Checkpoints
Create a development machine in Compute Engine
/ 5
Install Software in the development machine
/ 5
Create a GCS bucket
/ 5
Download some sample images into your bucket
/ 5
Create a Cloud Dataproc cluster
/ 5
Submit your job to Cloud Dataproc
/ 5
Processamento distribuído de imagens no Cloud Dataproc
- GSP010
- Visão geral
- Instalação
- Introdução
- Tarefa 1. Crie uma máquina de desenvolvimento no Compute Engine
- Tarefa 2. Instale o software
- Tarefa 3. Crie um bucket do Cloud Storage e colete imagens
- Tarefa 4. Crie um cluster do Cloud Dataproc
- Tarefa 5. Envie o job ao Cloud Dataproc
- Tarefa 6. Teste seu conhecimento
- Parabéns!
GSP010

Visão geral
Neste laboratório prático, você aprenderá a usar o Apache Spark no Cloud Dataproc para distribuir uma tarefa de processamento de imagens com alta demanda computacional em um cluster de máquinas. Este laboratório faz parte de uma série de laboratórios sobre processamento de dados científicos.
Conteúdo
- Como criar um cluster gerenciado do Cloud Dataproc com o Apache Spark pré-instalado
- Como criar e executar jobs que usam pacotes externos que não estão instalados no cluster
- Como encerrar o cluster
Pré-requisitos
Este é um laboratório de nível avançado. Recomendamos ter experiência com o Cloud Dataproc e o Apache Spark, mas isso não é obrigatório. Para aprender a usar esses serviços, confira os laboratórios a seguir:
- Dataproc: Qwik Start - linha de comando
- Dataproc: Qwik Start - console
- Introdução ao Cloud Dataproc: Hadoop e Spark no Google Cloud
Quando estiver tudo pronto, role a tela para baixo para conhecer melhor os serviços que você usará no laboratório.
Instalação
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você vai encontrar o seguinte:
- O botão Abrir console do Google Cloud
- O tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
-
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima.
O laboratório ativa os recursos e depois abre a página Fazer login em outra guia.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta. -
Se necessário, copie o Nome de usuário abaixo e cole na caixa de diálogo Fazer login.
{{{user_0.username | "Nome de usuário"}}} Você também encontra o Nome de usuário no painel Detalhes do laboratório.
-
Clique em Seguinte.
-
Copie a Senha abaixo e cole na caixa de diálogo de boas-vindas.
{{{user_0.password | "Senha"}}} Você também encontra a Senha no painel Detalhes do laboratório.
-
Clique em Seguinte.
Importante: você precisa usar as credenciais fornecidas no laboratório, e não as da sua conta do Google Cloud. Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais. -
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do Google Cloud será aberto nesta guia.

Introdução
Com o Cloud Dataproc, um serviço Spark e Hadoop gerenciado, você pode usar ferramentas de dados de código aberto para processamento em lote, consultas, streaming e machine learning. A automação do Cloud Dataproc facilita a criação e o gerenciamento de clusters. Ela também gera economia porque permite desativar os clusters que não estão em uso. Com menos tempo e dinheiro gastos com administração, você pode se concentrar nos jobs e dados.
Use o Cloud Dataproc para o escalonamento horizontal de jobs com alta demanda computacional e que têm estas características:
- O job é totalmente paralelo, ou seja, é possível processar cada subconjunto de dados em uma máquina diferente.
- Você tem um código do Apache Spark que faz a computação ou já tem experiência com o Apache Spark.
- A distribuição do trabalho é bastante uniforme entre os subconjuntos de dados.
Quando cada subconjunto exige um nível diferente de processamento (ou para pessoas sem experiência com o Apache Spark), o Apache Beam no Cloud Dataflow é uma boa alternativa porque ele tem pipelines de dados com escalonamento automático.
Neste laboratório, você executará um job que desenha os rostos na imagem usando um conjunto de regras de processamento especificadas no OpenCV. É melhor usar a API Vision para fazer isso, porque regras com códigos escritos manualmente não funcionam muito bem, mas este laboratório mostra como executar um job com alta demanda computacional de maneira distribuída.
Tarefa 1. Crie uma máquina de desenvolvimento no Compute Engine
Primeiro, você precisa criar a máquina virtual para hospedar os serviços.
