Points de contrôle
Create a development machine in Compute Engine
/ 5
Install Software in the development machine
/ 5
Create a GCS bucket
/ 5
Download some sample images into your bucket
/ 5
Create a Cloud Dataproc cluster
/ 5
Submit your job to Cloud Dataproc
/ 5
Traitement des images distribué dans Cloud Dataproc
- GSP010
- Aperçu
- Prérequis
- Introduction
- Tâche 1 : Créer un ordinateur de développement dans Compute Engine
- Tâche 2 : Installer le logiciel
- Tâche 3 : Créer un bucket Cloud Storage et collecter des images
- Tâche 4 : Créer un cluster Cloud Dataproc
- Tâche 5 : Envoyer votre job à Cloud Dataproc
- Tâche 6 : Tester vos connaissances
- Félicitations !
GSP010

Aperçu
Dans cet atelier pratique, vous allez apprendre à utiliser Apache Spark dans Cloud Dataproc pour distribuer une tâche de traitement d'images utilisant beaucoup de ressources de calcul sur un cluster de machines. Cet atelier fait partie d'une série portant sur le traitement de données scientifiques.
Objectifs de l'atelier
- Créer un cluster Cloud Dataproc géré avec Apache Spark pré-installé
- Créer et exécuter des jobs utilisant des packages externes qui ne sont pas encore installés sur votre cluster
- Arrêter votre cluster
Prérequis
Cet atelier est d'un niveau avancé. Une connaissance préalable de Cloud Dataproc et d'Apache Spark est recommandée, mais pas indispensable. Si vous souhaitez maîtriser ces services rapidement, reportez-vous aux ateliers suivants :
- Dataproc : Qwik Start – Ligne de commande
- Dataproc : Qwik Start – Console
- Présentation de Cloud Dataproc : Hadoop et Spark sur Google Cloud
Faites défiler la page vers le bas pour en savoir plus sur les services que vous utiliserez lors de cet atelier.
Prérequis
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- vous disposez d'un temps limité ; une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google Cloud
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google Cloud (ou effectuez un clic droit et sélectionnez Ouvrir le lien dans la fenêtre de navigation privée si vous utilisez le navigateur Chrome).
L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte. -
Si nécessaire, copiez le nom d'utilisateur ci-dessous et collez-le dans la boîte de dialogue Se connecter.
{{{user_0.username | "Username"}}} Vous trouverez également le nom d'utilisateur dans le panneau Détails concernant l'atelier.
-
Cliquez sur Suivant.
-
Copiez le mot de passe ci-dessous et collez-le dans la boîte de dialogue Bienvenue.
{{{user_0.password | "Password"}}} Vous trouverez également le mot de passe dans le panneau Détails concernant l'atelier.
-
Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis pour l'atelier. Ne saisissez pas ceux de votre compte Google Cloud. Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés. -
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas à des essais gratuits.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.

Introduction
Cloud Dataproc est un service géré Spark et Hadoop qui vous permet de bénéficier d'outils de données Open Source pour le traitement par lot, l'émission de requêtes, le streaming et le machine learning. L'automatisation Cloud Dataproc vous permet de créer des clusters rapidement, de les gérer facilement et de faire des économies en désactivant ceux que vous n'utilisez plus. Vous consacrez moins de temps et d'argent aux fonctions d'administration, ce qui vous permet de vous concentrer sur les jobs et les données.
Vous pouvez utiliser Cloud Dataproc pour distribuer les jobs utilisant beaucoup de ressources de calcul et répondant à ces critères :
- Il s'agit d'un job à parallélisme embarrassant : vous pouvez traiter plusieurs sous-ensembles de données sur différentes machines.
- Vous disposez déjà d'un code Apache Spark effectuant les calculs ou vous connaissez bien Apache Spark.
- La répartition du travail entre vos sous-ensembles de données est relativement uniforme.
Si différents sous-ensembles nécessitent des volumes d'opérations de traitement différents (ou si vous ne connaissez pas encore Apache Spark), Apache Beam sur Cloud Dataflow est une alternative séduisante, car cet outil offre des pipelines de données avec autoscaling.
Dans cet atelier, le job à exécuter marque les contours des visages sur l'image à l'aide d'un ensemble de règles de traitement d'images spécifiées dans OpenCV. L'API Vision est une option plus performante, du fait que ce type de règles codées manuellement ne fonctionne pas très bien. Cet atelier fournit un exemple d'exécution distribuée d'un job utilisant beaucoup de ressources de calcul.
