Prüfpunkte
Create BigQuery Python notebook and connect to runtime
/ 10
Create the cloud resource connection and grant IAM role
/ 10
Review images, dataset, and grant IAM role to service account
/ 10
Create the dataset and customer reviews table in BigQuery
/ 30
Create the Gemini Pro model in BigQuery
/ 10
Prompt Gemini to analyze customer reviews for keywords and sentiment
/ 20
Respond to customer reviews
/ 10
Kundenrezensionen mit Gemini und Python-Notebooks analysieren
- GSP1249
- Übersicht
- Ziele
- Einrichtung und Anforderungen
- Aufgabe 1: Python-Notebook in BigQuery erstellen und mit der Laufzeit verbinden
- Aufgabe 2: Cloud-Ressourcenverbindung erstellen und IAM-Rolle gewähren
- Aufgabe 3: Audiodateien und Dataset prüfen und dem Dienstkonto IAM-Rolle gewähren
- Aufgabe 4: Dataset und Tabelle mit Kundenrezensionen in BigQuery erstellen
- Aufgabe 5: Modell „Gemini Pro“ in BigQuery erstellen
- Aufgabe 6: Prompts an Gemini zur Analyse von Kundenrezensionen in Bezug auf Keywords und Sentiment senden
- Aufgabe 7: Auf Kundenrezensionen reagieren
- Das wars! Sie haben das Lab erfolgreich abgeschlossen.
GSP1249

Übersicht
In diesem Lab erfahren Sie, wie Sie BigQuery Machine Learning mit Remote-Modellen (Gemini Pro) nutzen, um Keywords zu extrahieren und das Kundensentiment in Kundenrezensionen zu bewerten.
BigQuery ist eine vollständig verwaltete, KI-fähige Data-Analytics-Plattform, mit der Sie die Wertschöpfung aus Daten maximieren können. Sie ist als Multi-Engine-, Multi-Format- und Multi-Cloud-Plattform konzipiert. Eines der zentralen Features ist BigQuery Machine Learning. Damit können Sie ML-Modelle (maschinelles Lernen) mithilfe von SQL-Abfragen oder Colab Enterprise-Notebooks erstellen und ausführen.
Gemini ist eine Reihe von auf generativer KI basierenden Modellen, die von Google DeepMind entwickelt wurden und auf multimodale Anwendungsfälle ausgelegt sind. Mit der Gemini API erhalten Sie Zugriff auf Modelle von Gemini Pro, Gemini Pro Vision und Gemini Flash.
Am Ende dieses Labs erstellen Sie eine Python-basierte Anwendung für den Kundenservice in einem Colab Enterprise-Notebook in BigQuery. Dabei verwenden Sie das Gemini Flash-Modell, um auf audiobasierte Kundenrezensionen zu reagieren.
Ziele
Aufgaben in diesem Lab:
- Python-Notebook in BigQuery mit Colab Enterprise erstellen
- Cloud-Ressourcenverbindung in BigQuery erstellen
- Dataset und Tabellen in BigQuery erstellen
- Gemini-Remote-Modelle in BigQuery erstellen
- Prompts an Gemini senden, um Keywords und Sentiment (positiv oder negativ) für textbasierte Kundenrezensionen zu analysieren
- Bericht mit der Anzahl positiver und negativer Rezensionen generieren
- Auf Kundenrezensionen reagieren – im großen Umfang
- Eine Anwendung für Kundenservicemitarbeiter erstellen, um auf audiobasierte Kundenrezensionen zu reagieren
Einrichtung und Anforderungen
Vor dem Klick auf „Start Lab“ (Lab starten)
Lesen Sie diese Anleitung. Labs sind zeitlich begrenzt und können nicht pausiert werden. Der Timer beginnt zu laufen, wenn Sie auf Lab starten klicken, und zeigt Ihnen, wie lange die Ressourcen für das Lab verfügbar sind.
In diesem praxisorientierten Lab können Sie die Lab-Aktivitäten in einer echten Cloud-Umgebung selbst durchführen – nicht in einer Simulations- oder Demo-Umgebung. Dazu erhalten Sie neue, temporäre Anmeldedaten, mit denen Sie für die Dauer des Labs auf Google Cloud zugreifen können.
Für dieses Lab benötigen Sie Folgendes:
- Einen Standardbrowser (empfohlen wird Chrome)
- Zeit für die Durchführung des Labs – denken Sie daran, dass Sie ein begonnenes Lab nicht unterbrechen können.
Lab starten und bei der Google Cloud Console anmelden
-
Klicken Sie auf Lab starten. Wenn Sie für das Lab bezahlen müssen, wird ein Pop-up-Fenster geöffnet, in dem Sie Ihre Zahlungsmethode auswählen können. Auf der linken Seite befindet sich der Bereich Details zum Lab mit diesen Informationen:
- Schaltfläche Google Cloud Console öffnen
- Restzeit
- Temporäre Anmeldedaten für das Lab
- Ggf. weitere Informationen für dieses Lab
-
Klicken Sie auf Google Cloud Console öffnen (oder klicken Sie mit der rechten Maustaste und wählen Sie Link in Inkognitofenster öffnen aus, wenn Sie Chrome verwenden).
Im Lab werden Ressourcen aktiviert. Anschließend wird ein weiterer Tab mit der Seite Anmelden geöffnet.