- No console do Cloud, acesse Compute Engine > Instâncias de VM > Criar instância.

-
Configure os campos indicados abaixo e mantenha o valor padrão dos outros:
-
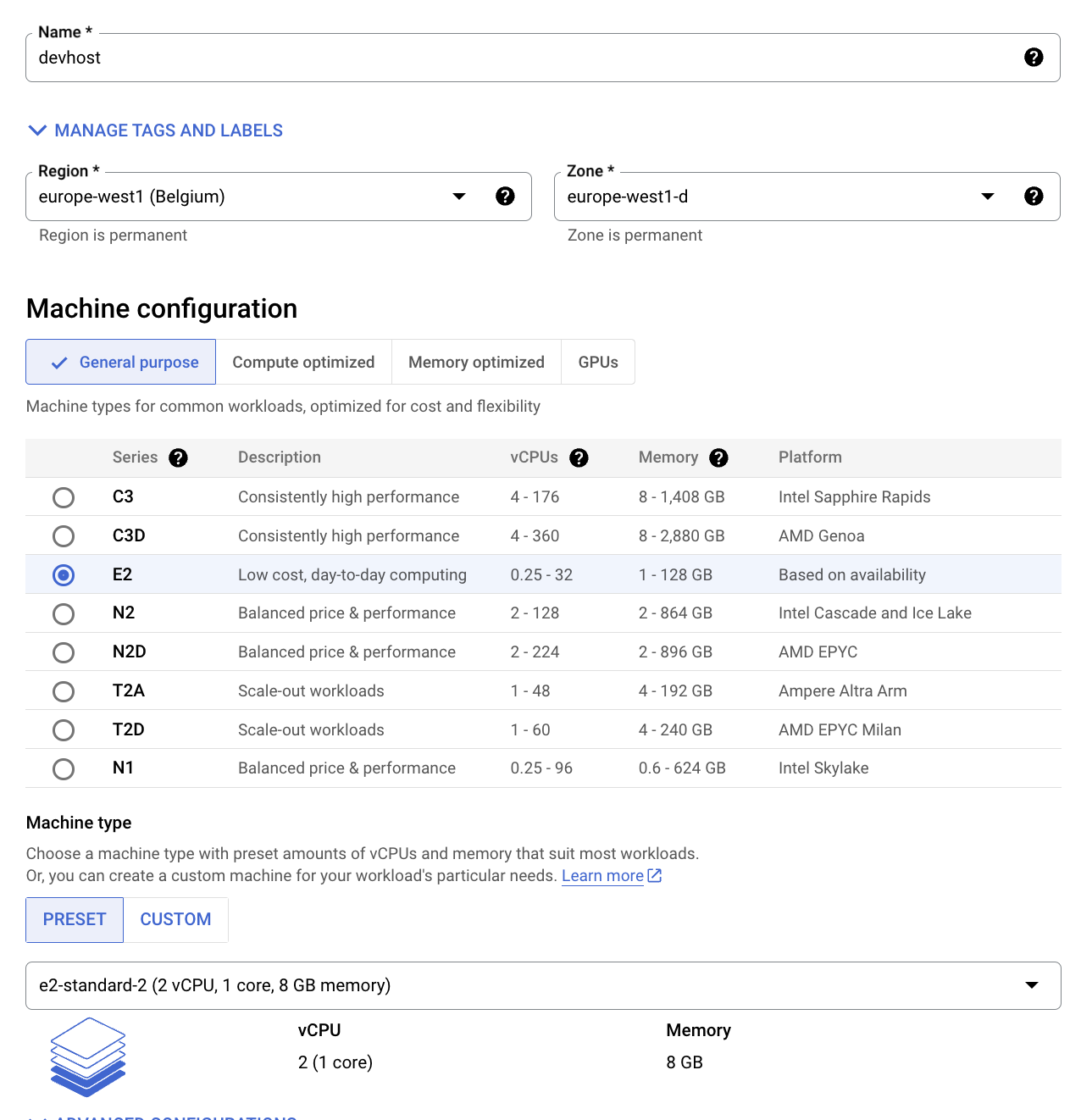
Nome: devhost
-
Série: N1
-
Tipo de máquina: 2 vCPUs (instância n1-standard-2)
-
Identidade e acesso à API: permitir acesso completo a todas as APIs do Cloud.
