Puntos de control
Enable relevant APIs.
/ 5
Application is developed with Story tab.
/ 5
Application marketing campaign tab is developed.
/ 5
Application image playground with furniture recommendation tab is developed.
/ 5
Image playground with oven instructions tab is developed.
/ 10
Image playground with ER diagrams tab is developed
/ 10
Image playground with math reasoning tab is developed.
/ 10
Application video playground with video description tab is developed.
/ 10
Video playground with video tags tab is developed.
/ 10
Video playground with video highlights tab is developed.
/ 10
Video playground with video geolocation tab is developed.
/ 10
Application is deployed to Cloud Run.
/ 10
Desarrolla una app con Gemini 1.0 Pro de Vertex AI
- Descripción general
- Objetivos
- Configuración
- Tarea 1: Configura tu entorno y proyecto
- Tarea 2: Configura el entorno de aplicaciones
- Tarea 3. Desarrolla la app
- Tarea 4: Ejecuta y prueba la app localmente
- Tarea 5: Genera una campaña de marketing
- Tarea 6: Genera el playground de imágenes
- Tarea 7: Analiza el diseño de imágenes
- Tarea 8: Analiza diagramas de ER
- Tarea 9: Razonamiento matemático
- Tarea 10: Genera el playground de videos
- Tarea 11: Genera etiquetas de video
- Tarea 12: Genera videos destacados
- Tarea 13: Genera la ubicación del video
- Tarea 14: Implementa la app en Cloud Run
- Finalice su lab
- ¡Felicitaciones!
Descripción general
Gemini es el nombre de una familia de modelos de IA generativa diseñados para casos de uso multimodales. Viene en tres tamaños: Ultra, Pro y Nano. Gemini 1.0 Pro está disponible para que desarrolladores y empresas compilen para tus propios casos de uso. Gemini 1.0 Pro acepta texto como entrada y genera texto como salida. También hay un extremo multimodal exclusivo de Gemini 1.0 Pro Vision que acepta texto y, además, imágenes como entrada, y genera texto como salida. Hay SDK disponibles para ayudarte a compilar apps en Python, Android (Kotlin), Node.js, Swift y JavaScript.
En Google Cloud, la API de Gemini de Vertex AI ofrece una interfaz unificada para interactuar con modelos de Gemini. La API admite instrucciones multimodales como entrada y muestra texto o código como salida. Actualmente, hay dos modelos disponibles en la API de Gemini:
-
Modelo de Gemini 1.0 Pro (gemini-pro): Se diseñó para realizar tareas de lenguaje natural, chat de código y texto de varios turnos, y de generación de código.
-
Modelo de Gemini 1.0 Pro Vision (gemini-pro-vision): Admite instrucciones multimodales. Puedes incluir texto, imágenes y video en las solicitudes de instrucciones y obtener respuestas de texto o código.
Vertex AI es una plataforma de aprendizaje automático (AA) que te permite entrenar y, también, implementar modelos de AA y aplicaciones de IA, y personalizar modelos de lenguaje grande (LLM) para usarlos en tus aplicaciones impulsadas por IA. Vertex AI permite la personalización de Gemini con control total de datos y beneficios de funciones adicionales de Google Cloud para mejorar la seguridad, la privacidad y el cumplimiento y la administración de datos. Para obtener más información sobre Vertex AI, consulta el vínculo en la sección Próximos pasos al final del lab.
En este lab, se usa el SDK de Vertex AI para Python para llamar a la API de Gemini de Vertex AI.
Objetivos
En este lab, aprenderás a realizar las siguientes tareas:
- Desarrollar una app de Python usando el framework de Streamlit
- Instalar el SDK de Vertex AI para Python
- Desarrollar código para interactuar con el modelo de Gemini 1.0 Pro (gemini-pro) usando la API de Gemini de Vertex AI.
- Desarrollar código para interactuar con el modelo de Gemini 1.0 Pro Vision (gemini-pro-vision) usando la API de Gemini de Vertex AI.
- Alojar tu aplicación en contenedores y, también, implementarla y probarla en Cloud Run
Configuración
En cada lab, recibirá un proyecto de Google Cloud y un conjunto de recursos nuevos por tiempo limitado y sin costo adicional.
-
Accede a Qwiklabs desde una ventana de incógnito.
-
Ten en cuenta el tiempo de acceso del lab (por ejemplo,
1:15:00) y asegúrate de finalizarlo en el plazo asignado.
No existe una función de pausa. Si lo necesita, puede reiniciar el lab, pero deberá hacerlo desde el comienzo. -
Cuando esté listo, haga clic en Comenzar lab.
-
Anote las credenciales del lab (el nombre de usuario y la contraseña). Las usarás para acceder a la consola de Google Cloud.
-
Haga clic en Abrir Google Console.
-
Haga clic en Usar otra cuenta, copie las credenciales para este lab y péguelas en el mensaje emergente que aparece.
Si usa otras credenciales, se generarán errores o incurrirá en cargos. -
Acepta las condiciones y omite la página de recursos de recuperación.
Active Cloud Shell
Cloud Shell es una máquina virtual que contiene herramientas de desarrollo y un directorio principal persistente de 5 GB. Se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a sus recursos de Google Cloud. gcloud es la herramienta de línea de comandos de Google Cloud, la cual está preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
-
En el panel de navegación de Google Cloud Console, haga clic en Activar Cloud Shell (
).
-
Haga clic en Continuar.
El aprovisionamiento y la conexión al entorno tardan solo unos momentos. Una vez que se conecte, también estará autenticado, y el proyecto estará configurado con su PROJECT_ID. Por ejemplo:

Comandos de muestra
-
Si desea ver el nombre de cuenta activa, use este comando:
(Resultado)
(Resultado de ejemplo)
-
Si desea ver el ID del proyecto, use este comando:
(Resultado)
(Resultado de ejemplo)
Tarea 1: Configura tu entorno y proyecto
-
Accede a la consola de Google Cloud con tus credenciales de lab y abre la ventana de terminal de Cloud Shell.
-
Para configurar tu ID del proyecto y las variables de entorno de la región, en Cloud Shell, ejecuta los siguientes comandos:
PROJECT_ID=$(gcloud config get-value project) REGION={{{project_0.default_region|set at lab start}}} echo "PROJECT_ID=${PROJECT_ID}" echo "REGION=${REGION}" -
Para usar distintos servicios de Google Cloud en este lab, debes habilitar algunas APIs:
gcloud services enable cloudbuild.googleapis.com cloudfunctions.googleapis.com run.googleapis.com logging.googleapis.com storage-component.googleapis.com aiplatform.googleapis.com
Para verificar este objetivo, haz clic en Revisar mi progreso.
Tarea 2: Configura el entorno de aplicaciones
En esta tarea, configurarás un entorno virtual de Python y, además, instalarás las dependencias de la aplicación.
Confirma que Cloud Shell está autorizado
-
Para confirmar que Cloud Shell está autorizado, en Cloud Shell, ejecuta el siguiente comando:
gcloud auth list -
Si se te solicita que autorices Cloud Shell, haz clic en Autorizar.
Crea el directorio de apps
-
Para crear el directorio de apps, ejecuta el siguiente comando:
mkdir ~/gemini-app -
Cambia al directorio
~/gemini-app:cd ~/gemini-app Los archivos de la aplicación se crean en el directorio
~/gemini-app. En el directorio, estarán los archivos de origen de la aplicación de Python, las dependencias y un archivo de Docker que se usarán más adelante en el lab.
