체크포인트
Create BigQuery Python notebook and connect to runtime
/ 10
Create the cloud resource connection and grant IAM role
/ 10
Review images, dataset, and grant IAM role to service account
/ 10
Create the dataset and customer reviews table in BigQuery
/ 30
Create the Gemini Pro model in BigQuery
/ 10
Prompt Gemini to analyze customer reviews for keywords and sentiment
/ 20
Respond to customer reviews
/ 10
Python 노트북을 사용해 Gemini로 고객 리뷰 분석하기
GSP1249

개요
이 실습에서는 BigQuery 머신러닝을 원격 모델(Gemini Pro)과 함께 사용하여 고객 리뷰에서 키워드를 추출하고 고객 감정을 평가하는 방법을 알아봅니다.
BigQuery는 데이터의 가치를 극대화하는 데 도움이 되는 완전 관리형 AI 지원 데이터 분석 플랫폼으로서 멀티 엔진, 멀티 형식, 멀티 클라우드로 설계되었습니다. 주요 기능 중 하나인 BigQuery 머신러닝을 통해 SQL 쿼리 또는 Colab Enterprise 노트북을 사용하여 머신러닝(ML) 모델을 만들고 실행할 수 있습니다.
Gemini는 Google DeepMind에서 개발한 생성형 AI 모델 제품군으로, 멀티모달 사용 사례를 위해 설계되었습니다. Gemini API를 통해 Gemini Pro, Gemini Pro Vision 및 Gemini Flash 모델에 액세스할 수 있습니다.
이 실습을 마치면 BigQuery 내의 Colab Enterprise 노트북에서 Python 기반 고객 서비스 애플리케이션을 빌드하고, Gemini Flash 모델을 사용하여 오디오 기반 고객 리뷰에 답변할 수 있습니다.
목표
이 실습에서는 다음을 수행하는 방법에 대해 알아봅니다.
- Colab Enterprise를 사용하여 BigQuery에서 Python 노트북 만들기
- BigQuery에서 Cloud 리소스 연결 생성하기
- BigQuery에서 데이터 세트 및 테이블 만들기
- BigQuery에서 Gemini 원격 모델 만들기
- 텍스트 기반 고객 리뷰에서 키워드와 감정(긍정 또는 부정)을 분석하도록 Gemini에 프롬프트 입력하기
- 긍정적 리뷰와 부정적 리뷰의 개수가 포함된 보고서 생성하기
- 대규모로 고객 리뷰에 답변하기
- 고객 서비스 담당자가 오디오 기반 고객 리뷰에 답변할 수 있는 애플리케이션 만들기
설정 및 요건
실습 시작 버튼을 클릭하기 전에
다음 안내를 확인하세요. 실습에는 시간 제한이 있으며 일시중지할 수 없습니다. 실습 시작을 클릭하면 타이머가 시작됩니다. 이 타이머에는 Google Cloud 리소스를 사용할 수 있는 시간이 얼마나 남았는지 표시됩니다.
실무형 실습을 통해 시뮬레이션이나 데모 환경이 아닌 실제 클라우드 환경에서 직접 실습 활동을 진행할 수 있습니다. 실습 시간 동안 Google Cloud에 로그인하고 액세스하는 데 사용할 수 있는 새로운 임시 사용자 인증 정보가 제공됩니다.
이 실습을 완료하려면 다음을 준비해야 합니다.
- 표준 인터넷 브라우저 액세스 권한(Chrome 브라우저 권장)
- 실습을 완료하기에 충분한 시간---실습을 시작하고 나면 일시중지할 수 없습니다.
실습을 시작하고 Google Cloud 콘솔에 로그인하는 방법
-
실습 시작 버튼을 클릭합니다. 실습 비용을 결제해야 하는 경우 결제 수단을 선택할 수 있는 팝업이 열립니다. 왼쪽에는 다음과 같은 항목이 포함된 실습 세부정보 패널이 있습니다.
- Google Cloud 콘솔 열기 버튼
- 남은 시간
- 이 실습에 사용해야 하는 임시 사용자 인증 정보
- 필요한 경우 실습 진행을 위한 기타 정보
-
Google Cloud 콘솔 열기를 클릭합니다(Chrome 브라우저를 실행 중인 경우 마우스 오른쪽 버튼으로 클릭하고 시크릿 창에서 링크 열기를 선택합니다).
실습에서 리소스가 가동되면 다른 탭이 열리고 로그인 페이지가 표시됩니다.
팁: 두 개의 탭을 각각 별도의 창으로 나란히 정렬하세요.
참고: 계정 선택 대화상자가 표시되면 다른 계정 사용을 클릭합니다. -
필요한 경우 아래의 사용자 이름을 복사하여 로그인 대화상자에 붙여넣습니다.
{{{user_0.username | "Username"}}} 실습 세부정보 패널에서도 사용자 이름을 확인할 수 있습니다.
-
다음을 클릭합니다.
