Puntos de control
Create BigQuery Python notebook and connect to runtime
/ 10
Create the cloud resource connection and grant IAM role
/ 10
Review images, dataset, and grant IAM role to service account
/ 10
Create the dataset and customer reviews table in BigQuery
/ 30
Create the Gemini Pro model in BigQuery
/ 10
Prompt Gemini to analyze customer reviews for keywords and sentiment
/ 20
Respond to customer reviews
/ 10
Analiza las opiniones de los clientes con Gemini utilizando notebooks de Python
- GSP1249
- Descripción general
- Objetivos
- Configuración y requisitos
- Tarea 1: Crea un notebook de Python en BigQuery y conéctate a un entorno de ejecución
- Tarea 2: Crea la conexión al recurso de Cloud y otorga el rol de IAM
- Tarea 3: Revisa archivos de audio y conjuntos de datos, y otorga el rol de IAM a la cuenta de servicio
- Tarea 4: Crea la tabla de opiniones de los clientes y el conjunto de datos en BigQuery
- Tarea 5. Crea el modelo de Gemini Pro en BigQuery
- Tarea 6. Envía una instrucción a Gemini para analizar las opiniones de los clientes en busca de palabras claves y sentimientos
- Tarea 7. Responde a las opiniones de los clientes
- ¡Felicitaciones!
GSP1249

Descripción general
En este lab, aprenderás a extraer palabras clave y a evaluar los sentimientos en las opiniones de los clientes usando BigQuery Machine Learning con modelos remotos (Gemini Pro).
BigQuery es una plataforma de análisis de datos completamente administrada y lista para la IA, que te ayuda a maximizar el valor de tus datos. Además, está diseñada para ser multimotor, multiformato y de múltiples nubes. Una de sus funciones clave es BigQuery Machine Learning, que te permite crear y ejecutar modelos de aprendizaje automático (AA) a través de consultas en SQL o con notebooks de Colab Enterprise.
Gemini es una familia de modelos de IA generativa desarrollados por Google DeepMind y diseñados para casos de uso multimodales. La API de Gemini otorga acceso a los modelos de Gemini Pro, Gemini Pro Vision y Gemini Flash.
Al final de este lab, compilarás una aplicación de atención al cliente basada en Python en un notebook de Colab Enterprise en BigQuery, usando el modelo de Gemini Flash para responder a las opiniones del cliente basadas en audio.
Objetivos
En este lab, aprenderás a realizar las siguientes tareas:
- Crear un notebook de Python en BigQuery usando Colab Enterprise
- Crear una conexión al recurso de Cloud en BigQuery
- Crear el conjunto de datos y las tablas en BigQuery
- Crear los modelos remotos de Gemini en BigQuery
- Enviar una instrucción a Gemini para analizar palabras clave y sentimientos (positivos o negativos) de las opiniones de los clientes basadas en textos
- Generar un informe con un recuento de las opiniones positivas y negativas
- Responder las opiniones de los clientes a gran escala
- Crear una aplicación para que los representantes del servicio de atención al cliente puedan responder las opiniones de los clientes basadas en audio
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab: Recuerda que, una vez que comienzas un lab, no puedes pausarlo.
Cómo iniciar tu lab y acceder a la consola de Google Cloud
-
Haga clic en el botón Comenzar lab. Si debe pagar por el lab, se abrirá una ventana emergente para que seleccione su forma de pago. A la izquierda, se encuentra el panel Detalles del lab, que tiene estos elementos:
- El botón Abrir la consola de Google Cloud
- El tiempo restante
- Las credenciales temporales que debe usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haz clic en Abrir la consola de Google Cloud (o haz clic con el botón derecho y selecciona Abrir el vínculo en una ventana de incógnito si ejecutas el navegador Chrome).
El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordene las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ves el diálogo Elegir una cuenta, haz clic en Usar otra cuenta. -
De ser necesario, copia el nombre de usuario a continuación y pégalo en el diálogo Acceder.
{{{user_0.username | "Username"}}} También puedes encontrar el nombre de usuario en el panel Detalles del lab.
-
Haz clic en Siguiente.
-
Copia la contraseña que aparece a continuación y pégala en el diálogo Te damos la bienvenida.
{{{user_0.password | "Password"}}} También puedes encontrar la contraseña en el panel Detalles del lab.
-
Haz clic en Siguiente.
