

Before you begin
- Labs create a Google Cloud project and resources for a fixed time
- Labs have a time limit and no pause feature. If you end the lab, you'll have to restart from the beginning.
- On the top left of your screen, click Start lab to begin
Create a Kubernetes cluster and deployments (Auth, Hello, and Frontend)
/ 50
Canary Deployment
/ 50
Im Zuge der Best Practices für DevOps werden häufig mehrere Deployments genutzt, um verschiedene Szenarien des Anwendungs-Deployments zu verwalten, z. B. kontinuierliche Deployments, Blau/Grün-Deployments und Canary-Deployments. In diesem Lab wird gezeigt, wie Sie Container für diese gängigen Szenarien skalieren und verwalten, bei denen mehrere heterogene Deployments verwendet werden.
Aufgaben in diesem Lab:
kubectl-Tool verwendenyaml-Dateien für das Deployment erstellenFür einen maximalen Lernerfolg empfehlen wir für dieses Lab Folgendes:
Bei heterogenen Deployments werden in der Regel mindestens zwei Infrastrukturumgebungen oder Regionen miteinander verbunden. Auf diese Art lassen sich bestimmte technische oder betriebliche Anforderungen erfüllen. Heterogene Deployments werden je nach Typ auch als Hybrid-Cloud, Multi-Cloud oder öffentliche/private Cloud bezeichnet.
In diesem Lab umfasst der Begriff Deployments, die in Regionen innerhalb einer einzelnen Cloud-Umgebung, in mehreren öffentlichen Cloud-Umgebungen (Multi-Cloud) oder in lokalen und öffentlichen Cloud-Umgebungen (hybrid oder öffentlich/privat) bereitgestellt werden.
In Deployments, die auf eine einzelne Umgebung oder Region beschränkt sind, können verschiedene geschäftliche und technische Probleme auftreten:
Heterogene Deployments können dabei helfen, diese Herausforderungen zu bewältigen. Sie müssen jedoch mit programmatischen und deterministischen Prozessen und Verfahren entworfen werden. Einmalige oder Ad-hoc-Deployment-Verfahren können dazu führen, dass Deployments oder Prozesse problemanfällig und fehlerintolerant sind. Bei Ad-hoc-Prozessen besteht die Gefahr, dass Daten verloren gehen oder dass der Traffic abgeschnitten wird. Ein gut geeigneter Deployment-Prozess muss wiederholbar sein und bewährte Ansätze für die Verwaltung der Bereitstellung, Konfiguration und Wartung enthalten.
Für heterogene Deployments gibt es drei gängige Szenarien:
In den folgenden Übungen lernen Sie häufige Anwendungsfälle von heterogenen Deployments kennen und erfahren, wie Sie Kubernetes und andere Infrastrukturressourcen in diesen Situationen nutzen.
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange die Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung selbst durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Pop-up-Fenster geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können. Auf der linken Seite befindet sich der Bereich Details zum Lab mit diesen Informationen:
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite Anmelden geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
Sie finden den Nutzernamen auch im Bereich Details zum Lab.
Klicken Sie auf Weiter.
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
Sie finden das Passwort auch im Bereich Details zum Lab.
Klicken Sie auf Weiter.
Klicken Sie sich durch die nachfolgenden Seiten:
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.

Cloud Shell ist eine virtuelle Maschine, auf der Entwicklertools installiert sind. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft auf Google Cloud. Mit Cloud Shell erhalten Sie Befehlszeilenzugriff auf Ihre Google Cloud-Ressourcen.
 .
.Wenn Sie verbunden sind, sind Sie bereits authentifiziert und das Projekt ist auf Ihre Project_ID,
gcloud ist das Befehlszeilentool für Google Cloud. Das Tool ist in Cloud Shell vorinstalliert und unterstützt die Tab-Vervollständigung.
