GSP642


概览
12 年前,Lily 创办了 Pet Theory 连锁宠物医院。近几年来,Pet Theory 宠物医院的规模迅速扩张。然而,他们的旧版预约系统无法应对日益增加的客流量,因此 Lily 想让您帮忙构建一个扩缩性优于旧版解决方案的云端系统。
Pet Theory 的运维团队只有 Patrick 一个人,因此需要一种无需持续进行大量维护工作的解决方案。该团队决定采用无服务器技术。
Pet Theory 聘请 Ruby 担任顾问,帮助他们改用无服务器技术。比较了几个无服务器数据库方案之后,该团队决定采用 Cloud Firestore。由于 Firestore 采用无服务器设计,因此无需提前配置容量,这意味着不存在存储空间不足或操作限制的风险。Firestore 通过实时监听器使您的数据在各个客户端应用之间保持同步,并为移动和 Web 客户端提供离线支持,可帮助您构建快速响应的应用,而无论网络延迟时间或互联网连接状况如何。
在此实验中,您需要帮助 Patrick 将 Pet Theory 的现有数据上传到 Cloud Firestore 数据库。他将与 Ruby 密切合作以实现这一目标。
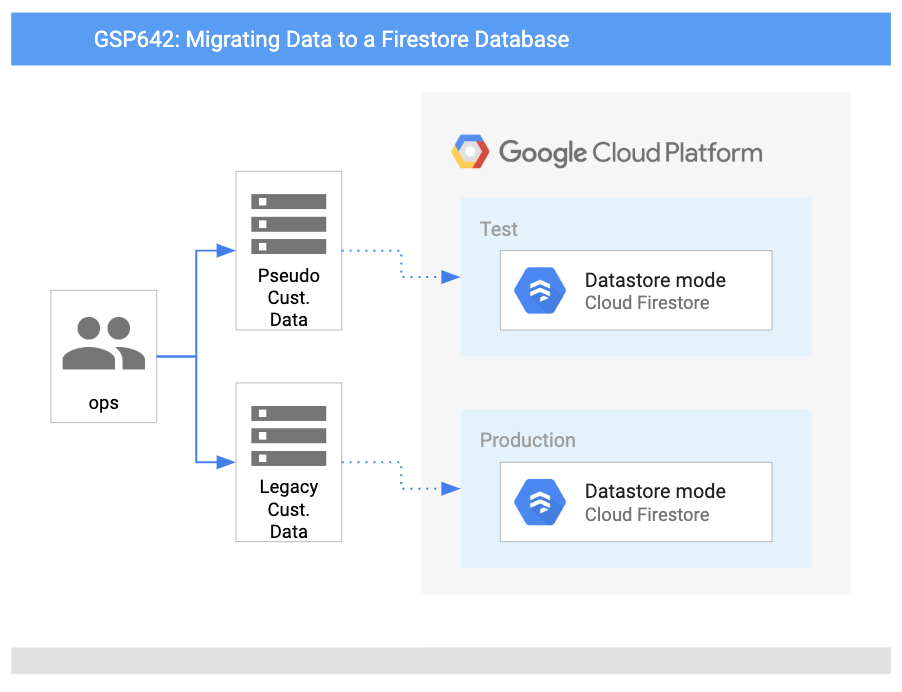
架构
下图概述了您将使用的服务,以及这些服务之间的关系:
目标
在本实验中,您将学习如何完成以下操作:
- 在 Google Cloud 中设置 Firestore。
- 编写数据库导入代码。
- 生成一系列用于测试的客户数据。
- 将用于测试的客户数据导入 Firestore。
前提条件
本实验是入门级实验。假设您熟悉 Cloud 控制台和 shell 环境。如果之前使用过 Firebase 会有所帮助,但这不是硬性要求。
您还应该能够自如地修改文件。您可以使用自己惯用的文本编辑器(如 nano、vi 等),也可以从 Cloud Shell 顶部的功能区启动代码编辑器:

准备就绪后,请向下滚动页面,并按下方步骤设置实验环境。
设置和要求
点击“开始实验”按钮前的注意事项
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。我们会为您提供新的临时凭据,让您可以在实验规定的时间内用来登录和访问 Google Cloud。
为完成此实验,您需要:
- 能够使用标准的互联网浏览器(建议使用 Chrome 浏览器)。
注意:请使用无痕模式或无痕浏览器窗口运行此实验。这可以避免您的个人账号与学生账号之间发生冲突,这种冲突可能导致您的个人账号产生额外费用。
注意:如果您已有自己的个人 Google Cloud 账号或项目,请不要在此实验中使用,以避免您的账号产生额外的费用。
如何开始实验并登录 Google Cloud 控制台
-
点击开始实验按钮。如果该实验需要付费,系统会打开一个弹出式窗口供您选择付款方式。左侧是实验详细信息面板,其中包含以下各项:
-
打开 Google Cloud 控制台按钮
- 剩余时间
- 进行该实验时必须使用的临时凭据
- 帮助您逐步完成本实验所需的其他信息(如果需要)
-
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示登录页面。
提示:请将这些标签页安排在不同的窗口中,并将它们并排显示。
注意:如果您看见选择账号对话框,请点击使用其他账号。
-
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
{{{user_0.username | "<用户名>"}}}
您也可以在实验详细信息面板中找到用户名。
-
点击下一步。
-
复制下面的密码,然后将其粘贴到欢迎对话框中。
{{{user_0.password | "<密码>"}}}
您也可以在实验详细信息面板中找到密码。
-
点击下一步。
重要提示:您必须使用实验提供的凭据。请勿使用您的 Google Cloud 账号凭据。
