GSP1052

概要
競争の激しい昨今の環境において、組織にはリアルタイムのデータに基づき迅速かつ簡単に意思決定を行うことが求められています。Datastream for BigQuery には、AlloyDB、MySQL、PostgreSQL、Oracle などの運用データベース ソースから Google Cloud のサーバーレス データ ウェアハウスである BigQuery に、直接シームレスにデータをレプリケート(複製)できるという特長があります。サーバーレスで自動スケーリングが可能なアーキテクチャを持つ Datastream を使うことで、低レイテンシでデータをレプリケートするための ELT(抽出、読み込み、変換)パイプラインを簡単に設定し、リアルタイムで分析や洞察を得ることができます。
このハンズオンラボでは、Cloud SQL for PostgreSQL データベースをデプロイし、gcloud コマンドラインを使用してサンプルのデータセットをインポートします。UI を使って Datastream ストリームを作成および開始し、データを BigQuery にレプリケートします。
ラボからコマンドをコピーして適切な場所に貼り付けることは簡単ですが、基本概念をよりよく理解できるよう、自分の手でコマンドを入力していただくことをおすすめします。
演習内容
- Google Cloud コンソールを使って Cloud SQL for PostgreSQL インスタンスを準備する
- データを Cloud SQL インスタンスにインポートする
- PostgreSQL データベース用の Datastream 接続プロファイルを作成する
- BigQuery を複製先とする Datastream 接続プロファイルを作成する
- Datastream ストリームを作成してレプリケーションを開始する
- 既存のデータと変更内容が BigQuery に正しくレプリケートされているかどうかを検証する
前提条件
- 標準的な Linux 環境に関する知識や経験がある
- 変更データ キャプチャ(CDC)の概念に関する知識や経験がある
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
注: このラボの実行には、シークレット モードまたはシークレット ブラウジング ウィンドウを使用してください。これにより、個人アカウントと受講者アカウント間の競合を防ぎ、個人アカウントに追加料金が発生することを防ぎます。
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
注: すでに個人の Google Cloud アカウントやプロジェクトをお持ちの場合でも、このラボでは使用しないでください。アカウントへの追加料金が発生する可能性があります。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。
左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google Cloud コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウでリンクを開く] を選択します)。
ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。
-
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
{{{user_0.username | "Username"}}}
[ラボの詳細] パネルでも [ユーザー名] を確認できます。
-
[次へ] をクリックします。
-
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
{{{user_0.password | "Password"}}}
[ラボの詳細] パネルでも [パスワード] を確認できます。
-
[次へ] をクリックします。
