检查点
Create BigQuery Python notebook and connect to runtime
/ 10
Create the cloud resource connection and grant IAM role
/ 10
Review images, dataset, and grant IAM role to service account
/ 10
Create the dataset and customer reviews table in BigQuery
/ 30
Create the Gemini Pro model in BigQuery
/ 10
Prompt Gemini to analyze customer reviews for keywords and sentiment
/ 20
Respond to customer reviews
/ 10
搭配使用 Python 筆記本,運用 Gemini 分析顧客評論
GSP1249

總覽
本實驗室將說明如何搭配運用 BigQuery Machine Learning 和遠端模型 (Gemini Pro),在顧客評論中擷取關鍵字和評估顧客情緒。
BigQuery 是內建 AI 的全代管資料分析平台,專為多引擎、跨格式和多雲端的環境而設計,可充分發揮資料的價值。其中一項重要功能就是 BigQuery Machine Learning,可使用 SQL 查詢或 Colab Enterprise 筆記本建立和執行機器學習 (ML) 模型。
Gemini 是由 Google DeepMind 開發的一系列生成式 AI 模型,專為多模態用途而設計。透過 Gemini API,您可以存取 Gemini Pro、Gemini Pro Vision 和 Gemini Flash 模型。
在本實驗室的最後,您將在 BigQuery 的 Colab Enterprise 筆記本中打造 Python 客戶服務應用程式,使用 Gemini Flash 模型回應音訊型顧客評論。
目標
本實驗室的內容包括:
- 使用 Colab Enterprise 在 BigQuery 中建立 Python 筆記本。
- 在 BigQuery 建立雲端資源連線。
- 在 BigQuery 建立資料集和資料表。
- 在 BigQuery 建立 Gemini 遠端模型。
- 提示 Gemini 分析顧客評論文字中的關鍵字和情緒 (正面或負面)。
- 生成報表,計算正面和負面評論的數量。
- 大規模回應顧客評論。
- 為客服代表打造應用程式,回應音訊型的顧客評論。
設定和需求
點選「Start Lab」按鈕前的須知事項
請詳閱以下操作說明。研究室活動會計時,而且中途無法暫停。點選「Start Lab」 後就會開始計時,讓您瞭解有多少時間可以使用 Google Cloud 資源。
您將在真正的雲端環境中完成實作研究室活動,而不是在模擬或示範環境。為達此目的,我們會提供新的暫時憑證,讓您用來在研究室活動期間登入及存取 Google Cloud。
如要完成這個研究室活動,請先確認:
- 您可以使用標準的網際網路瀏覽器 (Chrome 瀏覽器為佳)。
- 是時候完成研究室活動了!別忘了,活動一開始將無法暫停。
如何開始研究室及登入 Google Cloud 控制台
-
按一下「Start Lab」(開始研究室) 按鈕。如果研究室會產生費用,畫面中會出現選擇付款方式的彈出式視窗。左側的「Lab Details」窗格會顯示下列項目:
- 「Open Google Cloud console」按鈕
- 剩餘時間
- 必須在這個研究室中使用的暫時憑證
- 完成這個實驗室所需的其他資訊 (如有)
-
點選「Open Google Cloud console」;如果使用 Chrome 瀏覽器,也能按一下滑鼠右鍵,然後選取「在無痕式視窗中開啟連結」。
接著,實驗室會啟動相關資源並開啟另一個分頁,當中顯示「登入」頁面。
提示:您可以在不同的視窗中並排開啟分頁。
注意:如果頁面中顯示「選擇帳戶」對話方塊,請點選「使用其他帳戶」。 -
如有必要,請將下方的 Username 貼到「登入」對話方塊。
{{{user_0.username | "Username"}}} 您也可以在「Lab Details」窗格找到 Username。
-
點選「下一步」。
-
複製下方的 Password,並貼到「歡迎使用」對話方塊。
{{{user_0.password | "Password"}}} 您也可以在「Lab Details」窗格找到 Password。
-
點選「下一步」。
重要事項:請務必使用實驗室提供的憑證,而非自己的 Google Cloud 帳戶憑證。 注意:如果使用自己的 Google Cloud 帳戶來進行這個實驗室,可能會產生額外費用。 -
按過後續的所有頁面:
- 接受條款及細則。
- 由於這是臨時帳戶,請勿新增救援選項或雙重驗證機制。
