Checkpoints
Enable relevant APIs.
/ 5
Application is developed with Story tab.
/ 5
Application marketing campaign tab is developed.
/ 5
Application image playground with furniture recommendation tab is developed.
/ 5
Image playground with oven instructions tab is developed.
/ 10
Image playground with ER diagrams tab is developed
/ 10
Image playground with math reasoning tab is developed.
/ 10
Application video playground with video description tab is developed.
/ 10
Video playground with video tags tab is developed.
/ 10
Video playground with video highlights tab is developed.
/ 10
Video playground with video geolocation tab is developed.
/ 10
Application is deployed to Cloud Run.
/ 10
Desenvolver um app com o Gemini 1.0 Pro da Vertex AI
- Visão geral
- Objetivos
- Configuração
- Tarefa 1: configure o ambiente e o projeto
- Tarefa 2: configurar o ambiente no aplicativo
- Tarefa 3: desenvolva o app
- Tarefa 4: execute e teste o app localmente
- Tarefa 5: gere uma campanha de marketing
- Tarefa 6: gere o playground de imagem
- Tarefa 7: analise o layout de imagem
- Tarefa 8: analise diagramas de ER
- Tarefa 9: gere a justificativa de matemática
- Tarefa 10: gere o Video Playground
- Tarefa 11: gere tags de vídeo
- Tarefa 12: gere destaques do vídeo
- Tarefa 13: gere o local do vídeo
- Tarefa 14: implante o app no Cloud Run
- Finalize o laboratório
- Parabéns!
Visão geral
O Gemini é uma família de modelos de IA generativa para casos de uso multimodais. Ele tem três tamanhos: Ultra, Pro e Nano. O Gemini 1.0 Pro está disponível para que desenvolvedores e empresas criem para os casos de uso próprios. Essa versão do Gemini recebe texto como entrada e gera texto como saída. Ela também conta com um endpoint multimodal de visão, que recebe texto e imagens como entrada e gera texto como saída. Estão disponíveis SDKs para a criação de apps em Python, Android (Kotlin), Node.js, Swift e JavaScript.
No Google Cloud, a API Gemini da Vertex AI é uma interface unificada para interagir com modelos do Gemini. Ela dá suporte a comandos multimodais como entrada e gera texto ou código. Há dois modelos disponíveis na API Gemini no momento:
-
Modelo Gemini 1.0 Pro (gemini-pro): processa tarefas de linguagem natural, chat de código e texto com várias interações e geração de código.
-
Modelo Gemini 1.0 Pro Vision (gemini-pro-vision): dá suporte a comandos multimodais. É possível incluir texto, imagens e vídeo nos comandos e receber respostas de texto ou código.
A Vertex AI é uma plataforma de Machine Learning (ML) para treinar e implantar modelos de ML e aplicativos de IA, além de personalizar Modelos de Linguagem Grandes (LLMs) para uso em aplicativos com tecnologia de IA. Além da personalização do Gemini com controle total dos dados, o serviço também conta com os recursos do Google Cloud nas áreas de segurança empresarial, privacidade, governança de dados e compliance. Saiba mais sobre a Vertex AI no link da seção Próximas etapas, ao final do laboratório.
Neste laboratório, você vai usar o SDK da Vertex AI para Python para chamar a API Gemini da Vertex AI.
Objetivos
Neste laboratório, você vai aprender a fazer o seguinte:
- Desenvolver um app Python com o framework Streamlit.
- Instalar o SDK da Vertex AI para Python.
- Desenvolver código para interagir com o modelo Gemini 1.0 Pro (gemini-pro) usando a API Gemini da Vertex AI.
- Desenvolver código para interagir com o modelo Gemini 1.0 Pro Vision (gemini-pro-vision) usando a API Gemini da Vertex AI.
- Conteinerizar, implantar e testar o aplicativo no Cloud Run.
Configuração
Para cada laboratório, você recebe um novo projeto do Google Cloud e um conjunto de recursos por um determinado período e sem custos financeiros.
-
Faça login no Qwiklabs em uma janela anônima.
-
Confira o tempo de acesso do laboratório (por exemplo,
1:15:00) e finalize todas as atividades nesse prazo.
Não é possível pausar o laboratório. Você pode reiniciar o desafio, mas vai precisar refazer todas as etapas. -
Quando tudo estiver pronto, clique em Começar o laboratório.
-
Anote as credenciais (Nome de usuário e Senha). É com elas que você vai fazer login no Console do Google Cloud.
-
Clique em Abrir Console do Google.
-
Clique em Usar outra conta, depois copie e cole as credenciais deste laboratório nos locais indicados.
Se você usar outras credenciais, vai receber mensagens de erro ou cobranças. -
Aceite os termos e pule a página de recursos de recuperação.
Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual que contém ferramentas para desenvolvedores. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece aos seus recursos do Google Cloud acesso às linhas de comando. A gcloud é a ferramenta ideal para esse tipo de operação no Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
-
No painel de navegação do Console do Google Cloud, clique em Ativar o Cloud Shell (
).
-
Clique em Continuar.
O provisionamento e a conexão do ambiente podem demorar um pouco. Quando esses processos forem concluídos, você já vai ter uma autenticação, e o projeto estará definido com seu PROJECT_ID. Por exemplo:

Exemplo de comandos
-
Liste o nome da conta ativa:
(Saída)
(Exemplo de saída)
-
Liste o ID do projeto:
(Saída)
(Exemplo de saída)
Tarefa 1: configure o ambiente e o projeto
-
Faça login no console do Google Cloud com as credenciais do laboratório e abra a janela de terminal do Cloud Shell.
-
Para definir as variáveis de ambiente com o ID do projeto e a região, execute estes comandos no Cloud Shell:
PROJECT_ID=$(gcloud config get-value project) REGION={{{project_0.default_region|set at lab start}}} echo "PROJECT_ID=${PROJECT_ID}" echo "REGION=${REGION}" -
Para usar alguns serviços do Google Cloud no laboratório, é preciso ativar algumas APIs:
gcloud services enable cloudbuild.googleapis.com cloudfunctions.googleapis.com run.googleapis.com logging.googleapis.com storage-component.googleapis.com aiplatform.googleapis.com
Para verificar o objetivo, clique em Verificar meu progresso.
Tarefa 2: configurar o ambiente no aplicativo
Nesta tarefa, você vai configurar um ambiente virtual de Python e instalar as dependências do aplicativo.
Verifique se o Cloud Shell tem autorização
-
Para verificar se o Cloud Shell tem autorização, execute este comando no Cloud Shell:
gcloud auth list -
Se for solicitado que você autorize o Cloud Shell, clique em Autorizar.
Crie o diretório do app
-
Para criar o diretório do app, execute este comando:
mkdir ~/gemini-app -
Abra o diretório
~/gemini-app:cd ~/gemini-app Os arquivos do aplicativo serão criados no diretório
~/gemini-app. O diretório vai conter os arquivos de código-fonte e as dependências do aplicativo Python, além de um arquivo do Docker que será usado depois no laboratório.
Configure um ambiente virtual de Python
Crie um ambiente virtual sobre a instalação de Python. Os pacotes instalados nesse ambiente vão ficar isolados dos pacotes no ambiente de base. Quando forem usadas no ambiente virtual, as ferramentas como pip vão instalar os pacotes Python nesse ambiente.