Ausgabe:
Ausgabe:
gcloud finden Sie in Google Cloud in der Übersicht zur gcloud CLI.
Die Arbeitszone für Google Cloud legen Sie fest, indem Sie den folgenden Befehl ausführen und dabei
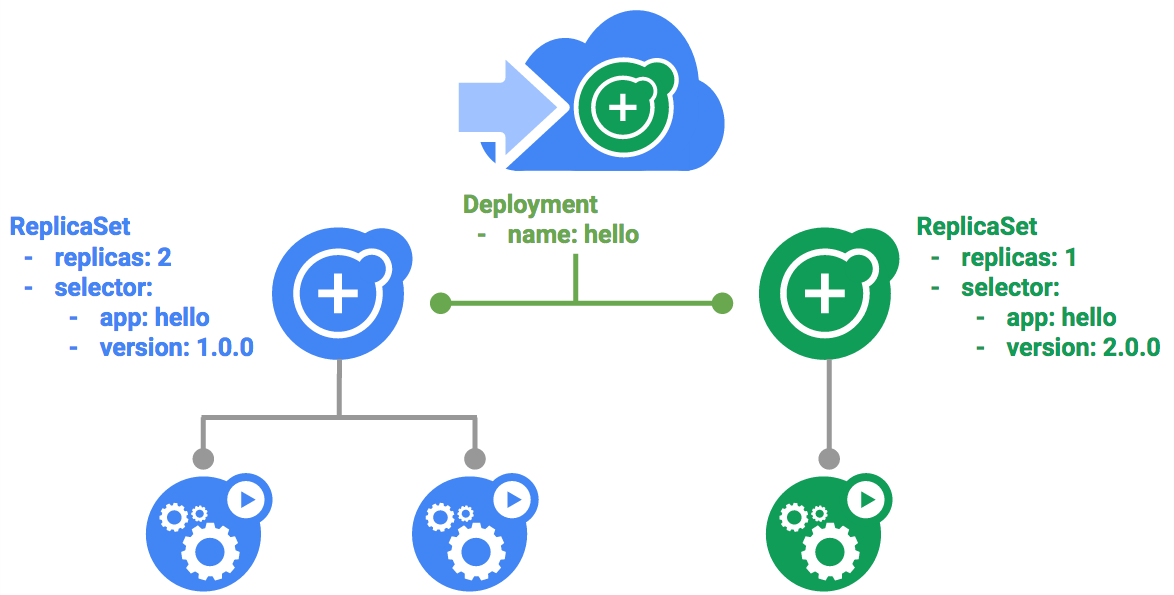
Als Erstes prüfen Sie das Deployment-Objekt.
explain in kubectl lassen sich dazu weitere Informationen abrufen.‑‑recursive verwenden:deployments/auth.yaml:Image vor:auth.yaml. Drücken Sie <Esc> und geben Sie Folgendes ein:Eingabetaste. Nun erstellen Sie ein einfaches Deployment. Sehen Sie sich dazu die Konfigurationsdatei an:Ausgabe:
Mit dem Deployment wird ein Replikat erstellt und die Version 1.0.0 des auth‑Containers verwendet.
Wenn Sie den Befehl kubectl create ausführen, um das auth‑Deployment zu erstellen, wird ein Pod angelegt, der den Daten im Deployment-Manifest entspricht. Dies bedeutet, dass Sie die Anzahl der Pods skalieren können, indem Sie die im Feld Replikate angegebene Zahl ändern.
kubectl create ein eigenes Deployment-Objekt:ReplicaSet für das Deployment erstellt. Sie können nun prüfen, ob ein ReplicaSet für das Deployment angelegt wurde:Der Name des ReplicaSet muss das Format auth‑xxxxxxx haben.