Tâche 1 : Créer un ordinateur de développement dans Compute Engine
Commencez par créer une machine virtuelle pour héberger vos services.
- Dans la console Cloud, accédez à Compute Engine > Instances de VM > Créer une instance.

-
Configurez les champs suivants et conservez la valeur par défaut pour les autres :
-
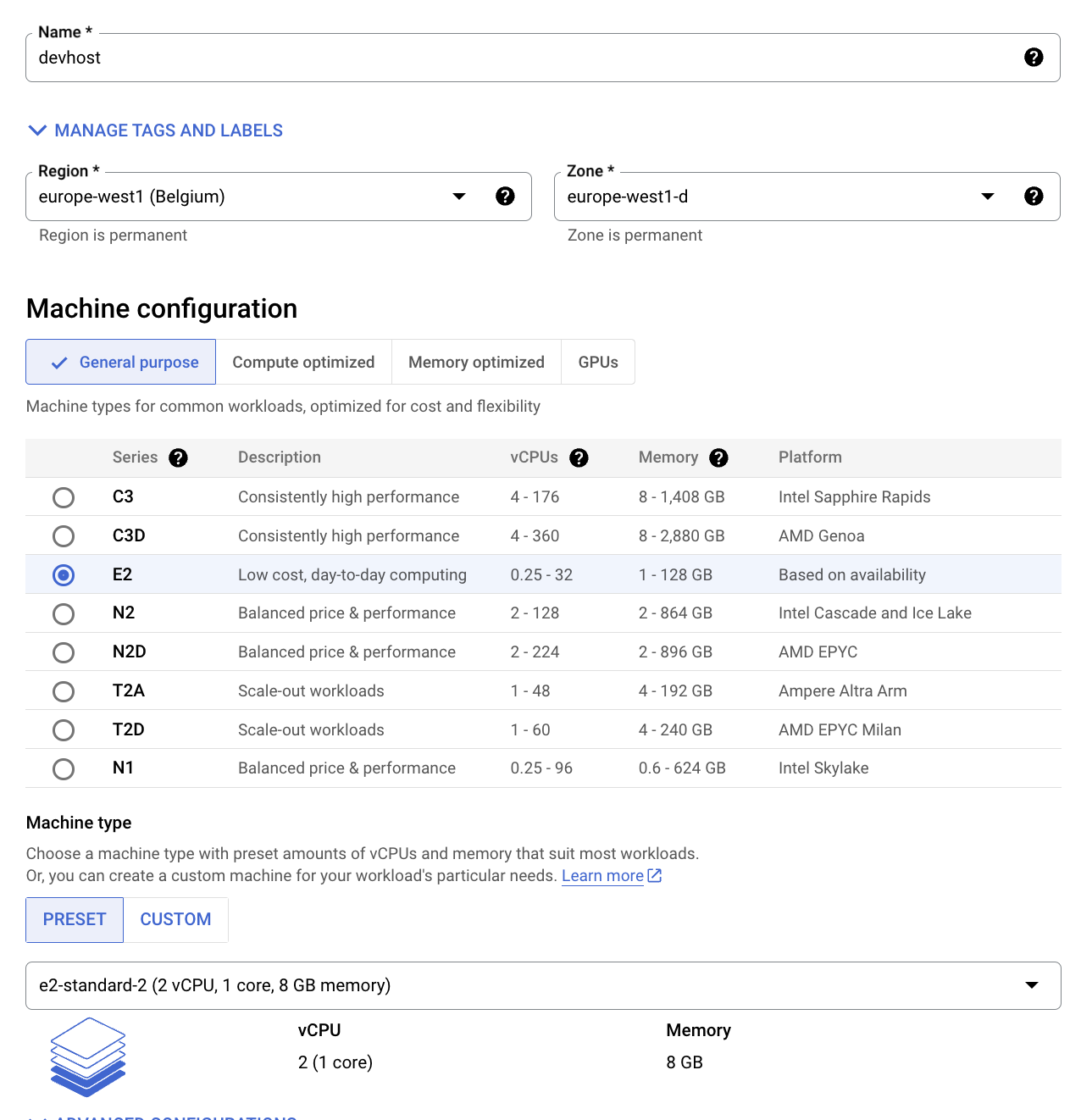
Nom : devhost
-
Série : N1
-
Type de machine : 2 vCPU (instance n1-standard-2)
-
Identité et accès à l'API : autorisez l'accès complet à toutes les API Cloud.
-
-
Cliquez sur Créer. Cette machine fera office d'hôte bastion pour le développement.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
- Maintenant, connectez-vous en SSH à l'instance en cliquant sur le bouton SSH de la console.
