Checkpoints
Create a database for replication
/ 50
Create the Datastream resources
/ 50
Datastream: replicação do PostgreSQL para o BigQuery
GSP1052

Visão geral
No ambiente competitivo de hoje, as organizações precisam tomar decisões de forma fácil e rápida com base em dados coletados em tempo real. O Datastream para BigQuery oferece replicação otimizada de origens de bancos de dados operacionais como AlloyDB, MySQL, PostgreSQL e Oracle diretamente para o BigQuery, o data warehouse sem servidor do Google Cloud. Com arquitetura sem servidor e com escalonamento automático, o Datastream permite configurar facilmente um pipeline ELT (Extract, Load, Transform, ou extrair, carregar e transformar) para a replicação de dados de baixa latência, gerando insights em tempo real.
Neste laboratório prático, você vai implantar um banco de dados do Cloud SQL para PostgreSQL e importar um conjunto de dados de amostra usando a linha de comando gcloud. Na interface, você vai criar e iniciar um fluxo do Datastream e replicar os dados para o BigQuery.
Embora seja possível copiar e colar os comandos do laboratório no local adequado, os estudantes precisam digitá-los para reforçar o aprendizado dos conceitos principais.
Atividades deste laboratório
- Preparar uma instância do Cloud SQL para PostgreSQL usando o console do Google Cloud
- Importar dados para a instância do Cloud SQL
- Criar um perfil de conexão do Datastream para o banco de dados do PostgreSQL
- Criar um perfil de conexão do Datastream para o destino do BigQuery
- Criar um fluxo do Datastream e começar a replicação
- Validar se os dados existentes e as alterações foram replicados corretamente para o BigQuery
Pré-requisitos
- Familiaridade com ambientes Linux padrão
- Familiaridade com conceitos de captura de dados alterados (CDC, na sigla em inglês)
Configuração e requisitos
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você vai encontrar o seguinte:
- O botão Abrir console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta. -
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Nome de usuário"}}} Você também encontra o Nome de usuário no painel Detalhes do laboratório.
-
Clique em Seguinte.
-
Copie a Senha abaixo e cole na caixa de diálogo de boas-vindas.
{{{user_0.password | "Senha"}}} Você também encontra a Senha no painel Detalhes do laboratório.
-
Clique em Seguinte.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud. Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais. -
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
- Clique em Ativar o Cloud Shell
na parte de cima do console do Google Cloud.
Depois de se conectar, vai notar que sua conta já está autenticada, e que o projeto está configurado com seu PROJECT_ID. A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
-
Clique em Autorizar.
-
A saída será parecida com esta:
Saída:
- (Opcional) É possível listar o ID do projeto usando este comando:
Saída:
Exemplo de saída:
gcloud, acesse o guia com informações gerais sobre a gcloud CLI no Google Cloud.
Tarefa 1: criar um banco de dados para replicação
Nesta seção, você vai preparar um banco de dados do Cloud SQL para PostgreSQL para replicação pelo Datastream.
Criar o banco de dados do Cloud SQL
- Execute o seguinte comando para ativar a API Cloud SQL:
- Execute o seguinte comando para criar uma instância de banco de dados do Cloud SQL para PostgreSQL:
DATASTREAM_IPS pelos IPs públicos do Datastream certos para sua região.
Após a criação da instância, anote o IP público dela. Você vai precisar dele mais tarde ao criar o perfil de conexão do Datastream.
Clique em Verificar meu progresso para conferir o objetivo.
Preencher o banco de dados com os dados de amostra
Conecte-se ao banco de dados do PostgreSQL executando o seguinte comando no Cloud Shell.
Quando a senha for solicitada, digite pwd.
Após se conectar ao banco de dados, execute o seguinte comando SQL para criar um esquema de amostra e uma tabela:
Configurar o banco de dados para replicação
- Execute o seguinte comando SQL para criar uma publicação e um slot de replicação:
Tarefa 2: criar os recursos do Datastream e começar a replicação
Agora que o banco de dados está pronto, crie os perfis de conexão e o fluxo do Datastream para começar a replicação.
-
No menu de navegação, clique em Mostrar todos os produtos. Em Análise, selecione Datastream
-
Clique em Ativar para ativar a API Datastream.
Criar perfis de conexão
Crie dois perfis de conexão, um para a origem do PostgreSQL e outro para o destino do BigQuery.
