GSP642


概要
Lily さんは 12 年前、獣医クリニック チェーン「Pet Theory」を開業しました。Pet Theory チェーンはここ数年で急速に拡大しました。しかし、増大した負荷を古い予約システムで処理しきれなくなったため、より拡張性の高いクラウドベースのシステムが必要になっています。
Pet Theory の運用チームのメンバーは Patrick さんだけなので、運用中のメンテナンスにあまり手間のかからないソリューションが必要です。そこで、サーバーレス テクノロジーを採用することになりました。
Ruby さんは、Pet Theory のサーバーレス移行を支援するコンサルタントとして雇われています。サーバーレス データベースのオプションを比較した後、チームは Cloud Firestore を採用することにしました。Firestore はサーバーレスなので、容量を事前にプロビジョニングする必要がありません。これはつまり、ストレージやオペレーションが上限に達するリスクがないということです。Firestore では、リアルタイム リスナーを通じてクライアント アプリ間でデータの同期が維持され、モバイルとウェブのオフライン サポートも提供されるので、ネットワーク レイテンシやインターネット接続に関係なく機能する、応答性の高いアプリを構築できます。
このラボでは、Patrick さんが Pet Theory の既存のデータを Cloud Firestore データベースにアップロードする作業をサポートします。Patrick さんは Ruby さんと密接に連携しながら作業を完了します。
アーキテクチャ
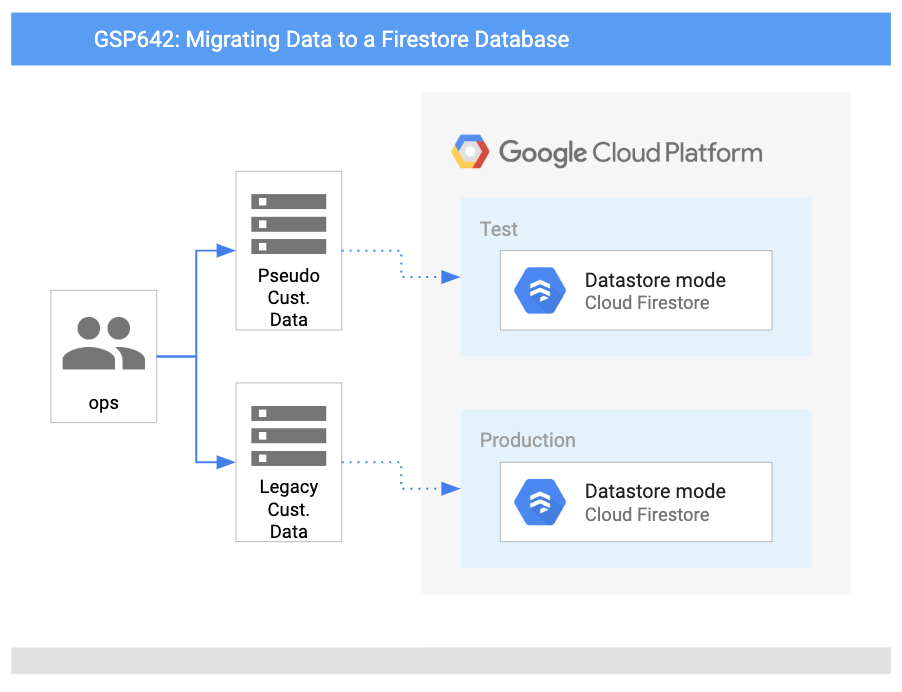
この図は、使用するサービスの概要と、それらがどのようにつながっているかを示しています。
目標
このラボでは、次の方法について学びます。
- Google Cloud で Firestore を設定する。
- データベースのインポート コードを記述する。
- テスト用の顧客データのコレクションを生成する。
- テスト用の顧客データを Firestore に読み込む。
前提条件
これは入門レベルのラボであり、Cloud コンソール環境とシェル環境に精通していることを前提としています。Firebase の使用経験は役立ちますが、必須ではありません。
ファイルの編集にも慣れている必要があります。ご自身で使い慣れたテキスト エディタ(nano、vi など)を使用するか、上部のリボンにある Cloud Shell からコードエディタを起動できます。
![[エディタを開く] ボタン](https://cdn.qwiklabs.com/UqR6a8QkaHUK41NyziQtVya67mqA9ivrzslZSt4sIoo%3D)
準備ができたら下にスクロールし、手順に沿ってラボ環境を設定します。
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
注: このラボの実行には、シークレット モードまたはシークレット ブラウジング ウィンドウを使用してください。これにより、個人アカウントと受講者アカウント間の競合を防ぎ、個人アカウントに追加料金が発生することを防ぎます。
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
注: すでに個人の Google Cloud アカウントやプロジェクトをお持ちの場合でも、このラボでは使用しないでください。アカウントへの追加料金が発生する可能性があります。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。
左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google Cloud コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google Cloud コンソールを開く] をクリックします(Chrome ブラウザを使用している場合は、右クリックして [シークレット ウィンドウでリンクを開く] を選択します)。
ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。
-
必要に応じて、下のユーザー名をコピーして、[ログイン] ダイアログに貼り付けます。
{{{user_0.username | "Username"}}}
[ラボの詳細] パネルでも [ユーザー名] を確認できます。
-
[次へ] をクリックします。
-
以下のパスワードをコピーして、[ようこそ] ダイアログに貼り付けます。
{{{user_0.password | "Password"}}}
[ラボの詳細] パネルでも [パスワード] を確認できます。
-
[次へ] をクリックします。
重要: ラボで提供された認証情報を使用する必要があります。Google Cloud アカウントの認証情報は使用しないでください。