-
Para criar o ambiente virtual de Python, execute este comando na pasta
gemini-app:python3 -m venv gemini-streamlit O módulo venv cria um ambiente virtual leve, com um conjunto independente de pacotes Python. -
Ative o ambiente virtual de Python:
source gemini-streamlit/bin/activate
Instale as dependências do aplicativo
O arquivo de requisitos de Python é um arquivo em texto simples que contém as dependências que o projeto exige. Para começar, precisamos incluir três módulos no arquivo.
Nosso app foi programado com Streamlit, uma biblioteca de Python de código aberto usada para criar apps da Web de machine learning e ciência de dados. O app usa a biblioteca do SDK da Vertex AI para Python para interagir com a API e os modelos do Gemini. Usamos o Cloud Logging para registrar as informações do aplicativo.
-
Para criar o arquivo de requisitos, execute este comando:
cat > ~/gemini-app/requirements.txt <<EOF streamlit google-cloud-aiplatform==1.38.1 google-cloud-logging==3.6.0 EOF -
Instale as dependências do aplicativo:
pip install -r requirements.txt O utilitário pip é o instalador de pacotes de Python.
Prossiga para a próxima tarefa quando a instalação de todos os pacotes terminar.
Tarefa 3: desenvolva o app
O código-fonte do aplicativo será gravado em vários arquivos .py. Vamos começar com o principal ponto de entrada em app.py.
Programe o ponto de entrada principal do app
-
Para criar o código do ponto de entrada de
app.py, execute este comando:cat > ~/gemini-app/app.py <<EOF import os import streamlit as st from app_tab1 import render_story_tab from vertexai.preview.generative_models import GenerativeModel import vertexai import logging from google.cloud import logging as cloud_logging # configurar o registro logging.basicConfig(level=logging.INFO) # anexar um manipulador do Cloud Logging ao logger raiz log_client = cloud_logging.Client() log_client.setup_logging() PROJECT_ID = os.environ.get('PROJECT_ID') # O ID do Google Cloud do seu projeto do Qwiklabs LOCATION = os.environ.get('REGION') # A região do seu projeto do Google Cloud do Qwiklabs vertexai.init(project=PROJECT_ID, location=LOCATION) @st.cache_resource def load_models(): text_model_pro = GenerativeModel("gemini-pro") multimodal_model_pro = GenerativeModel("gemini-pro-vision") return text_model_pro, multimodal_model_pro st.header("Vertex AI Gemini API", divider="rainbow") text_model_pro, multimodal_model_pro = load_models() tab1, tab2, tab3, tab4 = st.tabs(["Story", "Marketing Campaign", "Image Playground", "Video Playground"]) with tab1: render_story_tab(text_model_pro) EOF -
Confira o conteúdo do arquivo
app.py:cat ~/gemini-app/app.py O app usa
streamlitpara criar algumas guias na UI. Nesta versão inicial do app, criamos a primeira guia, Story (História), usada para gerar histórias. Vamos criar as outras guias nas próximas tarefas do laboratório.Primeiro o app inicia o
SDK da Vertex AIe transmite os valores das variáveis de ambiente PROJECT_ID e REGION.Ele carrega os modelos
gemini-proegemini-pro-visionusando a classeGenerativeModel, que representa um modelo do Gemini. A classe inclui métodos para gerar conteúdo usando texto, imagens e vídeos.O app cria quatro guias na UI, chamadas Story (História), Marketing Campaign (Campanha de marketing), Image Playground (Playground de imagem) e Video Playground (Playground de vídeo).
Depois ele invoca a função
render_tab1()para criar a UI da guia Story.
Desenvolva tab1: Story
-
Para escrever o código que mostra a guia Story na UI do app, execute este comando:
cat > ~/gemini-app/app_tab1.py <<EOF import streamlit as st from vertexai.preview.generative_models import GenerativeModel from response_utils import * import logging # create the model prompt based on user input. def generate_prompt(): # Story character input character_name = st.text_input("Enter character name: \n\n",key="character_name",value="Mittens") character_type = st.text_input("What type of character is it? \n\n",key="character_type",value="Cat") character_persona = st.text_input("What personality does the character have? \n\n", key="character_persona",value="Mitten is a very friendly cat.") character_location = st.text_input("Where does the character live? \n\n",key="character_location",value="Andromeda Galaxy") # Story length and premise length_of_story = st.radio("Select the length of the story: \n\n",["Short","Long"],key="length_of_story",horizontal=True) story_premise = st.multiselect("What is the story premise? (can select multiple) \n\n",["Love","Adventure","Mystery","Horror","Comedy","Sci-Fi","Fantasy","Thriller"],key="story_premise",default=["Love","Adventure"]) creative_control = st.radio("Select the creativity level: \n\n",["Low","High"],key="creative_control",horizontal=True) if creative_control == "Low": temperature = 0.30 else: temperature = 0.95 prompt = f"""Write a {length_of_story} story based on the following premise: \n character_name: {character_name} \n character_type: {character_type} \n character_persona: {character_persona} \n character_location: {character_location} \n story_premise: {",".join(story_premise)} \n If the story is "short", then make sure to have 5 chapters or else if it is "long" then 10 chapters. Important point is that each chapter should be generated based on the premise given above. First start by giving the book introduction, chapter introductions and then each chapter. It should also have a proper ending. The book should have a prologue and an epilogue. """ return temperature, prompt # function to render the story tab, and call the model, and display the model prompt and response. def render_story_tab (text_model_pro: GenerativeModel): st.write("Using Gemini 1.0 Pro - Text only model") st.subheader("Generate a story") temperature, prompt = generate_prompt() config = { "temperature": temperature, "max_output_tokens": 2048, } generate_t2t = st.button("Generate my story", key="generate_t2t") if generate_t2t and prompt: # st.write(prompt) with st.spinner("Generating your story using Gemini..."): first_tab1, first_tab2 = st.tabs(["Story response", "Prompt"]) with first_tab1: response = get_gemini_pro_text_response(text_model_pro, prompt, generation_config=config) if response: st.write("Your story:") st.write(response) logging.info(response) with first_tab2: st.text(prompt) EOF -
Confira o conteúdo do arquivo
app_tab1.py:cat ~/gemini-app/app_tab1.py A função
render_story_tabinvoca outras funções para mostrar os campos de entrada de texto e outras opções, gerando os controles de UI da guia.A função
generate_promptgera o comando de texto que é transmitido à API Gemini. Para criar a string do comando, o app combina as informações do personagem (que o usuário digitou na UI da guia) e opções como o tamanho (curto ou longo), o nível de criatividade (baixo ou alto) e a premissa.A função também retorna o valor de
temperaturecom base no nível de criatividade selecionado e na história. O valor é transmitido ao modelo como o parâmetro de configuraçãotemperature, que controla a aleatoriedade das previsões. O parâmetro de configuraçãomax_output_tokensdetermina o número máximo de tokens de saída que serão gerados por mensagem.Para gerar a resposta do modelo, um botão é criado na UI da guia. Quando o usuário clica no botão, o app invoca a função
get_gemini_pro_text_response, que vamos programar na próxima etapa do laboratório.
Desenvolva response_utils
O arquivo response_utils.py contém funções para gerar as respostas do modelo.