Perfil de conexão do PostgreSQL
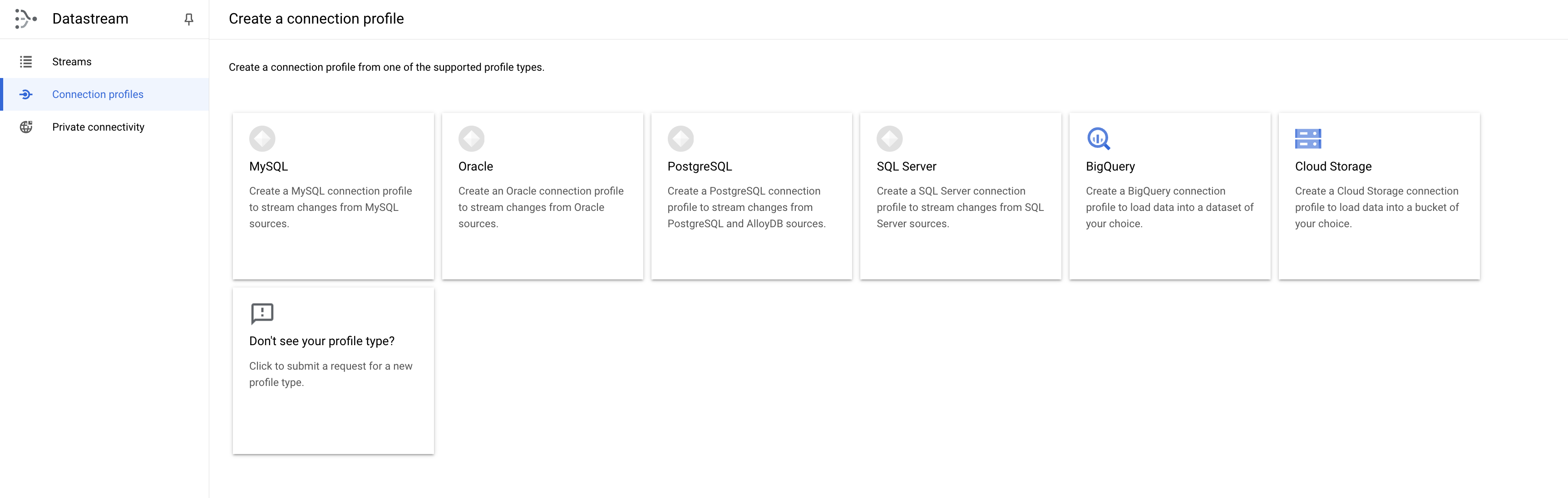
- No console do Cloud, navegue até a guia Perfis de conexão e clique em Criar perfil.

- Selecione o tipo de perfil PostgreSQL.
-
Use
postgres-cpcomo nome e ID do perfil de conexão. -
Digite os detalhes de conexão do banco de dados:
- Região:
- O IP e a porta da instância do Cloud SQL criada anteriormente
- Nome de usuário:
postgres - Senha:
pwd - Banco de dados:
postgres
-
Clique em Continuar.
-
Deixe a criptografia como NENHUMA e clique em CONTINUAR.
-
Selecione o método de conectividade Lista de permissões de IP e clique em Continuar.
-
Clique em EXECUTAR TESTE para garantir que o Datastream pode alcançar o banco de dados.
-
Clique em Criar.
Perfil de conexão do BigQuery
- No console do Cloud, navegue até a guia Perfis de conexão e clique em Criar perfil.
- Selecione o tipo de perfil BigQuery.
-
Use
bigquery-cpcomo nome e ID do perfil de conexão. -
Região
-
Clique em Criar.
Criar fluxo
Crie o fluxo que conecta os perfis de conexão criados acima e define a configuração do fluxo de dados da origem até o destino.
- No console do Cloud, navegue até a guia Fluxos e clique em Criar fluxo.

Definir os detalhes do fluxo
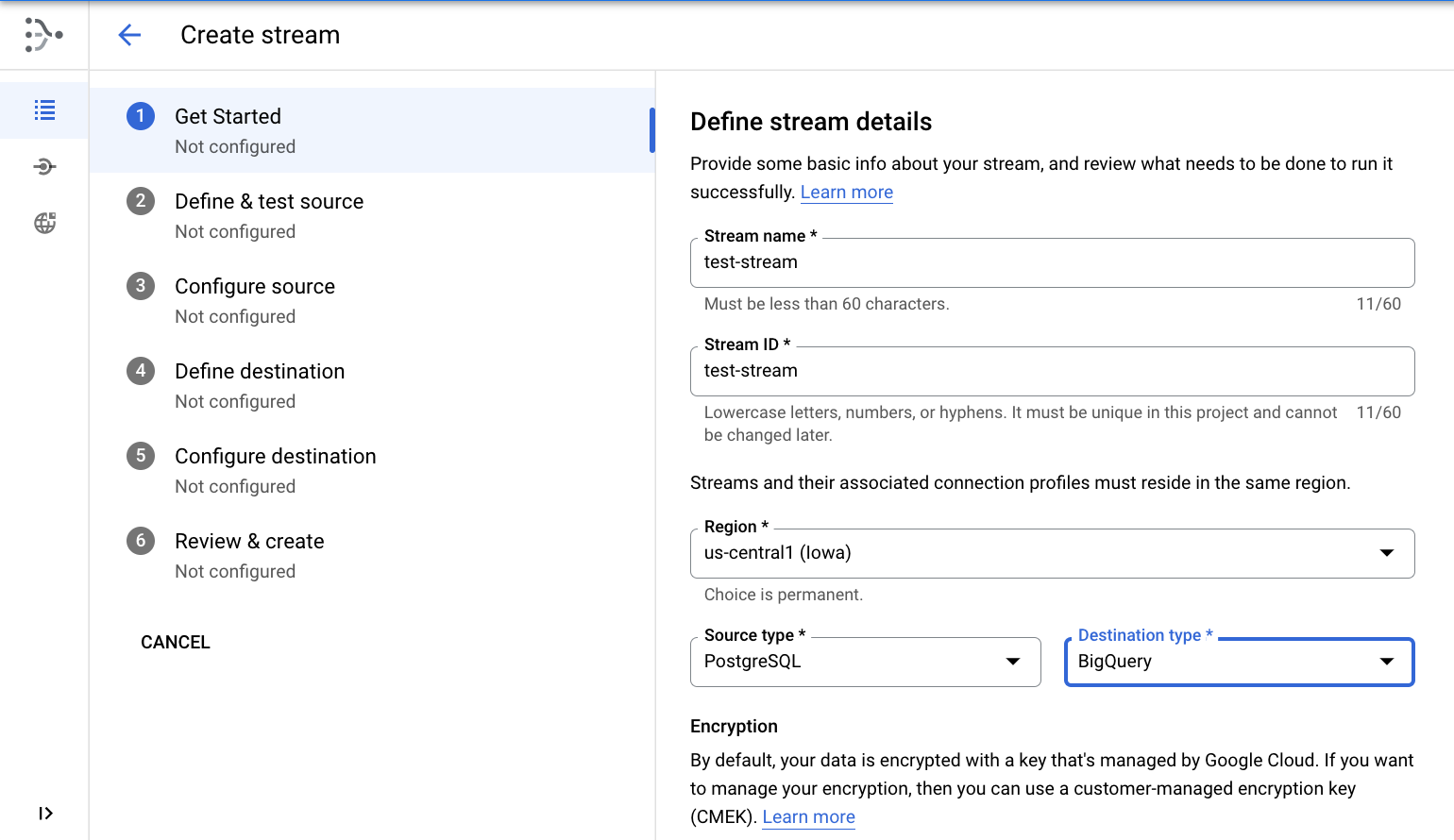
- Use
test-streamcomo nome e ID do fluxo. - Região
- Selecione PostgreSQL como tipo de origem
- Selecione BigQuery como tipo de destino
- Clique em CONTINUAR.