Configura un entorno virtual de Python
Crea un entorno virtual además de la instalación actual de Python para que todos los paquetes instalados en ese entorno se separen de los paquetes en el entorno base. Cuando se usan dentro de un entorno virtual, las herramientas de instalación como pip instalarán paquetes de Python en el entorno virtual.
-
Para crear un entorno virtual de Python, desde la carpeta
gemini-app, ejecuta el comando:python3 -m venv gemini-streamlit El módulo venv crea un entorno virtual ligero con su propio conjunto independiente de paquetes de Python. -
Activa el entorno virtual de Python:
source gemini-streamlit/bin/activate
Instala dependencias de la aplicación
Un archivo de requisitos de Python es un archivo de texto simple en el que se detallan las dependencias que requiere el proyecto. Para empezar, se necesitan tres módulos en un archivo de requisitos.
Nuestra app se escribe con Streamlit, una biblioteca de Python de código abierto que se usa para crear apps web para aprendizaje automático y ciencia de datos. La app usa el SDK de Vertex AI para que la biblioteca de Python interactúe con los modelos y la API de Gemini. Cloud Logging se usa para registrar información desde nuestra aplicación.
-
Para crear el archivo de requisitos, ejecuta el siguiente comando:
cat > ~/gemini-app/requirements.txt <<EOF streamlit google-cloud-aiplatform==1.38.1 google-cloud-logging==3.6.0 EOF -
Instala las dependencias de la aplicación:
pip install -r requirements.txt pip es el instalador de paquetes para Python.
Espera a que se instalen los paquetes antes de continuar con la siguiente tarea.
Tarea 3. Desarrolla la app
El código fuente de la app se escribirá en varios archivos fuente .py. Comencemos con el punto de entrada principal en app.py.
Escribe el punto de entrada principal de la app
-
Para crear el código del punto de entrada
app.py, ejecuta el siguiente comando:cat > ~/gemini-app/app.py <<EOF import os import streamlit as st from app_tab1 import render_story_tab from vertexai.preview.generative_models import GenerativeModel import vertexai import logging from google.cloud import logging as cloud_logging # configure logging logging.basicConfig(level=logging.INFO) # attach a Cloud Logging handler to the root logger log_client = cloud_logging.Client() log_client.setup_logging() PROJECT_ID = os.environ.get('PROJECT_ID') # Your Qwiklabs Google Cloud Project ID LOCATION = os.environ.get('REGION') # Your Qwiklabs Google Cloud Project Region vertexai.init(project=PROJECT_ID, location=LOCATION) @st.cache_resource def load_models(): text_model_pro = GenerativeModel("gemini-pro") multimodal_model_pro = GenerativeModel("gemini-pro-vision") return text_model_pro, multimodal_model_pro st.header("Vertex AI Gemini API", divider="rainbow") text_model_pro, multimodal_model_pro = load_models() tab1, tab2, tab3, tab4 = st.tabs(["Story", "Marketing Campaign", "Image Playground", "Video Playground"]) with tab1: render_story_tab(text_model_pro) EOF -
Consulta el contenido del archivo
app.py:cat ~/gemini-app/app.py La app usa
streamlitpara crear varias pestañas en la IU. En esta versión inicial de la app, compilamos la primera pestaña Story que incluye la funcionalidad para generar una historia. Luego, compilamos de forma incremental las otras pestañas en tareas subsecuentes en el lab.Primero, la app inicializa el paso del
SDK de Vertex AIen los valores de las variables de entorno PROJECT_ID y REGION.Luego, carga los modelos de
gemini-pro, ygemini-pro-visionusando la claseGenerativeModelque representa un modelo de Gemini. Esa clase incluye métodos que ayudan a generar contenido a partir de texto, imágenes y video.La app crea 4 pestañas en la IU denominadas Story, Marketing Campaign, Image Playground y Video Playground.
Después, el código de la app invoca la función
render_tab1()para crear la IU de la pestaña Story en la IU de la app.
Desarrolla la pestaña 1: Story
-
Para escribir el código que renderiza la pestaña Story en la IU de la app, ejecuta el siguiente comando:
cat > ~/gemini-app/app_tab1.py <<EOF import streamlit as st from vertexai.preview.generative_models import GenerativeModel from response_utils import * import logging # create the model prompt based on user input. def generate_prompt(): # Story character input character_name = st.text_input("Enter character name: \n\n",key="character_name",value="Mittens") character_type = st.text_input("What type of character is it? \n\n",key="character_type",value="Cat") character_persona = st.text_input("What personality does the character have? \n\n", key="character_persona",value="Mitten is a very friendly cat.") character_location = st.text_input("Where does the character live? \n\n",key="character_location",value="Andromeda Galaxy") # Story length and premise length_of_story = st.radio("Select the length of the story: \n\n",["Short","Long"],key="length_of_story",horizontal=True) story_premise = st.multiselect("What is the story premise? (can select multiple) \n\n",["Love","Adventure","Mystery","Horror","Comedy","Sci-Fi","Fantasy","Thriller"],key="story_premise",default=["Love","Adventure"]) creative_control = st.radio("Select the creativity level: \n\n",["Low","High"],key="creative_control",horizontal=True) if creative_control == "Low": temperature = 0.30 else: temperature = 0.95 prompt = f"""Write a {length_of_story} story based on the following premise: \n character_name: {character_name} \n character_type: {character_type} \n character_persona: {character_persona} \n character_location: {character_location} \n story_premise: {",".join(story_premise)} \n If the story is "short", then make sure to have 5 chapters or else if it is "long" then 10 chapters. Important point is that each chapter should be generated based on the premise given above. First start by giving the book introduction, chapter introductions and then each chapter. It should also have a proper ending. The book should have a prologue and an epilogue. """ return temperature, prompt # function to render the story tab, and call the model, and display the model prompt and response. def render_story_tab (text_model_pro: GenerativeModel): st.write("Using Gemini 1.0 Pro - Text only model") st.subheader("Generate a story") temperature, prompt = generate_prompt() config = { "temperature": temperature, "max_output_tokens": 2048, } generate_t2t = st.button("Generate my story", key="generate_t2t") if generate_t2t and prompt: # st.write(prompt) with st.spinner("Generating your story using Gemini..."): first_tab1, first_tab2 = st.tabs(["Story response", "Prompt"]) with first_tab1: response = get_gemini_pro_text_response(text_model_pro, prompt, generation_config=config) if response: st.write("Your story:") st.write(response) logging.info(response) with first_tab2: st.text(prompt) EOF -
Consulta el contenido del archivo
app_tab1.py:cat ~/gemini-app/app_tab1.py La función
render_story_tabgenera los controles de la IU en la pestaña invocando funciones para renderizar los campos de entrada de texto y otras opciones.La función
generate_promptgenera la instrucción de texto que se proporciona a la API de Gemini. La cadena de instrucción se crea por medio de la concatenación de valores que ingresa el usuario en la IU de la pestaña para el personaje de la historia y opciones como la extensión de la historia (corta o larga), el nivel de creatividad (bajo o alto) y la premisa.La función también muestra un valor
temperaturebasado en el nivel de creatividad seleccionado. Ese valor se proporciona como el parámetro de configuración detemperatureal modelo, que controla la aleatoriedad de las predicciones del modelo. El parámetro de configuraciónmax_output_tokensespecifica el número máximo de tokens de salida que se deben generar por mensaje.Para generar la respuesta del modelo, se crea un botón en la IU de la pestaña. Cuando se hace clic en el botón, se invoca la función
get_gemini_pro_text_response, cuyo código escribiremos en el próximo paso en el lab.