重要: ラボで提供された認証情報を使用する必要があります。Google Cloud アカウントの認証情報は使用しないでください。
注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。
-
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後、このタブで Google Cloud コンソールが開きます。
注: Google Cloud のプロダクトやサービスのリストを含むメニューを表示するには、左上のナビゲーション メニューをクリックします。
Cloud Shell をアクティブにする
Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
- Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン
 をクリックします。
をクリックします。
接続した時点で認証が完了しており、プロジェクトに各自の PROJECT_ID が設定されます。出力には、このセッションの PROJECT_ID を宣言する次の行が含まれています。
Your Cloud Platform project in this session is set to YOUR_PROJECT_ID
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
- (省略可)次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
gcloud auth list
-
[承認] をクリックします。
-
出力は次のようになります。
出力:
ACTIVE: *
ACCOUNT: student-01-xxxxxxxxxxxx@qwiklabs.net
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (省略可)次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
gcloud config list project
出力:
[core]
project = <project_ID>
出力例:
[core]
project = qwiklabs-gcp-44776a13dea667a6
注: Google Cloud における gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
タスク 1. レプリケーション用のデータベースを作成する
このセクションでは、Datastream によるレプリケーションのために Cloud SQL for PostgreSQL データベースを準備します。
Cloud SQL データベースを作成する
- 次のコマンドを実行して Cloud SQL API を有効にします。
gcloud services enable sqladmin.googleapis.com
- 次のコマンドを実行して Cloud SQL for PostgreSQL データベース インスタンスを作成します。
POSTGRES_INSTANCE=postgres-db
DATASTREAM_IPS={{{project_0.startup_script.ip_Address | IP_ADDRESS}}}
gcloud sql instances create ${POSTGRES_INSTANCE} \
--database-version=POSTGRES_14 \
--cpu=2 --memory=10GB \
--authorized-networks=${DATASTREAM_IPS} \
--region={{{project_0.default_region|REGION}}} \
--root-password pwd \
--database-flags=cloudsql.logical_decoding=on
注: このコマンドを実行すると、