-
Para criar o código para gerar a resposta de texto do modelo, execute este comando:
cat > ~/gemini-app/response_utils.py <<EOF from vertexai.preview.generative_models import (Content, GenerationConfig, GenerativeModel, GenerationResponse, Image, HarmCategory, HarmBlockThreshold, Part) def get_gemini_pro_text_response( model: GenerativeModel, prompt: str, generation_config: GenerationConfig, stream=True): safety_settings={ HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE, } responses = model.generate_content(prompt, generation_config = generation_config, safety_settings = safety_settings, stream=True) final_response = [] for response in responses: try: final_response.append(response.text) except IndexError: final_response.append("") continue return " ".join(final_response) EOF -
Confira o conteúdo do arquivo
response_utils.py:cat ~/gemini-app/response_utils.py A função
get_gemini_pro_text_responseusa a classeGenerativeModele algumas outras classes do pacotevertexai.preview.generative_modelsdo SDK da Vertex AI para Python. No métodogenerate_contentda classe, uma resposta é gerada usando o comando de texto transmitido ao método.Também transmitimos ao método o objeto
safety_settings, para bloquear conteúdo inseguro e controlar a resposta do modelo. No exemplo de código do laboratório, os valores da configuração de segurança instruem o modelo a sempre retornar conteúdo, seja qual for a possibilidade de que o conteúdo seja inseguro. Se seu aplicativo precisa de uma configuração mais restrita, avalie o conteúdo gerado e ajuste as configurações. Saiba mais na documentação sobre as configurações de segurança.
Tarefa 4: execute e teste o app localmente
Nesta tarefa, você vai executar o app localmente com streamlit e testar a funcionalidade dele.
Execute o aplicativo
-
Para executar o app localmente, execute este comando no Cloud Shell:
streamlit run app.py \ --browser.serverAddress=localhost \ --server.enableCORS=false \ --server.enableXsrfProtection=false \ --server.port 8080 O app será iniciado e vai mostrar um URL de acesso.
-
Para abrir a página inicial do app no navegador, clique em Visualização na Web na barra de menu do Cloud Shell, depois clique em Visualizar na porta 8080.
Outra opção para acessar o app é copiar e colar o URL em outra guia do navegador.
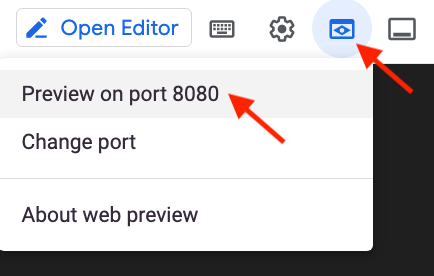
Teste o app: guia Story
Digite a entrada para gerar uma história, confira o comando e confira a resposta gerada pelo modelo Gemini 1.0 Pro.
-
Para gerar uma história, na guia Story, mantenha as configurações padrão e clique em Generate my story (Gerar minha história).
-
Aguarde a geração da resposta e clique na guia Story response.
-
Para conferir o comando usado para gerar a resposta, clique na guia Prompt (Comando).
-
Na janela do Cloud Shell, digite CTRL+C para fechar o app e voltar ao prompt de comando.
Para verificar o objetivo, clique em Verificar meu progresso.
Tarefa 5: gere uma campanha de marketing
Nesta tarefa, você vai usar o modelo de texto do Gemini 1.0 Pro para gerar uma campanha de marketing para uma empresa. Também vai desenvolver o código para gerar a segunda guia do app.
Desenvolva tab2: Marketing Campaign
-
Para criar o código que mostra a guia Marketing Campaign na UI do app, execute este comando:
cat > ~/gemini-app/app_tab2.py <<EOF import streamlit as st from vertexai.preview.generative_models import GenerativeModel from response_utils import * import logging # create the model prompt based on user input. def generate_prompt(): st.write("Using Gemini 1.0 Pro - Text only model") st.subheader("Generate your marketing campaign") product_name = st.text_input("What is the name of the product? \n\n",key="product_name",value="ZomZoo") product_category = st.radio("Select your product category: \n\n",["Clothing","Electronics","Food","Health & Beauty","Home & Garden"],key="product_category",horizontal=True) st.write("Select your target audience: ") target_audience_age = st.radio("Target age: \n\n",["18-24","25-34","35-44","45-54","55-64","65+"],key="target_audience_age",horizontal=True) # target_audience_gender = st.radio("Target gender: \n\n",["male","female","trans","non-binary","others"],key="target_audience_gender",horizontal=True) target_audience_location = st.radio("Target location: \n\n",["Urban", "Suburban","Rural"],key="target_audience_location",horizontal=True) st.write("Select your marketing campaign goal: ") campaign_goal = st.multiselect("Select your marketing campaign goal: \n\n",["Increase brand awareness","Generate leads","Drive sales","Improve brand sentiment"],key="campaign_goal",default=["Increase brand awareness","Generate leads"]) if campaign_goal is None: campaign_goal = ["Increase brand awareness","Generate leads"] brand_voice = st.radio("Select your brand voice: \n\n",["Formal","Informal","Serious","Humorous"],key="brand_voice",horizontal=True) estimated_budget = st.radio("Select your estimated budget ($): \n\n",["1,000-5,000","5,000-10,000","10,000-20,000","20,000+"],key="estimated_budget",horizontal=True) prompt = f"""Generate a marketing campaign for {product_name}, a {product_category} designed for the age group: {target_audience_age}. The target location is this: {target_audience_location}. Aim to primarily achieve {campaign_goal}. Emphasize the product's unique selling proposition while using a {brand_voice} tone of voice. Allocate the total budget of {estimated_budget}. With these inputs, make sure to follow following guidelines and generate the marketing campaign with proper headlines: \n - Briefly describe the company, its values, mission, and target audience. - Highlight any relevant brand guidelines or messaging frameworks. - Provide a concise overview of the campaign's objectives and goals. - Briefly explain the product or service being promoted. - Define your ideal customer with clear demographics, psychographics, and behavioral insights. - Understand their needs, wants, motivations, and pain points. - Clearly articulate the desired outcomes for the campaign. - Use SMART goals (Specific, Measurable, Achievable, Relevant, and Time-bound) for clarity. - Define key performance indicators (KPIs) to track progress and success. - Specify the primary and secondary goals of the campaign. - Examples include brand awareness, lead generation, sales growth, or website traffic. - Clearly define what differentiates your product or service from competitors. - Emphasize the value proposition and unique benefits offered to the target audience. - Define the desired tone and personality of the campaign messaging. - Identify the specific channels you will use to reach your target audience. - Clearly state the desired action you want the audience to take. - Make it specific, compelling, and easy to understand. - Identify and analyze your key competitors in the market. - Understand their strengths and weaknesses, target audience, and marketing strategies. - Develop a differentiation strategy to stand out from the competition. - Define how you will track the success of the campaign. - Use relevant KPIs to measure performance and return on investment (ROI). Provide bullet points and headlines for the marketing campaign. Do not produce any empty lines. Be very succinct and to the point. """ return prompt # function to render the story tab, and call the model, and display the model prompt and response. def render_mktg_campaign_tab (text_model_pro: GenerativeModel): st.write("Using Gemini 1.0 Pro - Text only model") st.subheader("Generate a marketing campaign") prompt = generate_prompt() config = { "temperature": 0.8, "max_output_tokens": 2048, } generate_t2m = st.button("Generate campaign", key="generate_t2m") if generate_t2m and prompt: # st.write(prompt) with st.spinner("Generating a marketing campaign using Gemini..."): first_tab1, first_tab2 = st.tabs(["Campaign response", "Prompt"]) with first_tab1: response = get_gemini_pro_text_response(text_model_pro, prompt, generation_config=config) if response: st.write("Marketing campaign:") st.write(response) logging.info(response) with first_tab2: st.text(prompt) EOF
Modifique o ponto de entrada principal do app
-
Para adicionar tab2 ao app, execute este comando:
cat >> ~/gemini-app/app.py <<EOF from app_tab2 import render_mktg_campaign_tab with tab2: render_mktg_campaign_tab(text_model_pro) EOF
Teste o app: guia Marketing campaign
Digite a entrada para gerar uma campanha de marketing, confira o comando e confira a resposta gerada pelo modelo Gemini 1.0 Pro.
