Checkpoint
Enable relevant APIs.
/ 5
Application is developed with Story tab.
/ 5
Application marketing campaign tab is developed.
/ 5
Application image playground with furniture recommendation tab is developed.
/ 5
Image playground with oven instructions tab is developed.
/ 10
Image playground with ER diagrams tab is developed
/ 10
Image playground with math reasoning tab is developed.
/ 10
Application video playground with video description tab is developed.
/ 10
Video playground with video tags tab is developed.
/ 10
Video playground with video highlights tab is developed.
/ 10
Video playground with video geolocation tab is developed.
/ 10
Application is deployed to Cloud Run.
/ 10
Sviluppo di un'app con Vertex AI utilizzando Gemini 1.0 Pro
- Panoramica
- Obiettivi
- Configurazione
- Attività 1: configura il tuo ambiente e il tuo progetto
- Attività 2: configura l'ambiente dell'applicazione
- Attività 3: sviluppa l'app
- Attività 4: esegui e testa l'app in locale
- Attività 5: genera una campagna di marketing
- Attività 6: genera il playground immagini
- Attività 7: analizza il layout dell'immagine
- Attività 8: analizza i diagrammi ER
- Attività 9: ragionamento matematico
- Attività 10: genera il playground video
- Attività 11: genera tag video
- Attività 12: genera momenti salienti del video
- Attività 13: genera la località del video
- Attività 14: esegui il deployment dell'app in Cloud Run
- Terminare il lab
- Complimenti!
Panoramica
Gemini è una famiglia di modelli di AI generativa progettati per casi d'uso multimodali. È disponibile in tre versioni: Ultra, Pro e Nano. Gemini 1.0 Pro è disponibile per sviluppatori e aziende per creare i propri casi d'uso. Gemini 1.0 Pro accetta testo come input e genera testo come output. È inoltre disponibile un endpoint multimodale dedicato di Gemini 1.0 Pro Vision che accetta testo e immagini come input e genera testo come output. Sono disponibili SDK per aiutarti a creare app in Python, Android (Kotlin), Node.js, Swift e JavaScript.
Su Google Cloud, l'API Gemini di Vertex AI fornisce un'interfaccia unificata per interagire con i modelli Gemini. L'API supporta prompt multimodali come codice o testo di input e output. Attualmente sono disponibili due modelli nell'API Gemini:
-
Modello Gemini 1.0 Pro (gemini-pro): progettato per gestire attività di elaborazione del linguaggio naturale, chat di testo e codice in più passaggi e generazione di codice.
-
Modello 1.0 Gemini Pro Vision (gemini-pro-vision): supporta prompt multimodali. Puoi includere testo, immagini e video nelle tue richieste di prompt e ottenere risposte di testo o codice.
Vertex AI è una piattaforma di machine learning (ML) che ti consente di addestrare ed eseguire il deployment di modelli ML e applicazioni AI e personalizzare modelli linguistici di grandi dimensioni (LLM) da utilizzare nelle tue applicazioni basate sull'AI. Vertex AI consente la personalizzazione di Gemini con il controllo dati completo e i vantaggi delle funzionalità aggiuntive di Google Cloud per la protezione, la sicurezza, la privacy, la conformità e la governance dei dati aziendali. Per scoprire di più su Vertex AI, visualizza il link nella sezione Passaggi successivi alla fine del lab.
In questo lab utilizzerai l'SDK Vertex AI per Python per chiamare l'API Gemini di Vertex AI.
Obiettivi
In questo lab imparerai a:
- Sviluppare un'app Python utilizzando il framework Streamlit.
- Installare l'SDK Vertex AI per Python.
- Sviluppare del codice per interagire con il modello Gemini 1.0 Pro (gemini-pro) utilizzando l'API Gemini di Vertex AI.
- Sviluppare del codice per interagire con il modello Gemini 1.0 Pro Vision (gemini-pro-vision) utilizzando l'API Gemini di Vertex AI.
- Containerizzare la tua applicazione, eseguirne il deployment e testarla su Cloud Run.
Configurazione
Per ciascun lab, riceverai un nuovo progetto Google Cloud e un insieme di risorse per un periodo di tempo limitato senza alcun costo aggiuntivo.
-
Accedi a Qwiklabs utilizzando una finestra di navigazione in incognito.
-
Tieni presente la durata dell'accesso al lab (ad esempio,
1:15:00) e assicurati di finire entro quell'intervallo di tempo.
Non è disponibile una funzionalità di pausa. Se necessario, puoi riavviare il lab ma dovrai ricominciare dall'inizio. -
Quando è tutto pronto, fai clic su Inizia lab.
-
Annota le tue credenziali del lab (Nome utente e Password). Le userai per accedere a Google Cloud Console.
-
Fai clic su Apri console Google.
-
Fai clic su Utilizza un altro account e copia/incolla le credenziali per questo lab nei prompt.
Se utilizzi altre credenziali, compariranno errori oppure ti verranno addebitati dei costi. -
Accetta i termini e salta la pagina di ripristino delle risorse.
Attiva Cloud Shell
Cloud Shell è una macchina virtuale che contiene strumenti per sviluppatori. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud. Cloud Shell fornisce l'accesso da riga di comando alle tue risorse Google Cloud. gcloud è lo strumento a riga di comando per Google Cloud. È preinstallato su Cloud Shell e supporta il completamento tramite tasto Tab.
-
In Google Cloud Console, nel riquadro di navigazione, fai clic su Attiva Cloud Shell (
).
-
Fai clic su Continua.
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Quando la connessione è attiva, anche l'autenticazione è avvenuta e il progetto è impostato sul tuo PROJECT_ID. Ad esempio:

Comandi di esempio
-
Elenca il nome dell'account attivo:
(Output)
(Output di esempio)
-
Elenca l'ID progetto:
(Output)
(Output di esempio)
Attività 1: configura il tuo ambiente e il tuo progetto
-
Accedi alla console Google Cloud con le tue credenziali del lab e apri la finestra del terminale Cloud Shell.
-
Per impostare l'ID progetto e le variabili di ambiente della regione, in Cloud Shell esegui i seguenti comandi:
PROJECT_ID=$(gcloud config get-value project) REGION={{{project_0.default_region|set at lab start}}} echo "PROJECT_ID=${PROJECT_ID}" echo "REGION=${REGION}" -
Per utilizzare vari servizi Google Cloud in questo lab, devi abilitare alcune API:
gcloud services enable cloudbuild.googleapis.com cloudfunctions.googleapis.com run.googleapis.com logging.googleapis.com storage-component.googleapis.com aiplatform.googleapis.com
Per verificare l'obiettivo, fai clic su Controlla i miei progressi.
Attività 2: configura l'ambiente dell'applicazione
In questa attività configurerai un ambiente virtuale Python e installerai le dipendenze dell'applicazione.
Conferma che Cloud Shell è autorizzato
-
Per confermare che Cloud Shell è autorizzato, in Cloud Shell esegui questo comando:
gcloud auth list -
Se ti viene richiesto di autorizzare Cloud Shell, fai clic su Autorizza.
Crea la directory dell'app
-
Per creare la directory dell'app, esegui questo comando:
mkdir ~/gemini-app -
Passa alla directory
~/gemini-app:cd ~/gemini-app I file dell'applicazione vengono creati nella directory
~/gemini-app. Questa directory conterrà le dipendenze, i file di origine dell'applicazione Python e un file Docker che utilizzeremo più avanti in questo lab.
Configura un ambiente Python virtuale
Crea un ambiente virtuale sopra l'installazione Python esistente, in modo che tutti i pacchetti installati in questo ambiente siano isolati dai pacchetti nell'ambiente di base. Se utilizzati dall'interno di un ambiente virtuale, gli strumenti di installazione come pip installeranno i pacchetti Python nell'ambiente virtuale.
