Puntos de control
Disable and re-enable the Dataflow API
/ 10
Create a Cloud Storage Bucket
/ 10
Copy Files to Your Bucket
/ 10
Create the BigQuery Dataset (name: lake)
/ 20
Build a Data Ingestion Dataflow Pipeline
/ 10
Build a Data Transformation Dataflow Pipeline
/ 10
Build a Data Enrichment Dataflow Pipeline
/ 10
Build a Data lake to Mart Dataflow Pipeline
/ 20
Procesamiento ETL en Google Cloud a través de Dataflow y BigQuery (Python)
- GSP290
- Descripción general
- Configuración y requisitos
- Tarea 1: Asegúrate de que la API de Dataflow esté habilitada correctamente
- Tarea 2: Descarga el código de partida
- Tarea 3. Crea un bucket de Cloud Storage
- Tarea 4: Copia archivos al bucket
- Tarea 5: Crea un conjunto de datos de BigQuery
- Tarea 6: Crea una canalización de Dataflow
- Tarea 7: Transfiere datos con una canalización de Dataflow
- Tarea 8: Revisa el código de Python de la canalización
- Tarea 9: Ejecuta la canalización de Apache Beam
- Tarea 10: Transforma los datos
- Tarea 11: Ejecuta la canalización de transformación de Dataflow
- Tarea 12: Enriquece los datos
- Tarea 13: Revisa el código de Python de la canalización de enriquecimiento de datos
- Tarea 14: Ejecuta la canalización de Dataflow de enriquecimiento de datos
- Tarea 15: Data lake a data mart y revisión del código de Python de la canalización
- Tarea 16: Ejecuta la canalización de Apache Beam para realizar la unión de datos y crear la tabla resultante en BigQuery
- Pon a prueba tus conocimientos
- ¡Felicitaciones!
GSP290

Descripción general
En Google Cloud, puedes crear canalizaciones de datos que ejecutan código de Python para transferir y transformar datos de conjuntos de datos públicos a BigQuery con estos servicios de Google Cloud:
- Cloud Storage
- Dataflow
- BigQuery
En este lab, usarás estos servicios para crear tu propia canalización de datos, incluidos los detalles de implementación y las consideraciones de diseño, para garantizar que tu prototipo cumpla con los requisitos. Asegúrate de abrir los archivos de Python y leer los comentarios cuando se te indique.
Actividades
En este lab, aprenderás a hacer lo siguiente:
- Crear y ejecutar canalizaciones de Dataflow (Python) para transferir datos
- Crear y ejecutar canalizaciones de Dataflow (Python) para transformar y enriquecer datos
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab: Recuerda que, una vez que comienzas un lab, no puedes pausarlo.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haga clic en el botón Comenzar lab. Si debe pagar por el lab, se abrirá una ventana emergente para que seleccione su forma de pago. A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón Abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debe usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordene las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta. -
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}} También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}} También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud. Nota: Usar tu propia Cuenta de Google podría generar cargos adicionales. -
Haga clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.

Activa Cloud Shell
Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
- Haz clic en Activar Cloud Shell
en la parte superior de la consola de Google Cloud.
Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu PROJECT_ID. El resultado contiene una línea que declara el PROJECT_ID para esta sesión:
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
- Puedes solicitar el nombre de la cuenta activa con este comando (opcional):
-
Haz clic en Autorizar.
-
Ahora, el resultado debería verse de la siguiente manera:
Resultado:
- Puedes solicitar el ID del proyecto con este comando (opcional):
Resultado:
Resultado de ejemplo:
gcloud, consulta la guía con la descripción general de gcloud CLI en Google Cloud.
Tarea 1: Asegúrate de que la API de Dataflow esté habilitada correctamente
Para garantizar el acceso a la API necesaria, reinicia la conexión a la API de Dataflow.
-
En la consola de Cloud, ingresa “API de Dataflow” en la barra de búsqueda superior. Haz clic en el resultado de API de Dataflow.
-
Haz clic en Administrar.
-
Haz clic en Inhabilitar API.
Si se te solicita confirmar, haz clic en Inhabilitar.
- Haz clic en Habilitar.
Cuando se haya habilitado de nuevo la API, se mostrará en la página la opción para inhabilitarla.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada.
Tarea 2: Descarga el código de partida
- Ejecuta el siguiente comando en Cloud Shell para obtener ejemplos de Dataflow para Python del GitHub de servicios profesionales de Google Cloud:
- Ahora, en Cloud Shell, establece una variable igual a tu ID del proyecto:
Tarea 3. Crea un bucket de Cloud Storage
- Usa el comando correspondiente en Cloud Shell para crear un nuevo bucket regional en la región
dentro de tu proyecto:
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada.