- 請勿申請免費試用。
Google Cloud 控制台稍後會在這個分頁開啟。

工作 1:建立 BigQuery Python 筆記本並連線至執行階段
在這項工作中,您會建立 BigQuery Python 筆記本,將筆記本連線至執行階段。
建立 BigQuery Python 筆記本
-
在 Google Cloud 控制台的導覽選單,點選「BigQuery」。
-
點選歡迎彈出式視窗中的「完成」。
-
點選「Python 筆記本」。
-
在「區域」部分選取
。 -
按一下「選取」。
Python 筆記本也會新增至專案下的 Explorer 筆記本部分。
-
將滑鼠游標懸停在各儲存格上,並點選隨即出現的「垃圾桶」圖示,刪除筆記本中的所有儲存格。
完成後,筆記本應為空白,且您可以進行下一個步驟。
連線至執行階段
-
點選「連線」。
-
點選「Qwiklabs 學生 ID」。
請稍候,最多需要 3 分鐘才能連線至執行階段。
之後,您會在瀏覽器視窗底部看到連線狀態更新為「已連線」。
點選「Check my progress」,確認目標已達成。
工作 2:建立雲端資源連線,授予 IAM 角色
在 BigQuery 建立雲端資源連線
在這項工作中,您會在 BigQuery 建立雲端資源連線,以便使用 Gemini Pro 和 Gemini Flash 模型。您也將調整角色設定,為雲端資源連線的服務帳戶授予 IAM 權限,這樣該服務帳戶就能使用 Vertex AI 服務。
您將使用 Python SDK 和 Google Cloud CLI 建立資源連線,但需要先匯入 Python 程式庫,並設定 project_id 和區域變數。
-
使用以下程式碼建立新的程式碼儲存格:
# Import Python libraries import vertexai from vertexai.generative_models import GenerativeModel, Part from google.cloud import bigquery from google.cloud import storage import json import io import matplotlib.pyplot as plt from IPython.display import HTML, display from IPython.display import Audio from pprint import pprint 這些程式碼將匯入 Python 程式庫。
-
執行此儲存格。程式庫現已載入,可供使用。
-
使用以下程式碼建立新的程式碼儲存格:
# Set Python variables for project_id and region project_id = "{{{project_0.project_id|Project ID}}}" region = " {{{ project_0.default_region | "REGION" }}}" 注意:這裡的 project_id 和區域是儲存為 Python 變數 (而非 SQL 變數),因此在儲存格中參照時只能使用 Python 程式碼 (而非 SQL 程式碼)。 -
執行此儲存格。project_id 和區域變數皆已設定。
-
使用以下程式碼建立新的程式碼儲存格:
# Create the resource connection !bq mk --connection \ --connection_type=CLOUD_RESOURCE \ --location=US \ gemini_conn 這些程式碼會使用 Google Cloud CLI 指令
bq mk --conection建立資源連線。 -
執行此儲存格。資源連線現已建立。
-
在 Explorer 中,點選專案 ID 旁邊的「查看動作」按鈕。
-
選擇「重新整理內容」。
-
展開「外部連線」。您會發現
us.gemini_conn現已列為外部連線。 -
按一下「us.gemini_conn」。
-
在「連線資訊」窗格,將服務帳戶 ID 複製到文字檔案,方便在下一項工作中使用。
為連線的服務帳戶授予 Vertex AI 使用者角色
-
在控制台的導覽選單,點選「IAM 與管理」。
-
點選「授予存取權」。
-
在「新主體」欄位,輸入先前複製的服務帳戶 ID。
-
在「請選擇角色」欄位輸入「Vertex AI」,然後選取「Vertex AI 使用者」角色。
-
點選「儲存」。
現在服務帳戶會具備 Vertext AI 使用者角色。
點選「Check my progress」,確認目標已達成。
工作 3:查看音訊檔和資料集,並為服務帳戶授予 IAM 角色
在這項工作中,您將查看資料集和音訊檔,然後為雲端資源連線的服務帳戶授予 IAM 權限。
查看 Cloud Storage 中的音訊檔、圖片檔和顧客評論資料集