-
Per creare l'ambiente virtuale Python, dalla cartella
gemini-app, esegui questo comando:python3 -m venv gemini-streamlit Il modulo venv crea un ambiente virtuale leggero, con il proprio set indipendente di pacchetti Python. -
Attiva l'ambiente virtuale Python:
source gemini-streamlit/bin/activate
Installa le dipendenze delle applicazioni
Un file dei requisiti Python è un semplice file di testo che elenca le dipendenze richieste dal tuo progetto. Per iniziare, ci sono tre moduli di cui abbiamo bisogno nel file dei requisiti.
La nostra app è stata scritta usando Streamlit, una libreria Python open source utilizzata per creare app web per il machine learning e la data science. L'app utilizza la libreria dell'SDK Vertex AI per Python per interagire con i modelli e l'API Gemini. Cloud Logging viene utilizzato per registrare informazioni dall'applicazione.
-
Per creare il file dei requisiti, esegui questo comando:
cat > ~/gemini-app/requirements.txt <<EOF streamlit google-cloud-aiplatform==1.38.1 google-cloud-logging==3.6.0 EOF -
Installa le dipendenze dell'applicazione:
pip install -r requirements.txt pip è il programma di installazione del pacchetto per Python.
Attendi finché non vengono installati tutti i pacchetti prima di continuare con l'attività successiva.
Attività 3: sviluppa l'app
Il codice sorgente dell'app verrà scritto in più file di origine .py. Cominciamo con l'entry point principale in app.py.
Scrivi l'entry point principale dell'app
-
Per creare il codice dell'entry point
app.py, esegui questo comando:cat > ~/gemini-app/app.py <<EOF import os import streamlit as st from app_tab1 import render_story_tab from vertexai.preview.generative_models import GenerativeModel import vertexai import logging from google.cloud import logging as cloud_logging # configure logging logging.basicConfig(level=logging.INFO) # attach a Cloud Logging handler to the root logger log_client = cloud_logging.Client() log_client.setup_logging() PROJECT_ID = os.environ.get('PROJECT_ID') # Your Qwiklabs Google Cloud Project ID LOCATION = os.environ.get('REGION') # Your Qwiklabs Google Cloud Project Region vertexai.init(project=PROJECT_ID, location=LOCATION) @st.cache_resource def load_models(): text_model_pro = GenerativeModel("gemini-pro") multimodal_model_pro = GenerativeModel("gemini-pro-vision") return text_model_pro, multimodal_model_pro st.header("Vertex AI Gemini API", divider="rainbow") text_model_pro, multimodal_model_pro = load_models() tab1, tab2, tab3, tab4 = st.tabs(["Story", "Marketing Campaign", "Image Playground", "Video Playground"]) with tab1: render_story_tab(text_model_pro) EOF -
Visualizza i contenuti del file
app.py:cat ~/gemini-app/app.py L'app utilizza
streamlitper creare una serie di schede nella UI. In questa versione iniziale dell'app, creiamo la prima scheda Story (Storia) che contiene funzionalità per generare una storia, quindi creiamo le altre schede in modo incrementale nelle attività successive del lab.L'app inizializza innanzitutto l'
SDK Vertex AIpassando i valori delle variabili di ambiente PROJECT_ID e REGION.Quindi carica i modelli
gemini-proegemini-pro-visionutilizzando la classeGenerativeModelche rappresenta un modello Gemini. Questa classe include metodi che aiutano a generare contenuti da testo, immagini e video.L'app crea quattro schede nella UI denominate Story (Storia), Marketing Campaign (Campagna di marketing), Image Playground (Playground immagini) e Video Playground (Playground video).
Il codice dell'app richiama quindi la funzione
render_tab1()per creare la UI per la scheda Story (Storia) nella UI dell'app.
Sviluppa tab1 - Story (Storia)
-
Per scrivere il codice che esegue il rendering della scheda Story (Storia) nella UI dell'app, esegui questo comando:
cat > ~/gemini-app/app_tab1.py <<EOF import streamlit as st from vertexai.preview.generative_models import GenerativeModel from response_utils import * import logging # create the model prompt based on user input. def generate_prompt(): # Story character input character_name = st.text_input("Enter character name: \n\n",key="character_name",value="Mittens") character_type = st.text_input("What type of character is it? \n\n",key="character_type",value="Cat") character_persona = st.text_input("What personality does the character have? \n\n", key="character_persona",value="Mitten is a very friendly cat.") character_location = st.text_input("Where does the character live? \n\n",key="character_location",value="Andromeda Galaxy") # Story length and premise length_of_story = st.radio("Select the length of the story: \n\n",["Short","Long"],key="length_of_story",horizontal=True) story_premise = st.multiselect("What is the story premise? (can select multiple) \n\n",["Love","Adventure","Mystery","Horror","Comedy","Sci-Fi","Fantasy","Thriller"],key="story_premise",default=["Love","Adventure"]) creative_control = st.radio("Select the creativity level: \n\n",["Low","High"],key="creative_control",horizontal=True) if creative_control == "Low": temperature = 0.30 else: temperature = 0.95 prompt = f"""Write a {length_of_story} story based on the following premise: \n character_name: {character_name} \n character_type: {character_type} \n character_persona: {character_persona} \n character_location: {character_location} \n story_premise: {",".join(story_premise)} \n If the story is "short", then make sure to have 5 chapters or else if it is "long" then 10 chapters. Important point is that each chapter should be generated based on the premise given above. First start by giving the book introduction, chapter introductions and then each chapter. It should also have a proper ending. The book should have a prologue and an epilogue. """ return temperature, prompt # function to render the story tab, and call the model, and display the model prompt and response. def render_story_tab (text_model_pro: GenerativeModel): st.write("Using Gemini 1.0 Pro - Text only model") st.subheader("Generate a story") temperature, prompt = generate_prompt() config = { "temperature": temperature, "max_output_tokens": 2048, } generate_t2t = st.button("Generate my story", key="generate_t2t") if generate_t2t and prompt: # st.write(prompt) with st.spinner("Generating your story using Gemini..."): first_tab1, first_tab2 = st.tabs(["Story response", "Prompt"]) with first_tab1: response = get_gemini_pro_text_response(text_model_pro, prompt, generation_config=config) if response: st.write("Your story:") st.write(response) logging.info(response) with first_tab2: st.text(prompt) EOF -
Visualizza i contenuti del file
app_tab1.py:cat ~/gemini-app/app_tab1.py La funzione
render_story_tabgenera i controlli UI nella scheda richiamando funzioni per eseguire il rendering dei campi di immissione del testo e altre opzioni.La funzione
generate_promptgenera il prompt di testo fornito all'API Gemini. La stringa del prompt viene creata concatenando i valori immessi dall'utente nella UI della scheda per il personaggio della storia e le opzioni come la durata (breve, lunga), il livello di creatività (basso, alto) e la premessa della storia.La funzione restituisce anche un valore
temperaturebasato sul livello di creatività selezionato della storia. Questo valore viene fornito come parametro di configurazionetemperatureal modello, che controlla la casualità delle previsioni del modello. Il parametro di configurazionemax_output_tokensspecifica il numero massimo di token di output da generare per messaggio.Per generare la risposta del modello, viene creato un pulsante nella UI della scheda. Quando si fa clic sul pulsante, viene richiamata la funzione
get_gemini_pro_text_response, che codificheremo nel passaggio successivo del lab.
Sviluppa response_utils
Il file response_utils.py contiene funzioni per generare le risposte del modello.
