チェックポイント
Create the connection resource
/ 20
Set up access to a Cloud Storage data lake
/ 30
Create the BigLake table
/ 20
Create the external table
/ 10
Update external table to Biglake table
/ 20
BigLake: Qwik Start
GSP1040

概要
BigLake は、データ ウェアハウスとデータレイクのデータアクセスを簡素化する統合ストレージ エンジンです。マルチクラウド ストレージとオープン フォーマット全体に対し、一貫した詳細なアクセス制御を行えます。
BigLake により、BigQuery の行レベル、および列レベルのきめ細かいセキュリティが、データが所在するオブジェクト ストア(Amazon S3、Azure Data Lake Storage Gen2、Google Cloud Storage など)のテーブルにも適用されます。アクセス権の委任を介して、テーブルへのアクセスが基盤となるクラウド ストレージ データから切り離されます。この機能を利用することで、組織内のユーザーやパイプラインに対して、テーブル全体へのアクセス権を与えるのではなく、行および列レベルのアクセス権を安全に付与できます。
BigLake テーブルを作成し終えたら、そのテーブルに対して他の BigQuery テーブルと同じようにクエリを実行できます。BigQuery では行および列レベルでのアクセス制御が適用されており、各ユーザーは自身にアクセス権があるデータのみを見ることができるようになっています。BigQuery API を介したデータアクセスのすべてにガバナンス ポリシーが適用されます。たとえば、BigQuery Storage API を使用すると、Apache Spark のようなオープンソースのクエリエンジンを使って、自身にアクセス権があるデータにアクセスできます。以下に図解します。

目標
このラボでは、次の作業を行います。
- 接続リソースを作成して表示する。