Definir a origem
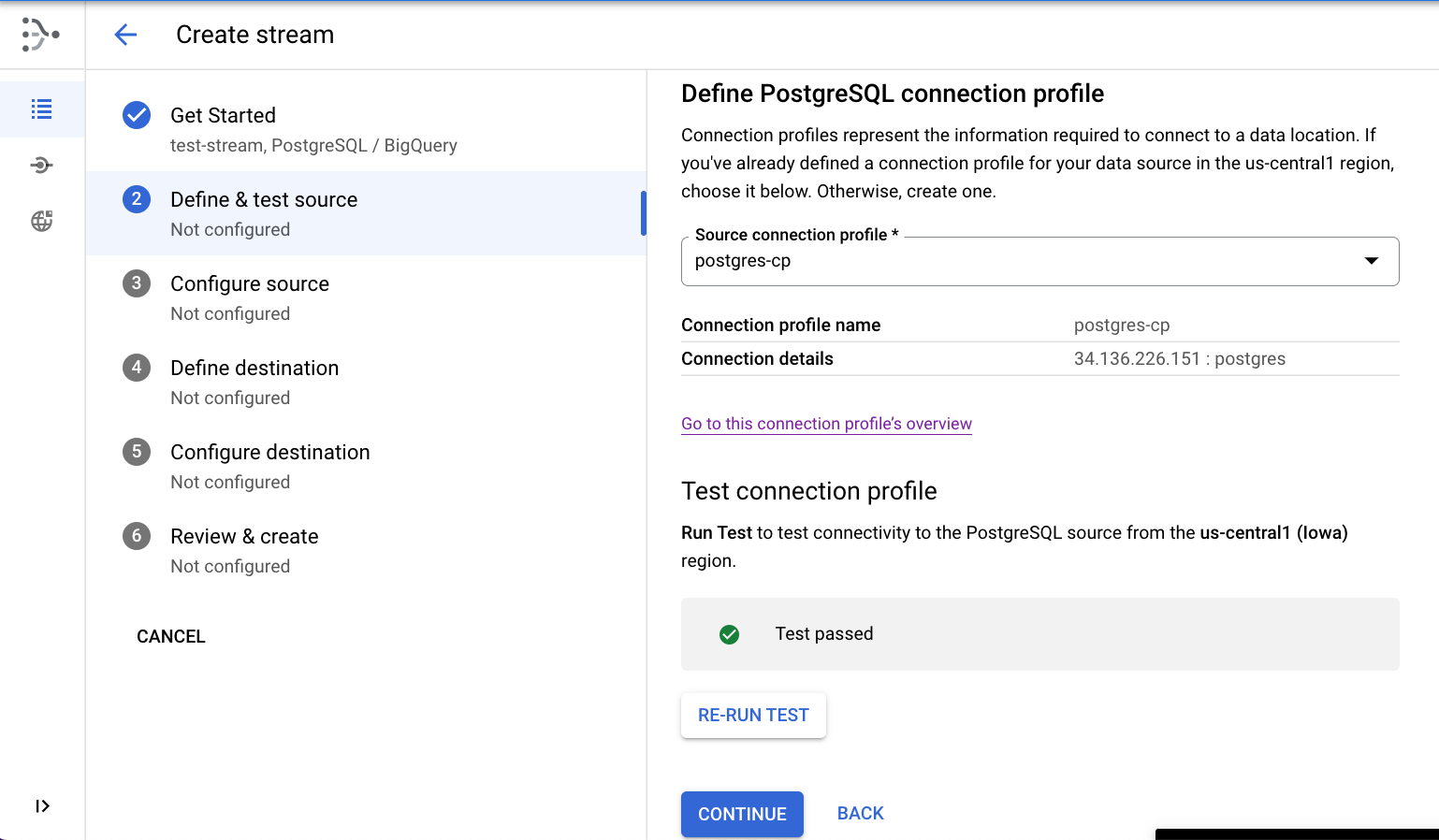
- Selecione o perfil de conexão postgres-cp criado na etapa anterior.