Importante: Debes usar las credenciales que te proporciona el lab. No uses las credenciales de tu cuenta de Google Cloud. Nota: Usar tu propia Cuenta de Google podría generar cargos adicionales. -
Haga clic para avanzar por las páginas siguientes:
- Acepta los Términos y Condiciones.
- No agregues opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No te registres para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Google Cloud en esta pestaña.

Tarea 1: Crea un notebook de Python en BigQuery y conéctate a un entorno de ejecución
En esta tarea, crearás un notebook de Python en BigQuery y lo conectarás al entorno de ejecución.
Crea el notebook de Python en BigQuery
-
En la consola de Google Cloud, en el menú de navegación, haz clic en BigQuery.
-
Haz clic en LISTO en la ventana emergente de bienvenida.
-
Haz clic en NOTEBOOK DE PYTHON.
-
Selecciona
para la región. -
Haz clic en SELECCIONAR.
También verás que se agregó el notebook de Python a la sección de notebooks del explorador en tu proyecto.
-
Para borrar todas las celdas que se encuentran en el notebook, haz clic en el ícono de la papelera que aparece cuando colocas el cursor sobre cada celda.
Una vez que finalices, el notebook debería estar en blanco: todo está listo para que continúes con el próximo paso.
Conéctate al entorno de ejecución
-
Haz clic en Conectar.
-
Haz clic en el ID de estudiante de Qwiklabs.
Espera un momento. Es posible que la conexión al entorno de ejecución demore hasta 3 minutos.
En algún momento, verás la actualización del estado de conexión como Conectado en la parte inferior de la ventana del navegador.
Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 2: Crea la conexión al recurso de Cloud y otorga el rol de IAM
Crea la conexión al recurso de Cloud en BigQuery
En esta tarea, crearás una conexión al recurso de Cloud en BigQuery para trabajar con modelos de Gemini Pro y Gemini Flash. También otorgarás los permisos de IAM a la cuenta de servicio de la conexión al recurso de Cloud, a través de un rol, para habilitar el acceso a los servicios de Vertex AI.
Usaremos el SDK de Python y Google Cloud CLI para crear la conexión al recurso. Sin embargo, primero debes importar bibliotecas Python y definir las variables de project_id y region.
-
Crea una celda nueva de código con el código incluido a continuación:
# Import Python libraries import vertexai from vertexai.generative_models import GenerativeModel, Part from google.cloud import bigquery from google.cloud import storage import json import io import matplotlib.pyplot as plt from IPython.display import HTML, display from IPython.display import Audio from pprint import pprint Con ese código, se importarán las bibliotecas de Python.
-
Ejecuta esta celda. Ahora se cargaron las bibliotecas y están listas para usarse.
-
Crea una celda nueva de código con el código incluido a continuación:
# Set Python variables for project_id and region project_id = "{{{project_0.project_id|Project ID}}}" region = " {{{ project_0.default_region | "REGION" }}}" Nota: project_id y region se guardan como variables de Python y no de SQL, por lo que solo puedes hacer referencias a estas en celdas usando código de Python y no de SQL. -
Ejecuta esta celda. Se definieron las variables de project_id y region.
-
Crea una celda nueva de código con el código incluido a continuación:
# Create the resource connection !bq mk --connection \ --connection_type=CLOUD_RESOURCE \ --location=US \ gemini_conn En este código, se usa el comando
bq mk --connectionde Google Cloud CLI para crear la conexión al recurso. -
Ejecuta esta celda. Ahora se creó la conexión al recurso.
-
Haz clic en el botón Ver acciones junto al ID del proyecto en el Explorador.
-
Selecciona Actualizar contenido.
-
Expande las conexiones externas. Observa que
us.gemini_connahora se detalla como una conexión externa. -
Haz clic en us.gemini_conn.
-
En el panel Información de conexión, copia el ID de cuenta de servicio en un archivo de texto para usarlo en la próxima tarea.
Otorga el rol de usuario de Vertex AI a la cuenta de servicio de la conexión
-
En la consola, en el menú de navegación, haz clic en IAM y administración.
-
Haz clic en Otorgar acceso.
-
En el campo Principales nuevas, ingresa el ID de cuenta de servicio que copiaste antes.
-
En el campo Selecciona un rol, escribe Vertex AI y, a continuación, selecciona el rol Usuario de Vertex AI.
-
Haz clic en Guardar.