在開始執行這項工作,並為資源連線服務帳戶授予權限前,請先查看資料集和圖片檔。
-
在 Google Cloud 控制台,依序選取「導覽選單」圖示
和「Cloud Storage」。
-
點選「
-bucket」bucket。 -
開啟此 bucket 中的 gsp1249 資料夾,您會看到五個項目:
-
audio資料夾包含所有將分析的音訊檔案。您可以開啟此資料夾,查看音訊檔。 -
customer_reviews.csv檔案是含有顧客評論文字的資料集。 -
images資料夾含有本實驗室之後要使用的圖片檔。歡迎前往此資料夾及查看其中的圖片檔。 -
notebook.ipynb是您要在本實驗室建立的筆記本副本。您可以視需要查看檔案。
注意:您可以使用驗證網址下載及查看各項目。 -
為連線的服務帳戶授予 IAM Storage 物件管理員角色
請先為資源連線的服務帳戶授予 IAM 權限,再開始使用 BigQuery,這樣能確保在執行查詢時,不會遇到存取遭拒錯誤。
-
返回 bucket 的根層級。
-
點選「權限」。
-
點選「授予存取權」。
-
在「新主體」欄位,輸入先前複製的服務帳戶 ID。
-
在「請選擇角色」欄位輸入「Storage 物件」,然後選取「Storage 物件管理員」角色。
-
點選「儲存」。
現在服務帳戶會具備 Storage 物件管理員角色。
點選「Check my progress」,確認目標已達成。
工作 4:在 BigQuery 建立資料集和顧客評論資料表
在這項工作中,您會建立專案資料集與顧客評論資料表。
建立資料集
資料集會用到下列屬性:
| 欄位 | 值 |
|---|---|
| 資料集 ID | gemini_demo |
| 位置類型 | 選取「多區域」 |
| 多區域 | 選取「美國」 |
-
回到 BigQuery 中的 Python 筆記本。
-
使用以下程式碼建立新的程式碼儲存格:
# Create the dataset %%bigquery CREATE SCHEMA IF NOT EXISTS `{{{project_0.project_id|Project ID}}}.gemini_demo` OPTIONS(location="US"); 注意,程式碼的開頭為
%%bigquery,讓 Python 瞭解在陳述式後方的程式碼是 SQL 程式碼。 -
執行此儲存格。
SQL 程式碼就會在專案中建立
gemini_demo資料集,列在 BigQuery Explorer 專案下方的美國地區。
建立含有樣本資料的顧客評論資料表
為了建立顧客評論資料表,您會使用 SQL 查詢。
-
使用以下程式碼建立新的程式碼儲存格:
# Create the customer reviews table %%bigquery LOAD DATA OVERWRITE gemini_demo.customer_reviews (customer_review_id INT64, customer_id INT64, location_id INT64, review_datetime DATETIME, review_text STRING, social_media_source STRING, social_media_handle STRING) FROM FILES ( format = 'CSV', uris = ['gs://{{{project_0.project_id|Project ID}}}-bucket/gsp1249/customer_reviews.csv']); -
執行此儲存格。
系統就會建立含有顧客評論範例資料的
customer_reviews資料表,包含資料集內每個評論的customer_review_id、customer_id、location_id、review_datetime、review_text、social_media_source和social_media_handle。 -
在 Explorer 點選「customer_reviews」資料表,查看結構定義和詳細資料。
-
使用下方程式碼建立新的程式碼儲存格,透過查詢資料表來查看記錄。
# Create the customer reviews table %%bigquery SELECT * FROM `gemini_demo.customer_reviews` ORDER BY review_datetime -
執行此儲存格。
系統就會顯示資料表中的記錄,包含所有資料欄。
點選「Check my progress」,確認目標已達成。
工作 5:在 BigQuery 中建立 Gemini Pro 模型
現在資料表已建立,可以開始使用了。這項工作要在 BigQuery 中建立 Gemini Pro 模型。
-
返回 Python 筆記本。
-
使用以下程式碼建立新的程式碼儲存格:
# Create the customer reviews table %%bigquery CREATE OR REPLACE MODEL `gemini_demo.gemini_pro` REMOTE WITH CONNECTION `us.gemini_conn` OPTIONS (endpoint = 'gemini-pro') -
執行此儲存格。
系統會建立
gemini_pro模型,並新增至模型專區的gemini_demo資料集。 -
在 Explorer 點選「gemini_pro」模型,查看詳細資料和結構定義。
點選「Check my progress」,確認目標已達成。
工作 6:提示 Gemini 分析顧客評論的關鍵字和情緒
在這項工作中,您會使用 Gemini Pro 模型,分析每個顧客評論的正/負面情緒。
分析顧客評論的正/負面情緒
-
使用以下程式碼建立新的程式碼儲存格:
# Create the sentiment analysis table %%bigquery CREATE OR REPLACE TABLE `gemini_demo.customer_reviews_analysis` AS ( SELECT ml_generate_text_llm_result, social_media_source, review_text, customer_id, location_id, review_datetime FROM ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_pro`, ( SELECT social_media_source, customer_id, location_id, review_text, review_datetime, CONCAT( 'Classify the sentiment of the following text as positive or negative.', review_text, "In your response don't include the sentiment explanation. Remove all extraneous information from your response, it should be a boolean response either positive or negative.") AS prompt FROM `gemini_demo.customer_reviews` ), STRUCT( 0.2 AS temperature, TRUE AS flatten_json_output))); -
執行此儲存格。
這項查詢會從
customer_reviews資料表擷取顧客評論、建立提示,然後透過gemini_pro模型使用提示來區分每個評論的情緒。查詢結果會儲存至新資料表customer_reviews_analysis中,您稍後可進一步用於分析。請稍候。模型約需 30 秒來處理顧客評論記錄。
模型處理完畢後,就會建立
customer_reviews_analysis資料表。 -
在 Explorer 點選「customer_reviews_analysis」資料表,查看結構定義和詳細資料。
-
使用以下程式碼建立新的程式碼儲存格:
# Pull the first 100 records from the customer_reviews_analysis table %%bigquery SELECT * FROM `gemini_demo.customer_reviews_analysis` ORDER BY review_datetime -
執行此儲存格。
結果會是含有
ml_generate_text_llm_result資料欄 (含情緒分析) 的多個資料列、顧客評論文字、顧客 ID 和地點 ID。請查看記錄。您可能會發現,有些正面和負面結果的格式不正確,含有句號或空格等額外字元。您可以使用下列 view 清理記錄。
建立 view 以清理記錄
-
使用以下程式碼建立新的程式碼儲存格:
# Sanitize the records within a new view %%bigquery CREATE OR REPLACE VIEW gemini_demo.cleaned_data_view AS SELECT REPLACE(REPLACE(LOWER(ml_generate_text_llm_result), '.', ''), ' ', '') AS sentiment, REGEXP_REPLACE( REGEXP_REPLACE( REGEXP_REPLACE(social_media_source, r'Google(\+|\sReviews|\sLocal|\sMy\sBusiness|\sreviews|\sMaps)?', 'Google'), 'YELP', 'Yelp' ), r'SocialMedia1?', 'Social Media' ) AS social_media_source, review_text, customer_id, location_id, review_datetime FROM `gemini_demo.customer_reviews_analysis`; -
執行此儲存格。
