



Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Create Cloud Dataproc cluster
/ 50
Create a Logistic Regression Model
/ 50
En este lab aprenderás a implementar la regresión logística usando una biblioteca de aprendizaje automático en Apache Spark. Spark se ejecuta en un clúster de Dataproc para desarrollar un modelo para datos de un conjunto de datos multivariable.
Dataproc es un servicio en la nube rápido, fácil de usar y completamente administrado que se utiliza para ejecutar clústeres de Apache Spark y Apache Hadoop de manera simple y rentable. Dataproc se integra fácilmente a otros servicios de Google Cloud, lo que te proporciona una plataforma eficaz y completa para procesamiento de datos, analítica y aprendizaje automático.
Apache Spark es un motor de analítica para procesamiento de datos a gran escala. La regresión logística está disponible como un módulo en MLlib, la biblioteca de aprendizaje automático de Apache Spark. Spark MLlib, también llamada Spark ML, incluye implementaciones para la mayoría de los algoritmos estándar de aprendizaje automático como agrupamientos en clústeres k-means, bosques aleatorios, mínimos cuadrados alternos, árboles de decisión, máquinas de vectores de soporte, entre otros. Spark se puede ejecutar en un clúster Hadoop, como Dataproc, con el objetivo de procesar conjuntos de datos muy grandes en paralelo.
Este lab utiliza un conjunto de datos base que se recuperó de US Bureau of Transport Statistics. El conjunto de datos proporciona información histórica sobre los vuelos internos en Estados Unidos y puede utilizarse para ilustrar una amplia gama de conceptos y técnicas de ciencia de datos. Este lab proporciona los datos como un conjunto de archivos de texto con formato CSV.
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
Haga clic en el botón Comenzar lab. Si debe pagar por el lab, se abrirá una ventana emergente para que seleccione su forma de pago. A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordene las pestañas en ventanas separadas, una junto a la otra.
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
También puedes encontrar el nombre de usuario en el panel Detalles del lab.
Haz clic en Siguiente.
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
También puedes encontrar la contraseña en el panel Detalles del lab.
Haz clic en Siguiente.
Haga clic para avanzar por las páginas siguientes:
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.