- [Opcional] Teste a conectividade clicando em EXECUTAR TESTE.
- Clique em CONTINUAR.
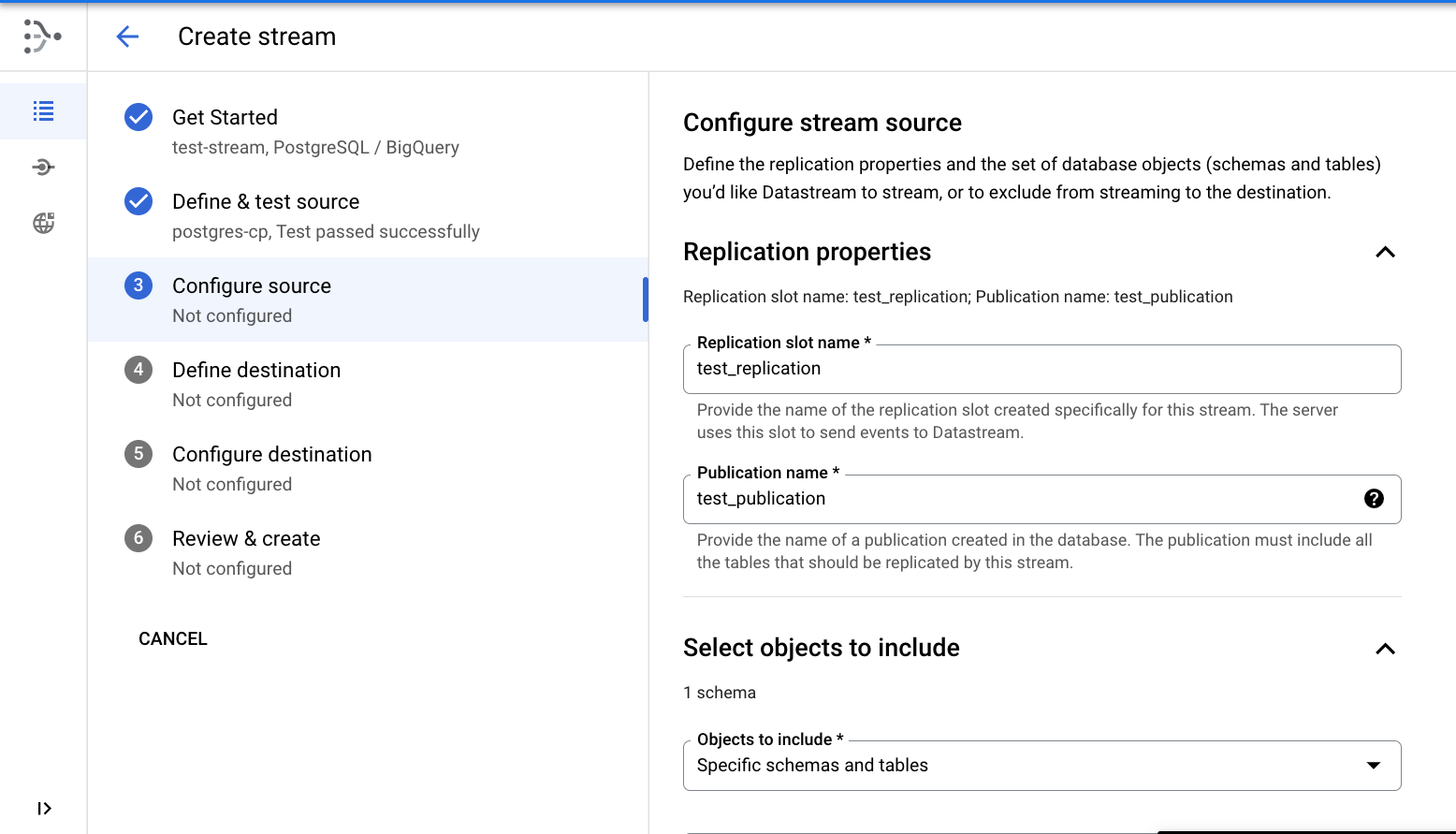
Configurar a origem
- Especifique o nome do slot de replicação como
test_replication. - Especifique o nome de publicação como
test_publication.
- Selecione o esquema test para replicação.