Tipp: Ordnen Sie die Tabs nebeneinander in separaten Fenstern an.
Hinweis: Wird das Dialogfeld Konto auswählen angezeigt, klicken Sie auf Anderes Konto verwenden. -
Kopieren Sie bei Bedarf den folgenden Nutzernamen und fügen Sie ihn in das Dialogfeld Anmelden ein.
{{{user_0.username | "Username"}}} Sie finden den Nutzernamen auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
-
Kopieren Sie das folgende Passwort und fügen Sie es in das Dialogfeld Willkommen ein.
{{{user_0.password | "Password"}}} Sie finden das Passwort auch im Bereich Details zum Lab.
-
Klicken Sie auf Weiter.
Wichtig: Sie müssen die für das Lab bereitgestellten Anmeldedaten verwenden. Nutzen Sie nicht die Anmeldedaten Ihres Google Cloud-Kontos. Hinweis: Wenn Sie Ihr eigenes Google Cloud-Konto für dieses Lab nutzen, können zusätzliche Kosten anfallen. -
Klicken Sie sich durch die nachfolgenden Seiten:
- Akzeptieren Sie die Nutzungsbedingungen.
- Fügen Sie keine Wiederherstellungsoptionen oder Zwei-Faktor-Authentifizierung hinzu (da dies nur ein temporäres Konto ist).
- Melden Sie sich nicht für kostenlose Testversionen an.
Nach wenigen Augenblicken wird die Google Cloud Console in diesem Tab geöffnet.

Aufgabe 1: Python-Notebook in BigQuery erstellen und mit der Laufzeit verbinden
In dieser Aufgabe erstellen Sie ein Python-Notebook in BigQuery und verbinden es mit der Laufzeit.
Python-Notebook in BigQuery erstellen
-
Klicken Sie in der Google Cloud Console im Navigationsmenü auf BigQuery.
-
Klicken Sie im Pop-up-Fenster „Willkommen“ auf FERTIG.
-
Klicken Sie auf PYTHON-NOTEBOOK.
-
Wählen Sie
als Region aus. -
Klicken Sie auf AUSWÄHLEN.
Außerdem wurde das Python-Notebook im Abschnitt „Notebooks“ des Explorers unter Ihrem Projekt hinzugefügt.
-
Löschen Sie alle Zellen im Notebook. Klicken Sie dazu auf das Papierkorbsymbol, das angezeigt wird, wenn Sie den Mauszeiger über die einzelnen Zellen bewegen.
Anschließend sollte das Notebook leer sein. Damit sind Sie bereit für die nächste Aufgabe.
Mit der Laufzeit verbinden
-
Klicken Sie auf Verbinden.
-
Klicken Sie auf die Qwiklabs-Teilnehmer-ID.
Haben Sie einen Augenblick Geduld. Es kann bis zu drei Minuten dauern, bis die Verbindung zur Laufzeit hergestellt wurde.
Unten im Browserfenster wird nun als Verbindungsstatus „Verbunden“ angezeigt.
Klicken Sie auf Fortschritt prüfen.
Aufgabe 2: Cloud-Ressourcenverbindung erstellen und IAM-Rolle gewähren
Cloud-Ressourcenverbindung in BigQuery erstellen
In dieser Aufgabe erstellen Sie eine Cloud-Ressourcenverbindung in BigQuery, um Gemini Pro- und Gemini Flash-Modelle anwenden zu können. Außerdem gewähren Sie dem Dienstkonto der Cloud-Ressourcenverbindung eine Rolle mit IAM-Berechtigungen, mit denen der Zugriff auf Vertex AI-Dienste möglich ist.
Sie verwenden das Python SDK und die Google Cloud CLI, um die Cloud-Ressourcenverbindung zu erstellen. Zuerst müssen Sie aber Python-Bibliotheken importieren und die Variablen „project_id“ und „region“ festlegen.
-
Erstellen Sie eine neue Codezelle mit dem folgenden Code:
# Import Python libraries import vertexai from vertexai.generative_models import GenerativeModel, Part from google.cloud import bigquery from google.cloud import storage import json import io import matplotlib.pyplot as plt from IPython.display import HTML, display from IPython.display import Audio from pprint import pprint Mit diesem Code werden die Python-Bibliotheken importiert.
-
Führen Sie diese Zelle aus. Die Bibliotheken werden nun geladen und können verwendet werden.
-
Erstellen Sie eine neue Codezelle mit dem folgenden Code:
# Set Python variables for project_id and region project_id = "{{{project_0.project_id|Project ID}}}" region = " {{{ project_0.default_region | "REGION" }}}" Hinweis: project_id und region werden hier als Python-Variablen und nicht als SQL-Variablen gespeichert. Daher können Sie sich in den Zellen nur mit Python-Code und nicht mit SQL-Code auf sie beziehen. -
Führen Sie diese Zelle aus. Die Variablen „project_id“ und „region“ sind festgelegt.
-
Erstellen Sie eine neue Codezelle mit dem folgenden Code:
# Create the resource connection !bq mk --connection \ --connection_type=CLOUD_RESOURCE \ --location=US \ gemini_conn Dieser Code verwendet den Befehl
bq mk --connectionder Google Cloud CLI, um die Ressourcenverbindung zu erstellen. -
Führen Sie diese Zelle aus. Die Ressourcenverbindung wurde erstellt.