- Cloud Storage データレイクへのアクセス権を設定する。
- BigLake テーブルを作成する。
- BigQuery を介して BigLake テーブルにクエリを実行する。
- アクセス制御ポリシーを設定する。
- 外部テーブルを BigLake テーブルにアップグレードする。
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google Cloud コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウでリンクを開く] を選択します)。
ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
{{{user_0.username | "Username"}}} [ラボの詳細] パネルでも [ユーザー名] を確認できます。
-
[次へ] をクリックします。
-
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
{{{user_0.password | "Password"}}} [ラボの詳細] パネルでも [パスワード] を確認できます。
-
[次へ] をクリックします。
重要: ラボで提供された認証情報を使用する必要があります。Google Cloud アカウントの認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後、このタブで Google Cloud コンソールが開きます。

Cloud Shell をアクティブにする
Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
- Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン
をクリックします。
接続した時点で認証が完了しており、プロジェクトに各自の PROJECT_ID が設定されます。出力には、このセッションの PROJECT_ID を宣言する次の行が含まれています。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
- (省略可)次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
-
[承認] をクリックします。
-
出力は次のようになります。
出力:
- (省略可)次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
出力:
出力例:
gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
タスク 1. 接続リソースを作成する
BigLake テーブルは接続リソースを使って Google Cloud Storage にアクセスします。接続リソースはプロジェクト内の 1 つの特定のテーブル、または任意の複数のテーブルに関連付けることができます。
-
ナビゲーション メニューから、[BigQuery] > [BigQuery Studio] にアクセスします。[完了] をクリックします。
-
接続を作成するには、[+ 追加]、[外部データソースへの接続] の順にクリックします。
- [接続タイプ] リストで、[Vertex AI リモートモデル、リモート関数、BigLake(Cloud リソース)] を選択します。
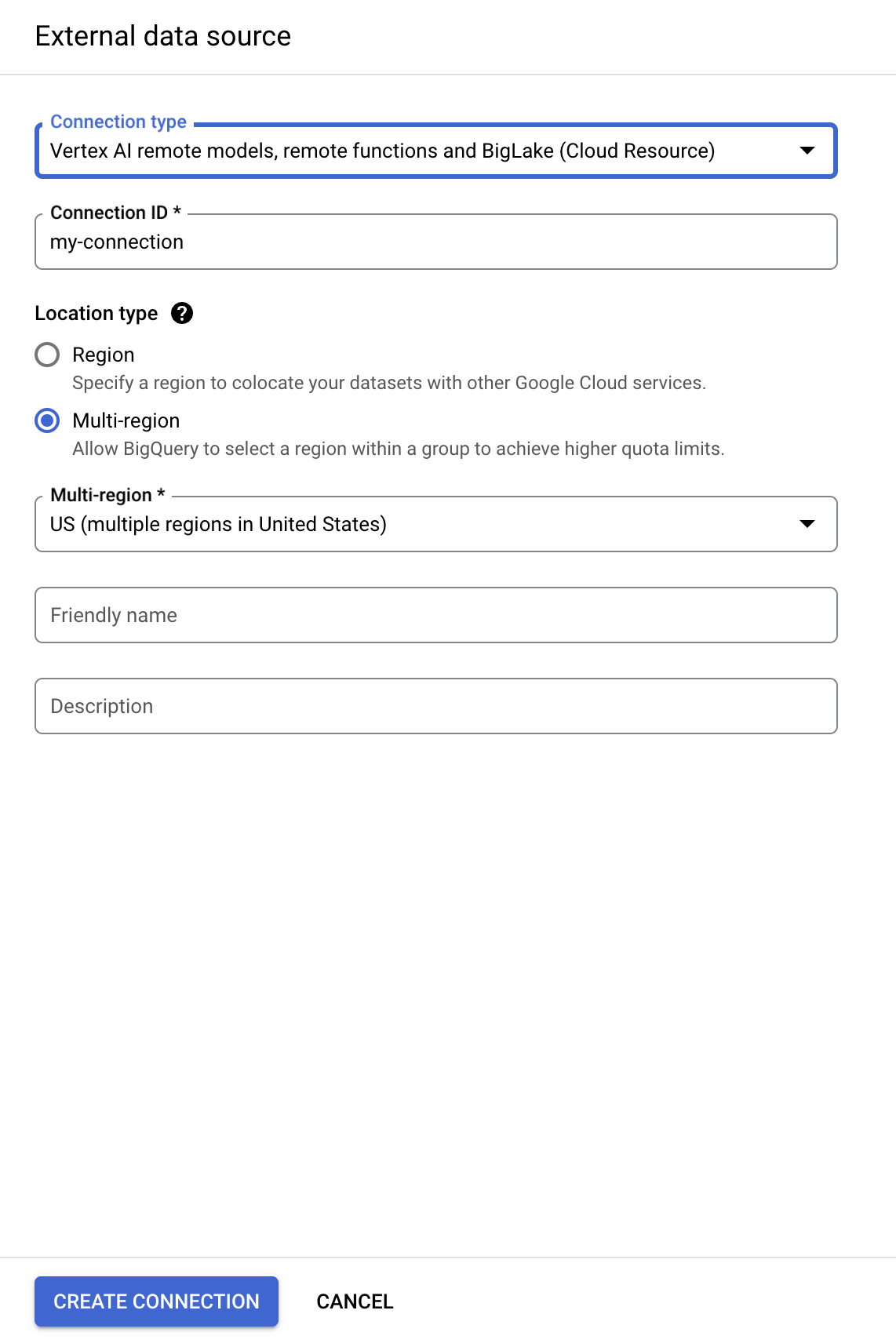
-
[接続 ID] に「
my-connection」と入力します。 -
[ロケーション タイプ] で [マルチリージョン] を選択し、プルダウンから [US(米国の複数のリージョン)] を選択します。
-
[接続を作成] をクリックします。
-
作成した接続の情報を確認するには、ナビゲーション メニューでその接続を選択します。
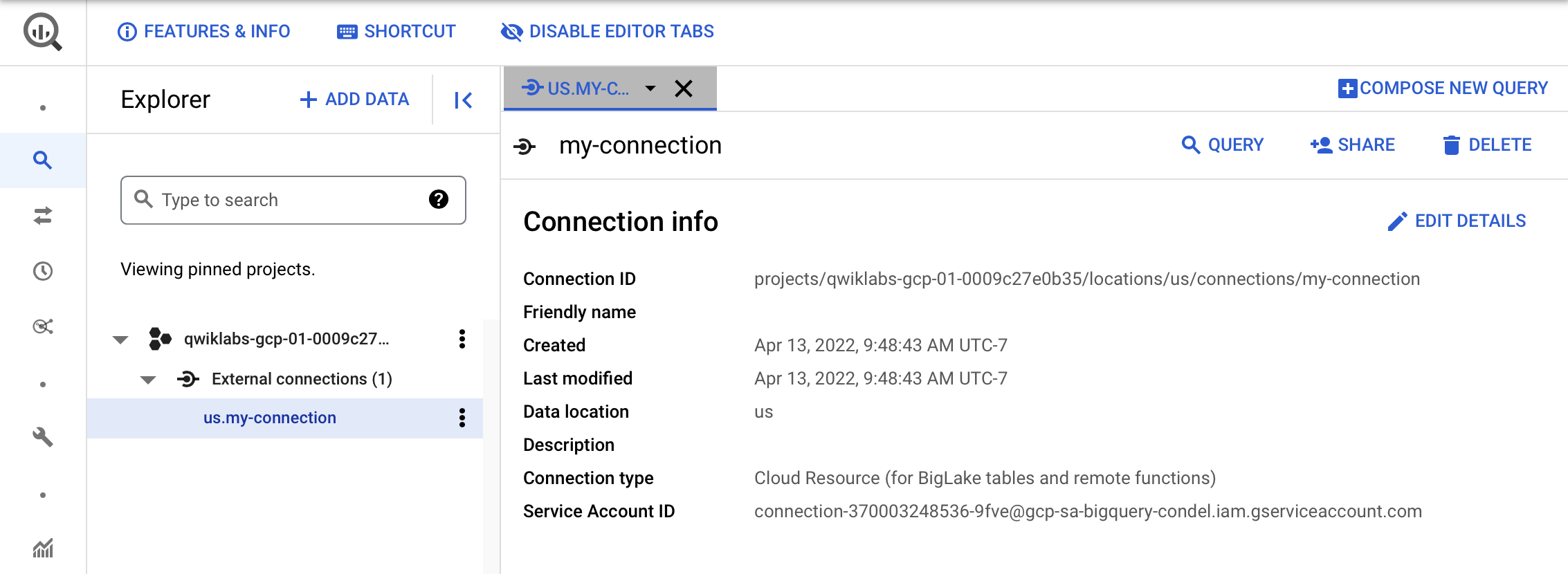
- [接続情報] でサービス アカウント ID をコピーします。この情報は後で必要になります。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 2. Cloud Storage データレイクへのアクセス権を設定する