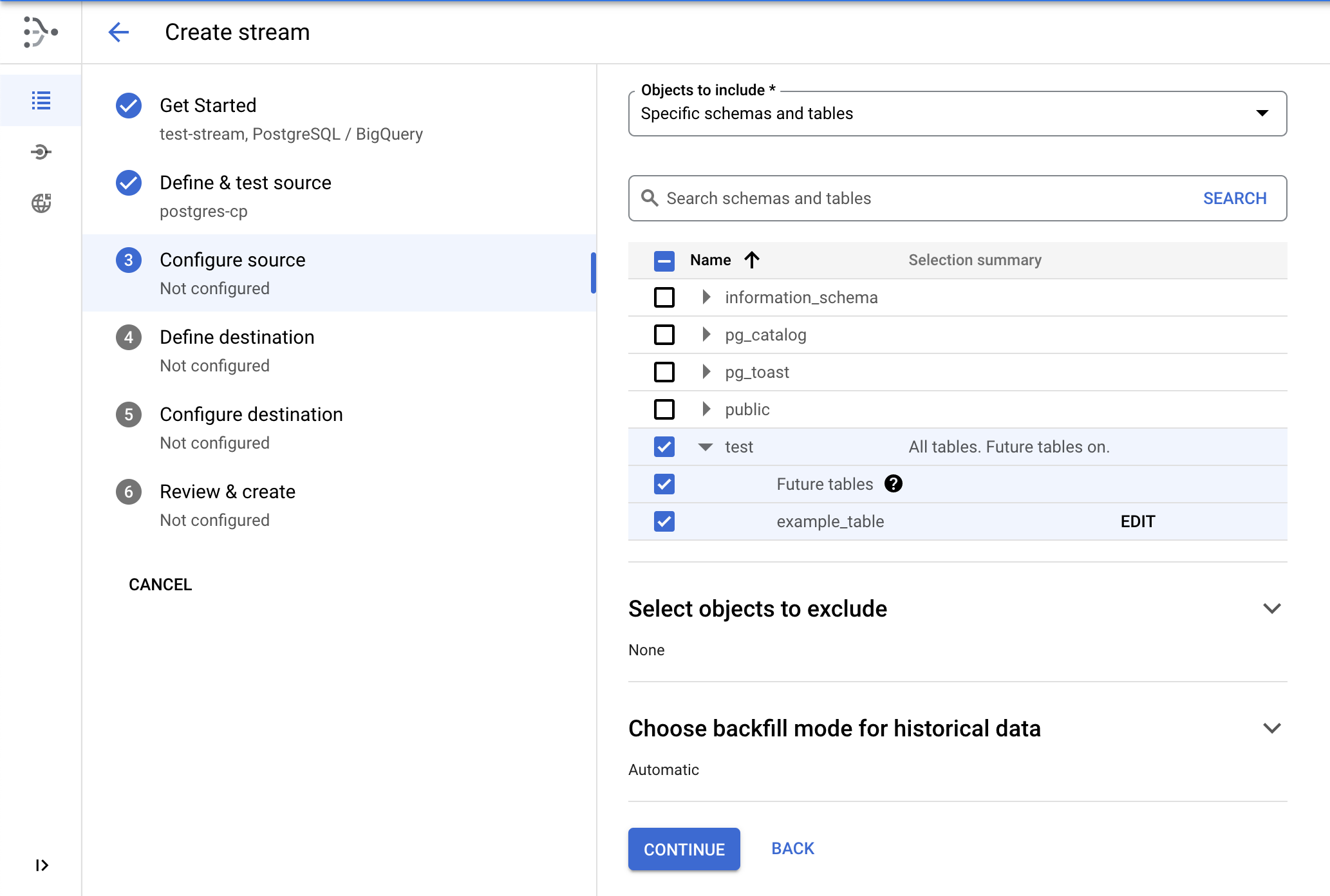
- Clique em Continuar.
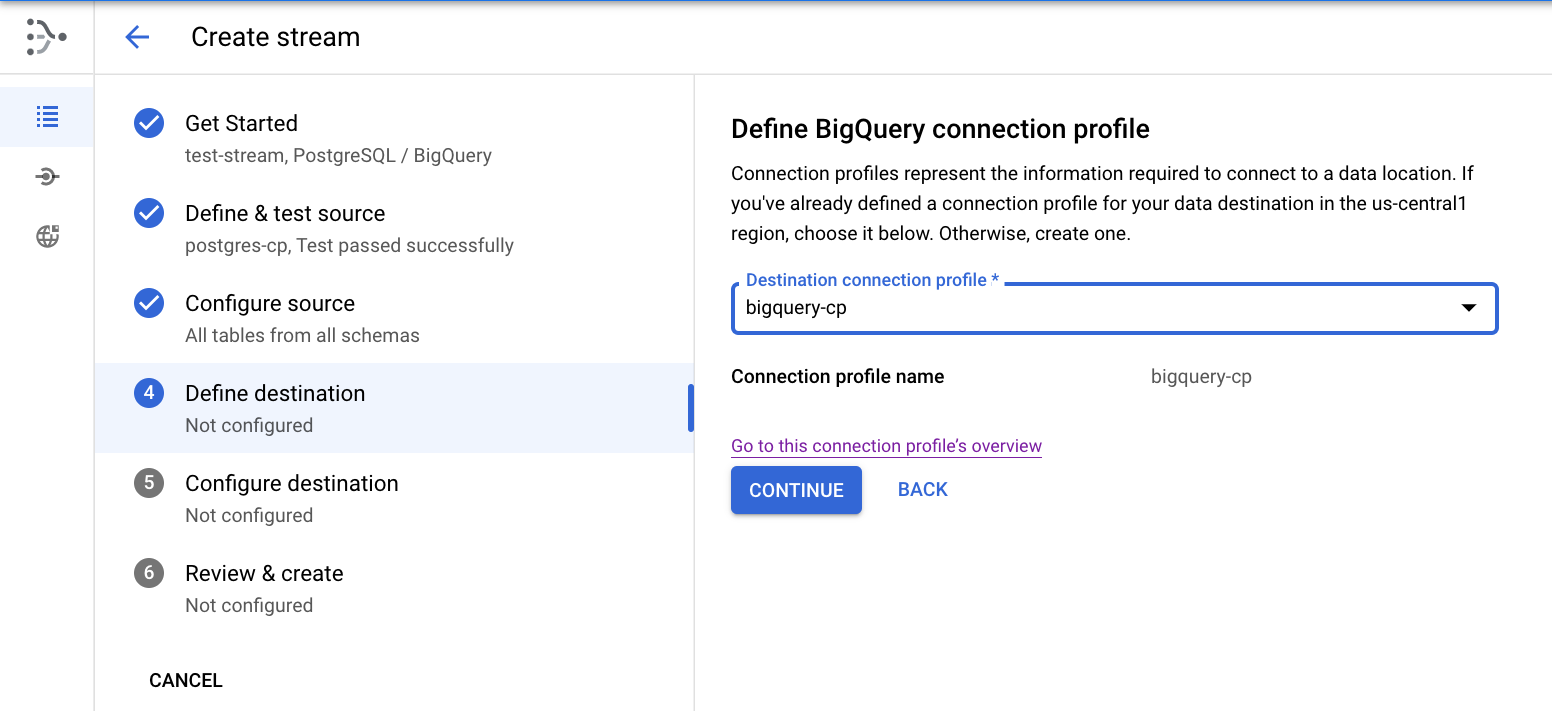
Definir o destino
- Selecione o perfil de conexão bigquery-cp criado na etapa anterior e clique em Continuar.