-
Klicken Sie neben der Projekt-ID im Explorer auf Aktionen ansehen.
-
Wählen Sie Inhalte aktualisieren aus.
-
Erweitern Sie Externe Verbindungen. Beachten Sie, dass
us.gemini_connnun als externe Verbindung aufgeführt wird. -
Klicken Sie auf us.gemini_conn.
-
Kopieren Sie im Bereich „Verbindungsinformationen“ die Dienstkonto-ID in eine Textdatei für die nächste Aufgabe.
Dem Dienstkonto der Verbindung die Rolle „Vertex AI User“ gewähren
-
Klicken Sie in der Console im Navigationsmenü auf IAM und Verwaltung.
-
Klicken Sie auf Zugriff gewähren.
-
Geben Sie im Feld Neue Hauptkonten die Dienstkonto-ID ein, die Sie zuvor kopiert haben.
-
Wählen Sie im Feld „Rolle auswählen“ die Option Vertex AI und dann Vertex AI User aus.
-
Klicken Sie auf Speichern.
Das Dienstkonto beinhaltet nun die Rolle „Vertex AI User“.
Klicken Sie auf Fortschritt prüfen.
Aufgabe 3: Audiodateien und Dataset prüfen und dem Dienstkonto IAM-Rolle gewähren
In dieser Aufgabe prüfen Sie das Dataset und die Audiodateien. Anschließend gewähren Sie dem Dienstkonto der Cloud-Ressourcenverbindung IAM-Berechtigungen.
Audiodateien, Bilddateien und Dataset der Kundenrezensionen in Cloud Storage prüfen
Bevor Sie in dieser Aufgabe dem Dienstkonto der Cloud-Ressourcenverbindung IAM-Berechtigungen gewähren, prüfen Sie das Dataset und die Bilddateien.
-
Wählen Sie in der Cloud Console das Navigationsmenü (
) und dann Cloud Storage aus.
-
Klicken Sie auf den Bucket
-bucket. -
Der Bucket enthält den Ordner „gsp12469“. Öffnen Sie diesen Ordner. Darin sind fünf Elemente enthalten:
- Der Ordner
audioenthält alle Audiodateien, die Sie analysieren werden. Sie können jetzt auf den Ordner „audio“ zugreifen und die Bilddateien prüfen. - Die Datei
customer_reviews.csventhält das Dataset mit den textbasierten Kundenrezensionen. - Der Ordner
imagesenthält eine Bilddatei, die Sie später in diesem Lab verwenden werden. Sie können den Ordner jederzeit aufrufen und die darin enthaltene Bilddatei öffnen. -
notebook.ipynb, eine Kopie des Notebooks, das Sie in diesem Lab erstellen. Sie können diese Datei jederzeit nach Bedarf aufrufen.
Hinweis: Sie können die Authentifizierungs-URL zum Herunterladen und Prüfen der einzelnen Elemente verwenden. - Der Ordner
Dem Dienstkonto der Verbindung die IAM-Rolle „Storage Object Admin“ gewähren
Gewähren Sie dem Dienstkonto der Ressourcenverbindung IAM-Berechtigungen, bevor Sie mit der Arbeit in BigQuery beginnen. Dadurch können Sie Fehler des Typs „Zugriff verweigert“ vermeiden.
-
Kehren Sie zum Stammverzeichnis des Buckets zurück.
-
Klicken Sie auf BERECHTIGUNGEN.
-
Klicken Sie auf ZUGRIFF GEWÄHREN.
-
Geben Sie im Feld Neue Hauptkonten die Dienstkonto-ID ein, die Sie zuvor kopiert haben.
-
Geben Sie im Feld „Rolle auswählen“ Storage Object ein und wählen Sie die Rolle Storage Object Admin aus.
-
Klicken Sie auf Speichern.
Das Dienstkonto beinhaltet nun die Rolle „Storage Object Admin“.
Klicken Sie auf Fortschritt prüfen.
Aufgabe 4: Dataset und Tabelle mit Kundenrezensionen in BigQuery erstellen
In dieser Aufgabe erstellen Sie ein Dataset für das Projekt und die Tabelle für Kundenrezensionen.
Dataset erstellen
Für das Dataset verwenden Sie folgende Attribute:
| Feld | Wert |
|---|---|
| Dataset-ID | gemini_demo |
| Standorttyp | Multiregional auswählen |
| Mehrere Regionen | US auswählen |
-
Kehren Sie zum Python-Notebook in BigQuery zurück.
-
Erstellen Sie eine neue Codezelle mit dem folgenden Code:
# Create the dataset %%bigquery CREATE SCHEMA IF NOT EXISTS `{{{project_0.project_id|Project ID}}}.gemini_demo` OPTIONS(location="US"); Beachten Sie, dass der Code mit
%%bigquerybeginnt. Python weiß somit, dass unmittelbar auf diese Anweisung SQL-Code folgt. -
Führen Sie diese Zelle aus.
Der SQL-Code erstellt dann das Dataset
gemini_demoin Ihrem Projekt in der US-Region, die unter Ihrem Projekt im BigQuery Explorer aufgeführt ist.
Tabelle für Kundenrezensionen mit Beispieldaten erstellen
Zum Erstellen der Tabelle für Kundenrezensionen führen Sie eine SQL-Abfrage durch.