-
Per scrivere il codice per generare la risposta di testo del modello, esegui questo comando:
cat > ~/gemini-app/response_utils.py <<EOF from vertexai.preview.generative_models import (Content, GenerationConfig, GenerativeModel, GenerationResponse, Image, HarmCategory, HarmBlockThreshold, Part) def get_gemini_pro_text_response( model: GenerativeModel, prompt: str, generation_config: GenerationConfig, stream=True): safety_settings={ HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE, } responses = model.generate_content(prompt, generation_config = generation_config, safety_settings = safety_settings, stream=True) final_response = [] for response in responses: try: final_response.append(response.text) except IndexError: final_response.append("") continue return " ".join(final_response) EOF -
Visualizza i contenuti del file
response_utils.py:cat ~/gemini-app/response_utils.py La funzione
get_gemini_pro_text_responseutilizzaGenerativeModele altre classi del pacchettovertexai.preview.generative_modelsnell'SDK Vertex AI per Python. Dal metodogenerate_contentdella classe, viene generata una risposta utilizzando il prompt di testo che viene passato al metodo.A questo metodo viene passato anche un oggetto
safety_settingsper controllare la risposta del modello bloccando i contenuti non sicuri. Il codice di esempio di questo lab utilizza valori delle impostazioni di sicurezza che indicano al modello di restituire sempre i contenuti indipendentemente dalla probabilità che non siano sicuri. Puoi valutare i contenuti generati e quindi modificare queste impostazioni se la tua applicazione richiede una configurazione più restrittiva. Per scoprire di più, visualizza la documentazione sulle impostazioni di sicurezza.
Attività 4: esegui e testa l'app in locale
In questa attività eseguirai l'app in locale utilizzando streamlit e ne testerai la funzionalità.
Esegui l'app
-
Per eseguire l'app in locale, in Cloud Shell, esegui questo comando:
streamlit run app.py \ --browser.serverAddress=localhost \ --server.enableCORS=false \ --server.enableXsrfProtection=false \ --server.port 8080 L'app viene avviata e ti viene fornito un URL per accedervi.
-
Per avviare la home page dell'app nel browser, fai clic su Anteprima web nella barra dei menu di Cloud Shell, quindi seleziona Anteprima sulla porta 8080.
Puoi anche copiare e incollare l'URL dell'app in una scheda separata del browser per accedere all'app.
Testa l'app - Scheda Story (Storia)
Genera una storia fornendo il tuo input, visualizza il prompt e la risposta generata dal modello Gemini 1.0 Pro.
-
Per generare una storia, nella scheda Story (Storia), lascia le impostazioni predefinite, quindi fai clic su Generate my story (Genera la mia storia).
-
Attendi che venga generata la risposta, quindi fai clic sulla scheda Story response (Risposta storia).
-
Per visualizzare il prompt utilizzato per generare la risposta, fai clic sulla scheda Prompt.
-
Nella finestra Cloud Shell, chiudi l'app e torna al prompt dei comandi premendo Control+C.
Per verificare l'obiettivo, fai clic su Controlla i miei progressi.
Attività 5: genera una campagna di marketing
In questa attività utilizzerai il modello di testo Gemini 1.0 Pro per generare una campagna di marketing per un'azienda. Svilupperai il codice che genera una seconda scheda nella tua app.
Sviluppa tab2 - Marketing Campaign (Campagna di marketing)
-
Per scrivere il codice che esegue il rendering della scheda Marketing Campaign (Campagna di marketing) nella UI dell'app, esegui questo comando:
cat > ~/gemini-app/app_tab2.py <<EOF import streamlit as st from vertexai.preview.generative_models import GenerativeModel from response_utils import * import logging # create the model prompt based on user input. def generate_prompt(): st.write("Using Gemini 1.0 Pro - Text only model") st.subheader("Generate your marketing campaign") product_name = st.text_input("What is the name of the product? \n\n",key="product_name",value="ZomZoo") product_category = st.radio("Select your product category: \n\n",["Clothing","Electronics","Food","Health & Beauty","Home & Garden"],key="product_category",horizontal=True) st.write("Select your target audience: ") target_audience_age = st.radio("Target age: \n\n",["18-24","25-34","35-44","45-54","55-64","65+"],key="target_audience_age",horizontal=True) # target_audience_gender = st.radio("Target gender: \n\n",["male","female","trans","non-binary","others"],key="target_audience_gender",horizontal=True) target_audience_location = st.radio("Target location: \n\n",["Urban", "Suburban","Rural"],key="target_audience_location",horizontal=True) st.write("Select your marketing campaign goal: ") campaign_goal = st.multiselect("Select your marketing campaign goal: \n\n",["Increase brand awareness","Generate leads","Drive sales","Improve brand sentiment"],key="campaign_goal",default=["Increase brand awareness","Generate leads"]) if campaign_goal is None: campaign_goal = ["Increase brand awareness","Generate leads"] brand_voice = st.radio("Select your brand voice: \n\n",["Formal","Informal","Serious","Humorous"],key="brand_voice",horizontal=True) estimated_budget = st.radio("Select your estimated budget ($): \n\n",["1,000-5,000","5,000-10,000","10,000-20,000","20,000+"],key="estimated_budget",horizontal=True) prompt = f"""Generate a marketing campaign for {product_name}, a {product_category} designed for the age group: {target_audience_age}. The target location is this: {target_audience_location}. Aim to primarily achieve {campaign_goal}. Emphasize the product's unique selling proposition while using a {brand_voice} tone of voice. Allocate the total budget of {estimated_budget}. With these inputs, make sure to follow following guidelines and generate the marketing campaign with proper headlines: \n - Briefly describe the company, its values, mission, and target audience. - Highlight any relevant brand guidelines or messaging frameworks. - Provide a concise overview of the campaign's objectives and goals. - Briefly explain the product or service being promoted. - Define your ideal customer with clear demographics, psychographics, and behavioral insights. - Understand their needs, wants, motivations, and pain points. - Clearly articulate the desired outcomes for the campaign. - Use SMART goals (Specific, Measurable, Achievable, Relevant, and Time-bound) for clarity. - Define key performance indicators (KPIs) to track progress and success. - Specify the primary and secondary goals of the campaign. - Examples include brand awareness, lead generation, sales growth, or website traffic. - Clearly define what differentiates your product or service from competitors. - Emphasize the value proposition and unique benefits offered to the target audience. - Define the desired tone and personality of the campaign messaging. - Identify the specific channels you will use to reach your target audience. - Clearly state the desired action you want the audience to take. - Make it specific, compelling, and easy to understand. - Identify and analyze your key competitors in the market. - Understand their strengths and weaknesses, target audience, and marketing strategies. - Develop a differentiation strategy to stand out from the competition. - Define how you will track the success of the campaign. - Use relevant KPIs to measure performance and return on investment (ROI). Provide bullet points and headlines for the marketing campaign. Do not produce any empty lines. Be very succinct and to the point. """ return prompt # function to render the story tab, and call the model, and display the model prompt and response. def render_mktg_campaign_tab (text_model_pro: GenerativeModel): st.write("Using Gemini 1.0 Pro - Text only model") st.subheader("Generate a marketing campaign") prompt = generate_prompt() config = { "temperature": 0.8, "max_output_tokens": 2048, } generate_t2m = st.button("Generate campaign", key="generate_t2m") if generate_t2m and prompt: # st.write(prompt) with st.spinner("Generating a marketing campaign using Gemini..."): first_tab1, first_tab2 = st.tabs(["Campaign response", "Prompt"]) with first_tab1: response = get_gemini_pro_text_response(text_model_pro, prompt, generation_config=config) if response: st.write("Marketing campaign:") st.write(response) logging.info(response) with first_tab2: st.text(prompt) EOF
Modifica l'entry point principale dell'app
-
Per aggiungere tab2 all'app, esegui questo comando:
cat >> ~/gemini-app/app.py <<EOF from app_tab2 import render_mktg_campaign_tab with tab2: render_mktg_campaign_tab(text_model_pro) EOF
Testa l'app - Scheda Marketing campaign (Campagna di marketing)
Genera una campagna di marketing fornendo il tuo input, visualizza il prompt e la risposta generata dal modello Gemini 1.0 Pro.