El resultado es que la cuenta de servicio ahora incluye el rol de usuario de Vertex AI.
Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 3: Revisa archivos de audio y conjuntos de datos, y otorga el rol de IAM a la cuenta de servicio
En esta tarea, revisarás el conjunto de datos y los archivos de audio. Luego, otorgarás los permisos de IAM a la cuenta de servicio de la conexión al recurso de Cloud.
Revisa los archivos de imagen y de audio, y el conjunto de datos de opiniones de los clientes en Cloud Storage
Antes de adentrarte en esta tarea para otorgar permisos a la cuenta de servicio de la conexión de recursos, revisa el conjunto de datos y los archivos de imagen.
-
En la consola de Google Cloud, selecciona el menú de navegación (
) y, luego, Cloud Storage.
-
Haz clic en el bucket
-bucket. -
El bucket contiene la carpeta gsp1249. Abre la carpeta. Verás cinco elementos en ella:
- La carpeta
audioincluye todos los archivos de audio que deberás analizar. Puedes acceder a la carpeta de audios y revisar los archivos de audio. - El archivo
customer_reviews.csves el conjunto de datos que contiene las opiniones de los clientes basadas en textos. - La carpeta
imagesincluye un archivo de imagen que usarás más adelante en este lab. Puedes acceder a esta carpeta y consultar el archivo de imagen que hay allí. -
notebook.ipynbes una copia del notebook que creas en este lab. Puedes consultarla en cualquier momento.
Nota: Puedes usar la URL autenticada para descargar y revisar cada uno de los elementos. - La carpeta
Otorga el rol de IAM de administrador de objetos de almacenamiento a la cuenta de servicio de la conexión
Otorgar los permisos de IAM a la cuenta de servicio de la conexión de recursos antes de empezar a trabajar en BigQuery garantizará que no se produzcan errores de acceso denegado cuando ejecutes consultas.
-
Regresa a la raíz del bucket.
-
Haz clic en PERMISOS.
-
Haz clic en OTORGAR ACCESO.
-
En el campo Principales nuevas, ingresa el ID de cuenta de servicio que copiaste antes.
-
En el campo Selecciona un rol, ingresa objetos de Storage y, a continuación, selecciona el rol Administrador de objetos de Storage.
-
Haz clic en Guardar.
Ahora el resultado de la cuenta de servicio incluye el rol de administrador de objetos de Storage.
Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 4: Crea la tabla de opiniones de los clientes y el conjunto de datos en BigQuery
En esta tarea, crearás un conjunto de datos del proyecto y la tabla de opiniones de los clientes.
Crea el conjunto de datos
Para el conjunto de datos, usarás las siguientes propiedades:
| Campo | Valor |
|---|---|
| ID de conjunto de datos | gemini_demo |
| Tipo de ubicación | selecciona Multirregional |
| Multirregional | selecciona US |
-
Regresa al notebook de Python en BigQuery.
-
Crea una celda nueva de código con el código incluido a continuación:
# Create the dataset %%bigquery CREATE SCHEMA IF NOT EXISTS `{{{project_0.project_id|Project ID}}}.gemini_demo` OPTIONS(location="US"); Observa que el código comienza con
%%bigquery, lo que le indica a Python que el código que viene inmediatamente después de la sentencia será código de SQL. -
Ejecuta esta celda.
Como resultado, el código SQL creará el conjunto de datos
gemini_demoen tu proyecto que reside en la región de EE.UU. detallada debajo del proyecto en el Explorador de BigQuery.
Crea la tabla de opiniones de los clientes con los datos de muestra
Para crear la tabla de opiniones de los clientes, usarás una consulta en SQL.
-
Crea una celda nueva de código con el código incluido a continuación:
# Create the customer reviews table %%bigquery LOAD DATA OVERWRITE gemini_demo.customer_reviews (customer_review_id INT64, customer_id INT64, location_id INT64, review_datetime DATETIME, review_text STRING, social_media_source STRING, social_media_handle STRING) FROM FILES ( format = 'CSV', uris = ['gs://{{{project_0.project_id|Project ID}}}-bucket/gsp1249/customer_reviews.csv']); -
Ejecuta esta celda.
El resultado es la tabla
customer_reviews, que se crea con los datos de muestra de opiniones de los clientes, incluidoscustomer_review_id,customer_id,location_id,review_datetime,review_text,social_media_sourceysocial_media_handlepara cada opinión en el conjunto de datos. -
En el Explorador, haz clic en la tabla customer_reviews y revisa el esquema y los detalles.
