Puntos de control
Create a development machine in Compute Engine
/ 5
Install Software in the development machine
/ 5
Create a GCS bucket
/ 5
Download some sample images into your bucket
/ 5
Create a Cloud Dataproc cluster
/ 5
Submit your job to Cloud Dataproc
/ 5
Procesamiento distribuido de imágenes en Cloud Dataproc
- GSP010
- Descripción general
- Configuración
- Introducción
- Tarea 1: Crea una máquina de desarrollo en Compute Engine
- Tarea 2: Instala el software
- Tarea 3: Crea un bucket de Cloud Storage y recopila imágenes
- Tarea 4: Crea un clúster de Cloud Dataproc
- Tarea 5: Envía tu trabajo a Cloud Dataproc
- Tarea 6: Pon a prueba tus conocimientos
- ¡Felicitaciones!
GSP010

Descripción general
En este lab práctico, aprenderás a usar Apache Spark en Cloud Dataproc para distribuir una tarea de procesamiento de imágenes intensiva desde un punto de vista informático en un clúster de máquinas. Este lab es parte de una serie de labs sobre procesamiento de datos científicos.
Aprendizajes esperados
- Cómo crear un clúster de Cloud Dataproc administrado con Apache Spark preinstalado
- Cómo compilar y ejecutar trabajos que usan paquetes externos aún no instalados en su clúster
- Cómo cerrar su clúster
Requisitos previos
Este es un lab de nivel avanzado. Se recomienda estar familiarizado con Cloud Dataproc y Apache Spark, aunque no es obligatorio. Si quieres ponerte al día con estos servicios, asegúrate de consultar los siguientes labs:
- Dataproc: Qwik Start - Línea de comandos
- Dataproc: Qwik Start - Console
- Introducción a Cloud Dataproc: Hadoop y Spark en Google Cloud
Cuando tengas todo listo, desplázate hacia abajo para obtener más información sobre los servicios que usarás en este lab.
Configuración
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab: Recuerda que, una vez que comienzas un lab, no puedes pausarlo.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haga clic en el botón Comenzar lab. Si debe pagar por el lab, se abrirá una ventana emergente para que seleccione su forma de pago. A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón Abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debe usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordene las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta. -
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}} También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}} También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud. Nota: Usar tu propia Cuenta de Google podría generar cargos adicionales. -
Haga clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.

Introducción
Cloud Dataproc es un servicio administrado de Spark y Hadoop con el que puedes aprovechar herramientas de datos de código abierto para procesamientos por lotes, consultas, transmisiones y aprendizaje automático. Con la automatización de Cloud Dataproc, podrás crear clústeres rápidamente, administrarlos con facilidad y ahorrar dinero desactivándolos cuando no los necesites. Al invertir menos tiempo y dinero en tareas de administración, podrás enfocarte en tus trabajos y datos.
Procura usar Cloud Dataproc para escalar horizontalmente trabajos de procesamiento intensivo que cumplan con estas características:
- El trabajo es embarazosamente paralelo; es decir, puedes procesar diferentes subconjuntos de datos en distintas máquinas.
- Ya tienes el código de Apache Spark que realiza el procesamiento o ya estás familiarizado con Apache Spark.
- La distribución del trabajo es bastante uniforme en todos tus subconjuntos de datos.
Si los diferentes subconjuntos requieren distinta cantidad de procesamiento (o si todavía no conoces Apache Spark), Apache Beam en Cloud Dataflow es una alternativa interesante porque proporciona canalizaciones de datos con ajuste de escala automático.
En este lab, el trabajo que ejecutarás marca los contornos de los rostros de una imagen mediante un conjunto de reglas de procesamiento de imagen especificado en OpenCV. Usar la API de Vision es una manera más eficaz de hacer esto, ya que ese tipo de reglas codificadas a mano no funcionan demasiado bien, pero este lab es un ejemplo de cómo realizar un trabajo de procesamiento intensivo de forma distribuida.
Tarea 1: Crea una máquina de desarrollo en Compute Engine
Primero, crea una máquina virtual para alojar tus servicios.