注意:在本次实验中使用您自己的 Google Cloud 账号可能会产生额外费用。
-
继续在后续页面中点击以完成相应操作:
- 接受条款及条件。
- 由于该账号为临时账号,请勿添加账号恢复选项或双重验证。
- 请勿注册免费试用。
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。
注意:如需查看列有 Google Cloud 产品和服务的菜单,请点击左上角的导航菜单。

激活 Cloud Shell
Cloud Shell 是一种装有开发者工具的虚拟机。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行。Cloud Shell 提供可用于访问您的 Google Cloud 资源的命令行工具。
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell
 。
。
如果您连接成功,即表示您已通过身份验证,且当前项目会被设为您的 PROJECT_ID 环境变量所指的项目。输出内容中有一行说明了此会话的 PROJECT_ID:
Your Cloud Platform project in this session is set to YOUR_PROJECT_ID
gcloud 是 Google Cloud 的命令行工具。它已预先安装在 Cloud Shell 上,且支持 Tab 自动补全功能。
- (可选)您可以通过此命令列出活跃账号名称:
gcloud auth list
-
点击授权。
-
现在,输出的内容应如下所示:
输出:
ACTIVE: *
ACCOUNT: student-01-xxxxxxxxxxxx@qwiklabs.net
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- (可选)您可以通过此命令列出项目 ID:
gcloud config list project
输出:
[core]
project = <project_ID>
输出示例:
[core]
project = qwiklabs-gcp-44776a13dea667a6
Note: For full documentation of gcloud, in Google Cloud, refer to the gcloud CLI overview guide.
任务 1. 在 Google Cloud 中设置 Firestore
Patrick 的任务是将 Pet Theory 的现有数据上传到 Cloud Firestore 数据库。他将与 Ruby 密切合作以实现这一目标。Ruby 收到了 IT 管理员 Patrick 的电子邮件…
|

IT 管理员 Patrick
|
Ruby,您好!
要采用无服务器技术,第一步是使用 Google Cloud 创建 Firestore 数据库。您能帮忙完成这项任务吗?我对这方面的设置不是很熟悉。
Patrick
|
|

软件顾问 Ruby
|
Patrick,您好!
当然可以,我很乐意提供帮助。我会向您发送一些新手入门资源,您创建好数据库之后,我们再联系。
Ruby
|
帮助 Patrick 通过 Cloud 控制台设置 Firestore 数据库。
-
在 Cloud 控制台中,找到导航菜单,选择 Firestore。
-
点击 +创建数据库。
-
选择原生模式选项,然后点击继续。
注意:两种模式在强一致性方面的效果都很出色,但它们看起来不同,而且针对不同用途进行了优化。
- 原生模式适用于让大量用户同时访问相同的数据(此外,它还具有实时更新等功能,而且可以在数据库与 Web/移动客户端之间建立直接连接)
- Datastore 模式侧重于高吞吐量(能够应对大量读写操作)。
- 在区域下拉菜单中,选择 区域,然后点击创建数据库。
这项任务完成后,Ruby 给 Patrick 发了一封电子邮件…
|
软件顾问 Ruby
|
Patrick,您好!