ReplicaSet angelegt:Als Nächstes wird der Dienst für das auth‑Deployment erstellt. Da Sie Dienstmanifestdateien bereits kennen, gehen wir hier nicht weiter ins Detail.
kubectl create:hello zu erstellen und freizugeben:frontend zu erstellen und bereitzustellen:ConfigMap für das Frontend erstellt.Daraufhin wird die Antwort „hello“ zurückgegeben.
kubectl lässt sich der Befehl „curl“ als Einzeiler schreiben:Klicken Sie unten auf Fortschritt prüfen. Wenn Sie einen Kubernetes-Cluster sowie Deployments für „auth“, „hello“ und „frontend“ erstellt haben, erhalten Sie ein Testergebnis.
Nachdem Sie ein Deployment erstellt haben, können Sie es skalieren. Aktualisieren Sie dazu das Feld spec.replicas.
kubectl explain können Sie eine Erklärung zu dem Feld abrufen:kubectl scale aktualisieren:Nach dem Update des Deployments wird in Kubernetes automatisch das dazugehörende ReplicaSet aktualisiert. Außerdem werden so viele neue Pods gestartet, bis die Gesamtzahl fünf erreicht ist.
hello ausgeführt werden:In diesem Abschnitt haben Sie Kubernetes-Deployments kennengelernt und erfahren, wie Sie eine Gruppe von Pods verwalten und skalieren.
In Deployments lassen sich Images mithilfe von Rolling Updates auf eine neuere Version aktualisieren. Bei diesem Vorgang wird ein neues ReplicaSet erstellt und die Zahl der Replikate im neuen ReplicaSet langsam gesteigert. Gleichzeitig wird die Replikatzahl im alten ReplicaSet verringert.
Image vor:Das aktualisierte Deployment wird in Ihrem Cluster gespeichert und das Rolling Update in Kubernetes ausgelöst.
ReplicaSet auf, das in Kubernetes erstellt wurde:Falls bei einem laufenden Roll-out Probleme auftreten, können Sie es pausieren und die Aktualisierung so stoppen.
Das Roll-out ist pausiert. Es sind also noch nicht alle Pods aktualisiert worden.
resume können Sie es fortsetzen:status die folgende Ausgabe erhalten:Ausgabe:
Beispiel: In einer neuen Version wurde ein Programmfehler erkannt. Er wirkt sich auf alle Nutzer aus, die eine Verbindung zu den neuen Pods hergestellt haben.
In diesem Fall sollten Sie ein Rollback auf die vorherige Version ausführen. Dies verschafft Ihnen Zeit, um das Problem zu untersuchen und anschließend eine korrigierte Version zu veröffentlichen.
rollout:Sehr gut. Sie haben gelernt, wie ein Rolling Update für Kubernetes-Deployments ausgeführt wird und wie Anwendungen ohne Ausfallzeit aktualisiert werden.
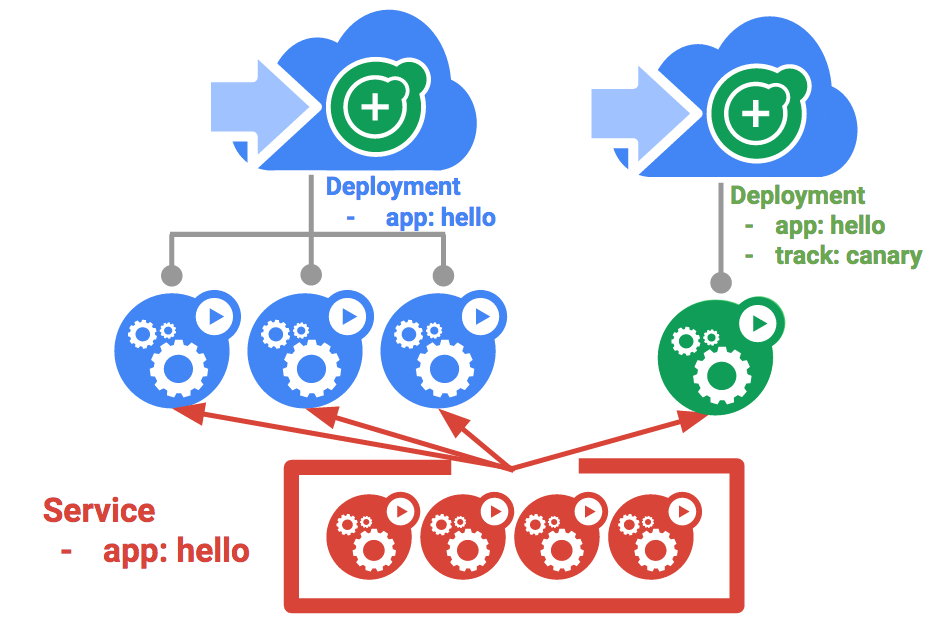
Wenn bestimmte Nutzer in der Produktion ein neues Deployment testen sollen, bietet sich ein Canary-Deployment an. Damit können Sie eine Änderung für eine kleine Nutzergruppe implementieren und so das Risiko verringern, das mit neuen Releases einhergeht.