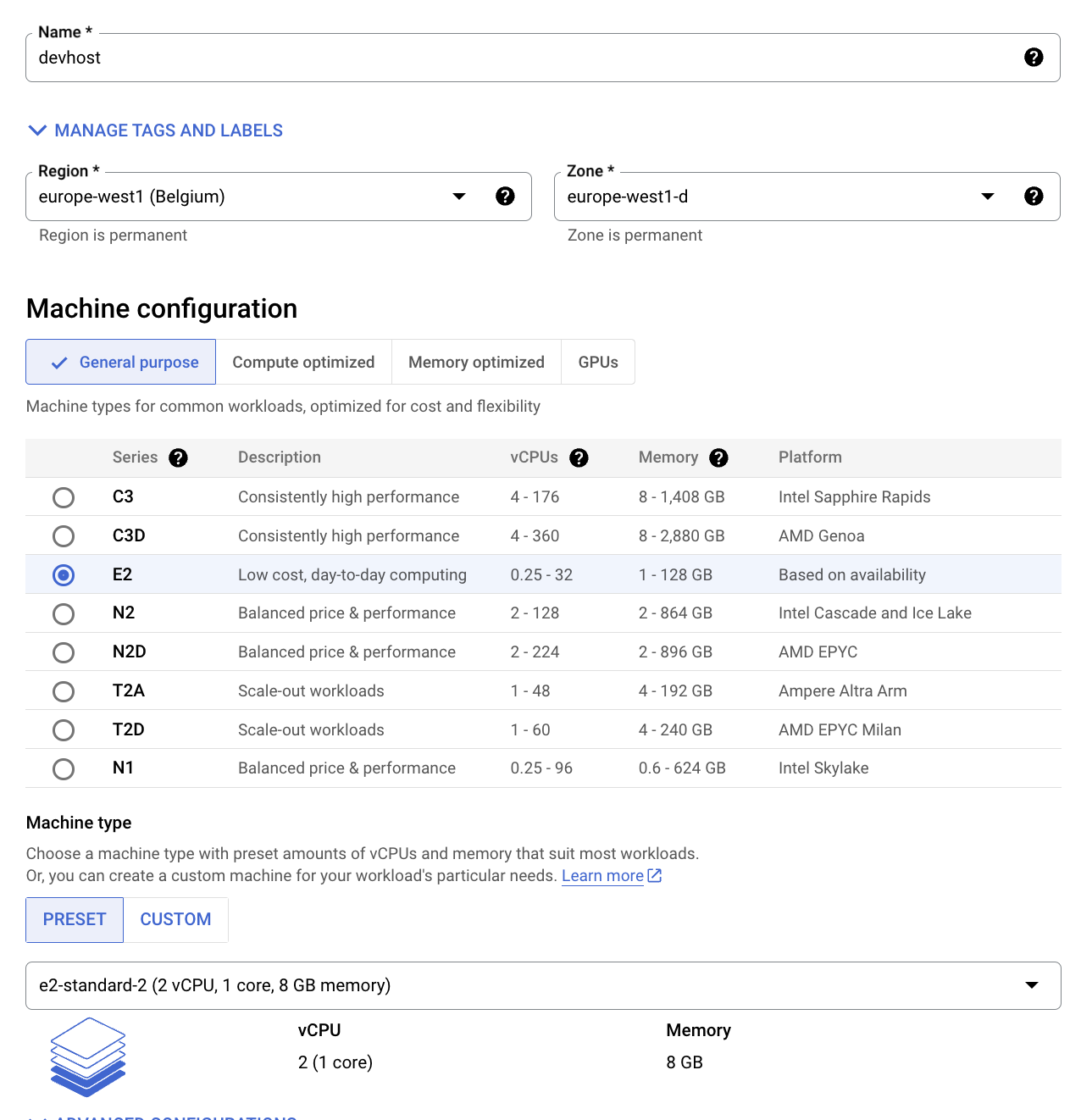
- En la consola de Cloud, ve a Compute Engine > Instancias de VM > Crear instancia.

-
Configura los siguientes campos y deja los demás con sus valores predeterminados:
-
Nombre: devhost
-
Serie: N1
-
Tipo de máquina: 2 CPU virtuales (instancia n1-standard-2)
-
Identidad y acceso a la API: Permitir el acceso total a todas las APIs de Cloud
-
-
Haz clic en Crear. Esta máquina funcionará como host “de bastión” de desarrollo.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará un puntaje de evaluación.
- Establece una conexión SSH a la instancia haciendo clic en el botón SSH de la consola.