您已经设置了 Firestore 数据库,太棒了!为了管理数据库访问权限,我们将使用系统自动创建的服务账号,该账号具有必要的权限。
我们现在可以从旧数据库迁移到 Firestore 了。
Ruby
|
|

IT 管理员 Patrick
|
Ruby,您好!
感谢您提供帮助,设置 Firestore 数据库其实并不难。
希望数据库导入流程会比旧数据库简单,旧数据库的导入流程相当复杂,需要执行很多步骤。
Patrick
|
任务 2. 编写数据库导入代码
新的 Cloud Firestore 数据库已设置完成,但其中没有数据。Pet Theory 的客户数据仍然只保存在旧数据库中。
Patrick 给 Ruby 发了一封电子邮件…
|

IT 管理员 Patrick
|
Ruby,您好!
经理想要开始将客户数据迁移到新的 Firestore 数据库。
我已经从旧数据库导出了 CSV 文件,但不清楚如何将这些数据导入 Firestore。
您能帮我一下吗?
Patrick
|
|
软件顾问 Ruby
|
Patrick,您好!
当然可以,我们安排一次会议来讨论一下需要执行哪些操作。
Ruby
|
正如 Patrick 所说,客户数据采用 CSV 文件格式。现在帮助 Patrick 创建一个应用,用于读取 CSV 文件中的客户记录,然后将其写入 Firestore。Patrick 熟悉 JavaScript,因此我们将使用 Node.js JavaScript 运行时构建此应用。
- 在 Cloud Shell 中,运行以下命令来克隆 Pet Theory 仓库:
git clone https://github.com/rosera/pet-theory
- 使用 Cloud Shell 代码编辑器(或您惯用的编辑器)修改文件。在 Cloud Shell 会话顶部的功能区中,点击打开编辑器,系统将打开新的标签页。如果出现提示,请点击在新窗口中打开,以启动代码编辑器:
- 然后,将当前工作目录改为
lab01:
cd pet-theory/lab01
在该目录中,您可以看到 Patrick 的 package.json 文件。该文件列出了 Node.js 项目所依赖的软件包,并且让构建具有可重复性,与其他人共享时会更轻松。
package.json 文件示例如下所示:
{
"name": "lab01",
"version": "1.0.0",
"description": "This is lab01 of the Pet Theory labs",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "Patrick - IT",
"license": "MIT",
"dependencies": {
"csv-parse": "^5.5.3"
}
}
Patrick 现已导入源代码,他向 Ruby 发送电子邮件,询问需要使用哪些软件包来完成迁移工作。
|
IT 管理员 Patrick
|
Ruby,您好!
我在旧数据库中使用的代码非常简单,只能创建用于导入流程的 CSV 文件。在开始迁移之前,还需要下载什么吗?
Patrick
|
|
软件顾问 Ruby
|
Patrick,您好!
有很多 @google-cloud Node.js 软件包可与 Firestore 搭配使用,建议您选用一款。
这样一来,我们应该只需对现有代码进行少量更改,因为软件包会处理繁重的工作。
Ruby
|
为了让 Patrick 的代码能够将数据写入 Firestore 数据库,您需要安装一些其他的对等依赖项。
- 运行以下命令来进行安装:
npm install @google-cloud/firestore
- 若要让应用能够将日志写入 Cloud Logging,需要再安装一个模块:
npm install @google-cloud/logging
成功完成命令后,package.json 会自动更新,以纳入新的对等依赖项,如下所示:
...