-
아래의 비밀번호를 복사하여 시작하기 대화상자에 붙여넣습니다.
{{{user_0.password | "Password"}}} 실습 세부정보 패널에서도 비밀번호를 확인할 수 있습니다.
-
다음을 클릭합니다.
중요: 실습에서 제공하는 사용자 인증 정보를 사용해야 합니다. Google Cloud 계정 사용자 인증 정보를 사용하지 마세요. 참고: 이 실습에 자신의 Google Cloud 계정을 사용하면 추가 요금이 발생할 수 있습니다. -
이후에 표시되는 페이지를 클릭하여 넘깁니다.
- 이용약관에 동의합니다.
- 임시 계정이므로 복구 옵션이나 2단계 인증을 추가하지 않습니다.
- 무료 체험판을 신청하지 않습니다.
잠시 후 Google Cloud 콘솔이 이 탭에서 열립니다.

작업 1. BigQuery Python 노트북을 만들고 런타임에 연결하기
이 작업에서는 BigQuery Python 노트북을 만들고 노트북을 런타임에 연결합니다.
BigQuery Python 노트북 만들기
-
Google Cloud 콘솔의 탐색 메뉴에서 BigQuery를 클릭합니다.
-
시작 팝업에서 완료를 클릭합니다.
-
Python 노트북을 클릭합니다.
-
리전으로
을(를) 선택합니다. -
선택을 클릭합니다.
또한 탐색기의 프로젝트 아래 노트북 섹션에 Python 노트북이 추가된 것을 확인할 수 있습니다.
-
각 셀 위로 마우스를 가져가면 나타나는 휴지통 아이콘을 클릭하여 노트북에 있는 모든 셀을 삭제합니다.
완료되면 노트북이 비어 있게 되며 이제 다음 단계로 넘어갈 준비가 된 것입니다.
런타임에 연결하기
-
연결을 클릭합니다.
-
Qwiklabs 수강생 ID를 클릭합니다.
잠시만 기다려 주세요. 런타임에 연결하는 데 최대 3분이 걸릴 수 있습니다.
시간이 지나면 브라우저 창 하단에 연결 상태가 '연결됨'으로 업데이트되는 것을 확인할 수 있습니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 2. 클라우드 리소스 연결을 생성하고 IAM 역할 부여하기
BigQuery에서 클라우드 리소스 연결 생성하기
이 작업에서는 Gemini Pro 및 Gemini Flash 모델로 작업을 수행할 수 있도록 BigQuery에서 Cloud 리소스 연결을 생성합니다. 또한 역할을 통해 클라우드 리소스 연결의 서비스 계정에 IAM 권한을 부여하여 Vertex AI 서비스에 액세스할 수 있도록 합니다.
Python SDK와 Google Cloud CLI를 사용하여 리소스 연결을 만듭니다. 하지만 먼저 Python 라이브러리를 가져오고 project_id 및 리전 변수를 설정해야 합니다.
-
아래의 코드로 새 코드 셀을 만듭니다.
# Import Python libraries import vertexai from vertexai.generative_models import GenerativeModel, Part from google.cloud import bigquery from google.cloud import storage import json import io import matplotlib.pyplot as plt from IPython.display import HTML, display from IPython.display import Audio from pprint import pprint 이 코드는 Python 라이브러리를 가져옵니다.
-
이 셀을 실행합니다. 이제 라이브러리가 로드되어 사용할 수 있는 상태가 되었습니다.
-
아래의 코드로 새 코드 셀을 만듭니다.
# Set Python variables for project_id and region project_id = "{{{project_0.project_id|Project ID}}}" region = " {{{ project_0.default_region | "REGION" }}}" 참고: project_id 및 리전은 여기에 SQL 변수가 아닌 Python 변수로 저장되므로, Python 코드를 사용하는 셀에서만 참조할 수 있으며 SQL 코드를 사용하는 셀에서는 참조할 수 없습니다. -
이 셀을 실행합니다. project_id 및 리전 변수가 설정되었습니다.
-
아래의 코드로 새 코드 셀을 만듭니다.
# Create the resource connection !bq mk --connection \ --connection_type=CLOUD_RESOURCE \ --location=US \ gemini_conn 이 코드는 Google Cloud CLI 명령어
bq mk --conection을 사용하여 리소스 연결을 생성합니다. -
이 셀을 실행합니다. 이제 리소스 연결이 생성되었습니다.
-
탐색기의 프로젝트 ID 옆에 있는 작업 보기 버튼을 클릭합니다.
-
콘텐츠 새로고침을 선택합니다.
-
외부 연결을 펼칩니다. 이제
us.gemini_conn이 외부 연결로 나열됩니다. -
us.gemini_conn을 클릭합니다.
-
연결 정보 창에서 서비스 계정 ID를 다음 작업에 사용할 수 있도록 텍스트 파일에 복사합니다.