注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。
-
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後、このタブで Google Cloud コンソールが開きます。
注: Google Cloud のプロダクトやサービスのリストを含むメニューを表示するには、左上のナビゲーション メニューをクリックします。
Cloud Shell をアクティブにする
Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
- Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン
 をクリックします。
をクリックします。
接続した時点で認証が完了しており、プロジェクトに各自の PROJECT_ID が設定されます。出力には、このセッションの PROJECT_ID を宣言する次の行が含まれています。
Your Cloud Platform project in this session is set to YOUR_PROJECT_ID
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
- (省略可)次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
gcloud auth list
-
[承認] をクリックします。
-
出力は次のようになります。
出力:
ACTIVE: *
ACCOUNT: student-01-xxxxxxxxxxxx@qwiklabs.net
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (省略可)次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
gcloud config list project
出力:
[core]
project = <project_ID>
出力例:
[core]
project = qwiklabs-gcp-44776a13dea667a6
注: Google Cloud における gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
タスク 1. Google Cloud で Firestore を設定する
Patrick さんのタスクは、Pet Theory の既存のデータを Cloud Firestore データベースにアップロードすることです。彼はこの目標を達成するために Ruby さんと連携します。Ruby さんは、IT 部門の Patrick さんから次のメッセージを受け取りました。
|

Patrick さん(IT 管理者)
|
Ruby さん、お世話になっております。
サーバーレス化にあたり、まず Google Cloud で Firestore データベースを作成しようと思います。こうした設定作業には不慣れなため、アドバイスをいただければと考えています。
Patrick
|
|

Ruby さん(ソフトウェア コンサルタント)
|
Patrick さん、ご連絡ありがとうございます。
承知しました。喜んでお手伝いさせていただきます。つきましては、作業を開始するためのリソースを送付いたします。データベースの作成が終わり次第、ご連絡いただけますでしょうか。よろしくお願いいたします。
Ruby
|
Patrick さんが Cloud コンソールで Firestore データベースを設定できるようにサポートしましょう。
-
Cloud コンソールのナビゲーション メニューに移動し、[Firestore] を選択します。
-
[+データベースを作成] をクリックします。
-
[ネイティブ モード] オプションを選択し、[続行] をクリックします。
注: どちらのモードも高パフォーマンスで強整合性ですが、見た目が異なり、それぞれのユースケース向けに最適化されています。
- ネイティブ モードは、多数のユーザーが同じデータに同時にアクセスできるようにするのに適しています。さらに、リアルタイム更新や、データベースとウェブ / モバイル クライアント間の直接接続のような機能も備えています。
- Datastore モードは、高スループット(大量の読み取りと書き込み)に重点が置かれています。
- [リージョン] プルダウンでリージョンを選択してから、[データベースを作成] をクリックします。
タスクの完了後、Ruby さんから Patrick さんに次のメールが届きます。
|
Ruby さん(ソフトウェア コンサルタント)
|
Patrick さん、ご連絡ありがとうございます。
Firestore データベースの設定、お疲れさまでございました。データベースへのアクセスを管理するには、必要な権限で自動的に作成されたサービス アカウントを使用することになります。
以上で、古いデータベースから Firestore に移行する準備は完了です。
Ruby
|
|

Patrick さん(IT 管理者)