程式碼會建立名為
cleaned_data_view的 view,並納入情緒結果、評論文字、顧客 ID 和地點 ID。此 view 會擷取情緒結果 (正面或負面),確保所有英文字母均改為小寫,並移除額外的空格或句號。這樣一來,就能更輕鬆在本實驗室的後續步驟中進一步分析這個 view。 -
使用以下程式碼建立新的程式碼儲存格:
# Pull the first 100 records from the cleaned_data_view view %%bigquery SELECT * FROM `gemini_demo.cleaned_data_view` ORDER BY review_datetime -
執行此儲存格。
請注意,現在
sentiment欄已有了正面/負面評論的乾淨值。您可以在後續步驟使用這個 view 建構報表。
建立正/負面評論數量的報表
您可以使用 Python 和 Matplotlib 程式庫,建立含有正面/負面評論數的長條圖報表。
-
建立新的程式碼儲存格,使用 BigQuery 用戶端查詢 cleaned_data_view 中的正面和負面評論,然後依情緒將評論歸類,將結果儲存在 DataFrame。
# Task 6.5 - Create the BigQuery client, and query the cleaned data view for positive and negative reviews, store the results in a dataframe and then show the first 10 records client = bigquery.Client() query = "SELECT sentiment, COUNT(*) AS count FROM `gemini_demo.cleaned_data_view` WHERE sentiment IN ('positive', 'negative') GROUP BY sentiment;" query_job = client.query(query) results = query_job.result().to_dataframe() results.head(10) -
執行此儲存格。
執行後會產生一個資料表,內含正面及負面評論的總數量。
-
建立新的儲存格來定義報表變數。
# Define variable for the report. sentiment = results["sentiment"].tolist() count = results["count"].tolist() -
執行此儲存格。沒有輸出內容。
-
建立新的儲存格來建構報表。
# Task 6.7 - Build the report. plt.bar(sentiment, count, color='skyblue') plt.xlabel("Sentiment") plt.ylabel("Total Count") plt.title("Bar Chart from BigQuery Data") plt.show() -
執行此儲存格。
結果會產生一張包含正面/負面評論數量的長條圖。
-
或者,您也可以使用下方的程式碼,建構一個簡單並套用顏色的正面/負面情緒數量報表:
# Create an HTML table for the counts of negative and positive sentiment and color codes the results. html_counts = f"""
""" # Display the HTML tables display(HTML(html_counts))Negative Positive {count[0]} {count[1]}
點選「Check my progress」,確認目標已達成。
工作 7:回應顧客評論
Data beans 希望使用圖片和音訊錄音,多方嘗試分析顧客評論。在筆記本的這一節中,您將使用 Cloud Storage、BigQuery、Gemini Flash 和 Python,對 Data beans 收到的顧客評論圖片和音訊檔案執行情緒分析。您將從產生的分析中生成客戶服務回應,這些回應會傳送給顧客,感謝對方留下評論。另外,也會生成建議措施,供咖啡廳根據評論採取行動。
您將大規模執行這項操作,並在之後搭配使用一張圖片和音訊檔案,以便瞭解如何為客服代表建立概念驗證應用程式。這麼做可在顧客意見回饋程序實現「人機迴圈」策略,客服代表就能同時對顧客和個別咖啡廳採取行動。