Configurar o destino
- Escolha "Região" e selecione
como local do conjunto de dados do BigQuery. - Defina o limite de inatividade como 0 segundo.
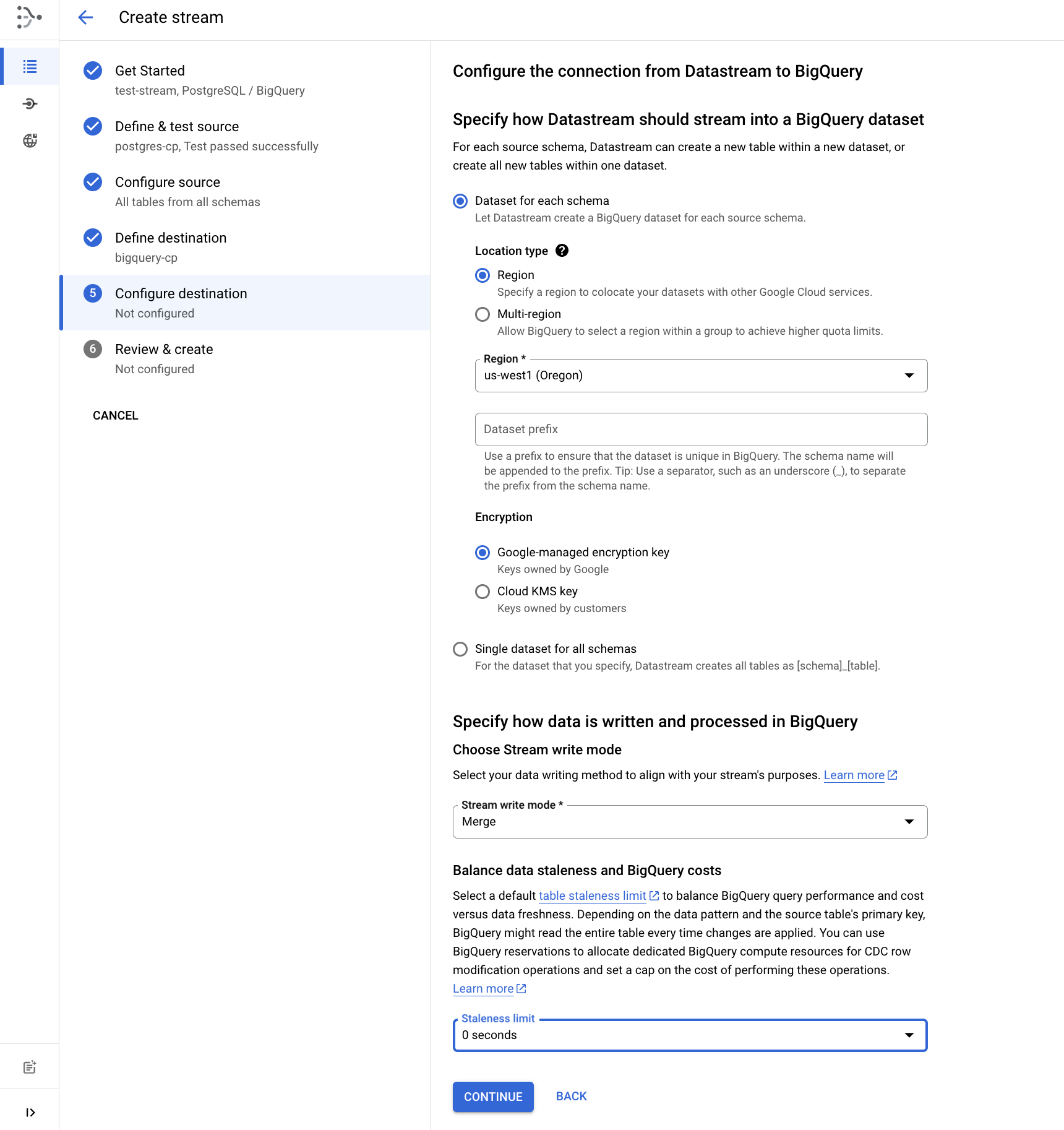
- Clique em Continuar.