|
Ruby さん、お世話になっております。
ご協力ありがとうございました。おかげさまで Firestore データベースは簡単に設定できました。
データベースのインポート プロセスも簡単であることを祈っています。以前のデータベースでは、かなり複雑で手間がかかったように記憶しています。
Patrick
|
タスク 2. データベースのインポート コードを記述する
新しい Cloud Firestore データベースは準備できましたが、中身は空の状態です。Pet Theory の顧客データは、まだ古いデータベースにのみ存在します。
Patrick さんは Ruby さんに次のメッセージを送信します。
|

Patrick さん(IT 管理者)
|
Ruby さん、お世話になっております。
弊社の上司の意向により、新しい Firestore データベースに対して、顧客データの移行を開始したいと考えております。
従来のデータベースから CSV ファイルをエクスポートしましたが、このデータを Firestore に読み込む方法がわかりません。
この方法につき、ご教示いただければ助かります。よろしくお願いいたします。
Patrick
|
|
Ruby さん(ソフトウェア コンサルタント)
|
Patrick さん、ご連絡ありがとうございます。
承知しました。では、どのような作業が必要になるか、打ち合わせにてお話しさせていただければと思います。よろしくお願いいたします。
Ruby
|
Patrick さんが言うとおり、顧客データは CSV ファイルで用意されます。ここで Patrick さんをサポートしましょう。CSV ファイルから顧客レコードを読み取って Firestore に書き込むアプリを作成します。Patrick さんは JavaScript に精通しているので、Node.js JavaScript ランタイムを使用してこのアプリケーションを構築します。
- Cloud Shell で次のコマンドを実行し、Pet Theory リポジトリのクローンを作成します。
git clone https://github.com/rosera/pet-theory
- Cloud Shell コードエディタ(または任意のエディタ)を使用してファイルを編集します。Cloud Shell セッションの上部のリボンにある [エディタを開く] をクリックすると、新しいタブでエディタが開きます。プロンプトが表示されたら、[新しいウィンドウで開く] をクリックしてコードエディタを起動します。
- 次に、現在の作業ディレクトリを
lab01 に変更します。
cd pet-theory/lab01
ディレクトリ内には、Patrick さんの package.json があります。このファイルは、Node.js プロジェクトが依存するパッケージをリストしたものです。これによりビルドの再作成が可能になり、他のユーザーとも簡単に共有できるようになります。
package.json の例を以下に示します。
{
"name": "lab01",
"version": "1.0.0",
"description": "This is lab01 of the Pet Theory labs",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "Patrick - IT",
"license": "MIT",
"dependencies": {
"csv-parse": "^5.5.3"
}
}
Patrick さんはソースコードを読み込み、Ruby さんに連絡を取って、移行を実施するためにどのパッケージが必要なのかを確認します。
|
Patrick さん(IT 管理者)
|
Ruby さん、お世話になっております。
古いデータベースで使用しているコードはかなり基本的なもので、インポートでは CSV しか作成できません。始める前にダウンロードが必要なものがあれば、お知らせいただけると助かります。
Patrick
|
|
Ruby さん(ソフトウェア コンサルタント)
|
Patrick さん、ご連絡ありがとうございます。
Google Cloud には Node パッケージがたくさん用意されていますので、そのいずれかを使って Firestore を操作することをおすすめします。
そうすれば、煩雑な作業をパッケージに任せられるので、既存のコードに簡単な変更を加えるだけで済みます。
Ruby
|
Patrick さんのコードを Firestore データベースに書き込めるようにするには、追加のピア依存関係をインストールする必要があります。
- 以下のコマンドを実行します。
npm install @google-cloud/firestore
- アプリが Cloud Logging にログを書き込めるように、追加のモジュールをインストールします。
npm install @google-cloud/logging
コマンドが正常に実行されると、package.json が自動的に更新され、新しいピア依存関係が含まれるようになります。これは次のようになります。
...
