체크포인트
Create a virtual machine to perform the creation of the pipeline and use as your website.
/ 20
Create the bigtable instance.
/ 20
Create a Google Cloud Storage bucket
/ 20
Run the dataflow pipeline
/ 20
Create a firewall rule to allow tcp:5000 for visualization.
/ 20
Tracking Cryptocurrency Exchange Trades with Google Cloud Platform in Real-Time
GSP603

Overview
Today’s financial world is complex, and the old technology used for constructing financial data pipelines isn’t keeping up. With multiple financial exchanges operating around the world and global user demand, these data pipelines have to be fast, reliable and scalable.
Currently, using an econometric approach—applying models to financial data to forecast future trends—doesn’t work for real-time financial predictions. And data that’s old, inaccurate or from a single source doesn’t translate into dependable data for financial institutions to use.
But building pipelines with Google Cloud can solve some of these key challenges. In this lab, you’ll describe how to build a pipeline to predict financial trends in microseconds, set up and configure a pipeline for ingesting real-time, time-series data from various financial exchanges, and how to design a suitable data model, which facilitates querying and graphing at scale.
You’ll find a tutorial below on setting up and deploying the proposed architecture using Google Cloud, particularly these products:
- Cloud Dataflow for scalable data ingestion system that can handle late data
- Cloud Bigtable, our scalable, low-latency time series database that’s reached 40 million transactions per second on 3500 nodes. Bonus: Scalable ML pipeline using Tensorflow eXtended, while not part of this tutorial, is a logical next step.
The tutorial will explain how to establish a connection to multiple exchanges, subscribe to their trade feed, and extract and transform these trades into a flexible format to be stored in Cloud Bigtable and be available to be graphed and analyzed.
This will also set the foundation for ML online learning predictions at scale. You’ll see how to graph the trades, volume, and time delta from trade execution until it reaches your system (an indicator of how close to real time you can get the data). You can find more details on GitHub too.
Requirements / Solutions
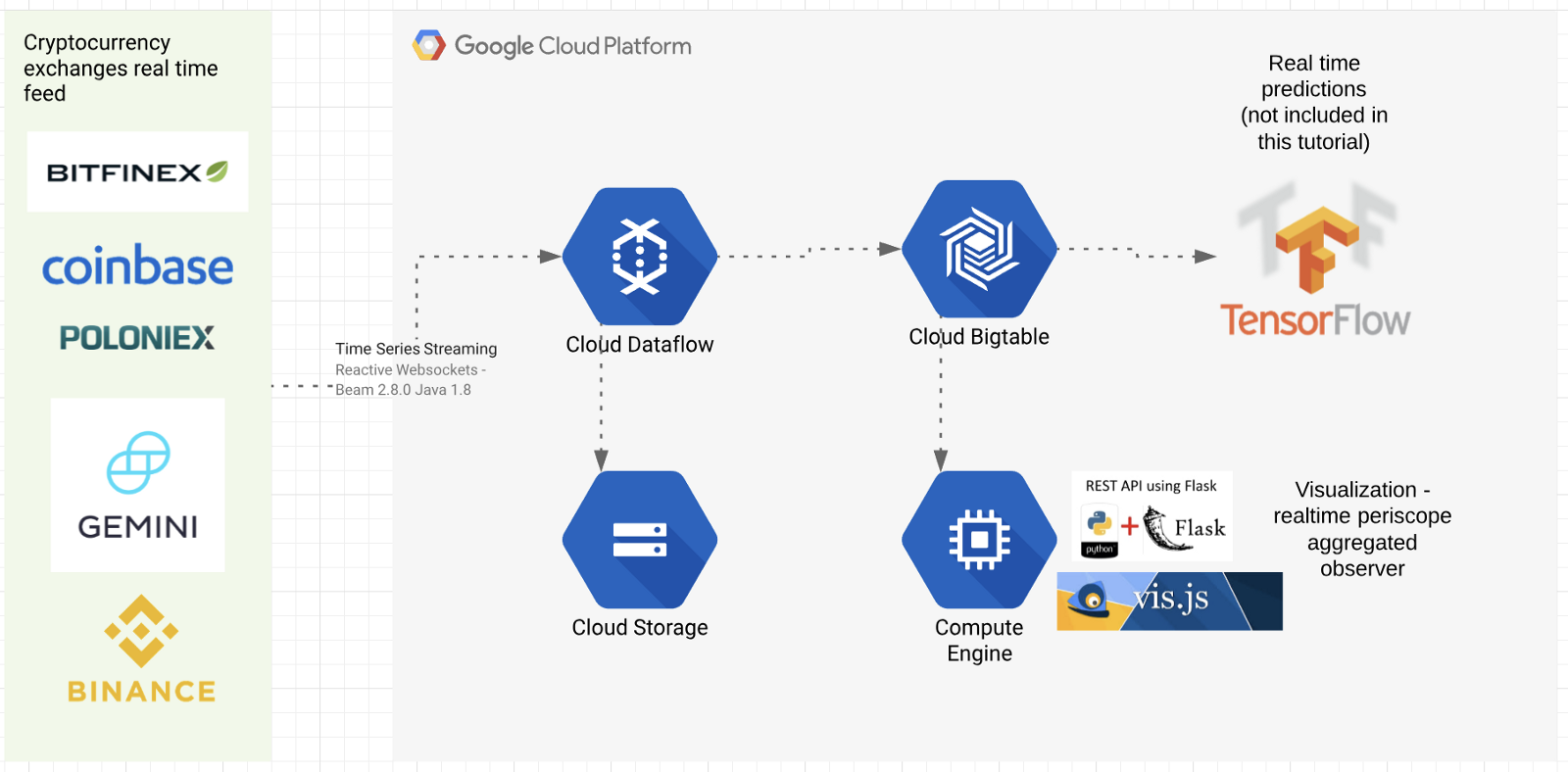
Architectural overview
The typical requirement for trading systems is low latency data ingestion, and for this lab is extended with near real-time data storage and querying at scale. You will learn the following from this lab:
- Ingest real-time trading data with low latency from globally scattered datasources / exchanges. Possibility to adopt data ingest worker pipeline location. Easily add additional trading pairs / exchanges. Solution: Dataflow + Xchange Reactive Websockets Framework
- Demonstrate an unbounded streaming source code that is runnable with multiple runners. Solution: Apache BEAM
- Strong consistency + linear scalability + super low latency for querying the trading data. Solution: Bigtable