このセクションでは、新しい接続リソースに Cloud Storage データレイクへの読み取り専用アクセス権を付与します。これにより、BigQuery がユーザーに代わって Cloud Storage ファイルにアクセスできるようになります。接続リソース サービス アカウントに Storage オブジェクト閲覧者の IAM ロールを付与することをおすすめします。これにより、サービス アカウントが Cloud Storage バケットにアクセスできるようになります。
-
ナビゲーション メニューから、[IAM と管理] > [IAM] にアクセスします。
-
[+ アクセス権を付与] をクリックします。
-
[新しいプリンシパル] フィールドに、前の手順でコピーしたサービス アカウント ID を入力します。
-
[ロールを選択] フィールドで、[Cloud Storage]、[Storage オブジェクト閲覧者] の順に選択します。
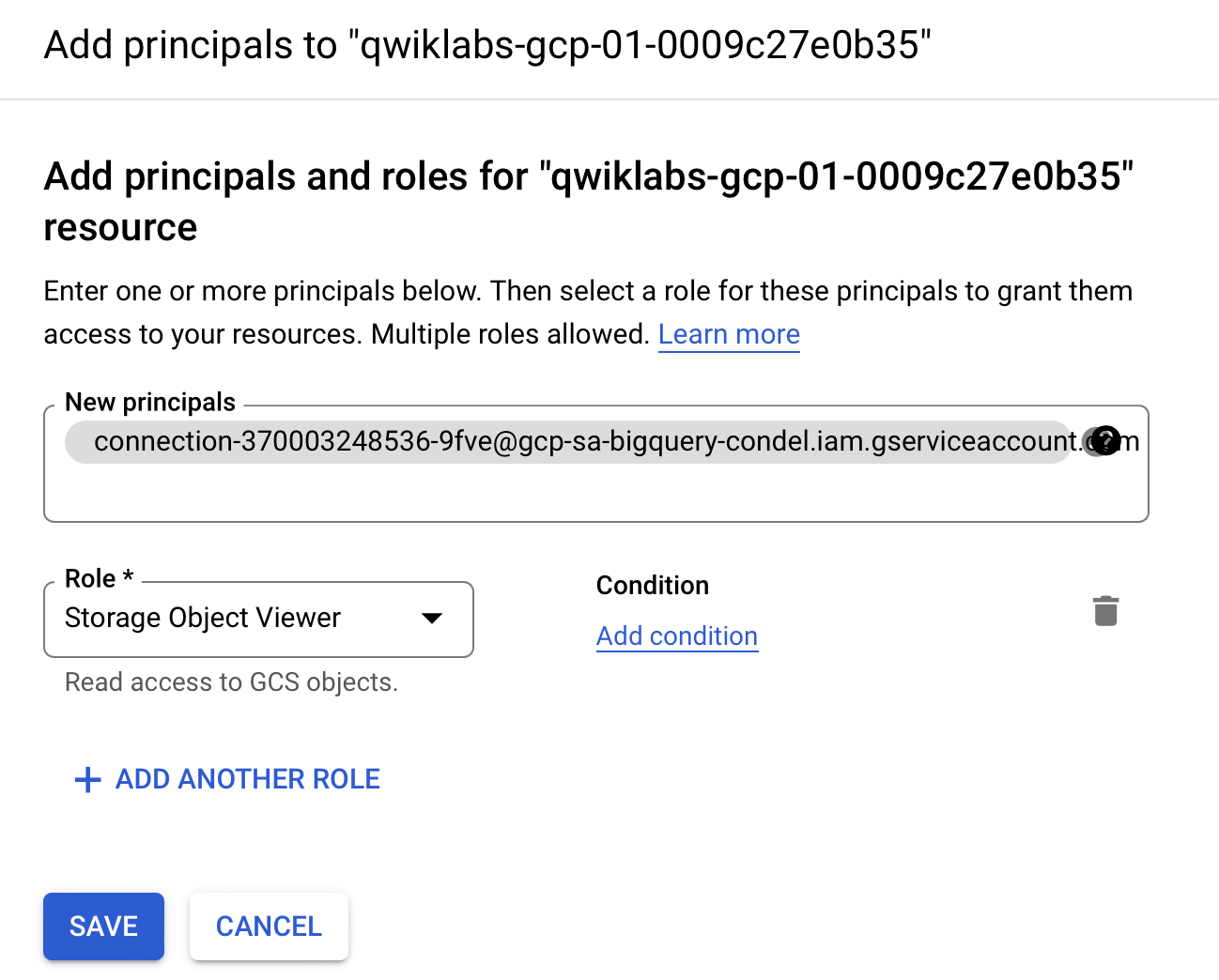
- [保存] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 3. BigLake テーブルを作成する
以下の例では CSV ファイル形式を使用していますが、制限事項に記載されているとおり、BigLake でサポートされているものであればどの形式でも使用可能です。BigQuery でのテーブルの作成に慣れている方であれば、ここでのプロセスも同様に行えます。唯一の違いとして、ここでは関連するクラウド リソースの接続を指定します。
前のステップでスキーマを指定しておらず、サービス アカウントにバケットへのアクセス権を付与していなかった場合、このステップは失敗してアクセス拒否のメッセージが通知されます。
データセットを作成する
-
再び [BigQuery] > [BigQuery Studio] にアクセスします。
-
プロジェクト名の隣にある 3 つの点をクリックし、[データセットを作成] を選択します。
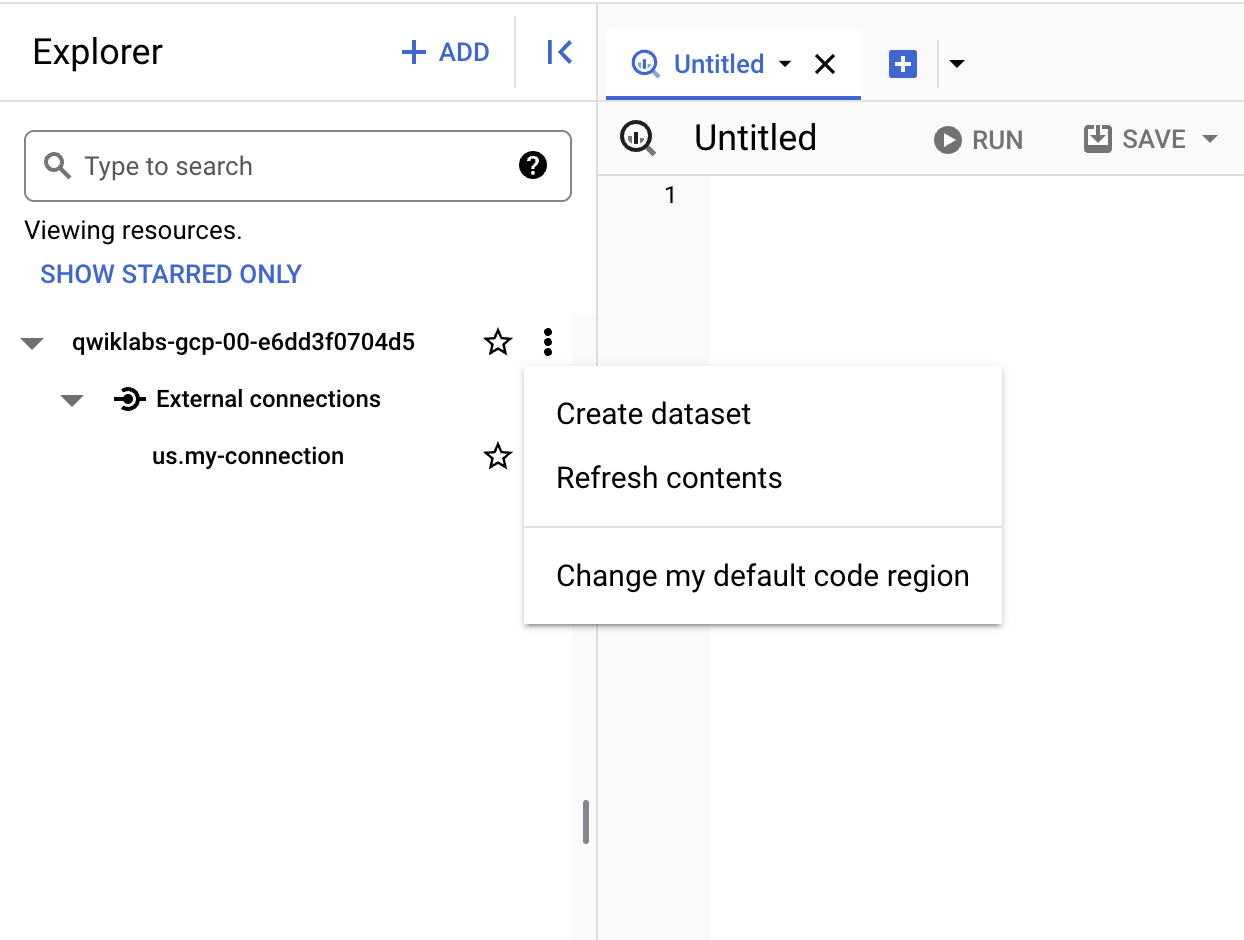
-