연결의 서비스 계정에 Vertex AI 사용자 역할 부여하기
-
콘솔의 탐색 메뉴에서 IAM 및 관리자를 클릭합니다.
-
액세스 권한 부여를 클릭합니다.
-
앞에서 복사한 서비스 계정 ID를 새 주 구성원 필드에 입력합니다.
-
역할 선택 필드에서 Vertex AI를 선택한 후 Vertex AI 사용자 역할을 선택합니다.
-
저장을 클릭합니다.
이렇게 하면 이제 서비스 계정에 Vertex AI 사용자 역할이 포함됩니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 3. 오디오 파일, 데이터 세트를 검토하고 서비스 계정에 IAM 역할 부여하기
이 작업에서는 데이터 세트와 오디오 파일을 검토한 다음, 클라우드 리소스 연결의 서비스 계정에 IAM 권한을 부여합니다.
Cloud Storage의 오디오 파일, 이미지 파일, 고객 리뷰 데이터 세트 검토하기
리소스 연결 서비스 계정에 권한을 부여하기 전에 데이터 세트와 이미지 파일을 검토합니다.
-
Google Cloud 콘솔에서 탐색 메뉴(
)를 선택한 다음 Cloud Storage를 선택합니다.
-
-bucket 버킷을 클릭합니다. -
버킷에는 gsp1249 폴더가 있습니다. 폴더를 엽니다. 다음 5개 항목이 표시됩니다.
-
audio폴더에는 분석할 모든 오디오 파일이 들어 있습니다. audio 폴더에 액세스하여 오디오 파일을 검토하세요. -
customer_reviews.csv파일은 텍스트 기반 고객 리뷰가 포함되어 있는 데이터 세트입니다. -
images폴더에는 이 실습 후반부에서 사용할 이미지 파일이 들어 있습니다. 이 폴더에 액세스하여 포함된 이미지 파일을 확인해 보세요. -
notebook.ipynb는 이 실습에서 만든 노트북의 사본입니다. 필요에 따라 자유롭게 검토하세요.
참고: 인증 URL을 사용하여 각 항목을 다운로드하고 검토할 수 있습니다. -
연결의 서비스 계정에 IAM 스토리지 객체 관리자 역할 부여하기
BigQuery에서 작업을 시작하기 전에 리소스 연결의 서비스 계정에 IAM 권한을 부여하면 쿼리를 실행할 때 액세스 거부 오류가 발생하지 않습니다.
-
버킷의 루트로 돌아갑니다.
-
권한을 클릭합니다.
-
액세스 권한 부여를 클릭합니다.
-
앞에서 복사한 서비스 계정 ID를 새 주 구성원 필드에 입력합니다.
-
역할 선택 필드에 스토리지 객체를 입력한 다음 스토리지 객체 관리자 역할을 선택합니다.
-
저장을 클릭합니다.
이렇게 하면 이제 서비스 계정에 스토리지 객체 관리자 역할이 포함됩니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 4. BigQuery에서 데이터 세트 및 고객 리뷰 테이블 만들기
이 작업에서는 프로젝트의 데이터 세트와 고객 리뷰에 대한 테이블을 만듭니다.
데이터 세트 만들기
데이터 세트에 대해 다음 속성을 사용합니다.
| 필드 | 값 |
|---|---|
| 데이터 세트 ID | gemini_demo |
| 위치 유형 | 멀티 리전 선택 |
| 멀티 리전 | US 선택 |
-
BigQuery의 Python 노트북으로 돌아갑니다.
-
아래의 코드로 새 코드 셀을 만듭니다.
# Create the dataset %%bigquery CREATE SCHEMA IF NOT EXISTS `{{{project_0.project_id|Project ID}}}.gemini_demo` OPTIONS(location="US"); 코드가
%%bigquery로 시작한다는 점에 주목하세요. 이는 이 문 바로 뒤에 오는 코드가 SQL 코드라는 것을 Python에 알려줍니다. -
이 셀을 실행합니다.
그러면 SQL 코드가 BigQuery 탐색기의 프로젝트 아래에 나열된 US 리전에 있는 프로젝트에
gemini_demo데이터 세트를 생성합니다.
샘플 데이터로 고객 리뷰 테이블 만들기
SQL 쿼리를 사용하여 고객 리뷰 테이블을 만듭니다.
-
아래의 코드로 새 코드 셀을 만듭니다.
# Create the customer reviews table %%bigquery LOAD DATA OVERWRITE gemini_demo.customer_reviews (customer_review_id INT64, customer_id INT64, location_id INT64, review_datetime DATETIME, review_text STRING, social_media_source STRING, social_media_handle STRING) FROM FILES ( format = 'CSV', uris = ['gs://{{{project_0.project_id|Project ID}}}-bucket/gsp1249/customer_reviews.csv']); -
이 셀을 실행합니다.