-
Haz consultas en la tabla para revisar los registros creando una nueva celda de código con el código incluido a continuación.
# Create the customer reviews table %%bigquery SELECT * FROM `gemini_demo.customer_reviews` ORDER BY review_datetime -
Ejecuta esta celda.
El resultado es que se muestran los registros de la tabla con todas las columnas incluidas.
Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 5. Crea el modelo de Gemini Pro en BigQuery
Ahora que las tablas ya están creadas, puedes comenzar a trabajar con ellas. En esta tarea, crearás un modelo de Gemini Pro en BigQuery.
-
Regresa al notebook de Python.
-
Crea una celda nueva de código con el código incluido a continuación:
# Create the customer reviews table %%bigquery CREATE OR REPLACE MODEL `gemini_demo.gemini_pro` REMOTE WITH CONNECTION `us.gemini_conn` OPTIONS (endpoint = 'gemini-pro') -
Ejecuta esta celda.
El resultado es que se crea el modelo
gemini_pro, y lo verás agregado al conjunto de datosgemini_demoen la sección de modelos. -
En el Explorador, haz clic en el modelo gemini_pro y revisa los detalles y el esquema.
Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 6. Envía una instrucción a Gemini para analizar las opiniones de los clientes en busca de palabras claves y sentimientos
En esta tarea, usarás el modelo de Gemini Pro para analizar cada una de las opiniones de los clientes en busca de sentimientos, tanto positivos como negativos.
Analiza las opiniones de los clientes en busca de sentimientos positivos y negativos
-
Crea una celda nueva de código con el código incluido a continuación:
# Create the sentiment analysis table %%bigquery CREATE OR REPLACE TABLE `gemini_demo.customer_reviews_analysis` AS ( SELECT ml_generate_text_llm_result, social_media_source, review_text, customer_id, location_id, review_datetime FROM ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_pro`, ( SELECT social_media_source, customer_id, location_id, review_text, review_datetime, CONCAT( 'Classify the sentiment of the following text as positive or negative.', review_text, "In your response don't include the sentiment explanation. Remove all extraneous information from your response, it should be a boolean response either positive or negative.") AS prompt FROM `gemini_demo.customer_reviews` ), STRUCT( 0.2 AS temperature, TRUE AS flatten_json_output))); -
Ejecuta esta celda.
En esta consulta, se toman las opiniones de los clientes de la tabla
customer_reviews, se crea la instrucción y, luego, se usan esas opiniones con el modelogemini_propara clasificar el sentimiento de cada opinión. Luego, los resultados se almacenan en una tabla nuevacustomer_reviews_analysispara que puedas usarla más adelante para realizar un análisis más profundo.Espera un momento. El modelo tarda alrededor de 30 segundos en procesar los registros de las opiniones de los clientes.
Una vez finalizado el modelo, el resultado es que se crea la tabla
customer_reviews_analysis. -
En el Explorador, haz clic en la tabla customer_reviews_analysis y revisa el esquema y los detalles.
-
Crea una celda nueva de código con el código incluido a continuación:
# Pull the first 100 records from the customer_reviews_analysis table %%bigquery SELECT * FROM `gemini_demo.customer_reviews_analysis` ORDER BY review_datetime -
Ejecuta esta celda.
El resultado son las filas de la columna
ml_generate_text_llm_result(que contiene el análisis de opiniones), el texto de las opiniones de los clientes, el ID de cliente y el ID de ubicación.Analiza algunos de los registros. Es posible que observes que algunos de los resultados de positivo y negativo no tienen el formato correcto, ya que incluyen caracteres extraños como puntos o espacios adicionales. Para limpiar los registros, puedes usar la vista que figura a continuación.
Crea una vista para limpiar los registros
-
Crea una celda nueva de código con el código incluido a continuación:
# Sanitize the records within a new view %%bigquery CREATE OR REPLACE VIEW gemini_demo.cleaned_data_view AS SELECT REPLACE(REPLACE(LOWER(ml_generate_text_llm_result), '.', ''), ' ', '') AS sentiment, REGEXP_REPLACE( REGEXP_REPLACE( REGEXP_REPLACE(social_media_source, r'Google(\+|\sReviews|\sLocal|\sMy\sBusiness|\sreviews|\sMaps)?', 'Google'), 'YELP', 'Yelp' ), r'SocialMedia1?', 'Social Media' ) AS social_media_source, review_text, customer_id, location_id, review_datetime FROM `gemini_demo.customer_reviews_analysis`; -
Ejecuta esta celda.