- Querying and visualization — Execute time series queries on Bigtable visualize it in on the webpage. Solution: Python Flask + Vis.js + Google Bigtable Python Client
Architecture / How it works
The source code is written in Java 8, Python 3.7, JavaScript; and Maven, PIP for dependency/build management.
The code can be divided into five main framework units:
- Data ingestion — The XChange Stream framework (Github link) Java library provides a simple and consistent streaming API for interacting with Bitcoin and other cryptocurrency exchanges via WebSocket protocol. XChange library is providing new interfaces for streaming API. Users can subscribe for live updates via reactive streams of RxJava library. We use this JAVA 8 framework to connect and configure some exchanges (BitFinex, Poloniex, BitStamp, OkCoin, Gemini, HitBTC, Binance...). Link to the exchange / trading pair configuration code
- Parallel processing — Apache Beam (Github link) Apache Beam is an open source unified programming model to define and execute data processing pipelines, including ETL, batch, and stream (continuous) processing. Supported runners: Apache Apex, Apache Flink, Apache Gearpump, Apache Samza, Apache Spark, and Google Cloud Dataflow. You will learn how to create an unbounded streaming source/reader and manage basic watermarking, checkpointing, and record ID for data ingestion. Link to the bridge between BEAM and XChange Stream framework
- Bigtable sink — Cloud Bigtable with Beam using the HBase API. (Github link) Connector and writer to Bigtable. You will see how to create a row key and create a Bigtable mutation function prior to writing to Bigtable. Link to the Bigtable key creation / mutation function
- Realtime API endpoint — Flask web server at port:5000 + Bigtable client (GitHub link) will be used to query the Bigtable and serve as API endpoint. Link to the Bigtable query builder + results retrieval and sampling
- JavaScript Visualization — Vis.JS Flask template that will query the real-time API endpoint every 500ms. Link to the HTML template file
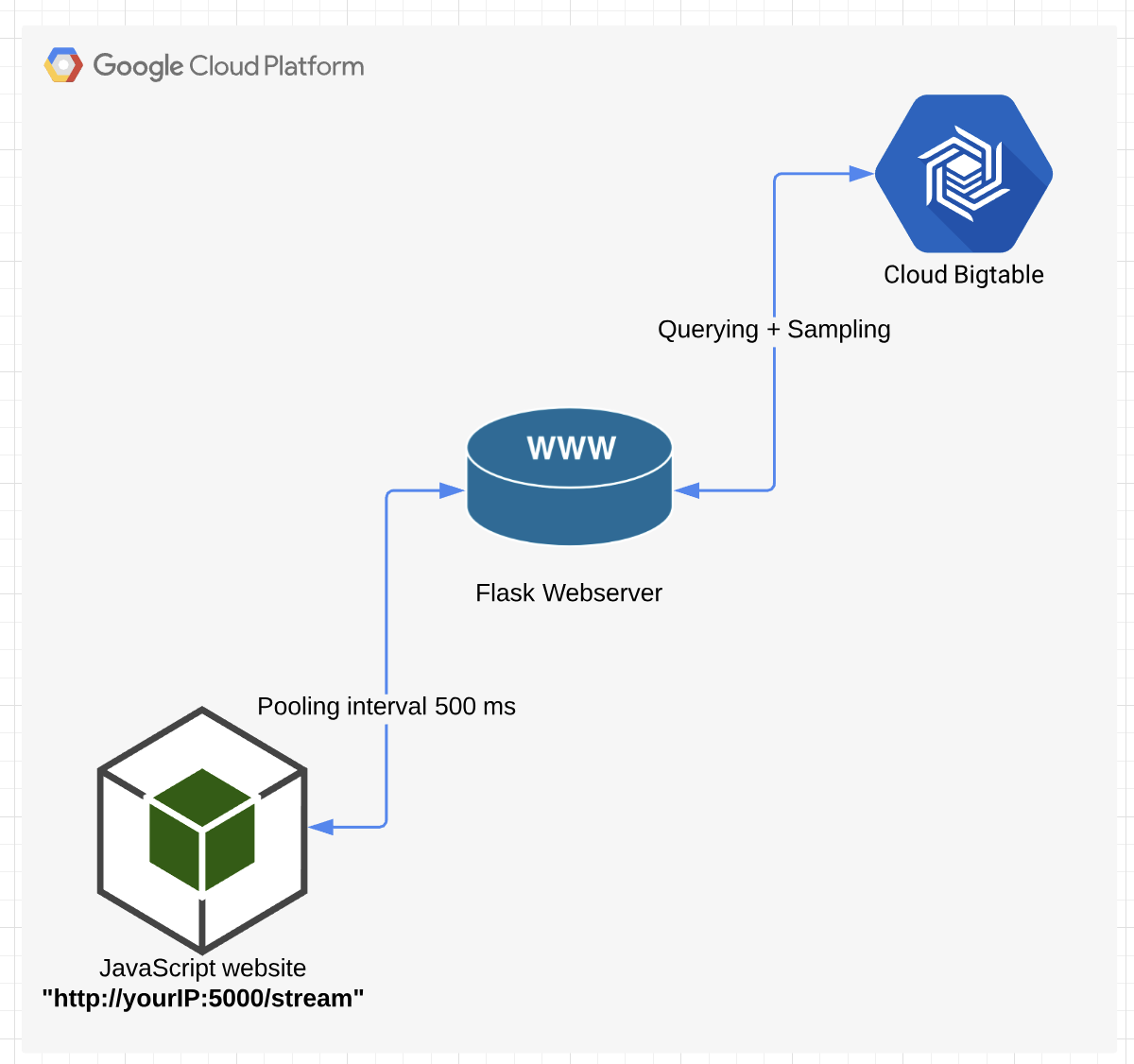
Flask web server will be run in the Google Cloud VM instance
Pipeline definition
For every exchange + trading pair, a different pipeline instance is created. The pipeline consists of 3 steps:
- UnboundedStreamingSource that contains ‘Unbounded Streaming Source Reader' (bitStamp2)
-
Pre-writing mutation and key definition
(ETH-USD Mut2) - Bigtable write step (ETH-USD2)
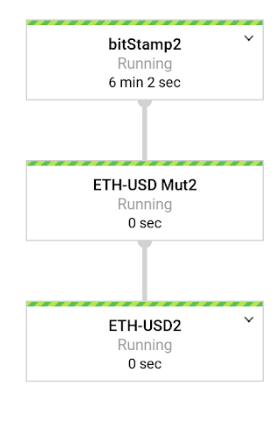
Bigtable row key design decisions
The DTO for this lab looks like this:
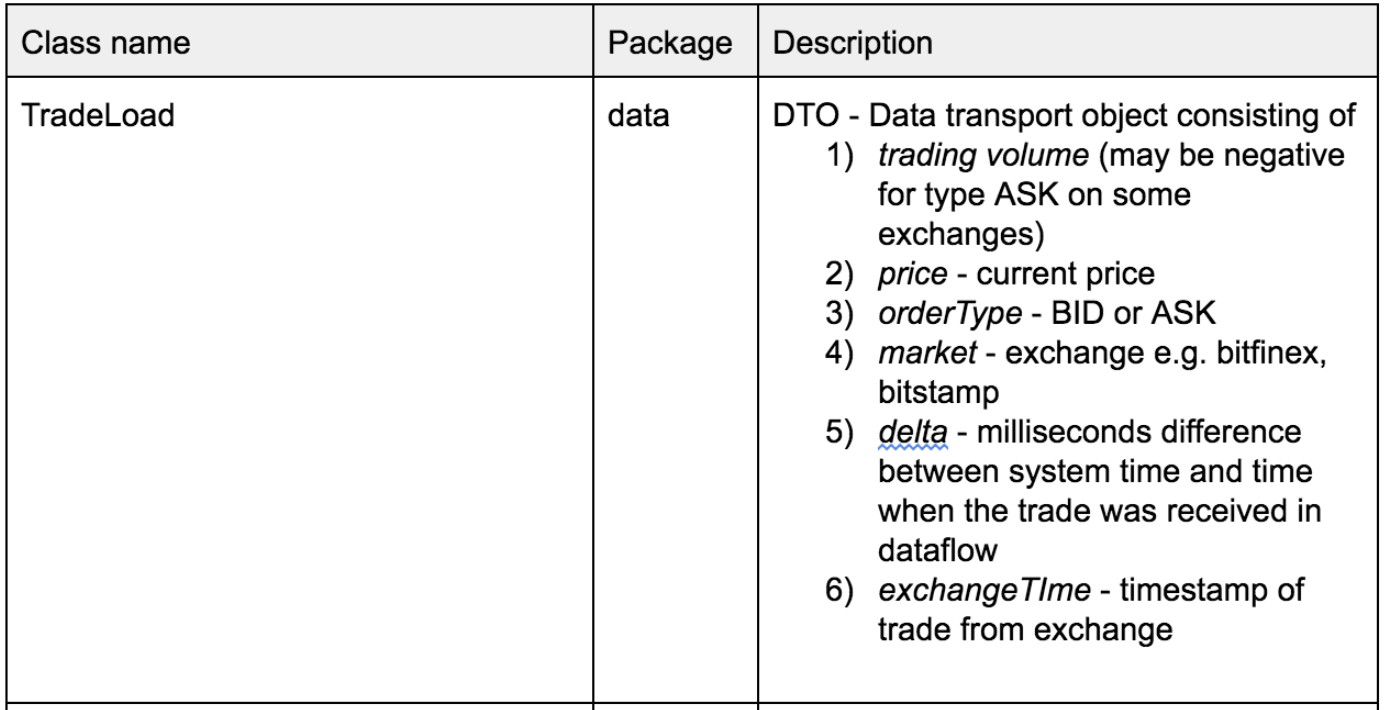
The row key structure is formulated in the following way:
TradingCurrency#Exchange#SystemTimestampEpoch#SystemNanosTime
E.g: a row key might look like BTC/USD#Bitfinex#1546547940918#63187358085
-
BTC/USD — Trading Pair
-
Bitfinex — Exchange
-
1546547940918 — Epoch timestamp ( more info)
-
63187358085 — System Nano time ( more info)
Why is nanotime added at the key end?