이렇게 하면 데이터 세트의 각 리뷰에 대한
customer_review_id,customer_id,location_id,review_datetime,review_text,social_media_source,social_media_handle이 포함된 샘플 고객 리뷰 데이터로customer_reviews테이블이 만들어집니다. -
탐색기에서 customer_reviews 테이블을 클릭하고 스키마와 세부정보를 검토합니다.
-
아래의 코드로 새 코드 셀을 만들고 테이블을 쿼리하여 레코드를 검토합니다.
# Create the customer reviews table %%bigquery SELECT * FROM `gemini_demo.customer_reviews` ORDER BY review_datetime -
이 셀을 실행합니다.
이렇게 하면 모든 열이 포함된 테이블의 레코드가 표시됩니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 5. BigQuery에서 Gemini Pro 모델 만들기
이제 테이블이 만들어졌으므로 테이블로 작업을 수행할 수 있습니다. 이 작업에서는 BigQuery에서 Gemini Pro 모델을 만듭니다.
-
Python 노트북으로 돌아갑니다.
-
아래의 코드로 새 코드 셀을 만듭니다.
# Create the customer reviews table %%bigquery CREATE OR REPLACE MODEL `gemini_demo.gemini_pro` REMOTE WITH CONNECTION `us.gemini_conn` OPTIONS (endpoint = 'gemini-pro') -
이 셀을 실행합니다.
이렇게 하면
gemini_pro모델이 생성되고 모델 섹션의gemini_demo데이터 세트에 해당 모델이 추가된 것을 볼 수 있습니다. -
탐색기에서 gemini_pro 모델을 클릭하고 스키마와 세부정보를 검토합니다.
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 6. 고객 리뷰에서 키워드와 감정을 분석하도록 Gemini에 프롬프트 입력하기
이 작업에서는 Gemini Pro 모델을 사용하여 각 고객 리뷰의 감정(긍정 또는 부정)을 분석합니다.
고객 리뷰에서 긍정적 또는 부정적 감정 분석하기
-
아래의 코드로 새 코드 셀을 만듭니다.
# Create the sentiment analysis table %%bigquery CREATE OR REPLACE TABLE `gemini_demo.customer_reviews_analysis` AS ( SELECT ml_generate_text_llm_result, social_media_source, review_text, customer_id, location_id, review_datetime FROM ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_pro`, ( SELECT social_media_source, customer_id, location_id, review_text, review_datetime, CONCAT( 'Classify the sentiment of the following text as positive or negative.', review_text, "In your response don't include the sentiment explanation. Remove all extraneous information from your response, it should be a boolean response either positive or negative.") AS prompt FROM `gemini_demo.customer_reviews` ), STRUCT( 0.2 AS temperature, TRUE AS flatten_json_output))); -
이 셀을 실행합니다.
이 쿼리는
customer_reviews테이블에서 고객 리뷰를 가져와 프롬프트를 구성한 다음 이를gemini_pro모델과 함께 사용하여 각 리뷰에 담긴 감정을 분류합니다. 결과는 새 테이블customer_reviews_analysis에 저장되므로 나중에 추가 분석에 사용할 수 있습니다.잠시만 기다려 주세요. 모델이 고객 리뷰 레코드를 처리하는 데 약 30초가 소요됩니다.
모델이 처리를 완료하면
customer_reviews_analysis테이블이 생성됩니다. -
탐색기에서 customer_reviews_analysis 테이블을 클릭하고 스키마와 세부정보를 검토합니다.
-
아래의 코드로 새 코드 셀을 만듭니다.
# Pull the first 100 records from the customer_reviews_analysis table %%bigquery SELECT * FROM `gemini_demo.customer_reviews_analysis` ORDER BY review_datetime -
이 셀을 실행합니다.
이렇게 하면
ml_generate_text_llm_result열(감정 분석 포함), 고객 리뷰 텍스트, 고객 ID, 위치 ID가 포함된 행이 생성됩니다.레코드를 살펴봅니다. 마침표, 여분의 공백과 같은 불필요한 문자로 인해 긍정 또는 부정에 대한 일부 결과의 형식이 올바르게 지정되지 않았을 수 있습니다. 아래의 뷰를 사용하여 레코드를 정리할 수 있습니다.
레코드를 정리할 뷰 만들기
-
아래의 코드로 새 코드 셀을 만듭니다.
# Sanitize the records within a new view %%bigquery CREATE OR REPLACE VIEW gemini_demo.cleaned_data_view AS SELECT REPLACE(REPLACE(LOWER(ml_generate_text_llm_result), '.', ''), ' ', '') AS sentiment, REGEXP_REPLACE( REGEXP_REPLACE( REGEXP_REPLACE(social_media_source, r'Google(\+|\sReviews|\sLocal|\sMy\sBusiness|\sreviews|\sMaps)?', 'Google'), 'YELP', 'Yelp' ), r'SocialMedia1?', 'Social Media' ) AS social_media_source, review_text, customer_id, location_id, review_datetime FROM `gemini_demo.customer_reviews_analysis`; -
이 셀을 실행합니다.