[データセット ID] には「
demo_dataset」と入力します。 -
[ロケーション タイプ] で [マルチリージョン] を選択し、プルダウンから [US(米国の複数のリージョン)] を選択します。
-
その他の項目はデフォルトのままにし、[データセットを作成] をクリックします。
データセットの作成を終えたら、既存のデータセットを Cloud Storage から BigQuery にコピーできるようになります。
テーブルを作成する
- [demo_dataset] の隣にある 3 つの点をクリックし、[テーブルを作成] をクリックします。
- [ソース] の [テーブルの作成元] で、[Google Cloud Storage] を選択します。
-
[参照] をクリックしてデータセットを選択します。[
] という名前のバケットに移動し、その中の customer.csvファイルを BigQuery にインポートするために選択して [選択] をクリックします。 -
[送信先] で、正しいラボ プロジェクトを選択していて、demo_dataset を使用していることを確認します。
-
テーブル名には「
biglake_table」を使用します。 -
[テーブルタイプ] を [外部テーブル] に変更します。
-
[Cloud リソース接続を使用して BigLake テーブルを作成する] チェックボックスをオンにします。
接続 ID として [us.my-connection] が選択されていることを確認します。構成は次のようになります。

- [スキーマ] で [テキストとして編集] を有効にし、次のスキーマをコピーしてテキスト ボックスに貼り付けます。
- [テーブルを作成] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 4. BigQuery を介して BigLake テーブルにクエリを実行する
BigLake テーブルを作成し終えたら、任意の BigQuery クライアントを使ってクエリを送信できるようになります。
-
biglake_table のプレビュー ツールバーから、[クエリ] > [新しいタブ] をクリックします。