-
Para executar o app localmente, execute este comando no Cloud Shell:
streamlit run app.py \ --browser.serverAddress=localhost \ --server.enableCORS=false \ --server.enableXsrfProtection=false \ --server.port 8080 O app será iniciado e vai mostrar um URL de acesso.
-
Para abrir a página inicial do app no navegador, clique em Visualização na Web na barra de menu do Cloud Shell, depois clique em Visualizar na porta 8080.
-
Para gerar uma campanha de marketing, na guia Marketing campaign, mantenha as configurações padrão e clique em Generate campaign (Gerar campanha).
-
Aguarde a geração da resposta e clique na guia Campaign response (Resposta da campanha).
-
Para conferir o comando usado para gerar a resposta, clique na guia Prompt (Comando).
-
Repita as etapas acima e crie campanhas com outros valores para os parâmetros como categoria de produto, público-alvo, local e metas.
-
Na janela do Cloud Shell, digite CTRL+C para fechar o app e voltar ao prompt de comando.
Para verificar o objetivo, clique em Verificar meu progresso.
Tarefa 6: gere o playground de imagem
Nesta tarefa, você vai usar o modelo Gemini 1.0 Pro Vision para processar imagens e para gerar recomendações e informações com base nas imagens apresentadas ao modelo.
Desenvolva tab3: Image Playground
Nesta subtarefa, você vai implementar o código da guia Image Playground, além do código para interagir com o modelo e gerar recomendações com base em imagens.
-
Para criar o código que vai mostrar a guia Image Playground na UI do app, execute este comando:
cat > ~/gemini-app/app_tab3.py <<EOF import streamlit as st from vertexai.preview.generative_models import GenerativeModel, Part from response_utils import * import logging # render the Image Playground tab with multiple child tabs def render_image_playground_tab(multimodal_model_pro: GenerativeModel): st.write("Using Gemini 1.0 Pro Vision - Multimodal model") recommendations, screens, diagrams, equations = st.tabs(["Furniture recommendation", "Oven instructions", "ER diagrams", "Math reasoning"]) with recommendations: room_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/living_room.jpeg" chair_1_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair1.jpeg" chair_2_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair2.jpeg" chair_3_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair3.jpeg" chair_4_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/chair4.jpeg" room_image_url = "https://storage.googleapis.com/"+room_image_uri.split("gs://")[1] chair_1_image_url = "https://storage.googleapis.com/"+chair_1_image_uri.split("gs://")[1] chair_2_image_url = "https://storage.googleapis.com/"+chair_2_image_uri.split("gs://")[1] chair_3_image_url = "https://storage.googleapis.com/"+chair_3_image_uri.split("gs://")[1] chair_4_image_url = "https://storage.googleapis.com/"+chair_4_image_uri.split("gs://")[1] room_image = Part.from_uri(room_image_uri, mime_type="image/jpeg") chair_1_image = Part.from_uri(chair_1_image_uri,mime_type="image/jpeg") chair_2_image = Part.from_uri(chair_2_image_uri,mime_type="image/jpeg") chair_3_image = Part.from_uri(chair_3_image_uri,mime_type="image/jpeg") chair_4_image = Part.from_uri(chair_4_image_uri,mime_type="image/jpeg") st.image(room_image_url,width=350, caption="Image of a living room") st.image([chair_1_image_url,chair_2_image_url,chair_3_image_url,chair_4_image_url],width=200, caption=["Chair 1","Chair 2","Chair 3","Chair 4"]) st.write("Our expectation: Recommend a chair that would complement the given image of a living room.") prompt_list = ["Consider the following chairs:", "chair 1:", chair_1_image, "chair 2:", chair_2_image, "chair 3:", chair_3_image, "and", "chair 4:", chair_4_image, "\n" "For each chair, explain why it would be suitable or not suitable for the following room:", room_image, "Only recommend for the room provided and not other rooms. Provide your recommendation in a table format with chair name and reason as columns.", ] tab1, tab2 = st.tabs(["Response", "Prompt"]) generate_image_description = st.button("Generate recommendation", key="generate_image_description") with tab1: if generate_image_description and prompt_list: with st.spinner("Generating recommendation using Gemini..."): response = get_gemini_pro_vision_response(multimodal_model_pro, prompt_list) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.text(prompt_list) EOF -
Confira o conteúdo do arquivo
app_tab3.py:cat ~/gemini-app/app_tab3.py A função
render_image_playground_tabcria a UI para que o usuário do app interaja com o modelo Gemini 1.0 Pro Vision. Ela cria um conjunto de guias na UI: "Furniture recommendation" (Recomendação de móveis), "Oven instructions" (Instruções do forno), "ER diagrams" (Diagramas de ER), "Math reasoning" (Justificativa de matemática). Você vai programar o código das outras guias nas próximas tarefas do laboratório.Na guia
Furniture recommendation(Recomendação de móveis), a imagem de uma sala de estar é usada para compreensão visual. Com outras imagens de cadeiras, o código invoca o endpoint de API multimodal do Gemini 1.0 Pro Vision para gerar uma recomendação de uma cadeira que combine com a sala de estar.O código usa mais de um comando de texto e as imagens da sala de estar e das cadeiras, depois transmite tudo isso ao modelo em uma lista. A classe
Parté usada para extrair a imagem do URI de conteúdo multiparte, hospedado em um bucket do Cloud Storage. O comando também determina que a saída do modelo deve ser no formato tabular e deve incluir a justificativa da recomendação.

Atualize response_utils
O arquivo response_utils.py contém funções para gerar as respostas do modelo.
-
Adicione ao arquivo o código que vai gerar a resposta multimodal do modelo:
cat >> ~/gemini-app/response_utils.py <<EOF def get_gemini_pro_vision_response(model: GenerativeModel, prompt_list, generation_config={}, stream=True): generation_config = {'temperature': 0.1, 'max_output_tokens': 2048 } responses = model.generate_content(prompt_list, generation_config = generation_config, stream=True) final_response = [] for response in responses: try: final_response.append(response.text) except IndexError: final_response.append("") continue return(" ".join(final_response)) EOF
Modifique o ponto de entrada principal do app
-
Para adicionar tab3 ao app, execute este comando:
cat >> ~/gemini-app/app.py <<EOF from app_tab3 import render_image_playground_tab with tab3: render_image_playground_tab(multimodal_model_pro) EOF
Teste o app: guia Image Playground
-
Execute o app usando o comando das etapas anteriores do laboratório.
-
Para abrir a página inicial do app no navegador, clique em Visualização na Web na barra de menu do Cloud Shell, depois clique em Visualizar na porta 8080.