にデータベースが作成されます。別のリージョンに作成したい場合は、
DATASTREAM_IPS をそのリージョンに合った
Datastream パブリック IP に置き換えてください。
データベース インスタンスを作成したら、そのインスタンスのパブリック IP をメモしておいてください。後で Datastream の接続プロファイルを作成する際に必要になるためです。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
レプリケーション用のデータベースを作成する
データベースにサンプルデータを入力する
Cloud Shell で次のコマンドを実行し、PostgreSQL データベースに接続します。
gcloud sql connect postgres-db --user=postgres
パスワードを求められたら「pwd」と入力します。
データベースに接続したら、次の SQL コマンドを実行してサンプルのスキーマとテーブルを作成します。
CREATE SCHEMA IF NOT EXISTS test;
CREATE TABLE IF NOT EXISTS test.example_table (
id SERIAL PRIMARY KEY,
text_col VARCHAR(50),
int_col INT,
date_col TIMESTAMP
);
ALTER TABLE test.example_table REPLICA IDENTITY DEFAULT;
INSERT INTO test.example_table (text_col, int_col, date_col) VALUES
('hello', 0, '2020-01-01 00:00:00'),
('goodbye', 1, NULL),
('name', -987, NOW()),
('other', 2786, '2021-01-01 00:00:00');
レプリケーション用のデータベースを構成する
- 次の SQL コマンドを実行し、パブリケーションとレプリケーション スロットを作成します。
CREATE PUBLICATION test_publication FOR ALL TABLES;
ALTER USER POSTGRES WITH REPLICATION;
SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('test_replication', 'pgoutput');
タスク 2. Datastream リソースを作成してレプリケーションを開始する
これでデータベースの準備が整ったので、Datastream の接続プロファイルとストリームを作成してレプリケーションを開始します。
-
ナビゲーション メニューで [すべてのプロダクトを表示] をクリックし、[分析] の項目にある [Datastream] を選択します。
-
[有効にする] をクリックして Datastream API を使用できるようにします。
接続プロファイルを作成する
接続プロファイルを 2 つ作成します。一つは複製元の PostgreSQL 用、もう一つは複製先の BigQuery 用です。
PostgreSQL の接続プロファイル
- Cloud コンソールで、[接続プロファイル] タブに移動して [プロファイルを作成] をクリックします。
![接続プロファイルのページ。右上に [プロファイルを作成] のリンクがある](https://cdn.qwiklabs.com/%2BWHJQ79%2F7o5oOPvGKWt%2Bzv6Sx94pJrO3sNI%2FfeYqLL0%3D)
- 接続プロファイルの種類として [PostgreSQL] を選択します。
![選択肢の一つとして [PostgreSQL] のタイルが表示されている](https://cdn.qwiklabs.com/%2F1cLHpUGslpbHEz2e0T5h3H3zNcsweIwbY%2FxrCpbrjQ%3D)