Tarea 4: Copia archivos al bucket
- Usa el comando
gsutilen Cloud Shell para copiar archivos al bucket de Cloud Storage que acabas de crear:
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada.
Tarea 5: Crea un conjunto de datos de BigQuery
- En Cloud Shell, crea un conjunto de datos en BigQuery llamado
lake. Todas tus tablas se cargarán en BigQuery aquí:
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada.
Tarea 6: Crea una canalización de Dataflow
En esta sección, crearás un Dataflow que solo permite anexar y que transferirá datos a la tabla de BigQuery. Puedes usar el Editor de código incorporado que te permitirá ver y editar el código en la consola de Google Cloud.
Abre el editor de código de Cloud Shell
- Haz clic en el ícono Abrir editor para navegar al código fuente en Cloud Shell:

- Si se te solicita, haz clic en Abrir en una nueva ventana. Se abrirá el editor de código en una ventana nueva. El editor de Cloud Shell te permite editar archivos en el entorno de Cloud Shell. Desde el Editor, puedes hacer clic en Abrir terminal para volver a Cloud Shell.
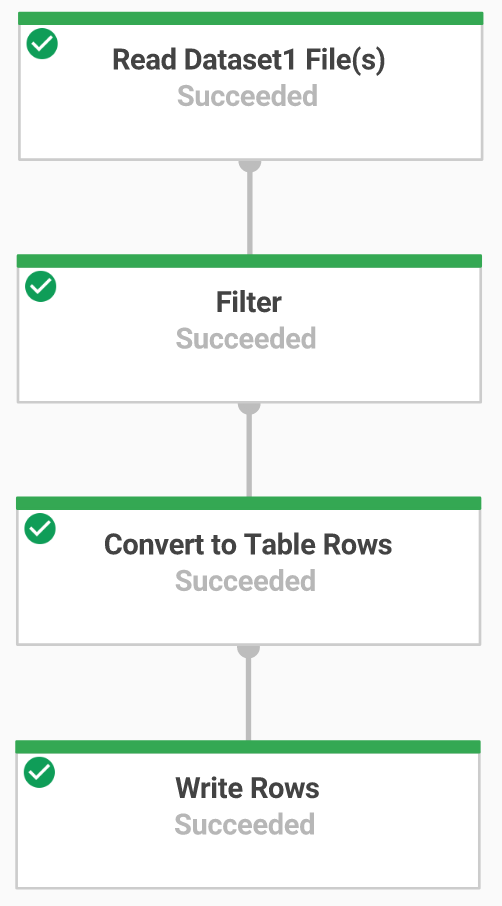
Tarea 7: Transfiere datos con una canalización de Dataflow
Ahora, crearás una canalización de Dataflow con una fuente de TextIO y un destino de BigQueryIO para transferir datos a BigQuery. Específicamente, la canalización hará lo siguiente:
- Transferir los archivos desde Cloud Storage
- Filtrar la fila del encabezado en los archivos
- Convertir las líneas leídas en objetos del diccionario
- Enviar las filas a BigQuery
Tarea 8: Revisa el código de Python de la canalización
En el Editor de código, navega a dataflow-python-examples > dataflow_python_examples y abre el archivo data_ingestion.py. Lee los comentarios en el archivo que explican lo que hace el código. Este código propagará el conjunto de datos lake con una tabla en BigQuery.
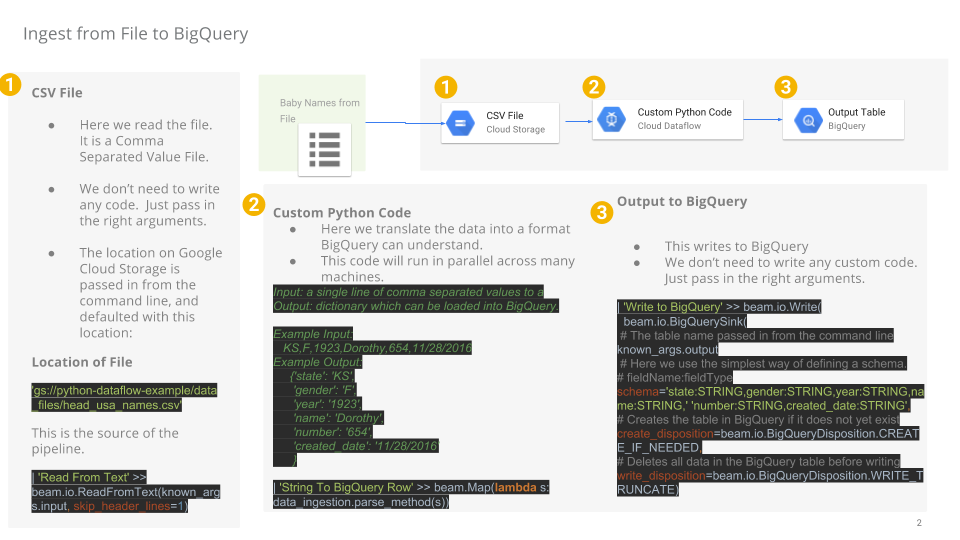
Tarea 9: Ejecuta la canalización de Apache Beam
- Vuelve a tu sesión de Cloud Shell para realizar el siguiente paso. Ahora, configurarás las bibliotecas de Python requeridas.