"dependencies": {
"@google-cloud/firestore": "^7.3.0",
"@google-cloud/logging": "^11.0.0",
"csv-parse": "^5.5.3"
}
现在来看一下脚本如何读取包含客户数据的 CSV 文件,然后将 CSV 文件中的每行数据作为一条记录写入 Firestore。Patrick 原本的应用代码如下所示:
const csv = require('csv-parse');
const fs = require('fs');
function writeToDatabase(records) {
records.forEach((record, i) => {
console.log(`ID: ${record.id} Email: ${record.email} Name: ${record.name} Phone: ${record.phone}`);
});
return ;
}
async function importCsv(csvFilename) {
const parser = csv.parse({ columns: true, delimiter: ',' }, async function (err, records) {
if (e) {
console.error('Error parsing CSV:', e);
return;
}
try {
console.log(`Call write to Firestore`);
await writeToDatabase(records);
console.log(`Wrote ${records.length} records`);
} catch (e) {
console.error(e);
process.exit(1);
}
});
await fs.createReadStream(csvFilename).pipe(parser);
}
if (process.argv.length < 3) {
console.error('Please include a path to a csv file');
process.exit(1);
}
importCsv(process.argv[2]).catch(e => console.error(e));
这段代码会从输入 CSV 文件中获取输出,然后将其导入旧数据库。接下来,更新这段代码以写入 Firestore。
- 打开
pet-theory/lab01/importTestData.js 文件。
若要通过应用引用 Firestore API,您需要将对等依赖项添加到现有代码库。
- 在文件第 3 行添加以下 Firestore 依赖项:
const { Firestore } = require("@google-cloud/firestore");
确保文件顶部的内容如下所示:
const csv = require('csv-parse');
const fs = require('fs');
const { Firestore } = require("@google-cloud/firestore"); // Add this
只需几行代码即可实现与 Firestore 数据库的集成。为此,Ruby 分享了一些模板代码供您和 Patrick 参考。
- 在第 34 行下方或
if (process.argv.length < 3) 条件语句之后添加以下代码:
async function writeToFirestore(records) {
const db = new Firestore({
// projectId: projectId
});
const batch = db.batch()
records.forEach((record)=>{
console.log(`Write: ${record}`)
const docRef = db.collection("customers").doc(record.email);
batch.set(docRef, record, { merge: true })
})
batch.commit()
.then(() => {
console.log('Batch executed')
})
.catch(err => {
console.log(`Batch error: ${err}`)
})
return
}
以上代码段声明了一个新的数据库对象,该对象引用了在本实验前面步骤中创建的数据库。该函数采用依序处理每条记录的批处理方式,并根据新增的标识符给出文档引用。在该函数执行结束后,经过批处理的内容将提交(写入)到数据库。
- 更新
importCsv 函数,以添加对 writeToFirestore 的函数调用,并移除对 writeToDatabase 的调用。它应如下所示:
async function importCsv(csvFilename) {
const parser = csv.parse({ columns: true, delimiter: ',' }, async function (err, records) {
if (err) {
console.error('Error parsing CSV:', err);
return;
}
try {
console.log(`Call write to Firestore`);
await writeToFirestore(records);
// await writeToDatabase(records);
console.log(`Wrote ${records.length} records`);
} catch (e) {
console.error(e);
process.exit(1);
}
});
await fs.createReadStream(csvFilename).pipe(parser);
}
- 为应用添加日志记录。若要通过应用引用 Logging API,需要将对等依赖项添加到现有代码库。紧接文件顶部的其他 require 语句,添加下面这行代码:
const { Logging } = require('@google-cloud/logging');
确保文件顶部的内容如下所示:
const csv = require('csv-parse');
const fs = require('fs');
const { Firestore } = require("@google-cloud/firestore");
const { Logging } = require('@google-cloud/logging');
- 添加几个常量变量,然后将 Logging 客户端初始化。将这些变量添加到文件中紧接上面几行的位置(约在第 5 行),如下所示:
const logName = "pet-theory-logs-importTestData";
// Creates a Logging client
const logging = new Logging();
const log = logging.log(logName);
const resource = {
type: "global",
};
- 在“console.log(
Wrote ${records.length} records);”这行代码的下面添加代码,以将日志写入 importCsv 函数,结果应如下所示:
// A text log entry
success_message = `Success: importTestData - Wrote ${records.length} records`;
const entry = log.entry(
{ resource: resource },
{ message: `${success_message}` }
);
log.write([entry]);
完成这些更新后,importCsv 函数代码块应如下所示:
async function importCsv(csvFilename) {
const parser = csv.parse({ columns: true, delimiter: ',' }, async function (err, records) {
if (err) {
console.error('Error parsing CSV:', err);
return;
}
try {
console.log(`Call write to Firestore`);
await writeToFirestore(records);
// await writeToDatabase(records);
console.log(`Wrote ${records.length} records`);
// A text log entry
success_message = `Success: importTestData - Wrote ${records.length} records`;
const entry = log.entry(
{ resource: resource },
{ message: `${success_message}` }
);
log.write([entry]);
} catch (e) {
console.error(e);
process.exit(1);
}
});
await fs.createReadStream(csvFilename).pipe(parser);
}
现在,应用代码运行时,Firestore 数据库将根据 CSV 文件中的内容进行更新。importCsv 函数将获取文件名,并逐行解析其中的内容。处理的每行内容现在都会发送到 Firestore 函数 writeToFirestore,每条新记录都会写入“customer”数据库。
注意:在生产环境中,您将编写自己的导入脚本。
任务 3. 创建测试数据
现在可以导入一些数据了!Patrick 与 Ruby 联系,说明他对使用真实客户数据进行测试的担忧…
|

IT 管理员 Patrick
|
Ruby,您好!