Habitualmente, el primer paso para escribir trabajos en Hadoop es iniciar su instalación. Esto implica establecer un clúster, instalarle Hadoop y configurarlo de manera que las máquinas se reconozcan entre ellas y puedan comunicarse de manera segura.
Luego, comienzas los procesos YARN y MapReduce y, finalmente, está todo listo para escribir unos programas en Hadoop. En Google Cloud, Dataproc hace más práctico iniciar un clúster Hadoop capaz de ejecutar MapReduce, Pig, Hive, Presto y Spark.
Si estás usando Spark, Dataproc ofrece un entorno Spark completamente administrado y sin servidores, solo tienes que enviar un programa Spark y Dataproc lo ejecuta. De esta manera, Dataproc es a Apache Spark lo que Dataflow es a Apache Beam. En realidad, Dataproc y Dataflow comparten servicios de backend.
En esta parte crearás una VM y, después, un clúster Dataproc en la VM.
En la consola de Cloud, en menú de navegación (
Haz clic en el botón SSH junto a la VM startup-vm para ejecutar y conectar una terminal.
Haz clic en Conectar para confirmar la conexión de SSH.
Ejecuta el siguiente comando para clonar el repositorio data-science-on-gcp y navegar hacia el directorio 06_dataproc:
create_cluster.sh quitando el código de dependencia zonal --zone ${REGION}-a
El resultado debería ser similar al siguiente:
Guarda el archivo con Ctrl+X, presiona Y e Intro
Crea un clúster de Dataproc para ejecutar los trabajos, especificando el nombre de tu bucket y la región en la que se encuentra:
Este comando podría tardar unos minutos.
En la consola de Cloud, en el menú de navegación, haz clic en Dataproc. Es posible que tengas que hacer clic en Más Productos y desplazar hacia abajo.
En lista de clústeres, haz clic en el nombre del clúster para ver más detalles.
Haz clic en la pestaña Interfaces web y, luego, haz clic en JupyterLab en la parte inferior del panel derecho.
En la sección del selector de Notebook, haz clic en Python 3 para abrir un notebook nuevo.
Para usar un notebook, debes ingresar comandos en una celda. Asegúrate de ejecutar los comandos en la celda presionando Mayúsculas + Intro o haciendo clic en el triángulo que aparece en el menú superior del notebook para ejecutar las celdas seleccionadas y avanzar.
Una vez que ese código se agregue al comienzo de cualquier secuencia de comandos de Spark en Python, cualquier código que se desarrolle con la shell interactiva de Spark o el notebook de Jupyter también funcionará cuando se inicie como una secuencia de comandos independiente.
Cuando iniciaste este lab, una secuencia de comandos automatizada te proporcionó datos en la forma de un conjunto de archivos CSV preparados, que se colocaron en tu bucket de Cloud Storage.
traindays leyendo un CSV preparado que la secuencia de comandos automatizada colocó en tu bucket de Cloud Storage.El archivo CSV identifica un subconjunto de días como válido para entrenamiento. Esto te permite crear vistas de todo el conjunto de datos flights, que está dividido en un conjunto de datos que se usa para entrenar a tu modelo, y otro que prueba o valida ese modelo.
Este comando muestra los primeros cinco registros en la tabla de entrenamiento:
El próximo paso del proceso es identificar los archivos de datos de origen.
all_flights-00000-*, ya que tiene un subconjunto representativo del conjunto de datos completo y se puede procesar en un tiempo razonable:
#inputs = 'gs://{}/flights/tzcorr/all_flights-*'.format(BUCKET) # FULL
"Truncated the string representation of a plan since it was too large." Para este lab, ignórala, ya que solo es relevante si quieres inspeccionar los registros de esquema SQL. Tu resultado debería ser similar al siguiente código:
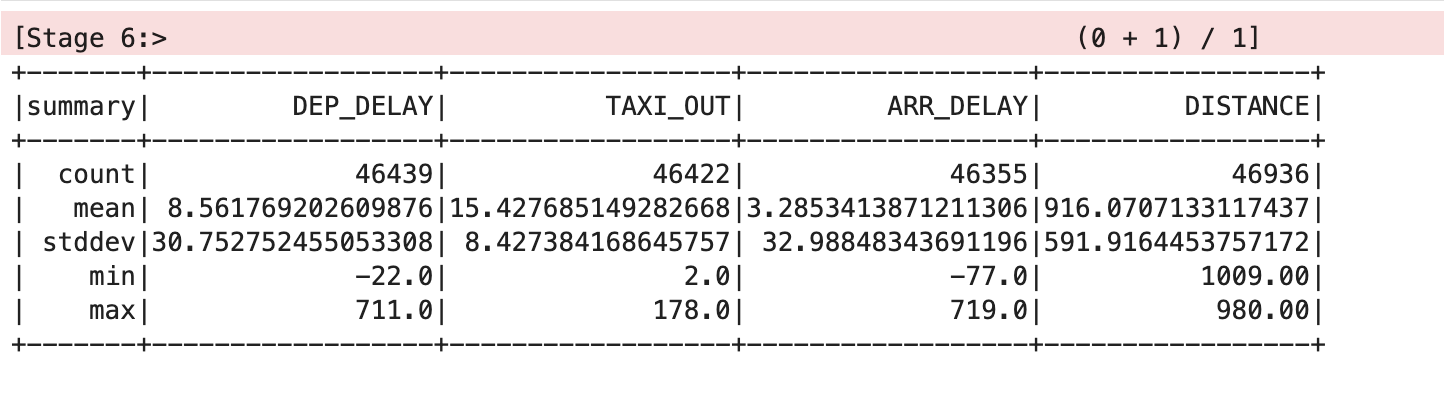
Esto debería mostrar un resultado similar a la siguiente tabla:
En esta tabla, los valores de la media y la desviación estándar se redondearon a dos decimales para mayor claridad, pero en la pantalla verás los valores de punto flotante completos.
En la tabla, se muestra que hay algunos problemas con los datos. No todos los registros tienen valores para todas las variables, hay diferentes estadísticas de recuento en DEP_DELAY, TAXI_OUT, ARR_DELAY y DISTANCE. Esto ocurre por los siguientes motivos:
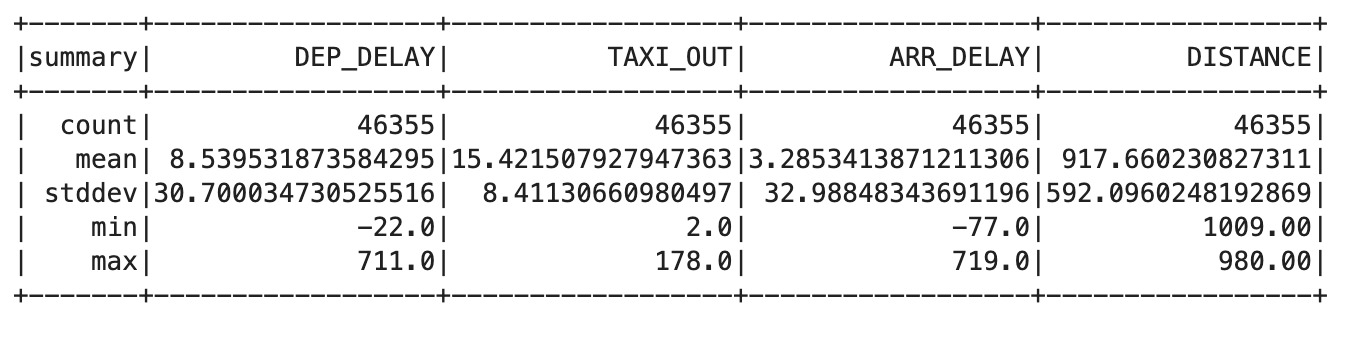
Esto debería mostrar un resultado similar a la siguiente tabla:
Este resultado debería mostrar el mismo valor de recuento para cada columna, lo cual indica que solucionaste el problema.
Ahora puedes crear una función que convierta un conjunto de datos de tu DataFrame en un ejemplo de entrenamiento. Un ejemplo de entrenamiento contiene una muestra de los atributos de entrada y la respuesta correcta para esas entradas.
En este caso, respondes si el retraso de la llegada es menor a 15 minutos. Las etiquetas que usas como entrada son los valores de retraso de salida, tiempo de carreteo previo al despegue y distancia de vuelo.
El DataFrame de entrenamiento crea un modelo de regresión logística basada en tu conjunto de datos de entrenamiento:
intercept=verdadero, porque, en este caso, la predicción para el retraso de llegadas no será igual a cero cuando todas las entradas sean cero.intercept=Falso.lrmodel tendrá pesos y un valor de intercepción que puedes inspeccionar:El resultado es similar al siguiente:
Cuando estos pesos se usen con la fórmula de regresión lineal, te permitirán crear un modelo utilizando código en el lenguaje que desees.
El resultado de 1 predice que el vuelo llegará a tiempo.
El resultado de 0 predice que el vuelo no llegará a tiempo.
Estos resultados no son probabilidades; se devuelven como verdadero o falso según un umbral que se configura en 0.5 de forma predeterminada.
Observa que los resultados son probabilidades, con el primer resultado cerca de 1 y el segundo, cerca de 0.
Nuevamente, tus resultados son 1 y 0, pero ahora reflejan el umbral de probabilidad del 70% que necesitas y no el 50% predeterminado.
Puedes guardar un modelo de regresión logística de Spark directamente en Cloud Storage. Esto te permite reutilizar un modelo sin tener que volver a entrenarlo desde cero.
Una ubicación de almacenamiento contiene solo un modelo. Esto evita interferencias con otros archivos existentes, que pueden causar problemas con la carga del modelo. Para ello, asegúrate de que la ubicación de almacenamiento esté vacía antes de guardar tu modelo de regresión Spark.
Este comando debería informar un error que indica CommandException: 1 files/objects could not be removed porque aún no se guardó el modelo. El error indica que no hay archivos en la ubicación de destino. Debes asegurarte de que la ubicación esté vacía antes de intentar guardar el modelo; esto es lo que nos garantiza este comando.
Se restablecieron los parámetros del modelo, es decir, los valores de intercepciones y pesos.
Esto imprime en pantalla un 0, que predice que el vuelo probablemente llegará tarde, según tu umbral de probabilidad del 70%.
Esto imprime en pantalla un 1, que predice que el vuelo probablemente llegará a tiempo, según tu umbral de probabilidad del 70%.
Una vez que se quiten los umbrales, obtendrás las probabilidades. La probabilidad de llegar tarde aumenta a medida que aumenta el tiempo de retraso de la salida.
Como se puede observar, el efecto es relativamente menor. La probabilidad aumenta de 0.63 a 0.76 aproximadamente a medida que la distancia pasa de un vuelo muy corto a un vuelo intercontinental.
Por otro lado, si mantienes constantes el tiempo de carreteo previo al despegue y la distancia, y analizas el efecto del retraso de la salida, vas a ver un impacto más drástico.
Esto debería mostrar un resultado similar a la siguiente tabla:
eval y devuelve los detalles de los vuelos totales cancelados, totales no cancelados, cancelados correctos y no cancelados correctos:Resultado:
Resultado:
Ahora sabes cómo usar Spark para realizar una regresión logística con un clúster de Dataproc.
Continúa con:
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 4 de diciembre de 2023
Prueba más reciente del lab: 4 de diciembre de 2023
Copyright 2025 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.



Este contenido no está disponible en este momento
Te enviaremos una notificación por correo electrónico cuando esté disponible

¡Genial!
Nos comunicaremos contigo por correo electrónico si está disponible

One lab at a time
Confirm to end all existing labs and start this one