이 코드는
cleaned_data_view뷰를 생성하며 감정 결과, 리뷰 텍스트, 고객 ID, 위치 ID를 포함합니다. 그런 다음 감정 결과(긍정 또는 부정)를 가져와 모든 문자를 소문자로 만들고 마침표, 여분의 공백과 같은 불필요한 문자를 삭제합니다. 이렇게 생성된 뷰를 사용하면 이 실습의 후반부에서 추가 분석을 더 쉽게 수행할 수 있습니다. -
아래의 코드로 새 코드 셀을 만듭니다.
# Pull the first 100 records from the cleaned_data_view view %%bigquery SELECT * FROM `gemini_demo.cleaned_data_view` ORDER BY review_datetime -
이 셀을 실행합니다.
이제
sentiment열에 긍정적 리뷰와 부정적 리뷰에 대해 정리된 값이 표시됩니다. 이후 단계에서 이 뷰를 사용하여 보고서를 빌드할 수 있습니다.
긍정적 리뷰와 부정적 리뷰의 개수에 대한 보고서 만들기
Python과 Matplotlib 라이브러리를 사용하여 긍정적 리뷰와 부정적 리뷰의 개수에 대한 막대 그래프 보고서를 만들 수 있습니다.
-
새 코드 셀을 만들어 BigQuery 클라이언트를 사용하여 긍정적 리뷰와 부정적 리뷰에 대한 cleaned_data_view를 쿼리하고, 리뷰를 감정에 따라 그룹화하여, DataFrame에 결과를 저장합니다.
# Task 6.5 - Create the BigQuery client, and query the cleaned data view for positive and negative reviews, store the results in a dataframe and then show the first 10 records client = bigquery.Client() query = "SELECT sentiment, COUNT(*) AS count FROM `gemini_demo.cleaned_data_view` WHERE sentiment IN ('positive', 'negative') GROUP BY sentiment;" query_job = client.query(query) results = query_job.result().to_dataframe() results.head(10) -
이 셀을 실행합니다.
셀을 실행하면 긍정적 리뷰와 부정적 리뷰의 총 개수가 포함된 테이블 출력이 표시됩니다.
-
새 셀을 만들어 보고서의 변수를 정의합니다.
# Define variable for the report. sentiment = results["sentiment"].tolist() count = results["count"].tolist() -
이 셀을 실행합니다. 출력이 없습니다.
-
새 셀을 만들어 보고서를 빌드합니다.
# Task 6.7 - Build the report. plt.bar(sentiment, count, color='skyblue') plt.xlabel("Sentiment") plt.ylabel("Total Count") plt.title("Bar Chart from BigQuery Data") plt.show() -
이 셀을 실행합니다.
이렇게 하면 긍정적 리뷰와 부정적 리뷰의 개수가 포함된 막대 그래프가 표시됩니다.
-
또는 아래의 코드를 사용하여 부정적 감정과 긍정적 감정의 개수에 대해 색상으로 구분된 간단한 보고서를 빌드할 수도 있습니다.
# Create an HTML table for the counts of negative and positive sentiment and color codes the results. html_counts = f"""
""" # Display the HTML tables display(HTML(html_counts))Negative Positive {count[0]} {count[1]}
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
작업 7. 고객 리뷰에 답변하기
Data Beans는 이미지와 오디오 녹음을 사용하여 고객 리뷰를 가지고 실험을 하려고 합니다. 이 노트북의 본 섹션에서는 Cloud Storage, BigQuery, Gemini Flash, Python을 사용하여 이미지와 오디오 파일로 Data Beans에 제공된 고객 리뷰에 대해 감정 분석을 수행합니다. 그리고 이러한 분석을 통해 고객에게 리뷰에 대한 감사를 전하는 고객 서비스 답변과 커피숍이 리뷰에 따라 취할 수 있는 조치를 생성합니다.
고객 서비스 담당자를 위한 개념 증명 애플리케이션을 만드는 방법을 배울 수 있도록 이 작업을 대규모로 수행해 보기도 하고, 나중에 하나의 이미지 및 오디오 파일로 수행해 보기도 하겠습니다. 이를 통해 고객 피드백 프로세스에 '인간 참여형(Human-In-The-Loop)' 전략을 사용할 수 있으며, 고객 서비스 담당자는 고객과 개별 커피숍 모두에 조치를 취할 수 있습니다.
JSON 응답을 사용하여 오디오 파일을 대규모로 처리하기
-
새로운 셀을 만들어 오디오 파일에 대해 감정 분석을 수행하고 고객에게 답변합니다.