Revisar e criar o fluxo
- Por fim, valide os detalhes do fluxo clicando em EXECUTAR VALIDAÇÃO. Quando a validação for concluída, clique em CRIAR E COMEÇAR.
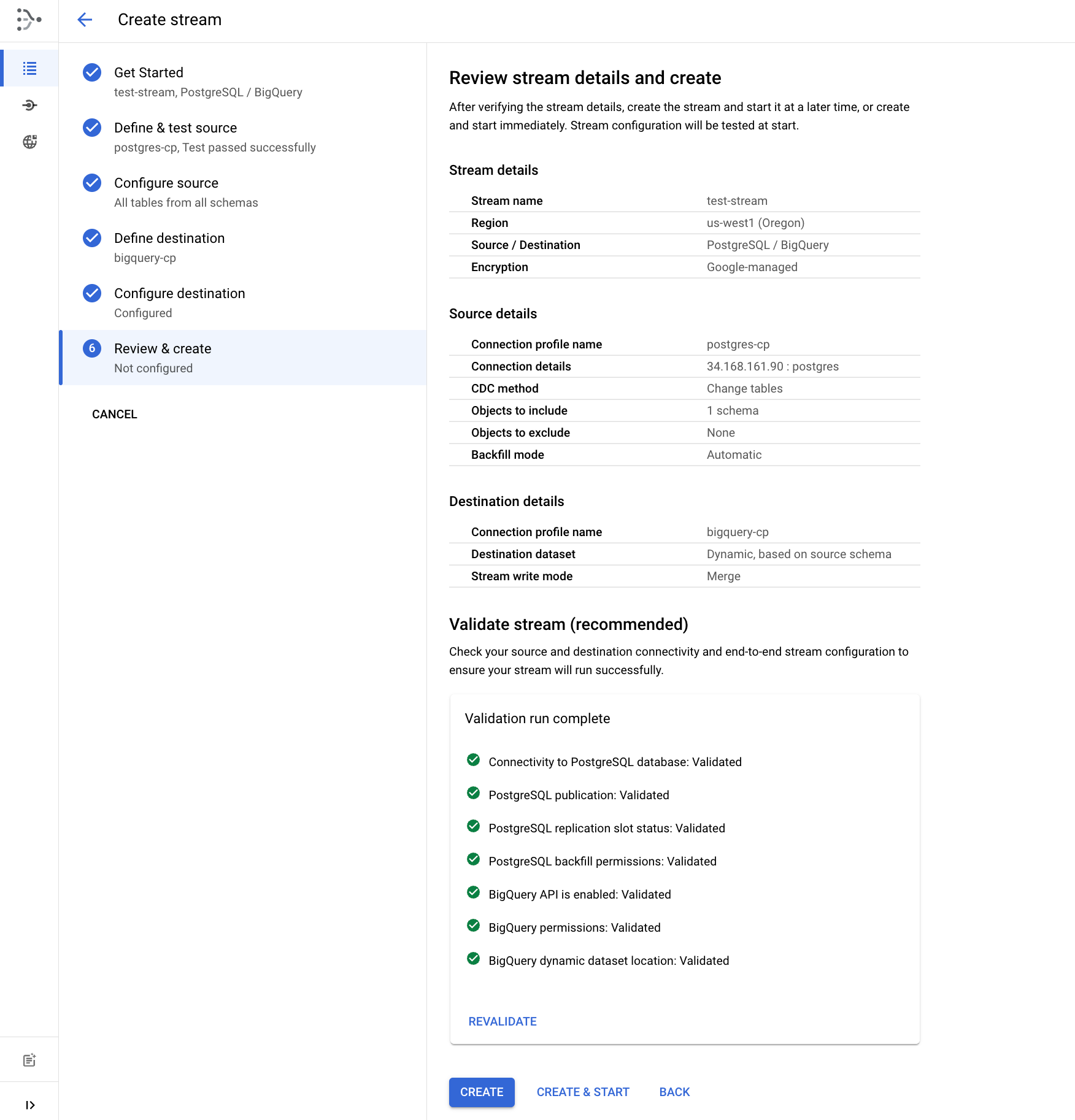
Aguarde aproximadamente 1 a 2 minutos até que o status do fluxo seja mostrado como "Em execução".
Clique em Verificar meu progresso para conferir o objetivo.
Tarefa 3: visualizar os dados no BigQuery
Agora que o fluxo está em execução, confira a replicação dos dados para o conjunto de dados do BigQuery.
- No menu de navegação do console do Google Cloud, acesse BigQuery.