-
Erstellen Sie eine neue Codezelle mit dem folgenden Code:
# Create the customer reviews table %%bigquery LOAD DATA OVERWRITE gemini_demo.customer_reviews (customer_review_id INT64, customer_id INT64, location_id INT64, review_datetime DATETIME, review_text STRING, social_media_source STRING, social_media_handle STRING) FROM FILES ( format = 'CSV', uris = ['gs://{{{project_0.project_id|Project ID}}}-bucket/gsp1249/customer_reviews.csv']); -
Führen Sie diese Zelle aus.
Daraufhin wird die Tabelle
customer_reviewsmit Beispieldaten für Kundenrezensionen erstellt, einschließlichcustomer_review_id,customer_id,location_id,review_datetime,review_text,social_media_sourceundsocial_media_handlefür jede Rezension im Dataset. -
Klicken Sie im Explorer auf die Tabelle customer_reviews und prüfen Sie das Schema und die Details.
-
Wenden Sie eine Abfrage auf die Tabelle an, um die Datensätze zu prüfen. Erstellen Sie dazu eine Codezelle mit dem folgenden Code:
# Create the customer reviews table %%bigquery SELECT * FROM `gemini_demo.customer_reviews` ORDER BY review_datetime -
Führen Sie diese Zelle aus.
Daraufhin werden die Datensätze aus der Tabelle mit allen Spalten angezeigt.
Klicken Sie auf Fortschritt prüfen.
Aufgabe 5: Modell „Gemini Pro“ in BigQuery erstellen
Die Tabellen wurden nun erstellt und können verwendet werden. In dieser Aufgabe erstellen Sie das Modell „Gemini Pro“ in BigQuery.
-
Kehren Sie zum Python-Notebook zurück.
-
Erstellen Sie eine neue Codezelle mit dem folgenden Code:
# Create the customer reviews table %%bigquery CREATE OR REPLACE MODEL `gemini_demo.gemini_pro` REMOTE WITH CONNECTION `us.gemini_conn` OPTIONS (endpoint = 'gemini-pro') -
Führen Sie diese Zelle aus.
Das Modell
gemini_prowird erstellt und zum Datasetgemini_demoim Abschnitt „Modelle“ hinzugefügt. -
Klicken Sie im Explorer auf das Modell gemini_pro und prüfen Sie die Details und das Schema.
Klicken Sie auf Fortschritt prüfen.
Aufgabe 6: Prompts an Gemini zur Analyse von Kundenrezensionen in Bezug auf Keywords und Sentiment senden
In dieser Aufgabe analysieren Sie mit dem Modell „Gemini Pro“ alle Kundenrezensionen in Bezug auf Sentiment, positiv und negativ.
Kundenrezensionen in Bezug auf positives und negatives Sentiment analysieren
-
Erstellen Sie eine neue Codezelle mit dem folgenden Code:
# Create the sentiment analysis table %%bigquery CREATE OR REPLACE TABLE `gemini_demo.customer_reviews_analysis` AS ( SELECT ml_generate_text_llm_result, social_media_source, review_text, customer_id, location_id, review_datetime FROM ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_pro`, ( SELECT social_media_source, customer_id, location_id, review_text, review_datetime, CONCAT( 'Classify the sentiment of the following text as positive or negative.', review_text, "In your response don't include the sentiment explanation. Remove all extraneous information from your response, it should be a boolean response either positive or negative.") AS prompt FROM `gemini_demo.customer_reviews` ), STRUCT( 0.2 AS temperature, TRUE AS flatten_json_output))); -
Führen Sie diese Zelle aus.
Diese Abfrage übernimmt Kundenrezensionen aus der Tabelle
customer_reviews, erstellt den Prompt und nutzt diesen mit dem Modellgemini_pro, um das Sentiment für jede Rezension zu klassifizieren. Die Ergebnisse werden in der neuen Tabellecustomer_reviews_analysisgespeichert und können später zur weiteren Analyse verwendet werden.Haben Sie einen Augenblick Geduld. Es kann ca. 30 Sekunden dauern, bis das Modell die Datensätze der Kundenrezensionen verarbeitet hat.
Mit Abschluss des Modells wird die Tabelle
customer_reviews_analysiserstellt. -
Klicken Sie im Explorer auf die Tabelle customer_reviews_analysis und prüfen Sie das Schema und die Details.
-
Erstellen Sie eine neue Codezelle mit dem folgenden Code:
# Pull the first 100 records from the customer_reviews_analysis table %%bigquery SELECT * FROM `gemini_demo.customer_reviews_analysis` ORDER BY review_datetime -
Führen Sie diese Zelle aus.
Es werden Zeilen mit der Spalte
ml_generate_text_llm_result(enthält die Sentimentanalyse), dem Text der Kundenrezension, der Kundennummer und der Standort-ID angezeigt.Werfen Sie einen Blick auf die Datensätze. Es kann sein, dass einige Ergebnisse für positiv und negativ nicht korrekt formatiert sind, da sie überflüssige Zeichen wie Punkte oder zusätzliche Leerzeichen enthalten. Mit der folgenden Ansicht können Sie die Datensätze bereinigen.