Desarrolla response_utils
El archivo response_utils.py contiene funciones para generar las respuestas del modelo.
-
Para escribir código para generar la respuesta de texto del modelo, ejecuta el siguiente comando:
cat > ~/gemini-app/response_utils.py <<EOF from vertexai.preview.generative_models import (Content, GenerationConfig, GenerativeModel, GenerationResponse, Image, HarmCategory, HarmBlockThreshold, Part) def get_gemini_pro_text_response( model: GenerativeModel, prompt: str, generation_config: GenerationConfig, stream=True): safety_settings={ HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE, } responses = model.generate_content(prompt, generation_config = generation_config, safety_settings = safety_settings, stream=True) final_response = [] for response in responses: try: final_response.append(response.text) except IndexError: final_response.append("") continue return " ".join(final_response) EOF -
Consulta el contenido del archivo
response_utils.py:cat ~/gemini-app/response_utils.py En la función
get_gemini_pro_text_response, se usan la claseGenerativeModely algunas de las otras clases del paquetevertexai.preview.generative_modelsen el SDK de Vertex AI para Python. Del métodogenerate_contentde la clase, se genera una respuesta usando la instrucción de texto que se pasa al método.También se pasa un objeto
safety_settingsal método para controlar la respuesta del modelo y bloquear contenido no seguro. En el código de muestra de este lab, se usan valores de configuración de seguridad que le indican al modelo que siempre muestre contenido independientemente de la probabilidad de que el contenido no sea seguro. Puedes evaluar el contenido generado y, luego, ajustar esos parámetros de configuración si la aplicación requiere una configuración más restrictiva. Para obtener más información, consulta la documentación sobre parámetros de configuración de seguridad.
Tarea 4: Ejecuta y prueba la app localmente
En esta tarea, ejecutas la app localmente usando streamlit y pruebas las funciones de la app.
Ejecuta la app
-
Para ejecutar la app localmente, en Cloud Shell, ejecuta el siguiente comando:
streamlit run app.py \ --browser.serverAddress=localhost \ --server.enableCORS=false \ --server.enableXsrfProtection=false \ --server.port 8080 Se inicia la app y se te proporciona una URL para acceder a ella.
-
Para lanzar la página principal de la app en tu navegador, haz clic en Vista previa en la Web en la barra de menú de Cloud Shell y, luego, en Vista previa en el puerto 8080.
También puedes copiar y pegar la URL de la app en una pestaña separada del navegador para acceder a la app.
Prueba la app: Pestaña Story
Genera una historia proporcionando tu entrada y consulta la instrucción y la respuesta que genera el modelo de Gemini 1.0 Pro.
-
Para generar una historia, en la pestaña Story, deja los parámetros predeterminados de configuración y, luego, haz clic en Generate my story.
-
Espera a que se genere la respuesta y, luego, haz clic en la pestaña Story response.
-
Para ver la instrucción que se usó para generar la respuesta, haz clic en la pestaña Prompt.
-
En la ventana de Cloud Shell, finaliza la app y vuelve al símbolo del sistema presionando control+c.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Tarea 5: Genera una campaña de marketing
En esta tarea, usarás el modelo de texto de Gemini 1.0 Pro para generar una campaña de marketing para una empresa. Desarrollarás el código que genera una segunda pestaña en tu app.
Desarrolla la pestaña 2: Marketing Campaign
-
Para escribir el código que renderiza la pestaña Marketing Campaign en la IU de la app, ejecuta el siguiente comando:
cat > ~/gemini-app/app_tab2.py <<EOF import streamlit as st from vertexai.preview.generative_models import GenerativeModel from response_utils import * import logging # create the model prompt based on user input. def generate_prompt(): st.write("Using Gemini 1.0 Pro - Text only model") st.subheader("Generate your marketing campaign") product_name = st.text_input("What is the name of the product? \n\n",key="product_name",value="ZomZoo") product_category = st.radio("Select your product category: \n\n",["Clothing","Electronics","Food","Health & Beauty","Home & Garden"],key="product_category",horizontal=True) st.write("Select your target audience: ") target_audience_age = st.radio("Target age: \n\n",["18-24","25-34","35-44","45-54","55-64","65+"],key="target_audience_age",horizontal=True) # target_audience_gender = st.radio("Target gender: \n\n",["male","female","trans","non-binary","others"],key="target_audience_gender",horizontal=True) target_audience_location = st.radio("Target location: \n\n",["Urban", "Suburban","Rural"],key="target_audience_location",horizontal=True) st.write("Select your marketing campaign goal: ") campaign_goal = st.multiselect("Select your marketing campaign goal: \n\n",["Increase brand awareness","Generate leads","Drive sales","Improve brand sentiment"],key="campaign_goal",default=["Increase brand awareness","Generate leads"]) if campaign_goal is None: campaign_goal = ["Increase brand awareness","Generate leads"] brand_voice = st.radio("Select your brand voice: \n\n",["Formal","Informal","Serious","Humorous"],key="brand_voice",horizontal=True) estimated_budget = st.radio("Select your estimated budget ($): \n\n",["1,000-5,000","5,000-10,000","10,000-20,000","20,000+"],key="estimated_budget",horizontal=True) prompt = f"""Generate a marketing campaign for {product_name}, a {product_category} designed for the age group: {target_audience_age}. The target location is this: {target_audience_location}. Aim to primarily achieve {campaign_goal}. Emphasize the product's unique selling proposition while using a {brand_voice} tone of voice. Allocate the total budget of {estimated_budget}. With these inputs, make sure to follow following guidelines and generate the marketing campaign with proper headlines: \n - Briefly describe the company, its values, mission, and target audience. - Highlight any relevant brand guidelines or messaging frameworks. - Provide a concise overview of the campaign's objectives and goals. - Briefly explain the product or service being promoted. - Define your ideal customer with clear demographics, psychographics, and behavioral insights. - Understand their needs, wants, motivations, and pain points. - Clearly articulate the desired outcomes for the campaign. - Use SMART goals (Specific, Measurable, Achievable, Relevant, and Time-bound) for clarity. - Define key performance indicators (KPIs) to track progress and success. - Specify the primary and secondary goals of the campaign. - Examples include brand awareness, lead generation, sales growth, or website traffic. - Clearly define what differentiates your product or service from competitors. - Emphasize the value proposition and unique benefits offered to the target audience. - Define the desired tone and personality of the campaign messaging. - Identify the specific channels you will use to reach your target audience. - Clearly state the desired action you want the audience to take. - Make it specific, compelling, and easy to understand. - Identify and analyze your key competitors in the market. - Understand their strengths and weaknesses, target audience, and marketing strategies. - Develop a differentiation strategy to stand out from the competition. - Define how you will track the success of the campaign. - Use relevant KPIs to measure performance and return on investment (ROI). Provide bullet points and headlines for the marketing campaign. Do not produce any empty lines. Be very succinct and to the point. """ return prompt # function to render the story tab, and call the model, and display the model prompt and response. def render_mktg_campaign_tab (text_model_pro: GenerativeModel): st.write("Using Gemini 1.0 Pro - Text only model") st.subheader("Generate a marketing campaign") prompt = generate_prompt() config = { "temperature": 0.8, "max_output_tokens": 2048, } generate_t2m = st.button("Generate campaign", key="generate_t2m") if generate_t2m and prompt: # st.write(prompt) with st.spinner("Generating a marketing campaign using Gemini..."): first_tab1, first_tab2 = st.tabs(["Campaign response", "Prompt"]) with first_tab1: response = get_gemini_pro_text_response(text_model_pro, prompt, generation_config=config) if response: st.write("Marketing campaign:") st.write(response) logging.info(response) with first_tab2: st.text(prompt) EOF
Modifica el punto de entrada principal de la app
-
Para agregar la pestaña 2 a la app, ejecuta el siguiente comando:
cat >> ~/gemini-app/app.py <<EOF from app_tab2 import render_mktg_campaign_tab with tab2: render_mktg_campaign_tab(text_model_pro) EOF
Prueba la app: Pestaña Marketing campaign
Genera una campaña de marketing proporcionando tu entrada y consulta la instrucción y la respuesta que genera el modelo de Gemini 1.0 Pro.
