Checkpoints
Create an API Key
/ 40
Make an Entity Analysis Request
/ 30
Check the Entity Analysis response
/ 30
Análise de entidades e sentimento com a API Natural Language
- GSP038
- Visão geral
- Objetivos
- Configuração e requisitos
- Tarefa 1: crie uma chave de API
- Tarefa 2: envie uma solicitação de análise de entidades
- Tarefa 3: chame a API Natural Language
- Tarefa 4: análise de sentimento com a API Natural Language
- Tarefa 5: como analisar o sentimento de uma entidade
- Tarefa 6: como analisar a sintaxe e as classes gramaticais
- Tarefa 7: processamento de linguagem natural multilíngue
- Parabéns!
GSP038

Visão geral
Com a API Cloud Natural Language, é possível extrair entidades do texto, fazer análises sintáticas e de sentimento e classificar o texto em categorias.
Neste laboratório, você vai aprender a usar a API Natural Language para analisar entidades, sentimento e sintaxe.
Objetivos
Neste laboratório, você vai aprender a:
- Criar uma solicitação da API Natural Language e chamar a API com curl
- Extrair entidades e fazer uma análise de sentimento no texto com a API Natural Language
- Realizar uma análise linguística no texto com a API Natural Language
- Criar uma solicitação da API Natural Language em outro idioma
Configuração e requisitos
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você vai encontrar o seguinte:
- O botão Abrir console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta. -
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Nome de usuário"}}} Você também encontra o Nome de usuário no painel Detalhes do laboratório.
-
Clique em Seguinte.
-
Copie a Senha abaixo e cole na caixa de diálogo de boas-vindas.
{{{user_0.password | "Senha"}}} Você também encontra a Senha no painel Detalhes do laboratório.
-
Clique em Seguinte.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud. Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais. -
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.

Tarefa 1: crie uma chave de API
Como você usa curl para enviar solicitações para a API Natural Language, é preciso uma chave de API para transmitir o URL da solicitação.
-
Para criar uma chave de API, no console do Cloud, selecione Menu de navegação > APIs e serviços > Credenciais.
-
Clique em Criar credenciais e selecione Chave de API.
-
Copie a chave de API criada e clique em Fechar.
Clique em Verificar meu progresso para conferir o objetivo.
Para realizar as próximas etapas, conecte-se à instância provisionada para você por SSH.
-
Clique em Menu de navegação > Compute Engine. Aqui vai aparecer a instância do Linux provisionada,
linux-instance, na lista de instâncias de VM. -
Clique no botão SSH. Você verá um shell interativo.
-
Na linha de comando, digite as seguintes informações e substitua
<YOUR_API_KEY>pela chave que você copiou:
Tarefa 2: envie uma solicitação de análise de entidades
O primeiro método da API Natural Language a ser usado é o analyzeEntities. Com esse método, a API poderá extrair entidades (como pessoas, lugares e eventos) do texto. Para testar a análise de entidades da API, use a seguinte frase:
Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series.
Você cria sua solicitação à API Natural Language no arquivo request.json.
- Use o nano (um editor de código) para criar o arquivo
request.json:
- Digite ou cole o seguinte código no
request.json:
- Pressione CTRL+X para sair do nano, Y para salvar o arquivo e ENTER para confirmar.
Na solicitação, você está dando informações à API Natural Language sobre o texto enviado. Os valores de tipo com suporte são PLAIN_TEXT ou HTML. No conteúdo, você transmite o texto que será enviado à API Natural Language para análise.
A API Natural Language também aceita o envio de arquivos armazenados no Cloud Storage para processamento de texto. Para enviar um arquivo do Cloud Storage, é necessário substituir content por gcsContentUri e atribuir a ele o valor do URI do arquivo de texto no Cloud Storage.
encodingType informa à API qual tipo de codificação usar no processamento do texto. A API vai usar essa informação para calcular onde determinadas entidades aparecem no texto.
Clique em Verificar meu progresso para ver o objetivo.
Tarefa 3: chame a API Natural Language
- Agora é possível transmitir o corpo da solicitação para a API Natural Language, junto com a variável de ambiente da chave de API que você salvou antes, usando o comando
curlabaixo (em uma única linha):
- Para verificar a resposta, execute:
O início da sua resposta será semelhante a:
Para cada entidade na resposta, você recebe o respectivo campo type, o URL da Wikipédia associado (se houver), salience e os índices de onde essa entidade apareceu no texto. A saliência é um número no intervalo [0,1] que se refere à centralidade da entidade no texto como um todo.
A API Natural Language também reconhece a mesma entidade mencionada de maneiras diferentes. Confira a lista de mentions na resposta: a API consegue identificar que "Joanne Rowling", "Rowling", "novelist" e "Robert Galbraith" apontam para a mesma coisa.
Clique em Verificar meu progresso para ver o objetivo.
Tarefa 4: análise de sentimento com a API Natural Language
Além de extrair entidades, é possível executar análise de sentimento em um bloco de texto com a API Natural Language. Essa solicitação JSON incluirá os mesmos parâmetros da solicitação acima, mas você precisará alterar o texto para incluir algo com um sentimento mais intenso desta vez.
- Use o nano para substituir o código em
request.jsonpelo seguinte e, se quiser, substitua ocontentabaixo por um texto próprio:
-
Pressione CTRL+X para sair do nano, Y para salvar o arquivo e ENTER para confirmar.
-
Em seguida, você vai enviar a solicitação ao endpoint
analyzeSentimentda API:
Sua resposta será semelhante a esta:
Chegamos a dois tipos de valores de sentimento: o do documento como um todo e o detalhado por frase. O método "sentiment" retorna dois valores:
-
score: um número entre -1,0 e 1,0 que indica o quanto a declaração é positiva ou negativa. -
magnitude: um número que varia de 0 a infinito e representa o peso do sentimento expresso na declaração, sem importar se ele é positivo ou negativo.