Nanotime is used to avoid multiple versions per row for different trades. Two DoFn mutations might execute in the same Epoch ms time if there is a streaming sequence of TradeLoad DTOs. NanoTime at the end will split Millisecond to an additional one million.
In your own environment, if this is not enough, you can hash the volume / price ratio and attach the hash at the end of the row key.
Row cells will contain an exact schema replica of the exchange TradeLoad DTO (see earlier in the table above). This choice will help you go from a specific (trading pair) — (exchange) to less specific (timestamp — nanotime) and avoid hotspots when you query the data.
Setup and requirements
Before you click the Start Lab button
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources will be made available to you.
This hands-on lab lets you do the lab activities yourself in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials that you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
- Access to a standard internet browser (Chrome browser recommended).
- Time to complete the lab---remember, once you start, you cannot pause a lab.
How to start your lab and sign in to the Google Cloud console
-
Click the Start Lab button. If you need to pay for the lab, a pop-up opens for you to select your payment method. On the left is the Lab Details panel with the following:
- The Open Google Cloud console button
- Time remaining
- The temporary credentials that you must use for this lab
- Other information, if needed, to step through this lab
-
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
Note: If you see the Choose an account dialog, click Use Another Account. -
If necessary, copy the Username below and paste it into the Sign in dialog.
{{{user_0.username | "Username"}}} You can also find the Username in the Lab Details panel.
-
Click Next.
-
Copy the Password below and paste it into the Welcome dialog.
{{{user_0.password | "Password"}}} You can also find the Password in the Lab Details panel.
-
Click Next.
Important: You must use the credentials the lab provides you. Do not use your Google Cloud account credentials. Note: Using your own Google Cloud account for this lab may incur extra charges. -
Click through the subsequent pages:
- Accept the terms and conditions.
- Do not add recovery options or two-factor authentication (because this is a temporary account).
- Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.

Activate Cloud Shell
Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud. Cloud Shell provides command-line access to your Google Cloud resources.
- Click Activate Cloud Shell
at the top of the Google Cloud console.
When you are connected, you are already authenticated, and the project is set to your Project_ID,
gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab-completion.
- (Optional) You can list the active account name with this command:
- Click Authorize.
Output:
- (Optional) You can list the project ID with this command:
Output:
gcloud, in Google Cloud, refer to the gcloud CLI overview guide.
Task 1. Create your lab resources
You need a virtual machine to perform the creation of the pipeline and use as your website.
- In Cloud Shell, run the following command:
The compute engine service account is used with the cloud API scope. This provides the necessary permissions to create the necessary resources for your environment.
Wait for the instance to start.
Click Check my progress to verify the objective.
Connect to the instance via SSH
-
In the Cloud Platform Console, on the Navigation menu, click Compute Engine > VM Instances.
-
For the instance called crypto-driver , click SSH.
A window will open and you will be automatically logged into the instance. You will run all commands for the remainder of this lab in the SSH window.
- Run the following commands to uninstall the existing google-cloud-cli and install all the necessary tools (such as java, git, maven, pip, python and cloud bigtable command line tool cbt):
This will also install virtualenv for the Python environment. All the Python related code will be executed in the Virtualenv.
- Now create the Bigtable resource. The first gcloud command will enable the required Bigtable and Dataflow API in the project. The next command will create a Bigtable Cluster called “cryptorealtime-c1” with one instance called “cryptorealtime”. The instance type is Development, and therefore it will be a one node instance. And finally, using the cbt command you are creating a table called “cryptorealtime” with one column family called “market” in the Bigtable instance.
Click Check my progress to verify the objective.
For this lab, one column family called market is used to simplify the schema design. For more on that you can read this link.
- Run the following command to create a bucket:
This bucket will be used by the Dataflow job as a staging area for the Jar files.
Click Check my progress to verify the objective.
- Now clone the application source code repository:
- Run the following to build the software:
Output:
The code for this lab is written in Java, which needs to be compiled and packaged as a Jar file using Maven build tool. The build will take a couple of minutes, please wait until you see the BUILD SUCCESS message.
- Once the build is finished, start the pipeline:
If you check the logs, don't worry about the errors you see. It is safe to ignore illegal thread pool exceptions.