# Conduct sentiment analysis on audio files and respond to the customer. vertexai.init(project="{{{project_0.project_id|Project ID}}}", location="{{{project_0.default_region|region}}}") model = GenerativeModel(model_name="gemini-1.5-flash") prompt = """ Please provide a transcript for the audio. Then provide a summary for the audio. Then identify the keywords in the transcript. Be concise and short. Do not make up any information that is not part of the audio and do not be verbose. Then determine the sentiment of the audio: positive, neutral or negative. Also, you are a customr service representative. How would you respond to this customer review? From the customer reviews provide actions that the location can take to improve. The response and the actions should be simple, and to the point. Do not include any extraneous characters in your response. Answer in JSON format with five keys: transcript, summary, keywords, sentiment, response and actions. Transcript should be a string, summary should be a sting, keywords should be a list, sentiment should be a string, customer response should be a string and actions should be string. """ bucket_name = "{{{project_0.project_id|Project ID}}}-bucket" folder_name = 'gsp1249/audio' # Include the trailing '/' def list_mp3_files(bucket_name, folder_name): storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) print('Accessing ', bucket, ' with ', storage_client) blobs = bucket.list_blobs(prefix=folder_name) mp3_files = [] for blob in blobs: if blob.name.endswith('.mp3'): mp3_files.append(blob.name) return mp3_files file_names = list_mp3_files(bucket_name, folder_name) if file_names: print("MP3 files found:") print(file_names) for file_name in file_names: audio_file_uri = f"gs://{bucket_name}/{file_name}" print('Processing file at ', audio_file_uri) audio_file = Part.from_uri(audio_file_uri, mime_type="audio/mpeg") contents = [audio_file, prompt] response = model.generate_content(contents) print(response.text) else: print("No MP3 files found in the specified folder.") 이 셀의 몇 가지 핵심 사항은 다음과 같습니다.
- 첫 번째 줄은 프로젝트 ID와 리전을 사용하여 Vertex AI를 초기화합니다. 여러분은 이 값을 채워야 합니다.
- 다음 줄은 Gemini Flash 모델을 기반으로 BigQuery에 model이라는 모델을 만듭니다.
- 그런 다음 Gemini Flash 모델에서 사용할 프롬프트를 정의합니다. 프롬프트는 오디오 파일을 텍스트로 효과적으로 변환한 다음, 텍스트의 감정을 분석하고, 분석이 완료되면 각 파일에 대해 고객 답변을 생성합니다.
- 버킷은 bucket_name 문자열 변수로 설정해야 합니다. 참고: folder_name은 gsp1249/audio 하위 폴더에도 사용됩니다. 변경하지 마세요.
- list_mp3_files라는 함수가 생성되어 버킷 내의 모든 mp3 파일을 식별합니다. 그런 다음 Gemini Flash 모델이 if 문 내에서 이러한 파일을 처리합니다.
-
이 셀을 실행합니다.
이렇게 하면 5개의 오디오 파일이 모두 분석되고 분석의 출력이 JSON 응답으로 제공됩니다. JSON 응답을 적절히 파싱하고 적절한 애플리케이션으로 라우팅하여 고객에게 응답하거나 개선 조치와 함께 해당 위치에 응답을 제공할 수 있습니다.
고객 서비스 담당자를 위한 애플리케이션 만들기
이 실습 섹션에서는 부정적 리뷰 분석을 기반으로 고객 서비스 애플리케이션을 만드는 방법을 알아봅니다. 실습할 내용은 다음과 같습니다.
- 이전 셀과 동일한 프롬프트를 사용하여 하나의 부정적인 리뷰 분석하기
- 부정적 리뷰 오디오 파일에서 스크립트를 생성하고, 적절한 형식을 사용하여 모델 출력으로부터 JSON 객체를 만든 다음, JSON 객체의 특정 부분을 Python 변수로 저장하여 HTML과 함께 애플리케이션의 일부로 사용할 수 있도록 합니다.
- HTML 테이블을 생성하고, 고객이 리뷰를 위해 업로드한 이미지를 로드하고, 플레이어에서 오디오 파일을 로드합니다.
- 이미지와 오디오 파일의 플레이어가 있는 HTML 테이블을 표시합니다.
-
새 셀을 만들고 다음 코드를 입력하면 부정적인 리뷰 오디오 파일의 스크립트를 생성하고 JSON 객체와 관련 변수를 만들 수 있습니다.
# Generate the transcript for the negative review audio file, create the JSON object, and associated variables audio_file_uri = f"gs://{bucket_name}/{folder_name}/data-beans_review_7061.mp3" print(audio_file_uri) audio_file = Part.from_uri(audio_file_uri, mime_type="audio/mpeg") contents = [audio_file, prompt] response = model.generate_content(contents) print('Generating Transcript...') #print(response.text) results = response.text # print("your results are", results, type(results)) print('Transcript created...') print('Transcript ready for analysis...') json_data = results.replace('```json', '') json_data = json_data.replace('```', '') jason_data = '"""' + results + '"""' # print(json_data, type(json_data)) data = json.loads(json_data) # print(data) transcript = data["transcript"] summary = data["summary"] sentiment = data["sentiment"] keywords = data["keywords"] response = data["response"] actions = data["actions"] 이 셀의 몇 가지 핵심 사항은 다음과 같습니다.