Ansicht zur Bereinigung der Datensätze erstellen
-
Erstellen Sie eine neue Codezelle mit dem folgenden Code:
# Sanitize the records within a new view %%bigquery CREATE OR REPLACE VIEW gemini_demo.cleaned_data_view AS SELECT REPLACE(REPLACE(LOWER(ml_generate_text_llm_result), '.', ''), ' ', '') AS sentiment, REGEXP_REPLACE( REGEXP_REPLACE( REGEXP_REPLACE(social_media_source, r'Google(\+|\sReviews|\sLocal|\sMy\sBusiness|\sreviews|\sMaps)?', 'Google'), 'YELP', 'Yelp' ), r'SocialMedia1?', 'Social Media' ) AS social_media_source, review_text, customer_id, location_id, review_datetime FROM `gemini_demo.customer_reviews_analysis`; -
Führen Sie diese Zelle aus.
Der Code erstellt die Ansicht
cleaned_data_viewmit den Sentimentergebnissen, dem Text der Kundenrezension, der Kundennummer und der Standort-ID. Dann wird sichergestellt, dass im Sentimentergebnis (positiv oder negativ) nur Kleinbuchstaben und keine überflüssigen Leerzeichen oder Punkte vorhanden sind. Mit der erstellten Ansicht lässt sich die Analyse in den späteren Schritten in diesem Lab einfacher durchführen. -
Erstellen Sie eine neue Codezelle mit dem folgenden Code:
# Pull the first 100 records from the cleaned_data_view view %%bigquery SELECT * FROM `gemini_demo.cleaned_data_view` ORDER BY review_datetime -
Führen Sie diese Zelle aus.
Beachten Sie, dass die Spalte
sentimentjetzt bereinigte Werte für positive und negative Rezensionen enthält. Sie können diese Ansicht in späteren Schritten zum Erstellen eines Berichts verwenden.
Bericht über die Anzahl positiver und negativer Rezensionen erstellen
Sie können die Python-Bibliothek und die Matplotlib-Bibliothek zum Erstellen eines Balkendiagrammberichts mit der Anzahl der positiven und negativen Rezensionen verwenden.
-
Erstellen Sie eine neue Codezelle, um den BigQuery-Client zum Abfragen der cleaned_data_view für positive und negative Kundenrezensionen zu verwenden. Gruppieren Sie dann die Kundenrezensionen nach Sentiment und speichern Sie die Ergebnisse in einem Dataframe.
# Task 6.5 - Create the BigQuery client, and query the cleaned data view for positive and negative reviews, store the results in a dataframe and then show the first 10 records client = bigquery.Client() query = "SELECT sentiment, COUNT(*) AS count FROM `gemini_demo.cleaned_data_view` WHERE sentiment IN ('positive', 'negative') GROUP BY sentiment;" query_job = client.query(query) results = query_job.result().to_dataframe() results.head(10) -
Führen Sie diese Zelle aus.
Es wird eine Tabelle mit der Gesamtzahl positiver und negativer Kundenrezensionen ausgegeben.
-
Erstellen Sie eine neue Zelle zum Definieren von Variablen für den Bericht.
# Define variable for the report. sentiment = results["sentiment"].tolist() count = results["count"].tolist() -
Führen Sie diese Zelle aus. Es gibt keine Ausgabe.
-
Erstellen Sie eine neue Zelle, um den Bericht zu erstellen.
# Task 6.7 - Build the report. plt.bar(sentiment, count, color='skyblue') plt.xlabel("Sentiment") plt.ylabel("Total Count") plt.title("Bar Chart from BigQuery Data") plt.show() -
Führen Sie diese Zelle aus.
Es wird ein Balkendiagramm mit der Gesamtzahl positiver und negativer Kundenrezensionen angezeigt.
-
Alternativ können Sie einen einfachen farbcodierten Bericht mit der Anzahl der negativen und positiven Sentiments erstellen. Verwenden Sie dazu den folgenden Code:
# Create an HTML table for the counts of negative and positive sentiment and color codes the results. html_counts = f"""
""" # Display the HTML tables display(HTML(html_counts))Negative Positive {count[0]} {count[1]}
Klicken Sie auf Fortschritt prüfen.
Aufgabe 7: Auf Kundenrezensionen reagieren
Data Beans möchte mit Kundenrezensionen experimentieren, die Bilder und Audioaufnahmen umfassen. In diesem Abschnitt des Notebooks verwenden Sie Cloud Storage, BigQuery, Gemini Flash und Python, um Sentimentanalysen zu Kundenrezensionen auszuführen, die als Bilder oder Audiodateien an Data Beans gesendet wurden. Anhand dieser Analysen generieren Sie Antworten für den Kundenservice, die an die Kunden zurückgesendet werden, um ihnen für ihre Rezension zu danken, und Maßnahmen zu nennen, die das Unternehmen aufgrund der Rezension ergreifen kann.
Sie führen diesen Vorgang zuerst in großem Umfang und anschließend mit einem einzelnen Bild und einer einzelnen Audiodatei aus. Dabei lernen Sie, wie Sie eine Proof-of-Concept-Anwendung für Kundenservicemitarbeiter erstellen können. Dadurch ermöglichen Sie eine Human-in-the-Loop-Strategie für den Kundenfeedbackprozess, bei der Kundenservicemitarbeiter Maßnahmen sowohl in Bezug auf Kunden als auch auf einzelne Café-Standorte ergreifen können.
