检查点
Create a dataset named 'ecommerce'
/ 30
Create a new partitioned table based on date.
/ 35
Your turn: Create a Partitioned Table
/ 35
在 BigQuery 中创建日期分区表
GSP414

概览
BigQuery 是 Google 推出的全托管式、无需运维、费用低廉的分析数据库。 借助 BigQuery,您可以查询 TB 级的数据,而不必管理任何基础设施,也无需数据库管理员。BigQuery 使用 SQL,并且支持随用随付模式。BigQuery 让您可以专心分析数据,发掘有意义的数据洞见。
在本实验中,您将学习如何在 BigQuery 中查询和创建分区表,以提高查询性能并减少资源用量。本实验中使用的数据来自一个电子商务数据集,其中包含 Google Merchandise Store 的上百万条 Google Analytics 记录,并且已加载到 BigQuery。
您将执行的操作
在本实验中,您将学习如何完成以下操作:
- 查询分区表。
- 创建您自己的分区表。
设置和要求
点击“开始实验”按钮前的注意事项
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。我们会为您提供新的临时凭据,让您可以在实验规定的时间内用来登录和访问 Google Cloud。
为完成此实验,您需要:
- 能够使用标准的互联网浏览器(建议使用 Chrome 浏览器)。
- 完成实验的时间 - 请注意,实验开始后无法暂停。
如何开始实验并登录 Google Cloud 控制台
-
点击开始实验按钮。如果该实验需要付费,系统会打开一个弹出式窗口供您选择付款方式。左侧是实验详细信息面板,其中包含以下各项:
- 打开 Google Cloud 控制台按钮
- 剩余时间
- 进行该实验时必须使用的临时凭据