"dependencies": {
"@google-cloud/firestore": "^7.3.0",
"@google-cloud/logging": "^11.0.0",
"csv-parse": "^5.5.3"
}
次に、スクリプトについて見てみます。このスクリプトは、顧客の CSV ファイルを読み取り、その CSV ファイルの各行に対応するレコードを Firestore に書き込むものです。Patrick さんの元のアプリケーションを以下に示します。
const csv = require('csv-parse');
const fs = require('fs');
function writeToDatabase(records) {
records.forEach((record, i) => {
console.log(`ID: ${record.id} Email: ${record.email} Name: ${record.name} Phone: ${record.phone}`);
});
return ;
}
async function importCsv(csvFilename) {
const parser = csv.parse({ columns: true, delimiter: ',' }, async function (err, records) {
if (e) {
console.error('Error parsing CSV:', e);
return;
}
try {
console.log(`Call write to Firestore`);
await writeToDatabase(records);
console.log(`Wrote ${records.length} records`);
} catch (e) {
console.error(e);
process.exit(1);
}
});
await fs.createReadStream(csvFilename).pipe(parser);
}
if (process.argv.length < 3) {
console.error('Please include a path to a csv file');
process.exit(1);
}
importCsv(process.argv[2]).catch(e => console.error(e));
これは、入力 CSV ファイルから出力を取得し、従来のデータベースに読み込むものです。次に、このコードを更新し、Firestore に対して書き込むようにします。
- ファイル
pet-theory/lab01/importTestData.js を開きます。
アプリケーションから Firestore API を参照するには、既存のコードベースにピア依存関係を追加する必要があります。
- ファイルの 3 行目に次の Firestore 依存関係を追加します。
const { Firestore } = require("@google-cloud/firestore");
ファイルの先頭が次のようになっていることを確認します。
const csv = require('csv-parse');
const fs = require('fs');
const { Firestore } = require("@google-cloud/firestore"); // これを追加
Firestore データベースとの統合は、数行のコードで実現できます。そこで Ruby さんは、Patrick さんとあなたにテンプレート コードを共有しました。
- 34 行目の
if (process.argv.length < 3) 句の下に次の内容を追加します。
async function writeToFirestore(records) {
const db = new Firestore({
// projectId: projectId
});
const batch = db.batch()
records.forEach((record)=>{
console.log(`Write: ${record}`)
const docRef = db.collection("customers").doc(record.email);
batch.set(docRef, record, { merge: true })
})
batch.commit()
.then(() => {
console.log('Batch executed')
})
.catch(err => {
console.log(`Batch error: ${err}`)
})
return
}
上記のコード スニペットは、新しいデータベース オブジェクトを宣言します。これは、ラボの前半で作成したデータベースを参照します。
この関数は、各レコードが順番に処理されるバッチプロセスを使用し、追加された ID に基づいてドキュメント参照を指定します。関数の最後に、バッチ コンテンツがデータベースに commit(書き込み)されます。
-
importCsv 関数を更新して、writeToFirestore の関数呼び出しを追加し、writeToDatabase の呼び出しを削除します。次のようになります。
async function importCsv(csvFilename) {
const parser = csv.parse({ columns: true, delimiter: ',' }, async function (err, records) {
if (err) {
console.error('Error parsing CSV:', err);
return;
}
try {
console.log(`Call write to Firestore`);
await writeToFirestore(records);
// await writeToDatabase(records);
console.log(`Wrote ${records.length} records`);
} catch (e) {
console.error(e);
process.exit(1);
}
});
await fs.createReadStream(csvFilename).pipe(parser);
}
- アプリケーションのロギングを追加します。アプリケーションを通じて Logging API を参照するには、既存のコードベースにピア依存関係を追加します。ファイルの上部にある他の require ステートメントのすぐ下に、次の行を追加します。