-
-
Clique em Criar. Esse será seu "Bastion Host" de desenvolvimento.
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada. Se você concluiu a tarefa, receberá uma pontuação de avaliação.
- Clique no botão SSH do console para acessar a instância pelo SSH.
Tarefa 2. Instale o software
Agora configure o software que executará o job. Usando o sbt, uma ferramenta de build de código aberto, você criará o arquivo JAR do job que será enviado ao cluster do Cloud Dataproc. O arquivo JAR contém o programa e os pacotes necessários para executar o job. O job detectará rostos em um conjunto de arquivos de imagens armazenado em um bucket do Google Cloud Storage. Depois, ele gravará arquivos de imagem com os rostos desenhados no mesmo bucket ou em outro.
- Configure o "Scala" e o "sbt". Na janela do SSH, execute os comandos abaixo para instalar o
Scalae osbte poder compilar o código:
Agora crie os arquivos do Feature Detector. O código deste laboratório é uma pequena modificação de uma solução que existe no repositório do Cloud Dataproc no GitHub. Depois de fazer o download do código, abra o diretório deste laborátorio com o comando cd e crie um arquivo JAR completo (ou "fat JAR") do Feature Detector para poder enviá-lo ao Cloud Dataproc.
- Execute os comandos abaixo na janela do SSH:
- Faça a compilação. Este comando cria um arquivo "fat JAR" do Feature Detector para poder enviá-lo ao Cloud Dataproc:
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada. Se você concluiu a tarefa, receberá uma pontuação de avaliação.
Tarefa 3. Crie um bucket do Cloud Storage e colete imagens
Agora que você criou os arquivos do Feature Detector, crie um bucket do Cloud Storage e adicione algumas imagens de amostra.
- Descubra o "ID do projeto" para usá-lo no nome do bucket:
- Dê um nome ao bucket e defina uma variável de shell com esse nome. A variável de shell será usada nos comandos para indicar o bucket:
- Use o programa
gsutil, que faz parte dogcloudno SDK Cloud, para criar o bucket que armazenará as imagens de amostra:
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada. Se você tiver concluído a tarefa, receberá uma pontuação de avaliação.
- Faça o download de algumas imagens de amostra para o bucket:
Você fez o download dessas imagens para o bucket do Cloud Storage:



Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada. Se você concluiu a tarefa, receberá uma pontuação de avaliação.
- Execute este comando para mostrar o conteúdo do bucket:
Saída:
Tarefa 4. Crie um cluster do Cloud Dataproc
- Execute os comandos abaixo na janela do SSH para dar um nome ao cluster e definir a variável
MYCLUSTER. Você usará a variável nos comandos para indicar o cluster:
- Defina uma região global do Compute Engine e crie um novo cluster:
- Se for preciso usar uma zona em vez de uma região, digite Y.
Talvez o processo demore alguns minutos. As configurações padrão de cluster, que incluem dois nós de trabalho, devem ser suficientes para o laboratório. Usamos n1-standard-2 como os tipos de máquinas worker e mestre para reduzir o número geral de núcleos que o cluster usa.
Para a flag initialization-actions, transmita um script que instala a biblioteca libgtk2.0-dev em cada máquina de cluster. As bibliotecas são necessárias para executar o aplicativo.
gcloud dataproc clusters delete ${MYCLUSTER}) e tente novamente o comando de criação de cluster anterior.
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada. Se você concluiu a tarefa, receberá uma pontuação de avaliação.
Tarefa 5. Envie o job ao Cloud Dataproc
Neste laboratório, o programa em execução será usado como detector facial. Por isso, o classificador haar inserido precisa descrever um rosto. O classificador haar é um arquivo XML usado para descrever os recursos que o programa deve detectar. Faça o download do arquivo do classificador "haar" e inclua o caminho dele para o Cloud Storage no primeiro argumento quando enviar o job para o cluster do Cloud Dataproc.
- Execute o comando a seguir na janela do SSH para carregar o arquivo de configuração de detecção facial no bucket:
- Use o conjunto de imagens que você enviou para o diretório
imgsdo bucket do Cloud Storage como entrada para o Feature Detector. Você precisa incluir o caminho para esse diretório como o segundo argumento no comando de envio do job.