El trabajo de Dataflow en este lab requerirá Python3.8. Para garantizar que estás utilizando la versión correcta, ejecutarás los procesos de Dataflow en un contenedor de Docker Python 3.8.
- Ejecuta lo siguiente en Cloud Shell para iniciar un contenedor de Python:
Con este comando, se obtendrá un contenedor de Docker con la versión estable más reciente de Python 3.8 y se ejecutará una shell de comando para ejecutar los siguientes comandos en el contenedor. La marca -v proporciona el código fuente como un volumen para el contenedor, de manera que podamos utilizar el editor de Cloud Shell y, aun así, acceder a él dentro del contenedor en ejecución.
- Una vez que el contenedor termine la extracción y comience a ejecutarse en Cloud Shell, ejecuta lo siguiente para instalar
apache-beamen ese contenedor en ejecución:
- Luego, en el contenedor en ejecución en Cloud Shell, cambia al directorio en el que vinculaste el código fuente:
Ejecuta la canalización de Dataflow de transferencia en la nube
- Lo que se muestra a continuación iniciará los trabajadores requeridos y los cerrará cuando el proceso haya finalizado:
- Vuelve a la consola de Cloud y abre el menú de navegación > Dataflow para ver el estado de tu trabajo.

-
Haz clic en el nombre del trabajo para ver el progreso. Una vez que el Estado del trabajo sea Sin errores, puedes continuar con el siguiente paso. Esta canalización de Dataflow tardará aproximadamente cinco minutos en comenzar, completar el trabajo y, luego, apagarse.
-
Navega a BigQuery (menú de navegación > BigQuery) para verificar si tus datos se propagaron.
- Haz clic en el nombre de tu proyecto para ver la tabla usa_names en el conjunto de datos
lake.

- Haz clic en la tabla y, luego, navega hasta la pestaña Vista previa para ver ejemplos de los datos de
usa_names.
usa_names, actualiza la página o visualiza las tablas en la IU clásica de BigQuery.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada.
Tarea 10: Transforma los datos
Ahora, crearás una canalización de Dataflow con una fuente de TextIO y un destino de BigQueryIO para transferir datos a BigQuery. En específico, harás lo siguiente:
- Transferir los archivos desde Cloud Storage
- Convertir las líneas leídas en objetos del diccionario
- Transformar los datos que contengan el año a un formato que BigQuery entienda como una fecha
- Enviar las filas a BigQuery
Revisa el código de Python de la canalización de transformación
En el editor de código, abre el archivo data_transformation.py. Lee los comentarios en el archivo que explican lo que hace el código.
Tarea 11: Ejecuta la canalización de transformación de Dataflow
Ejecutarás la canalización de Dataflow en la nube. Esto iniciará los trabajadores requeridos y los cerrará cuando el proceso haya finalizado:
- Para hacerlo, ejecuta los siguientes comandos:
-
Navega al menú de navegación > Dataflow y haz clic en el nombre del trabajo para ver su estado. Esta canalización de Dataflow tardará aproximadamente cinco minutos en comenzar, completar el trabajo y, luego, apagarse.
-
Una vez que el Estado del trabajo sea Sin errores en la pantalla de estado del trabajo de Dataflow, navega a BigQuery para verificar que se hayan propagado tus datos.
-
Deberías ver la tabla usa_names_transformed debajo del conjunto de datos
lake. -
Haz clic en la tabla y navega hasta la pestaña Vista previa para ver ejemplos de los datos de
usa_names_transformed.
usa_names_transformed, actualiza la página o visualiza las tablas por medio de la IU clásica de BigQuery.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada.