-
Per eseguire l'app in locale, in Cloud Shell, esegui questo comando:
streamlit run app.py \ --browser.serverAddress=localhost \ --server.enableCORS=false \ --server.enableXsrfProtection=false \ --server.port 8080 L'app viene avviata e ti viene fornito un URL per accedervi.
-
Per avviare la home page dell'app nel browser, fai clic su Anteprima web nella barra dei menu di Cloud Shell, quindi seleziona Anteprima sulla porta 8080.
-
Per generare una campagna di marketing, nella scheda Marketing campaign (Campagna di marketing), lascia le impostazioni predefinite, quindi fai clic su Generate campaign (Genera campagna).
-
Attendi che la risposta venga generata, quindi fai clic sulla scheda Campaign response (Risposta campagna).
-
Per visualizzare il prompt utilizzato per generare la risposta, fai clic sulla scheda Prompt.
-
Ripeti i passaggi precedenti per generare campagne di marketing con diversi valori dei parametri come categoria di prodotto, pubblico di destinazione, località e obiettivi della campagna.
-
Nella finestra Cloud Shell, chiudi l'app e torna al prompt dei comandi premendo Control+C.
Per verificare l'obiettivo, fai clic su Controlla i miei progressi.
Attività 6: genera il playground immagini
In questa attività utilizzerai il modello Gemini 1.0 Pro Vision per elaborare le immagini e ricevere suggerimenti e informazioni dalle immagini che vengono fornite al modello.
Sviluppa tab3 - Image Playground (Playground immagini)
In questa attività secondaria implementerai il codice per la scheda Image Playground (Playground immagini) e il codice per interagire con il modello per generare suggerimenti da un'immagine.
-
Per scrivere il codice che esegue il rendering della scheda Image Playground (Playground immagini) nella UI dell'app, esegui questo comando:
cat > ~/gemini-app/app_tab3.py <<EOF import streamlit as st from vertexai.preview.generative_models import GenerativeModel, Part from response_utils import * import logging # render the Image Playground tab with multiple child tabs def render_image_playground_tab(multimodal_model_pro: GenerativeModel): st.write("Using Gemini 1.0 Pro Vision - Multimodal model") recommendations, screens, diagrams, equations = st.tabs(["Furniture recommendation", "Oven instructions", "ER diagrams", "Math reasoning"]) with recommendations: room_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/living_room.jpeg" chair_1_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair1.jpeg" chair_2_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair2.jpeg" chair_3_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair3.jpeg" chair_4_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair4.jpeg" room_image_url = "https://storage.googleapis.com/"+room_image_uri.split("gs://")[1] chair_1_image_url = "https://storage.googleapis.com/"+chair_1_image_uri.split("gs://")[1] chair_2_image_url = "https://storage.googleapis.com/"+chair_2_image_uri.split("gs://")[1] chair_3_image_url = "https://storage.googleapis.com/"+chair_3_image_uri.split("gs://")[1] chair_4_image_url = "https://storage.googleapis.com/"+chair_4_image_uri.split("gs://")[1] room_image = Part.from_uri(room_image_uri, mime_type="image/jpeg") chair_1_image = Part.from_uri(chair_1_image_uri,mime_type="image/jpeg") chair_2_image = Part.from_uri(chair_2_image_uri,mime_type="image/jpeg") chair_3_image = Part.from_uri(chair_3_image_uri,mime_type="image/jpeg") chair_4_image = Part.from_uri(chair_4_image_uri,mime_type="image/jpeg") st.image(room_image_url,width=350, caption="Image of a living room") st.image([chair_1_image_url,chair_2_image_url,chair_3_image_url,chair_4_image_url],width=200, caption=["Chair 1","Chair 2","Chair 3","Chair 4"]) st.write("Our expectation: Recommend a chair that would complement the given image of a living room.") prompt_list = ["Consider the following chairs:", "chair 1:", chair_1_image, "chair 2:", chair_2_image, "chair 3:", chair_3_image, "and", "chair 4:", chair_4_image, "\n" "For each chair, explain why it would be suitable or not suitable for the following room:", room_image, "Only recommend for the room provided and not other rooms. Provide your recommendation in a table format with chair name and reason as columns.", ] tab1, tab2 = st.tabs(["Response", "Prompt"]) generate_image_description = st.button("Generate recommendation", key="generate_image_description") with tab1: if generate_image_description and prompt_list: with st.spinner("Generating recommendation using Gemini..."): response = get_gemini_pro_vision_response(multimodal_model_pro, prompt_list) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.text(prompt_list) EOF -
Visualizza i contenuti del file
app_tab3.py:cat ~/gemini-app/app_tab3.py La funzione
render_image_playground_tabcrea la UI che consente all'utente dell'app di interagire con il modello Gemini 1.0 Pro Vision. Crea una serie di schede: "Furniture recommendation" (Suggerimento mobili), "Oven instructions" (Istruzioni forno), "ER diagrams" (Diagrammi ER), "Math reasoning" (Ragionamento matematico) nella UI. Nelle attività successive di questo lab scriverai il codice per le schede rimanenti.Nella scheda
Furniture recommendation(Suggerimento mobili), viene utilizzata la scena di un soggiorno per la comprensione visiva. Insieme a una serie di immagini aggiuntive di sedie, il codice richiama l'endpoint API multimodale Gemini 1.0 Pro Vision per ottenere un suggerimento su una sedia che integri la scena del soggiorno.Il codice utilizza più di un prompt di testo e le immagini del soggiorno e delle sedie, quindi fornisce tutto questo al modello in un elenco. La classe
Partviene utilizzata per ottenere l'immagine dall'URI contenuto di più parti ospitato in un bucket Cloud Storage. Il prompt specifica inoltre un formato tabulare per l'output del modello e include la motivazione del suggerimento.

Aggiorna response_utils
Il file response_utils.py contiene funzioni per generare le risposte del modello.
-
Aggiorna il file per aggiungere il codice che genera la risposta multimodale del modello:
cat >> ~/gemini-app/response_utils.py <<EOF def get_gemini_pro_vision_response(model: GenerativeModel, prompt_list, generation_config={}, stream=True): generation_config = {'temperature': 0.1, 'max_output_tokens': 2048 } responses = model.generate_content(prompt_list, generation_config = generation_config, stream=True) final_response = [] for response in responses: try: final_response.append(response.text) except IndexError: final_response.append("") continue return(" ".join(final_response)) EOF
Modifica l'entry point principale dell'app
-
Per aggiungere tab3 all'app, esegui questo comando:
cat >> ~/gemini-app/app.py <<EOF from app_tab3 import render_image_playground_tab with tab3: render_image_playground_tab(multimodal_model_pro) EOF
Testa l'app - Scheda Image Playground (Playground immagini)
-
Esegui l'app utilizzando il comando fornito nei passaggi precedenti del lab.
-
Per avviare la home page dell'app nel browser, fai clic su Anteprima web nella barra dei menu di Cloud Shell, quindi seleziona Anteprima sulla porta 8080.
-
Fai clic su Image Playground (Playground immagini) e quindi su Furniture recommendation (Suggerimento mobili).
La scheda visualizza le immagini del soggiorno e delle sedie.
-
Fai clic su Generate recommendation (Genera suggerimento).
Se ti viene restituito questo errore: FailedPrecondition: 400 We are preparing necessary resources. Please wait few minutes and retry. (Precondizione non riuscita: 400 Stiamo preparando le risorse necessarie. Attendi alcuni minuti e riprova.), attendi alcuni minuti e quindi fai nuovamente clic su Generate recommendation (Genera suggerimento). -
Visualizza la risposta del modello Gemini 1.0 Pro Vision.