- 이 셀의 코드는 Cloud Storage에서 특정 오디오 파일(data-beans_review_7061.mp3)을 선택합니다.
- 그런 다음 이 파일을 '작업 7.1'이라는 라벨이 지정된 이전 셀의 프롬프트로 입력하여 Gemini Flash 모델에서 처리하도록 합니다.
- 모델의 응답은 JSON 형식으로 추출됩니다.
- 그런 다음 JSON 데이터를 파싱하고 스크립트, 요약, 감정, 키워드, 고객 답변, 조치에 대한 Python 변수를 저장합니다.
-
셀을 실행합니다.
출력은 간단합니다. 처리된 오디오 파일의 URI와 처리 메시지만 있습니다.
-
선택된 값을 토대로 HTML 기반 테이블을 만들고 부정적인 리뷰가 포함된 오디오 파일을 플레이어에 로드합니다.
# Create an HTML table (including the image) from the selected values. html_string = f""" customer_id: 7061 - @coffee_lover789
""" print('The table has been created.'){transcript} {sentiment} feedback {keywords[0]} {keywords[1]} {keywords[2]} {keywords[3]} Customer summary:{summary} Recommended actions:{actions} Suggested Response:{response} 이 셀의 몇 가지 핵심 사항은 다음과 같습니다.
- 셀의 코드는 HTML 테이블 문자열을 구성합니다.
- 그런 다음 스크립트, 감정, 키워드, 이미지, 요약, 조치, 응답에 대한 값을 테이블 셀에 삽입합니다.
- 코드는 또한 테이블 요소에 스타일 지정을 적용합니다.
- 셀이 실행되면 셀의 출력은 테이블이 생성된 시점을 표시합니다.
-
{summary}출력이 포함된<td style="padding:10px;">태그를 찾습니다. 이 태그 앞에 새 코드 줄을 추가합니다. -
이 새 코드 줄에
<td rowspan="3" style="padding: 10px;"><img src="<authenticated url here>" alt="Customer Image" style="max-width: 300px;"></td>를 붙여넣습니다. -
image_7061.png 파일의 인증 URL을 찾습니다. Cloud Storage로 이동하여 여기에 존재하는 유일한 버킷인 images 폴더를 선택한 다음 이미지를 클릭합니다.
-
결과 페이지에서 이미지의 인증 URL을 복사합니다.
-
BigQuery의 Python 노트북으로 돌아갑니다. 방금 붙여넣은 코드에서
<authenticated url here>를 실제 인증 URL로 바꿉니다. -
셀을 실행합니다.
이번에도 출력은 간단합니다. 각 단계가 완료되었음을 나타내는 몇 가지 처리 메시지만 있습니다.
-
아래 코드를 사용하여 오디오 파일을 다운로드하고 플레이어에 로드할 새 셀을 만듭니다.
# Download the audio file from Google Cloud Storage and load into the player storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) blob = bucket.blob(f"{folder_name}/data-beans_review_7061.mp3") audio_bytes = io.BytesIO(blob.download_as_bytes()) # Assuming a sample rate of 44100 Hz (common for MP3 files) sample_rate = 44100 print('The audio file is loaded in the player.') 이 셀의 몇 가지 핵심 사항은 다음과 같습니다.
- 이 셀의 코드는 Cloud Storage 버킷에 액세스하여 특정 오디오 파일(data-beans_review_7061.mp3)을 검색합니다.
- 그런 다음 해당 파일을 바이트 스트림으로 다운로드하고, 파일의 샘플링 레이트가 노트북의 플레이어에서 직접 재생할 수 있는 샘플링 레이트인지 확인합니다.
- 셀이 실행되면 셀의 출력은 오디오 파일이 플레이어에 로드되어 재생할 준비가 되었다는 메시지로 표시됩니다.
-
셀을 실행합니다.
-
새 셀을 만들어 아래의 코드를 입력합니다.
# Task 7.5 - Build the mockup as output to the cell. print('Analysis complete. Review the results below.') display(HTML(html_string)) display(Audio(audio_bytes.read(), rate=sample_rate, autoplay=True)) -
셀을 실행합니다.
이 셀에서 마법 같은 일이 일어납니다. HTML과 플레이어에 로드된 오디오 파일을 표시하는 데 display 메서드가 사용됩니다. 셀의 출력을 검토합니다. 아래 이미지와 동일해야 합니다.