- Envie o job ao Cloud Dataproc:
Você pode adicionar outras imagens ao bucket do Cloud Storage especificado no segundo argumento.
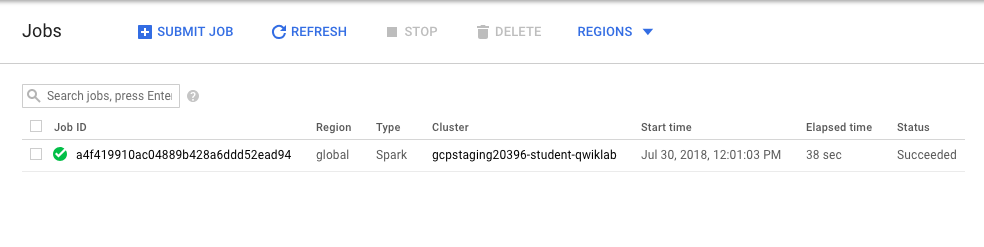
- Monitore o job. No console, acesse Menu de navegação > Dataproc > Jobs.
Passe para a próxima etapa quando você receber uma saída como esta:
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada. Se você concluiu a tarefa, receberá uma pontuação de avaliação.
-
Quando o job for concluído, acesse Menu de navegação > Cloud Storage e clique no bucket que você criou. O nome dele é seu nome de usuário seguido por
student-imagee um número aleatório. -
Clique em uma imagem do diretório Out.
-
Clique no ícone de Download para fazer o download da imagem para seu computador.
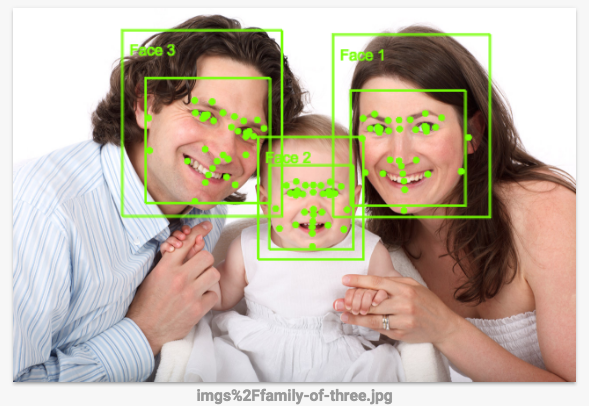
Qual é a precisão da detecção facial? É melhor usar a API Vision para fazer isso, porque regras manuais não funcionam muito bem. Confira a seguir como a detecção funciona.
-
Acesse a pasta
imgsdo seu bucket e clique nas outras imagens que você carregou. O download das três imagens de amostra começará. Salve as imagens no computador. -
Clique neste link para acessar a página da API Vision. Role a tela para baixo até a seção Try the API e faça upload das imagens que você armazenou no bucket. Você verá o resultado da detecção de imagem em alguns segundos. Como os modelos de machine learning usados são continuamente aprimorados, talvez seus resultados sejam diferentes:


- Se você quiser fazer melhorias no Feature Detector, altere o código
FeatureDetectore execute novamente os comandossbt assembly,gcloud dataprocejobs submit.
Tarefa 6. Teste seu conhecimento
Responda às perguntas de múltipla escolha a seguir para reforçar sua compreensão dos conceitos abordados neste laboratório. Use tudo o que você aprendeu até aqui.
Parabéns!
Você aprendeu a ativar um cluster do Cloud Dataproc e executar jobs.
Termine a Quest
Este laboratório autoguiado faz parte da Quest Scientific Data Processing. Uma Quest é uma série de laboratórios relacionados que formam um programa de aprendizado. Ao concluir uma Quest, você ganha um selo como reconhecimento da sua conquista. É possível publicar os selos e incluir um link para eles no seu currículo on-line ou nas redes sociais. Inscreva-se nesta Quest e receba o crédito de conclusão imediatamente. Consulte todas as Quests disponíveis no catálogo do Google Cloud Ensina.
Comece o próximo laboratório
Continue a Quest com o laboratório Como analisar dados de natalidade com o Datalab e o BigQuery ou tente uma destas opções:
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 18 de julho de 2023
Laboratório testado em 18 de julho de 2023
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.