-
Para ejecutar la app localmente, en Cloud Shell, ejecuta el siguiente comando:
streamlit run app.py \ --browser.serverAddress=localhost \ --server.enableCORS=false \ --server.enableXsrfProtection=false \ --server.port 8080 Se inicia la app y se te proporciona una URL para acceder a ella.
-
Para lanzar la página principal de la app en tu navegador, haz clic en Vista previa en la Web en la barra de menú de Cloud Shell y, luego, en Vista previa en el puerto 8080.
-
Para generar una campaña de marketing, en la pestaña Marketing campaign, deja los parámetros de configuración predeterminados y haz clic en Generate campaign.
-
Espera a que se genere la respuesta y, luego, haz clic en la pestaña Campaign response.
-
Para ver la instrucción que se usó para generar la respuesta, haz clic en la pestaña Prompt.
-
Repite los pasos anteriores para generar campañas de marketing con diferentes valores de los parámetros, como objetivos de la campaña, ubicación, categoría de producto y público objetivo.
-
En la ventana de Cloud Shell, finaliza la app y vuelve al símbolo del sistema presionando control+c.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Tarea 6: Genera el playground de imágenes
En esta tarea, usas el modelo de Gemini 1.0 Pro Vision para procesar imágenes y recibir recomendaciones y también información de las imágenes que se proporcionan al modelo.
Desarrolla la pestaña 3: Image Playground
En esta subtarea, implementas el código para la pestaña Image Playground y el código para interactuar con el modelo y generar recomendaciones a partir de una imagen
-
Para escribir el código que renderiza la pestaña Image Playground en la IU de la app, ejecuta el siguiente comando:
cat > ~/gemini-app/app_tab3.py <<EOF import streamlit as st from vertexai.preview.generative_models import GenerativeModel, Part from response_utils import * import logging # render the Image Playground tab with multiple child tabs def render_image_playground_tab(multimodal_model_pro: GenerativeModel): st.write("Using Gemini 1.0 Pro Vision - Multimodal model") recommendations, screens, diagrams, equations = st.tabs(["Furniture recommendation", "Oven instructions", "ER diagrams", "Math reasoning"]) with recommendations: room_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/living_room.jpeg" chair_1_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair1.jpeg" chair_2_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair2.jpeg" chair_3_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair3.jpeg" chair_4_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair4.jpeg" room_image_url = "https://storage.googleapis.com/"+room_image_uri.split("gs://")[1] chair_1_image_url = "https://storage.googleapis.com/"+chair_1_image_uri.split("gs://")[1] chair_2_image_url = "https://storage.googleapis.com/"+chair_2_image_uri.split("gs://")[1] chair_3_image_url = "https://storage.googleapis.com/"+chair_3_image_uri.split("gs://")[1] chair_4_image_url = "https://storage.googleapis.com/"+chair_4_image_uri.split("gs://")[1] room_image = Part.from_uri(room_image_uri, mime_type="image/jpeg") chair_1_image = Part.from_uri(chair_1_image_uri,mime_type="image/jpeg") chair_2_image = Part.from_uri(chair_2_image_uri,mime_type="image/jpeg") chair_3_image = Part.from_uri(chair_3_image_uri,mime_type="image/jpeg") chair_4_image = Part.from_uri(chair_4_image_uri,mime_type="image/jpeg") st.image(room_image_url,width=350, caption="Image of a living room") st.image([chair_1_image_url,chair_2_image_url,chair_3_image_url,chair_4_image_url],width=200, caption=["Chair 1","Chair 2","Chair 3","Chair 4"]) st.write("Our expectation: Recommend a chair that would complement the given image of a living room.") prompt_list = ["Consider the following chairs:", "chair 1:", chair_1_image, "chair 2:", chair_2_image, "chair 3:", chair_3_image, "and", "chair 4:", chair_4_image, "\n" "For each chair, explain why it would be suitable or not suitable for the following room:", room_image, "Only recommend for the room provided and not other rooms. Provide your recommendation in a table format with chair name and reason as columns.", ] tab1, tab2 = st.tabs(["Response", "Prompt"]) generate_image_description = st.button("Generate recommendation", key="generate_image_description") with tab1: if generate_image_description and prompt_list: with st.spinner("Generating recommendation using Gemini..."): response = get_gemini_pro_vision_response(multimodal_model_pro, prompt_list) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.text(prompt_list) EOF -
Consulta el contenido del archivo
app_tab3.py:cat ~/gemini-app/app_tab3.py Con la función
render_image_playground_tab, se compila la IU que habilita al usuario de la app para interactuar con el modelo de Gemini 1.0 Pro Vision. Se crea un conjunto de etiquetas en la IU: "Furniture recommendation", "Oven instructions", "ER diagrams" y "Math reasoning". Escribirás el código para las pestañas restantes en tareas posteriores en este lab.En la pestaña
Furniture recommendation, se usa un ambiente de sala de estar para hacer una comprensión visual. Junto con un conjunto adicional de imágenes de sillones, el código invoca al extremo multimodal de la API de Gemini 1.0 Pro Vision para obtener una recomendación de un sillón que complemente el ambiente de sala de estar.En este código, se usa más de una instrucción de texto y las imágenes de la sala de estar y los sillones. Eso se proporciona en una lista al modelo. La clase
Partse usa para obtener la imagen de la URI de contenido de varias partes que se aloja en un bucket de Cloud Storage. En la instrucción, también se especifica un formato tabular para la salida del modelo y para incluir la justificación de la recomendación.

Actualiza response_utils
El archivo response_utils.py contiene funciones para generar las respuestas del modelo.
-
Actualiza el archivo para agregar código que genere la respuesta multimodal del modelo:
cat >> ~/gemini-app/response_utils.py <<EOF def get_gemini_pro_vision_response(model: GenerativeModel, prompt_list, generation_config={}, stream=True): generation_config = {'temperature': 0.1, 'max_output_tokens': 2048 } responses = model.generate_content(prompt_list, generation_config = generation_config, stream=True) final_response = [] for response in responses: try: final_response.append(response.text) except IndexError: final_response.append("") continue return(" ".join(final_response)) EOF
Modifica el punto de entrada principal de la app
-
Para agregar la pestaña 3 a la app, ejecuta el siguiente comando:
cat >> ~/gemini-app/app.py <<EOF from app_tab3 import render_image_playground_tab with tab3: render_image_playground_tab(multimodal_model_pro) EOF
Prueba la app: Pestaña Image Playground
-
Ejecuta la app usando el comando que se proporciona en los pasos anteriores en este lab.
-
Para abrir la página principal de la app en tu navegador, haz clic en Vista previa en la Web en la barra de menú de Cloud Shell y, luego, en Vista previa en el puerto 8080.
-
Haz clic en Image Playground y, luego, en Furniture recommendation.
En la pestaña, se muestran las imágenes de la sala de estar y los sillones.
-
Haz clic en Generate recommendation.