-
Clique em Image Playground e em Furniture recommendation.
A guia mostra as imagens da sala de estar e de cadeiras.
-
Clique em Generate recommendation (Gerar recomendação).
Caso este erro apareça: FailedPrecondition: 400 We are preparing necessary resources. Please wait few minutes and retry., aguarde alguns minutos e clique de novo em Generate recommendation. -
Confira a resposta do modelo Gemini 1.0 Pro Vision.
A resposta está em uma tabela, como foi pedido no comando. O modelo recomenda duas das quatro cadeiras e dá a justificativa da recomendação.
-
Na janela do Cloud Shell, digite CTRL+C para fechar o app e voltar ao prompt de comando.
Para verificar o objetivo, clique em Verificar meu progresso.
Tarefa 7: analise o layout de imagem
Nesta tarefa, você vai usar o modelo Gemini 1.0 Pro Vision para extrair informações de uma imagem depois de analisar o layout de ícones e texto.
Atualize a guia "Image Playground": instruções de forno
Com a capacidade de extrair informações dos elementos visuais nas telas, o Gemini consegue analisar capturas de tela, ícones e layouts para entender completamente a imagem exibida. Nesta tarefa, você vai mostrar ao modelo a imagem do painel de controle de um forno doméstico, depois vai pedir que ele gere instruções para determinada função.
-
Para implementar o código da guia Oven instructions na guia Image Playground da UI do app, execute este comando:
cat >> ~/gemini-app/app_tab3.py <<EOF with screens: oven_screen_uri = "gs://cloud-training/OCBL447/gemini-app/images/oven.jpg" oven_screen_url = "https://storage.googleapis.com/"+oven_screen_uri.split("gs://")[1] oven_screen_img = Part.from_uri(oven_screen_uri, mime_type="image/jpeg") st.image(oven_screen_url, width=350, caption="Image of an oven control panel") st.write("Provide instructions for resetting the clock on this appliance in English") prompt = """How can I reset the clock on this appliance? Provide the instructions in English. If instructions include buttons, also explain where those buttons are physically located. """ tab1, tab2 = st.tabs(["Response", "Prompt"]) generate_instructions_description = st.button("Generate instructions", key="generate_instructions_description") with tab1: if generate_instructions_description and prompt: with st.spinner("Generating instructions using Gemini..."): response = get_gemini_pro_vision_response(multimodal_model_pro, [oven_screen_img, prompt]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.text(prompt+"\n"+"input_image") EOF O código acima vai criar a UI da guia Oven instructions. Usamos a imagem do painel de controle de um forno doméstico e um comando para que o modelo gere as instruções de uma função disponível no painel (neste caso, zerar o relógio).

Teste o app: "Image Playground", guia "Oven instructions"
-
Execute o app usando o comando das etapas anteriores do laboratório.
-
Para abrir a página inicial do app no navegador, clique em Visualização na Web na barra de menu do Cloud Shell, depois clique em Visualizar na porta 8080.
-
Clique em Image Playground e em Oven instructions.
A guia vai mostrar a imagem do painel de controle de um forno.
-
Clique em Generate instructions (Gerar instruções).
-
Confira a resposta do modelo Gemini 1.0 Pro Vision.
A resposta contém as instruções para zerar o relógio no painel de controle do forno. Ela também indica como localizar o botão no painel, o que demonstra a capacidade do modelo de analisar o layout do painel na imagem.
-
Na janela do Cloud Shell, digite CTRL+C para fechar o app e voltar ao prompt de comando.
Para verificar o objetivo, clique em Verificar meu progresso.
Tarefa 8: analise diagramas de ER
Com os recursos multimodais, o Gemini consegue entender diagramas e fazer ações práticas como gerar documentos ou código. Nesta tarefa, você vai usar o modelo Gemini 1.0 Pro Vision para analisar um diagrama de Relações de Entidades (ER, na sigla em inglês) e gerar uma documentação sobre as entidades e as relações do diagrama.
Atualize a guia "Image Playground": diagrama de ER
Nesta tarefa, você vai mostrar ao modelo uma imagem que contém um diagrama de ER, depois vai pedir ao modelo que gere uma documentação.
-
Para implementar o código da guia ER diagrams da guia Image Playground na UI do app, execute este comando:
cat >> ~/gemini-app/app_tab3.py <<EOF with diagrams: er_diag_uri = "gs://cloud-training/OCBL447/gemini-app/images/er.png" er_diag_url = "https://storage.googleapis.com/"+er_diag_uri.split("gs://")[1] er_diag_img = Part.from_uri(er_diag_uri,mime_type="image/png") st.image(er_diag_url, width=350, caption="Image of an ER diagram") st.write("Document the entities and relationships in this ER diagram.") prompt = """Document the entities and relationships in this ER diagram.""" tab1, tab2 = st.tabs(["Response", "Prompt"]) er_diag_img_description = st.button("Generate documentation", key="er_diag_img_description") with tab1: if er_diag_img_description and prompt: with st.spinner("Generating..."): response = get_gemini_pro_vision_response(multimodal_model_pro,[er_diag_img,prompt]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.text(prompt+"\n"+"input_image") EOF O código acima cria a UI da guia ER diagrams. Um texto e a imagem de um diagrama de ER são usados para pedir ao modelo que gere uma documentação sobre as entidades e as relações do diagrama.
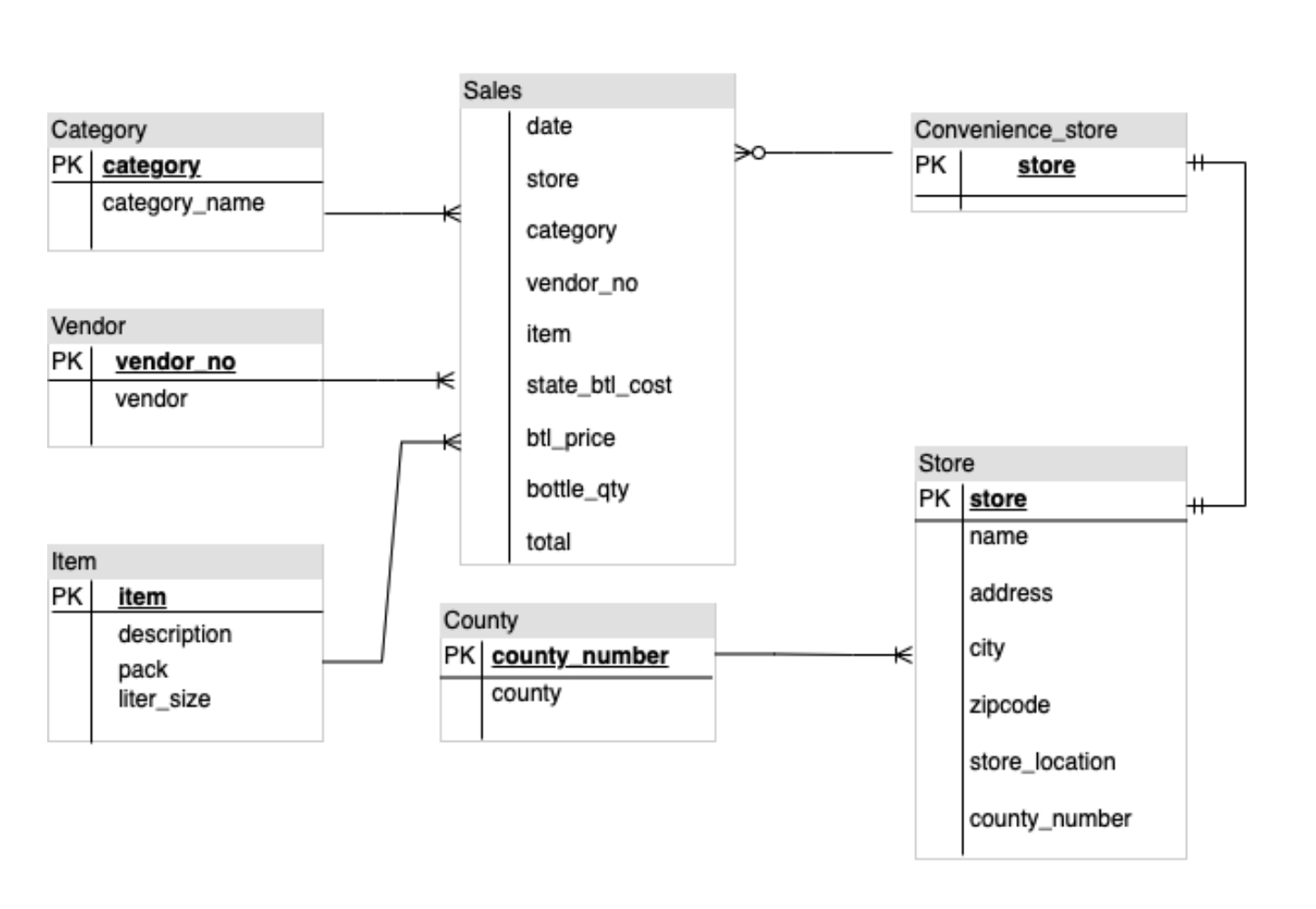
Teste o app: "Image Playground", guia "ER diagrams"
-
Execute o app usando o comando das etapas anteriores do laboratório.