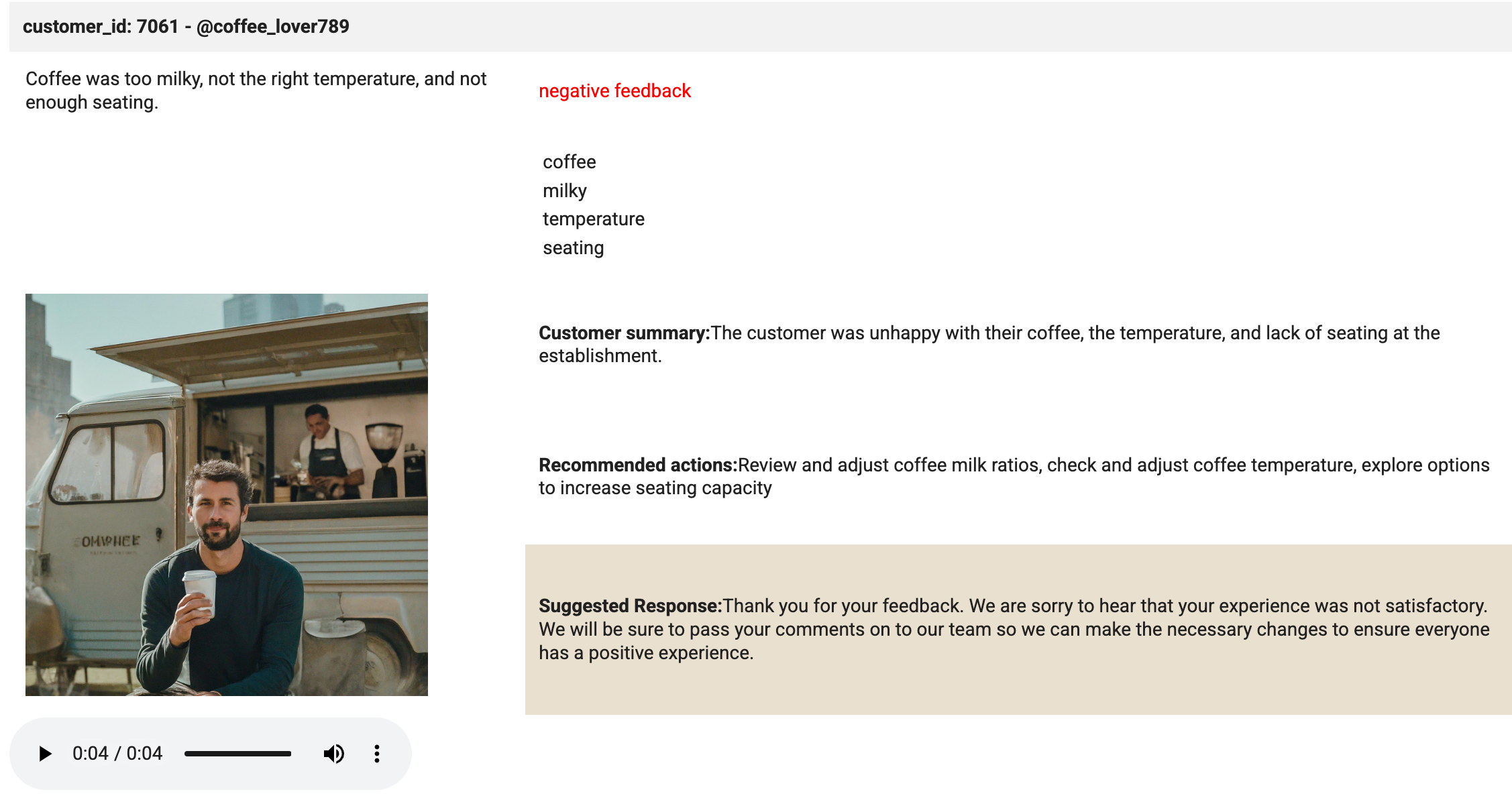
내 진행 상황 확인하기를 클릭하여 목표를 확인합니다.
수고하셨습니다.
BigQuery에서 클라우드 리소스 연결을 성공적으로 생성했습니다. 또한 Gemini에 프롬프트를 입력하여 고객 리뷰에서 감정과 키워드를 분석할 수 있도록 데이터 세트, 테이블, 모델을 만들었습니다. 마지막으로 Gemini를 사용해 오디오 기반 고객 리뷰를 분석하여 고객 서비스 애플리케이션 내에서 고객 리뷰에 답변하기 위한 요약과 키워드를 생성했습니다.
다음 단계/자세히 알아보기
Google Cloud 교육 및 자격증
Google Cloud 기술을 최대한 활용하는 데 도움이 됩니다. Google 강의에는 빠른 습득과 지속적인 학습을 지원하는 기술적인 지식과 권장사항이 포함되어 있습니다. 기초에서 고급까지 수준별 학습을 제공하며 바쁜 일정에 알맞은 주문형, 실시간, 가상 옵션이 포함되어 있습니다. 인증은 Google Cloud 기술에 대한 역량과 전문성을 검증하고 입증하는 데 도움이 됩니다.
설명서 최종 업데이트: 2024년 7월 26일
실습 최종 테스트: 2024년 7월 26일
Copyright 2024 Google LLC All rights reserved. Google 및 Google 로고는 Google LLC의 상표입니다. 기타 모든 회사명 및 제품명은 해당 업체의 상표일 수 있습니다.