透過 JSON 回應大規模處理音訊檔案
-
建立新的儲存格來對音訊檔進行情緒分析,並且回應顧客。
# Conduct sentiment analysis on audio files and respond to the customer. vertexai.init(project="{{{project_0.project_id|Project ID}}}", location="{{{project_0.default_region|region}}}") model = GenerativeModel(model_name="gemini-1.5-flash") prompt = """ Please provide a transcript for the audio. Then provide a summary for the audio. Then identify the keywords in the transcript. Be concise and short. Do not make up any information that is not part of the audio and do not be verbose. Then determine the sentiment of the audio: positive, neutral or negative. Also, you are a customr service representative. How would you respond to this customer review? From the customer reviews provide actions that the location can take to improve. The response and the actions should be simple, and to the point. Do not include any extraneous characters in your response. Answer in JSON format with five keys: transcript, summary, keywords, sentiment, response and actions. Transcript should be a string, summary should be a sting, keywords should be a list, sentiment should be a string, customer response should be a string and actions should be string. """ bucket_name = "{{{project_0.project_id|Project ID}}}-bucket" folder_name = 'gsp1249/audio' # Include the trailing '/' def list_mp3_files(bucket_name, folder_name): storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) print('Accessing ', bucket, ' with ', storage_client) blobs = bucket.list_blobs(prefix=folder_name) mp3_files = [] for blob in blobs: if blob.name.endswith('.mp3'): mp3_files.append(blob.name) return mp3_files file_names = list_mp3_files(bucket_name, folder_name) if file_names: print("MP3 files found:") print(file_names) for file_name in file_names: audio_file_uri = f"gs://{bucket_name}/{file_name}" print('Processing file at ', audio_file_uri) audio_file = Part.from_uri(audio_file_uri, mime_type="audio/mpeg") contents = [audio_file, prompt] response = model.generate_content(contents) print(response.text) else: print("No MP3 files found in the specified folder.") 這個儲存格有幾項重點:
- 第一行程式碼會使用專案 ID 和區域初始化 Vertex AI,因此您需要填入這些值。