-
接続プロファイルの名前および ID には postgres-cp を使用します。
-
データベースの接続詳細情報を次のように入力します。
- リージョン:
- 先ほど作成した Cloud SQL インスタンスの IP とポート
- ユーザー名:
postgres
- パスワード:
pwd
- データベース:
postgres
-
[続行] をクリックします。
-
暗号化は「なし」のままにして、[続行] をクリックします。
-
接続方法として [IP 許可リスト] をクリックし、[続行] をクリックします。
-
[テストを実行] をクリックし、準備したデータベースに Datastream が到達できることを確認します。
-
[作成] をクリックします。
BigQuery の接続プロファイル
- Cloud コンソールで、[接続プロファイル] タブに移動して [プロファイルを作成] をクリックします。
- 接続プロファイルの種類として [BigQuery] を選択します。
-
接続プロファイルの名前および ID には bigquery-cp を使用します。
-
リージョン
-
[作成] をクリックします。
ストリームを作成する
上で作成した接続プロファイルに接続するストリームを作成し、データを複製元から複製先にどのようにストリーミングするかの設定を定義します。
- Cloud コンソールで、[ストリーム] タブに移動して [ストリームの作成] をクリックします。
![[ストリーム] タブ。右上に [ストリームの作成] のリンクがある](https://cdn.qwiklabs.com/s4DlMI%2BuigseWMiEdDRgTYnBmghyxgEhWra2NRxkNng%3D)
ストリームの詳細を定義する
- ストリームの名前および ID には
test-stream を使用します。
- リージョン
- ソースタイプとして [PostgreSQL] を選択します。
- 宛先の種類として [BigQuery] を選択します。
- [続行] をクリックします。
![[ストリームの作成] の詳細ページのステップ 1 に入力した状態](https://cdn.qwiklabs.com/VN6fNjyYYWL2mbstgg2zrDzJfUB%2BygXMB7vIpLYg3JU%3D)
ソース(複製元)を定義する
- 前のステップで作成した postgres-cp の接続プロファイルを選択します。
- [省略可] [テストを実行] をクリックして接続性をテストします。
- [続行] をクリックします。
![[ストリームの作成] ページのステップ 2 に入力した状態](https://cdn.qwiklabs.com/wQpx8zzLoXduV%2FQgzecZUjVOsodk7sE4wi0CqR78JO4%3D)
ソース(複製元)を構成する
- レプリケーション スロット名は「
test_replication」とします。
- パブリケーション名は「
test_publication」とします。
![[ストリームの作成] ページのステップ 3 に入力した状態](https://cdn.qwiklabs.com/8U%2BTQcrgekXHD3qWUiI8ikLo5KmfSrl%2BbH56yfQKc5M%3D)
- レプリケーション用に [test] スキーマを選択します。
![複数の選択肢から [test] スキーマを選択した状態](https://cdn.qwiklabs.com/Lmrjnghu%2FsrkmvASF35aUKrtjjRCUY%2BMpNsPiobgn%2BQ%3D)
- [続行] をクリックします。
宛先(複製先)を定義する
- 前のステップで作成した [bigquery-cp] を接続プロファイルとして選択し、[続行] をクリックします。
![[ストリームの作成] ページのステップ 4 で [bigquery-cp] を選択した状態](https://cdn.qwiklabs.com/1SuvlVgaBoYruXirg1VIuvb0InSorFEnuZNBxu0D6yA%3D)