La risposta è in formato tabulare come richiesto nel prompt. Il modello suggerisce due delle quattro sedie e fornisce la motivazione del suggerimento.
-
Nella finestra Cloud Shell, chiudi l'app e torna al prompt dei comandi premendo Control+C.
Per verificare l'obiettivo, fai clic su Controlla i miei progressi.
Attività 7: analizza il layout dell'immagine
In questa attività utilizzerai il modello Gemini 1.0 Pro Vision per estrarre informazioni da un'immagine dopo aver analizzato il layout delle icone e del testo.
Aggiorna la scheda Image Playground (Playground immagini) - Oven instructions (Istruzioni forno)
Gemini è dotato della capacità di estrarre informazioni dagli elementi visivi sugli schermi e può analizzare screenshot, icone e layout per fornire una comprensione olistica della scena rappresentata. In questa attività, fornirai al modello un'immagine del pannello di controllo di un forno da cucina, quindi chiederai al modello di generare istruzioni per una funzione specifica.
-
Per implementare il codice per la scheda Oven instructions (Istruzioni forno) nella scheda Image Playground (Playground immagini) nella UI dell'app, esegui questo comando:
cat >> ~/gemini-app/app_tab3.py <<EOF with screens: oven_screen_uri = "gs://cloud-training/OCBL447/gemini-app/images/oven.jpg" oven_screen_url = "https://storage.googleapis.com/"+oven_screen_uri.split("gs://")[1] oven_screen_img = Part.from_uri(oven_screen_uri, mime_type="image/jpeg") st.image(oven_screen_url, width=350, caption="Image of an oven control panel") st.write("Provide instructions for resetting the clock on this appliance in English") prompt = """How can I reset the clock on this appliance? Provide the instructions in English. If instructions include buttons, also explain where those buttons are physically located. """ tab1, tab2 = st.tabs(["Response", "Prompt"]) generate_instructions_description = st.button("Generate instructions", key="generate_instructions_description") with tab1: if generate_instructions_description and prompt: with st.spinner("Generating instructions using Gemini..."): response = get_gemini_pro_vision_response(multimodal_model_pro, [oven_screen_img, prompt]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.text(prompt+"\n"+"input_image") EOF Il codice sopra crea la UI della scheda Oven instructions (Istruzioni forno). Viene utilizzata un'immagine del pannello di controllo di un forno da cucina insieme al testo per richiedere al modello di generare istruzioni per una funzione specifica disponibile sul pannello, in questo caso, la reimpostazione dell'orologio.

Testa l'app - Scheda Image Playground (Playground immagini) - Oven instructions (Istruzioni forno)
-
Esegui l'app utilizzando il comando fornito nei passaggi precedenti del lab.
-
Per avviare la home page dell'app nel browser, fai clic su Anteprima web nella barra dei menu di Cloud Shell, quindi seleziona Anteprima sulla porta 8080.
-
Fai clic su Image Playground (Playground immagini) e quindi su Oven instructions (Istruzioni forno).
La scheda visualizza un'immagine del pannello di controllo del forno.
-
Fai clic su Generate instructions (Genera istruzioni).
-
Visualizza la risposta del modello Gemini 1.0 Pro Vision.
La risposta contiene i passaggi che possono essere utilizzati per reimpostare l'orologio sul pannello di controllo del forno. Include anche istruzioni che indicano dove posizionare il pulsante sul pannello, dimostrando la capacità del modello di analizzare il layout del pannello nell'immagine.
-
Nella finestra Cloud Shell, chiudi l'app e torna al prompt dei comandi premendo Control+C.
Per verificare l'obiettivo, fai clic su Controlla i miei progressi.
Attività 8: analizza i diagrammi ER
Le capacità multimodali di Gemini gli consentono di comprendere diagrammi e intraprendere azioni attuabili, come la generazione di codice o di documenti. In questa attività utilizzerai il modello Gemini 1.0 Pro Vision per analizzare un diagramma entità-relazione (ER) e generare documentazione sulle entità e sulle relazioni trovate nel diagramma.
Aggiorna la scheda Image Playground (Playground immagini) - ER diagrams (Diagrammi ER)
In questa attività, fornirai un'immagine di un diagramma ER al modello e quindi chiederai al modello di generare la documentazione.
-
Per implementare il codice per la scheda ER diagrams (Diagrammi ER) nella scheda Image Playground (Playground immagini) nella UI dell'app, esegui questo comando:
cat >> ~/gemini-app/app_tab3.py <<EOF with diagrams: er_diag_uri = "gs://cloud-training/OCBL447/gemini-app/images/er.png" er_diag_url = "https://storage.googleapis.com/"+er_diag_uri.split("gs://")[1] er_diag_img = Part.from_uri(er_diag_uri,mime_type="image/png") st.image(er_diag_url, width=350, caption="Image of an ER diagram") st.write("Document the entities and relationships in this ER diagram.") prompt = """Document the entities and relationships in this ER diagram.""" tab1, tab2 = st.tabs(["Response", "Prompt"]) er_diag_img_description = st.button("Generate documentation", key="er_diag_img_description") with tab1: if er_diag_img_description and prompt: with st.spinner("Generating..."): response = get_gemini_pro_vision_response(multimodal_model_pro,[er_diag_img,prompt]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.text(prompt+"\n"+"input_image") EOF Il codice sopra crea la UI della scheda ER diagrams (Diagrammi ER). Un'immagine di un diagramma ER viene utilizzata insieme al testo per richiedere al modello di generare documentazione sulle entità e sulle relazioni trovate nel diagramma.
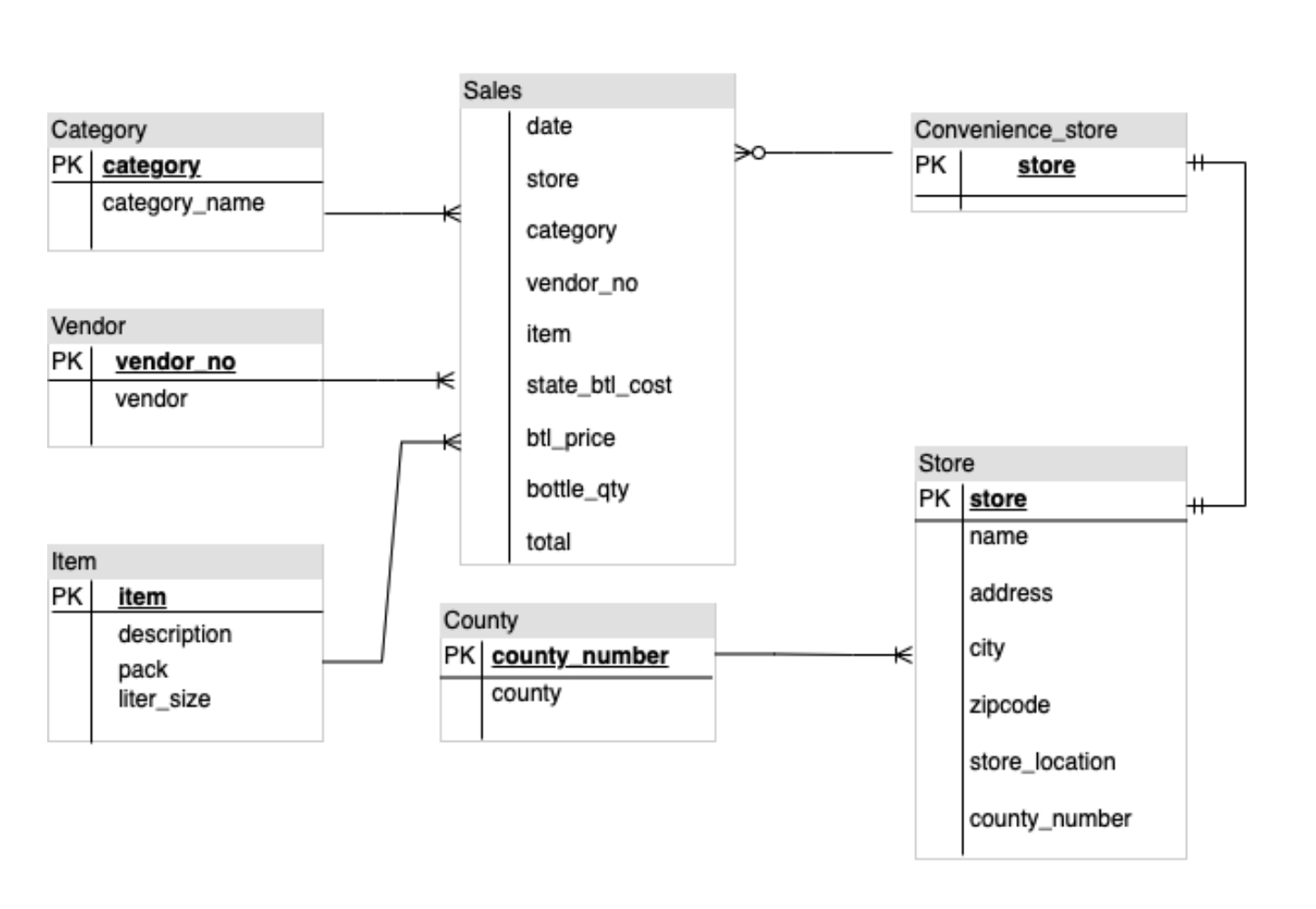
Testa l'app - Scheda Image Playground (Playground immagini - ER diagrams (Diagrammi ER)
-
Esegui l'app utilizzando il comando fornito nei passaggi precedenti del lab.