Audiodateien in großem Umfang mit JSON-Antworten verarbeiten
-
Erstellen Sie eine neue Zelle, um eine Sentimentanalyse zu Audiodateien auszuführen und dem Kunden zu antworten.
# Conduct sentiment analysis on audio files and respond to the customer. vertexai.init(project="{{{project_0.project_id|Project ID}}}", location="{{{project_0.default_region|region}}}") model = GenerativeModel(model_name="gemini-1.5-flash") prompt = """ Please provide a transcript for the audio. Then provide a summary for the audio. Then identify the keywords in the transcript. Be concise and short. Do not make up any information that is not part of the audio and do not be verbose. Then determine the sentiment of the audio: positive, neutral or negative. Also, you are a customr service representative. How would you respond to this customer review? From the customer reviews provide actions that the location can take to improve. The response and the actions should be simple, and to the point. Do not include any extraneous characters in your response. Answer in JSON format with five keys: transcript, summary, keywords, sentiment, response and actions. Transcript should be a string, summary should be a sting, keywords should be a list, sentiment should be a string, customer response should be a string and actions should be string. """ bucket_name = "{{{project_0.project_id|Project ID}}}-bucket" folder_name = 'gsp1249/audio' # Include the trailing '/' def list_mp3_files(bucket_name, folder_name): storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) print('Accessing ', bucket, ' with ', storage_client) blobs = bucket.list_blobs(prefix=folder_name) mp3_files = [] for blob in blobs: if blob.name.endswith('.mp3'): mp3_files.append(blob.name) return mp3_files file_names = list_mp3_files(bucket_name, folder_name) if file_names: print("MP3 files found:") print(file_names) for file_name in file_names: audio_file_uri = f"gs://{bucket_name}/{file_name}" print('Processing file at ', audio_file_uri) audio_file = Part.from_uri(audio_file_uri, mime_type="audio/mpeg") contents = [audio_file, prompt] response = model.generate_content(contents) print(response.text) else: print("No MP3 files found in the specified folder.") Einige wichtige Punkte zu dieser Zelle:
- In der ersten Zeile wird Vertex AI mit Ihrer Projekt-ID und Region initialisiert. Diese Werte müssen angegeben werden.
- In der nächsten Zeile wird ein Modell in BigQuery mit dem Namen „model“ erstellt, das auf dem Gemini Flash-Modell basiert.
- Anschließend definieren Sie einen Prompt zur Verwendung durch das Gemini Flash-Modell. Der Prompt konvertiert die Audiodatei effektiv in Text, analysiert das Sentiment des Textes und erstellt nach Abschluss der Analyse eine Kundenantwort für jede Datei.
- Sie müssen den Bucket als bucket_name-Stringvariable festlegen. Hinweis: „folder_name“ wird auch für den Unterordner „gsp1249/audio“ verwendet. Ändern Sie dies nicht.
- Die Funktion „list_mp3_files“ wird erstellt, um alle mp3-Dateien im Bucket zu bestimmen. Diese Dateien werden dann vom Gemini Flash-Modell innerhalb der if-Anweisung erstellt.
-
Führen Sie diese Zelle aus.
Daraufhin werden alle fünf Audiodateien analysiert und die Ausgabe der Analyse wird als JSON-Antwort zurückgegeben. Die JSON-Antwort kann entsprechend geparst und an die jeweiligen Anwendungen weitergeleitet werden, um dem Kunden oder Standort mit Verbesserungsmaßnahmen zu antworten.
Anwendung für Kundenservicemitarbeiter erstellen
In diesem Abschnitt des Labs lernen Sie, wie Sie eine Anwendung für den Kundenservice basierend auf der Analyse einer negativen Bewertung erstellen. Sie werden Folgendes tun:
- Sie verwenden denselben Prompt wie in der vorherigen Zelle, um eine einzelne negative Rezension zu analysieren.
- Sie generieren das Transkript zur Audiodatei der negativen Rezension, erstellen das JSON-Objekt anhand der Modellausgabe mit der entsprechenden Formatierung und speichern bestimmte Teile des JSON-Objekts als Python-Variablen, um diese mit HTML als Teil Ihrer Anwendung verwenden zu können.
- Sie generieren die HTML-Tabelle, laden das vom Kunden hochgeladene Bild für die Rezension und die Audiodatei in den Player.
- Sie öffnen die HTML-Tabelle mit dem Bild und dem Player für die Audiodatei.
-
Sie erstellen eine neue Zelle und geben den folgenden Code ein, um das Transkript für die Audiodatei der negativen Rezension und das JSON-Objekt mit den zugehörigen Variablen zu erstellen.
# Generate the transcript for the negative review audio file, create the JSON object, and associated variables audio_file_uri = f"gs://{bucket_name}/{folder_name}/data-beans_review_7061.mp3" print(audio_file_uri) audio_file = Part.from_uri(audio_file_uri, mime_type="audio/mpeg") contents = [audio_file, prompt] response = model.generate_content(contents) print('Generating Transcript...') #print(response.text) results = response.text # print("your results are", results, type(results)) print('Transcript created...') print('Transcript ready for analysis...') json_data = results.replace('```json', '') json_data = json_data.replace('```', '') jason_data = '"""' + results + '"""' # print(json_data, type(json_data)) data = json.loads(json_data) # print(data) transcript = data["transcript"] summary = data["summary"] sentiment = data["sentiment"] keywords = data["keywords"] response = data["response"] actions = data["actions"] Einige wichtige Punkte zu dieser Zelle:
- Der Code in der Zelle wählt eine bestimmte Audiodatei (data-beans_review_7061.mp3) aus Cloud Storage aus.