Wait for the command to complete.
run.sh script is a wrapper to submit the crypto tracking Dataflow job on Google Cloud. It takes the following arguments:
- Project_Name,
- Bigtable Instance name,
- Cloud Storage bucket to use as staging area,
- Bigtable Table name and
- Column family name to write the output of the pipeline.
When the pipeline starts, it will create two worker nodes. At this point, you will see two additional VMs in your project.
- Wait a couple of minutes, then run the following to observe the incoming trades by peeking into Bigtable. You can do this by using Cloud Bigtable CLI tool (called cbt). If the pipeline is successfully executing, you should see new data appearing in the cryptorealtime table.
You will see something like the following if the data is flowing. If you see nothing, please wait for a minute and try again.
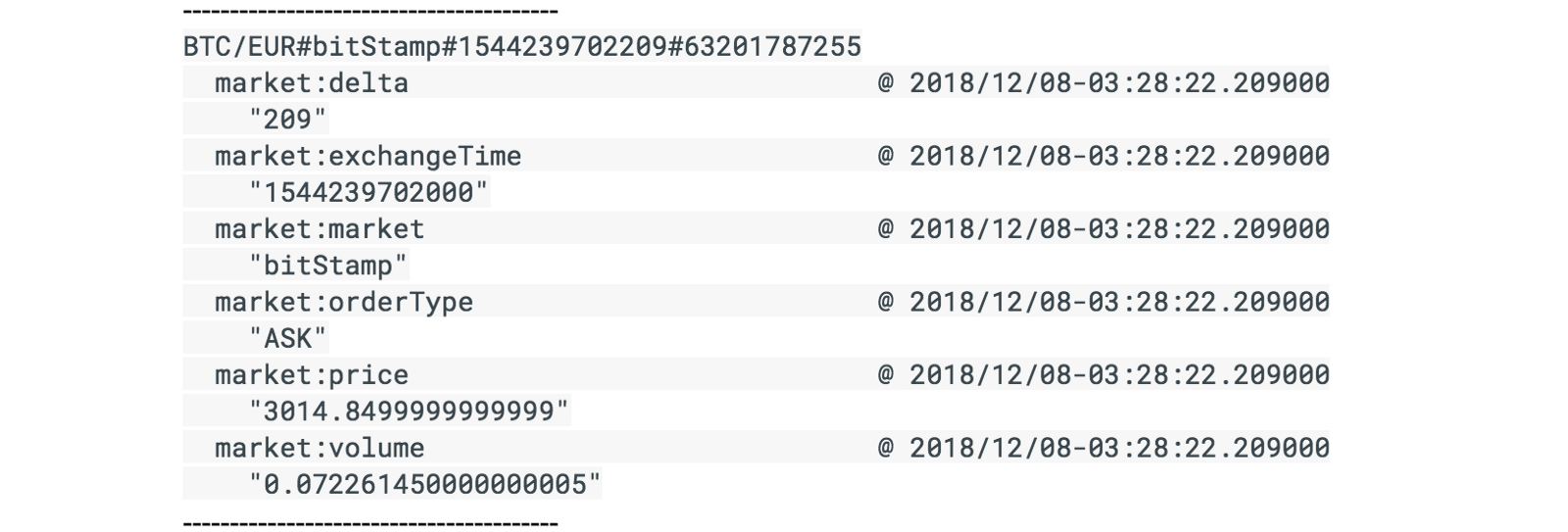
Click Check my progress to verify the objective.
Task 2. Examine the Dataflow pipeline
-
In the Cloud Platform Console, on the Navigation menu, click Dataflow.
-
Click the name of the existing pipeline.
You should see the status as Running for the listed jobs.