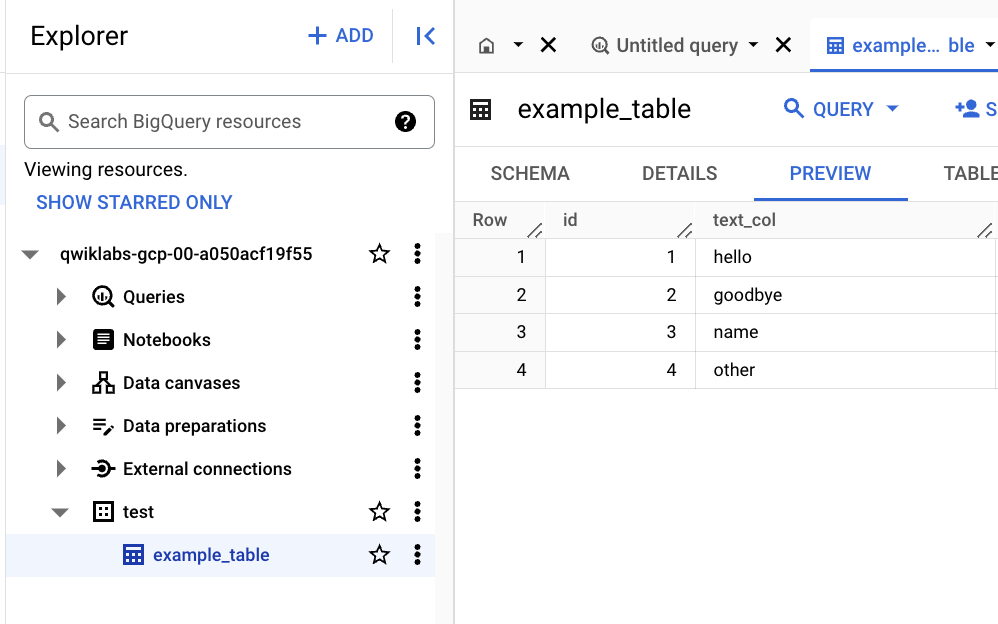
- No explorador do BigQuery Studio, abra o nó do projeto para ver a lista de bancos de dados.
- Abra o nó de banco de dados test.
- Clique na tabela example_table.
- Clique na guia VISUALIZAR para ver os dados no BigQuery.
Tarefa 4: verificar se as mudanças na origem são replicadas para o BigQuery
- Execute o seguinte comando no Cloud Shell para se conectar ao banco de dados do Cloud SQL (a senha é
pwd):
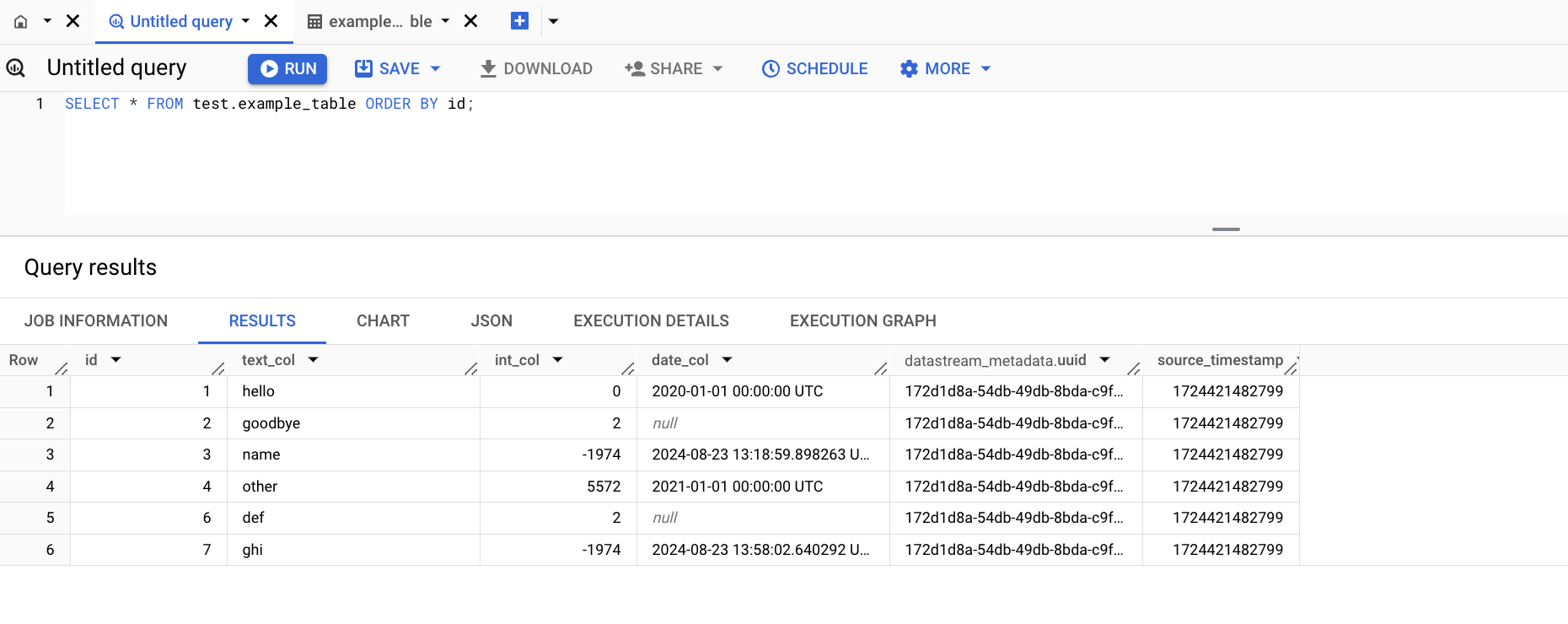
- Execute os seguintes comandos SQL para fazer algumas alterações nos dados:
- Abra o espaço de trabalho do BigQuery SQL e execute a seguinte consulta para ver as mudanças no BigQuery:
Parabéns!
O Datastream é um recurso importante de integração e análise de dados. Você aprendeu os conceitos básicos de replicação do PostgreSQL para o BigQuery com o Datastream.
Manual atualizado em 23 de agosto de 2024
Laboratório testado em 23 de agosto de 2024
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.