Si recibes este mensaje de error: FailedPrecondition: 400 We are preparing necessary resources. Please wait few minutes and retry., espera unos minutos y vuelve a hacer clic en Generate recommendation. -
Consulta la respuesta del modelo de Gemini 1.0 Pro Vision.
La respuesta está en formato tabular como se solicita en la instrucción. El modelo recomienda dos de los cuatro sillones y proporciona la justificación para la recomendación.
-
En la ventana de Cloud Shell, finaliza la app y vuelve al símbolo del sistema presionando control+c.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Tarea 7: Analiza el diseño de imágenes
En esta tarea, usarás el modelo de Gemini 1.0 Pro Vision para extraer la información de una imagen después de analizar el diseño de íconos y texto.
Actualiza la pestaña Oven instructions de la pestaña Image Playground
Gemini cuenta con la capacidad para extraer información de elementos visuales en pantallas y, además, puede analizar capturas de pantalla, íconos y diseños para proporcionar una comprensión holística del ambiente retratado. En esta tarea, proporcionas una imagen del panel de control de un horno de cocina al modelo y, luego, le indicas que genere instrucciones para una función específica.
-
Para implementar código para la pestaña Oven instructions en la pestaña Image Playground en la IU de la app, ejecuta el siguiente comando:
cat >> ~/gemini-app/app_tab3.py <<EOF with screens: oven_screen_uri = "gs://cloud-training/OCBL447/gemini-app/images/oven.jpg" oven_screen_url = "https://storage.googleapis.com/"+oven_screen_uri.split("gs://")[1] oven_screen_img = Part.from_uri(oven_screen_uri, mime_type="image/jpeg") st.image(oven_screen_url, width=350, caption="Image of an oven control panel") st.write("Provide instructions for resetting the clock on this appliance in English") prompt = """How can I reset the clock on this appliance? Provide the instructions in English. If instructions include buttons, also explain where those buttons are physically located. """ tab1, tab2 = st.tabs(["Response", "Prompt"]) generate_instructions_description = st.button("Generate instructions", key="generate_instructions_description") with tab1: if generate_instructions_description and prompt: with st.spinner("Generating instructions using Gemini..."): response = get_gemini_pro_vision_response(multimodal_model_pro, [oven_screen_img, prompt]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.text(prompt+"\n"+"input_image") EOF Con el código detallado arriba, se compila la IU de la pestaña Oven instructions. Se usa una imagen del panel de control de un horno de cocina junto con texto para indicarle al modelo que genere instrucciones para una función específica que está disponible en el panel, en este caso, restablecer el reloj.

Prueba la app: Pestaña Oven instructions de la pestaña Image Playground
-
Ejecuta la app usando el comando que se proporciona en los pasos anteriores en este lab.
-
Para lanzar la página principal de la app en tu navegador, haz clic en Vista previa en la Web en la barra de menú de Cloud Shell y, luego, en Vista previa en el puerto 8080.
-
Haz clic en Image Playground y, luego, en Oven instructions.
En la pestaña, se muestra una imagen del panel de control del horno.
-
Haz clic en Generate instructions.
-
Consulta la respuesta del modelo de Gemini 1.0 Pro Vision.
En la respuesta, se incluyen los pasos que se pueden usar para restablecer el reloj en el panel de control del horno. También se incluyen instrucciones que indican dónde encontrar el botón en el panel y en las que se destaca la capacidad del modelo para analizar el diseño del panel en la imagen.
-
En la ventana de Cloud Shell, finaliza la app y vuelve al símbolo del sistema presionando control+c.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Tarea 8: Analiza diagramas de ER
Las capacidades multimodales de Gemini le permiten comprender diagramas y tomar medidas prácticas, como generar código o documentos. En esta tarea, usarás el modelo de Gemini 1.0 Pro Vision para analizar un diagrama de relaciones de entidades (ER) y generar documentación sobre las entidades y relaciones que se incluyen en el diagrama.
Actualiza la pestaña ER diagrams de la pestaña Image Playground
En esta tarea, proporcionas una imagen de un diagrama de ER al modelo y, luego, le indicas al modelo que genere documentación.
-
Para implementar código para la pestaña ER diagrams en la pestaña Image Playground en la IU de la app, ejecuta el siguiente comando:
cat >> ~/gemini-app/app_tab3.py <<EOF with diagrams: er_diag_uri = "gs://cloud-training/OCBL447/gemini-app/images/er.png" er_diag_url = "https://storage.googleapis.com/"+er_diag_uri.split("gs://")[1] er_diag_img = Part.from_uri(er_diag_uri,mime_type="image/png") st.image(er_diag_url, width=350, caption="Image of an ER diagram") st.write("Document the entities and relationships in this ER diagram.") prompt = """Document the entities and relationships in this ER diagram.""" tab1, tab2 = st.tabs(["Response", "Prompt"]) er_diag_img_description = st.button("Generate documentation", key="er_diag_img_description") with tab1: if er_diag_img_description and prompt: with st.spinner("Generating..."): response = get_gemini_pro_vision_response(multimodal_model_pro,[er_diag_img,prompt]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.text(prompt+"\n"+"input_image") EOF Con el código detallado arriba, se compila la IU de la pestaña ER diagrams. Se usa una imagen de un diagrama de ER junto con texto para indicarle al modelo que genere documentación sobre las entidades y relaciones que hay en el diagrama.
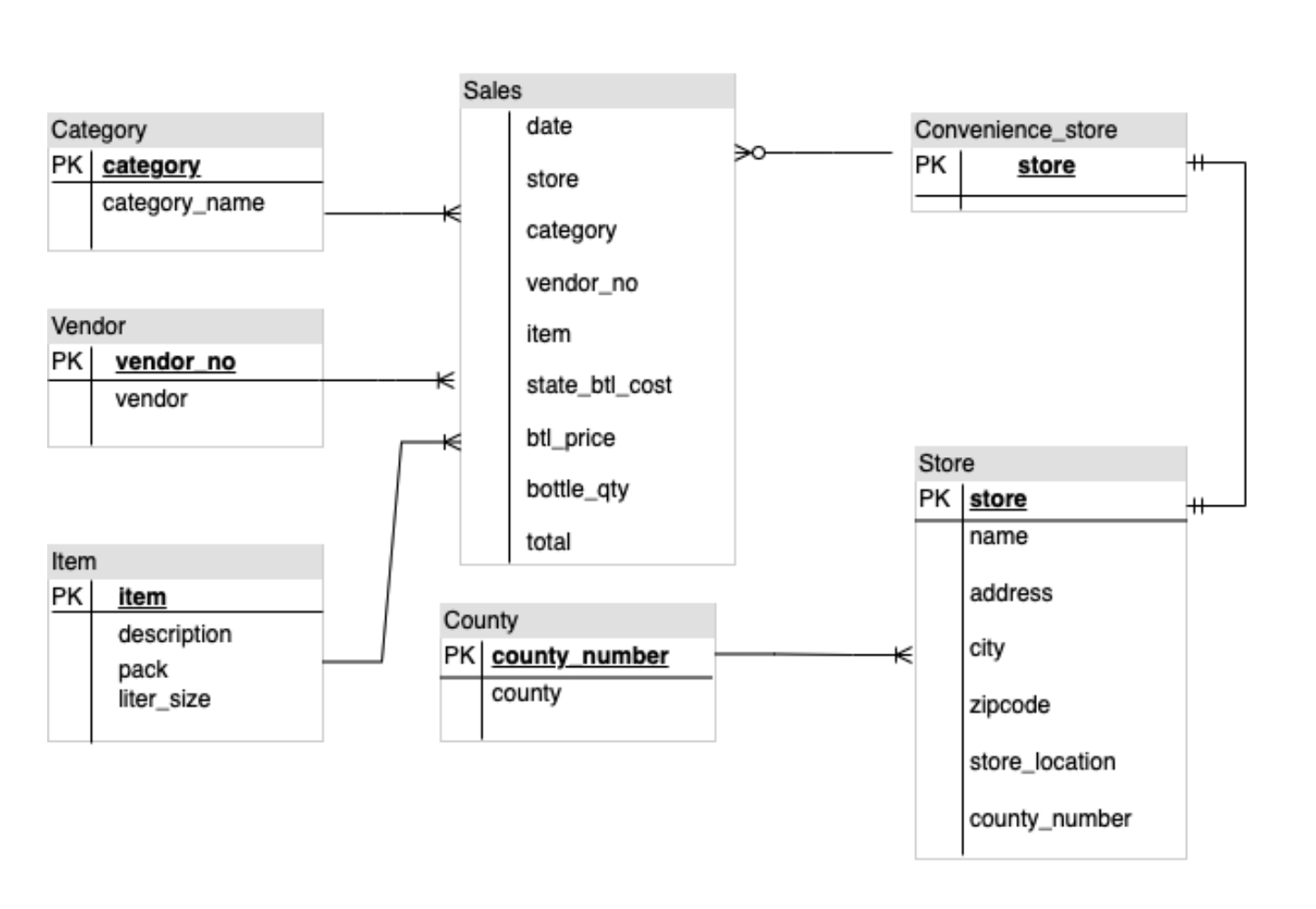
Prueba la app: Pestaña ER diagrams de la pestaña Image Playground
-
Ejecuta la app usando el comando que se proporciona en los pasos anteriores en este lab.