我认为最好不要使用客户数据进行测试。我们需要保护客户隐私,但也需要确保我们的数据导入脚本能够正常运作。
您能提供其他测试方法吗?
Patrick
|
|
软件顾问 Ruby
|
Patrick,您好!
Patrick,您说得对。这个问题比较棘手,因为客户数据可能包括个人身份信息 (PII)。
我会分享一些用于创建伪客户数据的起始代码。这样,我们就能使用这些数据来测试导入脚本。
Ruby
|
帮助 Patrick 启动并运行这个伪随机数据生成器。
- 首先,安装“faker”库,该库将供用于生成虚假客户数据的脚本使用。运行以下命令,更新
package.json 中的依赖项:
npm install faker@5.5.3
- 现在,在代码编辑器中打开名为 createTestData.js 的文件,然后检查代码。确保代码如下所示:
const fs = require('fs');
const faker = require('faker');
function getRandomCustomerEmail(firstName, lastName) {
const provider = faker.internet.domainName();
const email = faker.internet.email(firstName, lastName, provider);
return email.toLowerCase();
}
async function createTestData(recordCount) {
const fileName = `customers_${recordCount}.csv`;
var f = fs.createWriteStream(fileName);
f.write('id,name,email,phone\n')
for (let i=0; i<recordCount; i++) {
const id = faker.datatype.number();
const firstName = faker.name.firstName();
const lastName = faker.name.lastName();
const name = `${firstName} ${lastName}`;
const email = getRandomCustomerEmail(firstName, lastName);
const phone = faker.phone.phoneNumber();
f.write(`${id},${name},${email},${phone}\n`);
}
console.log(`Created file ${fileName} containing ${recordCount} records.`);
}
recordCount = parseInt(process.argv[2]);
if (process.argv.length != 3 || recordCount < 1 || isNaN(recordCount)) {
console.error('Include the number of test data records to create. Example:');
console.error(' node createTestData.js 100');
process.exit(1);
}
createTestData(recordCount);
- 为代码库添加日志记录。在第 3 行,为应用代码中的 Logging API 模块添加以下引用:
const { Logging } = require("@google-cloud/logging");
文件顶部的内容现在应如下所示:
const fs = require("fs");
const faker = require("faker");
const { Logging } = require("@google-cloud/logging"); //add this
- 现在,添加几个常量变量,然后将 Logging 客户端初始化。将这些变量添加到紧接
const 语句的位置:
const logName = "pet-theory-logs-createTestData";
// Creates a Logging client
const logging = new Logging();
const log = logging.log(logName);
const resource = {
// This example targets the "global" resource for simplicity
type: "global",
};
- 在“console.log(
Created file ${fileName} containing ${recordCount} records.);”这行代码的下面添加代码,以将日志写入 createTestData 函数,结果应如下所示:
// A text log entry
const success_message = `Success: createTestData - Created file ${fileName} containing ${recordCount} records.`;
const entry = log.entry(
{ resource: resource },
{
name: `${fileName}`,
recordCount: `${recordCount}`,
message: `${success_message}`,
}
);
log.write([entry]);
- 更新后,
createTestData 函数代码块应如下所示:
async function createTestData(recordCount) {
const fileName = `customers_${recordCount}.csv`;
var f = fs.createWriteStream(fileName);
f.write('id,name,email,phone\n')
for (let i=0; i<recordCount; i++) {
const id = faker.datatype.number();
const firstName = faker.name.firstName();
const lastName = faker.name.lastName();
const name = `${firstName} ${lastName}`;
const email = getRandomCustomerEmail(firstName, lastName);
const phone = faker.phone.phoneNumber();
f.write(`${id},${name},${email},${phone}\n`);
}
console.log(`Created file ${fileName} containing ${recordCount} records.`);
// A text log entry
const success_message = `Success: createTestData - Created file ${fileName} containing ${recordCount} records.`;
const entry = log.entry(
{ resource: resource },
{
name: `${fileName}`,
recordCount: `${recordCount}`,
message: `${success_message}`,
}
);
log.write([entry]);
}
- 在 Cloud Shell 中运行以下命令,以创建
customers_1000.csv 文件,该文件将包含 1,000 条测试数据记录:
node createTestData 1000
您应该会看到类似以下内容的输出:
Created file customers_1000.csv containing 1000 records.