宛先(複製先)を構成する
- リージョンを選択し、BigQuery データセットのロケーションとして [] を選択します。
- [未更新に関する制限事項] は [0 秒] に設定します。
![[ストリームの作成] ページのステップ 5 でロケーションを選択した状態](https://cdn.qwiklabs.com/t%2FE1dGztk%2FYCGKlUSM6ryNGNs6PkiRzrvE6AbIqLHnk%3D)
- [続行] をクリックします。
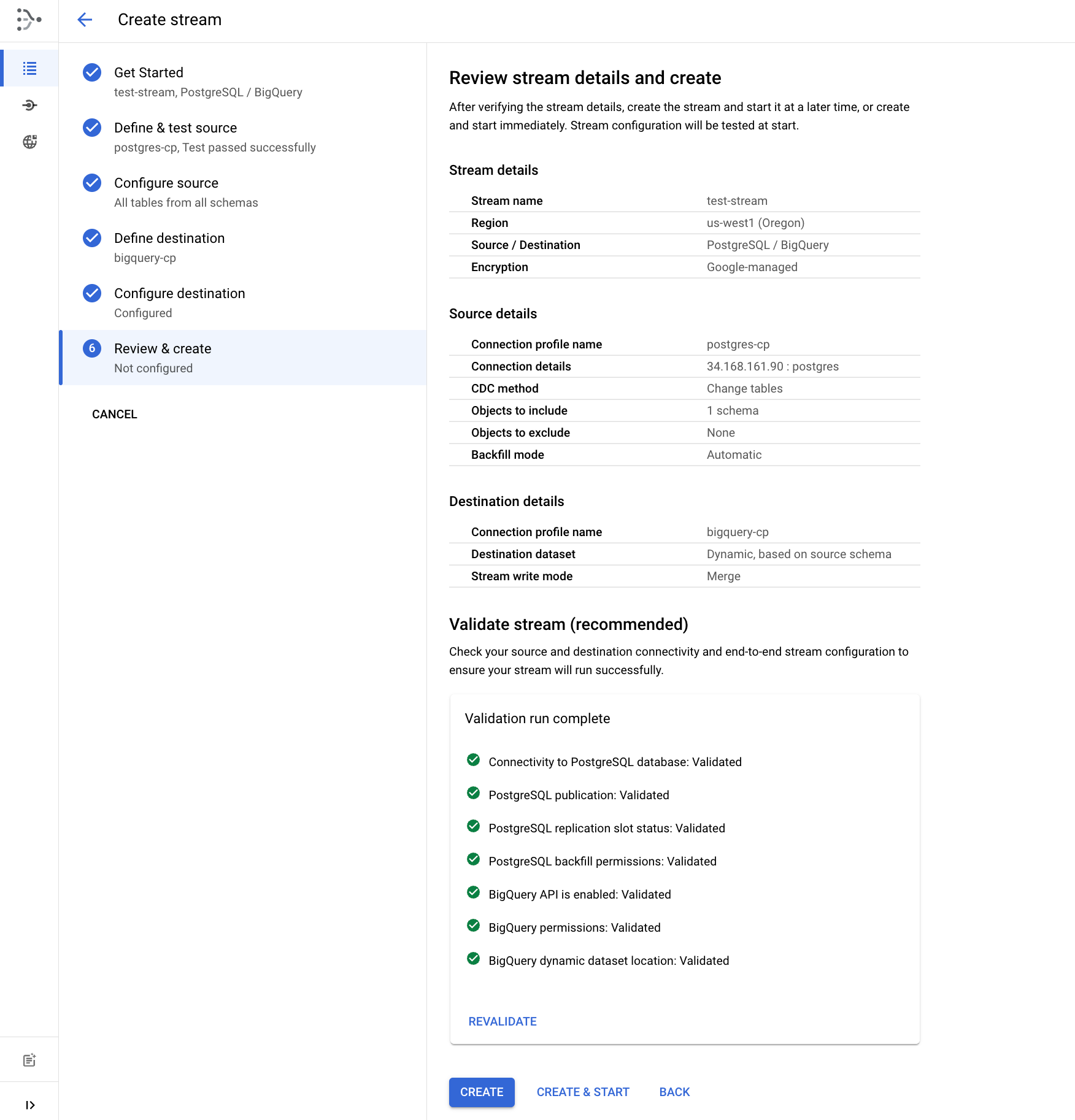
ストリームを確認して作成する
- いよいよ、[検証を実行] をクリックしてストリームの詳細を検証します。検証が問題なく完了したら、[作成して開始] をクリックします。
ストリームのステータスが稼働中になるまで、1~2 分ほど待ちます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
Datastream リソースを作成する
タスク 3. BigQuery のデータを表示する
ストリームが稼働し始めたら、データが BigQuery データセットにレプリケートされているのを確認します。
- Google Cloud コンソールで、ナビゲーション メニューから [BigQuery] にアクセスします。
- BigQuery Studio のエクスプローラで、プロジェクト ノードを開いてデータセットの一覧を確認します。
- [test] のデータセット ノードを開きます。
- テーブル [example_table] をクリックします。
- [プレビュー] タブをクリックして BigQuery のデータを確認します。
注: データが [プレビュー] セクションに表示されるまでに数分かかることがあります。
![example_table が表示されている BigQuery の [エクスプローラ] ページ](https://cdn.qwiklabs.com/%2BqmRJAi4IaaSwz1Iaut6uh46BVBjvzqQP9BVhuZDScs%3D)
タスク 4. 複製元の変更内容が BigQuery にレプリケートされていることを確認する
- Cloud Shell で次のコマンドを実行し、Cloud SQL データベースに接続します(パスワードは
pwd)。
gcloud sql connect postgres-db --user=postgres
- 次の SQL コマンドを実行してデータに変更を加えます。
INSERT INTO test.example_table (text_col, int_col, date_col) VALUES
('abc', 0, '2022-10-01 00:00:00'),
('def', 1, NULL),
('ghi', -987, NOW());
UPDATE test.example_table SET int_col=int_col*2;
DELETE FROM test.example_table WHERE text_col = 'abc';
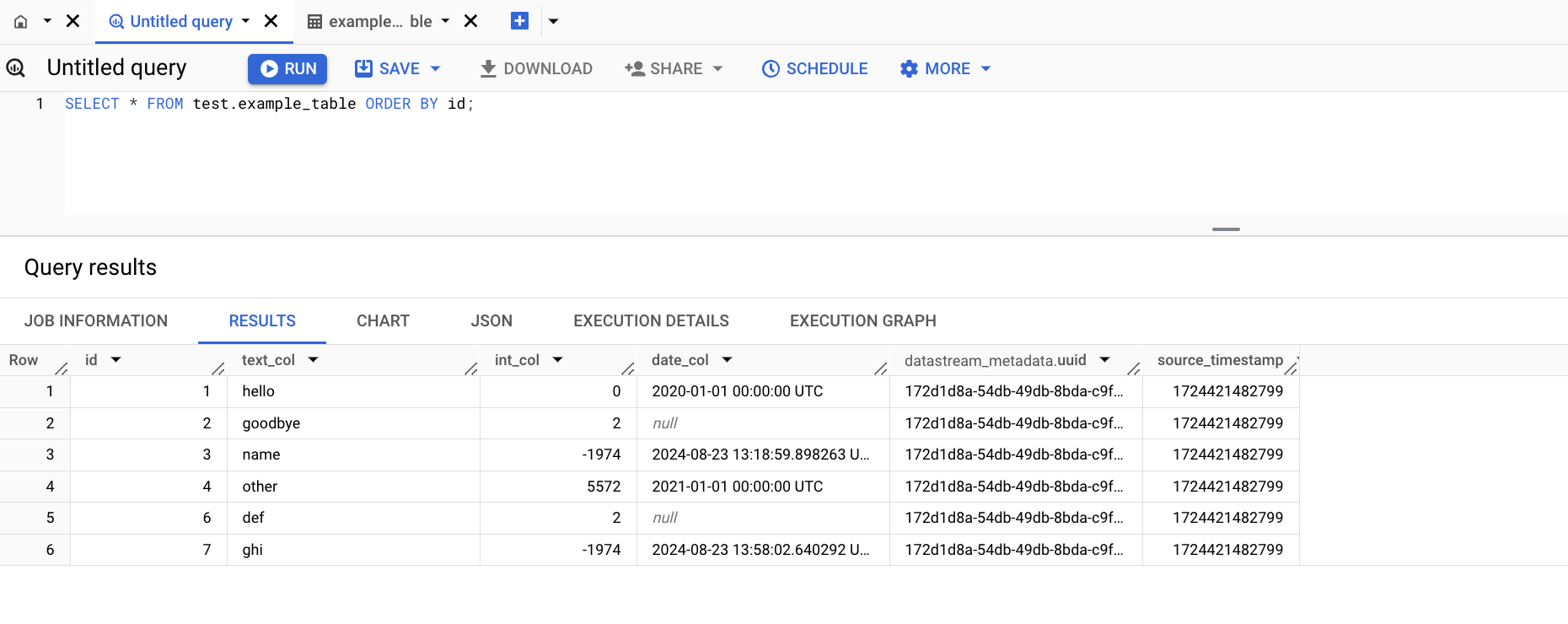
- BigQuery SQL ワークスペースを開いて次のクエリを実行し、BigQuery 内の変更を確認します。
SELECT * FROM test.example_table ORDER BY id;
お疲れさまでした
Datastream はデータの統合、分析ツールキットにおいて重要なものです。Datastream を使った PostgreSQL から BigQuery へのレプリケーションについての基本的な説明は以上です。
マニュアルの最終更新日: 2024 年 8 月 23 日
ラボの最終テスト日: 2024 年 8 月 23 日
Copyright 2025 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。