- 帮助您逐步完成本实验所需的其他信息(如果需要)
-
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示登录页面。
提示:请将这些标签页安排在不同的窗口中,并将它们并排显示。
注意:如果您看见选择账号对话框,请点击使用其他账号。 -
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
{{{user_0.username | "<用户名>"}}} 您也可以在实验详细信息面板中找到用户名。
-
点击下一步。
-
复制下面的密码,然后将其粘贴到欢迎对话框中。
{{{user_0.password | "<密码>"}}} 您也可以在实验详细信息面板中找到密码。
-
点击下一步。
重要提示:您必须使用实验提供的凭据。请勿使用您的 Google Cloud 账号凭据。 注意:在本次实验中使用您自己的 Google Cloud 账号可能会产生额外费用。 -
继续在后续页面中点击以完成相应操作:
- 接受条款及条件。
- 由于该账号为临时账号,请勿添加账号恢复选项或双重验证。
- 请勿注册免费试用。
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

打开 BigQuery 控制台
- 在 Google Cloud 控制台中,选择导航菜单 > BigQuery。
您会看到欢迎在 Cloud 控制台中使用 BigQuery 消息框,其中提供了指向快速入门指南和版本说明的链接。
- 点击完成。
BigQuery 控制台即会打开。
任务 1. 创建新数据集
-
首先,您需要创建一个数据集来存储表。
-
在“探索器”窗格中,点击项目 ID 旁边的查看操作,然后点击创建数据集。
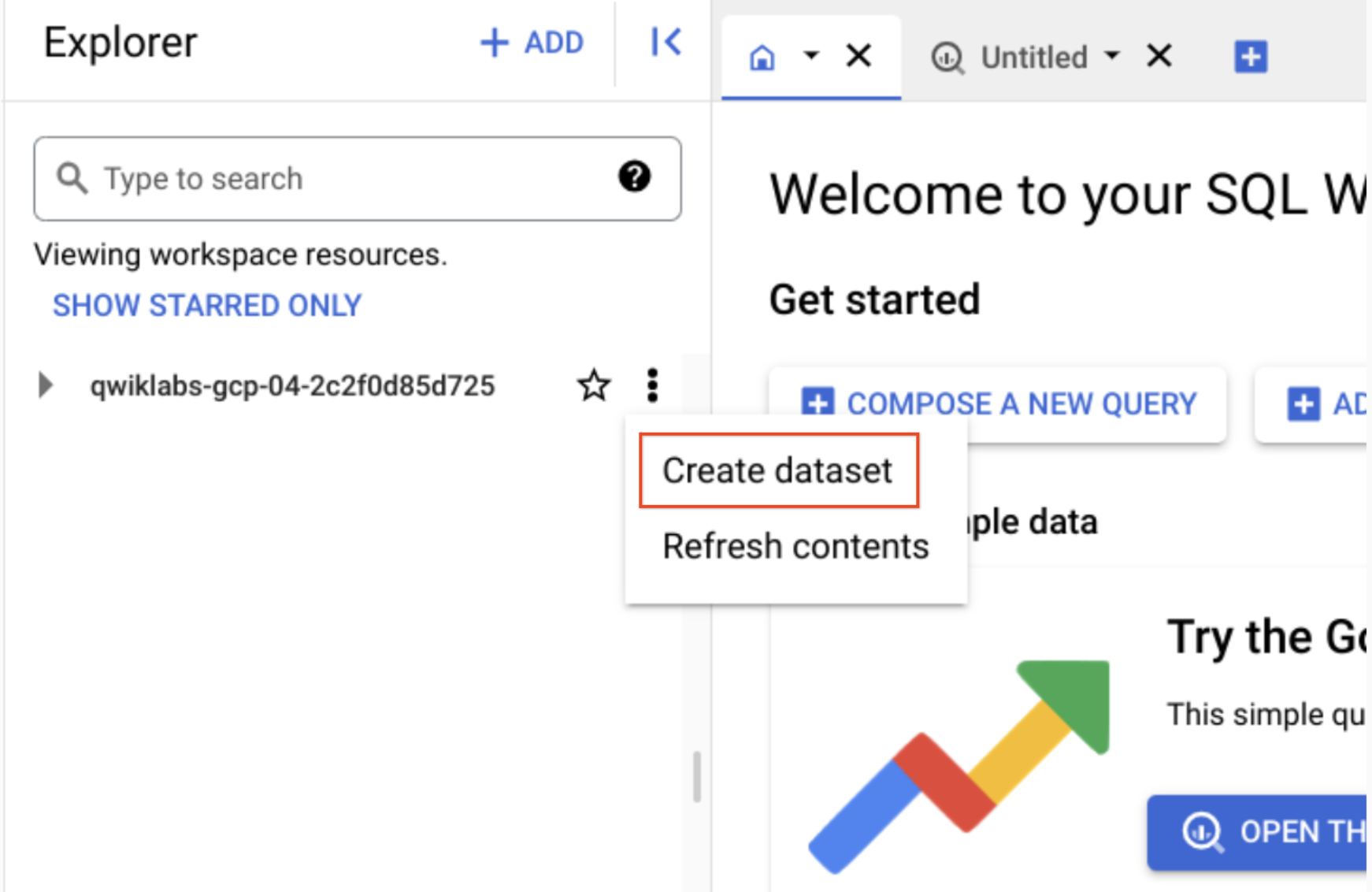
- 将数据集 ID 设置为 ecommerce。