En el código, se crea la vista
cleaned_data_viewy se incluyen los resultados de las opiniones, el texto de la opinión, el ID de cliente y el ID de ubicación. Luego, se toma el resultado de las opiniones (positivas o negativas), se garantiza que todas las letras estén en minúscula y se quitan los caracteres extraños, como espacios adicionales o puntos. La vista resultante facilitará un análisis más profundo en los pasos incluidos más adelante en este lab. -
Crea una celda nueva de código con el código incluido a continuación:
# Pull the first 100 records from the cleaned_data_view view %%bigquery SELECT * FROM `gemini_demo.cleaned_data_view` ORDER BY review_datetime -
Ejecuta esta celda.
Observa que la columna
sentimentahora tiene valores limpios para las opiniones positivas y negativas. Podrás usar esta vista en pasos posteriores para generar un informe.
Crea un informe de recuentos de opiniones positivas y negativas
Puedes usar Python y la biblioteca matplotlib para crear un informe de gráfico de barras de los recuentos de opiniones positivas y negativas.
-
Crea una celda de código nuevo para usar el cliente de BigQuery y realizar consultas en cleaned_data_view sobre las opiniones positivas y negativas. Luego, agrupa las opiniones por sentimiento para almacenar los resultados en un DataFrame.
# Task 6.5 - Create the BigQuery client, and query the cleaned data view for positive and negative reviews, store the results in a dataframe and then show the first 10 records client = bigquery.Client() query = "SELECT sentiment, COUNT(*) AS count FROM `gemini_demo.cleaned_data_view` WHERE sentiment IN ('positive', 'negative') GROUP BY sentiment;" query_job = client.query(query) results = query_job.result().to_dataframe() results.head(10) -
Ejecuta esta celda.
El resultado de ejecutar la celda es una tabla con la cantidad total de opiniones positivas y negativas.
-
Crea una celda nueva para definir las variables del informe.
# Define variable for the report. sentiment = results["sentiment"].tolist() count = results["count"].tolist() -
Ejecuta esta celda. No hay ningún resultado.
-
Crea una celda nueva para generar el informe.
# Task 6.7 - Build the report. plt.bar(sentiment, count, color='skyblue') plt.xlabel("Sentiment") plt.ylabel("Total Count") plt.title("Bar Chart from BigQuery Data") plt.show() -
Ejecuta esta celda.
El resultado es un gráfico de barras con los recuentos de opiniones positivas y negativas.
-
Como alternativa, puedes generar un informe sencillo codificado por color de las valoraciones positivas y negativas usando el código incluido a continuación:
# Create an HTML table for the counts of negative and positive sentiment and color codes the results. html_counts = f"""
""" # Display the HTML tables display(HTML(html_counts))Negative Positive {count[0]} {count[1]}
Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 7. Responde a las opiniones de los clientes
Data Beans quiere experimentar con opiniones de los clientes usando imágenes y grabaciones de audio. En esta sección del notebook, usarás CloudStorage, BigQuery, Gemini Flash y Python para realizar análisis de sentimientos con las opiniones de los clientes que proporcionó Data Beans como archivos de audio y de imágenes. Y, a partir del análisis resultante, generarás respuestas de atención al cliente que se enviarán a los clientes para agradecerles la opinión y contarles las medidas que puede tomar la cafetería en función de la opinión.
Harás esto a gran escala y, más adelante, con una imagen y archivo de audio para que aprendas a crear una aplicación de prueba de concepto para representantes del servicio de atención al cliente. Esto habilita la estrategia "con interacción humana" en el proceso de comentarios de los clientes. Por lo tanto, los representantes del servicio de atención al cliente pueden tomar medidas tanto con el cliente como con las distintas cafeterías.
Procesa archivos de audio a gran escala con respuestas de JSON
-
Crea una celda nueva para realizar análisis de opiniones con archivos de audio y responder al cliente.