-
次のコマンドを実行し、BigQuery エディタを介して BigLake テーブルにクエリを実行します。
-
[実行] をクリックします。
-
結果のテーブルにすべての列とデータが表示されていることを確認します。
タスク 5. アクセス制御ポリシーを設定する
作成した BigLake テーブルは、BigQuery テーブルと同様の方法で管理できます。BigLake テーブルのアクセス制御ポリシーを作成するには、まず BigQuery でポリシータグの分類体系を設定します。次に、そのポリシータグを機密性の高い行または列に適用します。このセクションでは、列レベルのポリシーを作成します。行レベルのセキュリティの設定方法については、行レベルのセキュリティ ガイドをご覧ください。
これらの目的のために、
ポリシータグを列に追加する
ここでは、作成したポリシータグを使用して、BigQuery テーブル内の特定の列へのアクセスを制限します。この例では、住所、郵便番号、電話番号といった機密情報へのアクセスを制限します。
-
ナビゲーション メニューから、[BigQuery] > [BigQuery Studio] にアクセスします。
-
[demo-dataset] > [biglake_table] に移動し、テーブルをクリックしてテーブルのスキーマページを開きます。
-
[スキーマを編集] をクリックします。
-
[address]、[postal_code]、[phone] の隣にあるチェックボックスをオンにします。
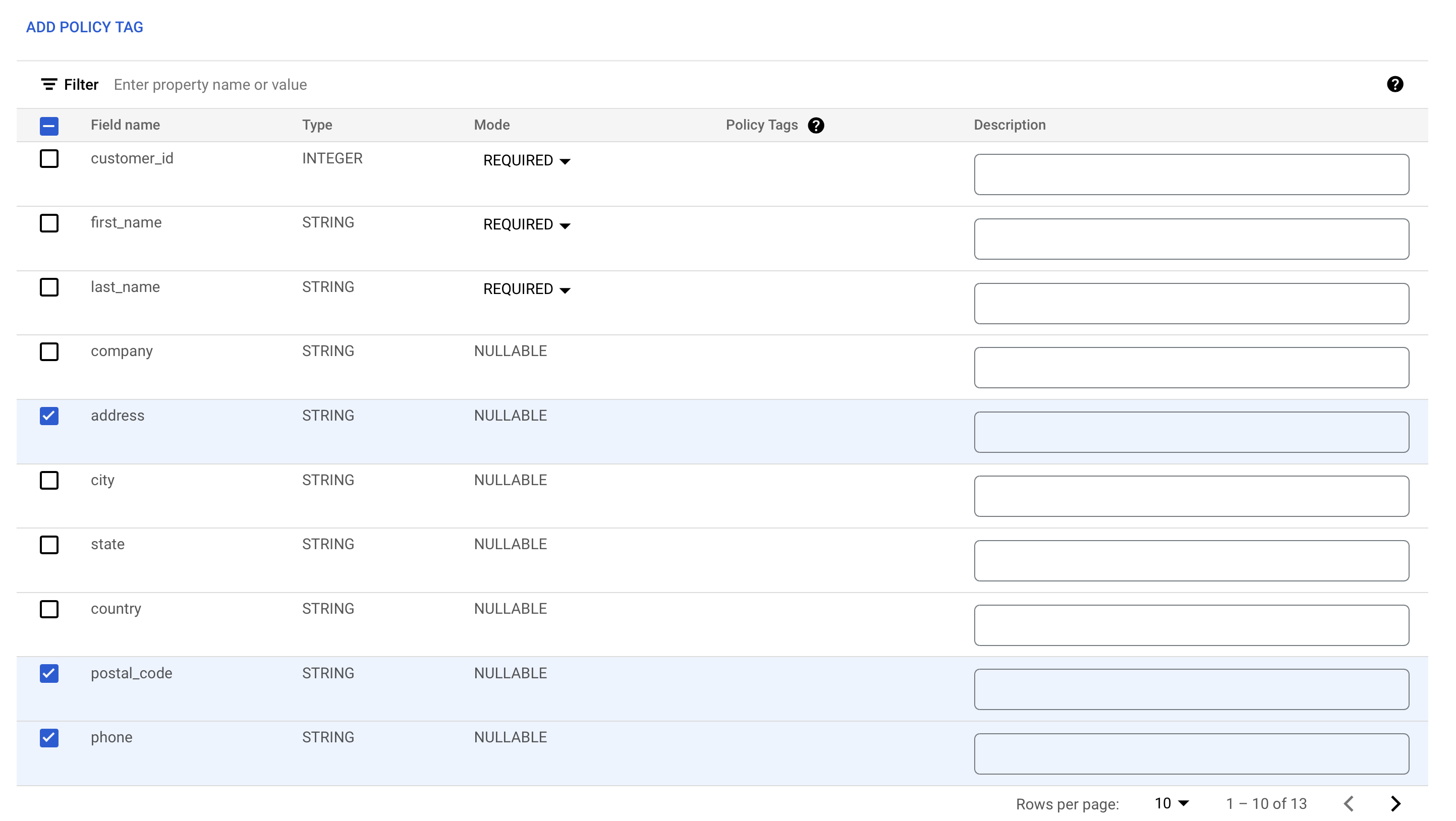
-
[ポリシータグを追加] をクリックします。
-
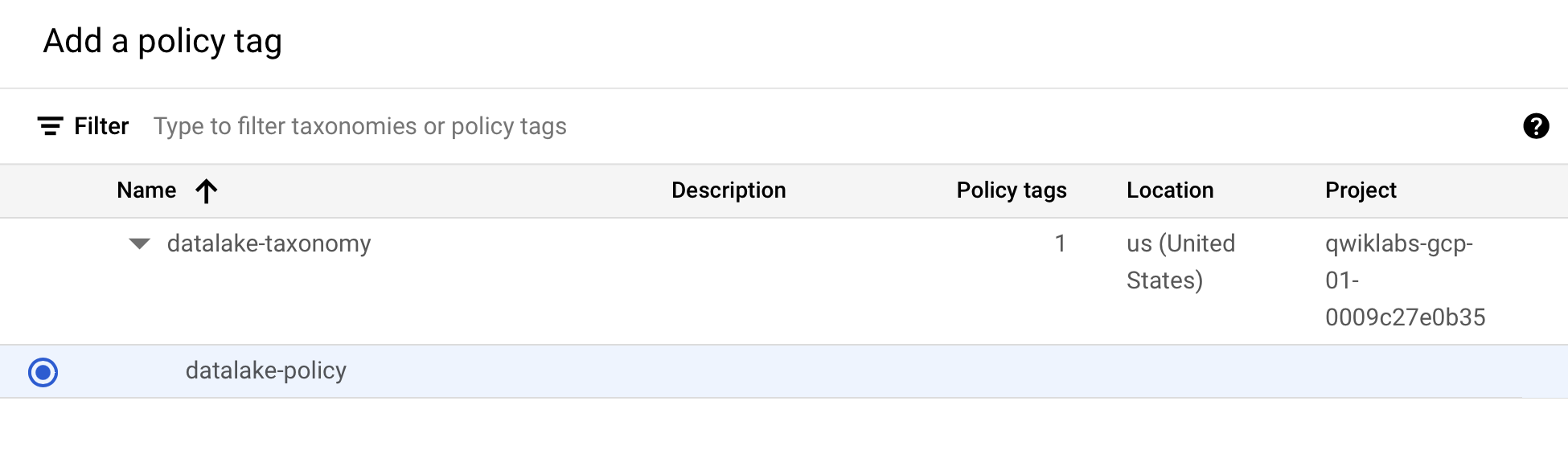
[
] をクリックして開き、[biglake-policy.] を選択します。
-
[選択] をクリックします。
列にポリシータグが付いたはずです。
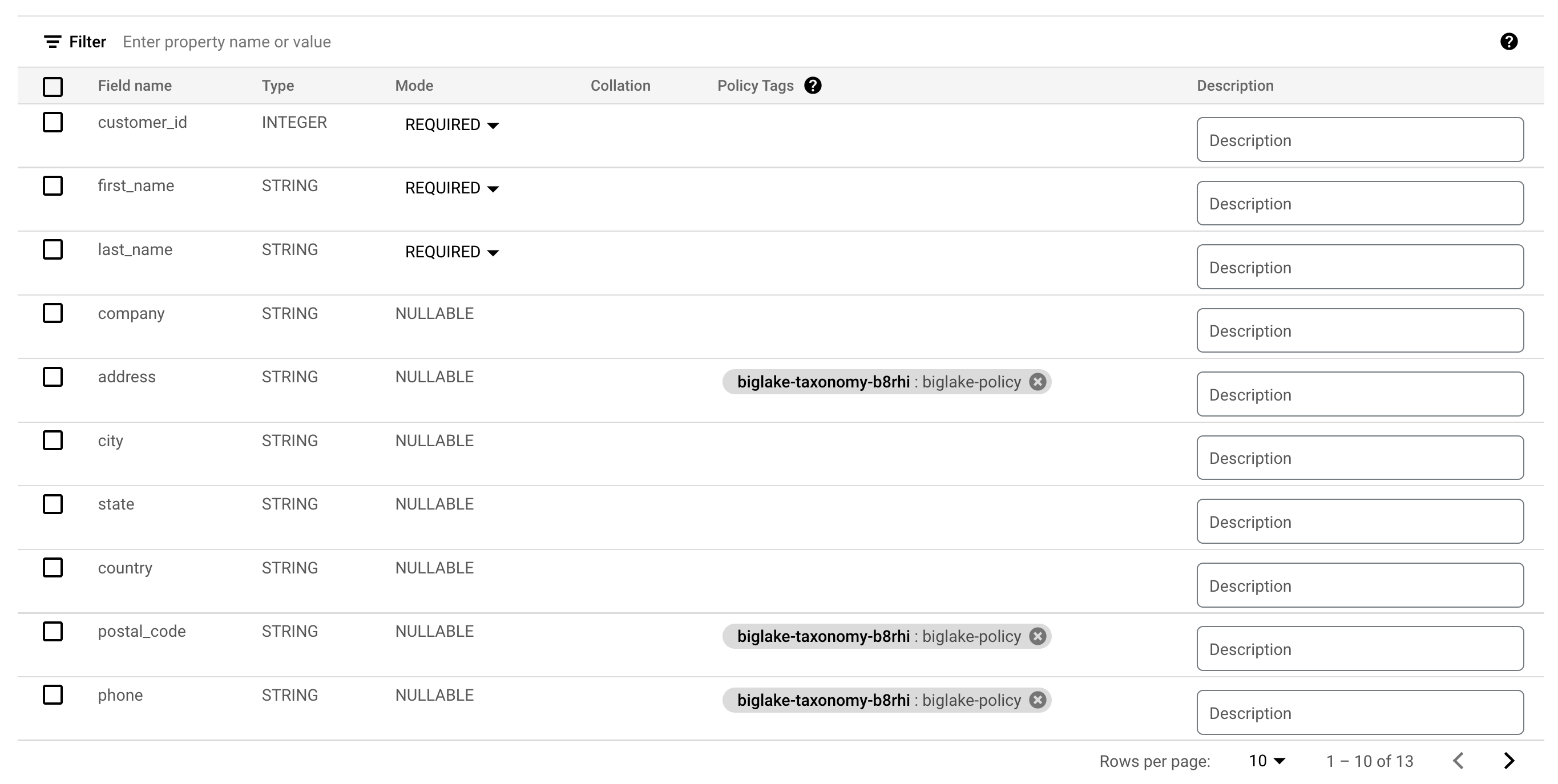
-
[保存] をクリックします。
-
テーブル スキーマが以下のようになっていることを確認します。