-
Para lanzar la página principal de la app en tu navegador, haz clic en Vista previa en la Web en la barra de menú de Cloud Shell y, luego, en Vista previa en el puerto 8080.
-
Haz clic en Image Playground y, luego, en ER diagrams.
En la pestaña, se muestra la imagen del diagrama de ER.
-
Haz clic en Generate documentation.
-
Consulta la respuesta del modelo de Gemini 1.0 Pro Vision.
En la respuesta, se incluye una lista de entidades y las relaciones encontradas en el diagrama.
-
En la ventana de Cloud Shell, finaliza la app y vuelve al símbolo del sistema presionando control+c.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Tarea 9: Razonamiento matemático
Gemini 1.0 Pro Vision también puede reconocer fórmulas matemáticas y ecuaciones, y extraer información específica de ellas. Esa capacidad es particularmente útil para generar explicaciones para problemas matemáticos.
Actualiza la pestaña Math reasoning de la pestaña Image Playground
En esta tarea, usarás el modelo de Gemini 1.0 Pro Vision para extraer y, también, interpretar una fórmula matemática a partir de una imagen.
-
Para implementar código para la pestaña Math reasoning en la pestaña Image Playground en la IU de la app, ejecuta el siguiente comando:
cat >> ~/gemini-app/app_tab3.py <<EOF with equations: math_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/math_eqn.jpg" math_image_url = "https://storage.googleapis.com/"+math_image_uri.split("gs://")[1] math_image_img = Part.from_uri(math_image_uri,mime_type="image/jpeg") st.image(math_image_url,width=350, caption="Image of a math equation") st.markdown(f""" Ask questions about the math equation as follows: - Extract the formula. - What is the symbol right before Pi? What does it mean? - Is this a famous formula? Does it have a name? """) prompt = """Follow the instructions Surround math expressions with $. Use a table with a row for each instruction and its result. INSTRUCTIONS: - Extract the formula. - What is the symbol right before Pi? What does it mean? - Is this a famous formula? Does it have a name? """ tab1, tab2 = st.tabs(["Response", "Prompt"]) math_image_description = st.button("Generate answers", key="math_image_description") with tab1: if math_image_description and prompt: with st.spinner("Generating answers for formula using Gemini..."): response = get_gemini_pro_vision_response(multimodal_model_pro, [math_image_img, prompt]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.text(prompt) EOF Con el código detallado arriba, se compila la IU de la pestaña Math reasoning. Se usa una imagen de una ecuación matemática junto con texto para indicarle al modelo que genere respuestas y otras características sobre la ecuación.

Prueba la app: Pestaña Math reasoning de la pestaña Image Playground
-
Ejecuta la app usando el comando que se proporciona en los pasos anteriores en este lab.
-
Para lanzar la página principal de la app en tu navegador, haz clic en Vista previa en la Web en la barra de menú de Cloud Shell y, luego, en Vista previa en el puerto 8080.
-
Haz clic en Image Playground y, luego, en Math reasoning.
En la pestaña, se muestra la imagen de la ecuación matemática.
-
Haz clic en Generate answers.
-
Consulta la respuesta del modelo de Gemini 1.0 Pro Vision.
En la respuesta, se incluyen las respuestas a las preguntas incluidas en la instrucción para el modelo.
-
En la ventana de Cloud Shell, finaliza la app y vuelve al símbolo del sistema presionando control+c.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Tarea 10: Genera el playground de videos
En esta tarea, usarás el modelo de Gemini 1.0 Pro Vision para procesar videos y generar etiquetas y, también, información a partir de videos que se proporcionan al modelo.
Desarrolla la pestaña 4: Video Playground
El modelo de Gemini 1.0 Pro Vision también puede proporcionar una descripción de lo que ocurre en el video. En esta subtarea, implementas el código para la pestaña Video Playground y el código para interactuar con el modelo y generar la descripción del video.
-
Para escribir el código que renderiza la pestaña Video Playground en la IU de la app, ejecuta el siguiente comando:
cat > ~/gemini-app/app_tab4.py <<EOF import streamlit as st from vertexai.preview.generative_models import GenerativeModel, Part from response_utils import * import logging # render the Video Playground tab with multiple child tabs def render_video_playground_tab(multimodal_model_pro: GenerativeModel): st.write("Using Gemini 1.0 Pro Vision - Multimodal model") video_desc, video_tags, video_highlights, video_geoloc = st.tabs(["Video description", "Video tags", "Video highlights", "Video geolocation"]) with video_desc: video_desc_uri = "gs://cloud-training/OCBL447/gemini-app/videos/mediterraneansea.mp4" video_desc_url = "https://storage.googleapis.com/"+video_desc_uri.split("gs://")[1] video_desc_vid = Part.from_uri(video_desc_uri, mime_type="video/mp4") st.video(video_desc_url) st.write("Generate a description of the video.") prompt = """Describe what is happening in the video and answer the following questions: \n - What am I looking at? - Where should I go to see it? - What are other top 5 places in the world that look like this? """ tab1, tab2 = st.tabs(["Response", "Prompt"]) video_desc_description = st.button("Generate video description", key="video_desc_description") with tab1: if video_desc_description and prompt: with st.spinner("Generating video description"): response = get_gemini_pro_vision_response(multimodal_model_pro, [prompt, video_desc_vid]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.write(prompt,"\n","{video_data}") EOF -
Consulta el contenido del archivo
app_tab4.py:cat ~/gemini-app/app_tab4.py Con la función
render_video_playground_tab, se compila la IU que habilita al usuario de la app para interactuar con el modelo de Gemini 1.0 Pro Vision. Se crea un conjunto de etiquetas en la IU: "Video description", "Video tags", "Video highlights" y "Video geolocation". Escribirás el código para las pestañas restantes en tareas posteriores en este lab.En la pestaña
Video description, se usa una instrucción junto con el video para generar una descripción del video y también identificar otros lugares que tienen un aspecto similar al lugar que aparece en el video.