# Conduct sentiment analysis on audio files and respond to the customer. vertexai.init(project="{{{project_0.project_id|Project ID}}}", location="{{{project_0.default_region|region}}}") model = GenerativeModel(model_name="gemini-1.5-flash") prompt = """ Please provide a transcript for the audio. Then provide a summary for the audio. Then identify the keywords in the transcript. Be concise and short. Do not make up any information that is not part of the audio and do not be verbose. Then determine the sentiment of the audio: positive, neutral or negative. Also, you are a customr service representative. How would you respond to this customer review? From the customer reviews provide actions that the location can take to improve. The response and the actions should be simple, and to the point. Do not include any extraneous characters in your response. Answer in JSON format with five keys: transcript, summary, keywords, sentiment, response and actions. Transcript should be a string, summary should be a sting, keywords should be a list, sentiment should be a string, customer response should be a string and actions should be string. """ bucket_name = "{{{project_0.project_id|Project ID}}}-bucket" folder_name = 'gsp1249/audio' # Include the trailing '/' def list_mp3_files(bucket_name, folder_name): storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) print('Accessing ', bucket, ' with ', storage_client) blobs = bucket.list_blobs(prefix=folder_name) mp3_files = [] for blob in blobs: if blob.name.endswith('.mp3'): mp3_files.append(blob.name) return mp3_files file_names = list_mp3_files(bucket_name, folder_name) if file_names: print("MP3 files found:") print(file_names) for file_name in file_names: audio_file_uri = f"gs://{bucket_name}/{file_name}" print('Processing file at ', audio_file_uri) audio_file = Part.from_uri(audio_file_uri, mime_type="audio/mpeg") contents = [audio_file, prompt] response = model.generate_content(contents) print(response.text) else: print("No MP3 files found in the specified folder.") Mencionaremos algunos puntos clave relacionados con esta celda:
- Con la primera línea, se inicializa Vertex AI con tu ID del proyecto y región, deberás completar esos valores.
- Con la línea que viene después, se crea un modelo en BigQuery, llamado model, basado en el modelo de Gemini Flash.
- Luego, defines una instrucción que debe usar el modelo de Gemini Flash. Con la instrucción, se convierte el archivo de audio en texto, se analiza la opinión del texto y, una vez que se completa el análisis, se crea una respuesta para cada archivo y cliente.
- Debes definir el bucket como la variable de cadena bucket_name. Nota: folder_name también se usa para la subcarpeta gsp1249/audio. No lo cambies.
- Se crea una función denominada list_mp3_files para identificar todos los archivos mp3 en el bucket. Luego, el modelo de Gemini Flash procesa los archivos en la sentencia "if".
-
Ejecuta esta celda.
Como consecuencia, se analizan los 5 archivos de audio, y el resultado del análisis se proporciona como una respuesta JSON. La respuesta JSON podría analizarse según corresponda y enrutarse a las aplicaciones adecuadas para responderle al cliente o a la ubicación con medidas para mejorar.
Crea una aplicación para representantes del servicio de atención al cliente
En esta sección del lab, aprenderás a crear una aplicación para atención al cliente basada en el análisis de opiniones negativas. Harás lo siguiente:
- Usa la misma instrucción que hay en la celda anterior para analizar una sola opinión negativa.
- Genera la transcripción del archivo de audio de la opinión negativa, crea el objeto JSON a partir del resultado del modelo con el formato adecuado y guarda las partes específicas del objeto JSON como variables de Python para usarlas con HTML en tu aplicación.
- Genera la tabla HTML, sube la imagen que cargó el cliente como parte de la opinión y carga el archivo de audio en el reproductor.
- Muestra la tabla HTML con la imagen y el reproductor del archivo de audio.
-
Crea una celda nueva y, luego, ingresa el siguiente código para generar la transcripción del archivo de audio de la opinión negativa y crear el objeto JSON y las variables asociadas.
# Generate the transcript for the negative review audio file, create the JSON object, and associated variables audio_file_uri = f"gs://{bucket_name}/{folder_name}/data-beans_review_7061.mp3" print(audio_file_uri) audio_file = Part.from_uri(audio_file_uri, mime_type="audio/mpeg") contents = [audio_file, prompt] response = model.generate_content(contents) print('Generating Transcript...') #print(response.text) results = response.text # print("your results are", results, type(results)) print('Transcript created...') print('Transcript ready for analysis...') json_data = results.replace('```json', '') json_data = json_data.replace('```', '') jason_data = '"""' + results + '"""' # print(json_data, type(json_data)) data = json.loads(json_data) # print(data) transcript = data["transcript"] summary = data["summary"] sentiment = data["sentiment"] keywords = data["keywords"] response = data["response"] actions = data["actions"] Mencionaremos algunos puntos clave relacionados con esta celda:
- El código en esta celda selecciona un archivo de audio específico de Cloud Storage (data-beans_review_7061.mp3).