const { Logging } = require('@google-cloud/logging');
ファイルの先頭が次のようになっていることを確認します。
const csv = require('csv-parse');
const fs = require('fs');
const { Firestore } = require("@google-cloud/firestore");
const { Logging } = require('@google-cloud/logging');
- 次に、いくつかの定数変数を追加し、Logging クライアントを初期化します。これらはファイルの上記の行(~5 行目)のすぐ下に次のように追加します。
const logName = "pet-theory-logs-importTestData";
// Logging クライアントの作成
const logging = new Logging();
const log = logging.log(logName);
const resource = {
type: "global",
};
- 「console.log(
Wrote ${records.length} records);」行のすぐ下に、importCsv 関数にログを書き込むための次のようなコードを追加します。
// テキスト ログエントリ
success_message = `Success: importTestData - Wrote ${records.length} records`;
const entry = log.entry(
{ resource: resource },
{ message: `${success_message}` }
);
log.write([entry]);
上記の更新の後、importCsv 関数のコードブロックは次のようになります。
async function importCsv(csvFilename) {
const parser = csv.parse({ columns: true, delimiter: ',' }, async function (err, records) {
if (err) {
console.error('Error parsing CSV:', err);
return;
}
try {
console.log(`Call write to Firestore`);
await writeToFirestore(records);
// await writeToDatabase(records);
console.log(`Wrote ${records.length} records`);
// テキスト ログエントリ
success_message = `Success: importTestData - Wrote ${records.length} records`;
const entry = log.entry(
{ resource: resource },
{ message: `${success_message}` }
);
log.write([entry]);
} catch (e) {
console.error(e);
process.exit(1);
}
});
await fs.createReadStream(csvFilename).pipe(parser);
}
これで、アプリケーション コードを実行すると、Firestore データベースが CSV ファイルの内容で更新されるようになります。importCsv 関数はファイル名を取得し、コンテンツを行ごとに解析します。処理された各行は、Firestore 関数 writeToFirestore に送信されます。ここで、新しい各レコードが「顧客」データベースに書き込まれます。
注: 本番環境では、独自のバージョンのインポート スクリプトを記述します。
タスク 3. テストデータを作成する
さて、それではデータを読み込みます。Patrick さんは、実際の顧客データを使ったテストの実行について懸念していることを Ruby さんに伝えます。
|

Patrick さん(IT 管理者)
|
Ruby さん、お世話になっております。
テストでは、顧客データを使用しないほうがよいと考えています。顧客のプライバシーを保つ必要があるのに加え、データ インポート スクリプトが正しく機能できるという確信が必要になります。
他のテスト方法などあれば、教えていただけますと助かります。
Patrick
|
|
Ruby さん(ソフトウェア コンサルタント)
|
Patrick さん、ご連絡ありがとうございます。
ご心配なされていること、ごもっともと存じます。顧客データには個人を特定できる情報(PII)が含まれている可能性があるため、取り扱いに注意が必要です。
つきましては、疑似顧客データを作成するスターター コードをいくつかご紹介いたします。作成したデータを使用して、インポート スクリプトをテストできます。
Ruby
|
Patrick さんが、この疑似ランダムデータ生成ツールを起動して実行できるようにサポートしましょう。
- 最初に、疑似顧客データを生成するスクリプト用の「faker」ライブラリをインストールします。次のコマンドを実行して、
package.json の依存関係を更新します。
npm install faker@5.5.3
- 次に、コードエディタで createTestData.js という名前のファイルを開き、コードを調べます。次のようになっていることを確認します。
const fs = require('fs');
const faker = require('faker');
function getRandomCustomerEmail(firstName, lastName) {
const provider = faker.internet.domainName();
const email = faker.internet.email(firstName, lastName, provider);
return email.toLowerCase();
}
async function createTestData(recordCount) {
const fileName = `customers_${recordCount}.csv`;