将其他选项保留为各自的默认值(数据位置、默认表到期时间)。
- 点击创建数据集。
点击检查我的进度,验证已完成以下目标:
任务 2. 创建表及日期分区
分区表是一种划分成多个区段(称为分区)的表,可让您更轻松地管理和查询数据。您可以将大型表划分为较小的分区,以提高查询性能,并通过减少查询读取的字节数来控制费用。
现在来创建一个新表,并将日期列或时间戳列绑定为一个分区。但在此之前,先来研究一下非分区表中的数据。
查询 2017 年访问者样本的网页分析
- 点击 + 编写新查询并添加下面的查询:
运行之前,请留意查询验证器图标旁边会指明将处理的数据总量:“本次查询在运行时将处理 1.74 GB 的数据”。
- 点击运行。
查询返回 5 个结果。
查询 2018 年访问者样本的网页分析
现在我们修改一下查询,看看 2018 年的访问者情况。
- 点击编写新查询以清空查询编辑器,然后添加此新查询。请注意
WHERE date参数已更改为20180708:
查询验证器将指明本次查询将处理的数据量。
- 点击运行。
请注意,虽然本次查询返回了 0 个结果,但是它仍然处理了 1.74 GB 的数据。为什么会这样?查询引擎需要扫描数据集中的所有记录,才能确定它们是否符合 WHERE 子句中的日期匹配条件。它必须查看每一条记录,以将相应的日期与条件“20180708”进行比较。
此外,LIMIT 5 并不会减少处理的数据总量,这只是一个常见的误解。
日期分区表的常见应用场景
每次都扫描整个数据集并将所有行与 WHERE 条件进行比较,这无疑很浪费时间。特别是您只关心特定时间段的记录时,例如:
- 去年的所有交易
- 过去 7 天内的所有访问者互动
- 上个月售出的所有商品
现在,我们只需要设置一个日期分区表,就不必像之前的查询一样扫描整个数据集并按日期字段进行过滤。这样,您就可以完全忽略掉与查询无关的某些分区中的扫描记录。
创建基于日期的新分区表
- 点击编写新查询并添加下面的查询,然后点击运行:
在此查询中,请留意新选项“PARTITION BY”字段。两个可供选择的分区选项是 DATE 和 TIMESTAMP。PARSE_DATE 函数用于日期字段(存储为字符串)中,通过它来获取用于分区的正确 DATE 类型。
- 点击 ecommerce 数据集,然后选择新表 partiton_by_day:
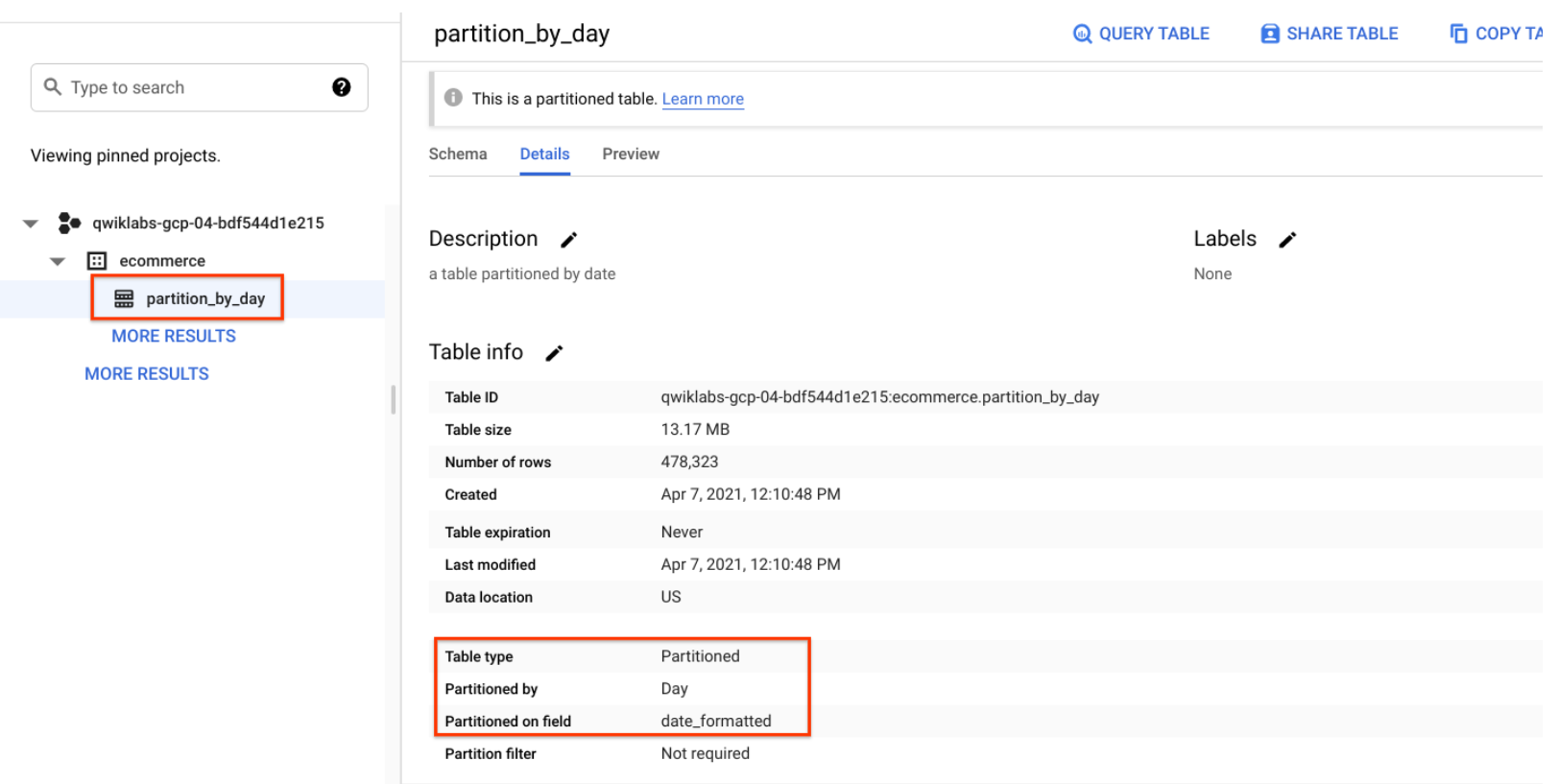
- 点击详情标签页。
确认您看到的信息如下:
- 分区依据:Day
- 分区日期:date_formatted
点击检查我的进度,验证已完成以下目标:
任务 3. 查看分区表的查询结果
- 请运行下面的查询,并留意要处理的总字节数:
这次处理的数据量是 25 KB(即 0.025MB),只是之前查询的数据量的一小部分。
- 现在运行下面的查询,并留意要处理的总字节数:
您应该会看到这样的信息:This query will process 0 B when run(本次查询运行时将处理 0 B 的数据)。
任务 4. 创建自动到期的分区表
自动到期的分区表可帮助您遵守相关数据隐私保护法规,并避免进行不必要的存储(在生产环境中可能需要付费)。如果您想为数据创建滚动窗口,可以添加一个到期日期,以便在您使用完分区后,它就会消失。
浏览可用的 NOAA 天气数据表
- 在左侧菜单中,点击探索器中的 + 添加,然后选择公共数据集。
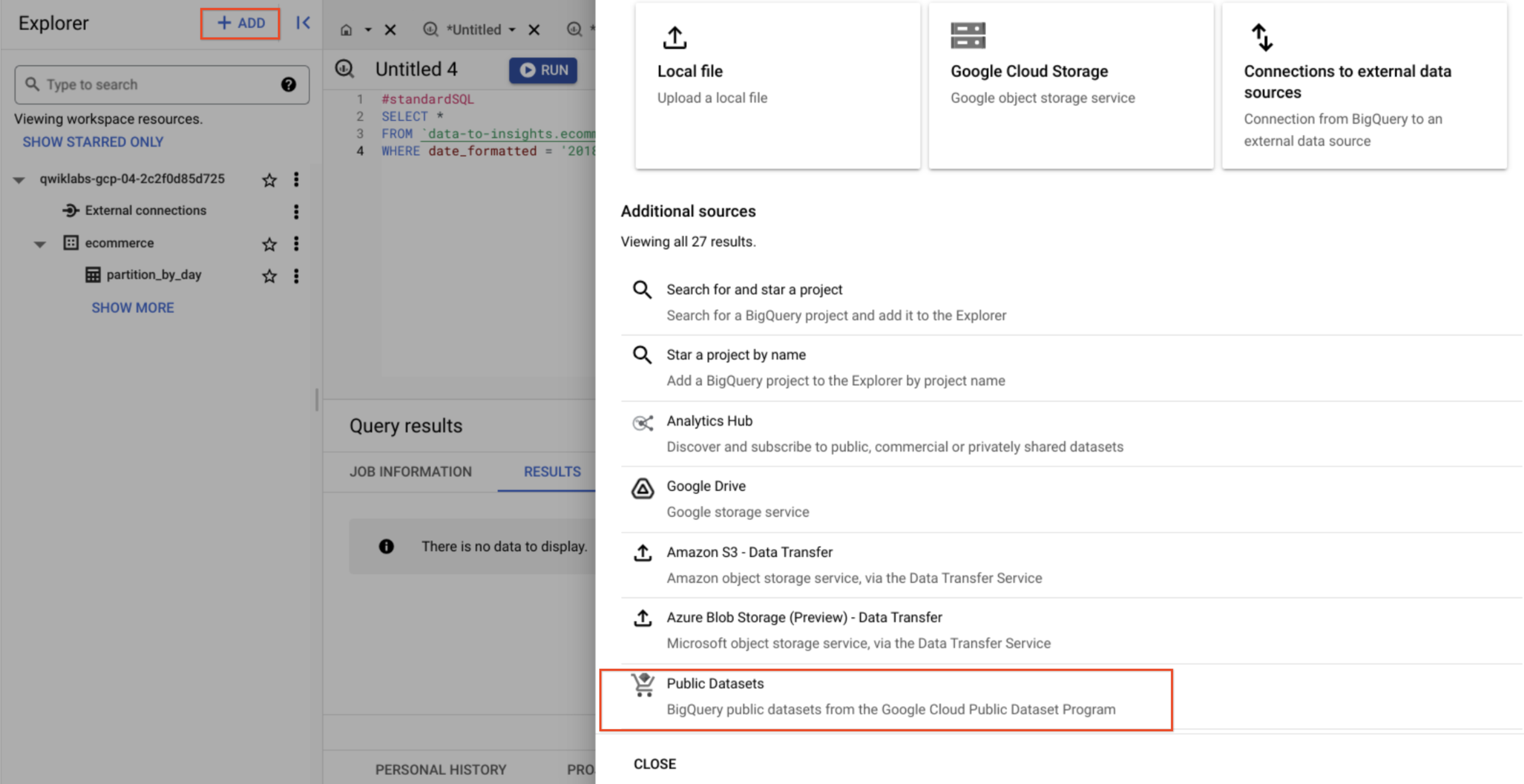
-
搜索 GSOD NOAA,然后选择相应的数据集。
-
点击查看数据集。
-
滚动浏览 noaa_gsod 数据集中的表(已手动分片且未分区):
您的目标是创建一个符合以下条件的表:
- 查询 2018 年往后的天气数据
- 过滤后仅包含具有各类降水(雨雪等)情况的日期
- 仅存储从该分区创建之日起 90 天(滚动窗口)内的各个数据分区
- 首先,复制和粘贴下面的查询:
-
点击运行。
-
