检查点
Disable and re-enable the Dataflow API
/ 10
Create a Cloud Storage Bucket
/ 10
Copy Files to Your Bucket
/ 10
Create the BigQuery Dataset (name: lake)
/ 20
Build a Data Ingestion Dataflow Pipeline
/ 10
Build a Data Transformation Dataflow Pipeline
/ 10
Build a Data Enrichment Dataflow Pipeline
/ 10
Build a Data lake to Mart Dataflow Pipeline
/ 20
在 Google Cloud 上使用 Dataflow 和 BigQuery 處理 ETL 作業 (Python)
- GSP290
- 總覽
- 設定和需求
- 工作 1:確定已成功啟用 Dataflow API
- 工作 2:下載範例程式碼
- 工作 3:建立 Cloud Storage 值區
- 工作 4:將檔案複製到值區
- 工作 5:建立 BigQuery 資料集
- 工作 6:建構 Dataflow pipeline
- 工作 7:使用 Dataflow pipeline 擷取資料
- 工作 8:查看 pipeline 的 Python 程式碼
- 工作 9:執行 Apache Beam pipeline
- 工作 10:資料轉換
- 工作 11:執行 Dataflow 資料轉換 pipeline
- 工作 12:資料擴充
- 工作 13:查看資料擴充 pipeline Python 程式碼
- 工作 14:執行 Dataflow 資料擴充 pipeline
- 工作 15:彙整資料湖泊與資料市集並檢查 pipeline Python 程式碼
- 工作 16:透過 Apache Beam pipeline 執行資料彙整作業,在 BigQuery 中建立結果資料表
- 隨堂測驗
- 恭喜!
GSP290

總覽
在 Google Cloud 中,您可以建構執行 Python 程式碼的資料 pipeline,進而透過下列 Google Cloud 服務擷取公開資料集的資料並轉換至 BigQuery:
- Cloud Storage
- Dataflow
- BigQuery
在本實驗室中,您將使用上述服務自行建立資料 pipeline,同時需考量設計要點和導入細節,確保原型符合要求。在操作過程中,務必按照說明開啟 Python 檔案並詳閱當中的註解。
學習內容
本實驗室的內容包括:
- 建構及執行 Dataflow pipeline (Python) 來擷取資料
- 建構及執行 Dataflow pipeline (Python) 來轉換及擴充資料
設定和需求
點選「Start Lab」按鈕前的須知事項
請詳閱以下操作說明。研究室活動會計時,而且中途無法暫停。點選「Start Lab」 後就會開始計時,讓您瞭解有多少時間可以使用 Google Cloud 資源。
您將在真正的雲端環境中完成實作研究室活動,而不是在模擬或示範環境。為達此目的,我們會提供新的暫時憑證,讓您用來在研究室活動期間登入及存取 Google Cloud。
如要完成這個研究室活動,請先確認:
- 您可以使用標準的網際網路瀏覽器 (Chrome 瀏覽器為佳)。
- 是時候完成研究室活動了!別忘了,活動一開始將無法暫停。
如何開始研究室及登入 Google Cloud 控制台
-