var f = fs.createWriteStream(fileName);
f.write('id,name,email,phone\n')
for (let i=0; i<recordCount; i++) {
const id = faker.datatype.number();
const firstName = faker.name.firstName();
const lastName = faker.name.lastName();
const name = `${firstName} ${lastName}`;
const email = getRandomCustomerEmail(firstName, lastName);
const phone = faker.phone.phoneNumber();
f.write(`${id},${name},${email},${phone}\n`);
}
console.log(`Created file ${fileName} containing ${recordCount} records.`);
}
recordCount = parseInt(process.argv[2]);
if (process.argv.length != 3 || recordCount < 1 || isNaN(recordCount)) {
console.error('Include the number of test data records to create. Example:');
console.error(' node createTestData.js 100');
process.exit(1);
}
createTestData(recordCount);
- コードベースに Logging を追加します。3 行目に、アプリケーション コードから Logging API モジュールへの参照を追加します。
const { Logging } = require("@google-cloud/logging");
ファイルの先頭は次のようになります。
const fs = require("fs");
const faker = require("faker");
const { Logging } = require("@google-cloud/logging"); //これを追加
- 次に、いくつかの定数変数を追加し、Logging クライアントを初期化します。これは
const ステートメントのすぐ下に追加します。
const logName = "pet-theory-logs-createTestData";
// Logging クライアントの作成
const logging = new Logging();
const log = logging.log(logName);
const resource = {
// この例では、わかりやすくするために「global」リソースをターゲットにしています
type: "global",
};
- 「console.log(
Created file ${fileName} containing ${recordCount} records.);」行のすぐ下に、createTestData 関数にログを書き込むための次のようなコードを追加します。
// テキスト ログエントリ
const success_message = `Success: createTestData - Created file ${fileName} containing ${recordCount} records.`;
const entry = log.entry(
{ resource: resource },
{
name: `${fileName}`,
recordCount: `${recordCount}`,
message: `${success_message}`,
}
);
log.write([entry]);
- 更新後、
createTestData 関数のコードブロックは次のようになります。
async function createTestData(recordCount) {
const fileName = `customers_${recordCount}.csv`;
var f = fs.createWriteStream(fileName);
f.write('id,name,email,phone\n')
for (let i=0; i<recordCount; i++) {
const id = faker.datatype.number();
const firstName = faker.name.firstName();
const lastName = faker.name.lastName();
const name = `${firstName} ${lastName}`;
const email = getRandomCustomerEmail(firstName, lastName);
const phone = faker.phone.phoneNumber();
f.write(`${id},${name},${email},${phone}\n`);
}
console.log(`Created file ${fileName} containing ${recordCount} records.`);
// テキスト ログエントリ
const success_message = `Success: createTestData - Created file ${fileName} containing ${recordCount} records.`;
const entry = log.entry(
{ resource: resource },
{
name: `${fileName}`,
recordCount: `${recordCount}`,
message: `${success_message}`,
}
);
log.write([entry]);
}
- Cloud Shell で次のコマンドを実行して、
customers_1000.csv ファイルを作成します。このファイルには、テストデータ 1,000 レコードが含まれます。
node createTestData 1000
次のような出力が返されます。
Created file customers_1000.csv containing 1000 records.