确认日期格式正确无误,并且降水量字段显示的是非零值。
任务 5. 您的任务:创建分区表
-
修改上一个查询,以创建一个符合以下指定条件的表:
- 表名:ecommerce.days_with_rain
- 对于 PARTITION BY,使用日期字段
- 对于 OPTIONS,指定 partition_expiration_days = 60
- 添加表说明“weather stations with precipitation, partitioned by day”
您的查询应如下所示:
点击检查我的进度,验证已完成以下目标:
确认数据分区到期时间正常生效
为确认您只存储了过去 60 天到今天的数据,请运行 DATE_DIFF 查询来获取分区的存在时间,这些分区设置为 60 天后到期。
下面的查询跟踪了 NOAA 气象台记录的日本和歌山县的平均降雨量,该县具有较多的降水。
- 添加并运行此查询:
任务 6. 确认最早的分区存在时间等于或少于 60 天
更新 ORDER BY 子句以先显示最早的分区。
- 添加并运行此查询:
恭喜!
您已经在 BigQuery 中成功创建和查询了分区表。
后续步骤/了解详情
- 如果您想了解如何创建不绑定特定日期列或时间戳列的注入时间分区表,请查阅 BigQuery 分区文档及相关示例。
- 已拥有 Google Analytics 账号,想要在 BigQuery 中查询您自己的数据集?请按照此导出指南中的说明操作。
- 查看下面的其他 BigQuery 实验:
Google Cloud 培训和认证
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
上次更新手册的时间:2024 年 2 月 3 日
上次测试实验的时间:2024 年 1 月 1 日
版权所有 2024 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。

