检查点
Create BigQuery Python notebook and connect to runtime
/ 10
Create the cloud resource connection and grant IAM role
/ 10
Review images, dataset, and grant IAM role to service account
/ 10
Create the dataset and customer reviews table in BigQuery
/ 30
Create the Gemini Pro model in BigQuery
/ 10
Prompt Gemini to analyze customer reviews for keywords and sentiment
/ 20
Respond to customer reviews
/ 10
使用 Python 笔记本通过 Gemini 分析顾客评价
GSP1249

概览
在本实验中,您将学习如何结合使用 BigQuery 机器学习和远程模型 (Gemini Pro) 来提取顾客评价中的关键字和评估顾客情绪。
BigQuery 是一个 AI 就绪型全托管式数据分析平台,可帮助您充分发掘数据的价值,并支持多引擎、多格式和多云。BigQuery 的主要功能之一便是机器学习,您可以使用 SQL 查询或 Colab Enterprise 笔记本创建和运行机器学习 (ML) 模型。
Gemini 是 Google DeepMind 开发的一系列生成式 AI 模型,专为多模态应用场景而设计。通过 Gemini API,您可以使用 Gemini Pro、Gemini Pro Vision 和 Gemini Flash 模型。
在本实验的最后阶段,您将在 BigQuery 中的 Colab Enterprise 笔记本中构建一个基于 Python 的客户服务应用,使用 Gemini Flash 模型来回复以音频为主的顾客评价。
目标
在本实验中,您将学习如何完成以下操作:
- 使用 Colab Enterprise 在 BigQuery 中创建 Python 笔记本。
- 在 BigQuery 中创建 Cloud 资源连接。
- 在 BigQuery 中创建数据集和表格。
- 在 BigQuery 中创建 Gemini 远程模型。
- 提示 Gemini 分析以文本为主的顾客评价的关键字和情绪(正面或负面)。
- 生成包含正面评价和负面评价数量的报告。
- 规模化回复顾客评价。
- 创建一个面向客户服务代表的应用,用于回复以音频为主的顾客评价。
设置和要求
点击“开始实验”按钮前的注意事项
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。我们会为您提供新的临时凭据,让您可以在实验规定的时间内用来登录和访问 Google Cloud。
为完成此实验,您需要:
- 能够使用标准的互联网浏览器(建议使用 Chrome 浏览器)。
- 完成实验的时间 - 请注意,实验开始后无法暂停。
如何开始实验并登录 Google Cloud 控制台
-
点击开始实验按钮。如果该实验需要付费,系统会打开一个弹出式窗口供您选择付款方式。左侧是实验详细信息面板,其中包含以下各项:
- 打开 Google Cloud 控制台按钮
- 剩余时间
- 进行该实验时必须使用的临时凭据
- 帮助您逐步完成本实验所需的其他信息(如果需要)
-
点击打开 Google Cloud 控制台(如果您使用的是 Chrome 浏览器,请右键点击并选择在无痕式窗口中打开链接)。
该实验会启动资源并打开另一个标签页,显示登录页面。
提示:请将这些标签页安排在不同的窗口中,并将它们并排显示。
注意:如果您看见选择账号对话框,请点击使用其他账号。 -
如有必要,请复制下方的用户名,然后将其粘贴到登录对话框中。
{{{user_0.username | "<用户名>"}}} 您也可以在实验详细信息面板中找到用户名。
-
点击下一步。
-
复制下面的密码,然后将其粘贴到欢迎对话框中。
{{{user_0.password | "<密码>"}}} 您也可以在实验详细信息面板中找到密码。
-
点击下一步。
重要提示:您必须使用实验提供的凭据。请勿使用您的 Google Cloud 账号凭据。 注意:在本次实验中使用您自己的 Google Cloud 账号可能会产生额外费用。 -
继续在后续页面中点击以完成相应操作:
- 接受条款及条件。
- 由于该账号为临时账号,请勿添加账号恢复选项或双重验证。
- 请勿注册免费试用。
片刻之后,系统会在此标签页中打开 Google Cloud 控制台。

任务 1:创建 BigQuery Python 笔记本并连接到运行时
在此项任务中,您会创建一个 BigQuery Python 笔记本,并将该笔记本连接到运行时。
创建 BigQuery Python 笔记本
-
在 Google Cloud 控制台中,点击导航菜单下的 BigQuery。
-
在“欢迎”弹出式窗口中点击完成。
-
点击 PYTHON 笔记本。
-
选择
区域。 -
点击选择。
您还会发现,该 Python 笔记本已添加到您的项目下探索器的笔记本部分中。
-
将光标悬停在每个单元上,然后点击出现的回收站图标,以删除笔记本中的所有单元。
完成后,笔记本应该会变为空白,您便可以执行下一步了。
连接到运行时
-
点击连接。
-
点击 Qwiklabs 学员 ID。
请耐心等待一会,最长可能需要 3 分钟才能连接到运行时。