Tarea 12: Enriquece los datos
Ahora, crearás una canalización de Dataflow con una fuente de TextIO y un destino de BigQueryIO para transferir datos a BigQuery. En específico, harás lo siguiente:
- Transferir los archivos desde Cloud Storage
- Filtrar la fila del encabezado en los archivos
- Convertir las líneas leídas en objetos del diccionario
- Enviar las filas a BigQuery
Tarea 13: Revisa el código de Python de la canalización de enriquecimiento de datos
-
En el Editor de código, abre el archivo
data_enrichment.py. -
Revisa los comentarios que explican lo que está haciendo el código. Este código propagará los datos en BigQuery.
La línea 83 actualmente se ve así:
- Edítala para que se vea así:
- Cuando termines de editar esta línea, recuerda Guardar este archivo actualizado, para ello, selecciona el menú desplegable Archivo del editor y haz clic en Guardar.
Tarea 14: Ejecuta la canalización de Dataflow de enriquecimiento de datos
Aquí ejecutarás la canalización de Dataflow en la nube.
- Ejecuta lo siguiente en Cloud Shell para iniciar los trabajadores necesarios y apagarlos cuando se complete la tarea:
-
Ve al menú de navegación > Dataflow para ver el estado del trabajo. Esta canalización de Dataflow tardará aproximadamente cinco minutos en comenzar, completar el trabajo y, luego, apagarse.
-
Una vez que el Estado del trabajo sea Sin errores en la pantalla de estado del trabajo de Dataflow, navega a BigQuery para verificar que se hayan propagado tus datos.
Deberías ver la tabla usa_names_enriched debajo del conjunto de datos lake.
- Haz clic en la tabla y navega hasta la pestaña Vista previa para ver ejemplos de los datos de
usa_names_enriched.
usa_names_enriched, actualiza la página o visualiza las tablas en la IU clásica de BigQuery.
Prueba la tarea de enriquecimiento de datos completada
Haz clic en Revisar mi progreso para verificar la tarea realizada.
Tarea 15: Data lake a data mart y revisión del código de Python de la canalización
Ahora, crea una canalización de Dataflow que lee los datos de dos fuentes de datos de BigQuery y, luego, une las fuentes de datos. Específicamente, harás lo siguiente:
- Transferir archivos desde dos fuentes de BigQuery
- Unir las dos fuentes de datos
- Filtrar la fila del encabezado en los archivos
- Convertir las líneas leídas en objetos del diccionario
- Enviar las filas a BigQuery
En el Editor de código, abre el archivo data_lake_to_mart.py. Lee los comentarios en el archivo que explican lo que hace el código. Este código unirá dos tablas y propagará los datos resultantes en BigQuery.
Tarea 16: Ejecuta la canalización de Apache Beam para realizar la unión de datos y crear la tabla resultante en BigQuery
Ahora, ejecuta la canalización de Dataflow en la nube.
- Ejecuta el siguiente bloque de código en Cloud Shell para iniciar los trabajadores necesarios y apagarlos cuando se complete la tarea:
-
Navega al menú de navegación > Dataflow y haz clic en el nombre de este nuevo trabajo para ver el estado. Esta canalización de Dataflow tardará aproximadamente cinco minutos en comenzar, completar el trabajo y, luego, apagarse.
-
Una vez que el Estado del trabajo sea Sin errores en la pantalla de estado del trabajo de Dataflow, navega a BigQuery para verificar que se hayan propagado tus datos.
Deberías ver la tabla orders_denormalized_sideinput debajo del conjunto de datos lake.
- Haz clic en la tabla y navega a la sección Vista previa para ver ejemplos de datos de
orders_denormalized_sideinput.
orders_denormalized_sideinput, actualiza la página o visualiza las tablas en la IU clásica de BigQuery.
Prueba la tarea de UNIÓN completada
Haz clic en Revisar mi progreso para verificar la tarea realizada.
Pon a prueba tus conocimientos
A continuación, se presentan algunas preguntas de opción múltiple para reforzar tus conocimientos de los conceptos de este lab. Trata de responderlas lo mejor posible.
¡Felicitaciones!
Ejecutaste código de Python con Dataflow para transferir datos a BigQuery y transformarlos.
Próximos pasos y más información
Si buscas más información, consulta la siguiente documentación oficial:
- Dataflow
- BigQuery
- Revisa la Guía de programación de Apache Beam si quieres consultar conceptos más avanzados.
- Consulta los siguientes labs:
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 11 de febrero de 2024
Prueba más reciente del lab: 12 de octubre de 2023
Copyright 2024 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.