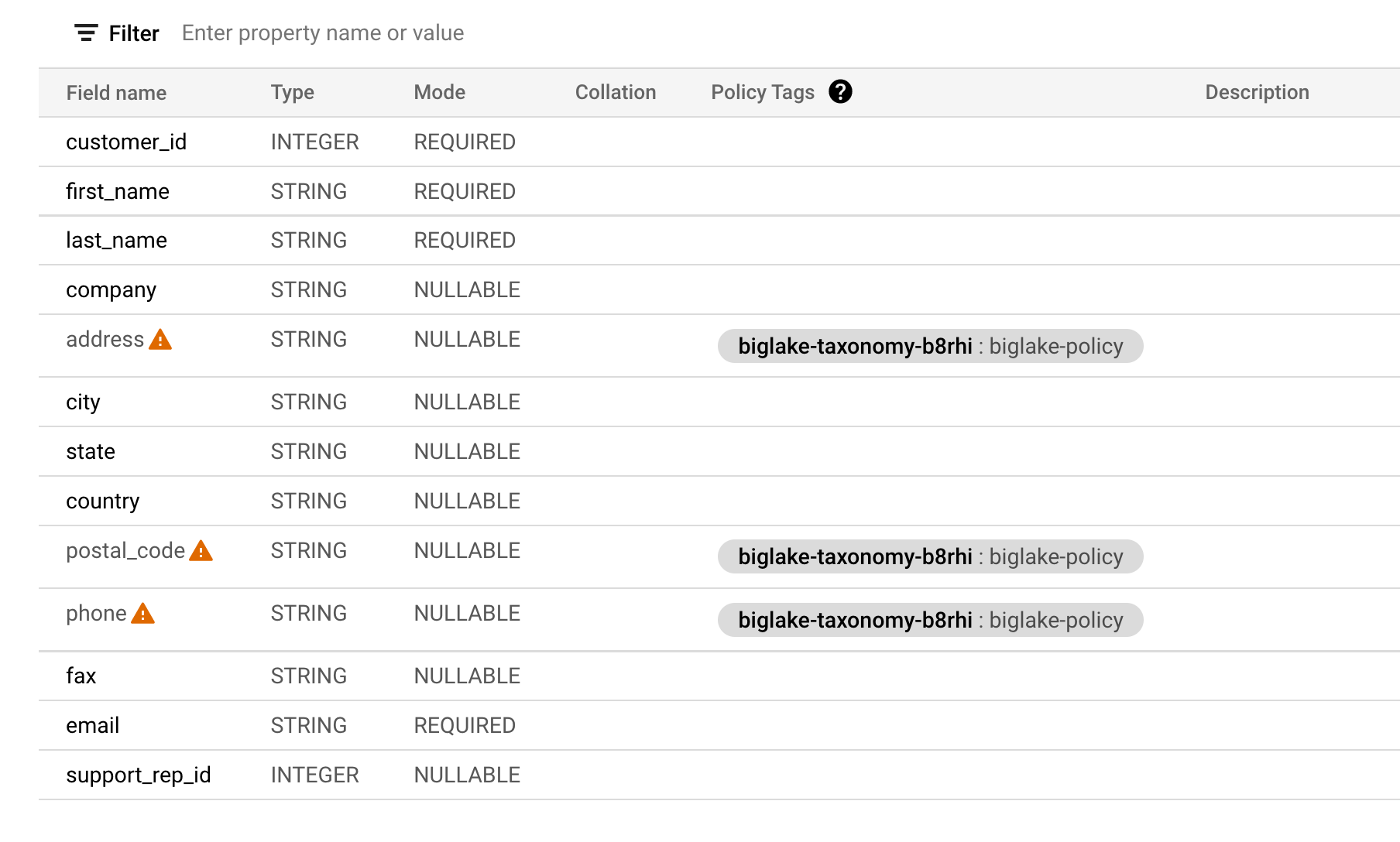
列レベルのセキュリティを確認する
-
biglake_table のクエリエディタを開きます。
-
次のコマンドを実行し、BigQuery エディタを介して BigLake テーブルにクエリを実行します。
-
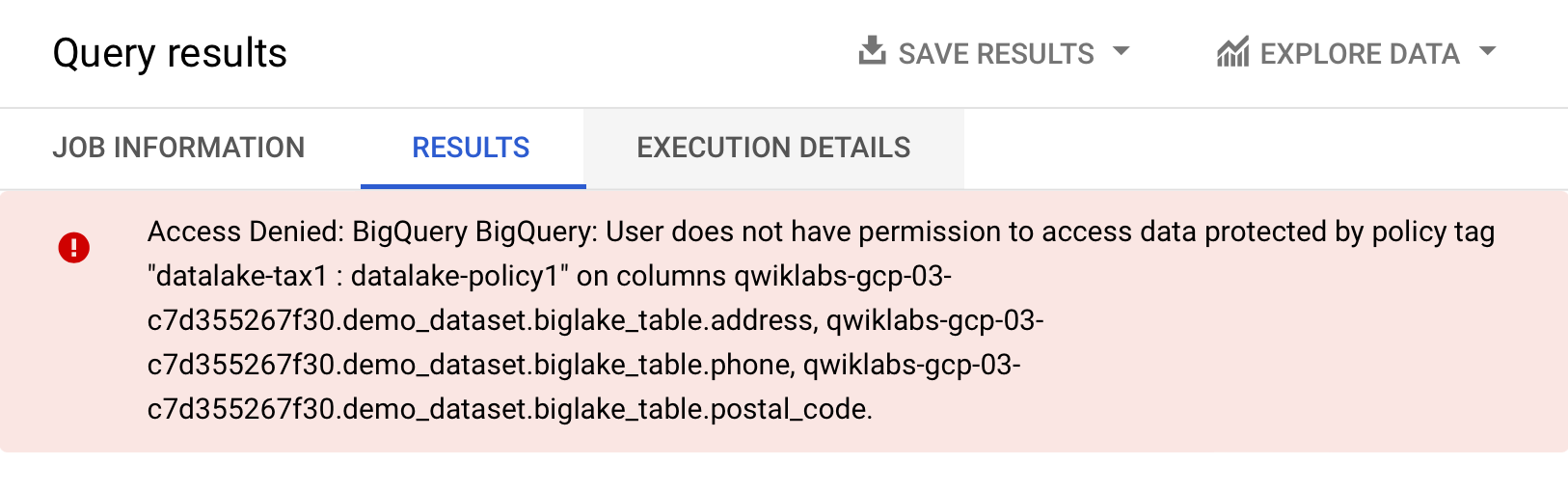
[実行] をクリックします。
アクセス拒否のエラーが通知されるはずです。
- 今度は次のクエリ(アクセス権のない列を除外しているもの)を実行します。
今回のクエリは問題なく実行され、アクセス権のある列が返されるはずです。この例は、BigQuery を介して適用される列レベルのセキュリティを、BigLake テーブルにも適用できることを示しています。
タスク 6. 外部テーブルを BigLake テーブルにアップグレードする
既存のテーブルをクラウド リソース接続に関連付けることによって、既存のテーブルを BigLake テーブルにアップグレードできます。フラグと引数の全一覧については、bq update と bq mkdef をご覧ください。
外部テーブルを作成する
-
[demo_dataset] の隣にある 3 つの点をクリックし、[テーブルを作成] をクリックします。
-
[ソース] の [テーブルの作成元] で、[Google Cloud Storage] を選択します。
-
[参照] をクリックしてデータセットを選択します。[
] という名前のバケットに移動し、その中の invoice.csvファイルを BigQuery にインポートするために選択して [選択] をクリックします。 -
[送信先] で、正しいラボ プロジェクトを選択していて、demo_dataset を使用していることを確認します。
-
テーブル名には「
external_table」を使用します。 -
[テーブルタイプ] を [外部テーブル] に変更します。
- [スキーマ] で [テキストとして編集] を有効にし、次のスキーマをコピーしてテキスト ボックスに貼り付けます。