届时,您将会看到浏览器窗口底部的连接状态更新为“已连接”。
点击检查我的进度以验证是否完成了以下目标:
任务 2:创建 Cloud 资源连接并授予 IAM 角色
在 BigQuery 中创建 Cloud 资源连接
在此项任务中,您将在 BigQuery 中创建一个 Cloud 资源连接,以便使用 Gemini Pro 和 Gemini Flash 模型。您还将通过角色为 Cloud 资源连接的服务账号授予 IAM 权限,使其能够访问 Vertex AI 服务。
您将使用 Python SDK 和 Google Cloud CLI 来创建资源连接。但首先,您需要导入 Python 库并设置 project_id 和 region 变量。
-
使用下方代码创建一个新的代码单元:
# Import Python libraries import vertexai from vertexai.generative_models import GenerativeModel, Part from google.cloud import bigquery from google.cloud import storage import json import io import matplotlib.pyplot as plt from IPython.display import HTML, display from IPython.display import Audio from pprint import pprint 这段代码将导入 Python 库。
-
运行此单元。现在库已加载成功且可供使用。
-
使用下方代码创建一个新的代码单元:
# Set Python variables for project_id and region project_id = "{{{project_0.project_id|Project ID}}}" region = " {{{ project_0.default_region | "REGION" }}}" 注意:在这段代码中,project_id 和 region 保存为 Python 变量而非 SQL 变量,因此您只能在使用 Python 代码(而非 SQL 代码)的单元中引用它们。 -
运行此单元。变量 project_id 和 region 已设置完成。
-
使用下方代码创建一个新的代码单元:
# Create the resource connection !bq mk --connection \ --connection_type=CLOUD_RESOURCE \ --location=US \ gemini_conn 这段代码将使用 Google Cloud CLI 命令
bq mk --connection创建资源连接。 -
运行此单元。资源连接现已创建。
-
点击“探索器”中项目 ID 旁边的查看操作按钮。
-
选择刷新内容。
-
展开外部连接。请注意,
us.gemini_conn现在作为外部连接列出。 -
点击 us.gemini_conn。
-
将“连接信息”窗格中的服务账号 ID 复制到一个文本文件中,以便在下个任务中使用。
向连接的服务账号授予 Vertex AI User 角色
-
在控制台中,点击导航菜单下的 IAM 和管理。
-
点击授予访问权限。
-
在新的主账号字段中,输入您之前复制的服务账号 ID。
-
在“选择角色”字段中,输入 Vertex AI,然后选择 Vertex AI User 角色。
-
点击保存。
这样该服务账号就拥有了 Vertext AI User 角色。
点击检查我的进度以验证是否完成了以下目标:
任务 3:查看音频文件、数据集并向服务账号授予 IAM 角色
在此项任务中,您将查看数据集和音频文件,然后向 Cloud 资源连接的服务账号授予 IAM 权限。
查看 Cloud Storage 上的音频文件、图片文件和顾客评价数据集
在开始执行向资源连接服务账号授予权限的任务之前,请先查看数据集和图片文件。
-
在 Google Cloud 控制台中,选择导航菜单 (
) 下的 Cloud Storage。
-
点击
-bucket 存储桶。 -
该存储桶包含 gsp1249 文件夹,请打开该文件夹。您将看到其中有五项内容:
-
audio文件夹,其中包含将要分析的所有音频文件。请自由访问此音频文件夹,查看音频文件。 -
customer_reviews.csv文件,此数据集文件包含以文本为主的顾客评价。 -
images文件夹,其中包含稍后将在本实验中用到的一个图片文件。请自由访问此文件夹,查看其中的图片文件。 -
notebook.ipynb,这是您在本实验中创建的笔记本的副本。请根据需要查看。
注意:您可以使用要求验证身份的网址来下载和查看每项内容。 -
向连接的服务账号授予 IAM Storage Object Admin 角色
在 BigQuery 中开展工作之前,向资源连接的服务账号授予 IAM 权限将确保您在运行查询时不会遇到访问遭拒的错误。
-
返回到存储桶的根目录。
-
点击权限。
-
点击授予访问权限。
-
在新的主账号字段中,输入您之前复制的服务账号 ID。
-
在“选择角色”字段中,输入 Storage Object,然后选择 Storage Object Admin 角色。
-
点击保存。
这样该服务账号就拥有了 Storage Object Admin 角色。
点击检查我的进度以验证是否完成了以下目标:
任务 4:在 BigQuery 中创建数据集和顾客评价表