- Diese Datei wird dann an den Prompt in der vorherigen Zelle mit der Bezeichnung „Task 7.1“ übergeben, um vom Gemini Flash-Modell verarbeitet zu werden.
- Die Antwort des Modells wird im JSON-Format extrahiert.
- Daraufhin werden die JSON-Daten geparst und Python-Variablen für Transkript, Zusammenfassung, Sentiment, Keywords, Kundenantwort und Maßnahmen gespeichert.
-
Führen Sie die Zelle aus.
Die Ausgabe ist minimal und enthält lediglich den URI der verarbeiteten Audiodatei und Verarbeitungsnachrichten.
-
Erstellen Sie eine HTML-basierte Tabelle anhand der ausgewählten Werte und laden Sie die Audiodatei mit der negativen Rezension in den Player.
# Create an HTML table (including the image) from the selected values. html_string = f""" customer_id: 7061 - @coffee_lover789
""" print('The table has been created.'){transcript} {sentiment} feedback {keywords[0]} {keywords[1]} {keywords[2]} {keywords[3]} Customer summary:{summary} Recommended actions:{actions} Suggested Response:{response} Einige wichtige Punkte zu dieser Zelle:
- Der Code in der Zelle erstellt einen HTML-Tabellenstring.
- Dann werden die Werte für Transkript, Sentiment, Keywords, Bild, Zusammenfassung, Maßnahmen und Antwort in die Tabellenzellen eingegeben.
- Der Code wendet auch Formatierung auf die Tabellenelemente an.
- Wenn die Zelle ausgeführt wurde, gibt die Ausgabe der Zelle an, wann die Tabelle erstellt wurde.
-
Suchen Sie das Tag
<td style="padding:10px;">mit der Ausgabe{summary}. Fügen Sie eine neue Codezeile vor diesem Tag hinzu. -
Fügen Sie
<td rowspan="3" style="padding: 10px;"><img src="<authenticated url here>" alt="Customer Image" style="max-width: 300px;"></td>in diese neue Codezeile ein. -
Suchen Sie die Authentifizierungs-URL für die Bilddatei „image_7061.png“. Wählen Sie in Cloud Storage den einzigen verfügbaren Bucket mit dem Bildordner aus und klicken Sie auf das Bild.
-
Kopieren Sie auf der angezeigten Seite die Authentifizierungs-URL für das Bild.
-
Kehren Sie zum Python-Notebook in BigQuery zurück. Ersetzen Sie
<authenticated url here>durch die tatsächliche Authentifizierungs-URL im gerade eingefügten Code. -
Führen Sie die Zelle aus.
Die Ausgabe ist wieder minimal. Sie enthält nur einige Verarbeitungsnachrichten zu den abgeschlossenen Schritten.
-
Erstellen Sie eine neue Zelle zum Herunterladen der Audiodatei und verwenden Sie den folgenden Code, um sie in den Player zu laden:
# Download the audio file from Google Cloud Storage and load into the player storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) blob = bucket.blob(f"{folder_name}/data-beans_review_7061.mp3") audio_bytes = io.BytesIO(blob.download_as_bytes()) # Assuming a sample rate of 44100 Hz (common for MP3 files) sample_rate = 44100 print('The audio file is loaded in the player.') Einige wichtige Punkte zu dieser Zelle:
- Der Code in der Zelle greift auf den Cloud Storage-Bucket zu und ruft die die spezifische Audiodatei (data-beans_review_7061.mp3) ab.
- Dann wird die Datei als Bytestream heruntergeladen und die Abtastrate der Datei bestimmt, damit sie in einem Player direkt im Notebook abgespielt werden kann.
- Wenn Sie die Zelle ausführen, erhalten Sie als Ausgabe eine Nachricht, die angibt, dass die Audiodatei in den Player geladen wurde und abgespielt werden kann.
-
Führen Sie die Zelle aus.
-
Erstellen Sie eine neue Zelle und geben Sie den folgenden Code ein:
# Task 7.5 - Build the mockup as output to the cell. print('Analysis complete. Review the results below.') display(HTML(html_string)) display(Audio(audio_bytes.read(), rate=sample_rate, autoplay=True)) -
Führen Sie die Zelle aus.