Tâche 2 : Installer le logiciel
À présent, configurez le logiciel pour qu'il exécute le job. À l'aide de sbt, un outil de création Open Source, créez le fichier JAR pour le job à envoyer sur le cluster Cloud Dataproc. Ce fichier JAR contiendra le programme et les packages requis pour l'exécution du job. Le job détectera les visages dans un ensemble de fichiers image stockées dans un bucket Cloud Storage, et créera des fichiers image sur lesquels les contours des visages seront marqués, dans ce même bucket ou un autre bucket Cloud Storage.
- Configurez Scala et sbt. Dans la fenêtre SSH, installez
Scalaetsbtavec les commandes suivantes, afin de pouvoir compiler le code :
Vous allez maintenant créer les fichiers du détecteur de caractéristiques. Le code de cet atelier est adapté d'une solution disponible dans le dépôt Cloud Dataproc sur GitHub, avec une légère variation. Vous téléchargerez le code, puis utiliserez la commande cd pour accéder au répertoire de cet atelier. Vous créerez ensuite un fichier Fat JAR du détecteur de caractéristiques, que vous enverrez ensuite à Cloud Dataproc.
- Exécutez les commandes suivantes dans la fenêtre SSH :
- Démarrez la création. Cette commande crée un fichier Fat JAR du détecteur de caractéristiques, que vous pourrez envoyer à Cloud Dataproc :
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
Tâche 3 : Créer un bucket Cloud Storage et collecter des images
Maintenant que vous avez créé vos fichiers de détecteur de caractéristiques, créez un bucket Cloud Storage et ajoutez-y des exemples d'images.
- Récupérez l'ID du projet et utilisez-le pour nommer votre bucket :
- Nommez votre bucket et définissez une variable de shell pour le nom de votre bucket. Cette variable de shell vous servira dans les commandes pour faire référence à votre bucket :
- Utilisez le programme
gsutilfourni avecgclouddans Cloud SDK pour créer le bucket qui contiendra vos exemples d'images :
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
- Importez des exemples d'images dans votre bucket :
Vous venez d'importer les images suivantes dans votre bucket Cloud Storage :



Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
- Exécutez la commande suivante pour afficher le contenu de votre bucket :
Résultat :
Tâche 4 : Créer un cluster Cloud Dataproc
- Exécutez les commandes suivantes dans la fenêtre SSH pour nommer votre cluster et définir la variable
MYCLUSTER. Vous utiliserez la variable dans certaines commandes pour faire référence à votre cluster :
- Définissez une région Compute Engine globale et créez un nouveau cluster :
- Si vous êtes invité à utiliser une zone au lieu d'une région, saisissez Y.
L'opération peut prendre quelques minutes. Les paramètres de cluster par défaut, qui incluent deux nœuds de calcul, devraient suffire pour cet atelier. n1-standard-2 est spécifié en tant que type de machine à la fois pour le nœud de calcul et l'instance principale afin de réduire le nombre global de cœurs utilisés par le cluster.
Pour l'option initialization-actions, vous transmettez un script qui installe la bibliothèque libgtk2.0-dev sur chacune des machines de votre cluster. Cette bibliothèque sera nécessaire pour exécuter le code.
gcloud dataproc clusters delete ${MYCLUSTER}). Si vous y parvenez, exécutez une nouvelle fois la commande de création de cluster.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
Tâche 5 : Envoyer votre job à Cloud Dataproc
Dans cet atelier, le programme que vous exécutez est utilisé en tant que détecteur de visages, donc le classificateur d'entrée haar doit décrire un visage. Un classificateur haar est un fichier XML servant à décrire les caractéristiques que le programme doit détecter. Vous importerez le fichier du classificateur haar dans Cloud Storage, et inclurez son chemin d'accès Cloud Storage dans le premier argument lorsque vous enverrez le job au cluster Cloud Dataproc.
- Exécutez la commande suivante dans la fenêtre SSH pour charger le fichier de configuration de la détection de visages dans votre bucket :
- Utilisez le jeu d'images que vous avez importé dans le répertoire
imgsdu bucket Cloud Storage comme entrée pour votre détecteur de caractéristiques. Vous devez inclure le chemin vers ce répertoire comme deuxième argument de votre commande d'envoi de job.
- Envoyez votre job à Cloud Dataproc :
Vous pouvez ajouter d'autres images à utiliser dans le bucket Cloud Storage spécifié dans le deuxième argument.