-
Per avviare la home page dell'app nel browser, fai clic su Anteprima web nella barra dei menu di Cloud Shell, quindi seleziona Anteprima sulla porta 8080.
-
Fai clic su Image Playground (Playground immagini) e quindi su ER Diagrams (Diagrammi ER).
La scheda visualizza l'immagine del diagramma ER.
-
Fai clic su Generate documentation (Genera documentazione).
-
Visualizza la risposta del modello Gemini 1.0 Pro Vision.
La risposta contiene l'elenco delle entità e delle relative relazioni trovate nel diagramma.
-
Nella finestra Cloud Shell, chiudi l'app e torna al prompt dei comandi premendo Control+C.
Per verificare l'obiettivo, fai clic su Controlla i miei progressi.
Attività 9: ragionamento matematico
Gemini 1.0 Pro Vision può anche riconoscere formule ed equazioni matematiche ed estrarne informazioni specifiche. Questa funzionalità è particolarmente utile per generare spiegazioni per problemi di matematica.
Aggiorna la scheda Image Playground (Playground immagini) - Math reasoning (Ragionamento matematico)
In questa attività utilizzerai il modello Gemini 1.0 Pro Vision per estrarre e interpretare una formula matematica da un'immagine.
-
Per implementare il codice per la scheda Math reasoning (Ragionamento matematico) nella scheda Image Playground (Playground immagini) nella UI dell'app, esegui questo comando:
cat >> ~/gemini-app/app_tab3.py <<EOF with equations: math_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/math_eqn.jpg" math_image_url = "https://storage.googleapis.com/"+math_image_uri.split("gs://")[1] math_image_img = Part.from_uri(math_image_uri,mime_type="image/jpeg") st.image(math_image_url,width=350, caption="Image of a math equation") st.markdown(f""" Ask questions about the math equation as follows: - Extract the formula. - What is the symbol right before Pi? What does it mean? - Is this a famous formula? Does it have a name? """) prompt = """Follow the instructions. Surround math expressions with $. Use a table with a row for each instruction and its result. INSTRUCTIONS: - Extract the formula. - What is the symbol right before Pi? What does it mean? - Is this a famous formula? Does it have a name? """ tab1, tab2 = st.tabs(["Response", "Prompt"]) math_image_description = st.button("Generate answers", key="math_image_description") with tab1: if math_image_description and prompt: with st.spinner("Generating answers for formula using Gemini..."): response = get_gemini_pro_vision_response(multimodal_model_pro, [math_image_img, prompt]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.text(prompt) EOF Il codice sopra crea la UI della scheda Math reasoning (Ragionamento matematico). Viene utilizzata un'immagine di un'equazione matematica insieme al testo per chiedere al modello di generare risposte e altre caratteristiche sull'equazione.

Testa l'app - Scheda Image Playground (Playground immagini) - Math reasoning (Ragionamento matematico)
-
Esegui l'app utilizzando il comando fornito nei passaggi precedenti del lab.
-
Per avviare la home page dell'app nel browser, fai clic su Anteprima web nella barra dei menu di Cloud Shell, quindi seleziona Anteprima sulla porta 8080.
-
Fai clic su Image Playground (Playground immagini) e quindi su Math reasoning (Ragionamento matematico).
La scheda visualizza l'immagine contenente l'equazione matematica.
-
Fai clic su Generate answers (Genera risposte).
-
Visualizza la risposta del modello Gemini 1.0 Pro Vision.
La risposta contiene le risposte alle domande fornite nel prompt del modello.
-
Nella finestra Cloud Shell, chiudi l'app e torna al prompt dei comandi premendo Control+C.
Per verificare l'obiettivo, fai clic su Controlla i miei progressi.
Attività 10: genera il playground video
In questa attività utilizzerai il modello Gemini 1.0 Pro Vision per elaborare video e generare tag e informazioni dai video forniti al modello.
Sviluppa tab4 - Video Playground (Playground video)
Il modello Gemini 1.0 Pro Vision può anche fornire la descrizione di ciò che sta accadendo in un video. In questa attività secondaria implementerai il codice per la scheda Video Playground (Playground video) e il codice per interagire con il modello per generare la descrizione di un video.
-
Per scrivere il codice che esegue il rendering della scheda Video Playground (Playground video) nella UI dell'app, esegui questo comando:
cat > ~/gemini-app/app_tab4.py <<EOF import streamlit as st from vertexai.preview.generative_models import GenerativeModel, Part from response_utils import * import logging # render the Video Playground tab with multiple child tabs def render_video_playground_tab(multimodal_model_pro: GenerativeModel): st.write("Using Gemini 1.0 Pro Vision - Multimodal model") video_desc, video_tags, video_highlights, video_geoloc = st.tabs(["Video description", "Video tags", "Video highlights", "Video geolocation"]) with video_desc: video_desc_uri = "gs://cloud-training/OCBL447/gemini-app/videos/mediterraneansea.mp4" video_desc_url = "https://storage.googleapis.com/"+video_desc_uri.split("gs://")[1] video_desc_vid = Part.from_uri(video_desc_uri, mime_type="video/mp4") st.video(video_desc_url) st.write("Generate a description of the video.") prompt = """Describe what is happening in the video and answer the following questions: \n - What am I looking at? - Where should I go to see it? - What are other top 5 places in the world that look like this? """ tab1, tab2 = st.tabs(["Response", "Prompt"]) video_desc_description = st.button("Generate video description", key="video_desc_description") with tab1: if video_desc_description and prompt: with st.spinner("Generating video description"): response = get_gemini_pro_vision_response(multimodal_model_pro, [prompt, video_desc_vid]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.write(prompt,"\n","{video_data}") EOF -
Visualizza i contenuti del file
app_tab4.py:cat ~/gemini-app/app_tab4.py La funzione
render_video_playground_tabcrea la UI che consente all'utente dell'app di interagire con il modello Gemini 1.0 Pro Vision. Crea una serie di schede: "Video description" (Descrizione video), "Video tags" (Tag video), "Video highlights" (Momenti salienti video), "Video geolocation" (Geolocalizzazione video) nella UI. Nelle attività successive di questo lab scriverai il codice per le schede rimanenti.La scheda
Video description(Descrizione video) utilizza un prompt insieme al video per generare una descrizione del video e identificare altri luoghi che sembrano simili a quello nel video.