按一下「Start Lab」(開始研究室) 按鈕。如果研究室會產生費用,畫面中會出現選擇付款方式的彈出式視窗。左側的「Lab Details」(研究室詳細資料) 面板會顯示下列項目:
- 「Open Google Console」(開啟 Google 控制台) 按鈕
- 剩餘時間
- 必須在這個研究室中使用的暫時憑證
- 完成這個研究室所需的其他資訊 (如有)
-
按一下「Open Google Console」(開啟 Google 控制台)。接著,研究室會啟動相關資源並開啟另一個分頁,當中會顯示「Sign in」(登入) 頁面。
提示:您可以在不同的視窗中並排開啟分頁。
注意事項:如果頁面中顯示了「Choose an account」(選擇帳戶) 對話方塊,請按一下「Use Another Account」(使用其他帳戶)。 -
如有必要,請複製「Lab Details」(研究室詳細資料) 面板中的使用者名稱,然後貼到「Sign in」(登入) 對話方塊。按一下「Next」(下一步)。
-
複製「Lab Details」(研究室詳細資料) 面板中的密碼,然後貼到「Welcome」(歡迎使用) 對話方塊。按一下「Next」(下一步)。
重要注意事項:請務必使用左側面板中的憑證,而非 Google Cloud 技能重點加強的憑證。 注意事項:如果使用自己的 Google Cloud 帳戶來進行這個研究室,可能會產生額外費用。 -
按過後續的所有頁面:
- 接受條款及細則。
- 由於這是臨時帳戶,請勿新增救援選項或雙重驗證機制。
- 請勿申請免費試用。
Cloud 控制台稍後會在這個分頁中開啟。

啟動 Cloud Shell
Cloud Shell 是搭載多項開發工具的虛擬機器,提供永久的 5 GB 主目錄,而且在 Google Cloud 中運作。Cloud Shell 提供指令列存取權,方便您使用 Google Cloud 資源。
- 點按 Google Cloud 控制台上方的「啟用 Cloud Shell」圖示
。
連線完成即代表已通過驗證,且專案已設為您的 PROJECT_ID。輸出內容中有一行宣告本工作階段 PROJECT_ID 的文字:
gcloud 是 Google Cloud 的指令列工具,已預先安裝於 Cloud Shell,並支援 Tab 鍵自動完成功能。
- (選用) 您可以執行下列指令來列出使用中的帳戶:
-
點按「授權」。
-
輸出畫面應如下所示:
輸出內容:
- (選用) 您可以使用下列指令來列出專案 ID:
輸出內容:
輸出內容範例:
gcloud 的完整說明,請前往 Google Cloud 並參閱「gcloud CLI overview guide」(gcloud CLI 總覽指南)。
工作 1:確定已成功啟用 Dataflow API
為確保能使用必要的 API,請重新啟動連至 Dataflow API 的連線。
-
在 Cloud 控制台最上方的搜尋列中,輸入「Dataflow API」。點選「Dataflow API」搜尋結果。
-
點選「管理」。
-
點選「停用 API」。
如果系統要求您確認操作,請點選「停用」。
- 點選「啟用」。
API 重新啟用後,頁面上會顯示停用選項。
測試已完成的工作
點選「Check my progress」確認工作已完成。
工作 2:下載範例程式碼
- 在 Cloud Shell 中執行下列指令,從 Google Cloud 的專業服務 GitHub 下載 Dataflow Python 範例程式碼:
- 接著在 Cloud Shell 中,將變數設為您的專案 ID。