在此项任务中,您将为项目创建一个数据集和顾客评价表。
创建数据集
对于数据集,您将用到以下属性:
| 字段 | 值 |
|---|---|
| 数据集 ID | gemini_demo |
| 位置类型 | 选择多区域 |
| 多区域 | 选择美国 |
-
返回到 BigQuery 中的 Python 笔记本。
-
使用下方代码创建一个新的代码单元:
# Create the dataset %%bigquery CREATE SCHEMA IF NOT EXISTS `{{{project_0.project_id|Project ID}}}.gemini_demo` OPTIONS(location="US"); 请注意,这段代码的开头为
%%bigquery,它告诉 Python 紧随该语句之后的代码为 SQL 代码。 -
运行此单元。
这段 SQL 代码将针对 BigQuery 探索器中您的项目下列出的美国地区创建
gemini_demo数据集。
创建包含示例数据的顾客评价表
要创建顾客评价表,您将会用到 SQL 查询。
-
使用下方代码创建一个新的代码单元:
# Create the customer reviews table %%bigquery LOAD DATA OVERWRITE gemini_demo.customer_reviews (customer_review_id INT64, customer_id INT64, location_id INT64, review_datetime DATETIME, review_text STRING, social_media_source STRING, social_media_handle STRING) FROM FILES ( format = 'CSV', uris = ['gs://{{{project_0.project_id|Project ID}}}-bucket/gsp1249/customer_reviews.csv']); -
运行此单元。
这样将创建包含顾客评价示例数据的
customer_reviews表,其中包括数据集中每条评价的customer_review_id、customer_id、location_id、review_datetime、review_text、social_media_source和social_media_handle。 -
在“探索器”中,点击 customer_reviews 表,查看架构和详细信息。
-
使用下方代码创建新的代码单元来查询该表,以查看评价记录。
# Create the customer reviews table %%bigquery SELECT * FROM `gemini_demo.customer_reviews` ORDER BY review_datetime -
运行此单元。
这样该表中的记录即会显示出来,所有列的数据都会列出。
点击检查我的进度以验证是否完成了以下目标:
任务 5:在 BigQuery 中创建 Gemini Pro 模型
现在表已经创建好,您可以开始处理它们了。在此项任务中,您将在 BigQuery 中创建 Gemini Pro 模型。
-
返回到 Python 笔记本。
-
使用下方代码创建一个新的代码单元:
# Create the customer reviews table %%bigquery CREATE OR REPLACE MODEL `gemini_demo.gemini_pro` REMOTE WITH CONNECTION `us.gemini_conn` OPTIONS (endpoint = 'gemini-pro') -
运行此单元。
这样将创建
gemini_pro模型,您会看到它已添加到位于“模型”部分的gemini_demo数据集中。 -
在“探索器”中,点击 gemini_pro 模型,查看详细信息和架构。
点击检查我的进度以验证是否完成了以下目标:
任务 6:提示 Gemini 分析顾客评价中的关键字和情绪
在此项任务中,您将使用 Gemini Pro 模型分析每条顾客评价的正面或负面情绪。
分析顾客评价的正面和负面情绪
-
使用下方代码创建一个新的代码单元:
# Create the sentiment analysis table %%bigquery CREATE OR REPLACE TABLE `gemini_demo.customer_reviews_analysis` AS ( SELECT ml_generate_text_llm_result, social_media_source, review_text, customer_id, location_id, review_datetime FROM ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_pro`, ( SELECT social_media_source, customer_id, location_id, review_text, review_datetime, CONCAT( 'Classify the sentiment of the following text as positive or negative.', review_text, "In your response don't include the sentiment explanation. Remove all extraneous information from your response, it should be a boolean response either positive or negative.") AS prompt FROM `gemini_demo.customer_reviews` ), STRUCT( 0.2 AS temperature, TRUE AS flatten_json_output))); -
运行此单元。