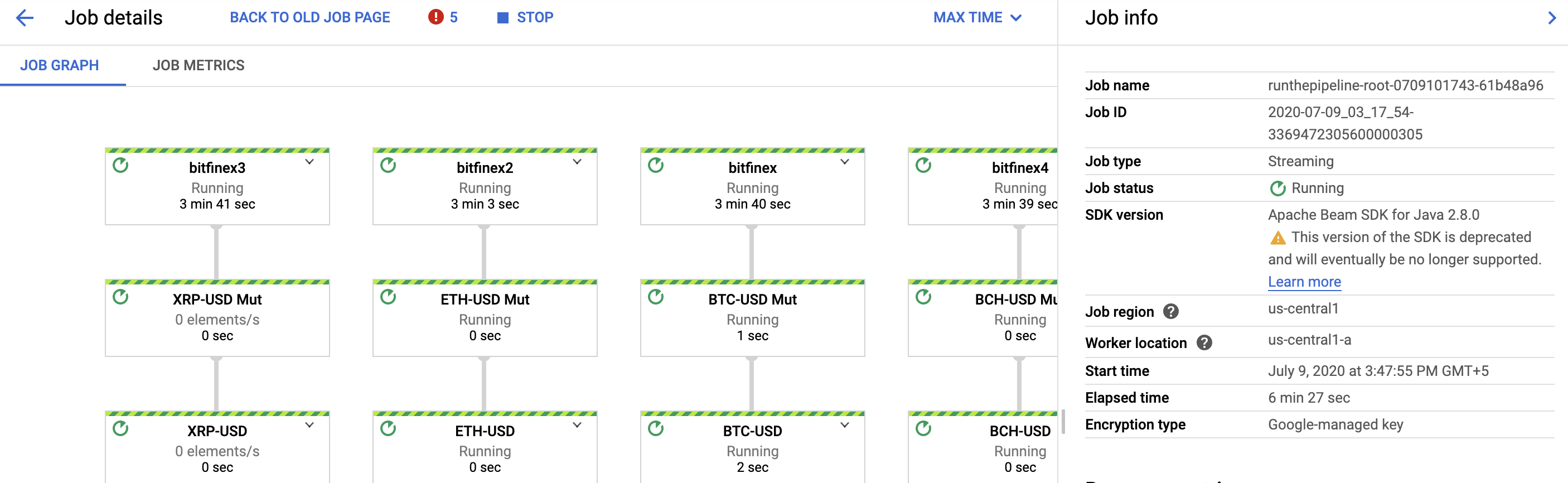
Task 3. Visualizing the data
You will configure the environment and run the python Flask frontend server visualization in these next steps.
- Go back to the SSH session and run the following command to open firewall port 5000 for visualization:
- Now link the VM with the firewall rule:
Click Check my progress to verify the objective.
- Next, navigate to the
frontenddirectory:
If prompted Proceed (Y/n)?, press Y.
app.py is a Python application to visualize the Crypto currency data stored in the Bigtable table “cryptorealtime”.
- Open another SSH session and run the following command to find your external IP address for the
crypto-driverinstance:
-
Copy the EXTERNAL IP address displayed to use for the next command.
-
Open a new tab in your web browser and use the following URL to see the visualization, replacing
<external-ip>with the IP address returned from the previous command:
You should see the visualization of aggregated ASK/BID pair on several exchanges (without predictor part).
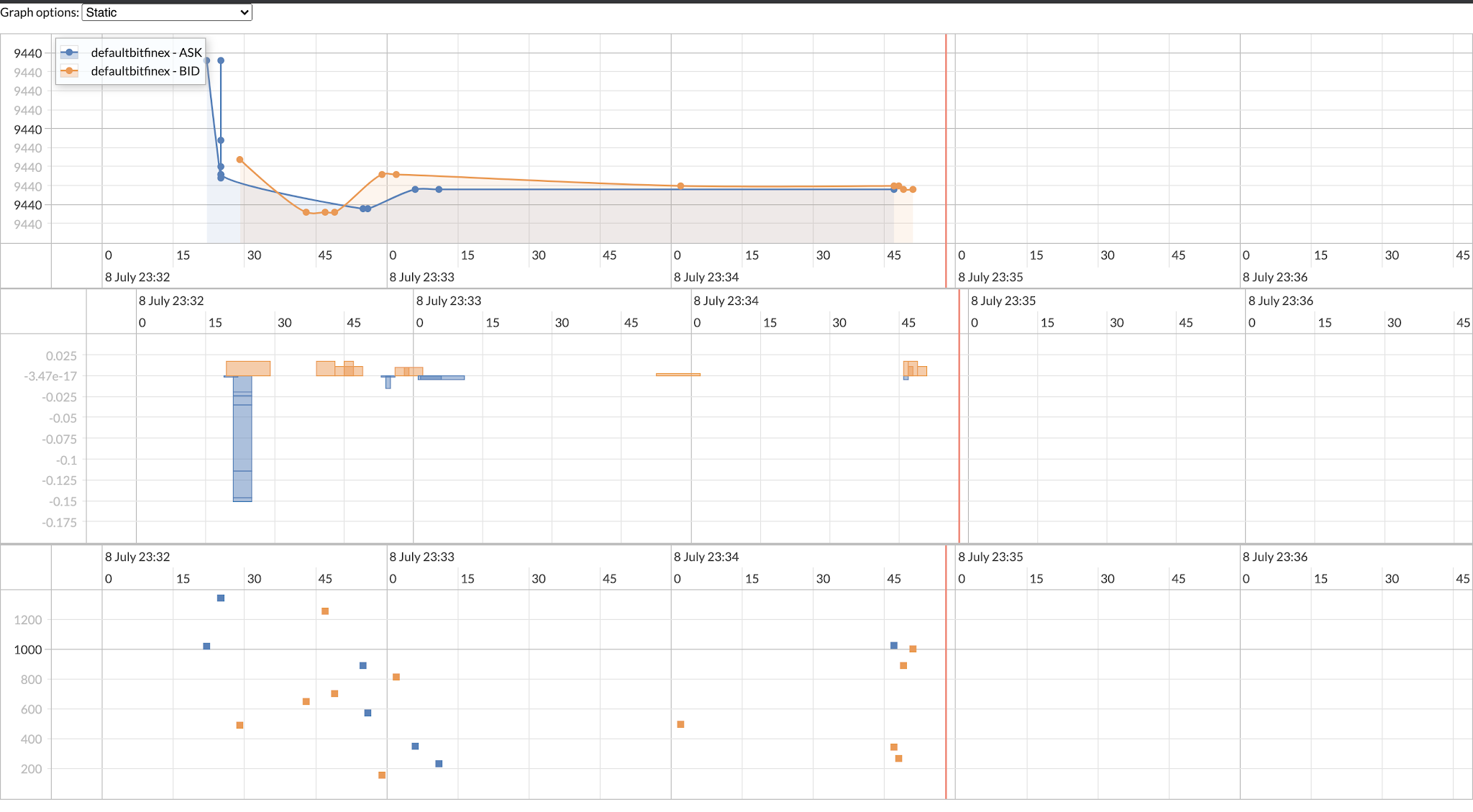
You have created a real-time "periscope" multi-exchange observer.
Task 4. Clean up
When you end this lab, the lab platform deletes the resources you used. In your own environment, it is useful to know how to save costs by cleaning up your unused, or no longer required, resources.
- You can stop the pipeline in either the Console or in the SSH session. It takes a few minutes with either method.
-
Console: Return to Dataflow page, click on the name of your job and click Stop. Select Cancel, then Stop Job.