-
Para abrir a página inicial do app no navegador, clique em Visualização na Web na barra de menu do Cloud Shell, depois clique em Visualizar na porta 8080.
-
Clique em Image Playground e em ER diagrams.
A guia vai mostrar a imagem do diagrama de ER.
-
Clique em Generate documentation (Gerar documentação).
-
Confira a resposta do modelo Gemini 1.0 Pro Vision.
A resposta contém a lista de entidades e as relações entre elas, conforme aparecem no diagrama.
-
Na janela do Cloud Shell, digite CTRL+C para fechar o app e voltar ao prompt de comando.
Para verificar o objetivo, clique em Verificar meu progresso.
Tarefa 9: gere a justificativa de matemática
O Gemini 1.0 Pro Vision também reconhece fórmulas e equações matemáticas e pode extrair informações delas. O recurso é útil principalmente para gerar explicações em problemas de matemática.
Atualize a guia "Image Playground": justificativa de matemática
Nesta tarefa, você vai usar o modelo Gemini 1.0 Pro Vision para extrair uma fórmula matemática de uma imagem e interpretar a fórmula.
-
Para implementar o código da guia Math reasoning (Justificativa de matemática) na guia Image Playground da UI do app, execute este comando:
cat >> ~/gemini-app/app_tab3.py <<EOF with equations: math_image_uri = "gs://cloud-training/OCBL447/gemini-app/images/math_eqn.jpg" math_image_url = "https://storage.googleapis.com/"+math_image_uri.split("gs://")[1] math_image_img = Part.from_uri(math_image_uri,mime_type="image/jpeg") st.image(math_image_url,width=350, caption="Image of a math equation") st.markdown(f""" Ask questions about the math equation as follows: - Extract the formula. - What is the symbol right before Pi? What does it mean? - Is this a famous formula? Does it have a name? """) prompt = """Follow the instructions. Surround math expressions with $. Use a table with a row for each instruction and its result. INSTRUCTIONS: - Extract the formula. - What is the symbol right before Pi? What does it mean? - Is this a famous formula? Does it have a name? """ tab1, tab2 = st.tabs(["Response", "Prompt"]) math_image_description = st.button("Generate answers", key="math_image_description") with tab1: if math_image_description and prompt: with st.spinner("Generating answers for formula using Gemini..."): response = get_gemini_pro_vision_response(multimodal_model_pro, [math_image_img, prompt]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.text(prompt) EOF O código acima cria a UI da guia Math reasoning. Um texto e a imagem de uma equação matemática são usados para pedir ao modelo que gere respostas e identifique outras características da equação.

Teste o app: "Image Playground", guia "Math reasoning"
-
Execute o app usando o comando das etapas anteriores do laboratório.
-
Para abrir a página inicial do app no navegador, clique em Visualização na Web na barra de menu do Cloud Shell, depois clique em Visualizar na porta 8080.
-
Clique em Image Playground e em Math reasoning.
A guia mostra a imagem da equação matemática.
-
Clique em Generate answers (Gerar respostas).
-
Confira a resposta do modelo Gemini 1.0 Pro Vision.
O modelo mostra as respostas às perguntas feitas no comando.
-
Na janela do Cloud Shell, digite CTRL+C para fechar o app e voltar ao prompt de comando.
Para verificar o objetivo, clique em Verificar meu progresso.
Tarefa 10: gere o Video Playground
Nesta tarefa, você vai usar o modelo Gemini 1.0 Pro Vision para gerar tags e informações com base nos vídeos apresentados.
Desenvolva tab4: Video Playground
O modelo Gemini 1.0 Pro Vision também pode descrever o que está acontecendo em um vídeo. Nesta subtarefa, você vai implementar o código da guia Video Playground (Playground de vídeos) e o código para pedir a descrição de um vídeo ao modelo.
-
Para criar o código que mostra a guia Video Playground na UI do app, execute este comando:
cat > ~/gemini-app/app_tab4.py <<EOF import streamlit as st from vertexai.preview.generative_models import GenerativeModel, Part from response_utils import * import logging # render the Video Playground tab with multiple child tabs def render_video_playground_tab(multimodal_model_pro: GenerativeModel): st.write("Using Gemini 1.0 Pro Vision - Multimodal model") video_desc, video_tags, video_highlights, video_geoloc = st.tabs(["Video description", "Video tags", "Video highlights", "Video geolocation"]) with video_desc: video_desc_uri = "gs://cloud-training/OCBL447/gemini-app/videos/mediterraneansea.mp4" video_desc_url = "https://storage.googleapis.com/"+video_desc_uri.split("gs://")[1] video_desc_vid = Part.from_uri(video_desc_uri, mime_type="video/mp4") st.video(video_desc_url) st.write("Generate a description of the video.") prompt = """Describe what is happening in the video and answer the following questions: \n - What am I looking at? - Where should I go to see it? - What are other top 5 places in the world that look like this? """ tab1, tab2 = st.tabs(["Response", "Prompt"]) video_desc_description = st.button("Generate video description", key="video_desc_description") with tab1: if video_desc_description and prompt: with st.spinner("Generating video description"): response = get_gemini_pro_vision_response(multimodal_model_pro, [prompt, video_desc_vid]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.write(prompt,"\n","{video_data}") EOF -
Confira o conteúdo do arquivo
app_tab4.py:cat ~/gemini-app/app_tab4.py A função
render_video_playground_tabcria a UI para que o usuário do app interaja com o modelo Gemini 1.0 Pro Vision. Ele cria um conjunto de guias na UI: "Video description" (Descrição do vídeo), "Video tags" (Tags do vídeo), "Video highlights" (Destaques do vídeo), "Video geolocation" (Geolocalização do vídeo). Você vai programar o código das outras guias nas próximas tarefas do laboratório.Na guia
Video description(Descrição do vídeo), um comando é usado com o vídeo para gerar uma descrição das imagens e para identificar locais semelhantes ao local do vídeo.
