rispettive società a cui sono associati.