- Luego, envía el archivo a la instrucción en la celda anterior etiquetada Task 7.1 para que lo procese el modelo de Gemini Flash.
- La respuesta del modelo se extrae en formato JSON.
- Luego, se analizan los datos JSON y se almacenan las variables de Python de transcripción, resumen, opinión, palabras clave, respuesta del cliente y medidas.
-
Ejecuta la celda.
El resultado es mínimo, tan solo el URI del archivo de audio que se procesó y los mensajes de procesamiento.
-
Crea un HTML basado en la tabla a partir de los valores seleccionados y sube el archivo de audio que incluye la opinión negativa al reproductor.
# Create an HTML table (including the image) from the selected values. html_string = f""" customer_id: 7061 - @coffee_lover789
""" print('The table has been created.'){transcript} {sentiment} feedback {keywords[0]} {keywords[1]} {keywords[2]} {keywords[3]} Customer summary:{summary} Recommended actions:{actions} Suggested Response:{response} Mencionaremos algunos puntos clave relacionados con esta celda:
- El código en la celda crea una cadena de tablas HTML.
- Luego, inserta los valores de transcripción, opinión, palabras clave, imagen, resumen, medidas y respuesta en las celdas de la tabla.
- El código también aplica el estilo a los elementos de la tabla.
- Cuando se ejecuta la celda, el resultado indica cuándo se creó la tabla.
-
Busca la etiqueta
<td style="padding:10px;">con el resultado{summary}incluido. Agrega una línea de código nueva antes de la etiqueta. -
Pega
<td rowspan="3" style="padding: 10px;"><img src="<authenticated url here>" alt="Customer Image" style="max-width: 300px;"></td>en la línea nueva de código. -
Busca la URL autenticada del archivo image_7061.png. Ve a Cloud Storage, selecciona el único bucket que tienes ahí, la carpeta de imágenes y, luego, haz clic en la imagen.
-
En la página que aparece, copia la URL autenticada de la imagen.
-
Regresa al notebook de Python en BigQuery. Reemplaza
<authenticated url here>con la URL autenticada real en el código que acabas de pegar. -
Ejecuta la celda.
De nuevo, el resultado es mínimo. Tan solo algunos mensajes de procesamiento que indican que se completaron todos los pasos.
-
Crea una celda nueva para descargar el archivo de audio y cargarlo en el reproductor, usando el código incluido a continuación:
# Download the audio file from Google Cloud Storage and load into the player storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) blob = bucket.blob(f"{folder_name}/data-beans_review_7061.mp3") audio_bytes = io.BytesIO(blob.download_as_bytes()) # Assuming a sample rate of 44100 Hz (common for MP3 files) sample_rate = 44100 print('The audio file is loaded in the player.') Mencionaremos algunos puntos clave relacionados con esta celda:
- El código en esta celda accede al bucket de Cloud Storage y recupera el archivo de audio específico (data-beans_review_7061.mp3).
- Después, descarga el archivo como una transmisión de bytes y determina la tasa de muestreo del archivo para que pueda reproducirse directamente en el reproductor del notebook.
- Cuando se ejecuta la celda, el resultado es un mensaje que dice que se cargó el archivo de audio al reproductor y que está listo para su reproducción.
-
Ejecuta la celda.
-
Crea una celda nueva y escribe el código incluido a continuación:
# Task 7.5 - Build the mockup as output to the cell. print('Analysis complete. Review the results below.') display(HTML(html_string)) display(Audio(audio_bytes.read(), rate=sample_rate, autoplay=True)) -
Ejecuta la celda.