Modifica l'entry point principale dell'app
-
Per aggiungere tab4 all'app, esegui questo comando:
cat >> ~/gemini-app/app.py <<EOF from app_tab4 import render_video_playground_tab with tab4: render_video_playground_tab(multimodal_model_pro) EOF
Testa l'app - Scheda Video Playground (Playground video)
-
Esegui l'app utilizzando il comando fornito nei passaggi precedenti del lab.
-
Per avviare la home page dell'app nel browser, fai clic su Anteprima web nella barra dei menu di Cloud Shell, quindi seleziona Anteprima sulla porta 8080.
-
Fai clic su Video Playground (Playground video) e quindi su Video description (Descrizione video).
-
La scheda visualizza il video di un luogo. Fai clic per riprodurre il video.
-
Fai clic su Generate video description (Genera descrizione video).
-
Visualizza la risposta del modello Gemini 1.0 Pro Vision.
La risposta contiene una descrizione del luogo e altri cinque luoghi che sembrano simili.
-
Nella finestra Cloud Shell, chiudi l'app e torna al prompt dei comandi premendo Control+C.
Per verificare l'obiettivo, fai clic su Controlla i miei progressi.
Attività 11: genera tag video
In questa attività utilizzerai il modello Gemini 1.0 Pro Vision per generare tag da un video.
Aggiorna la scheda Video Playground (Playground video) - Video tags (Tag video)
-
Per implementare il codice per la scheda Video tags (Tag video) nella scheda Video Playground (Playground video) nella UI dell'app, esegui questo comando:
cat >> ~/gemini-app/app_tab4.py <<EOF with video_tags: video_tags_uri = "gs://cloud-training/OCBL447/gemini-app/videos/photography.mp4" video_tags_url = "https://storage.googleapis.com/"+video_tags_uri.split("gs://")[1] video_tags_vid = Part.from_uri(video_tags_uri, mime_type="video/mp4") st.video(video_tags_url) st.write("Generate tags for the video.") prompt = """Answer the following questions using the video only: 1. What is in the video? 2. What objects are in the video? 3. What is the action in the video? 4. Provide 5 best tags for this video? Write the answer in table format with the questions and answers in columns. """ tab1, tab2 = st.tabs(["Response", "Prompt"]) video_tags_desc = st.button("Generate video tags", key="video_tags_desc") with tab1: if video_tags_desc and prompt: with st.spinner("Generating video tags"): response = get_gemini_pro_vision_response(multimodal_model_pro, [prompt, video_tags_vid]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.write(prompt,"\n","{video_data}") EOF Il codice sopra crea la UI della scheda Video tags (Tag video). Viene utilizzato un video insieme al testo per chiedere al modello di generare tag e rispondere a domande sulle scene nel video.
Testa l'app - Scheda Video Playground (Playground video) - Video tags (Tag video)
-
Esegui l'app utilizzando il comando fornito nei passaggi precedenti del lab.
-
Per avviare la home page dell'app nel browser, fai clic su Anteprima web nella barra dei menu di Cloud Shell, quindi seleziona Anteprima sulla porta 8080.
-
Fai clic su Video Playground (Playground video) e quindi su Video tags (Tag video).
-
La scheda visualizza il video che verrà utilizzato per la richiesta al modello. Fai clic per riprodurre il video.
-
Fai clic su Generate video tags (Genera tag video).
-
Visualizza la risposta del modello Gemini 1.0 Pro Vision.
La risposta contiene le risposte alle domande fornite nella richiesta al modello. Le domande e le risposte vengono fornite in formato tabulare e includono cinque tag come richiesto.
-
Nella finestra Cloud Shell, chiudi l'app e torna al prompt dei comandi premendo Control+C.
Per verificare l'obiettivo, fai clic su Controlla i miei progressi.
Attività 12: genera momenti salienti del video
In questa attività utilizzerai il modello Gemini 1.0 Pro Vision per generare i momenti salienti di un video che includono informazioni sugli oggetti, le persone e il contesto mostrato nel video.
Aggiorna la scheda Image Playground (Playground immagini) - Video highlights (Momenti salienti video)
-
Per implementare il codice per la scheda Video highlights (Momenti salienti video) nella scheda Video Playground (Playground video) nella UI dell'app, esegui questo comando:
cat >> ~/gemini-app/app_tab4.py <<EOF with video_highlights: video_highlights_uri = "gs://cloud-training/OCBL447/gemini-app/videos/pixel8.mp4" video_highlights_url = "https://storage.googleapis.com/"+video_highlights_uri.split("gs://")[1] video_highlights_vid = Part.from_uri(video_highlights_uri, mime_type="video/mp4") st.video(video_highlights_url) st.write("Generate highlights for the video.") prompt = """Answer the following questions using the video only: What is the profession of the girl in this video? Which features of the phone are highlighted here? Summarize the video in one paragraph. Write these questions and their answers in table format. """ tab1, tab2 = st.tabs(["Response", "Prompt"]) video_highlights_description = st.button("Generate video highlights", key="video_highlights_description") with tab1: if video_highlights_description and prompt: with st.spinner("Generating video highlights"): response = get_gemini_pro_vision_response(multimodal_model_pro, [prompt, video_highlights_vid]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.write(prompt,"\n","{video_data}") EOF Il codice sopra crea la UI della scheda Video highlights (Momenti salienti video). Viene utilizzato un video insieme al testo per chiedere al modello di generare i momenti salienti dal video.
Testa l'app - Scheda Video Playground (Playground video) - Video highlights (Momenti salienti video)
-
Esegui l'app utilizzando il comando fornito nei passaggi precedenti del lab.
-
Per avviare la home page dell'app nel browser, fai clic su Anteprima web nella barra dei menu di Cloud Shell, quindi seleziona Anteprima sulla porta 8080.
-
Fai clic su Video Playground (Playground video) e quindi su Video highlights (Momenti salienti video).
-
La scheda visualizza il video che verrà utilizzato per la richiesta al modello. Fai clic per riprodurre il video.
-
Fai clic su Generate video highlights (Genera momenti salienti video).
-
Visualizza la risposta del modello Gemini 1.0 Pro Vision.
La risposta contiene le risposte alle domande fornite nella richiesta al modello. Le domande e le risposte vengono fornite in formato tabulare ed elencano le caratteristiche del video come la professione della ragazza e le caratteristiche dello smartphone utilizzate. La risposta contiene anche una descrizione riepilogativa delle scene presenti nel video.
-
Nella finestra Cloud Shell, chiudi l'app e torna al prompt dei comandi premendo Control+C.
Per verificare l'obiettivo, fai clic su Controlla i miei progressi.
Attività 13: genera la località del video
In questa attività utilizzerai il modello Gemini 1.0 Pro Vision per determinare la località in cui si svolge la scena nel video.
Aggiorna la scheda Image Playground (Playground immagini) - Video geolocation (Geolocalizzazione video)
-
Per implementare il codice per la scheda Video geolocation (Geolocalizzazione video) nella scheda Video Playground (Playground video) nella UI dell'app, esegui questo comando:
cat >> ~/gemini-app/app_tab4.py <<EOF with video_geoloc: video_geolocation_uri = "gs://cloud-training/OCBL447/gemini-app/videos/bus.mp4" video_geolocation_url = "https://storage.googleapis.com/"+video_geolocation_uri.split("gs://")[1] video_geolocation_vid = Part.from_uri(video_geolocation_uri, mime_type="video/mp4") st.video(video_geolocation_url) st.markdown("""Answer the following questions from the video: - What is this video about? - How do you know which city it is? - What street is this? - What is the nearest intersection? """) prompt = """Answer the following questions using the video only: What is this video about? How do you know which city it is? What street is this? What is the nearest intersection? Answer the following questions using a table format with the questions and answers as columns. """ tab1, tab2 = st.tabs(["Response", "Prompt"]) video_geolocation_description = st.button("Generate", key="video_geolocation_description") with tab1: if video_geolocation_description and prompt: with st.spinner("Generating location information"): response = get_gemini_pro_vision_response(multimodal_model_pro, [prompt, video_geolocation_vid]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.write(prompt,"\n","{video_data}") EOF Il codice sopra crea la UI della scheda Video geolocation (Geolocalizzazione video). Viene utilizzato un video insieme al testo per chiedere al modello di rispondere a domande sul video che includono dati sulla posizione delle entità viste nel video.