- 下一行程式碼會根據 Gemini Flash 模型,在 BigQuery 的已命名模型中建立模型。
- 您需要定義供 Gemini Flash 模型使用的提示。這個提示會有效地將音訊檔案轉換為文字、分析文字中的情緒,並在分析完成後,為每個檔案建立顧客回應。
- 您需要將 bucket 設為 bucket_name 字串變數。注意:gsp1249/audio 子資料夾也會使用 folder_name,請勿變更。
- 系統會建立名為 list_mp3_files 的函式,找出 bucket 內所有 mp3 檔案,然後由 Gemini Flash 模型在 if 陳述式中處理所有檔案。
-
執行此儲存格。
系統就會分析全部 5 個音訊檔案,以 JSON 回應的形式提供分析輸出內容。JSON 回應可據此接受剖析,並轉送至適當應用程式,為顧客提供回應,或向地點建議改進措施。
為客服代表建立應用程式
在實驗室的這一節,您將瞭解如何根據負面評論分析,建立客戶服務應用程式。您將執行以下動作:
- 使用與上一個儲存格相同的提示,分析一條負面評論。
- 生成負面評論音訊檔案的轉錄稿,從模型輸出內容建立格式正確的 JSON 物件,然後將 JSON 物件的特定部分儲存為 Python 變數,這樣就能在應用程式中與 HTML 搭配使用。
- 生成 HTML 資料表,載入顧客在評論中上傳的圖片,並在播放器載入音訊檔案。
- 顯示 HTML 資料表,包含圖片和音訊檔案播放器。
-
建立新儲存格並輸入以下程式碼,即可生成負面評論音訊檔案的轉錄稿,並建立 JSON 物件和相關變數。
# Generate the transcript for the negative review audio file, create the JSON object, and associated variables audio_file_uri = f"gs://{bucket_name}/{folder_name}/data-beans_review_7061.mp3" print(audio_file_uri) audio_file = Part.from_uri(audio_file_uri, mime_type="audio/mpeg") contents = [audio_file, prompt] response = model.generate_content(contents) print('Generating Transcript...') #print(response.text) results = response.text # print("your results are", results, type(results)) print('Transcript created...') print('Transcript ready for analysis...') json_data = results.replace('```json', '') json_data = json_data.replace('```', '') jason_data = '"""' + results + '"""' # print(json_data, type(json_data)) data = json.loads(json_data) # print(data) transcript = data["transcript"] summary = data["summary"] sentiment = data["sentiment"] keywords = data["keywords"] response = data["response"] actions = data["actions"] 這個儲存格有幾項重點:
- 儲存格的程式碼會從 Cloud Storage 選取特定音訊檔案 (data-beans_review_7061.mp3)。
- 檔案會傳送至上一個儲存格中標籤為 Task 7.1 的提示,由 Gemini Flash 模型處理。
- 模型回應會擷取為 JSON 格式。
- JSON 資料會接受剖析,並儲存轉錄稿、摘要、情緒、關鍵字、顧客回應和建議措施的 Python 變數。
-
執行儲存格。
輸出內容非常少,只有已處理音訊檔案的 URI 和處理中的訊息。
-
依所選的值建立 HTML 資料表,將含有負面評論的音訊檔案載入至播放器。
# Create an HTML table (including the image) from the selected values. html_string = f""" customer_id: 7061 - @coffee_lover789
""" print('The table has been created.'){transcript} {sentiment} feedback {keywords[0]} {keywords[1]} {keywords[2]} {keywords[3]} Customer summary:{summary} Recommended actions:{actions} Suggested Response:{response} 這個儲存格有幾項重點:
- 儲存格的程式碼會建立 HTML 資料表字串。
- 請將轉錄稿、情緒、關鍵字、圖片、摘要、建議措施和回應的值插入資料表儲存格。
- 程式碼也會為資料表元素套用樣式。
- 儲存格執行時,儲存格輸出內容會指出資料表的建立時間。
-
找到含有
{summary}輸出內容的<td style="padding:10px;">標記,在標記前面新增程式碼行。 -
將以下內容貼上至新的程式碼行:
<td rowspan="3" style="padding: 10px;"><img src="<authenticated url here>" alt="Customer Image" style="max-width: 300px;"></td>。 -
找出 image_7061.png 檔案的驗證網址。前往 Cloud Storage,選取其中唯一的 bucket、圖片資料夾,然後按一下圖片。
-
在結果頁面,複製圖片的驗證網址。
-
回到 BigQuery 中的 Python 筆記本。在剛剛貼上的程式碼中,將
<authenticated url here>取代為實際的驗證網址。 -
執行儲存格。
同樣地,輸出內容不多,只有一些處理訊息,表示各步驟已完成。
-
使用以下程式碼建立新的儲存格,下載音訊檔案並載入至播放器。
# Download the audio file from Google Cloud Storage and load into the player storage_client = storage.Client() bucket = storage_client.bucket(bucket_name) blob = bucket.blob(f"{folder_name}/data-beans_review_7061.mp3") audio_bytes = io.BytesIO(blob.download_as_bytes()) # Assuming a sample rate of 44100 Hz (common for MP3 files) sample_rate = 44100 print('The audio file is loaded in the player.') 這個儲存格有幾項重點:
- 儲存格的程式碼會存取 Cloud Storage bucket,擷取特定音訊檔案 (data-beans_review_7061.mp3)。
- 程式碼會將檔案下載為位元組串流,判斷檔案的取樣率,方便直接在筆記本的播放器中播放。
- 儲存格執行時,儲存格輸出內容會顯示訊息,指出音訊檔案已載入播放器,可供播放。
-
執行儲存格。
-
建立新的儲存格,輸入以下程式碼:
# Task 7.5 - Build the mockup as output to the cell. print('Analysis complete. Review the results below.') display(HTML(html_string)) display(Audio(audio_bytes.read(), rate=sample_rate, autoplay=True)) -
執行儲存格。
儲存格就是奇蹟發生之處。系統會使用顯示方法,顯示 HTML 和已載入播放器的音訊檔案。請查看儲存格輸出內容,應與下圖相同:
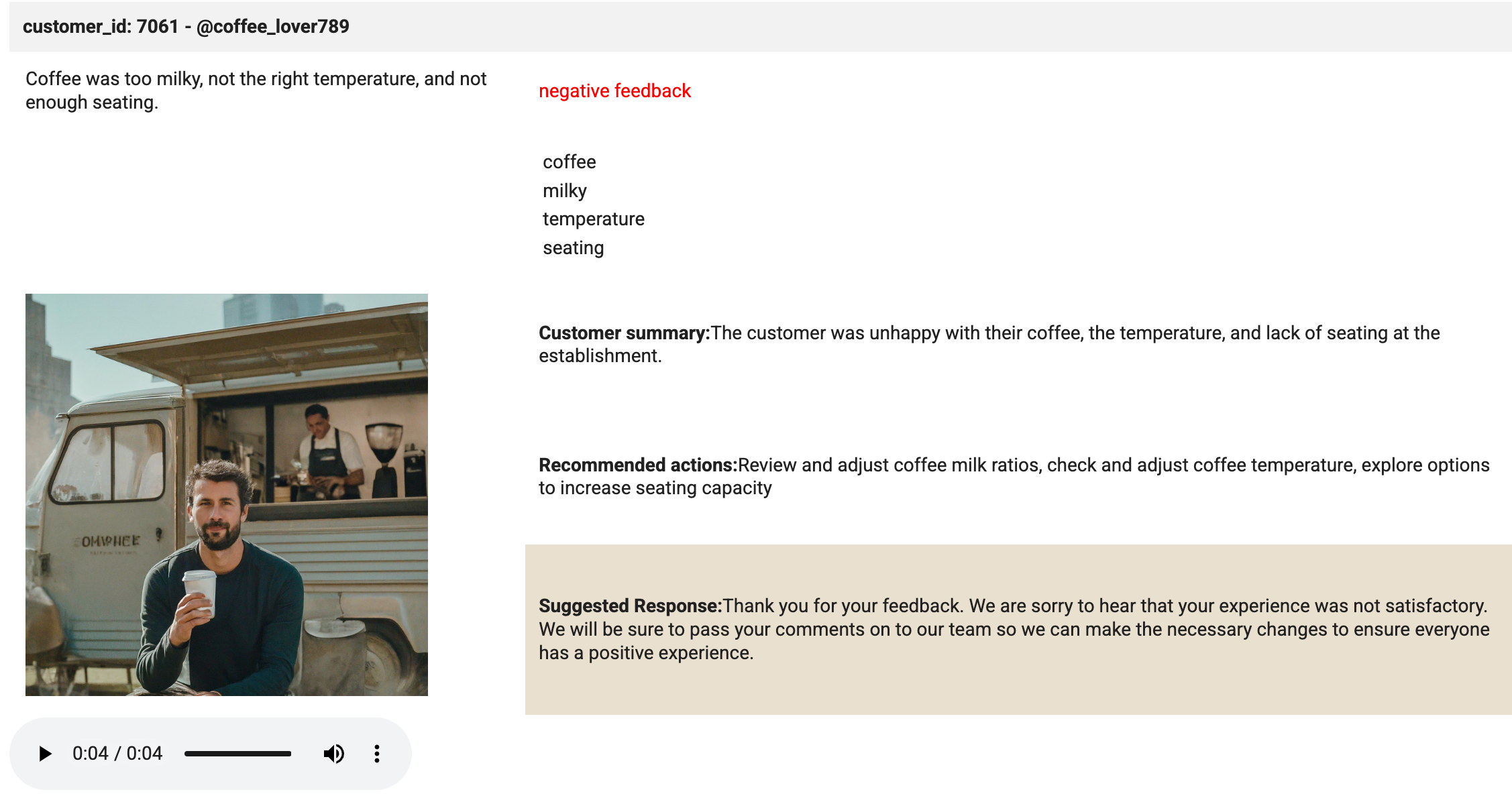
點選「Check my progress」,確認目標已達成。
恭喜!
您已順利在 BigQuery 建立雲端資源連線,也建立了資料集、資料表和模型,提示 Gemini 分析顧客評論中的情緒和關鍵字。最後,您使用 Gemini 分析音訊型顧客評論,生成摘要和關鍵字,在客戶服務應用程式中回應顧客評論。
後續步驟/瞭解詳情
Google Cloud 教育訓練與認證
協助您瞭解如何充分運用 Google Cloud 的技術。我們的課程會介紹專業技能和最佳做法,讓您可以快速掌握要領並持續進修。我們提供從基本到進階等級的訓練課程,並有隨選、線上和虛擬課程等選項,方便您抽空參加。認證可協助您驗證及證明自己在 Google Cloud 技術方面的技能和專業知識。
使用手冊上次更新日期:2024 年 7 月 26 日
實驗室上次測試日期:2024 年 7 月 26 日
Copyright 2024 Google LLC 保留所有權利。Google 和 Google 標誌是 Google LLC 的商標,其他公司和產品名稱則有可能是其關聯公司的商標。