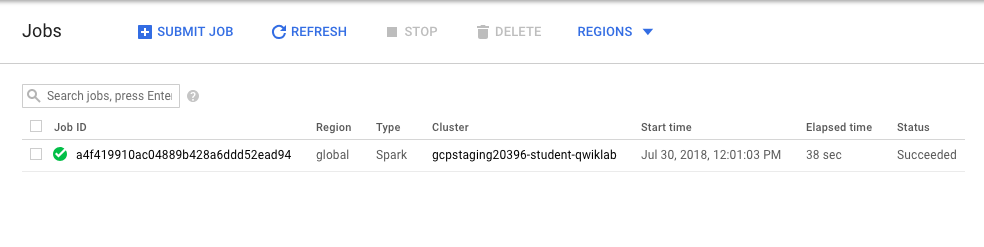
- Pour surveiller le job, dans la console, accédez au menu de navigation > Dataproc > Jobs.
Passez à l'étape suivante lorsque vous obtenez ce type de résultat :
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée. Si votre tâche a bien été exécutée, vous recevez une note d'évaluation.
-
Lorsque le job est terminé, accédez au menu de navigation > Cloud Storage, et recherchez le bucket que vous avez créé (son nom se compose de votre nom d'utilisateur, suivi de
student-imageet d'un nombre aléatoire), puis cliquez dessus. -
Cliquez ensuite sur une image dans le répertoire Out (Sortie).
-
Cliquez sur l'icône Télécharger pour télécharger l'image sur votre ordinateur.
Quelle est la précision de la détection des visages ? L'API Vision est plus performante, car ce type de règles codées manuellement ne fonctionne pas très bien. Son fonctionnement est présenté ici.
-
(Facultatif) Dans votre bucket, accédez au dossier
imgs, puis cliquez sur les autres images que vous avez importées dans le bucket. Les trois exemples d'images sont alors téléchargés. Enregistrez-les sur votre ordinateur. -
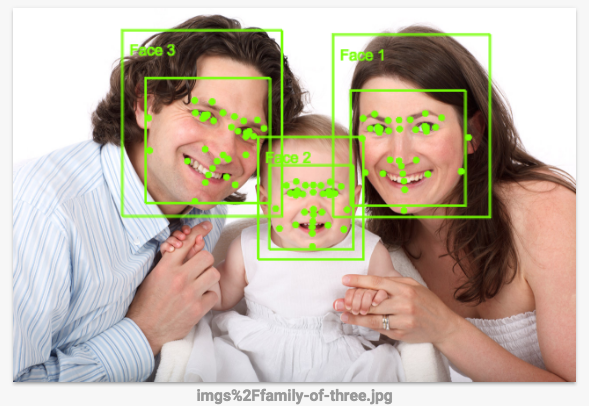
Cliquez sur ce lien pour accéder à la page de l'API Vision, faites défiler vers le bas jusqu'à la section Essayer l'API, puis chargez les images que vous avez importées depuis votre bucket. Le résultat de la détection d'images est visible en quelques secondes. Les modèles de machine learning sous-jacents ne cessent de progresser, donc vos résultats peuvent être différents de ceux-ci :


- (Facultatif) Si vous voulez essayer d'améliorer le détecteur de caractéristiques, vous pouvez apporter des modifications au code
FeatureDetector, puis exécuter une nouvelle fois les commandessbt assembly,gcloud dataprocetjobs submit.
Tâche 6 : Tester vos connaissances
Voici quelques questions à choix multiples qui vous permettront de mieux maîtriser les concepts abordés lors de cet atelier. Répondez-y du mieux que vous le pouvez.
Félicitations !
Vous avez appris à lancer un cluster Cloud Dataproc et à exécuter des jobs.
Terminer votre quête
Cet atelier d'auto-formation fait partie de la quête Scientific Data Processing. Une quête est une série d'ateliers associés qui constituent un parcours de formation. Si vous terminez cette quête, vous obtenez un badge attestant de votre réussite. Vous pouvez rendre publics les badges que vous recevez et ajouter leur lien dans votre CV en ligne ou sur vos comptes de réseaux sociaux. Inscrivez-vous à cette quête pour obtenir immédiatement les crédits associés. Découvrez toutes les quêtes disponibles dans le catalogue Google Cloud Skills Boost.
Atelier suivant
Continuez sur votre lancée en suivant l'atelier Analyser les données relatives à la natalité à l'aide de Datalab et BigQuery, ou essayez l'une de ces suggestions :
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière mise à jour du manuel : 18 juillet 2023
Dernier test de l'atelier : 18 juillet 2023
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.