此查询会从
customer_reviews表提取顾客评价、构建提示,然后将它们与gemini_pro模型结合使用,对每条评价的情绪进行分类。生成的结果会存储在一个名为customer_reviews_analysis的新表中,方便您稍后开展进一步分析。请耐心等待一会,该模型大约需要 30 秒时间来处理顾客评价记录。
模型完成处理后,将会创建
customer_reviews_analysis表。 -
在“探索器”中,点击 customer_reviews_analysis 表,查看架构和详细信息。
-
使用下方代码创建一个新的代码单元:
# Pull the first 100 records from the customer_reviews_analysis table %%bigquery SELECT * FROM `gemini_demo.customer_reviews_analysis` ORDER BY review_datetime -
运行此单元。
这样将生成包含
ml_generate_text_llm_result列(包含情感分析)、顾客评价文本、客户 ID 和地理位置 ID 的行。请查看这些记录。您可能会注意到,其中一些正面或负面结果的格式不正确、包含多余的字符,例如英文句点或额外空格。您可以通过下面的视图清理记录。
创建一个用于清理记录的视图
-
使用下方代码创建一个新的代码单元:
# Sanitize the records within a new view %%bigquery CREATE OR REPLACE VIEW gemini_demo.cleaned_data_view AS SELECT REPLACE(REPLACE(LOWER(ml_generate_text_llm_result), '.', ''), ' ', '') AS sentiment, REGEXP_REPLACE( REGEXP_REPLACE( REGEXP_REPLACE(social_media_source, r'Google(\+|\sReviews|\sLocal|\sMy\sBusiness|\sreviews|\sMaps)?', 'Google'), 'YELP', 'Yelp' ), r'SocialMedia1?', 'Social Media' ) AS social_media_source, review_text, customer_id, location_id, review_datetime FROM `gemini_demo.customer_reviews_analysis`; -
运行此单元。
这段代码将创建名为
cleaned_data_view的视图,并包含情绪评估结果、顾客评价文本、客户 ID 和地理位置 ID。然后它将提取情绪评估结果(正面或负面)并确保所有字母均为小写格式,且已移除多余的字符,例如额外的空格或英文句点。生成的视图便于您在本实验的稍后步骤中开展进一步分析。 -
使用下方代码创建一个新的代码单元:
# Pull the first 100 records from the cleaned_data_view view %%bigquery SELECT * FROM `gemini_demo.cleaned_data_view` ORDER BY review_datetime -
运行此单元。
请注意,现在
sentiment列已拥有干净的正面和负面评价值。您可以在稍后的步骤中使用此视图构建一份报告。
创建正面和负面评价数量报告
您可以使用 Python 和 Matplotlib 库创建包含正面和负面评价数量的条形图报告。
-
创建新的代码单元以使用 BigQuery 客户端查询 cleaned_data_view 中的正面和负面评价,并按情绪进行分组,然后将结果存储在一个 DataFrame 中。
# Task 6.5 - Create the BigQuery client, and query the cleaned data view for positive and negative reviews, store the results in a dataframe and then show the first 10 records client = bigquery.Client() query = "SELECT sentiment, COUNT(*) AS count FROM `gemini_demo.cleaned_data_view` WHERE sentiment IN ('positive', 'negative') GROUP BY sentiment;" query_job = client.query(query) results = query_job.result().to_dataframe() results.head(10) -
运行此单元。
单元运行完成后,将生成一个表格,其中包含正面评价总数和负面评价总数。
-
创建一个新单元来为报告定义变量。