- [テーブルを作成] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
外部テーブルを BigLake テーブルに更新する
- 新しい Cloud Shell ウィンドウを開き、次のコマンドを実行して、使用する接続を指定する新しい外部テーブル定義を生成します。
- テーブル定義が作成されていることを確認します。
- テーブルからスキーマを取得します。
- 新しい外部テーブルの定義を使用してテーブルを更新します。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
更新したテーブルを確認する
-
ナビゲーション メニューから、[BigQuery] > [BigQuery Studio] にアクセスします。
-
[demo-dataset] に移動して、[external_table] をダブルクリックします。
-
[詳細] タブを開きます。
-
[外部データ構成] で、テーブルが正しい接続 ID を使用していることを確認します。
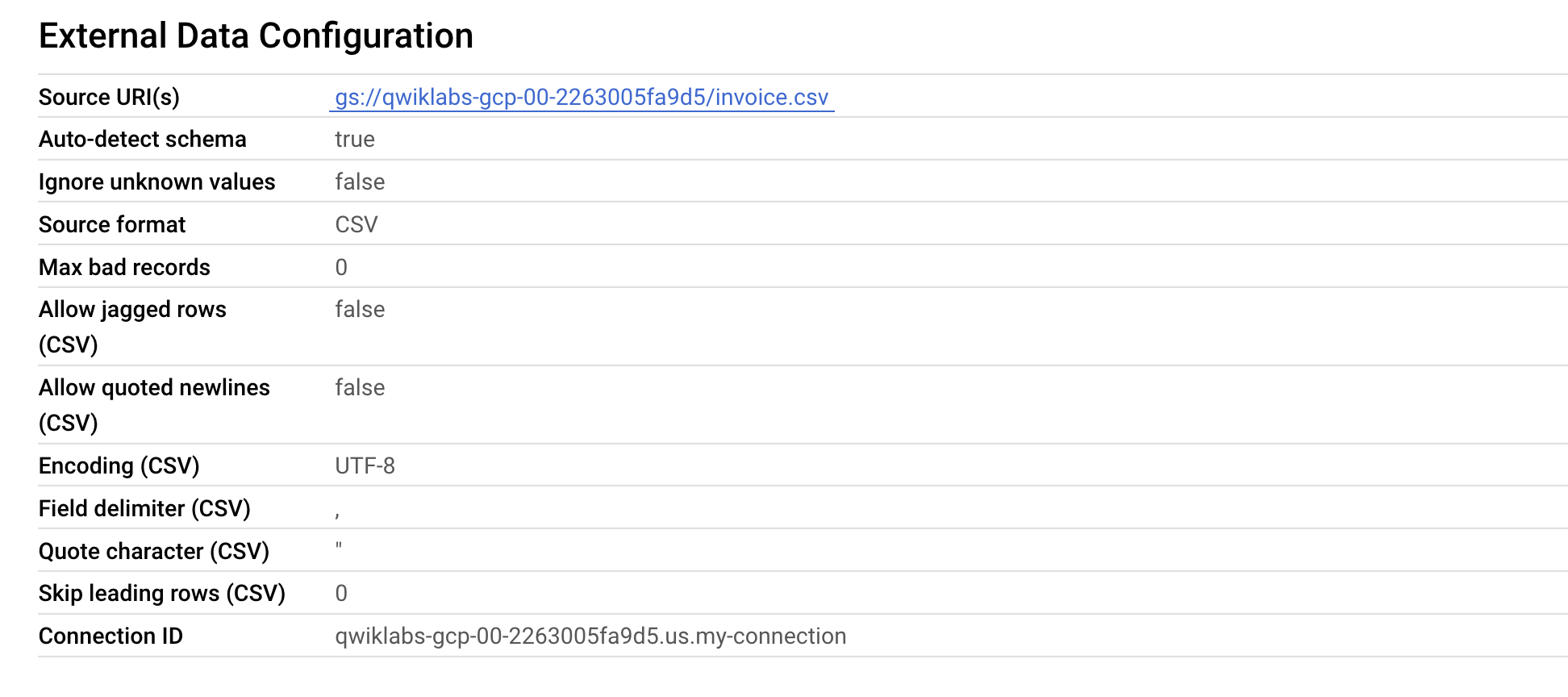
これで、既存の外部テーブルをクラウド リソース接続に関連付けることにより、BigLake テーブルにアップグレードできました。
お疲れさまでした
このラボでは、接続リソースを作成し、Cloud Storage データレイクへのアクセスを設定し、そこから BigLake テーブルを作成しました。続いて、BigQuery を介して BigLake テーブルにクエリを実行し、列レベルのアクセス制御ポリシーを設定しました。最後に、接続リソースを使用して既存の外部テーブルを BigLake テーブルに更新しました。
次のステップと詳細情報
BigLake への理解をさらに深めるために、以下のドキュメントをぜひご覧ください。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2024 年 1 月 16 日
ラボの最終テスト日: 2024 年 1 月 16 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。