In dieser Zelle geschieht die eigentliche Arbeit. Die Anzeigemethode wird zum Anzeigen der in den Player geladenen HTML- und Audiodatei verwendet. Prüfen Sie die Ausgabe der Zelle. Sie sollte mit dem folgenden Bild identisch sein:
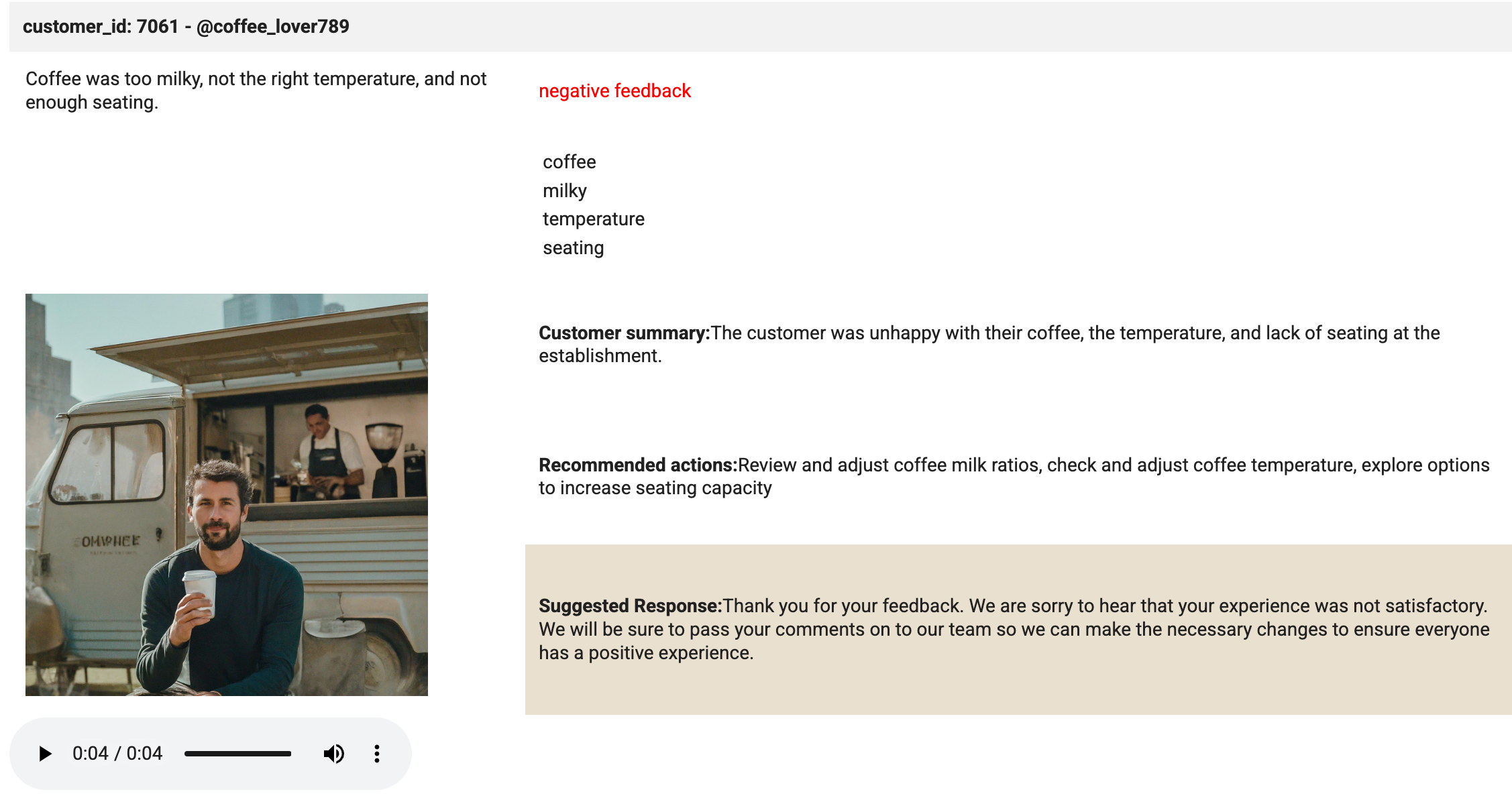
Klicken Sie auf Fortschritt prüfen.
Das wars! Sie haben das Lab erfolgreich abgeschlossen.
Sie haben eine Cloud-Ressourcenverbindung in BigQuery erstellt. Sie haben auch ein Dataset, Tabellen und Modelle erstellt, um Prompts an Gemini zu senden und das Sentiment und Keywords von Kundenrezensionen zu analysieren. Außerdem haben Sie mithilfe von Gemini audiobasierte Kundenrezensionen analysiert, um Zusammenfassungen und Keywords für Antworten auf Kundenrezensionen innerhalb einer Anwendung für den Kundenservice zu generieren.
Weitere Informationen
- Einführung in BigQuery ML
- Maschinelles Lernen mit der ML-Inferenz-Engine von BigQuery skalieren – Blog
- Gemini-Modelle
- Generative KI
Google Cloud-Schulungen und -Zertifizierungen
In unseren Schulungen erfahren Sie alles zum optimalen Einsatz unserer Google Cloud-Technologien und können sich entsprechend zertifizieren lassen. Unsere Kurse vermitteln technische Fähigkeiten und Best Practices, damit Sie möglichst schnell mit Google Cloud loslegen und Ihr Wissen fortlaufend erweitern können. Wir bieten On-Demand-, Präsenz- und virtuelle Schulungen für Anfänger wie Fortgeschrittene an, die Sie individuell in Ihrem eigenen Zeitplan absolvieren können. Mit unseren Zertifizierungen weisen Sie nach, dass Sie Experte im Bereich Google Cloud-Technologien sind.
Anleitung zuletzt am 26. Juli 2024 aktualisiert
Lab zuletzt am 26. Juli 2024 getestet
© 2024 Google LLC. Alle Rechte vorbehalten. Google und das Google-Logo sind Marken von Google LLC. Alle anderen Unternehmens- und Produktnamen können Marken der jeweils mit ihnen verbundenen Unternehmen sein.