-
Inside the second SSH session run:
gcloud dataflow jobs cancel \ $(gcloud dataflow jobs list \ --format='value(id)' \ --filter="name:runthepipeline*" \ --region="us-central1") When the pipeline stops, return to the command line in the SSH session by pressing CTRL+C.
- Inside the SSH session run the following commands to empty and delete the bucket. Replace with your your Project ID:
- Inside the SSH session run the following command to delete the Bigtable instance:
-
If prompted,
Do you want to continue (Y/n), press Y. -
Close the SSH console.
-
In the Cloud Platform Console, on the Navigation menu, click Compute Engine > VM Instances.
-
Check the box next to the crypto-driver instance then click Delete, then Delete again to confirm your action.
Congratulations!
You have learned how to do the following:
-
Set up and configure a pipeline for ingesting real-time time-series data from various crypto exchanges.
-
Design a suitable data model, which facilitates querying and graphing at scale.
-
Set up and deploy the proposed architecture using Google Cloud.
You established a connection to multiple exchanges, subscribed to their trade feed, then extracted and transformed these trades into a flexible format to be stored in Bigtable to be graphed and analyzed.
Next steps/ Learn more
This lab is based on this Medium article by Ivo Galic.
Google Cloud training and certification
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Tested January 22, 2024
Manual Last Updated January 22, 2024
Copyright 2024 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.