Modifica el punto de entrada principal de la app
-
Para agregar la pestaña 4 a la app, ejecuta el siguiente comando:
cat >> ~/gemini-app/app.py <<EOF from app_tab4 import render_video_playground_tab with tab4: render_video_playground_tab(multimodal_model_pro) EOF
Prueba la app: Pestaña Video Playground
-
Ejecuta la app usando el comando que se proporciona en los pasos anteriores en este lab.
-
Para lanzar la página principal de la app en tu navegador, haz clic en Vista previa en la Web en la barra de menú de Cloud Shell y, luego, en Vista previa en el puerto 8080.
-
Haz clic en Video Playground y, luego, en Video description.
-
En la pestaña, se muestra el video de un lugar. Haz clic para reproducir el video.
-
Haz clic en Generate video description.
-
Consulta la respuesta del modelo de Gemini 1.0 Pro Vision.
En la respuesta, se incluyen una descripción del lugar y 5 lugares más que tienen un aspecto similar.
-
En la ventana de Cloud Shell, finaliza la app y vuelve al símbolo del sistema presionando control+c.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Tarea 11: Genera etiquetas de video
En esta tarea, usarás el modelo de Gemini 1.0 Pro Vision para generar etiquetas a partir de un video.
Actualiza la pestaña Video tags de la pestaña Video Playground
-
Para implementar código para la pestaña Video tags en la pestaña Video Playground en la IU de la app, ejecuta el siguiente comando:
cat >> ~/gemini-app/app_tab4.py <<EOF with video_tags: video_tags_uri = "gs://cloud-training/OCBL447/gemini-app/videos/photography.mp4" video_tags_url = "https://storage.googleapis.com/"+video_tags_uri.split("gs://")[1] video_tags_vid = Part.from_uri(video_tags_uri, mime_type="video/mp4") st.video(video_tags_url) st.write("Generate tags for the video.") prompt = """Answer the following questions using the video only: 1. What is in the video? 2. What objects are in the video? 3. What is the action in the video? 4. Provide 5 best tags for this video? Write the answer in table format with the questions and answers in columns. """ tab1, tab2 = st.tabs(["Response", "Prompt"]) video_tags_desc = st.button("Generate video tags", key="video_tags_desc") with tab1: if video_tags_desc and prompt: with st.spinner("Generating video tags"): response = get_gemini_pro_vision_response(multimodal_model_pro, [prompt, video_tags_vid]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.write(prompt,"\n","{video_data}") EOF Con el código detallado arriba, se compila la IU de la pestaña Video tags. Se usa un video junto con texto para indicarle al modelo que genere etiquetas y responda preguntas sobre escenas en el video.
Prueba la app: Pestaña Video tags de la pestaña Video Playground
-
Ejecuta la app usando el comando que se proporciona en los pasos anteriores en este lab.
-
Para lanzar la página principal de la app en tu navegador, haz clic en Vista previa en la Web en la barra de menú de Cloud Shell y, luego, en Vista previa en el puerto 8080.
-
Haz clic en Video Playground y, luego, en Video tags.
-
En la pestaña, se muestra el video que se usará para indicarle la instrucción al modelo. Haz clic para reproducir el video.
-
Haz clic en Generate video tags.
-
Consulta la respuesta del modelo de Gemini 1.0 Pro Vision.
En la respuesta, se incluyen las respuestas a las preguntas que se proporcionaron en la instrucción para el modelo. Las preguntas y respuestas son salidas en formato tabular y, también, incluyen 5 etiquetas como se solicitó.
-
En la ventana de Cloud Shell, finaliza la app y vuelve al símbolo del sistema presionando control+c.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Tarea 12: Genera videos destacados
En esta tarea, usarás el modelo de Gemini 1.0 Pro Vision para generar, a partir de un video, clips destacados que incluyen información sobre los objetos, las personas y el contexto que se muestra en el video.
Actualiza la pestaña Video highlights de la pestaña Video Playground
-
Para implementar código para la pestaña Video highlights en la pestaña Video Playground en la IU de la app, ejecuta el siguiente comando:
cat >> ~/gemini-app/app_tab4.py <<EOF with video_highlights: video_highlights_uri = "gs://cloud-training/OCBL447/gemini-app/videos/pixel8.mp4" video_highlights_url = "https://storage.googleapis.com/"+video_highlights_uri.split("gs://")[1] video_highlights_vid = Part.from_uri(video_highlights_uri, mime_type="video/mp4") st.video(video_highlights_url) st.write("Generate highlights for the video.") prompt = """Answer the following questions using the video only: What is the profession of the girl in this video? Which features of the phone are highlighted here? Summarize the video in one paragraph. Write these questions and their answers in table format. """ tab1, tab2 = st.tabs(["Response", "Prompt"]) video_highlights_description = st.button("Generate video highlights", key="video_highlights_description") with tab1: if video_highlights_description and prompt: with st.spinner("Generating video highlights"): response = get_gemini_pro_vision_response(multimodal_model_pro, [prompt, video_highlights_vid]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.write(prompt,"\n","{video_data}") EOF Con el código detallado arriba, se compila la IU de la pestaña Video highlights. Se usa un video junto con texto para indicarle al modelo que genere clips destacados a partir del video.
Prueba la app: Pestaña Video highlights de la pestaña Video Playground
-
Ejecuta la app usando el comando que se proporciona en los pasos anteriores en este lab.
-
Para lanzar la página principal de la app en tu navegador, haz clic en Vista previa en la Web en la barra de menú de Cloud Shell y, luego, en Vista previa en el puerto 8080.
-
Haz clic en Video Playground y, luego, en Video highlights.
-
En la pestaña, se muestra el video que se usará para indicarle la instrucción al modelo. Haz clic para reproducir el video.
-
Haz clic en Generate video highlights.
-
Consulta la respuesta del modelo de Gemini 1.0 Pro Vision.
En la respuesta, se incluyen las respuestas a las preguntas que se proporcionaron en la instrucción para el modelo. Las preguntas y respuestas son salidas en formato tabular y detallan funciones del video, como la profesión de la mujer y las funciones del teléfono que se usan. La respuesta también incluye una descripción breve de las escenas del video.
-
En la ventana de Cloud Shell, finaliza la app y vuelve al símbolo del sistema presionando control+c.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Tarea 13: Genera la ubicación del video
En esta tarea, usarás el modelo de Gemini 1.0 Pro Vision para determinar la ubicación en la que se desarrolla la escena del video.
Actualiza la pestaña Video geolocation de la pestaña Video Playground
-
Para implementar código para la pestaña Video geolocation en la pestaña Video Playground en la IU de la app, ejecuta el siguiente comando:
cat >> ~/gemini-app/app_tab4.py <<EOF with video_geoloc: video_geolocation_uri = "gs://cloud-training/OCBL447/gemini-app/videos/bus.mp4" video_geolocation_url = "https://storage.googleapis.com/"+video_geolocation_uri.split("gs://")[1] video_geolocation_vid = Part.from_uri(video_geolocation_uri, mime_type="video/mp4") st.video(video_geolocation_url) st.markdown("""Answer the following questions from the video: - What is this video about? - How do you know which city it is? - What street is this? - What is the nearest intersection? """) prompt = """Answer the following questions using the video only: What is this video about? How do you know which city it is? What street is this? What is the nearest intersection? Answer the following questions using a table format with the questions and answers as columns. """ tab1, tab2 = st.tabs(["Response", "Prompt"]) video_geolocation_description = st.button("Generate", key="video_geolocation_description") with tab1: if video_geolocation_description and prompt: with st.spinner("Generating location information"): response = get_gemini_pro_vision_response(multimodal_model_pro, [prompt, video_geolocation_vid]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.write(prompt,"\n","{video_data}") EOF Con el código detallado arriba, se compila la IU de la pestaña Video geolocation. Se usa un video junto con texto para indicarle al modelo que responda preguntas sobre el video, incluida información de ubicación sobre entidades que se ven en el video.