工作 3:建立 Cloud Storage 值區
- 在 Cloud Shell 中使用 make bucket 指令,為專案的「
」區域建立新的區域值區:
測試已完成的工作
點選「Check my progress」確認工作已完成。
工作 4:將檔案複製到值區
- 在 Cloud Shell 中使用
gsutil指令,將檔案複製到剛才建立的 Cloud Storage 值區:
測試已完成的工作
點選「Check my progress」確認工作已完成。
工作 5:建立 BigQuery 資料集
- 在 Cloud Shell 中建立名為
lake的 BigQuery 資料集,所有載入 BigQuery 的資料表都會存放在這裡:
測試已完成的工作
點選「Check my progress」確認工作已完成。
工作 6:建構 Dataflow pipeline
在本節中,您將建立僅供附加的 Dataflow pipeline,以便將資料擷取至 BigQuery 資料表。您可以使用內建的程式碼編輯器,查看及編輯 Google Cloud 控制台中的程式碼。
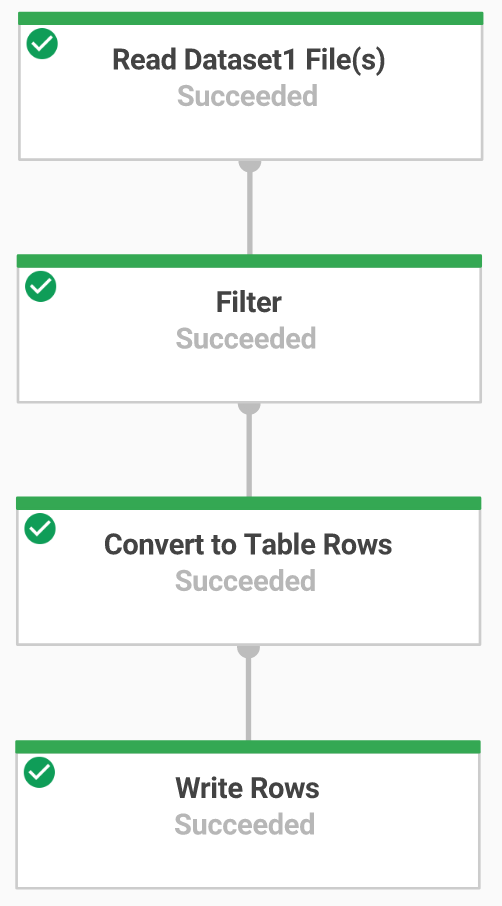
開啟 Cloud Shell 程式碼編輯器
- 在 Cloud Shell 中點按「開啟編輯器」圖示,以瀏覽原始碼:

- 如果出現提示訊息,請點按「在新視窗中開啟」。程式碼編輯器會在新視窗中開啟。您可以透過 Cloud Shell 編輯器,在 Cloud Shell 環境中編輯檔案。只要點按「編輯器」部分的「開啟終端機」,即可返回 Cloud Shell。
工作 7:使用 Dataflow pipeline 擷取資料
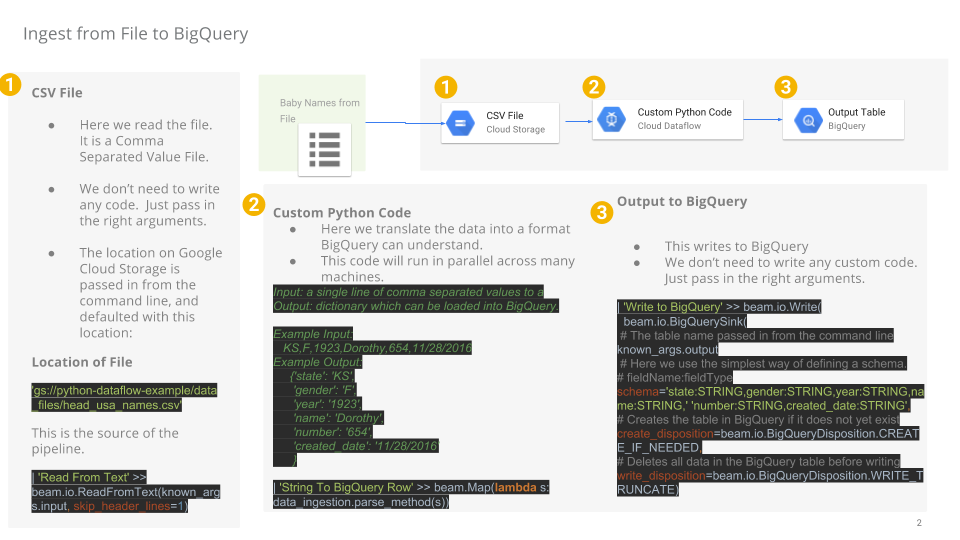
現在請使用 TextIO 來源和 BigQueryIO 目的地建構 Dataflow pipeline,將資料擷取至 BigQuery。具體來說,這個 pipeline 應能完成以下工作:
- 從 Cloud Storage 擷取檔案。
- 篩除檔案的標題列。
- 將讀取的資料行轉換為字典物件。
- 將資料列輸出至 BigQuery。
工作 8:查看 pipeline 的 Python 程式碼
在「程式碼編輯器」中,依序前往「dataflow-python-examples」>「dataflow_python_examples」,然後開啟「data_ingestion.py」檔案。請詳閱檔案註解,瞭解程式碼的作用。這個程式碼將填入 BigQuery 的 lake 資料集和資料表。
工作 9:執行 Apache Beam pipeline
- 進行這個步驟時,請返回 Cloud Shell 工作階段,設定稍後需要用到的 Python 程式庫。
本實驗室的 Dataflow 工作需要使用 Python3.8。為確保您使用的是正確版本,您將在 Python 3.8 Docker 容器中執行 Dataflow 程序。
- 在 Cloud Shell 中執行下列指令,啟動 Python 容器:
這個指令會使用最新的 Python 3.8 穩定版提取 Docker 容器,並執行指令殼層,在容器中執行後續指令。-v 旗標會提供原始碼做為容器的 volume,以便您在 Cloud Shell 編輯器中編輯程式碼,同時繼續在執行中的容器內存取原始碼。
- 當容器提取完畢並開始在 Cloud Shell 中執行時,請透過下列指令,在該容器中安裝
apache-beam:
- 接著在 Cloud Shell,將執行中容器的目錄變更為連結原始碼的位置:
在雲端執行 Dataflow 資料擷取 pipeline
- 執行下列指令來啟動所需工作站,並在完成作業後將其關閉:
- 返回 Cloud 控制台,然後依序開啟「導覽選單」>「Dataflow」,查看工作狀態。

-
點按工作名稱並查看其進度。「工作狀態」顯示「已完成」時,您即可前往下一個步驟。這個 Dataflow pipeline 從啟動、完成工作到關閉所需的時間約為五分鐘。
-
前往 BigQuery (依序點按「導覽選單」>「BigQuery」) 查看資料是否已填入。
- 點按專案名稱,查看
lake資料集底下的「usa_names」資料表。

- 點按資料表,然後前往「預覽」分頁查看
usa_names資料範例。
usa_names 資料表,請重新整理頁面,或使用傳統版 BigQuery 使用者介面查看。
測試已完成的工作
點選「Check my progress」確認工作已完成。
工作 10:資料轉換
現在請使用 TextIO 來源和 BigQueryIO 目的地建構 Dataflow pipeline,將資料擷取至 BigQuery。具體來說,這個 pipeline 應能完成以下工作:
- 從 Cloud Storage 擷取檔案。
- 將讀取的資料行轉換為字典物件。
- 將包含年份的資料轉換成 BigQuery 可理解的日期格式。
- 將資料列輸出至 BigQuery。
查看轉換 pipeline Python 程式碼
在程式碼編輯器中,開啟「data_transformation.py」檔案。請詳閱檔案註解,瞭解程式碼的作用。
工作 11:執行 Dataflow 資料轉換 pipeline
請在雲端執行 Dataflow pipeline,整個程序包括啟動所需工作站,並在完成作業後將其關閉。
- 執行下列指令來進行這項工作:
-
依序前往「導覽選單」>「Dataflow」,然後點按工作名稱來查看工作狀態。這個 Dataflow pipeline 從啟動、完成工作到關閉所需的時間約為五分鐘。
-
「工作狀態」畫面顯示 Dataflow 工作狀態為「已完成」後,請前往「BigQuery」檢查資料是否已填入。
-
您應該會在
lake資料集下方看到「usa_names_transformed」資料表。 -
點按資料表,然後前往「預覽」分頁查看「
usa_names_transformed」資料樣本。
usa_names_transformed 資料表,請重新整理頁面,或使用傳統版 BigQuery 使用者介面查看。
測試已完成的工作
點選「Check my progress」確認工作已完成。
工作 12:資料擴充
現在請使用 TextIO 來源和 BigQueryIO 目的地建構 Dataflow pipeline,將資料擷取至 BigQuery。具體來說,這個 pipeline 應能完成以下工作:
- 從 Cloud Storage 擷取檔案。
- 篩除檔案的標題列。
- 將讀取的資料行轉換為字典物件。
- 將資料列輸出至 BigQuery。
工作 13:查看資料擴充 pipeline Python 程式碼
-
在程式碼編輯器中,開啟「
data_enrichment.py」檔案。 -
詳閱註解,瞭解程式碼的作用。這個程式碼會將資料填入 BigQuery。
目前第 83 行程式碼看起來像這樣:
- 請將程式碼編輯成跟下方一樣:
- 這行程式碼編輯完成後,記得選取編輯器的「檔案」下拉式選單,然後點按「儲存」,儲存更新後的檔案。
工作 14:執行 Dataflow 資料擴充 pipeline
在這項工作中,您將在雲端執行 Dataflow pipeline。