- 打开
customers_1000.csv 文件,验证测试数据是否已创建完成。
验证您已完成的任务
点击检查我的进度,验证您已完成的任务。如果您已成功为 Firestore 数据库创建测试数据样本,系统会显示一个评估分数。
为 Firestore 数据库创建测试数据
任务 4. 导入用于测试的客户数据
- 若要测试导入功能,请使用导入脚本,以及在前面创建的测试数据:
node importTestData customers_1000.csv
您应该会看到类似以下内容的输出:
Writing record 500
Writing record 1000
Wrote 1000 records
- 如果出现类似以下内容的错误:
Error: Cannot find module 'csv-parse'
运行以下命令,将 csv-parse 软件包添加到环境:
npm install csv-parse
- 然后,再次运行前面的导入命令。您应该会看到类似以下内容的输出:
Writing record 500
Writing record 1000
Wrote 1000 records
通过前面的几个任务,您已经了解了 Patrick 和 Ruby 如何创建测试数据和脚本,以将数据导入 Firestore。Patrick 现在可以更有信心地将客户数据加载到 Firestore 数据库。
验证您已完成的任务
点击检查我的进度,验证您已完成的任务。如果您已成功将测试数据样本导入 Firestore 数据库,系统会显示一个评估分数。
将测试数据导入 Firestore 数据库
任务 5. 检查 Firestore 中的数据
在您和 Ruby 的帮助下,Patrick 现在已成功将测试数据迁移到 Firestore 数据库。打开 Firestore 看看结果吧!
- 返回到 Cloud 控制台标签页。在导航菜单中,点击 Firestore。然后点击铅笔图标。
-
输入 /customers 并按 Enter 键。
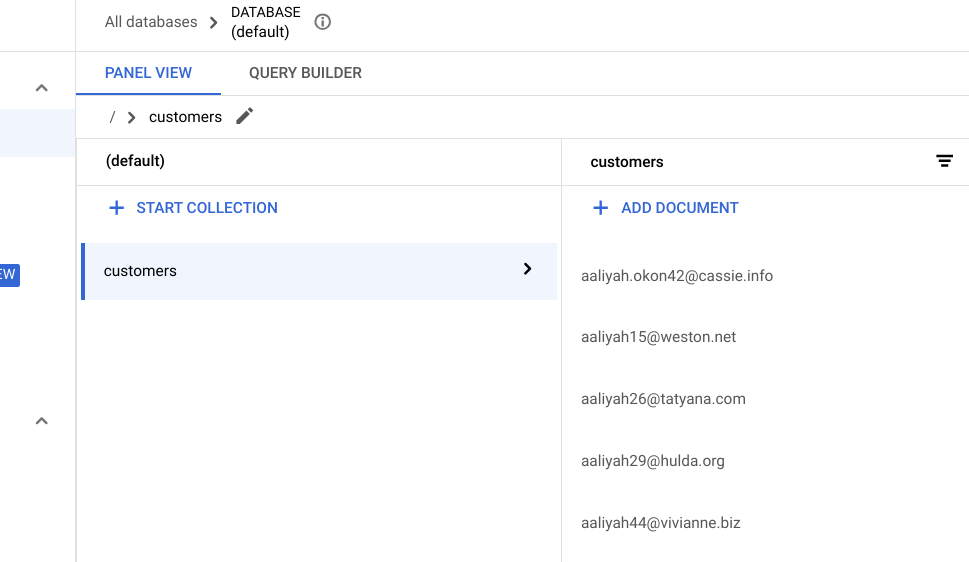
-
刷新浏览器标签页,您应该会看到已成功迁移的客户名单,如下所示:
恭喜!
在本实验中,您使用 Firestore 进行了实操练习。在生成一系列用于测试的客户数据后,您运行了一个脚本来将数据导入 Firestore。然后,您了解了如何通过 Cloud 控制台操作 Firestore 中的数据。
Google Cloud 培训和认证
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
上次更新手册的时间:2024 年 2 月 28 日
上次测试实验的时间:2024 年 2 月 28 日
版权所有 2025 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。