-
customers_1000.csv ファイルを開き、テストデータが作成されていることを確認します。
完了したタスクをテストする
[進行状況を確認] をクリックして、実行したタスクを確認します。Firestore データベースのサンプル テストデータを正常に作成すると、評価スコアが表示されます。
Firestore データベース用のテストデータを作成する
タスク 4. テスト用の顧客データを読み込む
- インポート機能をテストするには、インポート スクリプトと前に作成したテストデータの両方を使用します。
node importTestData customers_1000.csv
次のような出力が返されます。
Writing record 500
Writing record 1000
Wrote 1000 records
- 次のようなエラーが発生することがあります。
Error: Cannot find module 'csv-parse'
その場合は、次のコマンドを実行して、csv-parse パッケージを環境に追加します。
npm install csv-parse
- 次に、コマンドを再実行します。次の出力が表示されます。
Writing record 500
Writing record 1000
Wrote 1000 records
ここまで、テストデータとスクリプトを作成して、Firestore にデータを読み込む方法を見てきました。
Patrick さんは、顧客データを Firestore データベースに読み込む作業に自信を持てるようになりました。
完了したタスクをテストする
[進行状況を確認] をクリックして、実行したタスクを確認します。
サンプル テストデータが Firestore データベースに正常に読み込まれた場合は、評価スコアが表示されます。
Firestore データベースにテストデータを読み込む
タスク 5. Firestore でデータを調べる
あなたと Ruby さんが少しサポートしたおかげで、Patrick さんはテストデータを Firestore データベースに問題なく移行できました。Firestore を開いて、結果を確認してください。
- Cloud コンソールのタブに戻ります。ナビゲーション メニューで、[Firestore] をクリックします。開いたら、鉛筆アイコンをクリックします。
-
/customers と入力し、Enter キーを押します。
-
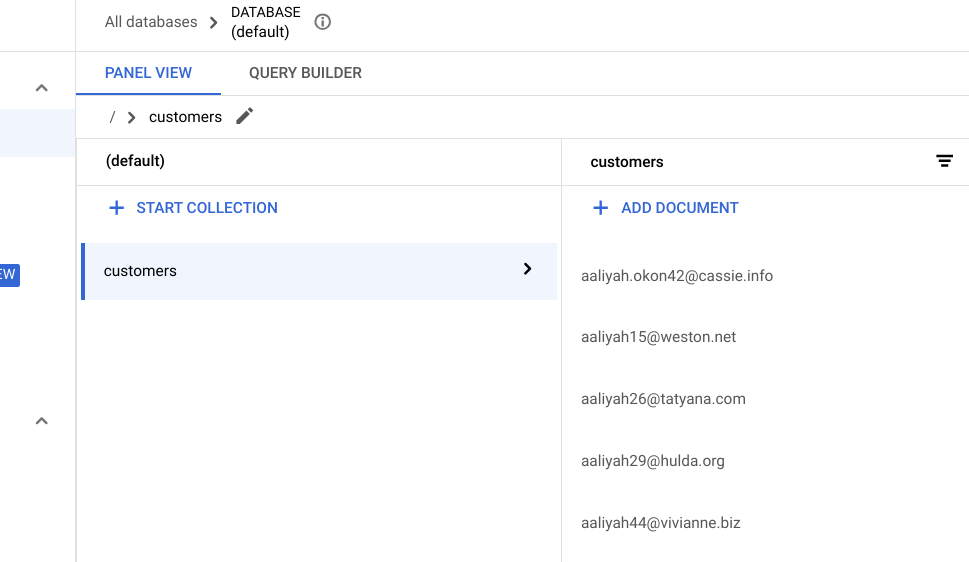
ブラウザのタブを更新すると、以下の顧客リストが正常に移行されたことがわかります。
お疲れさまでした
このラボでは、Firestore の実践演習を行いました。テスト用顧客データのコレクションを生成してから、スクリプトを実行してデータを Firestore に読み込みました。次に、Cloud コンソールを通じて Firestore のデータを操作する方法を学びました。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2024 年 2 月 28 日
ラボの最終テスト日: 2024 年 2 月 28 日
Copyright 2025 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。