# Define variable for the report. sentiment = results["sentiment"].tolist() count = results["count"].tolist() -
运行此单元。这段代码没有输出结果。
-
创建一个新单元来构建报告。
# Task 6.7 - Build the report. plt.bar(sentiment, count, color='skyblue') plt.xlabel("Sentiment") plt.ylabel("Total Count") plt.title("Bar Chart from BigQuery Data") plt.show() -
运行此单元。
这将生成一个展示正面和负面评价数量的条形图。
-
或者,您也可以使用下方代码构建一个简单直观、带有颜色标记的负面和正面情绪数量报告:
# Create an HTML table for the counts of negative and positive sentiment and color codes the results. html_counts = f"""
""" # Display the HTML tables display(HTML(html_counts))Negative Positive {count[0]} {count[1]}
点击检查我的进度以验证是否完成了以下目标:
任务 7:回复顾客评价
Data Beans 想要对使用图片和录音的顾客评价展开实验。在此笔记本的这一部分,您将使用 Cloud Storage、BigQuery、Gemini Flash 和 Python 对提供给 Data Beans 的图片和音频文件格式的顾客评价进行情感分析。然后您将根据分析结果生成客户服务回复,以便发回给顾客感谢他们的评价,并获得有关咖啡馆可以根据评价采取的措施的建议。
您将尝试两种方法来执行此任务,即规模化回复以及针对个别的图片和音频文件回复,这样您将能了解到如何创建一个面向客户服务代表的概念验证应用。这将使客户反馈流程实现“人机协同”策略,客户服务代表可以同时对顾客和各个咖啡馆执行操作。
使用 JSON 响应规模化处理音频文件
-
创建一个新单元来对音频文件进行情感分析并回复顾客。
# Conduct sentiment analysis on audio files and respond to the customer. vertexai.init(project="{{{project_0.project_id|Project ID}}}", location="{{{project_0.default_region|region}}}") model = GenerativeModel(model_name="gemini-1.5-flash") prompt = """ Please provide a transcript for the audio. Then provide a summary for the audio. Then identify the keywords in the transcript. Be concise and short. Do not make up any information that is not part of the audio and do not be verbose. Then determine the sentiment of the audio: positive, neutral or negative. Also, you are a customr service representative. How would you respond to this customer review? From the customer reviews provide actions that the location can take to improve. The response and the actions should be simple, and to the point. Do not include any extraneous characters in your response. Answer in JSON format with five keys: transcript, summary, keywords, sentiment, response and actions. Transcript should be a string, summary should be a sting, keywords should be a list, sentiment should be a string, customer response should be a string and actions should be string. """ bucket_name = "{{{project_0.project_id|Project ID}}}-bucket" folder_name = 'gsp1249/audio' # Include the trailing '/' def list_mp3_files(bucket_name, folder_name): storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) print('Accessing ', bucket, ' with ', storage_client) blobs = bucket.list_blobs(prefix=folder_name) mp3_files = [] for blob in blobs: if blob.name.endswith('.mp3'): mp3_files.append(blob.name) return mp3_files file_names = list_mp3_files(bucket_name, folder_name) if file_names: print("MP3 files found:") print(file_names) for file_name in file_names: audio_file_uri = f"gs://{bucket_name}/{file_name}" print('Processing file at ', audio_file_uri) audio_file = Part.from_uri(audio_file_uri, mime_type="audio/mpeg") contents = [audio_file, prompt] response = model.generate_content(contents) print(response.text) else: print("No MP3 files found in the specified folder.") 此单元的一些要点如下:
- 第一行使用您的项目 ID 和区域初始化 Vertex AI,您将需要填充这些值。
- 下一行将在 BigQuery 中创建一个模型,并基于 Gemini Flash 模型为该模型命名。
- 然后定义 Gemini Flash 模型将使用的提示。该提示能有效地将音频文件转换为文本,然后分析文本的情绪,待分析完成后,为每个文件创建一份客户回复。
- 您需要将存储桶设置为 bucket_name 字符串变量。注意:folder_name 也将用于 gsp1249/audio 子文件夹。请勿更改。
- 将会创建一个名为 list_mp3_files 的函数,用于识别存储桶中的所有 mp3 文件。然后 Gemini Flash 模型将在 if 语句中处理这些文件。
-
运行此单元。
全部的 5 个音频文件均已经过分析,分析结果以 JSON 响应的形式提供。随后可对该 JSON 响应进行解析并转送到合适的应用以回复顾客,或者转送到需要采取改进措施的地点。
创建面向客户服务代表的应用
在本实验的这个部分,您将学习如何基于负面评价分析结果创建一个客户服务应用。您将完成以下操作:
- 使用与上个单元相同的提示分析一条负面评价。
- 生成负面评价音频文件的转写内容,根据模型输出创建格式适当的 JSON 对象,并将 JSON 对象的特定部分保存为 Python 变量,以便在应用中将其与 HTML 结合使用。
- 生成 HTML 表格,加载顾客在评价中上传的图片,并在播放器中加载音频文件。
- 显示包含图片和音频文件播放器的 HTML 表格。
-
创建一个新单元,输入下方代码,这样就可以生成负面评价音频文件的转写内容、创建 JSON 对象和关联的变量。
# Generate the transcript for the negative review audio file, create the JSON object, and associated variables audio_file_uri = f"gs://{bucket_name}/{folder_name}/data-beans_review_7061.mp3" print(audio_file_uri) audio_file = Part.from_uri(audio_file_uri, mime_type="audio/mpeg") contents = [audio_file, prompt] response = model.generate_content(contents) print('Generating Transcript...') #print(response.text) results = response.text # print("your results are", results, type(results)) print('Transcript created...') print('Transcript ready for analysis...') json_data = results.replace('```json', '') json_data = json_data.replace('```', '') jason_data = '"""' + results + '"""' # print(json_data, type(json_data)) data = json.loads(json_data) # print(data) transcript = data["transcript"] summary = data["summary"] sentiment = data["sentiment"] keywords = data["keywords"] response = data["response"] actions = data["actions"] 此单元的一些要点如下:
- 单元中的代码将从 Cloud Storage 中选择一个特定的音频文件 (data-beans_review_7061.mp3)。