Tarea 2: Instala el software
Ahora, configura el software para que ejecute el trabajo. Mediante sbt, una herramienta de compilación de código abierto, compilarás el archivo JAR para el trabajo que enviarás al clúster de Cloud Dataproc. Ese archivo contendrá el programa y los paquetes obligatorios necesarios para ejecutar el trabajo. El trabajo detectará los rostros de un conjunto de archivos de imagen almacenado en un bucket de Cloud Storage y escribirá archivos de imagen con el contorno de los rostros en el mismo bucket de Cloud Storage o en otro.
- Configura Scala y sbt. En la ventana de SSH, instala
Scalaysbtcon los siguientes comandos para poder compilar el código:
Ahora, compilarás los archivos del detector de rasgos. El código de este lab corresponde a una leve modificación de una solución que existe en el repositorio de Cloud Dataproc en GitHub. Descargarás el código y, luego, ejecutarás cd en el directorio de este lab y compilarás un archivo “fat JAR” del detector de rasgos para poder enviarlo a Cloud Dataproc.
- Ejecuta los siguientes comandos en la ventana de SSH:
- Inicia la compilación. Con este comando, se compila un archivo “fat JAR” del detector de rasgos para poder enviarlo a Cloud Dataproc:
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará un puntaje de evaluación.
Tarea 3: Crea un bucket de Cloud Storage y recopila imágenes
Ahora que ya compilaste los archivos del detector de rasgos, crea un bucket de Cloud Storage y agrega algunas imágenes de muestra.
- Recupera el ID del proyecto que se usará para asignarle un nombre a tu bucket:
- Asígnale un nombre a tu bucket y establece en ese nombre una variable de shell, que se usará en comandos que hagan referencia a él:
- Usa el programa
gsutil, que se incluye congclouden el SDK de Cloud, para crear un bucket que contenga tus imágenes de muestra:
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará un puntaje de evaluación.
- Descarga algunas imágenes de muestra en tu bucket:
Acabas de descargar las siguientes imágenes en tu bucket de Cloud Storage:



Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará un puntaje de evaluación.
- Ejecuta el siguiente comando para ver el contenido del bucket:
Resultado:
Tarea 4: Crea un clúster de Cloud Dataproc
- Ejecuta los siguientes comandos en la ventana de SSH para asignarle un nombre al clúster y configurar la variable
MYCLUSTER. Usarás la variable en comandos para hacer referencia al clúster:
- Establece una región global de Compute Engine para crear y usar un nuevo clúster:
- Si se te solicita usar una zona en lugar de una región, ingresa Y.
Esto podría tardar unos minutos. La configuración predeterminada del clúster, que incluye dos nodos trabajadores, debería ser suficiente para este lab. Para reducir la cantidad general de núcleos que usa el clúster, se especifica n1-standard-2 como el tipo de máquina de instancia principal y de trabajador.
Para la marca initialization-actions, pasarás una secuencia de comandos que instala la biblioteca libgtk2.0-dev en cada una de tus máquinas de clústeres. Esta biblioteca se necesitará para ejecutar el código.
gcloud dataproc clusters delete ${MYCLUSTER}) y, luego, vuelve a ejecutar el comando anterior de creación de clúster.
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará un puntaje de evaluación.
Tarea 5: Envía tu trabajo a Cloud Dataproc
En este lab, el programa que ejecutas se usa como un detector de rostros, por lo que el clasificador haar ingresado debe describir un rostro. Un clasificador haar es un archivo XML que se usa para describir rasgos que detectará el programa. Descargarás el archivo del clasificador haar y, luego, incluirás su ruta de Cloud Storage en el primer argumento cuando envíes tu trabajo al clúster de Cloud Dataproc.
- Ejecuta el siguiente comando en la ventana de SSH para cargar el archivo de configuración de detección de rostro en tu bucket:
- Usa el conjunto de imágenes que subiste al directorio
imgsen el bucket de Cloud Storage como datos de entrada para el detector de rasgos. Debes incluir la ruta a ese directorio como segundo argumento del comando de envío de trabajos.
- Envía tu trabajo a Cloud Dataproc:
Puedes agregar otras imágenes al bucket de Cloud Storage especificado en el segundo argumento.