Canary-Deployments bestehen aus einem separaten Deployment, das die neue Version enthält, und einem Dienst, der sowohl das normale, stabile Deployment als auch das Canary-Deployment adressiert.
Ausgabe:
hello und hello-canary. Dies lässt sich mit dem folgenden kubectl-Befehl prüfen:Im Dienst hello wird der Selektor app:hello verwendet, der den Pods im Produktions- und im Canary-Deployment entspricht. Da das Canary-Deployment weniger Pods hat, ist es auch für weniger Nutzer sichtbar.
hello bereitgestellt wird:Klicken Sie unten auf Fortschritt prüfen. Wenn Sie ein Canary-Deployment erstellt haben, erhalten Sie ein Testergebnis.
In diesem Lab durfte jede Anfrage, die an den Nginx-Dienst gesendet wurde, vom Canary-Deployment beantwortet werden. Was aber, wenn Nutzer eben nicht das Canary-Deployment nutzen sollen? Dies kann z. B. hilfreich sein, wenn sich die UI einer Anwendung geändert hat und Sie den Nutzer nicht verwirren möchten. In diesem Fall ist es besser, wenn der Nutzer das ursprüngliche Deployment weiterverwendet.
Dazu müssen Sie einen Dienst mit Sitzungsaffinität erstellen. So ist garantiert, dass ein Nutzer immer dieselbe Version verwendet. Im Beispiel unten wird wieder der Dienst „hello“ verwendet. Es wurde jedoch ein neues Feld sessionAffinity hinzugefügt und dafür der Wert ClientIP festgelegt. Wenn Clients dieselbe IP‑Adresse haben, werden die von Ihnen gesendeten Anfragen also an dieselbe Version der Anwendung hello gerichtet.
Da es schwer ist, hierfür eine Testumgebung einzurichten, wird der Schritt in diesem Lab ausgelassen. Für Canary-Deployments in Produktionsumgebungen ist sessionAffinity jedoch gut geeignet.