Blocos mais longos de texto com declarações ponderadas têm valores de magnitude mais altos. A pontuação da primeira frase é positiva (0,7) e a da segunda é neutra (0,1).
Tarefa 5: como analisar o sentimento de uma entidade
Além de identificar detalhes de sentimento em todo o documento de texto, a API Natural Language também pode dividir o sentimento pelas entidades. Use esta frase como exemplo:
I liked the sushi but the service was terrible.
Nesse caso, calcular uma pontuação de sentimento para a frase inteira como você fez acima pode não ser tão útil. Se houvesse outras centenas de avaliações para o mesmo restaurante, seria interessante saber exatamente do que as pessoas gostaram ou não gostaram nas avaliações. Felizmente, a API Natural Language tem um método para extrair o sentimento de cada entidade contida no texto. Esse método é chamado de analyzeEntitySentiment. Vamos conferir como isso funciona.
- Use o nano para atualizar o
request.jsoncom a frase abaixo:
-
Pressione CTRL+X para sair do nano, Y para salvar o arquivo e ENTER para confirmar.
-
Em seguida, chame o endpoint
analyzeEntitySentimentcom o seguinte comando curl:
Na resposta, você extrai dois objetos de entidade: um para "sushi" e outro para "service". Esta é a resposta completa do JSON:
A pontuação retornada para "sushi" foi 0, ou seja, neutra, e a de "service", -0,7. Ótimo! Você também deve ter percebido que dois objetos de sentimento foram retornados para cada entidade. Se qualquer um desses termos fosse mencionado mais de uma vez, a API retornaria uma pontuação de sentimento e magnitude diferentes para cada menção, além de um sentimento agregado para a entidade.
Tarefa 6: como analisar a sintaxe e as classes gramaticais
Use a análise sintática, um dos outros métodos da API Natural Language, para conferir os detalhes linguísticos do texto. analyzeSyntax extrai informações linguísticas ao dividir o texto em uma série de frases e tokens (geralmente, limites de palavra) e apresentar uma análise mais detalhada desses tokens. A API informará a classe gramatical para cada palavra do texto (substantivo, verbo, adjetivo etc.) e como ela se relaciona com outras palavras da frase (se é o radical do verbo, um modificador de substantivo etc.).
Faça um teste com uma frase simples. Esta solicitação JSON será semelhante às anteriores e incluirá uma chave de atributos. Isso dirá para a API fazer as anotações de sintaxe.
- Use o nano para substituir o código no
request.jsonpelo seguinte:
-
Pressione CTRL+X para sair do nano, Y para salvar o arquivo e ENTER para confirmar.
-
Em seguida, chame o método
analyzeSyntaxda API:
A resposta vai retornar um objeto como o seguinte para cada token da frase:
Analise a resposta:
-
partOfSpeechinforma que "Joanne" é um substantivo. -
dependencyEdgeinclui dados que você pode usar para criar uma árvore de dependência sintática do texto. Basicamente, é um diagrama que mostra como as palavras de uma frase se relacionam umas com as outras. Uma árvore de dependência sintática da frase acima ficaria assim:
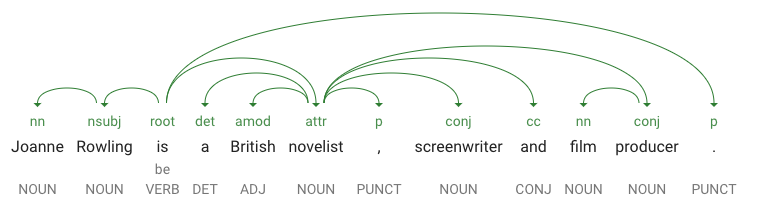
-
headTokenIndexé o índice do token com um arco que aponta para "Joanne". Pense em cada token da frase como uma palavra de uma matriz. -
headTokenIndexigual a 1 para "Joanne" refere-se à palavra "Rowling", à qual está ligada na árvore. O rótuloNN(abreviação de modificador composto por substantivo) descreve o papel da palavra na frase. "Joanne" modifica "Rowling", o sujeito da frase. -
lemmaé a forma canônica da palavra. Por exemplo, as palavras executar, executa, executou e executando têm todas o lema executar. O valor do "lemma" é útil para rastrear ocorrências de uma palavra em um texto longo.
Tarefa 7: processamento de linguagem natural multilíngue
A API Natural Language também oferece suporte a idiomas diferentes do inglês (uma lista completa pode ser conferida no Guia de suporte a idiomas).
- Modifique o código em
request.jsoncom uma frase em japonês:
- Pressione CTRL+X para sair do nano, Y para salvar o arquivo e ENTER para confirmar.
Você não informou à API em qual idioma o texto está, mas ela detectou o idioma automaticamente.
- Depois, você vai enviar o arquivo ao endpoint
analyzeEntities:
E vai receber a seguinte resposta:
Os URLs da Wikipédia apontam para as páginas da Wikipédia em japonês. Bacana, não é?
Parabéns!
Você aprendeu a realizar uma análise de texto com a API Cloud Natural Language extraindo entidades, analisando sentimento e fazendo anotações de sintaxe. Neste laboratório, você criou uma solicitação da API Natural Language e chamou a API com curl, extraiu entidades e fez a análise de sentimento no texto com essa API, realizou uma análise linguística no texto e criou uma solicitação da API Natural Language em outro idioma.
Próximas etapas
- Confira os tutoriais da API Natural Language na documentação.
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 14 de fevereiro de 2024
Laboratório testado em 13 de outubro de 2023
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.