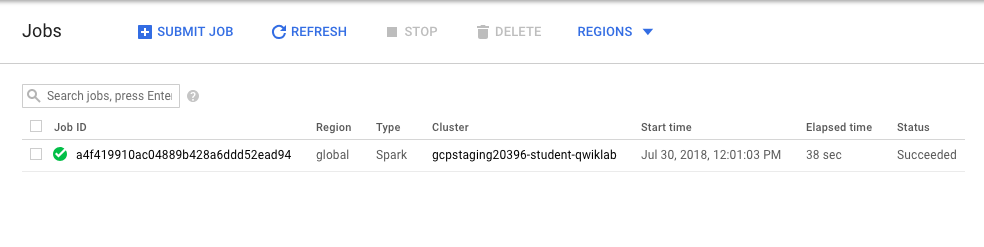
- Supervisa el trabajo. En la consola, ve al menú de navegación > Dataproc > Trabajos.
Continúa con el próximo paso cuando obtengas un resultado similar al siguiente:
Prueba la tarea completada
Haz clic en Revisar mi progreso para verificar la tarea realizada. Si la completaste correctamente, se te otorgará un puntaje de evaluación.
-
Cuando se complete el trabajo, ve al menú de navegación > Cloud Storage. Busca el bucket que creaste (tendrá tu nombre de usuario seguido de
student-imagey de un número aleatorio) y haz clic en él. -
Haz clic en la imagen del directorio Out.
-
Haz clic en el ícono Descargar, la imagen se descargará en tu computadora.
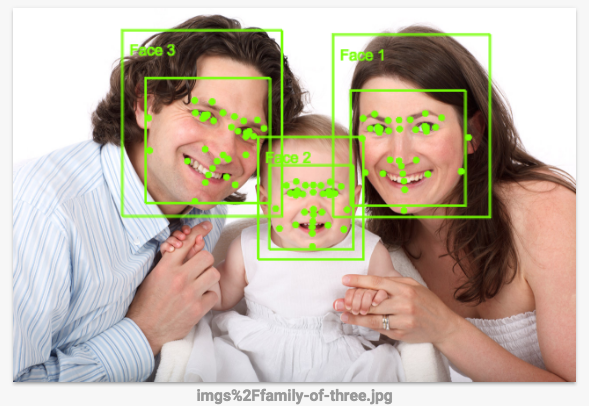
¿Qué tan exacta es la detección de rostros? Usar la API de Vision es una manera más efectiva de hacer esto, ya que este tipo de reglas codificadas a mano no funcionan demasiado bien. A continuación, podrás ver cómo funciona.
-
En tu bucket, ve a la carpeta
imgsy haz clic en las otras imágenes que subiste al bucket (opcional). Se descargarán las tres imágenes de muestra. Guárdalas en tu computadora. -
Haz clic en este vínculo para ir a la página de la API de Vision, desplázate hacia abajo hasta la sección Probar la API y sube las imágenes que descargaste de tu bucket. En apenas segundos, verás los resultados de la detección de imagen. Dado que los modelos subyacentes de aprendizaje automático mejoran constantemente, es posible que los resultados difieran:


- Si quieres experimentar y mejorar el detector de rasgos, puedes realizar cambios en el código
FeatureDetectory, luego, volver a ejecutarsbt assemblyy los comandosgcloud dataprocyjobs submit(opcional).
Tarea 6: Pon a prueba tus conocimientos
A continuación, se presentan algunas preguntas de opción múltiple para reforzar tus conocimientos de los conceptos de este lab. Trata de responderlas lo mejor posible.
¡Felicitaciones!
Aprendiste a iniciar un clúster de Cloud Dataproc y a ejecutar trabajos.
Finaliza la Quest
Este lab de autoaprendizaje forma parte de la Quest Scientific Data Processing. Una Quest es una serie de labs relacionados que forman una ruta de aprendizaje. Si completas esta Quest, obtendrás una insignia como reconocimiento por tu logro. Puedes hacer públicas tus insignias y agregar vínculos a ellas en tu currículum en línea o en tus cuentas de redes sociales. Inscríbete en esta Quest y obtén un crédito inmediato de realización. Consulta el catálogo de Google Cloud Skills Boost para ver todas las Quests disponibles.
Realiza tu próximo lab
Continúa tu Quest con Análisis de datos de natalidad mediante Datalab y BigQuery o prueba una de los siguientes labs:
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 18 de julio de 2023
Prueba más reciente del lab: 18 de julio de 2023
Copyright 2024 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.