- 然后将文件发送给上个单元中标记为 Task 7.1 的提示,Gemini Flash 模型随即会处理该提示。
- 该模型的响应将提取为 JSON 格式。
- 然后对 JSON 数据进行解析,并为转写内容、摘要、情绪、关键字、客户回复和行动措施存储 Python 变量。
-
运行该单元。
输出内容极少,只有已处理的音频文件的 uri 和处理消息。
-
根据选定的值创建一个基于 HTML 的表格,将包含负面评价的音频文件加载到播放器中。
# Create an HTML table (including the image) from the selected values. html_string = f""" customer_id: 7061 - @coffee_lover789
""" print('The table has been created.'){transcript} {sentiment} feedback {keywords[0]} {keywords[1]} {keywords[2]} {keywords[3]} Customer summary:{summary} Recommended actions:{actions} Suggested Response:{response} 此单元的一些要点如下:
- 单元中的代码将构建一个 HTML 表格字符串。
- 然后将转写内容、情绪、关键字、图片、摘要、行动措施和回复的值插入表格的单元格。
- 该代码还将对表格元素应用样式。
- 单元运行后,将在表格创建好时显示提示。
-
找到包含
{summary}输出内容的<td style="padding:10px;">标记。在此标记前添加新代码行。 -
将
<td rowspan="3" style="padding: 10px;"><img src="<authenticated url here>" alt="Customer Image" style="max-width: 300px;"></td>粘贴到该新代码行。 -
找到 image_7061.png 文件的要求验证身份的网址。前往 Cloud Storage,选择那里的唯一一个存储桶,选择图片文件夹,然后点击该图片。
-
在显示的页面上,复制该图片的要求验证身份的网址。
-
返回到 BigQuery 中的 Python 笔记本。在您刚刚粘贴的代码中,用实际的要求验证身份的网址替换
<authenticated url here>。 -
运行该单元。
输出内容同样极少。只有一些处理消息,指示每个步骤已完成。
-
使用下方代码创建一个新单元,以下载音频文件并将其加载到播放器中:
# Download the audio file from Google Cloud Storage and load into the player storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) blob = bucket.blob(f"{folder_name}/data-beans_review_7061.mp3") audio_bytes = io.BytesIO(blob.download_as_bytes()) # Assuming a sample rate of 44100 Hz (common for MP3 files) sample_rate = 44100 print('The audio file is loaded in the player.') 此单元的一些要点如下:
- 单元中的代码将访问 Cloud Storage 存储桶并检索特定的音频文件 (data-beans_review_7061.mp3)。
- 然后将该文件下载为字节流并确定文件的采样率,以便其可以直接在笔记本内的播放器中播放。
- 单元运行后,将输出一条消息说明音频文件已加载到播放器中并准备好播放。
-
运行该单元。
-
创建一个新单元并输入下方代码:
# Task 7.5 - Build the mockup as output to the cell. print('Analysis complete. Review the results below.') display(HTML(html_string)) display(Audio(audio_bytes.read(), rate=sample_rate, autoplay=True)) -
运行该单元。
该单元具有神奇的效果。使用了 display 方法来显示 HTML 和加载到播放器中的音频文件。请查看该单元的输出结果。它看起来应如下图所示:
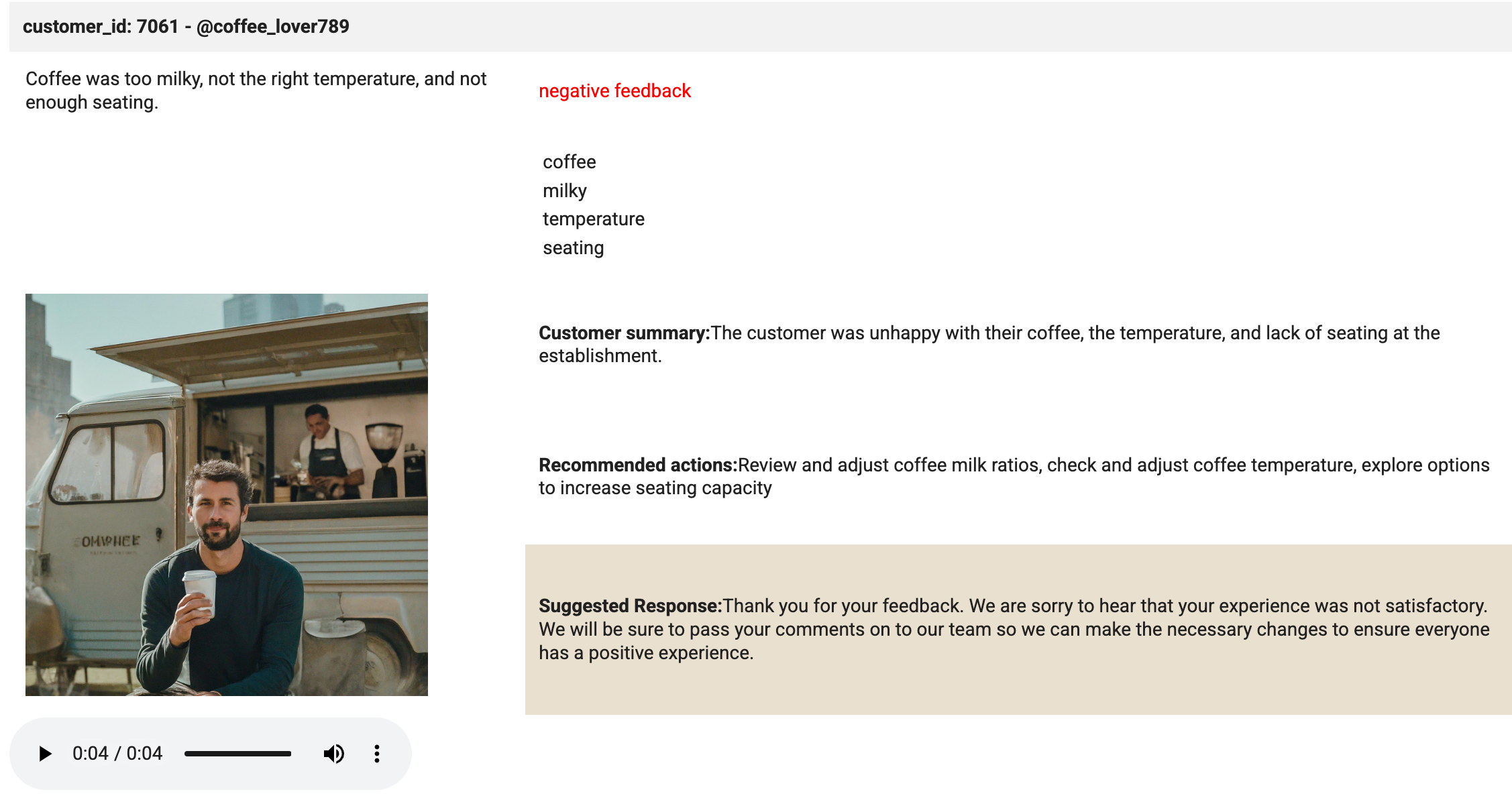
点击检查我的进度以验证是否完成了以下目标:
恭喜!
您成功在 BigQuery 中创建了 Cloud 资源连接。您还创建了数据集、表格和模型来提示 Gemini 分析顾客评价的情绪和关键字。最后,您使用 Gemini 分析了以音频为主的顾客评价,以生成摘要和关键字来在客户服务应用中回复顾客评价。
后续步骤/了解详情
Google Cloud 培训和认证
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
上次更新手册的时间:2024 年 7 月 26 日
上次测试实验的时间:2024 年 7 月 26 日
版权所有 2024 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。