Modifique o ponto de entrada principal do app
-
Para adicionar tab4 ao app, execute este comando:
cat >> ~/gemini-app/app.py <<EOF from app_tab4 import render_video_playground_tab with tab4: render_video_playground_tab(multimodal_model_pro) EOF
Teste o app: guia "Video Playground"
-
Execute o app usando o comando das etapas anteriores do laboratório.
-
Para abrir a página inicial do app no navegador, clique em Visualização na Web na barra de menu do Cloud Shell, depois clique em Visualizar na porta 8080.
-
Clique em Video Playground e em Video description.
-
A guia mostra o vídeo de um lugar. Clique para reproduzir o vídeo.
-
Clique em Generate video description (Gerar descrição do vídeo).
-
Confira a resposta do modelo Gemini 1.0 Pro Vision.
A resposta contém uma descrição do local e uma lista de cinco outros locais semelhantes.
-
Na janela do Cloud Shell, digite CTRL+C para fechar o app e voltar ao prompt de comando.
Para verificar o objetivo, clique em Verificar meu progresso.
Tarefa 11: gere tags de vídeo
Nesta tarefa, você vai usar o modelo Gemini 1.0 Pro Vision para gerar tags com base em um vídeo.
Atualize a guia "Video Playground": tags de vídeo
-
Para implementar o código da guia Video tags na guia Video Playground da UI do app, execute este código:
cat >> ~/gemini-app/app_tab4.py <<EOF with video_tags: video_tags_uri = "gs://cloud-training/OCBL447/gemini-app/videos/photography.mp4" video_tags_url = "https://storage.googleapis.com/"+video_tags_uri.split("gs://")[1] video_tags_vid = Part.from_uri(video_tags_uri, mime_type="video/mp4") st.video(video_tags_url) st.write("Generate tags for the video.") prompt = """Answer the following questions using the video only: 1. What is in the video? 2. What objects are in the video? 3. What is the action in the video? 4. Provide 5 best tags for this video? Write the answer in table format with the questions and answers in columns. """ tab1, tab2 = st.tabs(["Response", "Prompt"]) video_tags_desc = st.button("Generate video tags", key="video_tags_desc") with tab1: if video_tags_desc and prompt: with st.spinner("Generating video tags"): response = get_gemini_pro_vision_response(multimodal_model_pro, [prompt, video_tags_vid]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.write(prompt,"\n","{video_data}") EOF O código acima cria a UI da guia Video tags. Usando um vídeo e um texto, pedimos ao modelo que gere tags e responda a perguntas sobre cenas no vídeo.
Teste o app: guia "Video Playground", guia "Video tags"
-
Execute o app usando o comando das etapas anteriores do laboratório.
-
Para abrir a página inicial do app no navegador, clique em Visualização na Web na barra de menu do Cloud Shell, depois clique em Visualizar na porta 8080.
-
Clique em Video Playground e em Video tags.
-
A guia mostra o vídeo que será usado no comando do modelo. Clique para reproduzir o vídeo.
-
Clique em Generate video tags (Gerar tags de vídeo).
-
Confira a resposta do modelo Gemini 1.0 Pro Vision.
O modelo mostra as respostas às perguntas feitas no comando. As perguntas e as respostas são mostradas em uma tabela e incluem as cinco tags solicitadas.
-
Na janela do Cloud Shell, digite CTRL+C para fechar o app e voltar ao prompt de comando.
Para verificar o objetivo, clique em Verificar meu progresso.
Tarefa 12: gere destaques do vídeo
Nesta tarefa, você vai usar o modelo Gemini 1.0 Pro Vision para gerar os destaques de um vídeo, incluindo informações sobre os objetos, as pessoas e o contexto que aparecem nas imagens.
Atualize a guia "Image Playground": destaques do vídeo
-
Para implementar o código da guia Video highlights (Destaques do vídeo) na guia Video Playground da UI do app, execute este comando:
cat >> ~/gemini-app/app_tab4.py <<EOF with video_highlights: video_highlights_uri = "gs://cloud-training/OCBL447/gemini-app/videos/pixel8.mp4" video_highlights_url = "https://storage.googleapis.com/"+video_highlights_uri.split("gs://")[1] video_highlights_vid = Part.from_uri(video_highlights_uri, mime_type="video/mp4") st.video(video_highlights_url) st.write("Generate highlights for the video.") prompt = """Answer the following questions using the video only: What is the profession of the girl in this video? Which features of the phone are highlighted here? Summarize the video in one paragraph. Write these questions and their answers in table format. """ tab1, tab2 = st.tabs(["Response", "Prompt"]) video_highlights_description = st.button("Generate video highlights", key="video_highlights_description") with tab1: if video_highlights_description and prompt: with st.spinner("Generating video highlights"): response = get_gemini_pro_vision_response(multimodal_model_pro, [prompt, video_highlights_vid]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.write(prompt,"\n","{video_data}") EOF O código acima cria a UI da guia Video highlights. Usando um vídeo e um texto, pedimos ao modelo que gere os destaques do vídeo.
Teste o app: guia "Video Playground", guia "Video highlights"
-
Execute o app usando o comando das etapas anteriores do laboratório.
-
Para abrir a página inicial do app no navegador, clique em Visualização na Web na barra de menu do Cloud Shell, depois clique em Visualizar na porta 8080.
-
Clique em Video Playground e em Video highlights.
-
A guia mostra o vídeo que será usado no comando do modelo. Clique para reproduzir o vídeo.
-
Clique em Generate video highlights (Gerar destaques do vídeo).
-
Confira a resposta do modelo Gemini 1.0 Pro Vision.
O modelo mostra as respostas às perguntas feitas no comando. As perguntas e as respostas são mostradas em uma tabela e incluem algumas características do vídeo, como a profissão da garota e os recursos do celular usado. A resposta também contém uma descrição resumida das cenas do vídeo.
-
Na janela do Cloud Shell, digite CTRL+C para fechar o app e voltar ao prompt de comando.
Para verificar o objetivo, clique em Verificar meu progresso.
Tarefa 13: gere o local do vídeo
Nesta tarefa, você vai usar o modelo Gemini 1.0 Pro Vision para descobrir o local em que o vídeo se passa.