- 請在 Cloud Shell 中執行下列指令來啟動所需工作站,並在完成作業後將其關閉:
-
依序前往「導覽選單」>「Dataflow」,查看工作狀態。這個 Dataflow pipeline 從啟動、完成工作到關閉所需的時間約為五分鐘。
-
「工作狀態」畫面顯示 Dataflow 工作狀態為「已完成」後,請前往「BigQuery」檢查資料是否已填入。
您應該會在 lake 資料集底下看到「usa_names_enriched」資料表。
- 點按資料表,然後前往「預覽」分頁查看「
usa_names_enriched」資料樣本。
usa_names_enriched 資料表,請重新整理頁面,或使用傳統版 BigQuery 使用者介面查看。
測試完成的資料擴充工作
點選「Check my progress」確認工作已完成。
工作 15:彙整資料湖泊與資料市集並檢查 pipeline Python 程式碼
現在,請建構並使用 Dataflow pipeline,從兩個 BigQuery 資料來源讀取資料,然後彙整資料來源。具體來說,這個 pipeline 應能完成以下工作:
- 從兩個 BigQuery 來源擷取檔案。
- 彙整兩個資料來源。
- 篩除檔案的標題列。
- 將讀取的資料行轉換為字典物件。
- 將資料列輸出至 BigQuery。
在「程式碼編輯器」中,開啟「data_lake_to_mart.py」檔案。請詳閱檔案註解,瞭解程式碼的作用。這個程式碼會彙整兩份資料表,並將彙整後的資料填入 BigQuery。
工作 16:透過 Apache Beam pipeline 執行資料彙整作業,在 BigQuery 中建立結果資料表
在這項工作中,您將在雲端執行 Dataflow pipeline。
- 請在 Cloud Shell 中執行下列程式碼區塊來啟動所需工作站,並在完成作業後將其關閉:
-
依序前往「導覽選單」>「Dataflow」,然後點按工作名稱,查看這項新工作的狀態。這個 Dataflow pipeline 從啟動、完成工作到關閉所需的時間約為五分鐘。
-
「工作狀態」畫面顯示 Dataflow 工作狀態為「已完成」後,請前往「BigQuery」檢查資料是否已填入。
您應該會在 lake 資料集下方看到「orders_denormalized_sideinput」資料表。
- 點按資料表,然後前往「預覽」分頁查看
orders_denormalized_sideinput資料樣本。
orders_denormalized_sideinput 資料表,請重新整理頁面,或使用傳統版 BigQuery 使用者介面查看。
測試完成的彙整工作
點選「Check my progress」確認工作已完成。
隨堂測驗
您可透過下列選擇題更清楚本實驗室的概念。盡力回答即可。
恭喜!
您已順利使用 Dataflow 執行 Python 程式碼,將資料擷取至 BigQuery 並轉換資料。
後續步驟/瞭解詳情
想瞭解更多資訊嗎?歡迎瀏覽以下官方說明文件:
- Dataflow
- BigQuery
- 查看 Apache Beam 程式設計指南,學習更多進階概念。
- 參考下列實驗室:
Google Cloud 教育訓練與認證
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2024 年 2 月 11 日
實驗室上次測試日期:2023 年 10 月 12 日
Copyright 2024 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。