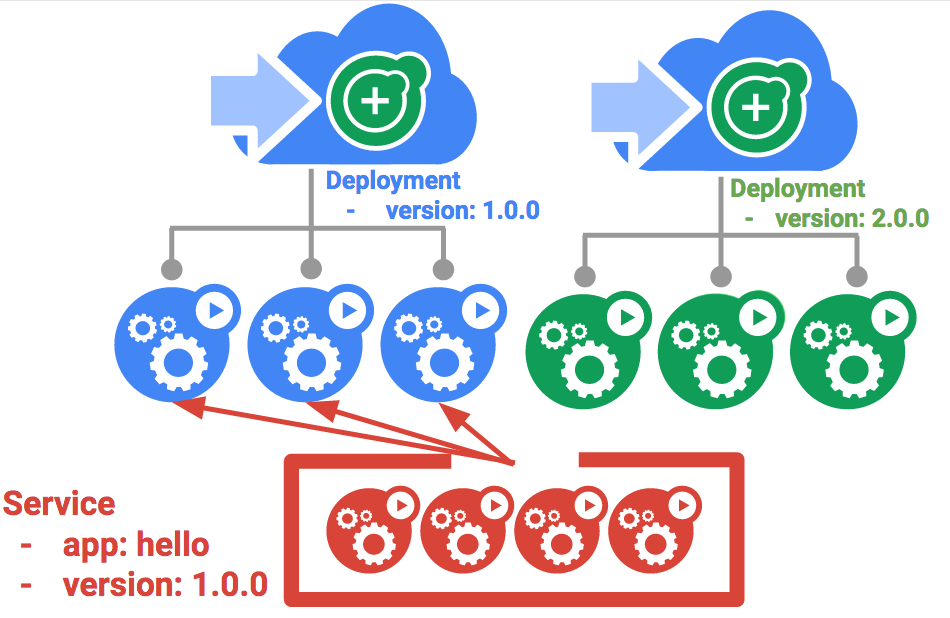
Rolling Updates sind die ideale Lösung, denn sie ermöglichen es Ihnen, eine Anwendung nach und nach mit minimalem Aufwand sowie geringsten Leistungseinbußen und Ausfallzeiten bereitzustellen. Bei einigen Instanzen sollten Sie Load Balancer so ändern, dass sie erst dann auf die neue Version verweisen, wenn diese vollständig bereitgestellt wurde. Hier sind Blau/Grün-Deployments die beste Wahl.
Dabei werden in Kubernetes zwei separate Deployments erstellt: eine für die ältere "blaue" und eine andere für die neue "grüne" Version. Verwenden Sie für das „blaue“ Deployment die vorhandene Version von hello. Der Zugriff auf die Deployments erfolgt über einen Dienst, der als Router fungiert. Sobald die neue „grüne“ Version ausgeführt wird, wechseln Sie mit einem Dienstupdate dorthin.
Verwenden Sie den bestehenden Dienst „hello“, aber aktualisieren Sie ihn, sodass er über den Selektor app:hello, version: 1.0.0, verfügt. Der Selektor entspricht dem vorhandenen „blauen“ Deployment. Der Selektor entspricht nicht dem neuen „grünen“ Deployment, da dieses eine andere Version verwendet.
resource service/hello is missing, da dies automatisch eingefügt wird.Damit Blau/Grün-Deployments unterstützt werden, erstellen Sie ein neues „grünes“ Deployment für die neue Version. Damit werden das Versionslabel und der Image-Pfad aktualisiert.
Bei Bedarf können Sie auf dieselbe Weise ein Rollback auf die ältere Version durchführen.
Geschafft! Sie kennen sich jetzt mit Blau/Grün-Deployments aus und wissen, wie Sie Updates bereitstellen, wenn gleichzeitig bei mehreren Anwendungen die Version geändert werden soll.
Sie haben das Befehlszeilentool kubectl praktisch angewendet und gelernt, wie Sie mithilfe von YAML-Dateien und vielen verschiedenen Deployment-Konfigurationen Deployments starten, aktualisieren und skalieren. Nach diesem Lab können Sie die erworbenen Fähigkeiten sicher in Ihre DevOps-Arbeit einfließen lassen.
DevOps-Lösungen und ‑Leitfäden (Google Cloud-Dokumentation).
Auf der Kubernetes-Website können Sie eine Verbindung zur Kubernetes-Community herstellen!
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 2. April 2024 aktualisiert
Lab zuletzt am 14. August 2023 getestet
© 2025 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.



Diese Inhalte sind derzeit nicht verfügbar
Bei Verfügbarkeit des Labs benachrichtigen wir Sie per E-Mail

Sehr gut!
Bei Verfügbarkeit kontaktieren wir Sie per E-Mail

One lab at a time
Confirm to end all existing labs and start this one