Atualize a guia "Image Playground": geolocalização do vídeo
-
Para implementar o código da guia Video geolocation (Geolocalização do vídeo) na guia Video Playground da UI do app, execute este comando:
cat >> ~/gemini-app/app_tab4.py <<EOF with video_geoloc: video_geolocation_uri = "gs://cloud-training/OCBL447/gemini-app/videos/bus.mp4" video_geolocation_url = "https://storage.googleapis.com/"+video_geolocation_uri.split("gs://")[1] video_geolocation_vid = Part.from_uri(video_geolocation_uri, mime_type="video/mp4") st.video(video_geolocation_url) st.markdown("""Answer the following questions from the video: - What is this video about? - How do you know which city it is? - What street is this? - What is the nearest intersection? """) prompt = """Answer the following questions using the video only: What is this video about? How do you know which city it is? What street is this? What is the nearest intersection? Answer the following questions using a table format with the questions and answers as columns. """ tab1, tab2 = st.tabs(["Response", "Prompt"]) video_geolocation_description = st.button("Generate", key="video_geolocation_description") with tab1: if video_geolocation_description and prompt: with st.spinner("Generating location information"): response = get_gemini_pro_vision_response(multimodal_model_pro, [prompt, video_geolocation_vid]) st.markdown(response) logging.info(response) with tab2: st.write("Prompt used:") st.write(prompt,"\n","{video_data}") EOF O código acima cria a UI da guia Video geolocation. Usando um vídeo e texto, pedimos ao modelo que responda a perguntas sobre o vídeo, incluindo a localização das entidades que aparecem nas imagens.
Teste o app: guia "Video Playground", guia "Video geolocation"
-
Execute o app usando o comando das etapas anteriores do laboratório.
-
Para abrir a página inicial do app no navegador, clique em Visualização na Web na barra de menu do Cloud Shell, depois clique em Visualizar na porta 8080.
-
Clique em Video Playground e em Video geolocation.
-
A guia mostra o vídeo que será usado no comando do modelo. Clique para reproduzir o vídeo.
-
Clique em Generate (Gerar).
-
Confira a resposta do modelo Gemini 1.0 Pro Vision.
O modelo mostra as respostas às perguntas feitas no comando. As perguntas e as respostas são mostradas em uma tabela e incluem as informações de localização pedidas.
-
Na janela do Cloud Shell, digite CTRL+C para fechar o app e voltar ao prompt de comando.
Para verificar o objetivo, clique em Verificar meu progresso.
Tarefa 14: implante o app no Cloud Run
Agora que fez os testes locais, você pode implantar o app no Cloud Run do Google Cloud para que outras pessoas o usem. O Cloud Run é uma plataforma de computação gerenciada para executar contêineres diretamente na infraestrutura escalonável do Google.
Configure o ambiente
-
Abra o diretório
app:cd ~/gemini-app -
Verifique se as variáveis de ambiente PROJECT_ID e REGION foram definidas:
echo "PROJECT_ID=${PROJECT_ID}" echo "REGION=${REGION}" -
Se elas não foram definidas, execute o comando para definir as variáveis:
PROJECT_ID=$(gcloud config get-value project) REGION={{{project_0.default_region|set at lab start}}} echo "PROJECT_ID=${PROJECT_ID}" echo "REGION=${REGION}" -
Defina variáveis de ambiente com o serviço e o repositório de artefatos:
SERVICE_NAME='gemini-app-playground' # Nome do seu serviço do Cloud Run. AR_REPO='gemini-app-repo' # Nome do repositório do Artifact Registry que armazena a imagem de contêiner do seu aplicativo. echo "SERVICE_NAME=${SERVICE_NAME}" echo "AR_REPO=${AR_REPO}"
Crie o repositório do Docker
-
Para criar o repositório no Artifact Registry, execute o comando:
gcloud artifacts repositories create "$AR_REPO" --location="$REGION" --repository-format=Docker O Artifact Registry, um serviço do Google Cloud, é o ponto central para você armazenar e gerenciar pacotes de software e imagens de contêiner do Docker. -
Configure a autenticação do repositório:
gcloud auth configure-docker "$REGION-docker.pkg.dev"
Crie a imagem de contêiner
Vamos usar um Dockerfile para criar a imagem de contêiner do aplicativo. O Dockerfile é um documento de texto com todos os comandos que um usuário executaria na linha de comando para montar a imagem de contêiner. Ele é usado com o Docker, uma plataforma de contêiner que compila e executa imagens de contêiner.
-
Para criar um
Dockerfile, execute o comando:cat > ~/gemini-app/Dockerfile <<EOF FROM python:3.8 EXPOSE 8080 WORKDIR /app COPY . ./ RUN pip install -r requirements.txt ENTRYPOINT ["streamlit", "run", "app.py", "--server.port=8080", "--server.address=0.0.0.0"] EOF -
Para criar a imagem de contêiner do app, execute o comando:
gcloud builds submit --tag "$REGION-docker.pkg.dev/$PROJECT_ID/$AR_REPO/$SERVICE_NAME" O comando gcloud builds submit envia uma build usando o Cloud Build. Quando a flag tag é usada, o Cloud Build usa um Dockerfile e compila uma imagem de contêiner usando os arquivos de aplicativo do diretório de origem. O Cloud Build é um serviço que executa builds no Google Cloud com base nas especificações do usuário. Ele gera artefatos com contêineres do Docker e arquivos Java.
Prossiga para a próxima etapa quando o comando terminar.
Implante e teste o app no Cloud Run
A tarefa final é implantar o serviço no Cloud Run com a imagem que foi criada e enviada ao repositório do Artifact Registry.
-
Para implantar o app no Cloud Run, execute o comando:
gcloud run deploy "$SERVICE_NAME" \ --port=8080 \ --image="$REGION-docker.pkg.dev/$PROJECT_ID/$AR_REPO/$SERVICE_NAME" \ --allow-unauthenticated \ --region=$REGION \ --platform=managed \ --project=$PROJECT_ID \ --set-env-vars=PROJECT_ID=$PROJECT_ID,REGION=$REGION -
Depois da implantação, um URL do serviço é gerado na saída do comando anterior. Para testar o app no Cloud Run, acesse esse URL em uma nova guia ou janela do navegador.
-
Escolha uma funcionalidade do app para testar. O app vai pedir para a API Gemini da Vertex AI gerar e exibir as respostas.
Para verificar o objetivo, clique em Verificar meu progresso.
Finalize o laboratório
Após terminar seu laboratório, clique em End Lab. O Qwiklabs removerá os recursos usados e limpará a conta para você.
Você poderá avaliar sua experiência neste laboratório. Basta selecionar o número de estrelas, digitar um comentário e clicar em Submit.
O número de estrelas indica o seguinte:
- 1 estrela = muito insatisfeito
- 2 estrelas = insatisfeito
- 3 estrelas = neutro
- 4 estrelas = satisfeito
- 5 estrelas = muito satisfeito
Feche a caixa de diálogo se não quiser enviar feedback.
Para enviar seu feedback, fazer sugestões ou correções, use a guia Support.
Parabéns!
Neste laboratório, você fez o seguinte:
- Desenvolveu um app Python com o framework Streamlit.
- Instalou o SDK da Vertex AI para Python.
- Desenvolveu código para interagir com o modelo Gemini 1.0 Pro (gemini-pro) usando a API Gemini da Vertex AI.
- Usou comandos de texto com o modelo para gerar uma história e uma campanha de marketing.
- Desenvolver código para interagir com o modelo Gemini 1.0 Pro Vision (gemini-pro-vision) usando a API Gemini da Vertex AI.
- Usou o modelo e textos para processar imagens e vídeos e extrair informações deles.
- Implantou e testou o app no Cloud Run.
Próximas etapas/Saiba mais
- Vertex AI
- Gemini
- Referência dos modelos generativos do SDK da Vertex AI
- Artifact Registry
- Cloud Build
- Cloud Run
Copyright 2023 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de empresas e produtos podem ser marcas registradas das empresas a que estão associados.