Aquí es donde ocurre la magia. El método de visualización se usa para mostrar el HTML y el archivo de audio que se cargó en el reproductor. Revisa el resultado de la celda. Debe ser idéntico a la imagen que se incluye a continuación:
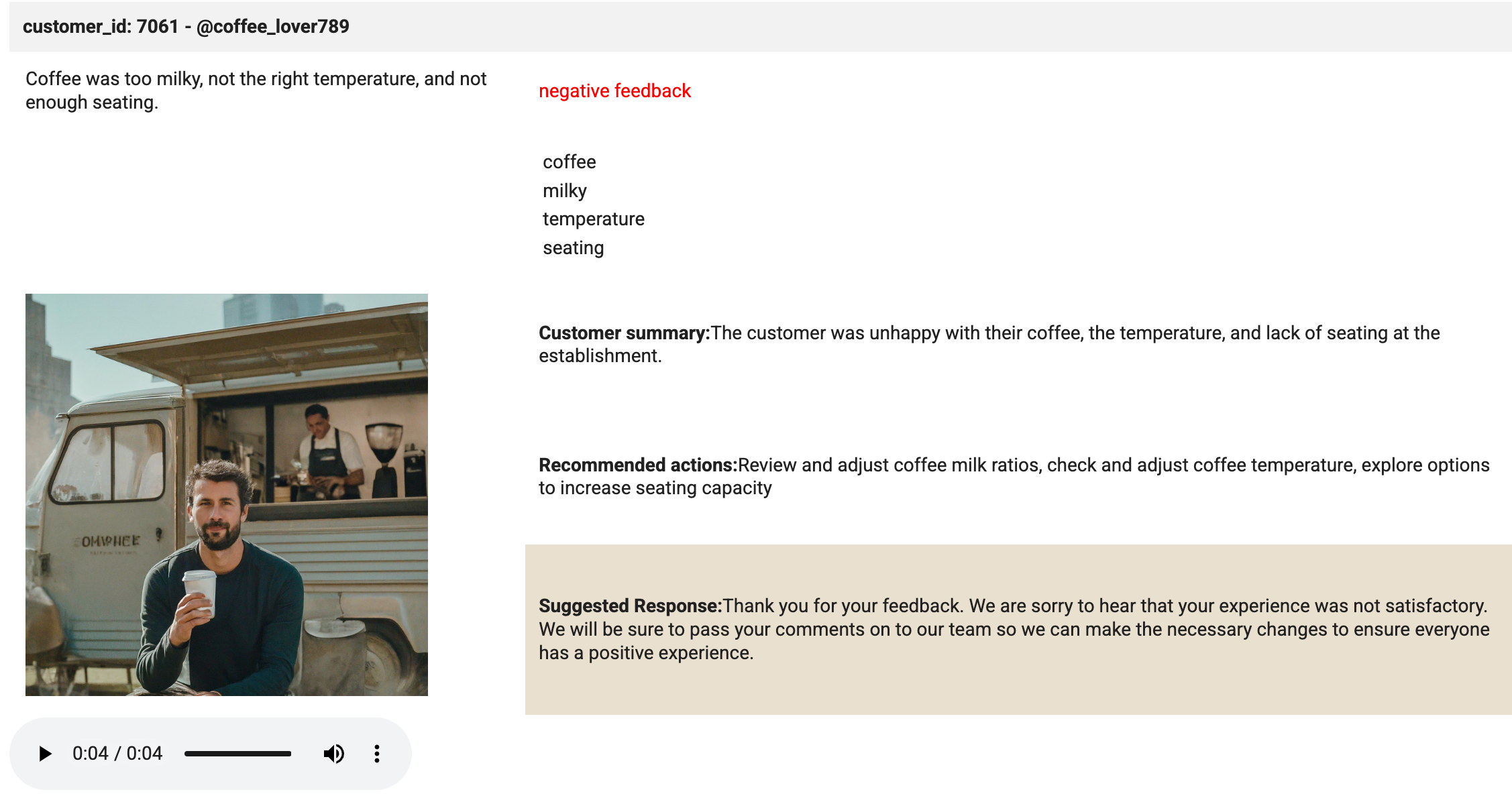
Haz clic en Revisar mi progreso para verificar el objetivo.
¡Felicitaciones!
Creaste correctamente una conexión al recurso de Cloud en BigQuery. También creaste un conjunto de datos, tablas y modelos para enviarle una instrucción a Gemini para que analice los sentimientos y las palabras clave de las opiniones de los clientes. Por último, usaste Gemini para analizar opiniones de clientes basadas en audios y generar resúmenes y palabras clave para responder las opiniones de los clientes en una aplicación de atención al cliente.
Próximos pasos/Más información
- Introducción a BigQuery ML
- Escala el aprendizaje automático con el motor de inferencia de BigQuery ML: Blog
- Modelos de Gemini
- IA generativa
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 26 de julio de 2024
Prueba más reciente del lab: 26 de julio de 2024
Copyright 2024 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.