Prueba la app: Pestaña Video geolocation de la pestaña Video Playground
-
Ejecuta la app usando el comando que se proporciona en los pasos anteriores en este lab.
-
Para lanzar la página principal de la app en tu navegador, haz clic en Vista previa en la Web en la barra de menú de Cloud Shell y, luego, en Vista previa en el puerto 8080.
-
Haz clic en Video Playground y, luego, en Video geolocation.
-
En la pestaña, se muestra el video que se usará para indicarle la instrucción al modelo. Haz clic para reproducir el video.
-
Haz clic en Generar.
-
Consulta la respuesta del modelo de Gemini 1.0 Pro Vision.
En la respuesta, se incluyen las respuestas a las preguntas que se proporcionaron en la instrucción para el modelo. Las preguntas y respuestas son salidas en formato tabular y, también, incluyen la información de ubicación como se solicitó.
-
En la ventana de Cloud Shell, finaliza la app y vuelve al símbolo del sistema presionando control+c.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Tarea 14: Implementa la app en Cloud Run
Ahora que ya probaste la app de manera local, puedes hacer que esté disponible para otras personas. Para ello, implementa la app en Cloud Run en Google Cloud. Cloud Run es una plataforma de procesamiento administrada que te permite ejecutar contenedores de aplicación sobre la infraestructura escalable de Google.
Configura el entorno
-
Asegúrate de estar en el directorio
app:cd ~/gemini-app -
Verifica que estén configuradas las variables de entorno PROJECT_ID y REGION:
echo "PROJECT_ID=${PROJECT_ID}" echo "REGION=${REGION}" -
Si esas variables de entorno no están configuradas, ejecuta el comando para establecerlas:
PROJECT_ID=$(gcloud config get-value project) REGION={{{project_0.default_region|set at lab start}}} echo "PROJECT_ID=${PROJECT_ID}" echo "REGION=${REGION}" -
Configura las variables de entorno para tu repositorio de servicios y artefactos:
SERVICE_NAME='gemini-app-playground' # Name of your Cloud Run service. AR_REPO='gemini-app-repo' # Name of your repository in Artifact Registry that stores your application container image. echo "SERVICE_NAME=${SERVICE_NAME}" echo "AR_REPO=${AR_REPO}"
Crea el repositorio de Docker
-
Para crear el repositorio en Artifact Registry, ejecuta el comando:
gcloud artifacts repositories create "$AR_REPO" --location="$REGION" --repository-format=Docker Artifact Registry ia a Google Cloud service that provides a single location for storing and managing your software packages and Docker container images. -
Configura la autenticación del repositorio:
gcloud auth configure-docker "$REGION-docker.pkg.dev"
Compila la imagen del contenedor
Usaremos un Dockerfile para compilar la imagen del contenedor de nuestra aplicación. Un Dockerfile es un documento de texto que contiene todos los comandos a los que puede llamar un usuario en la línea de comandos para ensamblar una imagen de contenedor. Se usa con Docker, una plataforma de contenedores que compila y ejecuta imágenes de contenedores.
-
Para crear un
Dockerfile, ejecuta el comando:cat > ~/gemini-app/Dockerfile <<EOF FROM python:3.8 EXPOSE 8080 WORKDIR /app COPY . ./ RUN pip install -r requirements.txt ENTRYPOINT ["streamlit", "run", "app.py", "--server.port=8080", "--server.address=0.0.0.0"] EOF -
Para compilar la imagen del contenedor de tu app, ejecuta el siguiente comando:
gcloud builds submit --tag "$REGION-docker.pkg.dev/$PROJECT_ID/$AR_REPO/$SERVICE_NAME" El comando gcloud builds submit envía una compilación usando Cloud Build. Cuando se usa con la marca tag, Cloud Build usa un Dockerfile para compilar una imagen de contenedor de los archivos de la aplicación en el directorio del código fuente. Cloud Build es un servicio que ejecuta compilaciones basadas en tus especificaciones en Google Cloud y produce artefactos como contenedores de Docker o archivos de Java.
Espera a que termine el comando antes de seguir al próximo paso.
Implementa y prueba la app en Cloud Run
La última tarea es implementar el servicio en Cloud Run con la imagen que se compiló y envió al repositorio en Artifact Registry.
-
Para implementar tu app en Cloud Run, ejecuta el siguiente comando:
gcloud run deploy "$SERVICE_NAME" \ --port=8080 \ --image="$REGION-docker.pkg.dev/$PROJECT_ID/$AR_REPO/$SERVICE_NAME" \ --allow-unauthenticated \ --region=$REGION \ --platform=managed \ --project=$PROJECT_ID \ --set-env-vars=PROJECT_ID=$PROJECT_ID,REGION=$REGION -
Después de implementar el servicio, se genera una URL del servicio en la salida del comando anterior. Para probar la app en Cloud Run, navega a esa URL en una ventana o pestaña del navegador separada.
-
Elige las funciones de la app que quieres probar. La app le pedirá a la API de Gemini de Vertex AI que genere y muestre las respuestas.
Para verificar este objetivo, haz clic en Revisar mi progreso.
Finalice su lab
Cuando haya completado su lab, haga clic en Finalizar lab. Qwiklabs quitará los recursos que usó y limpiará la cuenta por usted.
Tendrá la oportunidad de calificar su experiencia en el lab. Seleccione la cantidad de estrellas que corresponda, ingrese un comentario y haga clic en Enviar.
La cantidad de estrellas indica lo siguiente:
- 1 estrella = Muy insatisfecho
- 2 estrellas = Insatisfecho
- 3 estrellas = Neutral
- 4 estrellas = Satisfecho
- 5 estrellas = Muy satisfecho
Puede cerrar el cuadro de diálogo si no desea proporcionar comentarios.
Para enviar comentarios, sugerencias o correcciones, use la pestaña Asistencia.
¡Felicitaciones!
En este lab, aprendiste a hacer lo siguiente:
- Desarrollaste una app de Python usando el framework de Streamlit.
- Instalaste el SDK de Vertex AI para Python.
- Desarrollaste código para interactuar con el modelo de Gemini 1.0 Pro (gemini-pro) usando la API de Gemini de Vertex AI.
- Usaste instrucciones de texto con el modelo para generar una historia y una campaña de marketing.
- Desarrollaste código para interactuar con el modelo de Gemini 1.0 Pro Vision (gemini-pro-vision) usando la API de Gemini de Vertex AI.
- Usaste texto, imágenes y videos con el modelo para procesar y extraer información de imágenes y videos.
- Implementaste y probaste la app en Cloud Run.
Próximos pasos/Más información
- Vertex AI
- Gemini
- Referencia de modelos generativos del SDK de Vertex AI
- Artifact Registry
- Cloud Build
- Cloud Run
Copyright 2023 Google LLC. Todos los derechos reservados. Google y el logotipo de Google son marcas de Google LLC. El resto de los nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que están asociados.