Testa l'app - Scheda Video Playground (Playground video) - Video geolocation (Geolocalizzazione video)
-
Esegui l'app utilizzando il comando fornito nei passaggi precedenti del lab.
-
Per avviare la home page dell'app nel browser, fai clic su Anteprima web nella barra dei menu di Cloud Shell, quindi seleziona Anteprima sulla porta 8080.
-
Fai clic su Video Playground (Playground video) e quindi su Video geolocation (Geolocalizzazione video).
-
La scheda visualizza il video che verrà utilizzato per la richiesta al modello. Fai clic per riprodurre il video.
-
Fai clic su Genera.
-
Visualizza la risposta del modello Gemini 1.0 Pro Vision.
La risposta contiene le risposte alle domande fornite nella richiesta al modello. Le domande e le risposte vengono fornite in formato tabulare e includono i dati sulla posizione come richiesto.
-
Nella finestra Cloud Shell, chiudi l'app e torna al prompt dei comandi premendo Control+C.
Per verificare l'obiettivo, fai clic su Controlla i miei progressi.
Attività 14: esegui il deployment dell'app in Cloud Run
Ora che hai testato l'app localmente, puoi renderla disponibile agli altri eseguendone il deployment in Cloud Run su Google Cloud. Cloud Run è una piattaforma di computing gestita che ti consente di eseguire container di applicazioni sull'infrastruttura scalabile di Google.
Configura l'ambiente
-
Assicurati di essere nella directory
app:cd ~/gemini-app -
Verifica che le variabili di ambiente PROJECT_ID e REGION siano impostate:
echo "PROJECT_ID=${PROJECT_ID}" echo "REGION=${REGION}" -
Se queste variabili di ambiente non sono impostate, esegui questo comando per impostarle:
PROJECT_ID=$(gcloud config get-value project) REGION={{{project_0.default_region|set at lab start}}} echo "PROJECT_ID=${PROJECT_ID}" echo "REGION=${REGION}" -
Imposta le variabili di ambiente per il servizio e il repository di artefatti:
SERVICE_NAME='gemini-app-playground' # Name of your Cloud Run service. AR_REPO='gemini-app-repo' # Name of your repository in Artifact Registry that stores your application container image. echo "SERVICE_NAME=${SERVICE_NAME}" echo "AR_REPO=${AR_REPO}"
Crea il repository Docker
-
Per creare il repository in Artifact Registry, esegui questo comando:
gcloud artifacts repositories create "$AR_REPO" --location="$REGION" --repository-format=Docker Artifact Registry è un servizio Google Cloud che fornisce un'unica località per l'archiviazione e la gestione dei pacchetti software e delle immagini container Docker. -
Configura l'autenticazione nel repository:
gcloud auth configure-docker "$REGION-docker.pkg.dev"
Crea l'immagine container
Utilizzeremo un Dockerfile per creare l'immagine container per la nostra applicazione. Un Dockerfile è un documento di testo che contiene tutti i comandi che un utente può chiamare sulla riga di comando per assemblare un'immagine container. Viene utilizzato con Docker, una piattaforma di container che crea ed esegue immagini container.
-
Per creare un
Dockerfile, esegui questo comando:cat > ~/gemini-app/Dockerfile <<EOF FROM python:3.8 EXPOSE 8080 WORKDIR /app COPY . ./ RUN pip install -r requirements.txt ENTRYPOINT ["streamlit", "run", "app.py", "--server.port=8080", "--server.address=0.0.0.0"] EOF -
Per creare l'immagine container per la tua app, esegui questo comando:
gcloud builds submit --tag "$REGION-docker.pkg.dev/$PROJECT_ID/$AR_REPO/$SERVICE_NAME" Il comando gcloud builds submit invia una build utilizzando Cloud Build. Se utilizzato con il flag tag, Cloud Build usa un Dockerfile per creare un'immagine container dai file dell'applicazione nella directory di origine. Cloud Build è un servizio che esegue build in base alle tue specifiche su Google Cloud e produce artefatti come container Docker o archivi Java.
Attendi il completamento del comando prima di procedere al passaggio successivo.
Esegui il deployment della tua app e testala su Cloud Run
L'attività finale consiste nell'eseguire il deployment del servizio su Cloud Run con l'immagine creata e di cui è stato eseguito il push al repository in Artifact Registry.
-
Per eseguire il deployment dell'app su Cloud Run, esegui questo comando:
gcloud run deploy "$SERVICE_NAME" \ --port=8080 \ --image="$REGION-docker.pkg.dev/$PROJECT_ID/$AR_REPO/$SERVICE_NAME" \ --allow-unauthenticated \ --region=$REGION \ --platform=managed \ --project=$PROJECT_ID \ --set-env-vars=PROJECT_ID=$PROJECT_ID,REGION=$REGION -
Dopo il deployment del servizio, viene generato un URL del servizio nell'output del comando precedente. Per testare la tua app su Cloud Run, vai all'URL in una scheda o finestra separata del browser.
-
Scegli la funzionalità dell'app che desideri testare. L'app richiederà all'API Gemini di Vertex AI di generare e visualizzare le risposte.
Per verificare l'obiettivo, fai clic su Controlla i miei progressi.
Terminare il lab
Una volta completato il lab, fai clic su Termina lab. Qwiklabs rimuove le risorse che hai utilizzato ed esegue la pulizia dell'account.
Avrai la possibilità di inserire una valutazione in merito alla tua esperienza. Seleziona il numero di stelle applicabile, inserisci un commento, quindi fai clic su Invia.
Il numero di stelle corrisponde alle seguenti valutazioni:
- 1 stella = molto insoddisfatto
- 2 stelle = insoddisfatto
- 3 stelle = esperienza neutra
- 4 stelle = soddisfatto
- 5 stelle = molto soddisfatto
Se non vuoi lasciare un feedback, chiudi la finestra di dialogo.
Per feedback, suggerimenti o correzioni, utilizza la scheda Assistenza.
Complimenti!
In questo lab hai imparato a:
- Sviluppare un'app Python utilizzando il framework Streamlit.
- Installare l'SDK Vertex AI per Python.
- Sviluppare del codice per interagire con il modello Gemini 1.0 Pro (gemini-pro) utilizzando l'API Gemini di Vertex AI.
- Utilizzare prompt di testo con il modello per generare una storia e una campagna di marketing.
- Sviluppare del codice per interagire con il modello Gemini 1.0 Pro Vision (gemini-pro-vision) utilizzando l'API Gemini di Vertex AI.
- Utilizzare testo, immagini e video con il modello per elaborare ed estrarre informazioni da immagini e video.
- Eseguire il deployment e testare l'app su Cloud Run.
Passaggi successivi/Scopri di più
- Vertex AI
- Gemini
- Riferimento ai modelli generativi SDK di Vertex AI
- Artifact Registry
- Cloud Build
- Cloud Run
Copyright 2023 Google LLC Tutti i diritti riservati. Google e il logo Google sono marchi di Google LLC. Tutti gli altri nomi di società e prodotti sono marchi delle rispettive società a cui sono associati.

